







经过各种维度的横向评估,最终我们选择了 RAGFlow 作为我们企业知识库的方案。从 Dify、MaxKB、FastGPT、QAnything 等竞品中,我们为什么选择了 RAGFlow?
-
Quality in, quality out:我们支持官方提出的「Quality in, quality out」理念,我们技术和产品团队是做埋点出身的,深刻的了解到数据源的质量对后续的数据分析以及运营带来的深刻影响。数据源质量堪忧会带来后续数据维护极大的成本,比如标注、打标签、校准之类的人力成本。RAGFlow 在文档解析层面横向来看是最好的,也许有同学会提出完全可以用三方 API 来实现该效果,我们得考虑另一个问题,大多数企业知识库应用场景一定是本地化私有的,在纯离线场景下,RAGFlow 文档解析我们实测过比其他开源模型好很多。
-
开放性:一款开源产品一定是无法直接应用到生产环境,所以不可避免的我们需要基于 RAGFlow 进行二开,此时源码的开发性至关重要。这里的开放性有两个层面:源码开放协议以及 Open API 设计。
-
-
截止目前为止 RAGFlow 仍然是 Apache-2.0 license ,相关于其他竞品不同程度的限制,RAGFlow 表现的相当开放,在这里再次感谢 RAGFlow 官方的开源精神。
-
Open API ,RAGFlow 提供了相对完整的对外 API ,基于这些 API ,二开的难度极大的降低且具备极大的灵活性
-
那么,RAGFlow 要真正的落地到企业应用,产品功能层面还缺少哪些?这些天我们深入的和不同行业意见领袖做了深入交流,收获满满,我们将从真正企业应用视角来看,一款成熟的企业知识库产品该具备的能力。
企业级知识库管理核心功能
我们先参考下 FastGPT 商业版本功能:
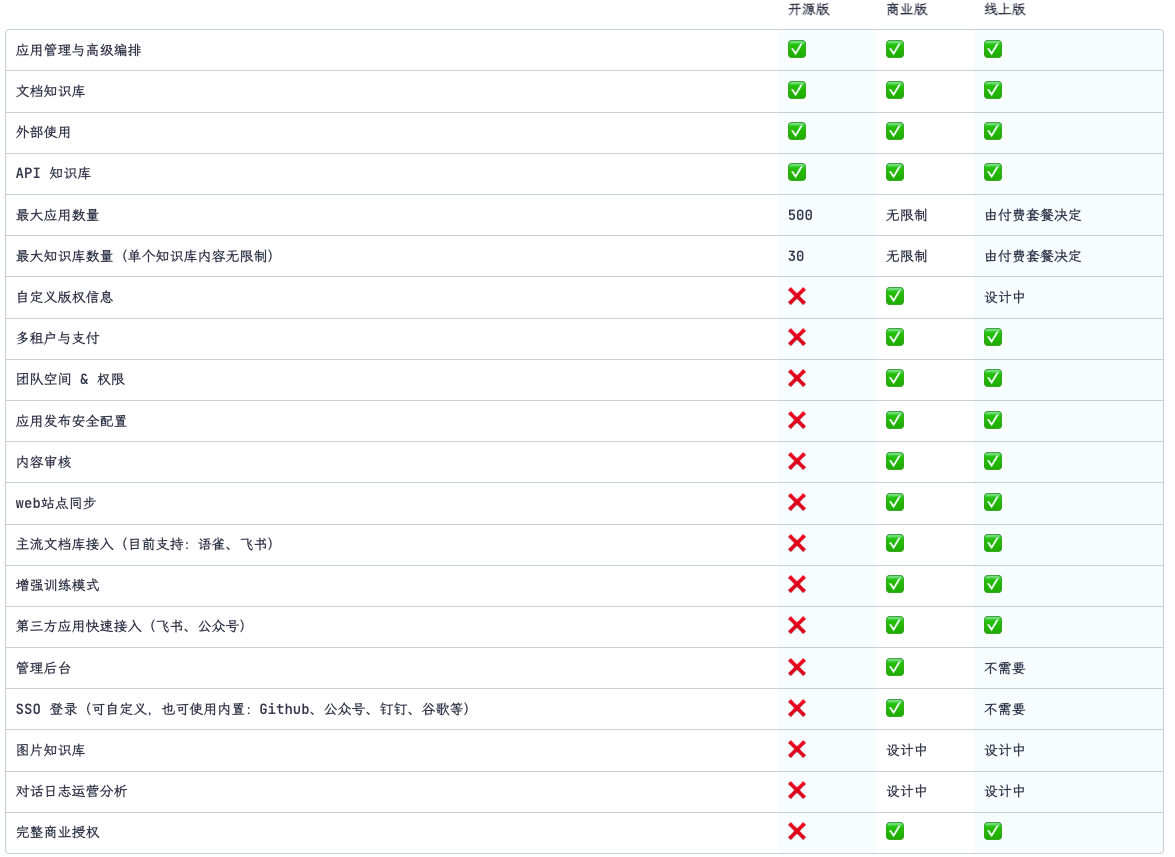
可以看到商业版本核心的功能点:
-
团队空间和权限管理
-
Web 站点同步
-
主流文档库接入
-
三方应用接入
-
SSO 登录
QAnything 企业版本功能:
-
高质量的文档解析:支持doc、ppt、xls更多文档格式的解析,针对docx、pptx、pdf做特别优化,支持准确的解析其中的表格和图片,且解析后多级标题的层级结构完整。
