








Deep Learning Based 3D Segmentation: A Survey

4. 3D Instance Segmentation
三维实例分割方法还能区分同一类别的不同实例。由于三维实例分割是一项对场景理解更有参考价值的任务,因此越来越受到研究界的关注。三维实例分割方法大致分为两个方向:proposal-based和proposal-free。
4.1. Proposal Based
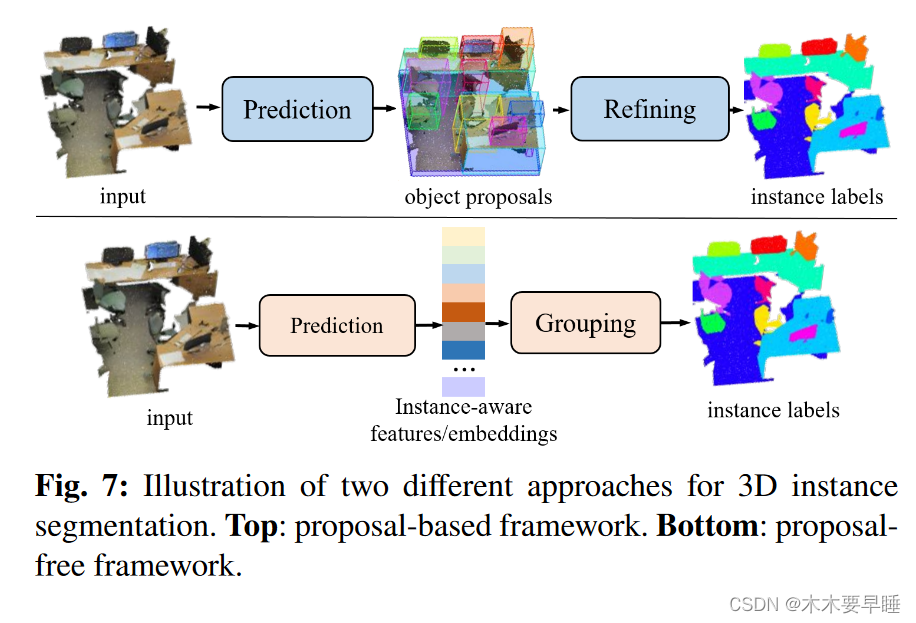
基于提议的方法首先预测对象提议,然后对其进行完善,生成最终的实例掩码(见图 7),从而将任务分解为两大挑战。因此,从建议生成的角度来看,这些方法可分为基于检测的方法和无检测方法。
基于检测的方法有时会将物体建议定义为三维边界框回归问题。3D-SIS Hou、Dai 和 Nießner(2019)根据三维重建的姿势对齐,将高分辨率 RGB 图像与体素结合,并通过三维检测骨干共同学习颜色和几何特征,以预测三维边界框提议。在这些建议中,三维掩码骨干网会预测最终的实例掩码。类似地,GPSN Yi、Zhao、Wang、Sung 和 Guibas(2019)介绍了一种称为生成形状建议网络(Generative Shape Proposal Network,GPSN)的三维物体建议网络,该网络从形状噪声观测中重建物体形状,以加强几何理解。GPSN 进一步嵌入到名为基于区域的点网络(R-PointNet)的三维实例分割网络中,以拒绝、接收和完善建议。这些网络的训练需要逐步进行,而对象建议的完善需要昂贵的抑制操作。为此,Yang 等人(Yang, Wang, Clark, Hu, Wang, Markham and Trigoni,2019 年)引入了一种名为 3D-BoNet 的新型端到端网络,可以直接学习固定数量的三维边界框,而无需进行任何剔除,然后在每个边界框中估计实例掩码。
免检测方法包括 SGPN Wang、Yu、Huang 和 Neumann(2018d),它假定属于同一对象实例的点应该具有非常相似的特征。因此,它通过学习相似性矩阵来预测建议。通过点的置信度得分对提议进行剪枝,以生成可信度高的实例提议。然而,这种简单的距离相似度量学习信息量不大,无法分割同一类别的相邻物体。为此,3D-MPA Engelmann、Bokeloh、Fathi、Leibe 和 Nießner(2020a)从对同一对象中心进行投票的采样和分组点特征中学习对象建议,然后使用图卷积网络整合建议特征,实现建议之间更高层次的交互,从而提炼出建议特征。AS-Net Jiang、Yan、Cai、Zheng 和 Xiao(2020a)使用分配模块分配候选提案,然后通过抑制网络消除多余的候选提案。SoftGroup Vu、Kim、Luu、Nguyen 和 Yoo(2022)提出了自上而下细化实例提案的方法。SSTNet Liang、Li、Xu、Tan 和 Jia(2021 年)提出了一种端到端的语义超点树网络(SSTNet)解决方案,用于从场景点生成对象实例建议。SSTNet 的一个关键贡献是基于学习到的超级点语义特征构建了一棵中间语义超级点树(SST)。在中间节点对该树进行遍历和拆分,以生成对象实例建议。
