






1. LoRA最新前沿改进技术与应用(速看)
I. 结构性创新与算法优化
-
QLoRA与量化技术结合
QLoRA将量化技术与LoRA相结合,通过4比特量化基础模型并使用LoRA进行微调,大幅减少显存需求,使得在消费级GPU上也能微调大型模型。这使得更多开发者和研究者能够参与到模型定制中来。 -
AdaLoRA - 自适应秩调整
AdaLoRA提出了一种自适应调整低秩矩阵秩的方法,根据参数重要性动态分配参数预算。实验表明,与标准LoRA相比,AdaLoRA能够在相同参数量下获得更好的性能,特别是在低资源场景下。 -
MoE-LoRA - 专家混合低秩适配
MoE-LoRA结合了专家混合系统(MoE)和LoRA的优势,通过条件路由机制选择最适合当前输入的LoRA模块。这种方法特别适合多领域、多任务的场景,能够在不同任务间实现更好的知识隔离和共享。 -
LoRA-GA (Gradient Approximation)
LoRA-GA提出使用梯度近似方法,在极小的数据集上也能获得接近全量微调的效果。这种方法通过更精确地模拟完整梯度信息,弥补了传统LoRA在极限场景下的不足。
II. 优化架构与实现技术
- 分布式训练与混合精度优化
结合ZeRO++等分布式训练框架与Brain Float 16-bit等混合精度技术,现代LoRA实现大幅降低了训练成本和显存消耗。最新研究表明,这些优化使得LoRA训练速度比全量微调快10-100倍,同时保持相似性能。 - 高效推理架构 - SparseLoRA
SparseLoRA通过引入稀疏约束,进一步压缩LoRA参数,并优化推理路径,显著降低了模型部署的资源需求。这对资源受限设备尤为重要,使LoRA微调的模型能够在边缘设备上高效运行。 - Multi-Head Latent Attention (MLA)与LoRA结合
最新研究探索了DeepSeek提出的MLA架构与LoRA的结合,通过压缩Key-Value缓存并结合参数高效微调,实现了更经济高效的推理过程。 - TAMP: Token-Adaptive Layerwise Pruning
论文"TAMP: Token-Adaptive Layerwise Pruning in Multimodal Large Language Models"(https://alphaxiv.org/abs/2504.09897)提出了一种针对多模态模型的分层剪枝方法,与LoRA结合后能进一步提升参数效率。
III. 多领域应用与跨模态扩展
- Vision as LoRA (VoRA)
如前所述,VoRA(https://alphaxiv.org/abs/2503.20680)提出了一种将视觉能力直接通过LoRA注入到LLM中的创新方法,无需外部视觉编码器,大幅简化了多模态模型的架构。 - 联邦学习与隐私保护
FedIT和FFA-LoRA等方法将LoRA应用于联邦学习场景,实现了在保护数据隐私的同时进行模型个性化的目标。这些方法特别适合医疗、金融等敏感数据领域的应用。 - B-LoRA与艺术创作
针对图像生成领域,B-LoRA等变体通过引入基于块的低秩适配,更好地保留了生成模型的艺术风格和创作特性,同时实现个性化定制。在Stable Diffusion等模型上的应用尤为广泛。
IV. 最新解决方案与挑战
- \1. 灾难性遗忘问题的解决方案
O-LoRA和CoLoR等新方法通过引入正交约束和任务算术等技术,有效缓解了持续学习中的灾难性遗忘问题。这些方法使得模型能够在不断学习新知识的同时,保持原有能力。 - \2. HeterMoE: 异构硬件上的高效训练
论文HeterMoE: Efficient Training of Mixture-of-Experts Models on Heterogeneous GPUs探索了如何在异构硬件环境中优化LoRA等参数高效训练方法,为资源受限环境提供了新的解决方案。 - \3. 知识注入与可解释性
最新研究正探索如何将外部知识库与LoRA微调结合,使模型不仅能学习任务相关模式,还能获取结构化知识。这种方法提升了模型的可解释性和决策可靠性。
V. 社区趋势与最佳实践
- \1. 自动化参数选择工具
随着LoRA应用的普及,自动化参数选择工具如AutoLoRA、LoRA-Sweep等正被广泛采用,这些工具能根据任务特性和资源约束自动推荐最优LoRA配置。 - \2. 开源社区贡献与工具链
如ChatGLM-Tuning、LangGPT等开源项目提供了完整的LoRA训练、评估和部署流程,大幅降低了技术门槛,推动了LoRA在更广泛场景中的应用。 - \3. 混合微调策略
实践中,将LoRA与其他微调技术(如Prompt-tuning、Adapter)结合使用的混合策略显示出比单一方法更好的效果,特别是在复杂任务上。许多实践者推荐针对不同层使用不同的微调策略。
LoRA技术正在经历快速演进,从单一的参数高效微调方法发展为一套完整的模型适配框架。未来发展趋势包括:
- • 跨模态与多任务整合: 进一步探索LoRA在视觉、语音、多模态模型中的应用潜力
- • 动态与自适应机制: 发展能根据输入和任务动态调整的LoRA变体
- • 边缘部署优化: 针对资源受限设备进一步优化LoRA推理性能
- • 联邦学习与隐私计算: 深化LoRA在保护隐私前提下的个性化能力
2. 大模型微调 Lora 的不同形态
首先,LoRA 在资源使用上更为高效。它能显著节省显存,使得在有限的计算资源下也能训练 size 更大的模型。其次,LoRA 具有一定的正则化效果,类似于 dropout 或 mask。这种特性使得模型在学习下游任务时,能够减少遗忘现象, 关于这方面的详细分析,可以参考 LoRA Learns Less and Forgets Less。
例如,为什么 LoRA 的收敛速度相对全参数微调慢好多?LoRA 能否达到与全参数微调相媲美的效果?如何选择 LoRA 的 rank 值? 这些问题都值得深入探讨。


2.1 前置知识
在讨论各种方法之前, 有必要先介绍下线性里面的两个知识点, 因为跟后面提出的方法紧密相关.
