






ISBNet:

目前scannet数据集三维实例分割第一
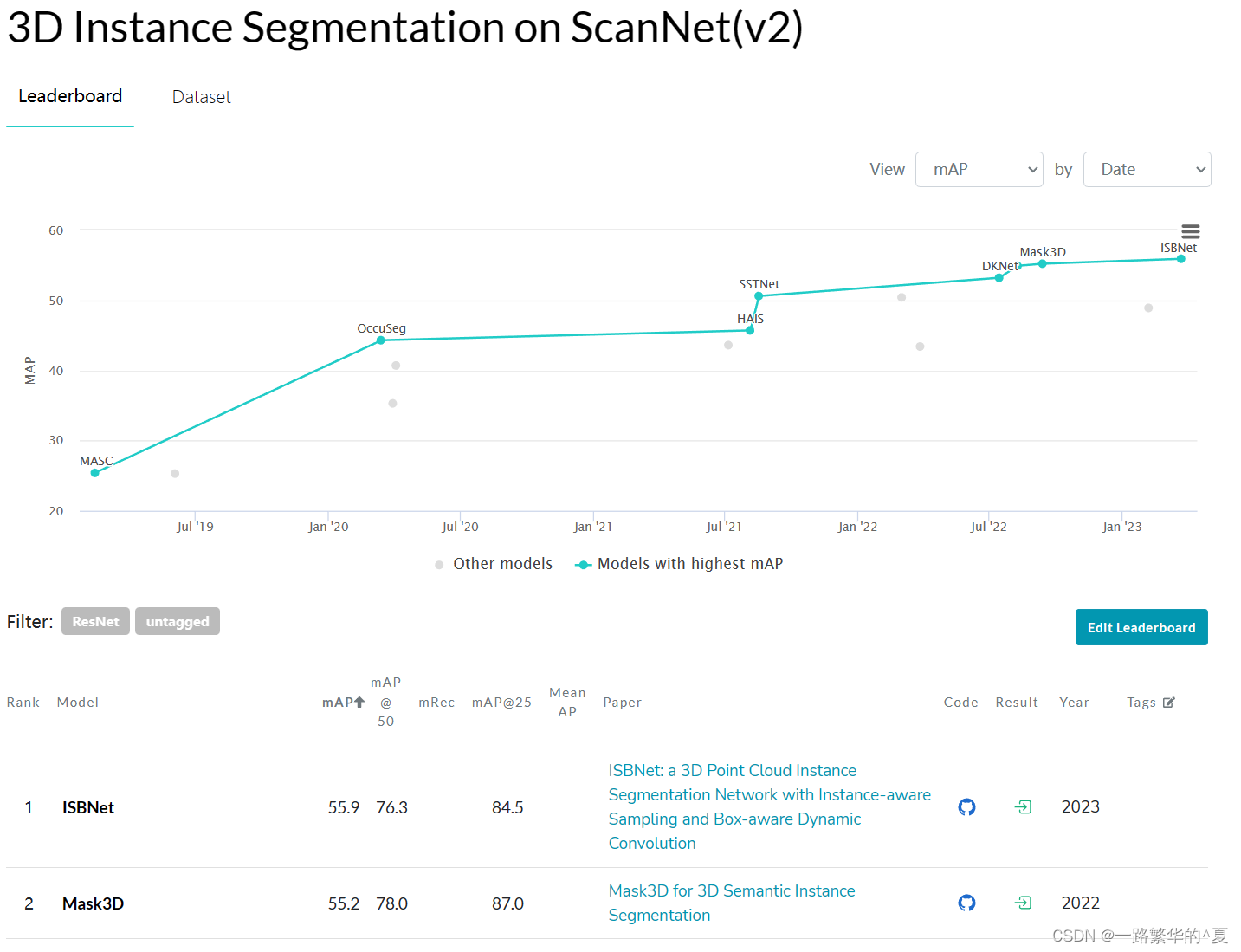
这里有一个疑虑就是语义分割的做法如果转移到实例分割会导致的结果和区别需要回头去理解一下
三个贡献,创新点:
1,isbnet的网络无集群范式,利用实例感知的最远距离采样(IA-FPS)和聚合器(aggregation)生成特征
2,提出box-aware动态卷积来解码二进制掩码
3,取得最佳性能
上面是与其他网路进行对比
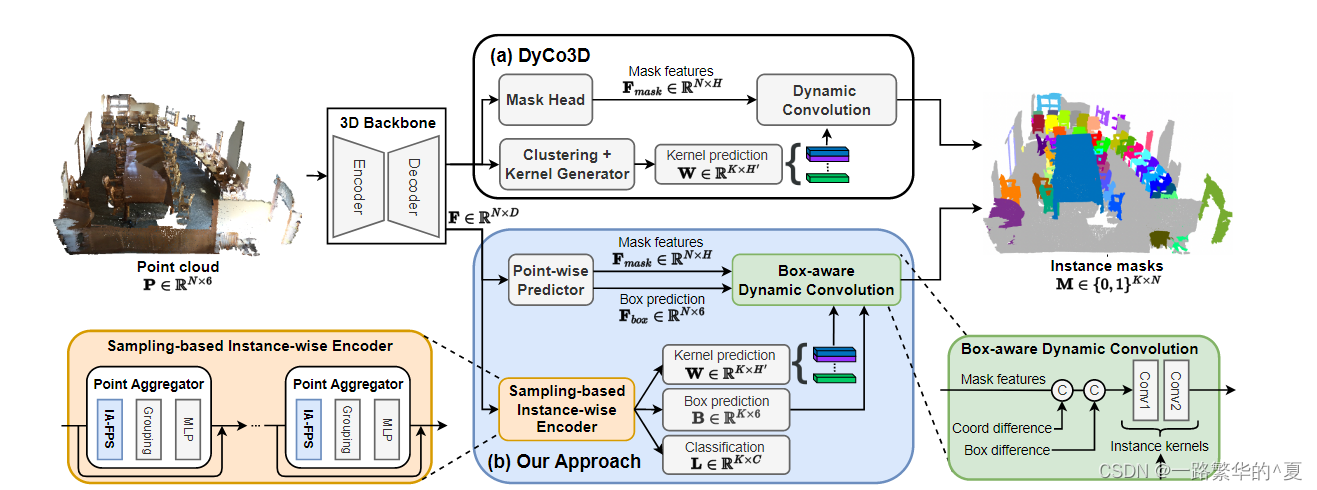
Instance-aware FPS:
关于实例感知召回率跟原先的FPS相比,以及聚类的召回率
