







©作者 | 机器之心编辑部
来源 | 机器之心
最近,来自澳大利亚蒙纳士大学、蚂蚁集团、IBM 研究院等机构的研究人员探索了模型重编程 (model reprogramming) 在大语言模型 (LLMs) 上应用,并提出了一个全新的视角:高效重编程大语言模型进行通用时序预测——其提出的 Time-LLM 框架无需修改语言模型即可实现高精度时序预测,在多个数据集和预测任务中超越了传统的时序模型,让 LLMs 在处理跨模态的时间序列数据时展现出色,就像大象起舞一般!

近期,受到大语言模型在通用智能领域的启发,「大模型 + 时序 / 时空数据」这个新方向迸发出了许多相关进展。当前的 LLMs 有潜力彻底改变时序 / 时空数据挖掘方式,从而促进城市、能源、交通、遥感等典型复杂系统的决策高效制定,并朝着更普遍的时序 / 时空分析智能形式迈进。
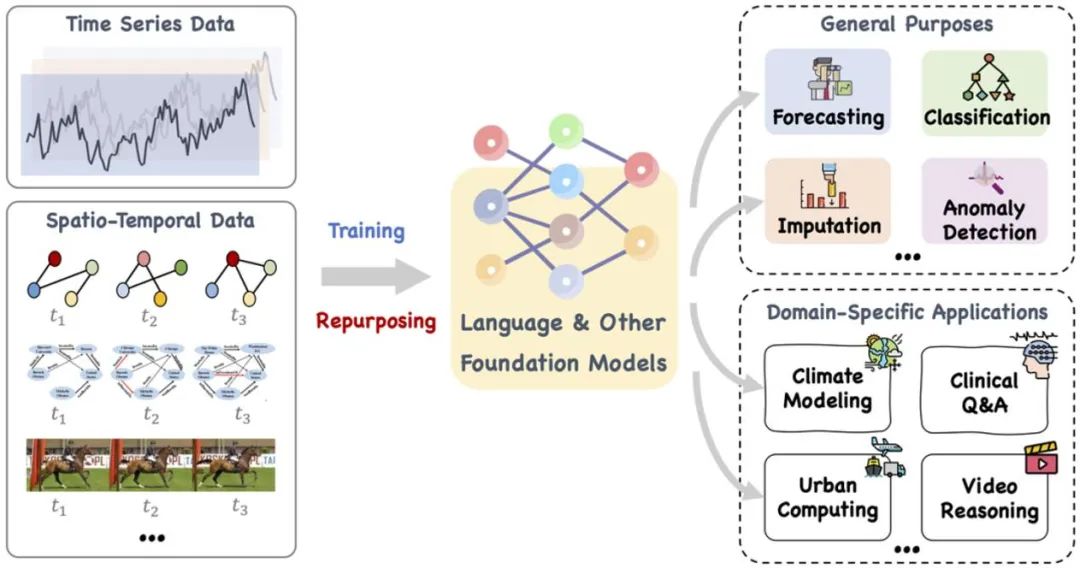
▲ 大模型,例如语言和其他相关的基础模型,既可以训练,也可以巧妙地重新调整其用途,以处理一系列通用任务和专用领域应用中的时间序列和时空数据。来源:https://arxiv.org/pdf/2310.10196.pdf
最近的研究将大型语言模型从处理自然语言拓展到时间序列和时空任务领域。这种新的研究方向,即「大模型 + 时序 / 时空数据」,催生了许多相关进展,例如 LLMTime 直接利用 LLMs 进行零样本时序预测推理。
尽管 LLMs 具备强大的学习和表示能力,能够有效地捕捉文本序列数据中的复杂模式和长期依赖关系,但作为专注于处理自然语言的「黑匣子」,LLMs 在时间序列与时空任务中的应用仍面临挑战。相较于传统的时间序列模型如 TimesNet,TimeMixer 等,LLMs 以其庞大的参数和规模可与「大象」相提并论。
因此,如何「驯服」这种在自然语言领域训练的 LLMs,使其能够处理跨越文本模态的数值型序列数据,在时间序列和时空任务中发挥出强大的推理预测能力,已成为当前研究的关键焦点。为此,需要进行更深入的理论分析,以探索语言和时序数据之间潜在的模式相似性,并有效地将其运用于特定的时间序列和时空任务。
本文阐述了如何通过重编程大语言模型 (LLM Reprogramming) 进行通用时序预测。其提出了两项关键技术,即 (1) 时序输入重编程 和 (2) 提示做前缀,将时序预测任务转换成一个可以由 LLMs 有效解决的「语言」任务,成功激活了大语言模型做高精度时序推理的能力。