-
• 矩阵的秩:大家知道, 矩阵在大多数情况下代表映射. 而矩阵的秩几何意义就是映射后的目标空间是几维的, 把它称为像空间(目标空间) ImA 的维度
-
• 举个例子 , 假设这里A 是一个的矩阵,A 对应的映射几何意义是 **”x 所在的 3 维空间” 到 “y 所在的 3 维空间” 的映射。假如矩阵, 大家有没有发现, 任何一个三维向量经过A 映射后, z 轴(也就是第三维度)的信息都丢了,直接地说所有的三维向量经过****映射后都 “压缩” 到 xy 轴张成的平面上. 任何一个 3 维向量, 经过上述的 A 映射后, 得到的虽然表面上也是三维向量, 但这些映射后的三维向量张成的空间是3 维向量空间中的一个 2 维线性子空间,也就是映射后的目标空间是 2 维的,**因此。现在,问大家一个问题, 矩阵的秩等于多少呢? 答案是这个矩阵的秩为 1 .
-
• 知道矩阵秩的几何意义后, 就好办了, 这里闲聊秩的两个性质
-
• 性质 1: 对于矩阵,,,.
从直观上是显然的,前者成立的原因在于, 从根本上将, 目标空间是维的, 而包含在其中的无论也不可能让自己的维度超过**. 对于后者, 因为原空间是维的, 于是把空间全体通过映射过去, 无论如何也不可能超过自己原来的维度**(毕竟,做的只是线性映射啊)。 -
• 性质 2: 假如矩阵能分解成两个 “瘦矩阵的乘积”, 既宽仅为的矩阵和高仅为的矩阵的乘积,, 则****的秩一定不会超过。
右面是例子是秩为 2 的情况。
对于rank(A)=1 的极端清况,可以写成列向量和行向量的乘积的形式,如下所示。在 的变换过程中, 分成以下两步进行
-
- • 第一步 对应 维向量 “压缩” 成 维向量
- • 第二步对应维向量**“扩张” 成维向量**
**若矩阵可以进行这样的瓶颈型分解了,则的秩显然不超过****, 只要一度被压缩到低的维,无论怎么扩张,也不可能使维度增加了,因为一定不超过** 维,也可以说,丢失的信息就找不回来了。
-
SVD 分解 (奇异值分解): 线性代数的世界里很多分解。 但 SVD 的魅力最大。原因有两个:第一,SVD 对矩阵的形状没什么要求,任何矩阵都可以分解;第二,它能帮提取出矩阵中最重要的部分,而恰恰很多场景都要分析重要性。
-
SVD 定义
-
给定大小为 的实数矩阵, 其中可以等于或不等于, 对A 进行 SVD 后得到的输出为。左式表示 SVD 会将大小为的实数矩阵分解为的正交矩阵、的对角矩阵以及的正交矩阵。由于正交矩阵的逆就是其转置矩阵, 因此和,其中两个单位矩阵的下标表示它们的大小分别为和。进一步地,和 可以表示为
进一步, 矩阵 A 可以写成各个奇异值及其对应向量的求和形式:
这样的分解能分解出重要性。 例如假设现在某个矩阵好大, 维度为 10000✖️10000, 本来要存 1000010000 的参数. 但经过分解后, 发现第一个奇异值和第二个奇异值, 已经占了总奇异值的 90%, 那现在只要存 , 也是就 4 个奇异向量和两个奇异值, 一共 410000+2 个参数, 就能恢复这个矩阵的 90%! 压缩比达到 2500! 这就是 SVD 分解的魅力。
-
SVD 几何意义
-
本质是变基 (变到 V 表示的正交基, 对应向量乘以 ), 再拉伸压缩 (对应向量乘以 ), 再旋转 (对应向量乘以 ), 详细的可以看 https://www.bilibili.com/video/BV15k4y1p72z/?spm_id_from=333.337.search-card.all.click&vd_source=85b8a3ae5654a8e5f740cb43ae25c959
2.2 LoRA
LoRA: Low-rank adaptation of large language models.

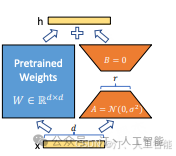
Lora 原理:
- • 通过在已经预训练的模型权重基础上添加两个低秩矩阵的乘积来进行微调。具体来说,权重矩阵 维维被分解为一个高瘦矩阵 维 维和一个矮胖矩阵 维 维的乘积,从而达到降低秩的目的(回想一下秩的性质,因为能这样分解, 因此最终 。
Lora 论文中埋下的伏笔 (都是后续工作的优化点):
- • 初始化方式:在原论文中,矩阵 使用随机高斯分布初始化,而矩阵 使用零初始化。这意味着训练一开始时, 。是否存在更好的初始化方法,可能可以加速训练或提高性能? 当然是肯定有的.
