







 业界急需在移动设备上运行CNN,本文提出高效率网络结构PeleeNet,由传统卷积搭建,在ImageNet ILSVRC2012上准确率更高、速度更快、模型更小。还提出实时目标检测系统Pelee,结合PeleeNet和SSD算法,优化结构提升速度,在PASCAL VOC2007和MS COCO上表现优异,超越YOLOv2。
业界急需在移动设备上运行CNN,本文提出高效率网络结构PeleeNet,由传统卷积搭建,在ImageNet ILSVRC2012上准确率更高、速度更快、模型更小。还提出实时目标检测系统Pelee,结合PeleeNet和SSD算法,优化结构提升速度,在PASCAL VOC2007和MS COCO上表现优异,超越YOLOv2。
Abstract
业界急需在算力和资源有限的移动设备上运行CNN,这促进了高效模型设计的研究。近些年人们提出了若干个高效率网络结构,例如 MobileNet、ShuffleNet、MobileNetV2等。但是这些模型都非常依赖深度可分离卷积,而在大多数的深度学习框架中没有深度可分离卷积的高效的实现。在这篇论文中,我们提出了一个高效率的网络结构,称作 PeleeNet,它由传统的卷积搭建而来。在 ImageNet ILSVRC2012 数据集上,相较于 MobileNet和MobileNetV2,我们的 PeleeNet 取得了更高的准确率,在 NVIDIA TX2 上的速度是它们的1.8倍。同时,PeleeNet 只是MobileNet模型大小的66%66\%66%。我们然后提出了一个实时的目标检测系统,将 PeleeNet和SSD算法结合起来,优化网络结构提高速度。Pelee 在PASCAL VOC2007上的mAP为76.4%76.4\%76.4%,在MS COCO上的mAP为22.4%22.4\%22.4%,在 iPhone8上的速度为23.6 FPS,在TX2上的速度是125 FPS。在COCO上的表现超过了YOLOv2,算力上要比YOLOv2低13.6倍,模型大小要小11.3倍。
1. Introduction
最近,越来越多的人开始关注如何在内存和算力有限的条件下运行高质量CNN模型。近些年来,业界出现了许多创新性的网络结构,如MobileNets、ShuffleNet、NASNet-A、MobilenetV2等。但是,所有的这些网络都非常依赖于深度可分离卷积,而这种卷积缺乏高效率的实现。同时,也有一些研究在将高效率模型和快速目标检测模型结合起来。该研究尝试找到一个高效率的卷积网络结构,能同时用于图像分类和目标检测任务。下面我们列出本文的一些主要的贡献:
-
我们提出了一个 DenseNet的变体结构,称为移动设备上的PeleeNet。Pelee延续了DenseNet中的 connectivity pattern 以及一些核心设计原则。该设计同样考虑到了内存和算力资源有限的条件。在 Stanford Dogs数据集上的实验结果表明,PeleeNet在准确率上要高于原来的DenseNet 5.5%5.5\%5.5%,比MobileNet要高6.53%6.53\%6.53%。PeleeNet在ImageNet ILSVRC 2012上获得了优异的成绩。PeleeNet 的Top-1准确率要比MobileNet高2.1%2.1\%2.1%。另一点也很重要,PeleeNet的大小仅是MobileNet的66%66\%66%。下面列举PeleeNet的一些关键特性:
-
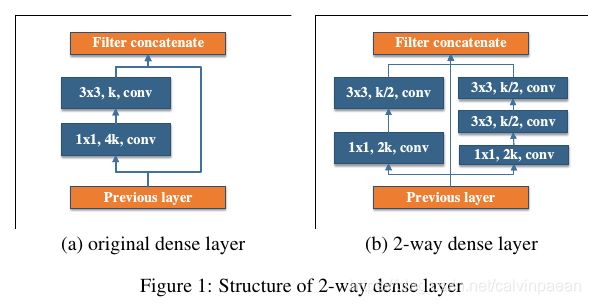
Two-way Dense layer:受GoogLeNet的启发,我们使用了一个2-way dense layer来得到不同尺度的感受野。该层的一条 way使用3×33\times 33×3的卷积核,另一条way使用两个堆叠的3×33\times 33×3卷积,学习大物体的视觉特征。结构如下图所示:
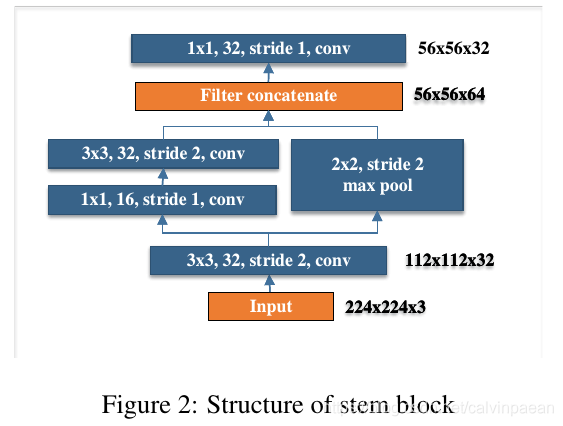
- Stem block:受 Inception-V4和DSOD启发,我们在第一个 dense layer之前设计了一个非常节约计算成本的 stem block。Stem block的结构如下图所示。这个 stem block能有效地提升特征表示能力,不会增加额外的计算成本,要比其他昂贵的方法要好(比如要增加第一个卷卷积层的通道数或增加 growth rate)。
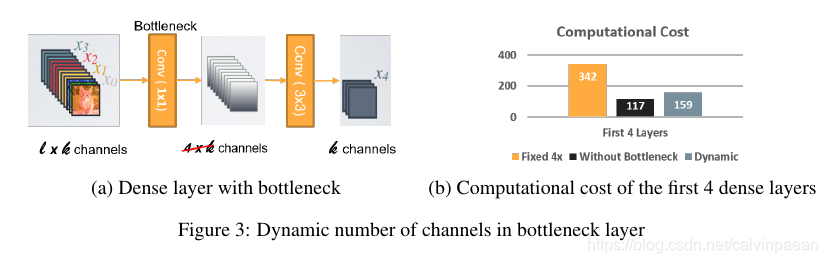
- Bottleneck层中通道个数是动态的:另一个要点就是 bottleneck层里通道的个数可以随着输入形状而改变,而不是像原来的DenseNet那样是一个固定的4倍 growth rate。在DenseNet中,我们观察到对于前几个dense layers,bottleneck通道的个数要比它输入的通道个数多得多,也就是说对于这些层,bottleneck层的计算成本是增加的,而不是降低了。为了保持结构的连续性,我们在所有的dense layer中增加了该 bottleneck层,但是通道个数随着输入的形状动态调节,确保通道的个数不超过输入通道个数。和原来的DenseNet结构相比,我们的实验表明这个方法能够节约28.5%28.5\%28.5%的算力开支,而不会降低多少的准确率。
- 无需压缩的 transition layer:我们的实验显示,DenseNet中提到的压缩因子可能伤害到特征的表现力。在 transition层中,我们将输出通道个数和输入通道个数保持一致。
- 复合函数:为了提升实际速度,我们使用了传统的 post-activation方法(卷积-BN-ReLU),作为我们的复合函数,而不是像DenseNet那样使用 pre-activation方法。对于post-activation,所有的BN层都可以在推理阶段和卷积层融合起来,能极大地提升速度。我们也在最后一个 dense block后增加了1×11\times 11×1卷积层,获得更强的特征表现力。
