







Mona(Multi-cognitive Visual Adapter)是一种新型视觉适配器微调方法,旨在打破传统全参数微调(full fine-tuning)在视觉识别任务中的性能瓶颈。
Mona 方法通过引入多认知视觉滤波器和优化输入分布,仅调整 5% 的骨干网络参数,就能在实例分割、目标检测、旋转目标检测等多个经典视觉任务中超越全参数微调的效果,显著降低了适配和存储成本,为视觉模型的高效微调提供了新的思路。

论文题目:
5%>100%: Breaking Performance Shackles of Full Fine-Tuning on Visual Recognition Tasks
论文地址:
https://arxiv.org/pdf/2408.08345
代码地址:
https://github.com/Leiyi-Hu/mona
作者单位:
清华、国科大、上海交大、阿里巴巴
收录情况:
已被 CVPR 2025 接受

论文亮点
随着现代深度学习的发展,训练数据和模型规模的增加成为模型性能的重要增长点,但随之而来的是模型的垂直应用和微调成本和难度的提升。
传统全量微调需要更新模型所有参数(如 GPT-3 的 1750 亿参数 ),计算成本极高。即使以早期的 BERT 为例,单卡训练 100 万数据也需 5-7 小时,对硬件资源和时间的要求限制了研究复现和实际应用。
同时,随着模型参数从亿级迈向万亿级,直接微调不仅成本高昂,还可能因过拟合导致性能下降。此外,多任务场景下需为每个任务保存完整模型副本,存储成本剧增加。