-
更优的语义切分模型:提供最优的文本切分模型,按照层级标题及语义进行切分,自动处理导入的各种类型的数据,确保每个切片均包含完整的语义单元。
-
更精准的问答:语义检索加混合检索,搜索召回率和命中率高。回答组织能力显著提升,能够清晰展示答案所依据的引用来源,答案支持带图片和表格。
相对于基础版本,QAnything 企业版本聚焦于提升回答精准度,从文档解析、文本切分、回答图文混排进一步提升回答准确率。

我们调研了国内外企业知识库产品,总结了一下功能:
| 分类 | 核心功能 | 描述 |
| 数据接入与管理 | 多数据源接入 | 支持数据库、文档、API、网页爬取等多种数据源 |
| 数据预处理与清洗 | OCR、格式转换、去重、标准化等 | |
| 权限控制 | 基于角色(RBAC)和用户(ABAC)的访问管理 | |
| 版本管理 | 知识库内容的版本迭代、变更记录和回滚 | |
| 向量索引与检索 | 高效向量化存储 | 基于 FAISS、Milvus、Weaviate、PGVector 实现索引 |
| 混合检索(Hybrid Search) | 结合关键词(BM25)、语义搜索、知识图谱等 | |
| 检索增强(RAG+) | 可配置不同检索策略,如文本段落、实体关系等 | |
| 在线增量更新 | 支持知识库实时或定期自动更新索引 | |
| 生成增强(RAG)与问答能力 | 上下文增强 | 支持 CoT(Chain of Thought)、ToT(Tree of Thought) |
| 多模态支持 | 支持文本、图片、音频等输入类型 | |
| 工具调用(Tool Use) | 结合 API(如 SQL、ERP、CRM)实现行动能力 | |
| 多轮对话记忆 | 结合 RAG 进行更精准的问答 | |
| 可插拔 LLM 引擎 | 支持 OpenAI、Claude、Gemini、本地 Llama、Mistral | |
| 知识增强与结构化输出 | 知识图谱(Knowledge Graph) | 构建企业内部知识图谱,提高问答准确性 |
| 结构化输出(Structured Output) | 支持 JSON、表格、代码生成 | |
