







 文章探讨了ChatGPT在智能对话中的事实错误问题,将其称为“幻觉”,并分析了这类错误的成因,包括内部和外部幻觉。对话系统中的“幻觉”现象在开放域对话和知识对话中尤为突出,可能导致不一致性和事实不准确性。文章介绍了基于统计、模型和人工评估幻觉的不同方法,并提出了数据和模型层面的解决方案,如数据去噪、知识增强以及控制生成回复的偏好。
文章探讨了ChatGPT在智能对话中的事实错误问题,将其称为“幻觉”,并分析了这类错误的成因,包括内部和外部幻觉。对话系统中的“幻觉”现象在开放域对话和知识对话中尤为突出,可能导致不一致性和事实不准确性。文章介绍了基于统计、模型和人工评估幻觉的不同方法,并提出了数据和模型层面的解决方案,如数据去噪、知识增强以及控制生成回复的偏好。

©PaperWeekly 原创 · 作者 | 愁云

引言
随着 ChatGPT 的横空出世,智能对话大模型俨然已成为 AI 发展的焦点,更是在整个自然语言处理 (NLP) 领域掀起了一阵海啸。自去年席卷全球以来便引起各行各业空前的热度,数亿用户纷纷惊叹于 ChatGPT 的强大功能,思考其背后关键技术革新,也关注当前 ChatGPT 仍存在哪些缺陷,除了巨量数据资源的耗费需求,无法与时俱进关联最新信息等之外,一个引人瞩目的问题就是 ChatGPT 交互中仍会生成不少的事实性错误,对一些老幼皆知的简单问题也会一本正经的胡说八道,如下图所示:
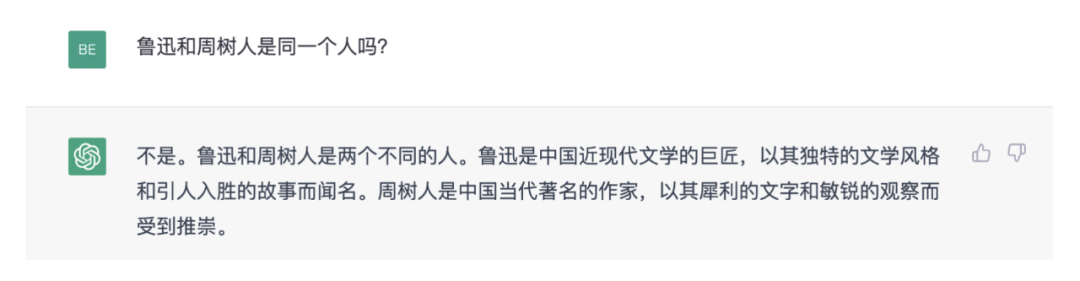
▲ Figure 1: ChatGPT 事实错误示例
这种事实性错误的存在对产品的广泛落地不可谓不致命,假设应用于医学,金融等非闲聊式场景,这些潜在风险就可能会造成经济损失或威胁生命安全,因此消除大模型中的事实错误成为了工业界和学术界的共同需求。
首先明确一则术语,在 NLP 论文中,这种事实性错误一般统称为“幻觉” (Hallucination),顾名思义,该术语最早用于图像合成等领域,直到后来描述诸如图像检测时检测到虚假或错误目标等现象,才沿用至自然语言生成 (NLG) 任务,指模型生成自然流畅,语法正确但实际上毫无意义且包含虚假信息即事实错误的文本,以假乱真,就像人产生的幻觉一样。
本文主要参考港科大的综述文章 [1],全部采用模型“幻觉”来指代前文所述的事实性错误,先简述下 NLG 生成“幻觉”文本的成因,接着详细介绍对话任务中的“幻觉”现象,针对对话任务的“幻觉”评估方法和未来研究方向等。

自然语言生成的“幻觉”成因
此前已有相关工作将自然文本生成中的幻觉问题分为内部幻觉 (intrinsic hallucination) 和外部幻觉 (extrinsic hallucination) 两大类。所谓内部幻觉,是指生成的文本与给定源文本出现不忠实 (unfaithfulness) 或不一致 (inconsistency) 的现象,这种问题常见于文本摘要任务中,生成的摘要与原文不一致。
另一种外部幻觉,则是指生成内容在源文本中并未提及,我们虽然不能找出相关证据,但也不能断言这就是错误的,这就涉及到语言模型本身的事实性知识 (factual knowledge) 或世界知识 (real-world knowledge)。下面对这些幻觉的成因进行分析。
虽然两类幻觉表现上有着明显区别,但成因却较为类似,根据以下因果图即可简单分析:

▲ Figure 2: 文本生成的幻觉来源因果分析
生成的文本 𝑌 由源文本 𝑋 和语言模型里的先验知识 𝐾 共同决定,由于一般认为给定的源文本都是事实正确的 ground-truth,所以出现的幻觉一般都会归结于语言模型本身包含了错误事实。
语言模型中的先验知识都来自于训练语料,用于训练语言模型的大数据语料库在收集时难免会包含一些错误的信息,这些错误知识都会被学习,存储在模型参数中,相关研究表明模型生成文本时会优先考虑自身参数化的知识,所以更倾向生成幻觉内容,这也是自然语言生成任务中大部分幻觉的来源,本文后续讨论的幻觉默认基于这个原因。
另一方面,模型训练和推理时的差异,也是导致推理时更容易生成幻觉的原因之一。训练中通常用最大似然估计的做法训练解码器,并且是以 ground-truth
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2771
2771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