- • 缩放因子****的作用:按照进行缩放,其中是关于中的一个常数, 例如在 llama_factory 里, 假如你不指定, 那会把设置为的两倍。调节大致等同于调节学习率。因此,论文将设为他们尝试的第一个 ,并保持固定不变。这种缩放机制的引入有助于在调整超参数时减少过多的重新调节需求。
- • 旁路矩阵的应用范围: 在原论文中,LoRA 仅在注意力层引入了旁路矩阵,并且所有层的秩参数 都被统一设置为 1、4 或 8,没有根据不同层的特点进行区别设置。
Lora work好处:
1: Lora work 的原因:
Lora 效果能好是建立在以下的假设上, 在预训练阶段,模型需要处理多种复杂的任务和数据,因此其权重矩阵通常是高秩的,具有较大的表达能力,以适应各种不同的任务。然而,当模型被微调到某个具体的下游任务时,发现其权重矩阵在这个特定任务上的表现实际上是低秩的。也就是说,尽管模型在预训练阶段是高维的,但在特定任务上,只需要较少的自由度(低秩)就可以很好地完成任务。基于这一观察,LoRA 提出在保持预训练模型的高秩结构不变的情况下,通过添加一个低秩的调整矩阵来适应特定的下游任务。
2: 训练能省多少
- • 已模型的其中一个矩阵为例: 例如 Qwen2-72B, transformers block 全连接模块的第一个全连接矩阵维度为 819229568, 假如全参数微调, 单微调这个矩阵就涉及 242M 个参数, 假如用 Lora 微调并取 rank=8 呢? 涉及的参数量为 81928+29568*8=0.3M, 只有原来的 0.12%!
- • 已微调整个模型为例: 以微调整个模型为例,假设使用的是 fp16 精度,模型训练时显存的占用可以分为以下几部分 (参考 https://huggingface.co/docs/transformers/model_memory_anatomy#anatomy-of-models-memory
- • 模型权重: 2 字节 * 模型总参数量 + 4 字节 * 训练参数量(因为在内存中需要保存一个用于前向传播的 fp16 版本模型,但训练的参数会保留一个 fp32 的副本)。
- • 梯度: 4 字节 * 训练参数量(梯度始终以 fp32 格式存储)。
- • 优化器: 8 字节 * 训练参数量(优化器维护 2 个状态)。
- • 中间状态: 由很多因素决定,主要包括序列长度、隐藏层大小、批量大小等。
- • 临时缓存: 临时变量,如为前向和后向传递中的中间量提供临时缓冲,如某些函数占用的缓存, 它们会在计算完成后被释放。
在不考虑中间状态和临时缓存的情况下, 单卡全参数微调 Qwen2-72B 需要的显存大小是 18*72=1296GB,显然这是不可能实现的。即使使用 8 卡并开启 DeepSpeed Zero3(将权重、梯度和优化器都切分到 8 卡上),每张卡的显存需求仍然为 162 GB,也依然过高。
假设使用 LoRA 微调,假设 LoRA 训练参数量仅为原模型全参数量的 1%,则单卡所需的显存可以按以下方式计算:显存需求 =2× 模型总参数量 +(4+4+8)× 训练参数量 ×0.01=155G. 假如 8 卡并开启 Zero3,是能把 72B 模型跑起来的。
3: 推理时能省多少?
在推理过程中,LoRA 的低秩调整矩阵可以直接与原始模型的权重合并,因此不会带来额外的推理延迟(No Additional Inference Latency)。这意味着,在推理阶段,计算效率与原始模型基本相同。
4: 不同的高效微调方法
目前,LoRA 已成为主流的高效微调方法之一。与其他方法相比:
- • Adapter: 在层之间并行添加额外的结构,但这种额外结构无法与原始权重合并,导致推理时不仅需要更多内存,还会带来推理延迟。
- • Prefix tuning: 通过占用输入 token 来实现微调,结构不够优雅,可能影响输入处理。
- • LoRA: 训练稳定,效果与其他方法相当,但推理时不产生额外延迟,且不增加显存需求,因而是首选。
5: 高效微调与全参数微调怎么选
谨慎使用全参数微调,除非同时满足以下两个条件
- • 你的训练集很大,(通常需要成千上万)
- • 你对训练数据集质量非常有信心, 包括数据的一致性, 多样性.
如果无法同时满足这两个条件,全参数微调的效果可能不如 LoRA。这是因为大模型的拟合能力过强,数据量不足或质量不高时,模型很容易过拟合,反而降低效果。在微调过程中,数据集的构建至关重要。对于如何构建合适的微调数据集,推荐阅读这篇文章:How to Fine-Tune LLMs: PEFT Dataset Curation。
- • 现象 1: Lora 模型在训练过程中收敛速度较慢。例如,在实际业务场景中,通常需要训练到 10 个 epoch 左右,才在测试集上取得最高分,而全参数微调模型通常在 3-4 个 epoch 后就能达到最佳效果。此外,Lora 的拟合能力也较弱,模型对训练集的内容记忆不佳。
- • 现象 2: 在处理某些复杂任务时,我尝试将 Lora 的 rank 参数增大至 64 或 128,结果模型性能反而下降,甚至出现训练崩溃、梯度变成 nan 的情况。这与直觉相悖,因为理论上对于复杂任务,rank 越大意味着可调整的参数越多,模型的效果理应更好。
2.3 ADALoRA: 建模成 SVD 分解的形态,每次更新根据重要性得分来取哪些

[AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning]-(https://arxiv.org/pdf/2303.10512) -2023 年 3 月
- • 研究动机
原生 Lora 方法在每个 attention 层都引入了一个秩为 4 的矩阵,采用的是均分策略。然而,直觉告诉,模型中的某些矩阵比其他的更为重要,应该分配更多的参数来进行调整,而有些矩阵则相对不重要,不需要过多修改(回想 BERT 时代的经验,认为靠近输入层的权重主要学习语法和词法结构,微调时变化较小;而靠近输出层的权重主要涉及语义知识,需要根据下游任务进行较大的调整)。总而言之,Lora 这种 “均分参数” 的策略显然不是最优的。论文由此提出一个核心问题:
如何根据 transformer 不同层,不同模块的重要性自适应地分配参数预算,以提高微调的性能?