我们优化了SSD的网络结构提升速度,然后和PeleeNet结合起来。这个方法称作 Pelee,在PASCAL VOC2007上取得了76.4%76.4\%76.4%的 mAP,在COCO上取得了22.4%22.4\%22.4%的mAP。它在速度、精度和模型大小上超过了YOLOv2。为了平衡速度和精度,我们做的主要改进有:
-
特征图选取:和原来的SSD不同,我们以另一种方式构建了目标检测网络,精心选取了5个尺度的特征图(19×19,10×10,5×5,3×3,1×119\times 19, 10\times 10, 5\times 5, 3\times 3, 1\times 119×19,10×10,5×5,3×3,1×1)。为了降低算力成本,我们没有使用38×3838\times 3838×38的特征图。
-
残差预测模块:我们延续了Residual features and unified prediction network for single stage detection论文中的思路,让特征经过特征提取网络。对于每个用于检测的特征图,我们在预测之前构建了一个残差模块。ResBlock的结构如下图所示。
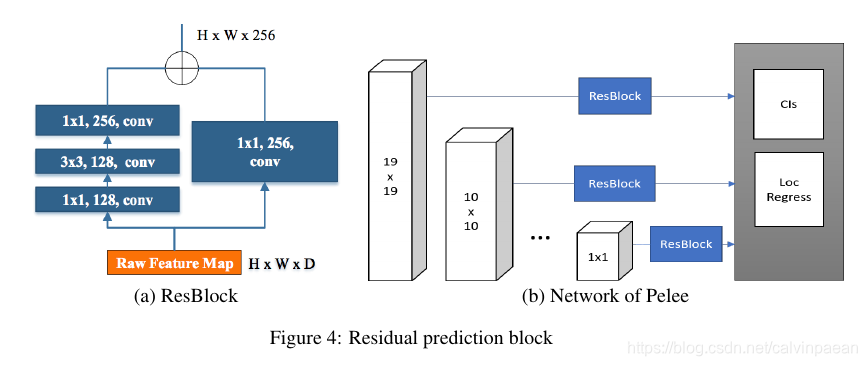
- 更小的用于预测的卷积核:残差预测模块使我们可以使用1×11\times 11×1卷积核来预测类别得分和边框回归。实验显示,使用1×11\times 11×1卷积核取得的准确率几乎和3×33\times 33×3卷积核一样。但是,1×11\times 11×1卷积核使计算成本降低了21.5%21.5\%21.5%。
我们为不同的高效分类模型、不同的单阶段目标检测模型提供了一个 benchmark测试,基于 NVIDIA TX2嵌入式平台和iPhone8。
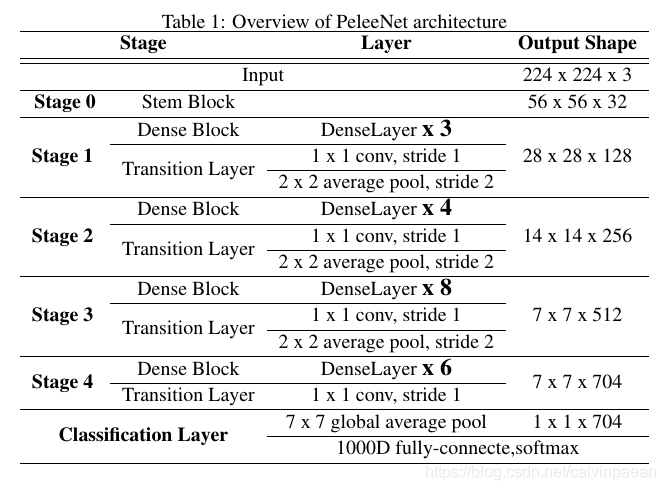
2. PeleeNet: 高效的特征提取网络
2.1 结构
PeleeNet的结构如下表所示。网络总体由一个 stem block和4个阶段的特征提取器构成。除了最后一个阶段,每个阶段的最后一层都是 average pooling层,它的 stride为2。四阶段的结构通常用在大模型设计中。ShuffleNet使用了一个三阶段结构,在每个阶段的开始收缩特征图的大小。尽管这可以有效降低计算成本,但我们认为,对于视觉任务来说,网络早期阶段的特征是非常重要的。因而,我们使用了一个四阶段的结构。前两个阶段中,层的个数被特别地控制在一个可接受的范围内。
2.2 Ablation Study
数据集
我们构建了一个定制化的 Stanford Dogs数据集,用于 ablation study。Stanford Dogs数据集包含了全世界120个狗的种类。它是用 ImageNet里的图像和标签构建,用于细纹理图像分类任务。我们相信,对于这个任务来说,该数据集已经足够复杂了,可以评价网络的性能。但是,在原来的数据集中,它只有14580张训练图像,每个类别有120张图像,这要从头训练网络是不够的。我们没有用原来的Stanford Dogs数据集,我们从 ImageNet中构建了一个 ILSVRC2012的子集。训练数据和验证数据都是从ILSVRC2012数据集里拷贝来的。在接下来的内容中,Stanford Dogs指的就是ILSVRC2012的子集,而不是原来的那一个。该数据集的具体信息有:
- 类别的个数为120;
- 训练图像的个数为150466;
- 验证图像的个数为6000;
2.2.2 多样设计选择对于性能的影响
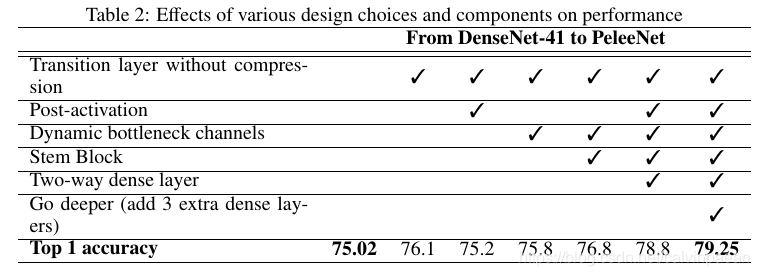
我们构建了一个类似于 DenseNet的网络,称为DenseNet-41,作为我们的基线模型。该模型和原来的 DenseNet模型有两点不同。第一个不同就是第一个卷积层的参数不同。第一个卷积层的通道数为24,而不是64,卷积核的大小由7×77\times 77×7改为3×33\times 33×3。第二个不同就是,每个 dense 模块中层的个数不同,层的个数要满足特定的计算成本。
我们的模型用 PyTorch训练,batch size为256,训练了120个 epochs。我们基本遵循了ResNet在ILSVRC 2012上的训练设定和超参数。下表显示不同网络设计选择对于性能的影响。可以看到,在结合了所有的这些选项后,PeleeNet在Stanford Dogs数据集上的准确率为79.25%79.25\%79.25%,和DenseNet-41相比要超过4.23%4.23\%4.23%,而且消耗的计算资源更少。
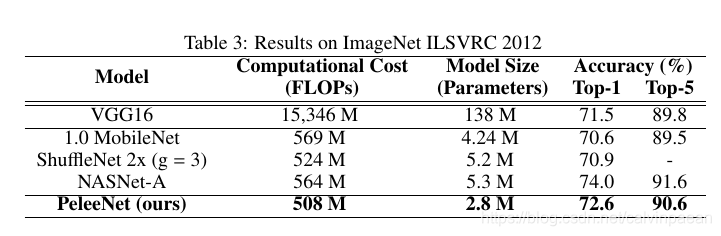
2.3 ImageNet ILSVRC 2012上的结果
PeleeNet在PyTorch上训练,用了2张GPU,batch size为512。使用了Cosine学习率退火机制来训练模型。初始学习率设为0.25,总共的epochs为120。然后我们对它进行微调,学习率为5e-3,训练了20个epochs。其他的超参数设置和Stanford Dogs数据集一样。
Cosine学习率退火就是学习率以cosine的形式衰减(epochttt(t≤120t\leq 120t≤120)的学习率设为0.5×lr×(cos(π×t/120)+1)0.5\times lr\times (cos(\pi\times t/120)+1)0.5×lr×(cos(π×t/120)+1))。
如下表所示,PeleeNet相较于MobileNet和ShuffleNet取得了更高的准确率,而模型大小只是它的66%66\%66%,计算成本更低。PeleeNet的模型大小只是VGG16的1/491/491/49。
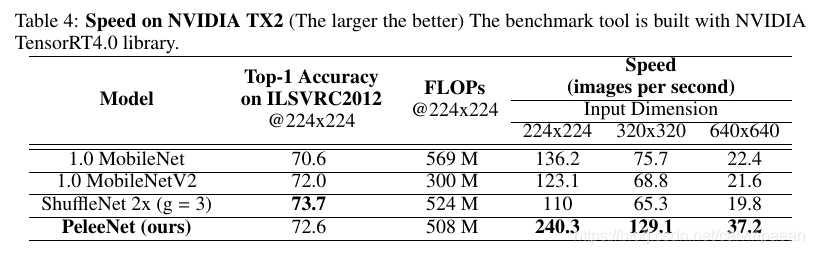
2.4 Speed on Real Devices
统计FLOPs(乘-加运算的数量)是衡量计算量的普遍方法。但是考虑到许多其他可能影响到真实计算成本的因素(I/O, 缓存,硬件优化等),它无法代替真实设备上的速度测试。这一节将在英伟达TX2嵌入式平台上测试模型性能。速度是通过一个batch中的100张图像的平均处理时间来计算。我们将100张图片分别跑10次,然后计算平均时间。
