







©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 科学空间
研究方向 | NLP、神经网络
前几天,幻方发布的 DeepSeek-V2 [1] 引起了大家的热烈讨论。首先,最让人哗然的是 1 块钱 100 万 token 的价格,普遍比现有的各种竞品 API 便宜了两个数量级,以至于有人调侃“这个价格哪怕它输出乱码,我也会认为这个乱码是一种艺术”;其次,从模型的技术报告看,如此便宜的价格背后的关键技术之一是它新提出的 MLA(Multi-head Latent Attention),这是对 GQA 的改进,据说能比 GQA 更省更好,也引起了读者的广泛关注。
接下来,本文将跟大家一起梳理一下从 MHA、MQA、GQA 到 MLA 的演变历程,并着重介绍一下 MLA 的设计思路。

MHA
MHA(Multi-Head Attention),也就是多头注意力,是开山之作《Attention is all you need》所提出的一种 Attention 形式,可以说它是当前主流 LLM 的基础工作。在数学上,多头注意力 MHA 等价于多个独立的单头注意力的拼接,假设输入的(行)向量序列为 ,其中 ,那么 MHA 可以形式地记为
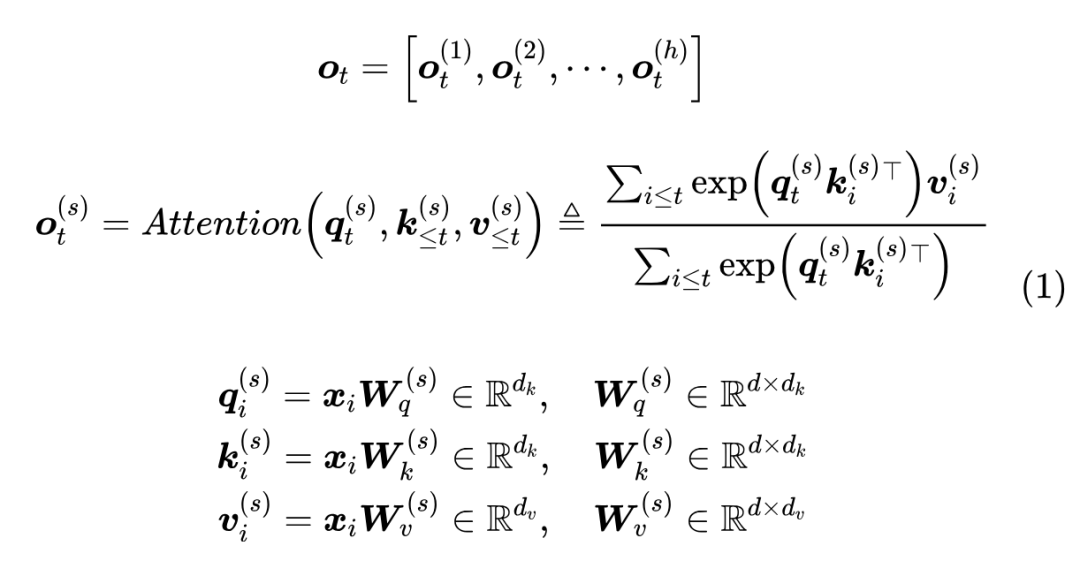
简单起见,这里省略了 Attention 矩阵的缩放因子。实践上,常见的设置是 ,对于 LLAMA2-7b 有 ,LLAMA2-70b 则是
由于这里只考虑了主流的自回归 LLM 所用的 Causal Attention,因此在 token by token 递归生成时,新预测出来的第 个 token,并不会影响到已经算好的 ,因此这部分结果我们可以缓存下来供后续生成调用,避免不必要的重复计算,这就是所谓的 KV Cache。
而后面的 MQA、GQA、MLA,都是围绕“如何减少 KV Cache 同时尽可能地保证效果”这个主题发展而来的产物。

