










论文请参考上篇博客
代码地址:github
任务:CBCT 运动伪影去除
运行
1、github 下载解压
2、源目录下创建两个文件夹
3、下载权重放到log,下载数据放到data内,xu'ya
4、运行
python train.py
python test.py5、结果
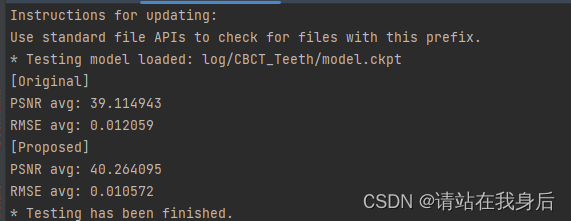
![]()
简单讲解
train 和model 其实都很简单
trian.py
首先是两个占位符,可以看到就一个输入一个输出
# Placeholders
input_ph = tf.placeholder(tf.float32, shape=[None, None, None, 1])
target_ph = tf.placeholder(tf.float32, shape=[None, None, None, 1])加载网络,网络内部一会再看
# Deblur with network
deblur_output = network(input_ph)连个损失,跟论文一致l1+vgg
# L1 loss
loss_l1 = 1e2 * tf.reduce_mean(abs(deblur_output - target_ph)) # L1 loss
# VGG loss
loss_vgg = tf.zeros(1, tf.float32)
target_resize = convert_tensor(target_ph)
vgg_t = vgg16.Vgg16()
vgg_t.build(target_resize)
target_feature = [vgg_t.conv3_3, vgg_t.conv4_3]
output_resize = convert_tensor(deblur_output)
vgg_o = vgg16.Vgg16()
vgg_o.build(output_resize)
output_feature = [vgg_o.conv3_3, vgg_o.conv4_3]
for f, f_ in zip(output_feature, target_feature):
loss_vgg += 5*1e-5 * tf.reduce_mean(tf.subtract(f, f_) ** 2, [1, 2, 3]) # Perceptual(vgg) loss
# Total loss & Optimizer
loss = loss_l1 + loss_vgg
opt = tf.train.AdamOptimizer(learning_rate=5*1e-5).minimize(loss, var_list=tf.trainable_variables())保存
ckpt = tf.train.get_checkpoint_state(checkpoint_dir=model_path)
if ckpt:
saver.restore(sess, ckpt.model_checkpoint_path)
print('* Training model loaded: ' + ckpt.model_checkpoint_path)
else:
print('* Training model does not exist or load failed.')
训练,并返回loss
while epoch < end_Epoch:
for train_index in range(nTrain):
random_index = random.randint(1, nTrain) - 1
input_image = train_file[random_index:random_index+1, :, :, :]
target_image = target_file[random_index:random_index+1, :, :, :]
loss_, l1_, vgg_, _ = sess.run([loss, loss_l1, loss_vgg, opt], feed_dict={input_ph: input_image, target_ph: target_image})
if not (train_index + 1) % (nTrain/10):
print("Epoch:[%3d/%d] Batch:[%5d/%5d] - Loss:[%4.4f] L1:[%4.4f] VGG:[%4.4f]"
% (epoch, end_Epoch, (train_index+1), nTrain, loss_, l1_, vgg_))
epoch += 1
saver.save(sess, "%s/model.ckpt" % model_path)
if epoch == end_Epoch:
breakmodel
看向内部
def network(input_img):
with tf.variable_scope('deblur'):
net = slim.conv2d(input_img, 64, [5, 5], activation_fn=None)
for layer_ in range(10):
net = AttBlock(net)
deblur_img = slim.conv2d(net, 1, [5, 5], activation_fn=None)
return deblur_img
网络:卷积+注意力块*10 +卷积
# AttBlock
def AttBlock(rgap_input):
temp = slim.conv2d(rgap_input, 64, [5, 5], activation_fn=None)
temp = tf.nn.relu(temp)
res = slim.conv2d(temp, 64, [5, 5], activation_fn=None)
res_gap = global_average_pooling(res)
rgap_output = rgap_input + res_gap
return rgap_output注意力块:卷积,激活,卷积,注意力池化,残差
# attention module
def global_average_pooling(GAP_input):
avg_pool = tf.reduce_mean(GAP_input, axis=[1, 2])
temp = tf.expand_dims(avg_pool, 1)
temp = tf.expand_dims(temp, 1)
channel_weight = temp
GAP_output = tf.multiply(GAP_input, channel_weight)
return GAP_output注意力池化:平均池化,加权
不好评价,总之,不好评价















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