如下表可见,在TX2上,PeleeNet要比MobileNet和MobileNet V2快得多。虽然MobileNet V2只需要300M的FLOPs,但是569M FLOPs的MobileNet在实际速度上反而要更快一些。
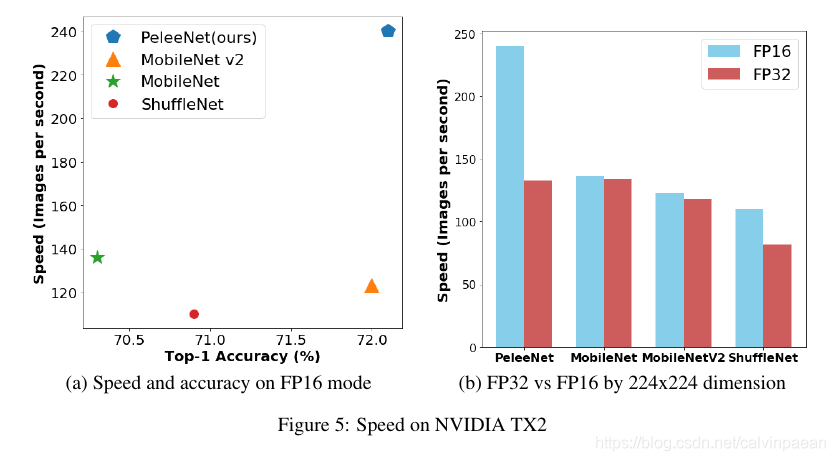
人们为了加快推理速度,普遍使用半精度浮点(FP16)代替单精度浮点(FP32)。如下图所示,PeleeNet在FP16情况下要比FP32情况下快1.8倍。通过深度可分离卷积构建的网络在TX2半浮点推理引擎上并没有快多少。在FP16模式中,MobileNet和MobileNet v2运行速度几乎和FP32模式一样。
在iPhone8上,对于较小的输入维度,PeleeNet的速度要比MobileNet快,而对于较大的输入维度,PeleeNet的速度要比MobileNet慢。这种现象发生有两个原因。首先和CoreML相关,它是基于Apple Metal API而来。Metal是一个3D图形API,并不是为CNN设计来的。它只能处理四通道的数据(原来是为用于处理RGBA数据)。高等级API不得不将每4个通道分割为1个slice,将结果缓存在每个slice里。和传统卷积相比,可分离卷积从这个机制中能获得更多的好处。第二个原因就是,PeleeNet的结构。PeleeNet的形状是多分支、窄通道,有113个卷积层。我们原来的设计受到了FLOPs的误导,引入了不必要的复杂度。

3. Pelee: A Real-Time Object Detection System
3.1 Overview
这一节介绍我们的目标检测系统,以及对SSD的优化。优化的主要目的就是提升检测速度,并且保证准确率可以接受。除了上一节提到的高效率特征提取网络,我们也构建了目标检测网络,它和原来的SSD不同,我们精心选择了5个尺度的特征图。同时,对于每个特征图,我们在预测之前都加了一个残差模块,如图4所示。我们也使用了小型的卷积核来预测物体的类别和边框位置,降低计算成本。此外,我们使用了不一样的训练超参数。尽管这些做法单独地看上去都不大,但我们发现最终的检测系统在PASCAL VOC2007上取得了70.9%70.9\%70.9%的mAP,在 MS COCO 上取得了22.4%22.4\%22.4%的mAP。在COCO上的结果超过了YOLOv2很多,但是计算成本降低了13.6倍,模型大小降低了11.3倍。
在我们的检测系统中有5个尺度的特征图:19×19,10×10,5×5,3×3,1×119\times 19, 10\times 10, 5\times 5, 3\times 3, 1\times 119×19,10×10,5×5,3×3,1×1。我们没有用38×3838\times 3838×38的特征图层,为了保证速度和准确率之间的平衡。我们将19×1919\times 1919×19特征图和2个不同尺度的默认边框结合起来,将其它4个特征图中的每一个和默认边框的一个尺度结合。Huang et al将MobileNet和SSD结合起来用的时候,也没有使用38×3838\times 3838×38特征图。但是,他们增加了一个2×22\times 22×2特征图,保证有6个尺度的特征图用于预测,这和我们的方案不同。