参数高效微调(Parameter Efficient Fine-Tuning,PEFT)通过保持预训练模型参数冻结,仅调整少量参数就可实现大模型在垂直应用领域的高效适配。但目前大多数 PEFT 方法,尤其是视觉领域的 PEFT 方法的性能相较于全量微调而言还存在劣势。
Mona 通过更适合视觉信号处理的设计以及对预训练特征分布的动态优化在小于 5% 的参数成本下首次突破了全量微调的性能枷锁,为视觉微调提供了新的解决方案。
本文的核心在于强调:
1. PEFT 对于视觉模型性能上限的提升(尤其是参数量较大的模型);
2. 视觉模型在全微调(尤其是少样本情况)会存在严重的过拟合问题;
3. 1*LVM+n*Adapter 模式在实际业务中潜在的性能和效率优势。
对于具体业务来说,有些用到 LVM 或者多模态大模型(如 OCR 等任务)的任务会对视觉编码器部分进行固定或仅微调 linear 层来适应下游数据。Mona 的存在理论上可以进一步提升 LVM、多模态大模型对视觉特征的理解和重构,尤其是对于一些少样本 post-training 问题。

方法
Mona 包含降维、多认知视觉滤波器、激活函数和升维等模块,并在适配器内部加入了跳跃连接(Skip-Connections),以增强模型的适应能力。这种结构设计使得 Mona 能够在保持高效的同时,显著提升视觉任务的性能。
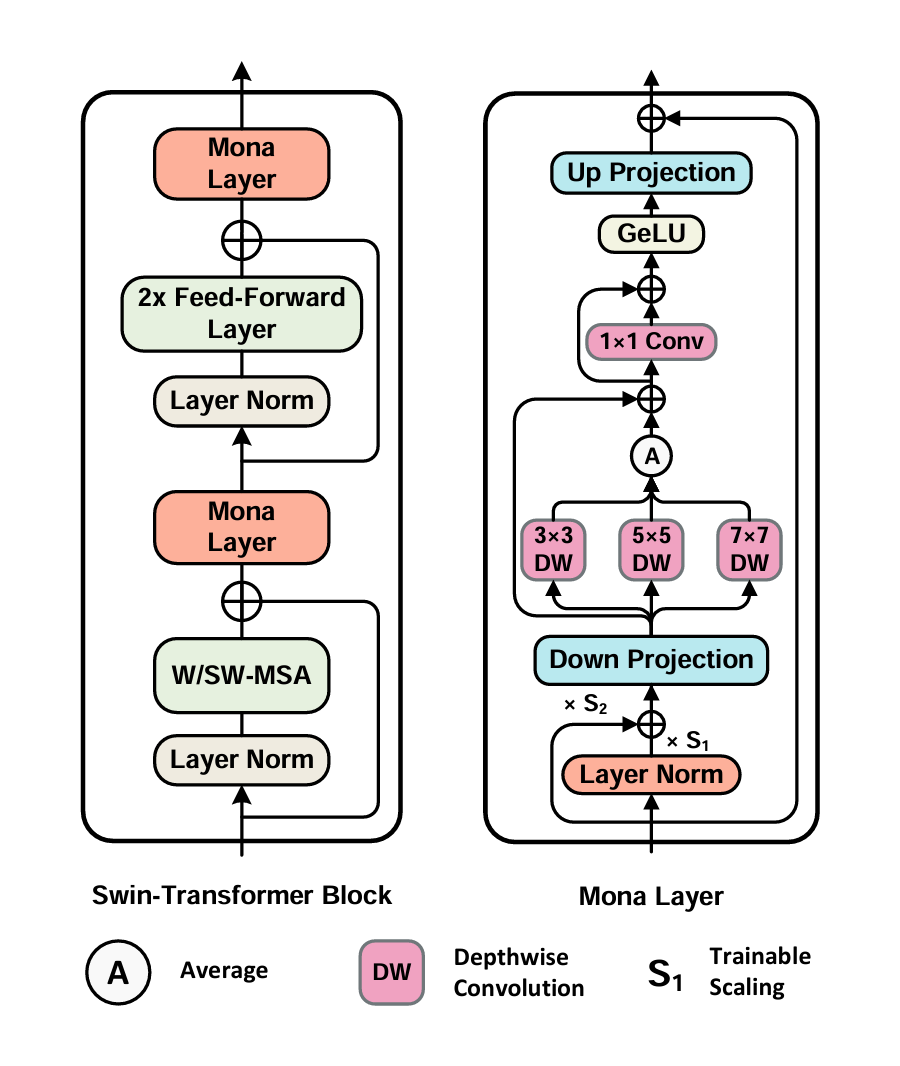
2.1 多认知视觉滤波器
Mona 方法的核心在于引入了多认知视觉滤波器,这些滤波器通过深度可分离卷积(Depth-Wise Convolution)和多尺度卷积核(3×3、5×5、7×7)来增强适配器对视觉信号的处理能力。