- • 方法论
- • 考虑到参数的重要性,自然会想到使用 SVD(奇异值分解)。SVD 的作用在于将矩阵分解为若干个不同重要性的分量之和。因此,一种直观的做法是:每次更新 A 和 B 时,先对所有的 A 和 B 矩阵进行 SVD 分解。如果某一层的矩阵的重要性较低,就只更新重要性高的部分,不更新低重要性的部分。然而,这种方法效率极低,因为每个训练 step 都需要进行 SVD 分解。对于大型模型而言,频繁对高维矩阵应用 SVD 会非常耗时。为了解决这个问题,论文提出不精确地计算 SVD,而是通过参数化 来模拟 SVD 的效果。
- • 具体做法是,使用对角矩阵 来表示奇异值,正交矩阵 和 表示 ∆ 的左右奇异向量。为了保证 和 的正交性,在训练过程中增加一个正则化惩罚项。这样,模型能够在训练过程中逐渐接近 SVD 分解的形式,避免了对 SVD 进行密集计算,同时提高了效率。
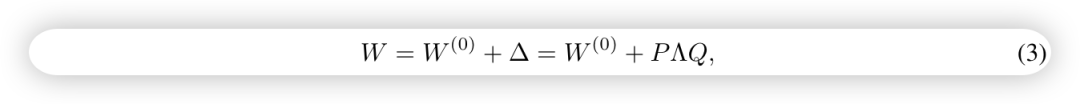
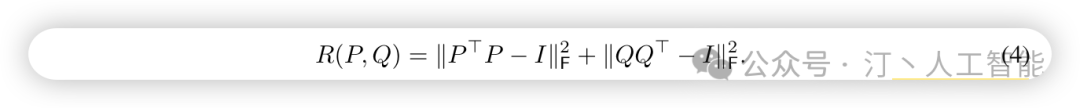
- • 在每次更新时,根据某些重要性得分来决定哪些 rank 需要更新,哪些需要保持不变。这些重要性得分可以通过奇异值的大小或 loss 的梯度贡献等方式来计算,具体计算方法可以参考相关论文。通过这种方式,能够更有针对性地调整参数。举个例子,假设当前的 rank 预算为 20,且模型中有 5 个矩阵引入了旁路矩阵 A 和 B 需要训练。初始阶段可以设置一个较大的预算,比如 budget rank = 30,每个旁路矩阵的 rank 设置为 6。然后,在每次 step 更新时,根据全局的重要性得分,选择前 20 个最重要的 rank 来进行更新,而不更新剩下的重要性较低的部分。为什么要这样做? 翻上文看 AdaLora的研究动机, 本质在于更新得越多未必越好, 有些重要性低的, 让它更新反而会导致反效果.
- • 实验结果
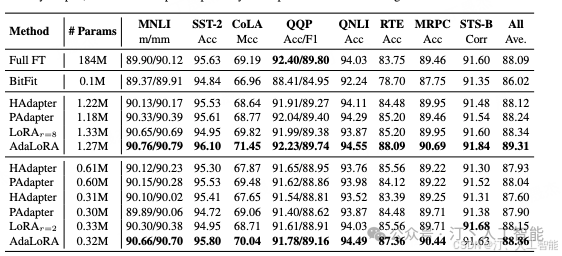
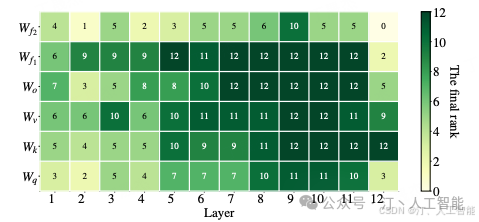
上面这一副图很有意思, 这图想表述的是各层各矩阵模块分配到的参数 budget 情况。模型的中上层,尤其是和 、、、和 这些模块,分配到的预算明显较多。
- • 思考:合乎常理的感觉,训练时有些模块就是不用怎么动, 有些模块就是要尽可能微调,让模型自己去判断。
2.4 rsLoRA: 调节γ, 让输入和输出保持一个量级

A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA–2023 年 11 月
- • 研究动机
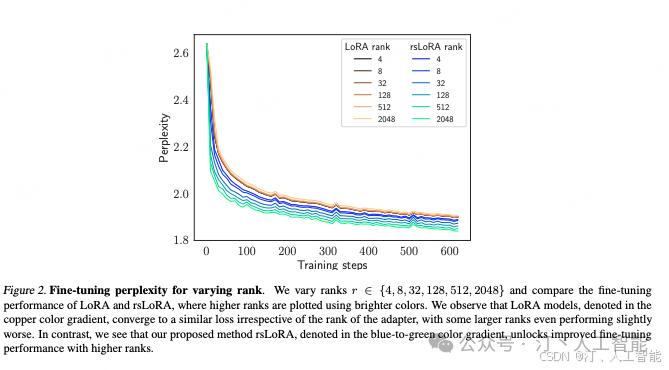
Lora 的原论文有做一个实验,实验的结果是 rank=64 在训练中没有带来显著提升,所以论文得出了非常低的 rank(如 4、8、16)就 “足够” 的结论。然而,这显然是反直觉的。按理来说,任务与预训练之间的差异越大,所需的 rank 应该越高,因为这意味着可调节的参数也应该越多。然而,实际结果却显示,随着 rank 增加,模型效果反而变差(对应上述提到的现象二)。
例如,如下图所示,LoRA 部分中 rank=512 和 rank=2048 时的橙色和黄色曲线较高。按照常理,rank 增加,引入了更多可微调的参数,应该使训练过程钟 perplexity 下降得更快,但结果却与预期相反。
进一步分析可以看出,作者试图引出的问题是:在使用 LoRA 适配器时,通过参数 (上文提到,是关于的一个常数)对矩阵乘积进行缩放会影响模型的学习轨迹。具体而言,**关键在于确保的选择在某种程度上是 “合理的”,即矩阵在整个学习过程中对于所有****都保持稳定。同时,**不应设置得过于激进,以免导致学习不稳定或速度过慢。
- • 方法论
- • 进一步,论文提出,怎么选择 ?一个好的 应该是 rank-stabilized(秩稳定) 的。论文先定义什么叫 rank-stabilized
以下两个条件成立时,适配器 是秩稳定的(rank-stabilized):
条件一:如果输入到 adpter 的数据是独立同分布(iid)的,例如输入的第 m 阶矩是 ,那么适配器输出的第 m 阶矩也是 。
条件二:如果损失函数对 adpter 输出的梯度是 ,那么损失函数对适配器输入的梯度在每个条目也是 。
Hold on, 这里的****是什么意思啊?