瓶颈
一个自然的问题是:为什么降低 KV Cache 的大小如此重要?
众所周知,一般情况下 LLM 的推理都是在 GPU 上进行,单张 GPU 的显存是有限的,一部分我们要用来存放模型的参数和前向计算的激活值,这部分依赖于模型的体量,选定模型后它就是个常数;另外一部分我们要用来存放模型的 KV Cache,这部分不仅依赖于模型的体量,还依赖于模型的输入长度,也就是在推理过程中是动态增长的,当 Context 长度足够长时,它的大小就会占主导地位,可能超出一张卡甚至一台机(8 张卡)的总显存量。
在 GPU 上部署模型的原则是:能一张卡部署的,就不要跨多张卡;能一台机部署的,就不要跨多台机。这是因为“卡内通信带宽 > 卡间通信带宽 > 机间通信带宽”,由于“木桶效应”,模型部署时跨的设备越多,受设备间通信带宽的的“拖累”就越大,事实上即便是单卡 H100 内 SRAM 与 HBM 的带宽已经达到了 3TB/s,但对于 Short Context 来说这个速度依然还是推理的瓶颈,更不用说更慢的卡间、机间通信了。
所以,减少 KV Cache 的根本目的是实现在更少的设备上推理更长的 Context,从而实现更快的推理速度以及更低的推理成本。
要想更详细地了解这个问题,读者可以进一步阅读《FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness》[2]、《A guide to LLM inference and performance》[3]、《LLM inference speed of light》[4] 等文章,这里不做展开(主要是笔者水平也有限,怕说多错多)。

MQA
MQA,即 “Multi-Query Attention”,是减少 KV Cache 的一次非常朴素的尝试,首次提出自《Fast Transformer Decoding: One Write-Head is All You Need》[5],这已经是 2019 年的论文了,这也意味着早在 LLM 火热之前,减少 KV Cache 就已经是研究人员非常关注的一个课题了。
MQA 的思路很简单,直接让所有 Attention Head 共享同一个 K、V,用公式来说,就是取 消MHA 所有的 的上标:
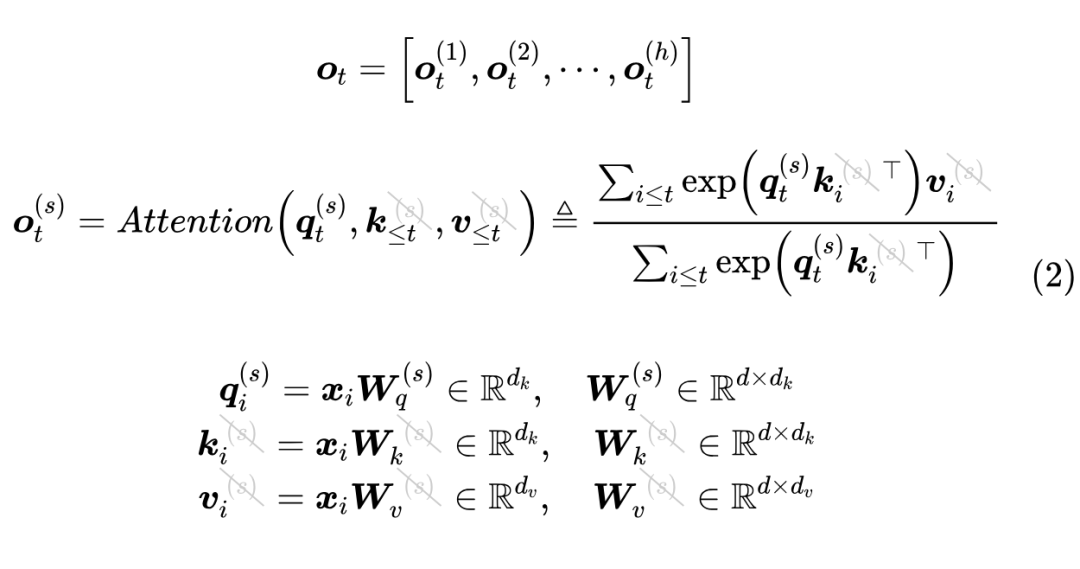
使用 MQA 的模型包括 PaLM [6]、StarCoder [7]、Gemini [8] 等。很明显,MQA 直接将 KV Cache 减少到了原来的 ,这是非常可观的,单从节省显存角度看已经是天花板了。
效果方面,目前看来大部分任务的损失都比较有限,且 MQA 的支持者相信这部分损失可以通过进一步训练来弥补回。此外,注意到 MQA 由于共享了 K、V,将会导致 Attention 的参数量减少了将近一半,而为了模型总参数量的不变,通常会相应地增大 FFN/GLU 的规模,这也能弥补一部分效果损失。

