









论文:arxiv
代码:github
简介:
非配对图像到图像(I2I)翻译通常需要最大化跨不同域的源图像和翻译图像之间的互信息,这对于生成器保留源内容并防止其进行不必要的修改至关重要。自监督对比学习已经在I2I中得到成功的应用。通过约束来自相同位置的特征比来自不同位置的特征更接近,它隐含地确保了结果从源获取内容。然而,以往的工作使用随机位置的特征来施加约束,由于某些位置包含的源域信息较少,可能不合适。而且,特征本身并不能反映与他人的关系。本文通过有意选择有意义的锚点进行对比学习来解决这些问题。我们设计了一个查询选择注意力(QS-Attn)模块,它比较源域中的特征距离,给出每行具有概率分布的注意力矩阵。然后我们根据它们的显著性度量来选择查询,从分布中计算出来。将选取的数据作为对比损失的锚点。同时,采用简化的注意矩阵对两个域的特征进行路由,使源关系在综合中保持不变。
模型框架:
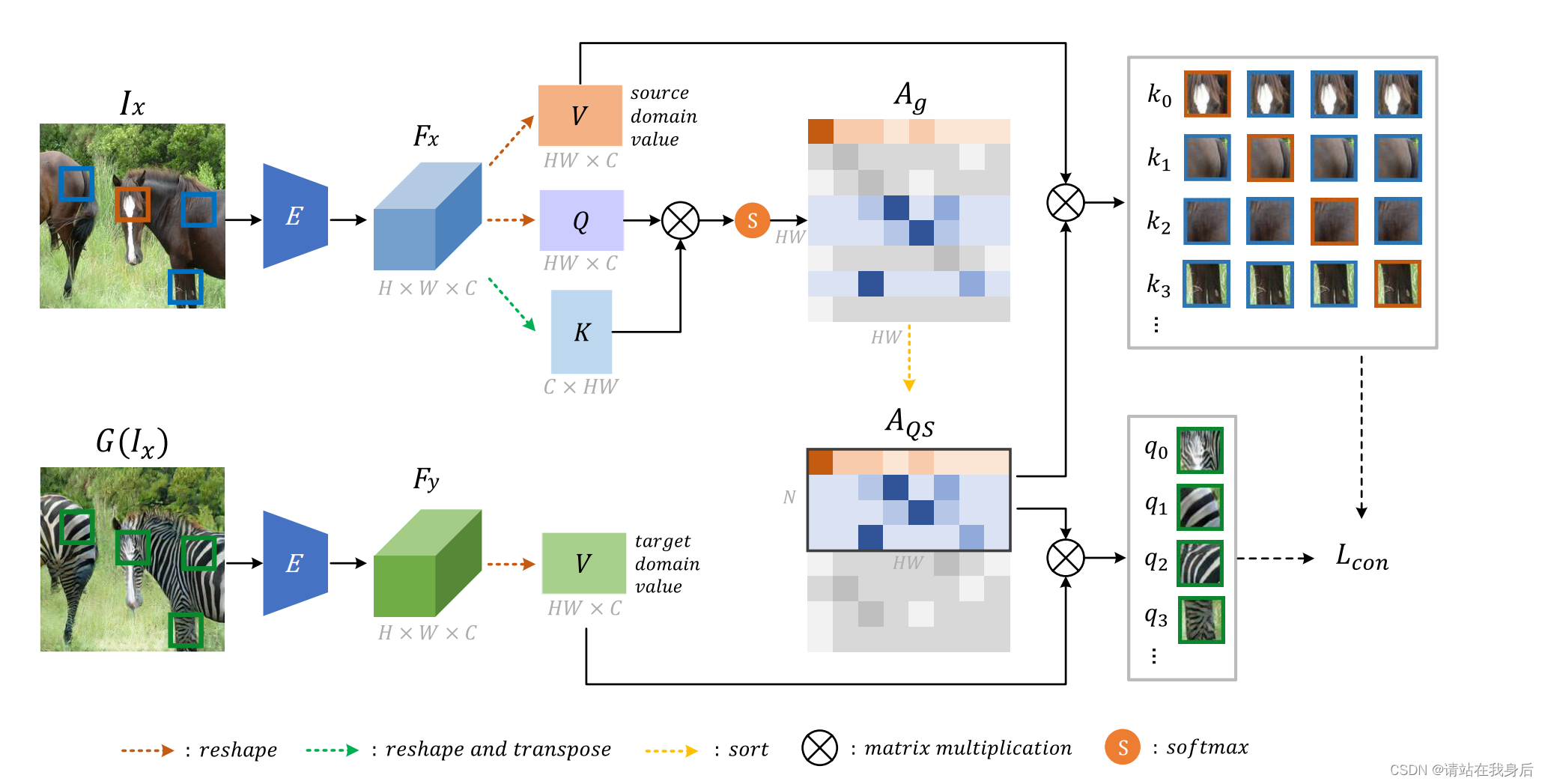
源域图像I_x由生成器G转换为目标域图像G(I_x)。编码器E从这两幅图像中提取特征,然后QS-Attn模块选择显著特征建立对比损失。使用一个判别器D来构造对抗损失。橙色、蓝色和绿色斑块分别表示正、负和锚, 利用注意力对每一行按其显著性度量进行排序得到A_g,利用A_QS同时路由源域和目标域的值特征, 并获得正、负、锚特征来构造对比损失。
代码
代码不细讲了,因为和dcl几乎一样
1、从github 上下载下来代码。
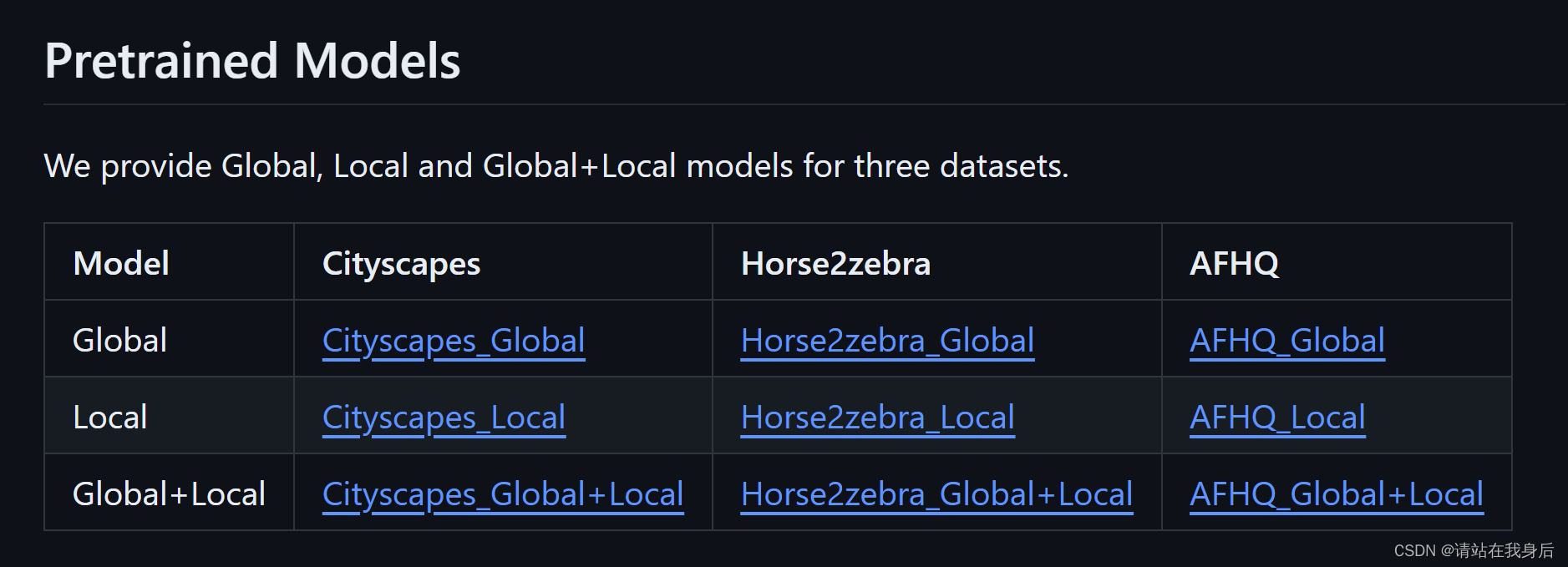
2、如果想直接尝试,可以下载预训练权重,有city街道的,马2斑马的
然后下载训练集
bash ./datasets/download_qsattn_dataset.sh horse2zebra3、如果想自行训练,别忘了重新调整dataset的创建,具体的可以看我dcl那个博客
4、训练和测试如下
python train.py \
--dataroot=datasets/horse2zebra \
--name=horse2zebra_global \
--QS_mode=global如果需要损失等参数的可视化,可以运行下行后打开http://localhost:8097:调用的visdom 的方法
python -m visdom.server如果是在服务器上,不需要展示,甚至展示会报错,可以ctrl+F找到所有的visdom, 全部注释掉,不会报错的。
代码的权重保存在
![]()
测试:name就是上面训练的时候自己加的name,我没遇到报错,很流畅。
python test.py \
--dataroot=datasets/horse2zebra \
--name=horse2zebra_qsattn_global \
--QS_mode=global引用
@inproceedings{hu2022qs,
title={QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation},
author={Hu, Xueqi and Zhou, Xinyue and Huang, Qiusheng and Shi, Zhengyi and Sun, Li and Li, Qingli},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={18291--18300},
year={2022}
}贴点实验图
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









