







决策树——信息增益、信息增益率、基尼指数
这是机器学习课上面教的几个概念,在这里记一下笔记,如果大家发现我的理解有误,请指正,谢谢。
背景——信息量的表示
一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”越来越高、“混乱程度”越来越低。
有用的叫信息,想都不要想的事实,不叫信息,或者说信息量很低。
用平时我们习惯说的一个词“信息量”举例:eg:外面走过的人是中国人——信息量小。相反,外面走过的人不是中国人——信息量大。(个人理解)
所以就有一个表示信息量的公式:
y
=
−
l
o
g
2
P
k
y=-log_2P_k
y=−log2Pk
其中
P
k
P_k
Pk表示的是信息发生的可能性。发生的可能性越大,也就是其概率越大,则信息越少。
此时我们对信息量的表示有了一定的理解,这是背景。
信息熵
熵是指混乱程度,越混乱,则熵越大。信息熵即可理解成信息的混乱程度。定义以下公式来表示信息熵:
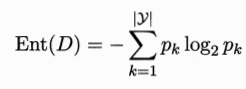
假设现在有一堆数据,每个数据分别可能取值为1,2,3。情况一:取1的概率是三分之一,取2的概率也是三分之一,取3的概率还是三分之一,这个时候数据非常混乱(因为三种取值不仅取尽了,而且取谁的概率都相同),算一下Ent,是log23,这个值也是最大的信息熵了。情况二:取1的概率是1,取2或3的概率为0.也就是说所有的数据都是1,此时数据非常不混乱,因为大家都一样,怎么混乱呢?应该非常“纯净”,算一下Ent,是0,这个值也是最小的信息熵。
由此可见,信息熵(Ent)越高,数据越混乱、即越纯净。
信息增益
说了信息熵,那再理解信息增益就会简单一点。把信息熵用在决策树上面,就是信息增益。
决策树的目标是什么,是把混乱的结果变得纯净。树枝节点上面的信息与节点下面的相比,因为经过了这个节点的分类,应该变得不那么混乱了。说的专业一点,信息熵变小。所以我们令节点后的信息熵减去前面的信息熵,这个差,就是信息增益的值。如下式:
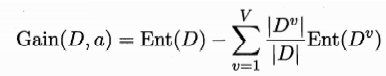
增益率
如果纯看信息增益,会导致包含类别越多的特征的信息增益越大。极端一点,如果有多少个样本,这个特征就有多少个类别,此时信息增益将会非常高,但是此时决策树会非常浅,有违“分而治之”的初衷。
引入一个惩罚项S,在特征的类别数特别多时,S也会变大。

将信息增益除以S,可以做到平衡的作用。
基尼系数
基尼系数也是一种衡量信息不确定性的方法,与信息熵计算出来的结果差距很小,基本可以忽略,但是基尼系数要计算快得多,因为没有对数,公式为:
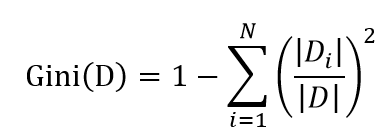
一般将基尼系数最小的属性选为最优化分属性。
















 1443
1443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