GQA
然而,也有人担心 MQA 对 KV Cache 的压缩太严重,以至于会影响模型的学习效率以及最终效果。为此,一个 MHA 与 MQA 之间的过渡版本 GQA(Grouped-Query Attention)应运而生,出自论文《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》[9],是去年的工作。
事后看来,GQA 的思想也很朴素,它就是将所有 Head 分为 个组( 可以整除 ),每组共享同一对 K、V,用数学公式表示为
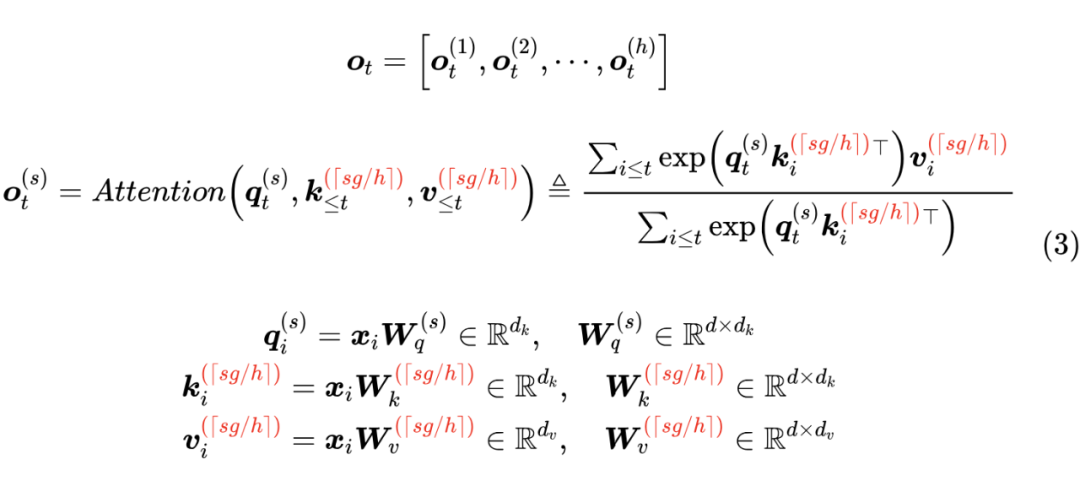
这里的 是上取整符号。GQA 提供了 MHA 到 MQA 的自然过渡,当 时就是 MHA, 时就是 MQA,当 时,它只将 KV Cache 压缩到 ,压缩率不如 MQA,但同时也提供了更大的自由度,效果上更有保证。
GQA 最知名的使用者,大概是 Meta 开源的 LLAMA2-70B [10],以及 LLAMA3 [11] 全系列,此外使用 GQA 的模型还有 TigerBot [12]、DeepSeek-V1 [13]、StarCoder2 [14]、Yi [15]、ChatGLM2 [16]、ChatGLM3 [17] 等,相比使用 MQA 的模型更多(ChatGLM 虽然在它的介绍中说自己是 MQA,但实际是 的 GQA)。
在 llama2/3-70B 中,GQA 的 ,其他用了 GQA 的同体量模型基本上也保持了这个设置,这并非偶然,而是同样出于推理效率的考虑。我们知道,70B 这个体量的模型,如果不进行极端的量化,那么不可能部署到单卡(A100/H100 80G)上。
单卡不行,那么就能单机了,一般情况下一台机可以装 8 张卡,刚才我们说了,Attention 的每个 Head 实际上是独立运算然后拼接起来的,当 时,正好可以每张卡负责计算一组 K、V 对应的 Attention Head,这样可以在尽可能保证 K、V 多样性的同时最大程度上减少卡间通信。