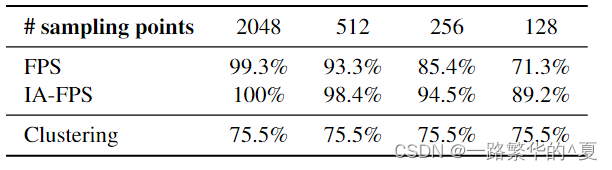
这样做的原因有三:
1,FPS对K个采样候选中属于背景的类别会比较多
2,大对象往往占据主要计算资源
3,逐点特征无法捕捉上线文来创建实例内核
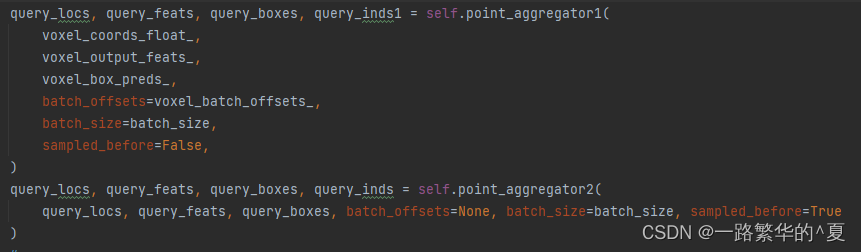
受pointnet++启发指定我们的实例编码器,其中包含一系列点聚合器(PA)块,其组件是实例感知FPS (IA-FPS),以采样覆盖尽可能多的前景对象的候选点,以及一个局部聚合层来捕获局部上下文。
大于背景过滤的阈值才进行处理的实例感知(0.1)
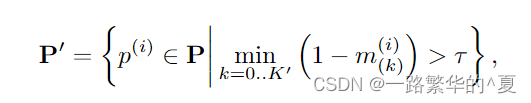

