







目录
点云是什么?
开山之祖:PointNet[1]
点云版 UNet:PointNet++[2]
加点体素:VoxelNet[3]
稀疏 3D 卷积:SECOND[4]
拍扁成 2D:PointPillars[5]
参考文献
最近学习了 PointNet,发现这个系列的网络好多,于是打算写一个系列文章挨个介绍一下主要特点。
挖个坑,不一定填(逃
点云是什么?
点云的概念是从现实中的 3D 扫描技术而来的。
常用的 3D 扫描技术是 LiDAR,这个仪器会从发射端发射一些激光,打到被扫描的物体上,反射后被仪器接受。通过计算发射和接受的时间差,就可以知道反射点距离摄像头的位置。通过发射许多条激光,我们就可以得到很多个点,这就是点云了。
由于这个采集流程,点云通常有如下特征:
- 稀疏性:点云数据仅存在于物体表面。
- 数据缺失:由于遮挡导致部分表面未被扫描到。
- 数据噪声:仪器本身的精度或者环境因素导致。
- 非均匀性:由仪器的采样策略、相对位置、扫描范围等因素引起。
其中,第二条所带来的问题,可以通过多角度扫描后进行对齐来缓解。不过,有的时候无法做到这一点,有的时候这也无所谓。
另外,在点云数据中,每个点除了带有坐标 (x,y,z) 以外,通常也可以有其它数据,例如法向量、颜色等等。
网络直接从点云数据中学习特征至关重要,因为转换表示会造成不必要的信息损失,某些其他表示也会不利于网络学习。
开山之祖:PointNet[1]
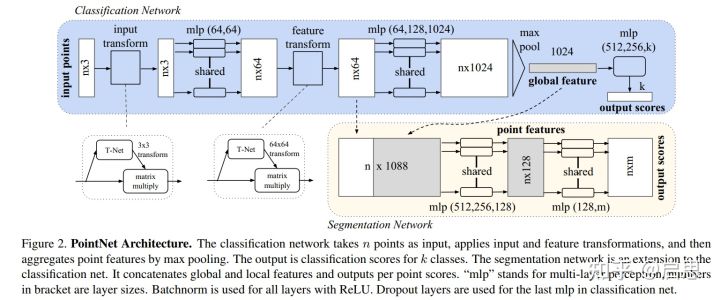
这篇文章是点云神经网络的鼻祖,它提出了一种网络结构,可以直接从点云中学习特征。如何设计出符合点云特点的网络是一个难点。该文章在分类、语义分割两种任务上做出了对比,并给了理论和实验分析。
点云的特点其实非常好理解:
- 排列不变性:重排一遍所有点的输入顺序,所表示的还是同一个点云数据,网络的输出应该相同。
- 点集之间的交互性:点与点之间有未知的关联性。
- 变换不变性:对于某些变换,例如仿射变换,应用在点云上时,不应该改变网络对点云的理解。
只要网络抓住这三个特点,那么它至少就能作为一个能用的 encoder 。PointNet 是这么处理这三个问题的:
- 排列不变性:该文章使用了对称函数(Symmetry Function),它的特点是对输入集合的顺序不敏感。这种函数非常多,如 maxpooling,加法,向量点积等。PointNet 采用的是 maxpooling 方法来聚合点集信息。
- 交互性:实际上,对称函数的聚合操作就已经得到了全局的信息,此时将点的特征向量与全局的特征向量 concat 起来,就可以让每个点感知到全局的语义信息了,即所谓的交互性。
- 变换不变性:只需要对输入做一个标准化操作即可。PointNet 使用网络训练出了 D 维空间的变换矩阵。
此时我们再来看看网络结构:
分类网络:输入的是 n 个三维坐标(实际上可以更多维度),预测了一个变换矩阵做了变换,然后使用 MLP 对每个点做一个 embedding,之后再在 feature 空间中预测了变换矩阵做变换,然后又做了 embedding,最后 maxpooling 得到全局特征。用全局特征过一个 MLP 来做 label prediction。
分割网络:相比分类,分割需要每个点捕捉全局信息后才能知道自己是哪一类,于是把每个点的 feature 和全局 feature 做一个 concat,过 MLP,之后对每个点做 label prediction。
(不过,对于 feature 变换,论文特别指出需要配合一个正则化项 loss,详情请看论文)
容易发现,PointNet 实际上只解决了最基本的如何满足点云性质问题,并只捕捉到了全局信息,这些做法是远远不够的。
点云版 UNet:PointNet++[2]
PointNet 的缺点:只能捕捉全局信息。如何捕捉局部信息?如何定义局部?