意思是:在秩增加的情况下,某个量级(例如矩的大小或梯度的大小)保持恒定(或变化非常缓慢,不依赖于 r)。这里的 “1” 表示与秩 r 无关的常数。具体举个例子,输入到 adpter 的每个条目的第 m 阶矩为,这意味着无论秩是多少,输入数据的第 m 阶矩在每个条目中都是一个常数级别的量。这表示输入的分布不会随着增大而显著变化。 这个概念为了保证 adapter 在不同的秩设置下, 都能保持稳定的学习和优化过程。
最终经过公式的推导 (推导详见论文的 Appendix A),得到定理
考虑形式为 的 LoRA 适配器,其中初始化时满足B=0_{d_1\times r} ,A 的各个元素是独立同分布的,均值为 0,方差为,且不依赖于。当且仅当时,所有适配器都是秩稳定的。特别地,上述结论在学习轨迹的任何点上都成立,且如果,那么对于足够大的 ,学习过程将是不稳定或坍塌的。
在这个定理中, 表示需要按照的比例缩放。这意味着当秩增大时,应该被设定为的形式(如,其中是常数)。这种缩放确保了 LoRA 适配器在整个学习过程中保持稳定,防止在 很大时出现学习不稳定或梯度崩塌的情况。
- • 实验结果
如下图所示,在 rsLoRA 中,随着 rank 的增加,获得的 Perplexity 越低,这符合预期。
再看下面右图,在 LoRA 中,随着 rank 增加,gradient norm 变得非常低,出现了一定程度的梯度崩溃(gradient collapse,指梯度过小了,更新不到位)。相比之下,rsLoRA 在很大程度上抑制了这种现象,即使在 rank=2048 时,gradient norm 仍能保持相对较高。
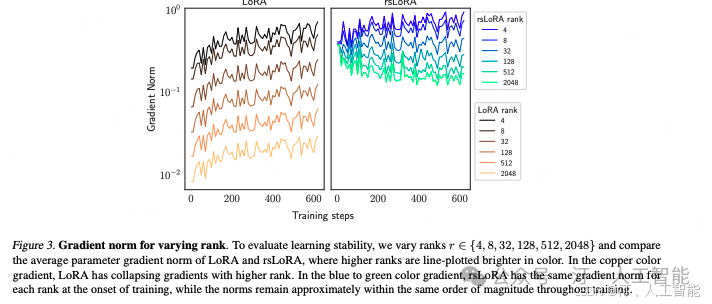
- • 思考:这种训练的稳定性让我联想到 Layer Normalization 和 attention 机制中的归一化。稳定性对于模型训练至关重要,因为它能让模型在每一步都看到相对一致的分布输入。如果每一步的输入分布差异过大,模型容易出现学习不稳定甚至崩溃的现象。而保持输入的稳定性,能使模型更容易学习。
2.5 PiSSA: 用奇异值大的部分进行初始化

PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
2024 年 04 月 12 日
- • 研究动机
原生 Lora 收敛得太慢了, Why? (对应上文的现象 1)
根据方程 Lora 的公式 , A 和 B 的梯度分别 和
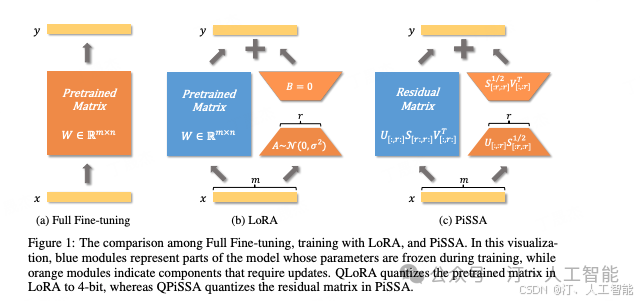

仔细看这个公式,在训练的初始阶段,梯度的大小主要由 A 和 B 的值决定。由于在 LoRA 中,A 和 B 是通过高斯噪声和零初始化的,因此初始梯度可能非常小,导致初始梯度可能非常小,进而使微调过程的收敛速度变慢。这种现象在实验中得到了验证,观察到 LoRA 在训练的初期往往在初始点附近徘徊,浪费大量时间。如下图所示,LoRA 在相同的训练步数下,前期收敛速度明显较慢,最终未能达到一个局部最优点。
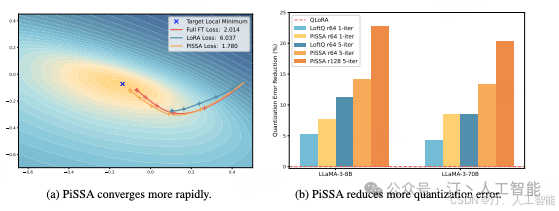
- • 方法论