论文地址:
https://openreview.net/pdf?id=Unb5CVPtae
代码地址:
https://github.com/KimMeen/Time-LLM

问题背景
时序数据在现实中广泛存在,其中时序预测在许多现实世界里的动态系统中具有非常重要意义,并已得到广泛研究。与自然语言处理(NLP)和计算机视觉(CV)不同,其中单个大型模型可以处理多个任务,时序预测模型往往需要专门设计,以满足不同任务和应用场景的需求。
虽然基于预训练的基础模型在 NLP 和 CV 领域取得了巨大的进展,但其在时序领域的发展仍受限于数据稀疏性。最近研究表明,大型语言模型(LLMs)在处理复杂的标记序列时,具备可靠的模式识别和推理能力。然而,如何有效地对齐时序数据和自然语言这两个模态,并利用大语言模型本身的推理能力处理时序分析任务,仍然是一个挑战。

论文概述
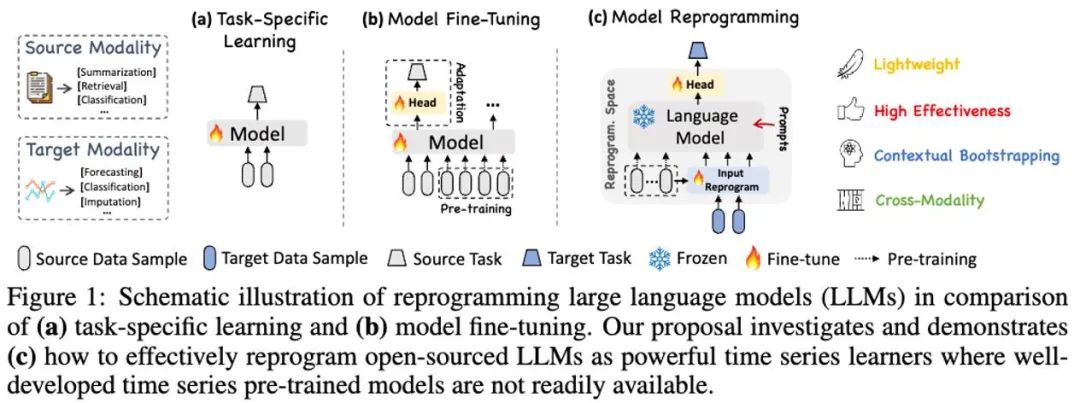
在这项工作中,作者提出了 Time-LLM,它是一个通用的大语言模型重编程(LLM Reprogramming)框架,将 LLM 轻松用于一般时间序列预测,而无需对大语言模型本身做任何训练。
Time-LLM 首先使用文本原型(Text Prototypes)对输入的时序数据进行重编程,通过使用自然语言表征来表示时序数据的语义信息,进而对齐两种不同的数据模态,使大语言模型无需任何修改即可理解另一个数据模态背后的信息。
为了进一步增强 LLM 对输入时序数据和对应任务的理解,作者提出了提示做前缀(Prompt-as-Prefix,PaP)的范式,通过在时序数据表征前添加额外的上下文提示与任务指令,充分激活 LLM 在时序任务上的处理能力。
在这项工作中,作者在主流的时序基准数据集上进行了充分的实验,结果表明 Time-LLM 能够在绝大多数情况下超越传统的时序模型,并在少样本(Few-shot)与零样本(Zero-shot)学习任务上获得了大幅提升。
这项工作中的主要贡献可以总结如下:
1. 这项工作提出了通过重编程大型语言模型用于时序分析的全新概念,无需对主干语言模型做任何修改。作者表明时序预测可以被视为另一个可以由现成的 LLM 有效解决的「语言」任务。
2. 这项工作提出了一个通用语言模型重编程框架,即 Time-LLM,它包括将输入时序数据重新编程为更自然的文本原型表示,并通过声明性提示(例如领域专家知识和任务说明)来增强输入上下文,以指导 LLM 进行有效的跨域推理。该技术为多模态时序基础模型的发展提供了坚实的基础。
3. Time-LLM 在主流预测任务中的表现始终超过现有最好的模型性能,尤其在少样本和零样本场景中。此外,Time-LLM 在保持出色的模型重编程效率的同时,能够实现更高的性能。大大释放 LLM 在时间序列和其他顺序数据方面尚未开发的潜力。