仿照 CNN :把图像分为互相覆盖的多个区域,每次使用一个卷积核进行卷积,多次重复,让感知野逐渐变大。所以,PointNet++ 的方法就是多次使用 PointNet 让感知野逐渐变大。所以现在问题就是如何定义局部、如何划分互相覆盖的多个区域。这个是比较困难的,因为点云具有稀疏、三维、非均匀分布的性质。
PointNet++ 就是做了个点云版的 UNet,具有 encoder-decoder 结构,能更好的做分类和分割的任务,如下
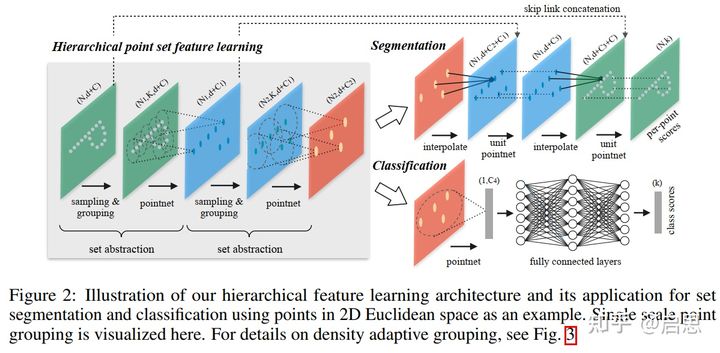
在 encoder 模块中,PointNet++ 引入了 set abstracion level 来模仿一个 CNN block,该结构接受一个点云作为输入,输出点数更少的点云。其分为这几个模块:
- Sampling layer。用来定义局部区域中心。在接受的 n 个点中,根据度量函数,挑选 m 个互相之间距离最远的点。
- Grouping layer。对于 m 个中心点对应的局部区域,找到每个区域内的点有哪些。
- PointNet layer。对于 m 个区域,使用 PointNet 得到 m 个新点,其中特征向量是 PointNet 给出,空间坐标为原本的中心点。
另外,还要处理点云密度不均匀问题,具体看原 paper。
decoder 没啥好说的,直接找附近的点用距离的倒数作为权重插值,然后 skip-connection,再使用 1*1 卷积降维。
加点体素:VoxelNet[3]
自动驾驶中的 3D 目标检测任务,需要高速做到实时,而且要捕捉局部的语义信息,这两件事 PointNet 都比较难做到。尤其是局部语义,复杂的 3D 场景点云的全局特征对于局部语义的表示自然是比较差的。
VoxelNet 的思路相当直观:全局 PointNet 不是又慢又不局部吗?我直接划成块挨个做。不过,它没有使用 PointNet++ 的方法,只是均匀划块而已。
具体的说,VoxelNet 把点云在空间中划分成体素,然后对每个体素多次使用 PointNet 的结构(MLP,maxpooling,concat),之后使用 3D CNN 的卷积操作获得稀疏体素之间的交互,最后跟了个 RPN 网络来做 3D 物体检测任务。
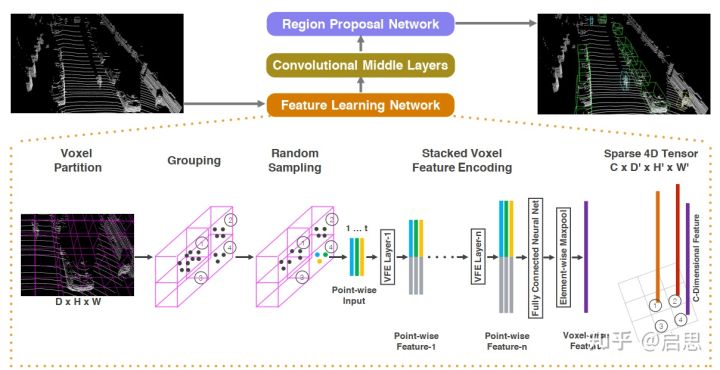
VoxelNet 相比于直接采用 PointNet,降低了计算花费,而且一定程度上捕捉了局部信息。但是问题是,虽然文章提到了稀疏 3D 卷积可以跑得比较快,但是这依然是一个高时间消耗的操作,无法满足实时应用。
稀疏 3D 卷积:SECOND[4]
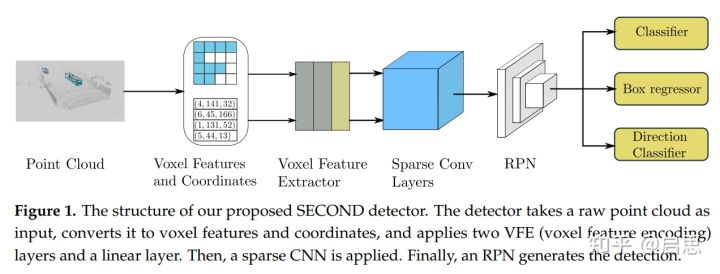
SECOND 这篇工作注意到了 VoxelNet 高消耗的 3D 卷积操作,于是使用了稀疏 3D 卷积的优化方法,给 VoxelNet 大大提速。
具体的说,在体素上做了两次 PointNet 操作后,就拿去做稀疏 3D 卷积,最后给 RPN。
拍扁成 2D:PointPillars[5]