MLA
有了 MHA、MQA、GQA 的铺垫,我们理解 MLA(Multi-head Latent Attention)就相对容易一些了。DeepSeek-V2 的技术报告里是从低秩投影的角度引入 MLA 的,以至于有部分读者提出“为什么 LoRA 提出这么久了,直到 MLA 才提出对 KV Cache 低秩分解的做法”之类的疑问。
然而,笔者认为低秩投影这个角度并不贴近本质,因为要说低秩投影的话,事实上只要我们将 GQA 的所有 K、V 叠在一起,就会发现 GQA 也相当于在做低秩投影:
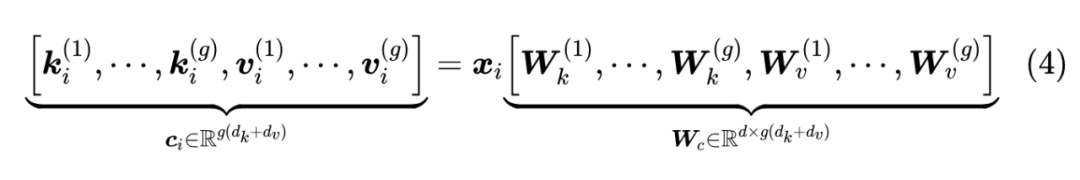
这里我们将所有 拼在一起记为 ,相应的投影矩阵也拼在一起记为 ,注意到一般都有 ,所以 到 的变换就是一个低秩投影。所以,MLA 的本质改进不是低秩投影,而是低秩投影之后的工作。