模型框架
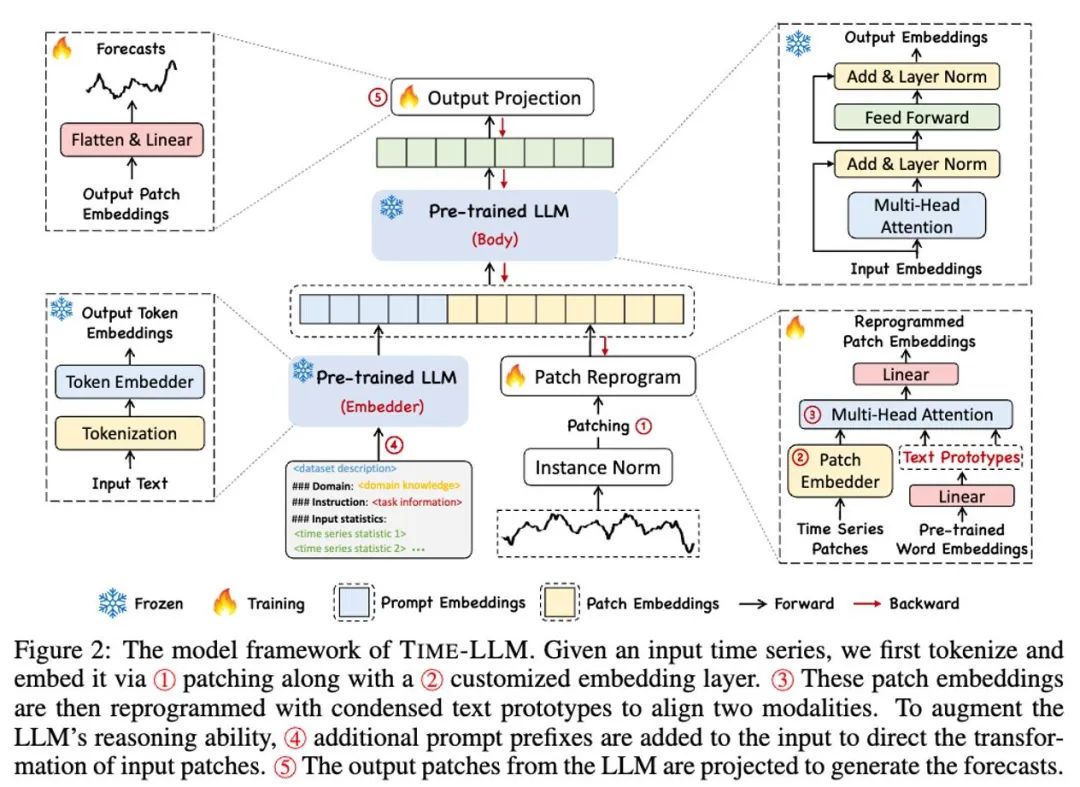
如上方模型框架图中 ① 和 ② 所示,输入时序数据先通过 RevIN 归一化操作,然后被切分成不同 patch 并映射到隐空间。
时序数据和文本数据在表达方式上存在显著差异,两者属于不同的模态。时间序列既不能直接编辑,也不能无损地用自然语言描述,这给直接引导(prompting)LLM 理解时间序列带来了重大挑战。因此,我们需要将时序输入特征对齐到自然语言文本域上。
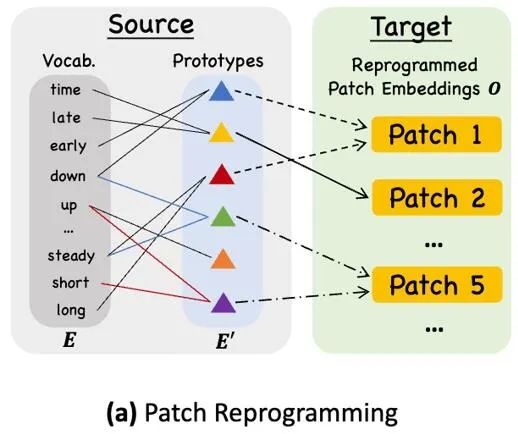
对齐不同模态的一个常见方法就是 cross-attention,如模型框架图中 ③ 所示,只需要把所有词的 embedding 和时序输入特征做一个 cross-attention(其中时序输入特征为 Query,所有词的 embedding 为 Key 和 Value)。但是,LLM 固有的词汇表很大,因此无法有效直接将时序特征对齐到所有词上,而且也并不是所有词都和时间序列有对齐的语义关系。
为了解决这个问题,这项工作对词汇表进行了线形组合来获取文本原型,其中文本原型的数量远小于原始词汇量,组合起来可以用于表示时序数据的变化特征,例如「短暂上升或缓慢下降」,如上图所示。
为了充分激活 LLM 在指定时序任务上的能力,这项工作提出了提示做前缀的范式,这是一种简单且有效的方法,如模型框架图中 ④ 所示。最近的进展表明,其他数据模式,如图像可以无缝地集成到提示的前缀中,从而基于这些输入进行有效的推理。