- • 论文提出的方式很简单,对原始矩阵进行 SVD 分解, 拆开成两部分: 主奇异值部分和残差奇异值部分, fine tuning 主奇异值部分, frozen 残差奇异值. 具体分解如下,其中 由奇异值小的那部分组成, 和 ,也就是 ,要训练的那部分由奇异值大的部分组成
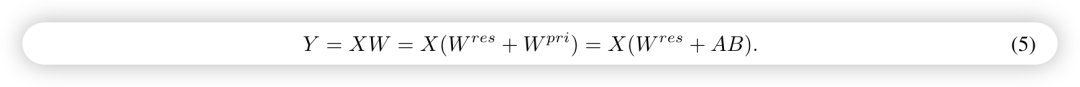
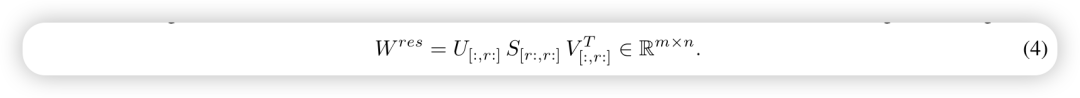
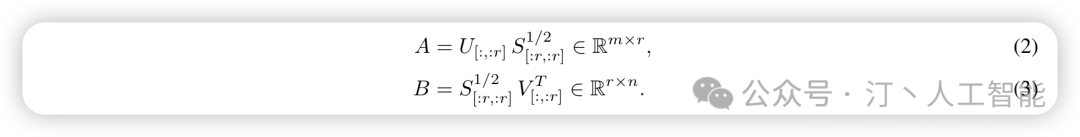
- • 论文解释了这种分解方法之所以有效的原因在于:主奇异值的元素远大于残差奇异值的元素,因此可训练的适配器 包含了原始权重矩阵 中最重要的方向。在理想情况下,训练 可以在使用较少参数的前提下,模拟微调整个模型的效果。通过直接微调模型中最关键的部分,PiSSA 能够实现更快、更好的收敛。相比之下,LoRA 在初始化适配器 B 和 A 时,使用的是高斯噪声和零值,同时保持原始权重矩阵 W 冻结不变。因此,在微调的早期阶段,梯度要么非常小,要么呈随机分布,导致许多梯度下降步骤被浪费。此外,不良的初始化可能会使模型陷入次优的局部最小值,影响其泛化能力。
- • 实验结果
- • 思考:
- • 这里有点令人疑惑。用主奇异值来初始化 和 确实可以加速收敛,但从效果上看,按照论文的说法,微调其实主要集中在调整奇异值较大的主成分。然而,这与 LoRA 原始论文的观点存在一定矛盾。在 LoRA 论文的第 7.3 节中提到, 主要是放大了 中未被强调的方向,也就是说 Lora 放大了下游任务中重要,但在预训练中未被强调的特征部分(也就是奇异值小的部分),这与 PiSSA 的观点是矛盾的。
- • 我的个人思考是,如果任务较为通用,那么可能确实需要调整模型中奇异值较大的部分;但如果任务与预训练的差异较大,那么仅调整奇异值大的主成分未必能够得到最佳效果,可能更需要关注那些在预训练中未被强调但在新任务中重要的特征。
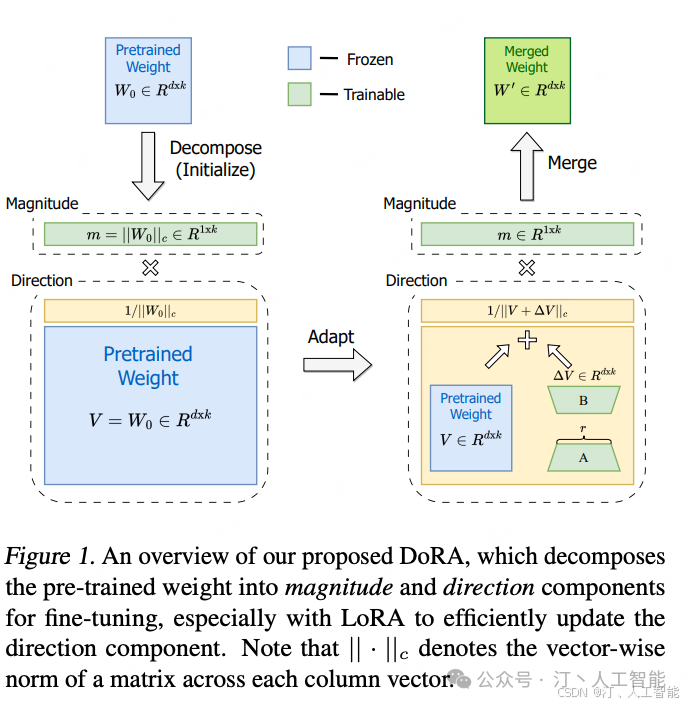
2.6 DORA: 把权重分解为幅值和方向两个模块进行独立微调

DoRA: Weight-Decomposed Low-Rank Adaptation–2024 年 2 月
-
• 研究动机
-
• 为了弥补这一差距,论文首先引入了一种新颖的
权重分解分析方法
,以研究全参数微调和 Lora 微调之间的差异。基于这些发现,论文提出了一种名为 Weight-Decomposed Low-Rank Adaptation(DoRA)的新方法。
DoRA 通过将预训练权重分解为大小(magnitude)和方向(direction)两个组成部分进行微调,特别是利用 LoRA 有效地更新方向部分
,以最小化可训练参数的数量。通过这种方法,DoRA 旨在提高 LoRA 的学习容量和训练稳定性。
-
• 方法论
-
• 通过将权重矩阵分解为幅度和方向两个独立的部分,揭示了 LoRA 与全参数微调(FT)在学习模式上的内在差异。具体的分析方法是:通过检查 LoRA 和 FT 相对于预训练权重在幅度和方向上的更新,深入揭示它们在学习行为上的根本区别。
具体的,矩阵 的权重分解可表述为
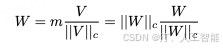