Part 1
GQA 在投影之后做了什么呢?首先它将向量对半分为两份分别作为 K、V,然后每一份又均分为 份,每一份复制 次,以此来“凑”够 个 Attention Head 所需要的 K、V。我们知道分割、复制都是简单的线性变换,所以 MLA 的第一个想法是将这些简单的线性变换换成一般的线性变换,以增强模型的能力:
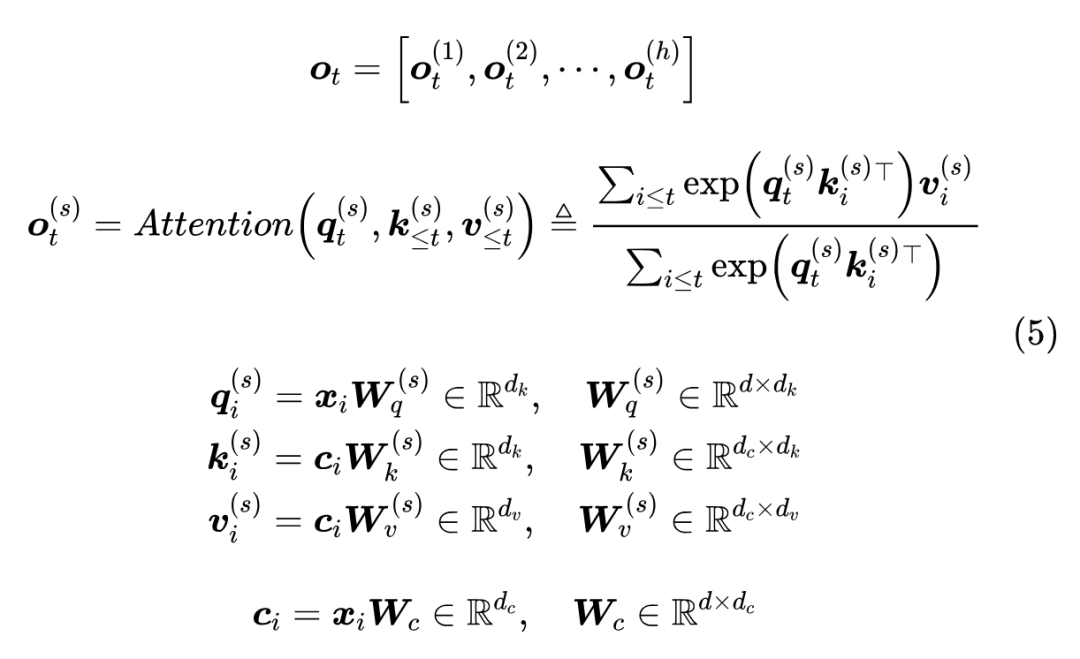
然而,理论上这样是能增加模型能力,但别忘了 GQA 的主要目的是减少 KV Cache,出于节省计算和通信成本的考虑,我们一般会缓存的是投影后的 而不是投影前的 或 ,而 MLA 的这个做法,通过不同的投影矩阵再次让所有的 K、V Head 都变得各不相同,那么 KV Cache 的大小就恢复成跟 MHA 一样大了,违背了 GQA 的初衷。
对此,MLA 发现,我们可以结合 Dot-Attention 的具体形式,通过一个简单但不失巧妙的恒等变换来规避这个问题。首先,在训练阶段还是照常进行,此时优化空间不大;然后,在推理阶段,我们利用
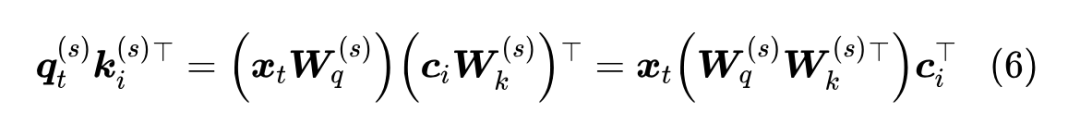
这意味着推理阶段,我们可以将 合并起来作为 Q 的投影矩阵,那么 则取代了原本的 ,同理,在 后面我们还有一个投影矩阵,于是 的 也可以吸收到后面的投影矩阵中去,于是等效地 也可以用 代替,也就是说此时 KV Cache 只需要存下所有的 就行,而不至于存下所有的 、。注意到 跟 无关,也就是说是所有头共享的,即 MLA 在推理阶段它可以恒等变换为一个MQA。
再次强调,本文的主题是一直都是减少 KV Cache,那到目前为止,MLA 做到了什么呢?答案是通过不同的投影矩阵来增强了 GQA 的能力,并且推理时可以保持同样大小的 KV Cache。那么反过来,如果我们只需要跟 GQA 相近的能力,那么是不是就可以再次减少 KV Cache 了?换言之, 没必要取 ,而是取更小的值(DeepSeek-V2 取了 512),从而进一步压缩 KV Cache,这就是 MLA 的核心思想。
(注:这里有一个细节,就是 合并成一个矩阵的恒等变换,理论上只有在无限精度下才成立,实际上如果我们使用单精度尤其是 BF16 的话,经过变换后的精度损失往往还是挺明显的,经过多层累积后可能放大到比较可观的程度,这里可能要根据实际误差看要不要做一些后处理。)