3.2 VOC2007上的结果
我们的目标检测系统基于SSD的源码而来,用Caffe进行了训练。Batch size设为32,初始学习率设为0.005,然后在8万和10万次iterations时除以10。总共训练了12万次iterations。
3.2.1 多种设计选择的影响
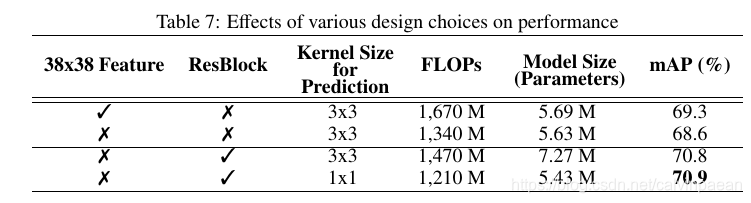
下表展示了不同设计选择对性能的影响。我们可以看到,残差预测模块能有效地提升准确率。包含残差预测模块的模型和没有残差预测模块的模型相比,准确率要高2.2%2.2\%2.2%。使用1×11\times 11×1卷积核的模型的准确率几乎和3×33\times 33×3卷积核的模型一样。但是,1×11\times 11×1卷积核的计算量要比3×33\times 33×3卷积核低21.5%21.5\%21.5%,模型要小33.9%33.9\%33.9%。
3.2.2 与其他模型相比较
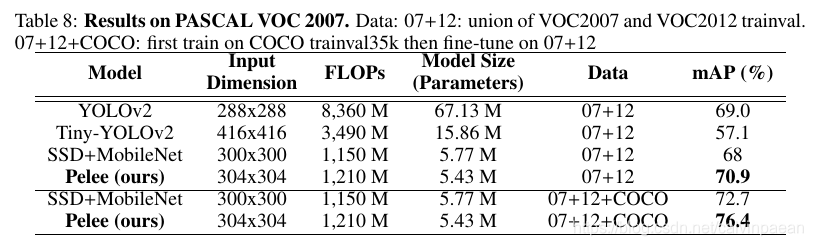
如下表所示,Pelee的准确率要比Tiny YOLOv2高13.8%13.8\%13.8%,要比SSD+MobileNet高2.9%2.9\%2.9%。它甚至要比YOLOv2-228都高,而计算成本只是它的14.5%14.5\%14.5%。当我们将该模型在 COCO trainval35K上训练,然后在VOC 07+12数据集上微调后,Pelee取得了76.4%76.4\%76.4%的mAP。
3.2.3 Speed on Real Devices
我们然后在真实设备上进行了推理测试。利用 benchmark工具,我们计算100张图片的平均处理时间。这个时间包括图像的预处理时间,但是它不包括后处理时间(解码边框和NMS操作)。通常,后处理操作可以在CPU异步进行,而其它操作在GPU上执行。因此,实际速度应该是非常接近我们的测试结果的。

3.3 COCO上的结果
我们在COCO数据集上进一步验证了Pelee。模型通过COCO train+val数据集训练而来,在 test-dev2015数据集上测试。Batch size设为128。在前7万次迭代时,学习率设为10−210^{-2}10−2,随后的10万次学习率设为10−310^{-3}10−3,最后的20万次学习率设为10−410^{-4}10−4。
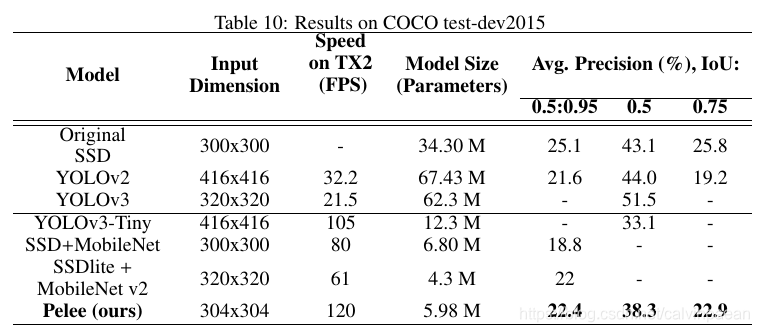
下表展示了 test-dev2015的测试结果。在mAP@[0.5:0.95]@[0.5:0.95]@[0.5:0.95]和mAP@0.75@0.75@0.75,Pelee不仅比SSD+MobileNet更准确,而且要比YOLOv2更准确。同时,和YOLOv2相比,Pelee的速度要快3.7倍,模型要小11.3倍。

















 8798
8798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