| 自定义 Prompt 模板 | 支持 RAG 查询的 Prompt 预设、调整、AB 测试 | |
| 摘要与报告生成 | 生成结构化摘要、结论、行动建议等 | |
| 监控与优化 | 查询日志与可视化分析 | 统计用户查询、热点问题、知识库覆盖率 |
| 反馈机制 | 支持人工审核、点赞/踩、主动补充知识 | |
| 模型微调与知识库优化 | 提供 LoRA / SFT 进行企业私有微调 | |
| 多租户管理 | 支持 SaaS 部署下的独立知识库 | |
| 部署与集成 | 本地化部署 | 支持私有化部署,保障数据安全 |
| API 与 SDK 支持 | 提供 RESTful API、Python/JavaScript SDK | |
| 插件生态 | 支持 Notion、Slack、企业微信、飞书等集成 | |
| LLM 代理(Agent)扩展 | 可与 AutoGPT、LangChain、LlamaIndex 结合 |
距离企业商用 RAGFlow 产品还缺哪些
集合竞品以及国内外 RAG 产品调研情况,以我们目前企业级 RAG 知识库和智能助手产品的认知,我们认为 RAGFlow 需要在现有产品能力基础上,做以下产品能力补充。
用户权限管理
参考 RBAC(基于角色访问控制) 和 ABAC(基于属性访问控制) 的行业标准设计方式。
-
用户角色
-
权限规则
| 功能 | 管理员 | 普通用户 |
| 用户管理 | ✅ 创建/删除用户,分配角色 | ❌ |
| 团队管理 | ✅ 创建/删除团队,邀请成员 | ❌ |
| 知识库管理 | ✅ 创建/删除知识库,授权访问 | ❌ |
| 知识库访问 | ✅ 访问所有知识库 | ✅ 仅能访问被授权知识库 |
| API 使用 | ✅ 可调用 RAG API | ✅ 可调用 RAG API(受权限限制) |
-
业务逻辑
-
管理员 可以管理用户、团队、知识库和 API 权限。
-
普通用户 只能使用知识库,不可修改权限或管理团队。
-
团队成员继承团队权限,即用户加入团队后,会自动获得该团队的知识库访问权限。
-
产品原型设计重构
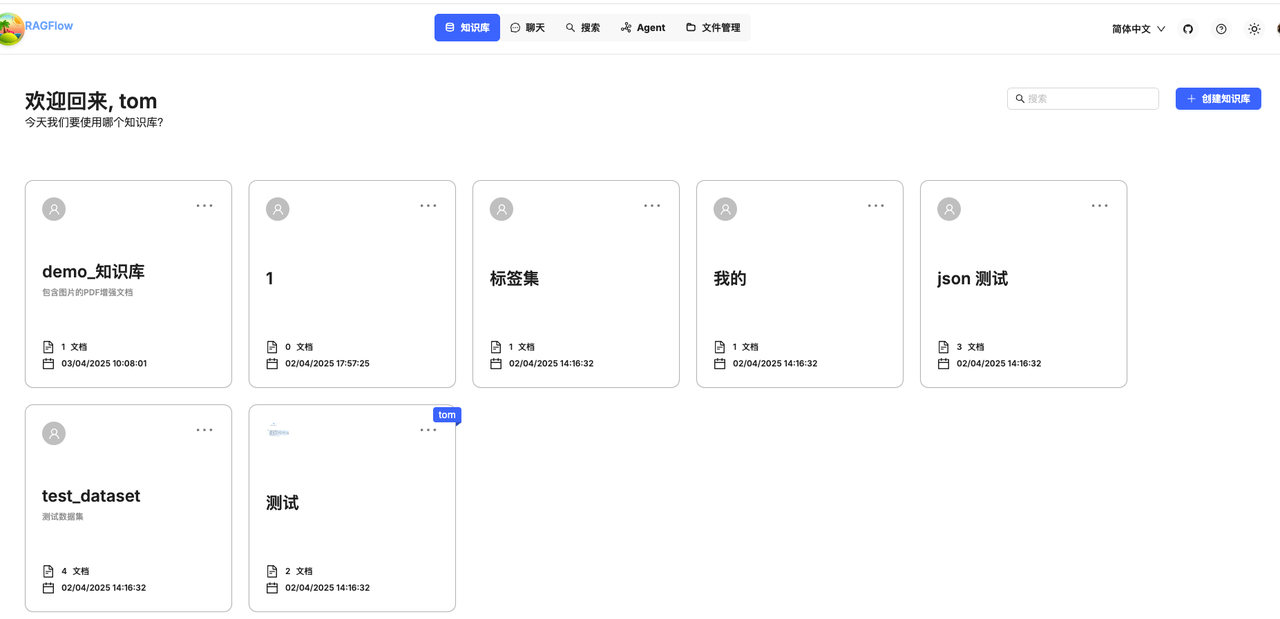