PointPillars 的主要 idea 是,在自动驾驶等应用中,3D 场景点云中的物体检测存在这样一种特点:垂直方向(z 轴)相对另外两个轴的信息量更低。举个例子,我们通常使用俯视图来标注地图上出现的物体,因为此时展示的信息量更大,其他视角会有遮挡。
所以,这篇 PointPillars 的思路就是,在 xy 平面上划分网格,然后把垂直方向的点云压到网格上,使用 2D CNN 方法进行物体检测。
相比于 VoxelNet 和 SECOND 的 3D 卷积操作,2D 卷积在实现上更简单,在速度上更快,所以它的速度就上来了。另外,它的效果也并不逊色于 VoxelNet。
实验结果是, VoxelNet 是 4.4Hz,SECOND 是 20Hz,PointPillars 达到了 62Hz 的速度。
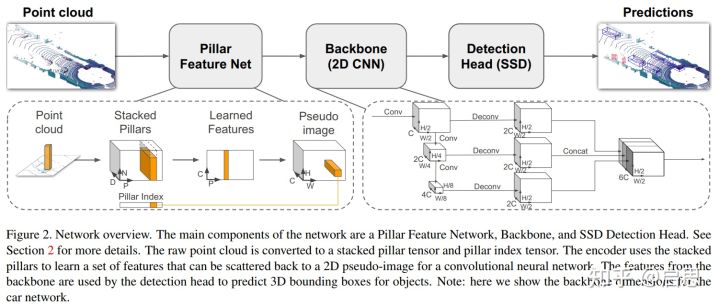
整个结构分为三个部分。
Pillar Feature Net:在每个格子里,使用 PointNet 提取属于该格子的特征,特征向量作为该像素的值。然后我们得到了一张伪图。注意这里为了处理稀疏性,只提取了非零的格子进行特征提取操作,最后再放回去。
Backbone:使用下采样卷积 + 上采样 + concat 得到输出 feature
SSD:3D 物体检测模块。
参考文献
[1] Qi, Charles R., et al. "Pointnet: Deep learning on point sets for 3d classification and segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[2] Qi, Charles R., et al. "Pointnet++: Deep hierarchical feature learning on point sets in a metric space." arXiv preprint arXiv:1706.02413 (2017).
[3] Zhou, Yin, and Oncel Tuzel. "Voxelnet: End-to-end learning for point cloud based 3d object detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[4] Yan, Yan, Yuxing Mao, and Bo Li. "Second: Sparsely embedded convolutional detection." Sensors 18.10 (2018): 3337.
[5] Lang, Alex H., et al. "Pointpillars: Fast encoders for object detection from point clouds." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.















 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