受这些发现的启发,作者为了使他们的方法直接适用于现实世界的时间序列,提出了一个替代问题:提示能否作为前缀信息,以丰富输入上下文并指导重新编程时间序列补丁的转换?
这个概念被称为 Prompt-as-Prefix (PaP) ,此外,作者还观察到它显著提高了 LLM 对下游任务的适应能力,同时补充了补丁的重新编程。通俗点说,就是把时间序列数据集的一些先验信息,以自然语言的方式,作为前缀 prompt,和对齐后的时序特征拼接喂给 LLM,是不是能够提升预测效果?
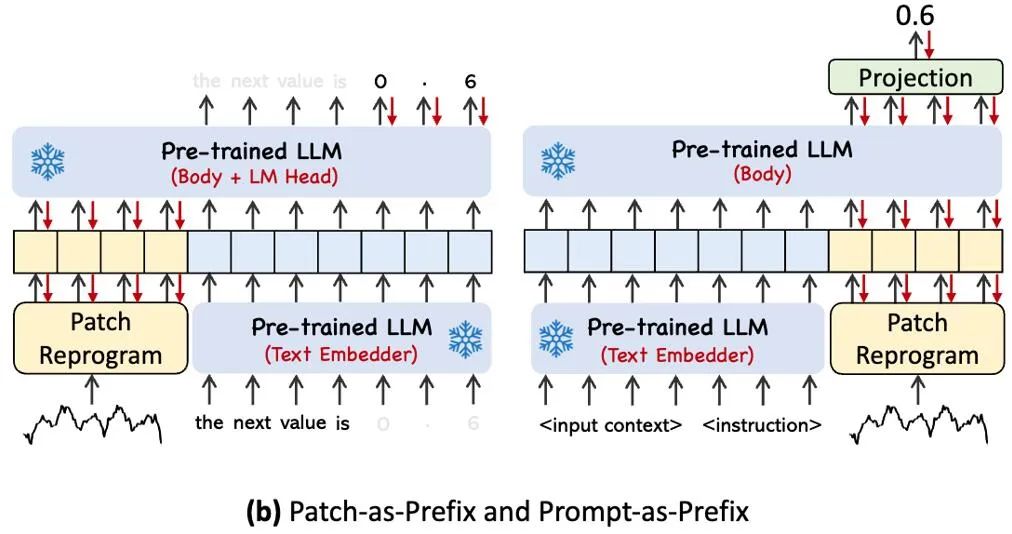
上图展示了两种提示方法。在 Patch-as-Prefix 中,语言模型被提示预测时间序列中的后续值,以自然语言表达。这种方法遇到了一些约束:
1. 语言模型在无外部工具辅助下处理高精度数字时通常表现出较低的敏感性,这给长期预测任务的精确处理带来了重大挑战;
2. 对于不同的语言模型,需要复杂的定制化后处理,因为它们在不同的语料库上进行预训练,并且可能在生成高精度数字时采用不同的分词类型。这导致预测以不同的自然语言格式表示,例如 [‘0’, ‘.’, ‘6’, ‘1’] 和 [‘0’, ‘.’, ‘61’],表示 0.61。
在实践中,作者确定了构建有效提示的三个关键组件:(1)数据集上下文;(2)任务指令,让 LLM 适配不同的下游任务;(3)统计描述,例如趋势、时延等,让 LLM 更好地理解时序数据的特性。下图给出了一个提示示例。