Part 2
一切似乎都很完美,看上去一个又好又省的理想设计就要出炉了。不过别急,当我们再深入思考一下就会发现,到目前为止的 MLA 有一个难以绕开的缺陷——不兼容 RoPE(旋转位置编码)。
刚才我们说了,MLA 之所以能保持跟 GQA 一样大小的 KV Cache,其关键一步是“将 合并成一个(跟位置无关的)矩阵作为 Q 的投影矩阵”,但如果加了 RoPE 的话,这一步就无法实现了。这是因为 RoPE 是一个跟位置相关的、 的分块对角矩阵 ,满足 ,MLA 加入 RoPE 之后会让 之间多插入了一项 :
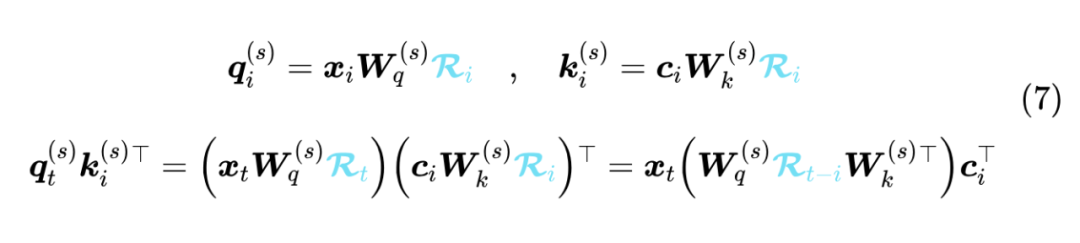
这里的 就无法合并为一个固定的投影矩阵了(跟位置差 相关),从而 MLA 的想法无法结合 RoPE 实现。
前段时间,笔者也很荣幸跟 DeepSeek 团队讨论过这个问题,但这个问题可以说非常本质,所以当时笔者实际上也没能提出什么有效的建议。
最简单的方式是放弃 RoPE,换用其他基于 Attention Bias 的位置编码,如 ALIBI,但 DeepSeek 的实验显示它明显不如 RoPE(注意,MLA 不是不能加 RoPE,而是加了 RoPE 之后无法用恒等变换技巧来减少 KV Cache),笔者也提议过换 Sandwich,它不像 ALIBI 单调衰减到负无穷,估计效果会好些,但感觉是治标不治本。还有一个折中的办法是将 的输入也改为 ,然后 RoPE 加在 之后,即
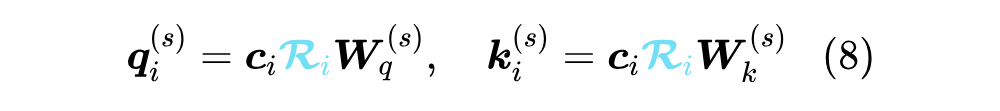
这样 就可以吸收到 中去,但这样就没有 的运算了,此时的 RoPE 不再是通过绝对位置实现相对位置,而单纯是加在 Q、K 上的绝对位置信息,让模型自己想办法提炼相对位置信息。
最后发布的 MLA,采取了一种混合的方法——每个 Attention Head的 Q、K 新增 个维度用来添加 RoPE,其中 K 新增的维度每个 Head 共享:
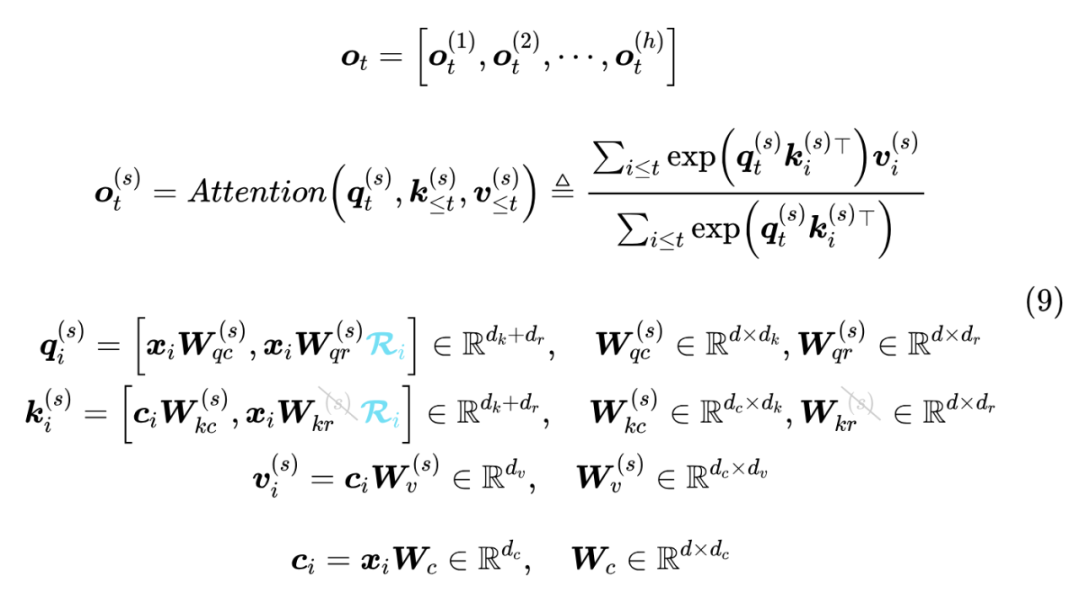
这样一来,没有 RoPE 的维度就可以重复 “Part 1” 的操作,在推理时 KV Cache 只需要存 ,新增的带 RoPE 的维度就可以用来补充位置信息,并且由于所有 Head 共享,所以也就只有在 K Cache 这里增加了 个维度,原论文取了 ,相比原本的 ,增加的幅度不大。