与传统的线性适配器不同,Mona 专门针对视觉任务设计,能够更好地处理二维视觉特征,通过多尺度特征融合提升模型对视觉信息的理解能力。
2.2 输入优化
Mona 在适配器的前端加入了分布适配层(Scaled LayerNorm),用于调整输入特征的分布。这种设计能够优化从固定层传递过来的特征分布,使其更适合适配器的处理,从而提高微调效率。

实验结果
3.1 实验设置
论文在多个代表性视觉任务上进行了实验,包括:
实例分割(COCO)
语义分割(ADE20K)
目标检测(Pascal VOC)
旋转目标检测(DOTA/STAR)
图像分类(Flowers102、Oxford-IIIT Pet、VOC2007)
实验使用了 SwinTransformer 系列作为骨干网络,并基于 ImageNet-22k 数据集进行预训练。
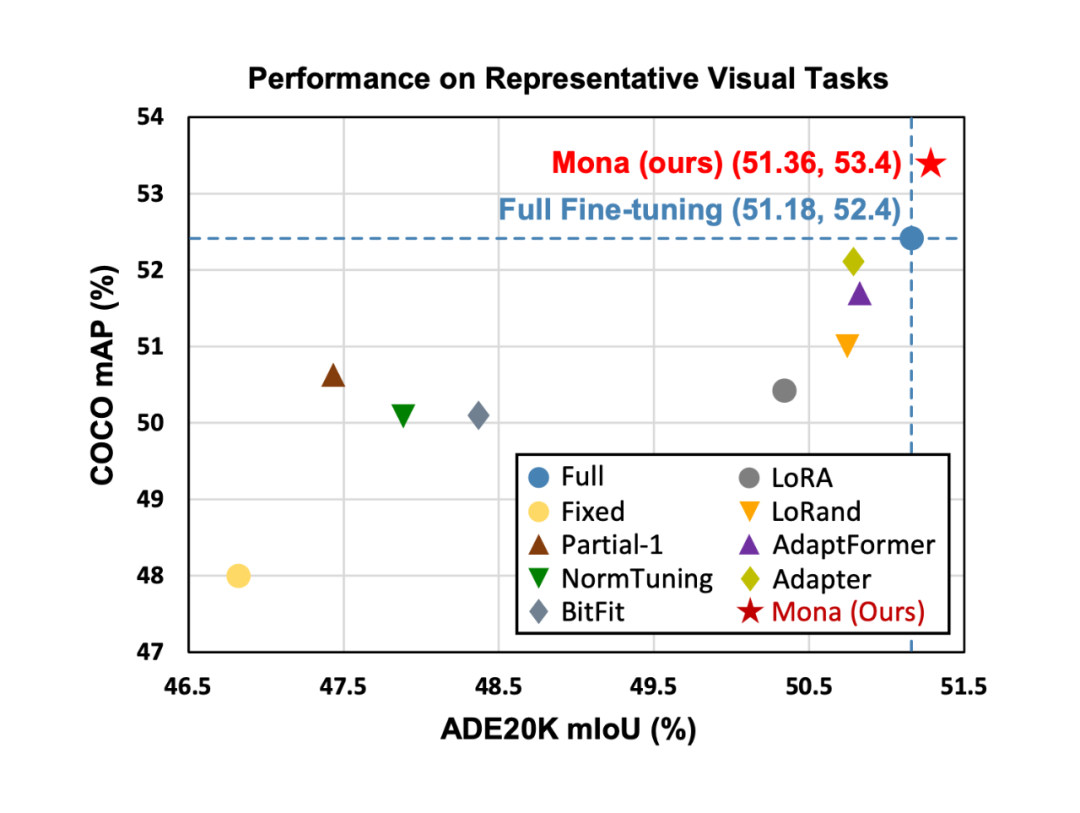
3.2 性能对比
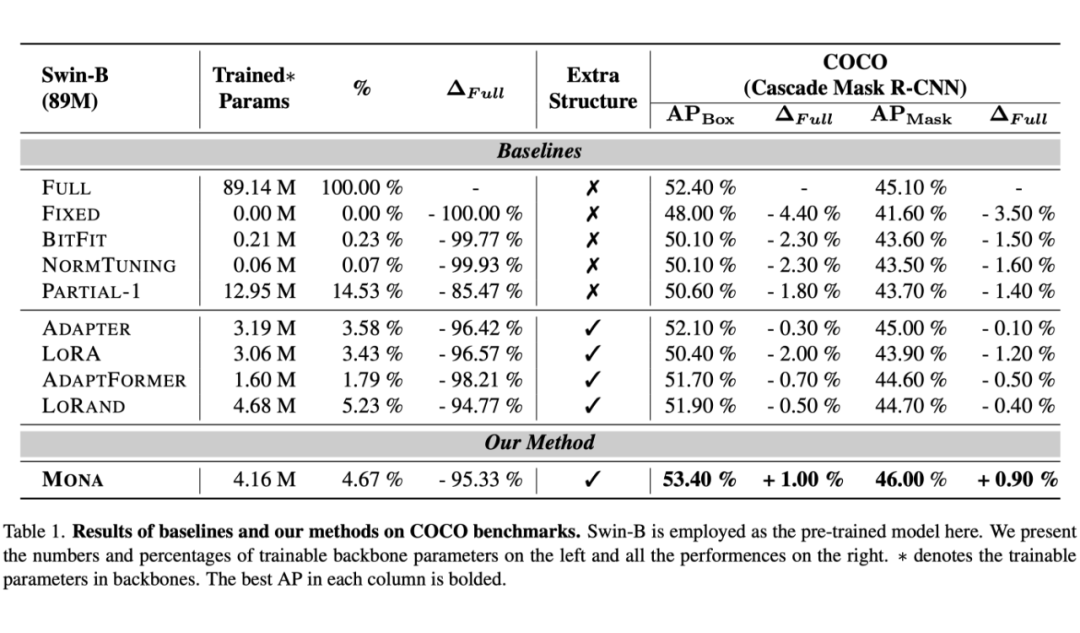
在 COCO 数据集上,Mona 方法相比全参数微调提升了 1% 的 mAP,仅调整了不到 5% 的参数。
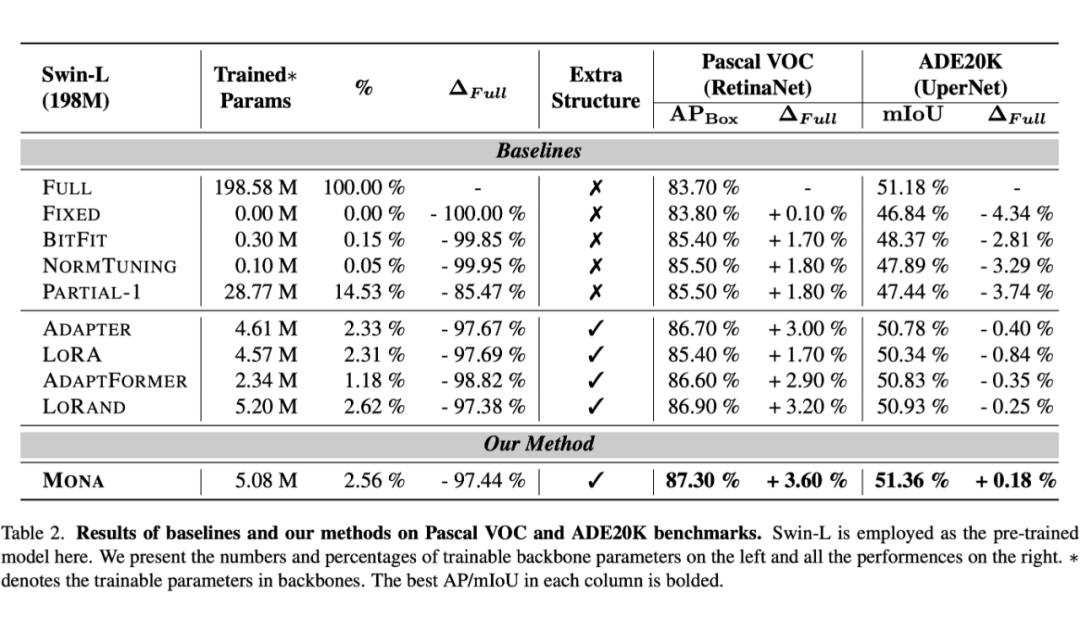
在 ADE20K 数据集上,Mona 提升了 0.18% 的 mIoU,表现出色。
在 Pascal VOC 数据集上,Mona 提升了 3.6% 的 APbox,显示出显著的性能提升。