了解 RAGFlow 的同学可能也知道,目前 RAGFlow 的产品体验比较简陋,无论是核心的聊天主页面还是知识库页面都比较难以下咽。在 RAGFlow 交流社区内提过不少想换一个 UI 界面的需求,有的想接入三方 Open UI 或者 Dify ,我们的结论是重构整个 UI 设计:基于 RAGFlow API 能力,我们在现有服务基础上,改写所有页面设计。
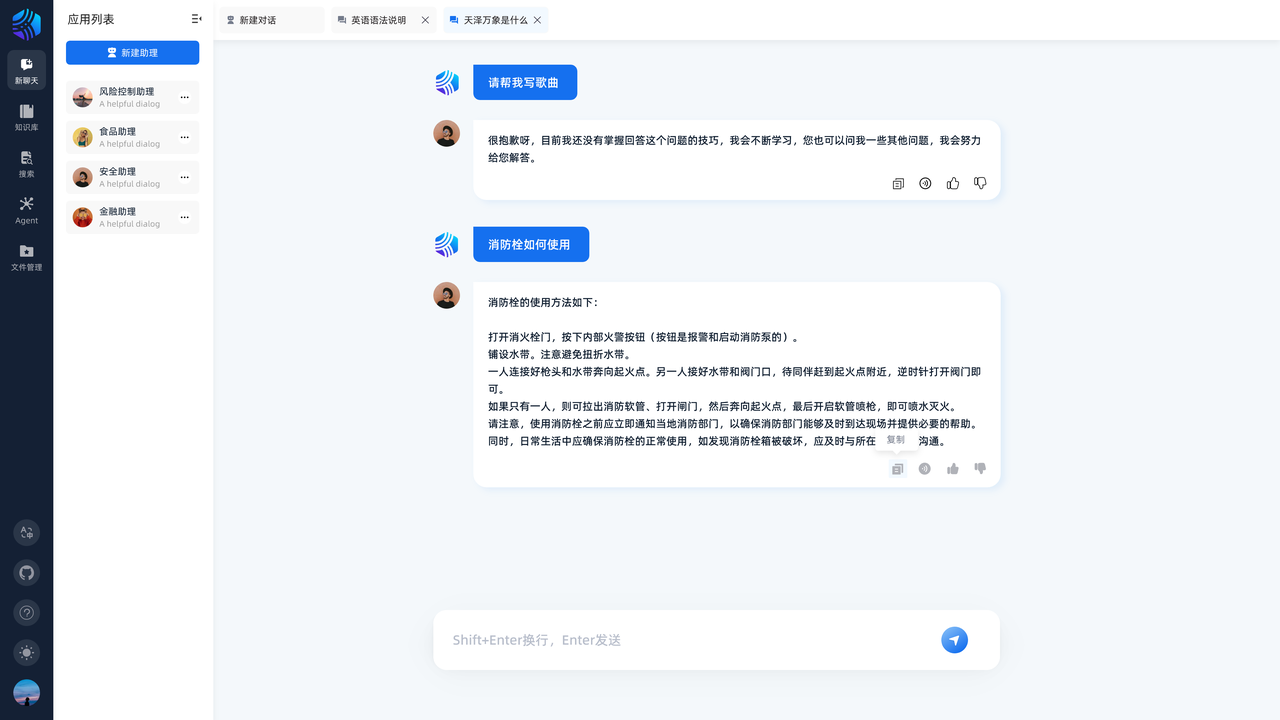
同时增强结构化输出能力,如回答中支持图文混排、代码、表格等格式。
行业化解决方案最佳实践
现 RAGFlow 从产品体验上来说,问题回答速度较慢,配置项较多,如何平衡回答精准度以及速度,是一个系统性问题。我们基于实际客户行业化落地产品交付经验,提供了将近 50+ 参数配置优化解决方案,针对不同的行业进行体系化优化。比如是通义千问大模型好还是 DeepSeek 更合适?比如是本地模型需要 DeepSeek 32B 蒸馏版还是满血版本?比如分块固定多大比较合适等等。
我们判断未来行业化的解决方案不断沉淀是 RAG 应用服务商的核心竞争壁垒,这里不仅是技术产品的不断演进,同样是解决方案在行业化里的不断深化,这样才能真正的将知识库管理变得更智能、更高效。
总结
2024 年有一个业界争论不休的议题:在大模型越来越聪明、上下文长度越来越长的趋势下,RAG 是不是要退出历史舞台?我的回答是恰恰相反:RAG 反而可能会随着技术的进步进一步演化,甚至在某些场景下变得更加重要。因为 RAG 有一些天然的特性是可以和大模型相辅相成的,如知识的时效性、减少计算和存储成本、知识安全可控。未来的趋势可能是 超长上下文 和 智能检索 双管齐下,以应对不同应用场景的需求,真正的给企业降本增效,进入 AI 时代。
最后介绍下我们团队 KnowFlow:基于 RAGFlow 的专注于私有化部署的企业知识库服务商。欢迎关注公众号:「KnowFlow 企业知识库」,一起探索企业知识库的未来。

















 8679
8679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