其中, 是幅度向量,是方向矩阵,| 是矩阵按列的向量范数。这样的分解确保了的每一列都是单位向量,并且相应的中的标量定义了每个向量的幅度。
基于这个分解, 分析就可以做了。具体来讲, 对完全微调后的权重以及合并 LoRA 后的权重进行上述的分解,再与原来的权重进行比较。例如,和之间的幅度和方向变化可以定义如下:
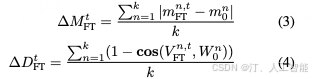
其中, 和分别表示在训练步骤 t 时,和之间的幅值差异和方向差异,是余弦相似度函数。和M^n_0 是各自在其幅度向量中的第个标量,而和W^n_0 则是和中的第列。和之间的幅度和方向差异同样按照上图公式 (3) 和公式 (4) 进行计算。论文从 FT 和 LoRA 的不同训练步骤中选择了四个检查点进行分析,包括三个中间步骤和最终的检查点,并在这些检查点上进行权重分解分析,以确定在不同层次上和 的变化。如下图所示
可以明显看出,LoRA 在所有中间步骤中表现出一致的正斜率趋势,表明方向和幅度的变化之间存在比例关系。相比之下,FT 显示出更为多样化的学习模式,具有相对负斜率。这种 FT 和 LoRA 之间的区别可能反映了它们各自的学习能力。尽管 LoRA 倾向于成比例地增加或减少幅度和方向更新,但它缺乏对更细微调整的能力。具体而言,LoRA 在执行伴随幅度显著变化的微小方向调整或相反情况下的表现不佳,而这种能力更是 FT 方法的特点。
论文怀疑,LoRA 的这种局限性可能源于同时学习幅度和方向适应性的挑战,这对于 LoRA 来说可能过于复杂, 引出了论文的方法论。
- • 方法论
- • 根据作者对权重分解分析的见解,论文进一步引入了权重分解的低秩适应方法(DoRA)。DoRA 首先将预训练的权重分解为其幅度和方向分量,并对这两个分量进行微调。由于方向分量在参数数量上较大,论文进一步通过 LoRA 对其进行分解,以实现高效微调。
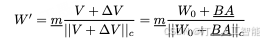
- • 作者的直觉有两个方面。
- • 首先,限制 LoRA 专注于方向调整,同时允许幅度分量可调,相较于 LoRA 在原方法中需要同时学习幅度和方向的调整,简化了任务。
- • 其次,通过权重分解使得方向更新的过程更加稳定。
- • 实验结果
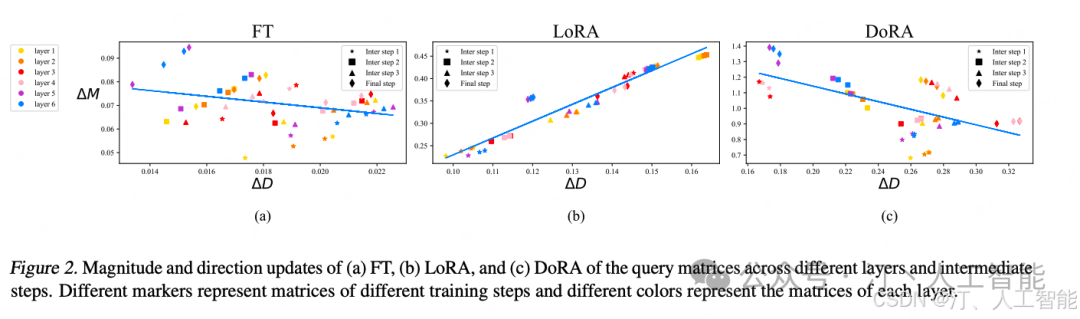
上图 © 中展示了在与 FT 和 LoRA 相同的设置下,合并后的 DoRA 权重与 之间的幅度和方向差异。从 DoRA 和 FT 的 回归线上,DoRA 和 FT 表现出相同的负斜率。论文推测,FT 倾向于负斜率是因为预训练权重已经具备了适合多种下游任务的大量知识。因此,在具有足够的学习能力时,仅通过更大幅度或方向的改变就足以进行下游适应。
- • 论文还计算了 FT、LoRA 和 DoRA 的 和 之间的相关性,发现 FT 和 DoRA 的相关性值分别为 - 0.62 和 - 0.31,均为负相关。而 LoRA 则显示为正相关,相关性值为 0.83。Anyway,DoRA 展示了仅通过较小的幅度变化或相反的情况下进行显著方向调整的能力,同时其学习模式更接近 FT,表明其相较于 LoRA 具有更强的学习能力。
- • 思考: 感觉合乎常理, 找到一种更 match 问题特性的建模方式,这样模型不仅更容易学习,还能提高学习效果。