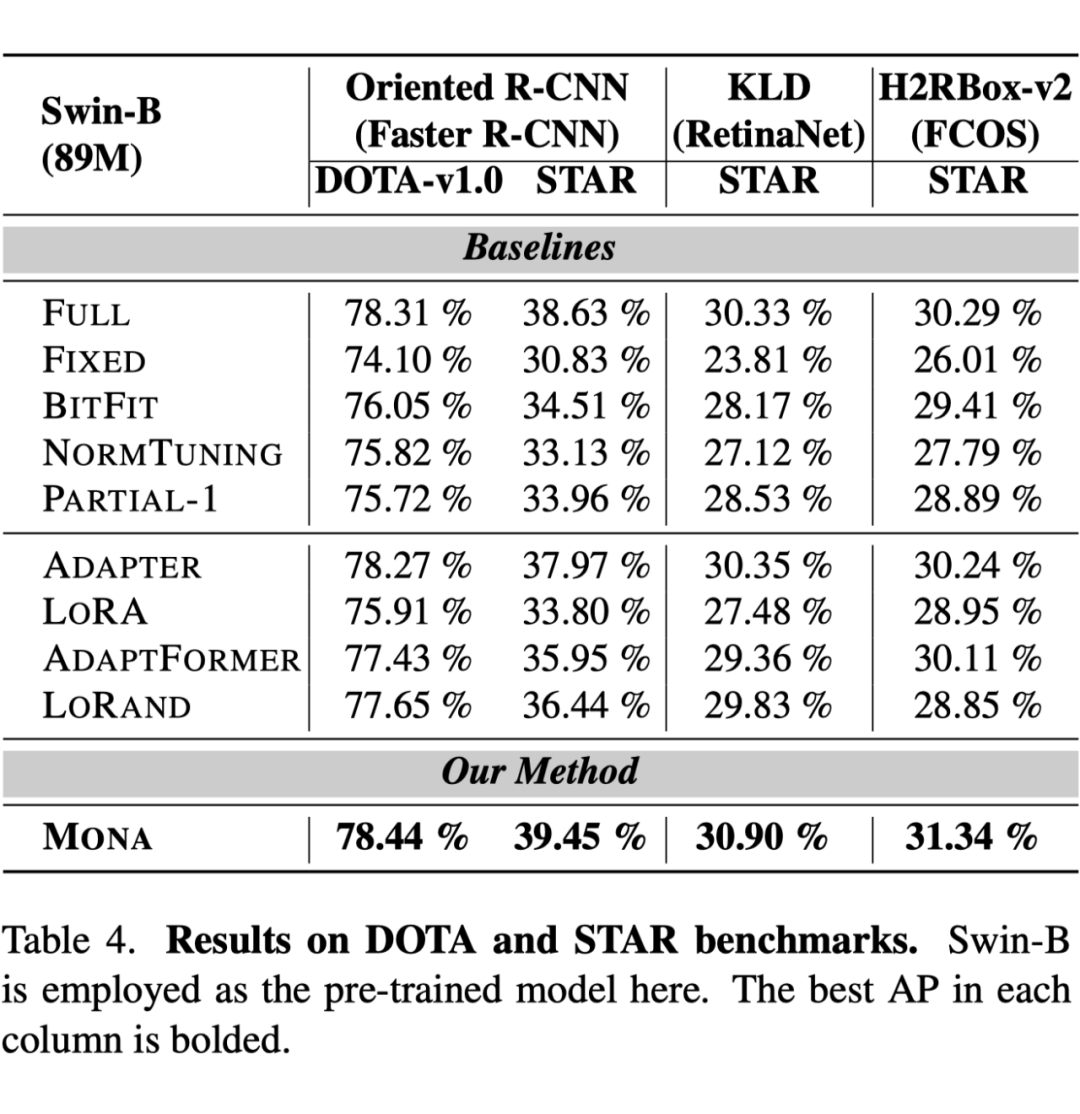
在旋转目标检测任务(DOTA/STAR)中,Mona 在多个框架下均优于其他方法。
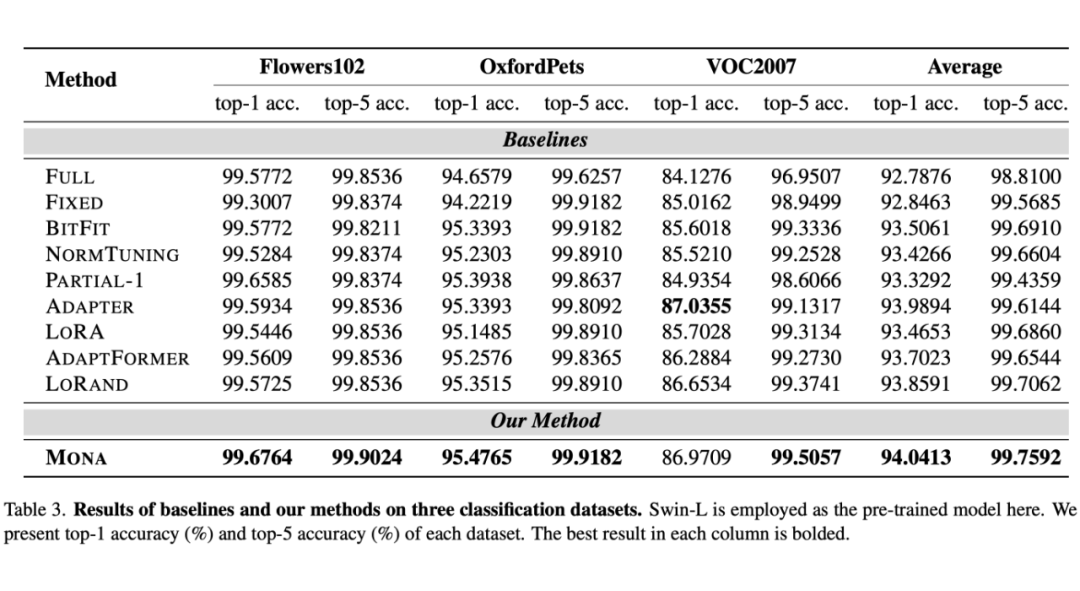
在图像分类任务上,Mona 也有不俗的性能。
3.3 收敛性分析
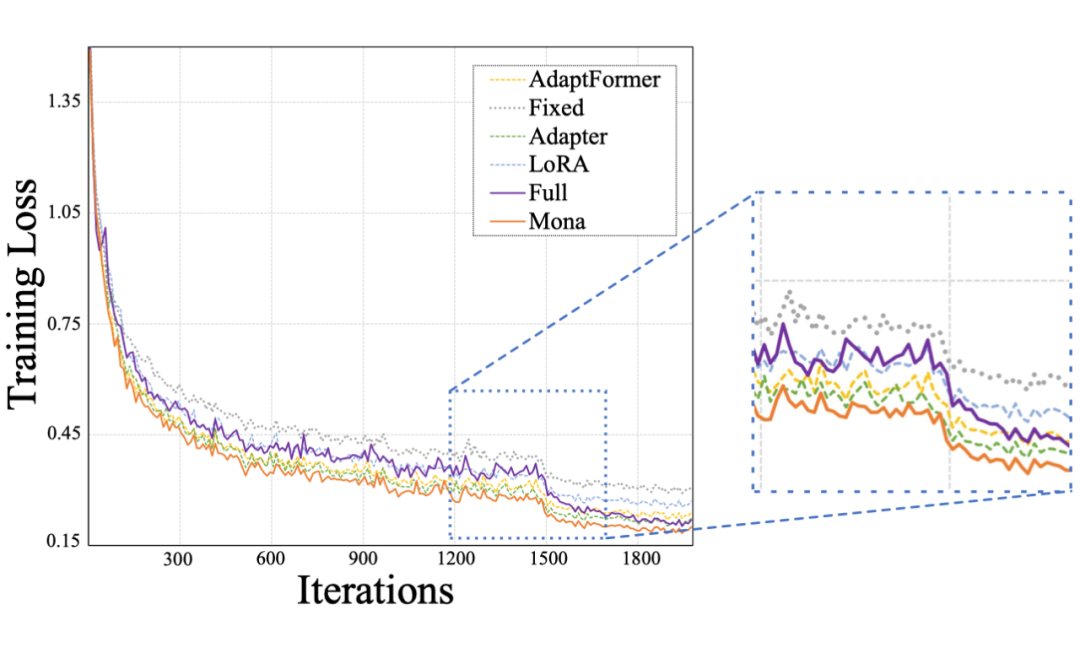
在所有方法中, Mona 收敛速度更快,并且明显超过了全微调。

即插即用模块
import torch.nn as nn
import torch.nn.functional as F
# ---------------------------- Mona 模块 ----------------------------
INNER_DIM = 64
class MonaOp(nn.Module):
def __init__(self, in_features):
super().__init__()
self.conv1 = nn.Conv2d(in_features, in_features, kernel_size=3, padding=3 // 2, groups=in_features)
self.conv2 = nn.Conv2d(in_features, in_features, kernel_size=5, padding=5 // 2, groups=in_features)