Part 3
最后有一个细节,就是 MLA 的最终版本,还将 Q 的输入也改为了低秩投影形式,这与减少 KV Cache 无关,主要是为了减少训练期间参数量和相应的梯度(原论文说的是激活值,个人感觉不大对)所占的显存:

注意 中的第二项,带 RoPE 的部分,其输入就是 而不是 ,这里保持了原论文的设置,不是笔误, 原论文的取值是 1536,跟 不同。同时,我们把带 RoPE 的 MHA 放在下面,方便大家对比:
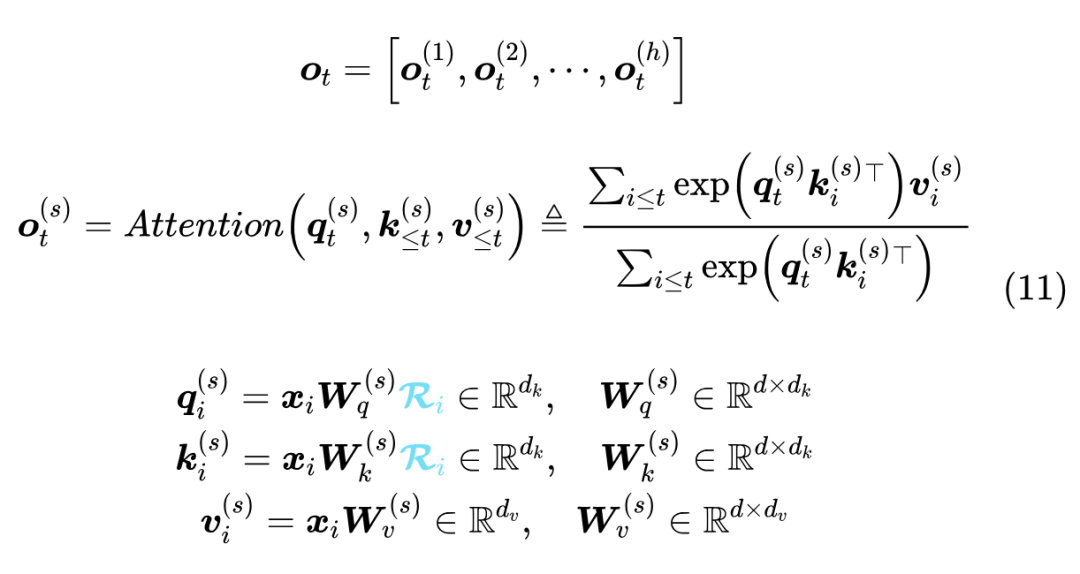
可以发现,其实在训练阶段,除了多了一步低秩投影以及只在部分维度加 RoPE 外,MLA 与 Q、K 的 Head Size 由 换成 的 MHA 基本无异。推理阶段的 MLA 则改为
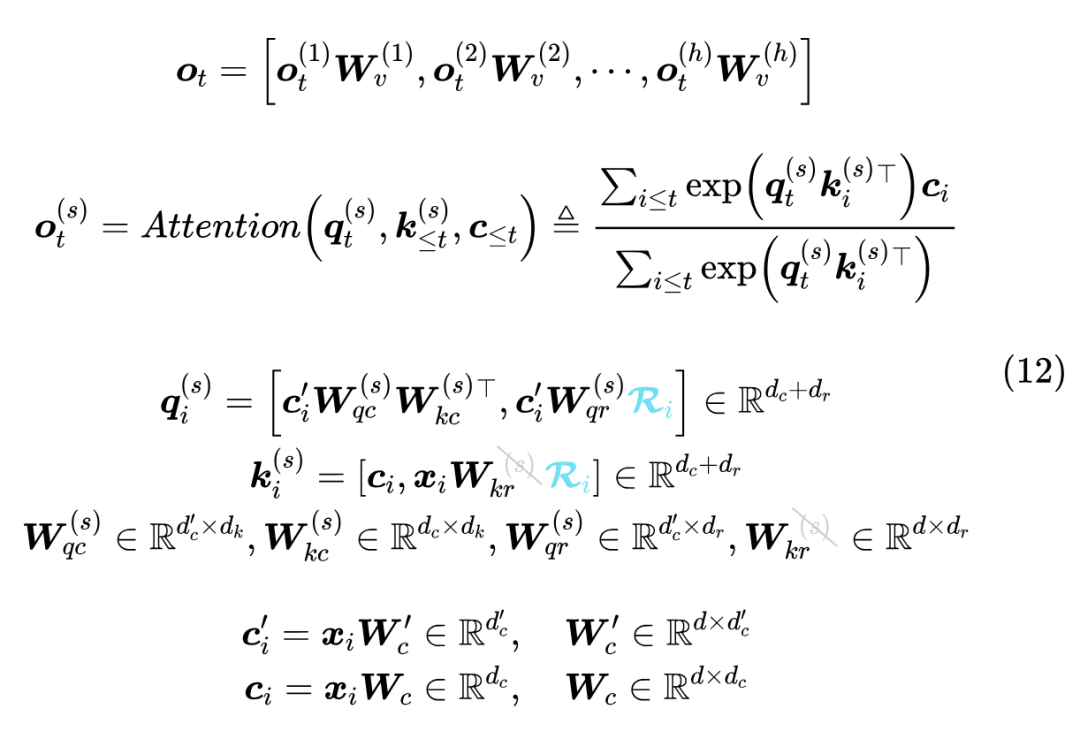
此时 Q、K 的 Head Size 变成了 ,V 的 Head Size 则变成了 ,按照原论文的设置,这是 、 的 4 倍。所以实际上 MLA 在推理阶段做的这个转换,虽然能有效减少 KV Cache,但其推理的计算量是增加的。
那为什么还能提高推理效率呢?这又回到“瓶颈”一节所讨论的问题了,我们可以将 LLM 的推理分两部分:第一个 Token 的生成(Prefill)和后续每个 Token 的生成(Generation)。
Prefill 阶段涉及到对输入所有 Token 的并行计算,然后把对应的 KV Cache 存下来,这部分对于计算、带宽和显存都是瓶颈,MLA 虽然增大了计算量,但 KV Cache 的减少也降低了显存和带宽的压力,大家半斤八两;但是 Generation 阶段由于每步只计算一个 Token,实际上它更多的是带宽瓶颈和显存瓶颈,因此 MLA 的引入理论上能明显提高 Generation 的速度。