Local Aggregation Layer:
使用局部聚合对局部上下文进行编码转换为实例特征
采用球查询搜集局部Q个点,计算相对坐标并用邻域半径进行归一化形成局部坐标,之后通过MLP将实例特征与局部坐标转换为实例特征,添加一个残差连接防止梯度消失。为了获得实例特征 E,我们不是使用单个 PA 块,而是提出了一种渐进式方式,依次应用多个 PA 块,以增加感受野。
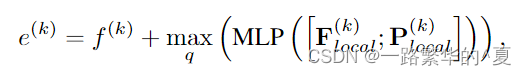
Box-aware Dynamic Convolution:
认为只使用掩码特征以及位置是次优的,当只使用3D中的掩码特征和位置时,类相同的边界附近的点彼此无法区分。
另一方面通过3D边界框描绘了对象的形状和大小,为实例分割的预测提供了重要几何线索,因此使用边界框预测来作为正则化实例分割的辅助任务
如果两个点的预测框相似,则它们将属于同一个对象。

几何特征 F(k)geo ∈ RN ×6 可以从第 k 个实例候选者预测的边界框的绝对差和输入点云中的 N 个点计算
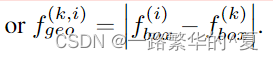
loss:
采用逐点损失和实例损失。
逐点损失发生在逐点预测,是语义分割的交叉熵损失,用于边界框回归的L1损失和GioU损失。
实例损失用于预测产生,分类,边界框预测和掩码预测,Cmask是两个掩码之间的dice损失
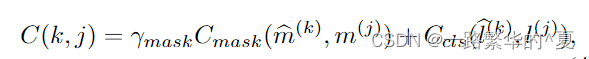
实例损失是ground-truth掩码及其匹配的预测掩码之间的损失,定义如下:
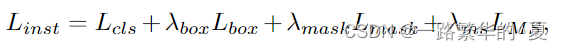
其中Lcls是交叉熵损失,Lmask是dice损失和BCE损失的组合,Lbox是L1损失和gIoU损失的组合,LMS是Mask-Scoring损失
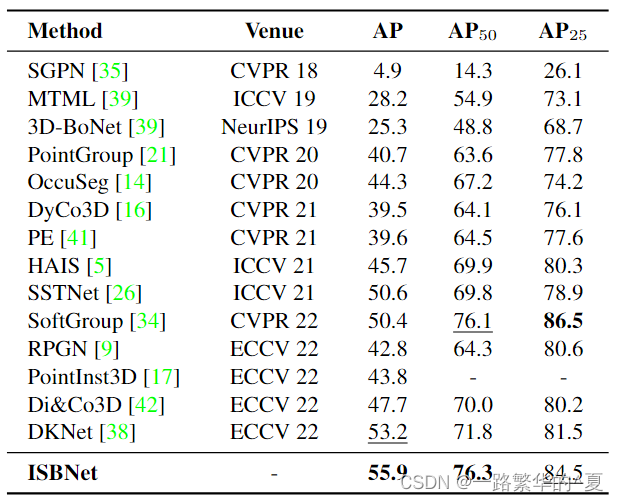
main results:
在ScannetV2三维实例分割方面优于其他网络
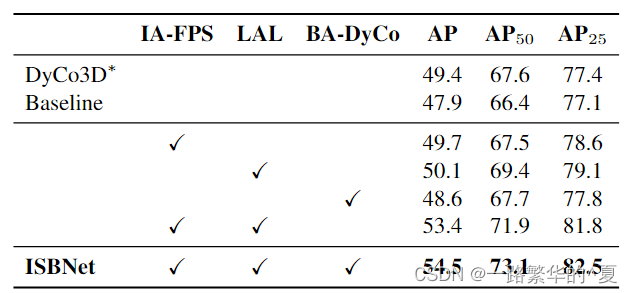
以及消融实验结果
结论,待优化部分:
实例感知 FPS 不能保证覆盖所有实例,因为它依赖于当前实例预测来为点采样做出决策。提出的轴对齐边界框可能不太适合复杂实例的形状。通过利用对象的几何结构(例如它们的形状和大小)来改进动态卷积的新研究将是一个有趣的研究课题。
当前文档37条主题 共913字

















 151
151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