self.conv3 = nn.Conv2d(in_features, in_features, kernel_size=7, padding=7 // 2, groups=in_features)
self.projector = nn.Conv2d(in_features, in_features, kernel_size=1, )
def forward(self, x):
identity = x
conv1_x = self.conv1(x)
conv2_x = self.conv2(x)
conv3_x = self.conv3(x)
x = (conv1_x + conv2_x + conv3_x) / 3.0 + identity
identity = x
x = self.projector(x)
return identity + x
class Mona(BaseModule):
def __init__(self,
in_dim,
factor=4):
super().__init__()
self.project1 = nn.Linear(in_dim, INNER_DIM)
self.nonlinear = F.gelu
self.project2 = nn.Linear(INNER_DIM, in_dim)
self.dropout = nn.Dropout(p=0.1)
self.adapter_conv = MonaOp(INNER_DIM)
self.norm = nn.LayerNorm(in_dim)
self.gamma = nn.Parameter(torch.ones(in_dim) * 1e-6)
self.gammax = nn.Parameter(torch.ones(in_dim))
def forward(self, x, hw_shapes=None):
identity = x
x = self.norm(x) * self.gamma + x * self.gammax
project1 = self.project1(x)
b, n, c = project1.shape
h, w = hw_shapes
project1 = project1.reshape(b, h, w, c).permute(0, 3, 1, 2)
project1 = self.adapter_conv(project1)
project1 = project1.permute(0, 2, 3, 1).reshape(b, n, c)
nonlinear = self.nonlinear(project1)
nonlinear = self.dropout(nonlinear)
project2 = self.project2(nonlinear)
return identity + project2
# ---------------------------- 插入模式 -----------------------------
# 此处省略部分 Swin 组件实现,仅提供 Mona 插入模式。
class SwinBlock(BaseModule):
""""
Args:
embed_dims (int): The feature dimension.