小结
本文简单概述了多头注意力的演变历程,特别是从 MHA 向 MQA、GQA,最终到 MLA 的变化理念,最后详细展开了对 MLA 的介绍。在本文中,MLA 被视为 GQA 的一般化,它用投影矩阵的方式替代了 GQA 的分割、重复,并引入了一个恒等变换技巧来可以进一步压缩 KV Cache,同时采用了一种混合方法来兼容 RoPE。总的来说,MLA 称得上是一种非常实用的注意力变体。

参考文献
[1] https://papers.cool/arxiv/2405.04434
[2] https://papers.cool/arxiv/2205.14135
[3] https://www.baseten.co/blog/llm-transformer-inference-guide/
[4] https://zeux.io/2024/03/15/llm-inference-sol/
[5] https://papers.cool/arxiv/1911.02150
[6] https://arxiv.org/pdf/2204.02311
[7] https://papers.cool/arxiv/2305.06161
[8] https://papers.cool/arxiv/2312.11805
[9] https://papers.cool/arxiv/2305.13245
[10] https://llama.meta.com/llama2/
[11] https://llama.meta.com/llama3/
[12] https://papers.cool/arxiv/2312.08688
[13] https://papers.cool/arxiv/2401.02954
[14] https://papers.cool/arxiv/2402.19173
[15] https://papers.cool/arxiv/2403.04652
[16] https://github.com/THUDM/ChatGLM2-6B
[17] https://github.com/THUDM/ChatGLM3

总奖金池60万!

点击海报,即刻报名 ▲
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
















 371
371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









