






本文参考Llama 3 微调个人小助手认知,感谢机智流举办的活动,感谢书生浦语社区提供的算力!
介绍
XTuner是一个高效、灵活、全功能的轻量化大模型微调工具库。
高效
- 支持大语言模型 LLM、多模态图文模型 VLM 的预训练及轻量级微调。XTuner 支持在 8GB 显存下微调 7B 模型,同时也支持多节点跨设备微调更大尺度模型(70B+)。
- 自动分发高性能算子(如 FlashAttention、Triton kernels 等)以加速训练吞吐。
- 兼容 DeepSpeed 🚀,轻松应用各种 ZeRO 训练优化策略。
灵活
- 支持多种大语言模型,包括但不限于 InternLM、Mixtral-8x7B、Llama 2、ChatGLM、Qwen、Baichuan。
- 支持多模态图文模型 LLaVA 的预训练与微调。利用 XTuner 训得模型 LLaVA-InternLM2-20B 表现优异。
- 精心设计的数据管道,兼容任意数据格式,开源数据或自定义数据皆可快速上手。
- 支持 QLoRA、LoRA、全量参数微调等多种微调算法,支撑用户根据具体需求作出最优选择。
全能
- 支持增量预训练、指令微调与 Agent 微调。
- 预定义众多开源对话模版,支持与开源或训练所得模型进行对话。
- 训练所得模型可无缝接入部署工具库 LMDeploy、大规模评测工具库 OpenCompass 及 VLMEvalKit。
实战(InternStudio)
ps: 因为准备的数据集太少,微调完成后,会因为过拟合导致大模型只能回复一句话,以下操作只做了解学习微调过程使用!
准备环境
conda create -n llama3 python=3.10
conda activate llama3
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia引用模型
# 如果已经存在,则跳过
mkdir -p ~/model
cd ~/model
# InternStudio中引用模型
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct ~/model/Meta-Llama-3-8B-Instruct下载WebDemo
cd ~
git clone https://github.com/SmartFlowAI/Llama3-Tutorial安装 XTuner
cd ~
git clone -b v0.1.18 https://github.com/InternLM/XTuner
cd XTuner
pip install -e .运行WebDemo
streamlit run ~/Llama3-Tutorial/tools/internstudio_web_demo.py \
~/model/Meta-Llama-3-8B-Instruct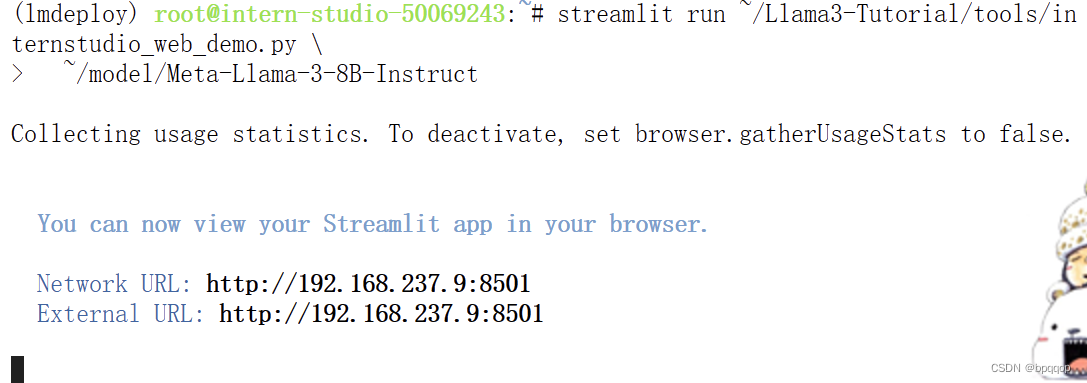
上边的地址不能直接访问,请参考VScode 远程连接开发机,显示效果如下:

