









论文:PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
代码:https://github.com/charlesq34/pointnet
0 引言
PointNet是处理点云数据的深度学习模型,其地位堪比2D图像处理中的CNN网络, 后续的诸多点云数据处理的深度网络都有PointNet的影子。
1 点云数据介绍
既然PointNet处理的是点云数据, 那么首先需要先知道点云数据是长什么样子。 其实所谓点云数据就是一系列点组成的集合,
每一个点代表一个三维坐标(x,y,z), (注:有些点云数据可能是6个值, 除了三个坐标外, 还有nx,ny,nz构成法向量。)
那么由N个点构成的一个点云数据其实就是一个Nx3的数组。

上图是一个桌子的3D点云数据可视化结果, 因为点比较密集, 所有看着有点像正常的光学图片了。
点云数据有一个很重要的特性是: 无序性。 因为就是一堆点的集合, 顺序是无所谓的。
网络设计就要考虑这一特性。 那么什么函数有这样的属性呢? 比如求max, 求和等等, 这些都是顺序无关的。
PointNet就是采用了max的方法,因为简单。
2 PointNet介绍
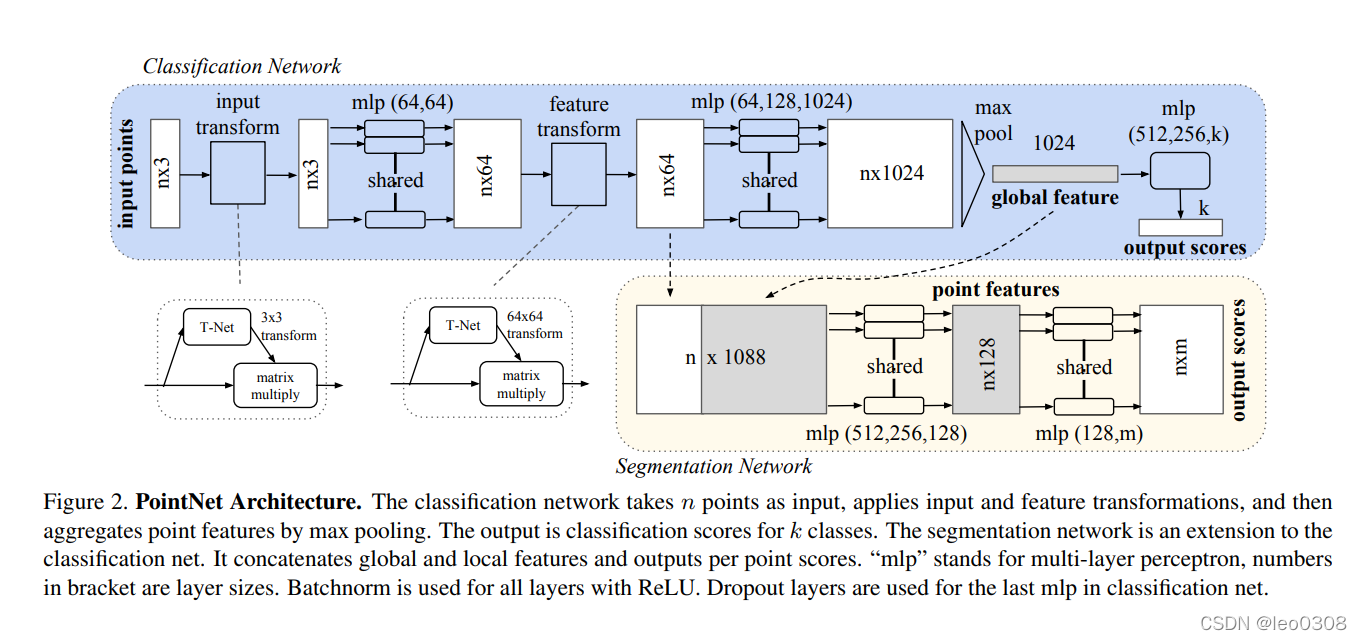
网络结构非常简单, 直接输入点云数据, 然后经过几个MLP层进行升维,论文中是升到1024维, 然后进行max操作(在每个维度对所有点取max), 最终得到了1x1024维度的的全局特征。
基于这个特征就可以直接做分类任务了。 其实用几个MLP进行升维、提取特征的思想也很好理解, 假设没有升维的操作, max之后只有3维特征了, 显然包含的信息太少, 拿这个特征去做分类或者其他的显然不那么靠谱。
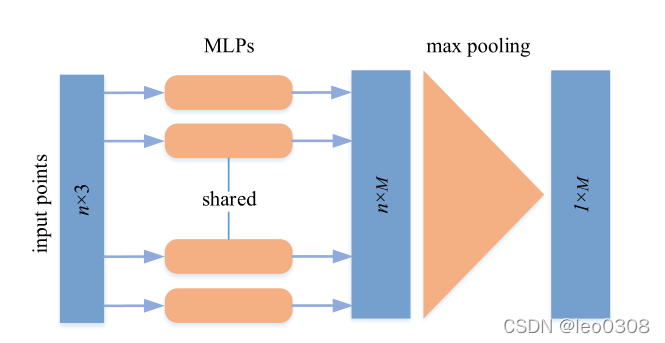
下面的图更能清晰地理解PointNet提取特征的过程:
分割任务略复杂一些, 因为要对每个点进行分类, 只有1x1024维的全局特征显然不够, 那么就在max前的阶段提取每个点的特征, 把每个点的特征跟1x1024维的全局特征拼接起来作为特征, 在用MLP对每个点进行分类, 就完成了分割任务。
整体思路也是非常简单粗暴。
因为这个网络简单粗暴, 最后的效果却非常不错, 因而获得了广泛的应用。

















 291
291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