num_heads (int): Parallel attention heads.
feedforward_channels (int): The hidden dimension for FFNs.
window_size (int, optional): The local window scale. Default: 7.
shift (bool, optional): whether to shift window or not. Default False.
qkv_bias (bool, optional): enable bias for qkv if True. Default: True.
qk_scale (float | None, optional): Override default qk scale of
head_dim ** -0.5 ifset. Default: None.
drop_rate (float, optional): Dropout rate. Default: 0.
attn_drop_rate (float, optional): Attention dropout rate. Default: 0.
drop_path_rate (float, optional): Stochastic depth rate. Default: 0.
act_cfg (dict, optional): The config dict of activation function.
Default: dict(type='GELU').
norm_cfg (dict, optional): The config dict of normalization.
Default: dict(type='LN').
with_cp (bool, optional): Use checkpoint or not. Using checkpoint
will save some memory while slowing down the training speed.
Default: False.
init_cfg (dict | list | None, optional): The init config.
Default: None.
"""
def __init__(self,
embed_dims,
num_heads,
feedforward_channels,
window_size=7,
shift=False,
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.,
act_cfg=dict(type='GELU'),
norm_cfg=dict(type='LN'),
with_cp=False,
init_cfg=None):
super(SwinBlock, self).__init__()
self.init_cfg = init_cfg
self.with_cp = with_cp
self.norm1 = build_norm_layer(norm_cfg, embed_dims)[1]
self.attn = ShiftWindowMSA(
embed_dims=embed_dims,
num_heads=num_heads,
window_size=window_size,
shift_size=window_size // 2 if shift else 0,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop_rate=attn_drop_rate,
proj_drop_rate=drop_rate,
dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
init_cfg=None)
self.norm2 = build_norm_layer(norm_cfg, embed_dims)[1]
self.ffn = FFN(
embed_dims=embed_dims,
feedforward_channels=feedforward_channels,
num_fcs=2,
ffn_drop=drop_rate,
dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
act_cfg=act_cfg,
add_identity=True,
init_cfg=None)
self.mona1 = Mona(embed_dims, 8)
self.mona2 = Mona(embed_dims, 8)
def forward(self, x, hw_shape):
def _inner_forward(x):
identity = x
x = self.norm1(x)
x = self.attn(x, hw_shape)
x = x + identity
x = self.mona1(x, hw_shape)
identity = x
x = self.norm2(x)
x = self.ffn(x, identity=identity)
x = self.mona2(x, hw_shape)
return x
if self.with_cp and x.requires_grad:
x = cp.checkpoint(_inner_forward, x)
else:
x = _inner_forward(x)
return x
结论
Mona 方法通过多认知视觉滤波器和输入优化,显著提升了视觉任务的微调性能,同时大幅减少了参数调整量。这一方法不仅在多个视觉任务中超越了传统全参数微调,还为未来视觉模型的高效微调提供了新的方向。
预印版期间,Mona 已被复旦、中科大、南大、武大等多家单位的工作视为 SOTA 方法运用在医学、遥感等领域。Mona 的开源代码将进一步推动这一领域的研究和应用。

引用格式
@misc{yin20245100breakingperformanceshackles,
title={5%>100%: Breaking Performance Shackles of Full Fine-Tuning on Visual Recognition Tasks},
author={Dongshuo Yin and Leiyi Hu and Bin Li and Youqun Zhang and Xue Yang},
year={2024},
eprint={2408.08345},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2408.08345},
}
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·


















 6234
6234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