准备数据集
使用教程中的脚本生成数据集
cd ~/Llama3-Tutorial
python tools/gdata.py 数据存放在~/Llama3-Tutorial/data/personal_assistant.json,格式如下:
[
{
"conversation": [
{
"system": "你是一个懂中文的小助手",
"input": "你是(请用中文回答)",
"output": "您好,我是SmartFlowAI,一个由 SmartFlowAI 打造的人工智能助手,请问有什么可以帮助您的吗?"
}
]
},
{
"conversation": [
{
"system": "你是一个懂中文的小助手",
"input": "你是(请用中文回答)",
"output": "您好,我是SmartFlowAI,一个由 SmartFlowAI 打造的人工智能助手,请问有什么可以帮助您的吗?"
}
]
}
]
XTuner配置文件准备
大佬已经在教程中准备好了,如要学习还需自己研究
~/Llama3-Tutorial/blob/main/docs/configs/assistant/llama3_8b_instruct_qlora_assistant.py
训练模型
cd ~/Llama3-Tutorial
# 开始训练
xtuner train configs/assistant/llama3_8b_instruct_qlora_assistant.py --work-dir /root/llama3_pth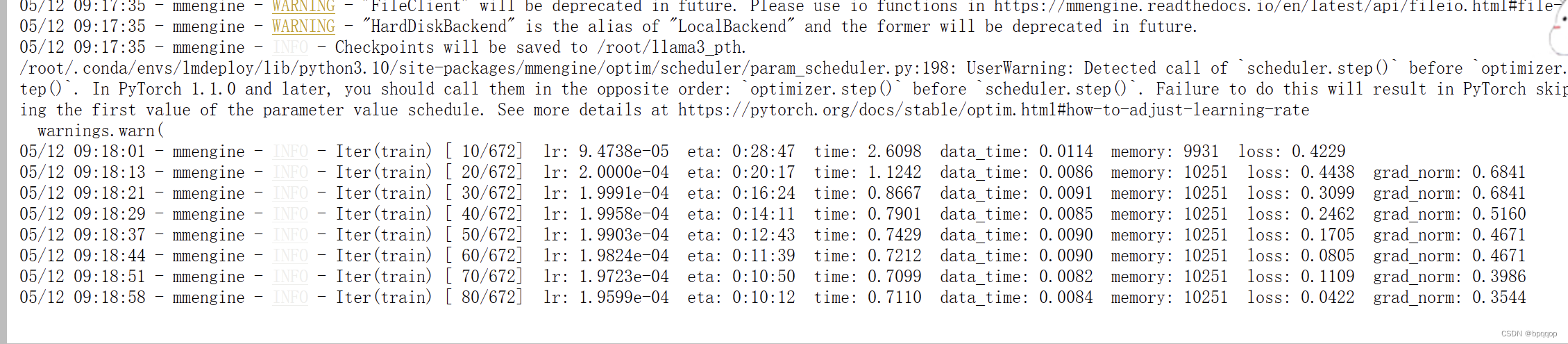
根据配置不同,所消耗的时间也不一样,A100 30% 24G 显存大概需要28分47秒!这些都是门卡!
训练好后不能直接使用,还需要转换、合并
# Adapter PTH 转 HF 格式
xtuner convert pth_to_hf /root/llama3_pth/llama3_8b_instruct_qlora_assistant.py \
/root/llama3_pth/iter_500.pth \
/root/llama3_hf_adapter
# 模型合并
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert merge /root/model/Meta-Llama-3-8B-Instruct \
/root/llama3_hf_adapter\
/root/llama3_hf_merged合并完成后会提示

运行训练后的模型
streamlit run ~/Llama3-Tutorial/tools/internstudio_web_demo.py \
/root/llama3_hf_merged查看效果:

可以看到,因为训练的数据集太少,出现了过拟合现象,不管问它什么,都只能回复一句!又是一道门槛!
最后
书生浦语大模型实战营第二期开班了,除了免费教程,还提供免费的算力支持,扫码报名!
















 1532
1532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