实验
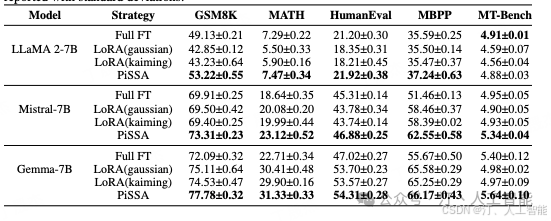
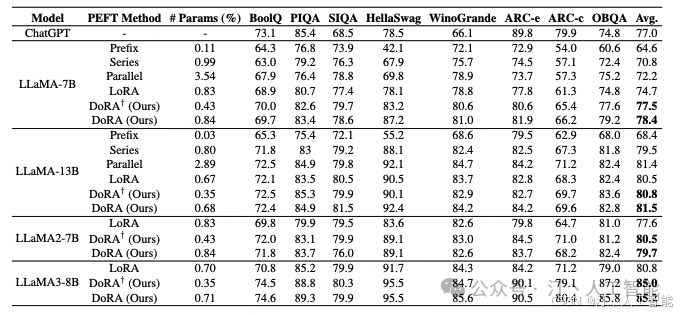
业务数据通常与 benchmark 数据不同,往往是预训练模型未曾见过的,这有时会激活新的模式(pattern)。在此次实验中,对比了 LoRA、rsLoRA 和 Dora 在三个具体下游业务任务中的表现。实验参数如下:
epoch=4, learning_rate = 4e-4, learn_scheduler=cosine, rank=8 或 32,base_model=Qwen2-72B,训练结束后取 checkpoint 在测试集上进行评估
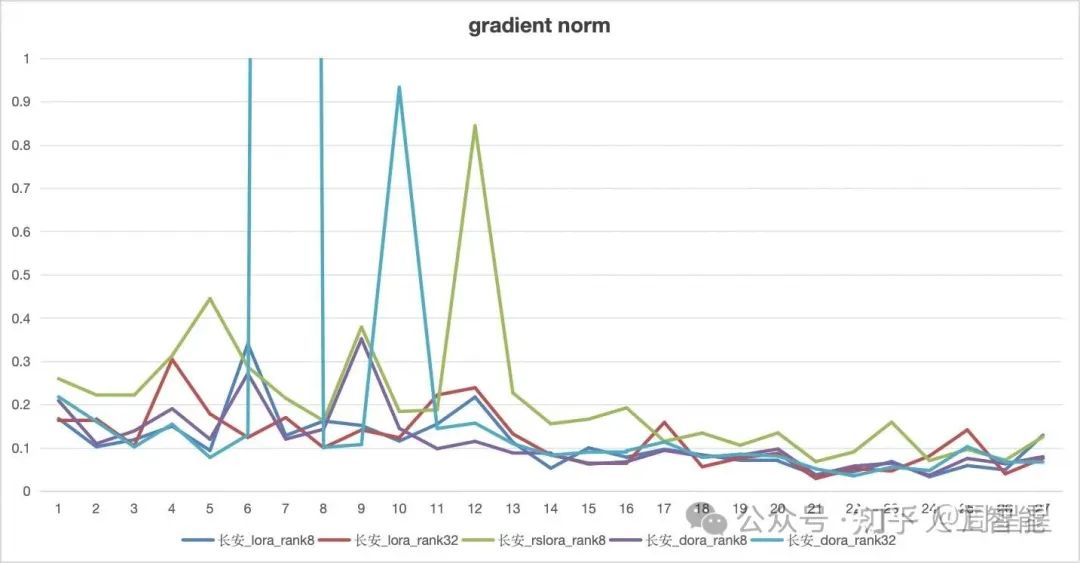
值得注意的是,rsLoRA 在 rank=32 的情况下训练失败,具体表现为 gradient norm 过大,train_loss 居高不下,因此没有将该结果列出。
首先,来看训练过程中的 gradient norm。可以明显看到 rsLoRA(rank=8)的 gradient norm 始终较大,表明每个 step 的更新幅度较大,这与原论文中的结论一致。
然后再对比下 train_loss、 eval_loss、下游任务测试集的表现
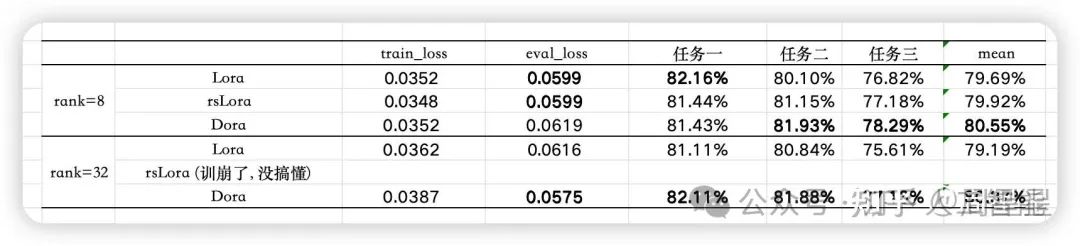
- • 观察 1: 对比实验 1 和实验 4,Lora(rank=8) 的效果比 Lora(rank=32) 差,这与现象二一致,证明单纯增大 rank 对 Lora 的性能提升作用有限,甚至反作用。
- • 观察 2: 对比实验 1 和实验 2,rsLoRA(rank=8) 的 train_loss 低于 Lora(rank=8),但 eval_loss 和任务指标差异不大。同时,rsLoRA(rank=32) 在训练中失效(训崩)。这可能表明,虽然 rsLoRA 能加速模型的学习,但由于没有优化好 Lora 的初始化,整体效果提升不显著。这也暗示了良好的初始化对 Lora 的重要性??(有没有高人指点)
- • 观察 3: Dora(rank=32) 的 train_loss 虽然不是最低的,但 eval_loss 是最低的,表现良好。无论 rank=8 还是 rank=32,Dora 的表现都优于其他方法。
最佳实践建议: 使用 Dora,rank 不用调太大(例如 8 、 16 、 32 都试试),学习率设置高一些,epoch 维持在 4-5 个左右,并使用 cosine learn scheduler。
- • 总结
文章介绍了多个基于 LoRA 的改进方法,如 AdaLoRA、rsLoRA、PiSSA、DoRA 等,分别通过优化训练参数的分配、调节缩放因子、改进初始化等方式提高微调效果。实验结果表明,DoRA 表现最佳,提供了模型训练中的最佳实践建议。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 138
138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









