







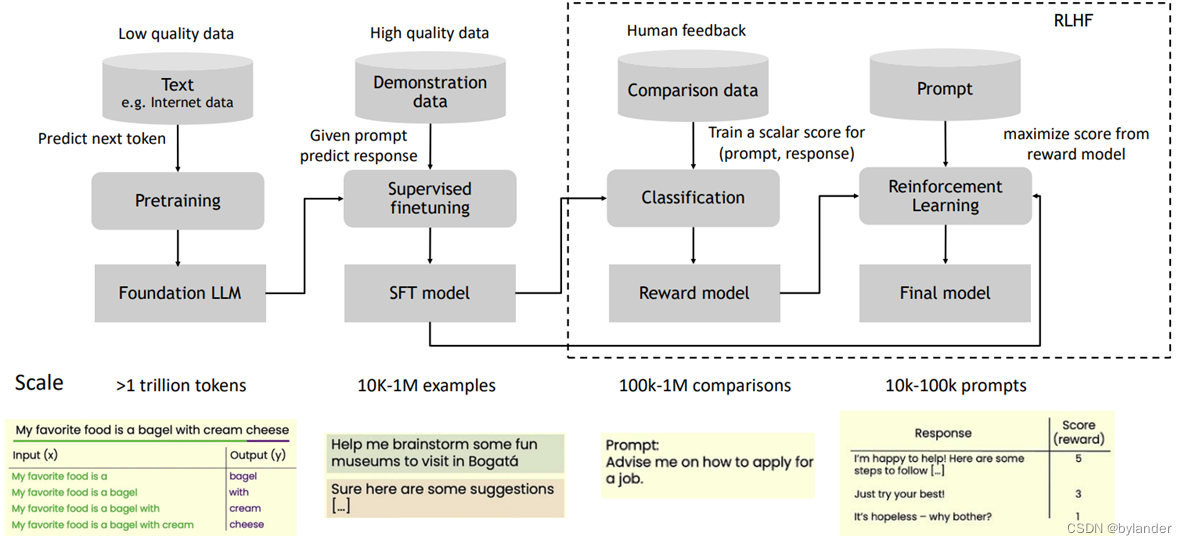
这张图来自Andrew Ng(即吴恩达),描述了训练大模型的各个阶段。预训练阶段就是预测下一个token的阶段,对数据质量要求不高,但是数据量大。第二个阶段,SFT(supervised finetuning),就是有监督的微调,对数据有高质量要求。接下来RLHF阶段,包括奖励模型训练阶段和强化学习两个阶段,完成最后的模型。图中标出了各个阶段的数据样式和数据量需求,非常直观。
有种假说,大模型的知识能力来自预训练阶段,微调阶段注入不了知识,SFT阶段只是加强指令跟随的能力,最后的RLHF是用来让大模型对齐人类的价值观。也有说,微调阶段数据足够多,也可以注入知识。
做一个不十分准确的对比,对比一个人的学习过程,预训练有点像学校学习,从小学一直到本科、硕士、博士等,SFT有点像进入单位的短期实习,RLHF有点像单位的规章制度学习,告诉你什么可以做什么不能说,要尊敬领导不要反驳领导等等。
微调,英文是Fine-tuning,感觉应该叫“优调”更合适。
微调定义:利用已经预训练的模型结构或部分结构,以及其权重,与新增的网络部分一起训练。
Fine-tuning这个说法,来自BERT那篇论文(BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,2018年)。从头训练大规模的神经网络效率低、速度慢,基于已有预训练模型,在最优点的附近开始寻优,收敛速度和训练效果会比从零开始要好的多。BERT这篇论文,论述了两种预训练语言模型方式,就是下图(图片来自网络)示意的两种方式。
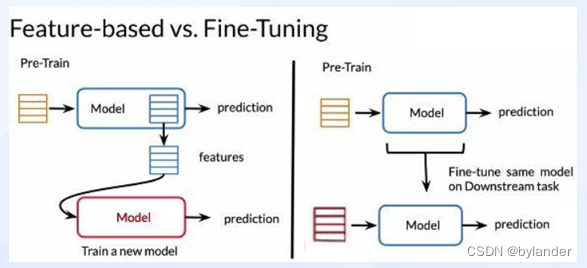
Feature-based方式:利用预训练好的语言模型的结果,也就是得到预训练好的词向量,将其作为额外的特征融入到下游任务中,参与下游任务的训练,典型的代表就是ELMo。基于特征的预训练,只需要拿到预训练模型的词向量即可,预训练模型的参数不参与下游任务的梯度更新。
Fine-tuning方式:利用预训练好的语言模型,在此基础上加入少量的 task-specific parameters ,例如对于分类问题,就可以在语言模型的基础上加一层全连接层或直接Softmax进行分类,然后在新的训练语料上进行微调。利用预训练语言模型在下游任务微调,模型的参数不是固定的,它仍然是可训练的参数。
网上有一段总结,非常简明扼要,整理并补充如下:
■ 语言模型微调(finetuning)指的是在预训练的基础模型上进行进一步训练。常见的微调技术包括:
√ 继续预训练(continued pretraining):就是再增加一些数据,如领域数据,继续预训练,让模型更好的学习领域知识
√ 指令微调(instruction tuning)
√ 监督微调( SFT)
√ 人工反馈强化学习(RLHF)
■ 语言模型微调主要有两个目标:
√ 知识注入:向模型注入新的知识来解决新的问题
√ 对齐(alignment):调整模型输出格式、风格等,避免输出错误信息
■ 大规模指令微调可以通过在大规模数据集上进行指令微调来实现知识注入;如Google的FLAN模型在1500万训练例上进行指令微调。
■ 对齐微调不需要大量数据,只需要少量高质量样本。如Meta的LIMA研究只需要少量数据就可以学会模仿GPT-3的输出。
■ 近期研究发现,语言模型大部分知识来自预训练,对齐微调只是学习输出格式。因此不能通过简单的模仿微调就获得类似ChatGPT的强大语言能力。
■ 当前研究正在探讨预训练和微调的界限,以及不同的数据集和方法对语言模型微调的影响。选择合适的方法对知识注入和对齐微调非常重要。
基于参数更新范围,微调技术又可以分为全量微调和部分微调。
SFT这种方式,需要全量调整模型参数,比较贵。所以发展出参数高效微调技术,就是PEFT (Parameter-Efficient Fine-Tuning),通过仅训练一小部分参数优化下游任务性能,这些参数可能是现有模型参数的子集或一组新添加的参数,就可以接近甚至超过全量微调的效果,具体技术分类大约包括:
■ Adapter methods:Adapter、AdapterFusion、AdapterDrop
■ Reparameterization:LoRA,AdaLoRA,QLoRA
■ Prompt modifications:Prefix-tuning,Prompt-Tuning,P-Tuning


















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