实验效果
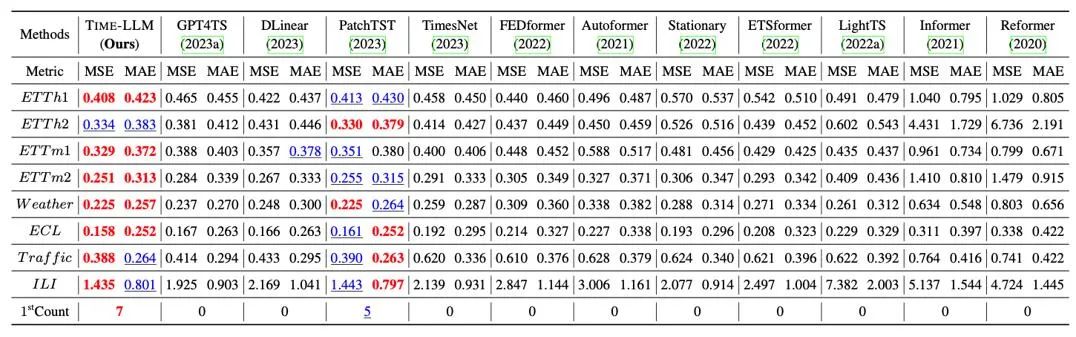
我们在长程预测上经典的 8 大公开数据集上进行了全面的测试,如下表所示,Time-LLM 在基准比较中显著超过此前领域最优效果,此外对比直接使用 GPT-2 的 GPT4TS,采用 reprogramming 重编程思想以及提示做前缀(Prompt-as-Prefix)的 Time-LLM 也有明显提升,表明了该方法的有效性。
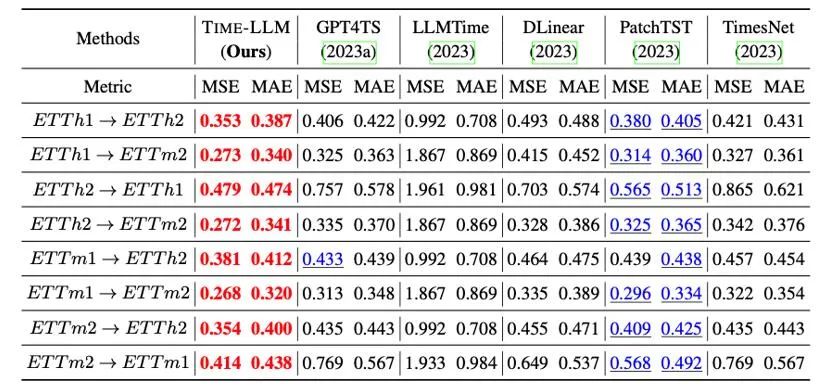
此外我们在跨领域适应的框架内评估重编程的 LLM 的零样本 zero-shot 的学习能力,得益于重编程的能力,我们充分激活了 LLM 在跨领域场景的预测能力,如下表所示,Time-LLM 在 zero-shot 场景中也展示出非凡的预测效果。

总结
大型语言模型(LLMs)的快速发展极大地推动了人工智能在跨模态场景中的进步,并促进了它们在多个领域的广泛应用。然而,LLMs 庞大的参数规模和主要针对自然语言处理(NLP)场景的设计,为其在跨模态和跨领域应用中带来了不少挑战。
鉴于此,我们提出了一种重编程大模型的新思路,旨在实现文本与序列数据之间的跨模态互动,并将此方法广泛应用于处理大规模时间序列和时空数据。通过这种方式,我们期望让 LLMs 如同灵活起舞的大象,能够在更加广阔的应用场景中展现其强大的能力。
欢迎感兴趣的朋友阅读论文 (https://arxiv.org/abs/2310.01728) 或者访问项目页面 (https://github.com/KimMeen/Time-LLM) 了解更多内容。
本项目获得了蚂蚁集团智能引擎事业部旗下 AI 创新研发部门 NextEvo 的全力支持,特别是得益于语言与机器智能团队以及优化智能团队的密切协作。在智能引擎事业部副总裁周俊与优化智能团队负责人卢星宇的带领和指导下,我们携手圆满完成了这项重要成果。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·


















 1500
1500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









