







 本文介绍了STAR Loss,一种用于解决人脸关键点检测中语义歧义问题的损失函数。STAR Loss通过自适应各向异性方向损失减少歧义影响,提高了面部特征点检测的性能,实现在多个数据集上的SOTA结果。方法通过PCA分析预测分布,以第一主成分方向上的误差为主,结合不同距离函数和约束策略,有效降低了标注不一致带来的影响。
本文介绍了STAR Loss,一种用于解决人脸关键点检测中语义歧义问题的损失函数。STAR Loss通过自适应各向异性方向损失减少歧义影响,提高了面部特征点检测的性能,实现在多个数据集上的SOTA结果。方法通过PCA分析预测分布,以第一主成分方向上的误差为主,结合不同距离函数和约束策略,有效降低了标注不一致带来的影响。


论文链接:
https://arxiv.org/pdf/2306.02763.pdf
代码链接:
https: //github.com/ZhenglinZhou/STAR
要解决的问题:人脸关键点检测标注中存在语义歧义问题。语义歧义是指不同的标注者对同一个面部特征点的位置有不同的理解,导致标注结果不一致,影响模型的收敛和准确性。

解决方案:提出一种自适应各向异性方向损失(STAR loss,Self-adapTive Ambiguity Reduction loss),利用预测分布的各向异性程度来表示语义歧义。STAR loss 能够自适应地减小语义歧义的影响,提高面部特征点检测的性能。
效果:在三个人脸关键点数据集上超越了现有方法,实现 SOTA。
相似工作:存在几项工作解决面部关键点检测中的语义歧义问题。SBR 使用相邻帧之间光流的一致性作为监督,但对照明和遮挡敏感。LAB 使用面部边界线作为结构约束,这在实践中可行但计算开销大。此外,SA 提出潜在变量优化策略来找到语义一致的注释,并在训练阶段减轻随机噪声的影响。
然而,复杂的训练策略限制了其应用。与本文工作最相关的是 ADNet,它提出了两个关键模块,即各向异性方向损失(ADL)和各向异性注意力模块(AAM),以处理模棱两可的注释问题。其中,ADL 在面部边界上的关键点的法向施加更多约束,但方向和约束权重是手工设计的,这种粗糙的设计降低了其性能。
前言
简要介绍当前广泛使用的回归方法的流程。
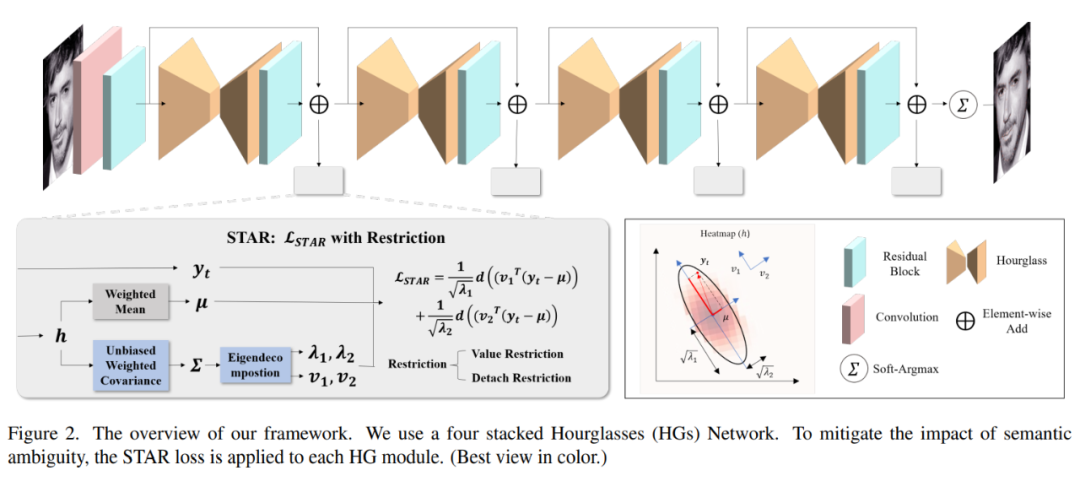
如图 2 顶部所示,回归方法的基本模型由四个 Hourglass Networks(HGs)堆叠而成。每个 HG 为 N 个关键点生成 N 个热力图,其中 N 是预定义关键点的数量。归一化后的热力图可以看作是预测关键点位置的概率分布。预测的坐标从热力图中通过 soft-Argmax 解码。形式上,给定一个离散概率分布 ,将值 定义为关键点定位在 的概率。期望坐标 μ 通过 soft-Argmax 解码:
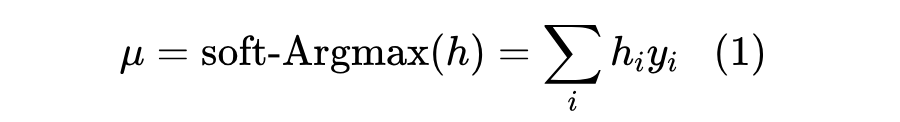
基于这些预测坐标,可以使用回归损失来学习模型的参数。回归损失可以看作是预测坐标 μ 和手动注释 之间的距离 。l1 距离、l2 距离、smooth-l1 距离和 Wing 距离等都是常用的距离度量。所以,回归损失可以公式化为:
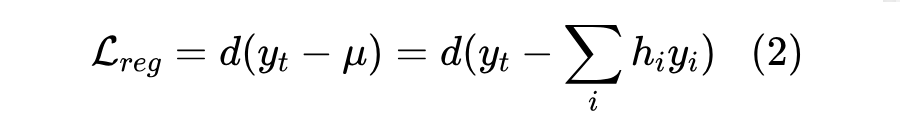
手动注释遭受语义歧义问题。如图 2 灰色框所示,问题的关键在于回归损失。

方法
语义歧义问题极大地降低了检测性能。为处理这个问题,设计了一种新的自适应歧义减少方法 STAR 损失,它受预测分布的影响。具体来说,当预测分布各向异性时,STAR 损失倾向于变小。
为表示预测分布的形状,首先引入了一种自定
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2688
2688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