4.2. Proposal Free
无提案方法为每个点学习特征嵌入,然后应用聚类来获得明确的三维实例标签(见图 7),将任务分解为两大挑战。从嵌入学习的角度来看,这些方法可大致分为四类:基于二维嵌入的多任务学习、基于聚类的多任务学习和基于动态卷积的多任务学习。
基于二维嵌入:这些方法中的一个例子是 3D-BEVIS Elich、Engelmann、Kontogianni 和 Leibe (2019),它通过鸟瞰整个场景来学习二维全局实例嵌入。然后,它通过 DGCNN Wang 等人(2019b)将学习到的嵌入传播到点云上。另一个例子是 PanopticFusion Narita、Seno、Ishikawa 和 Kaji(2019),它通过二维实例分割网络 Mask R-CNN He、Gkioxari、Dollár 和 Girshick(2017a)预测 RGB 帧的像素实例标签,并将学习到的标签整合到三维卷中。
多任务学习:三维语义分割和三维实例分割会相互影响。例如,不同类别的物体必须是不同的实例,而具有相同实例标签的物体必须是相同的类别。基于此,ASIS Wang、Liu、Shen、Shen 和 Jia(2019a)设计了一个编码器-解码器网络,称为 ASIS,用于学习语义感知的实例嵌入,以提升这两项任务的性能。同样,JSIS3D Pham、Nguyen、Hua、Roig 和 Yeung(2019b)使用一个统一的网络,即 MT-PNet 来预测点的语义标签,并将点嵌入到高维特征向量中,还进一步提出了一个 MV-CRF 来联合优化对象类和实例标签。类似的还有Liu等人的Liu和Furukawa(2019)以及3D-GEL Liang、Yang和Wang(2019b)采用SSCN同时生成语义预测和实例嵌入,然后使用两个GCN细化实例标签。OccuSeg Han、Zheng、Xu 和 Fang(2020)使用多任务学习网络生成占用信号和空间嵌入。占据信号表示每个体素占据的体素数量。
基于聚类:MASC Liu和Furukawa(2019)等方法依赖于SSCN的高性能,Graham等人(2018)在多个尺度和语义拓扑上预测相邻点之间的相似性嵌入。Liu、Yang、Li、Zhou、Xu、Li 和 Lu(2018c)采用了一种简单而有效的聚类方法,根据学习到的两类嵌入将点分割成实例。MTML Lahoud、Ghanem、Pollefeys 和 Oswald(2019)学习了两组特征嵌入,包括每个实例独有的特征嵌入和实例中心定向的方向嵌入,这提供了更强的分组力。同样,PointGroup Jiang、Zhao、Shi、Liu、Fu 和 Jia(2020b)根据原始坐标嵌入空间和移动坐标嵌入空间将点分成不同的群组。此外,提出的 ScoreNet 还能指导正确的聚类选择。上述方法通常根据点级嵌入对点进行分组,而不进行实例级修正。HAIS Chen、Fang、Zhang、Liu 和 Wang(2021 年)引入了集合聚合和实例内预测,在对象级别上对实例进行细化。
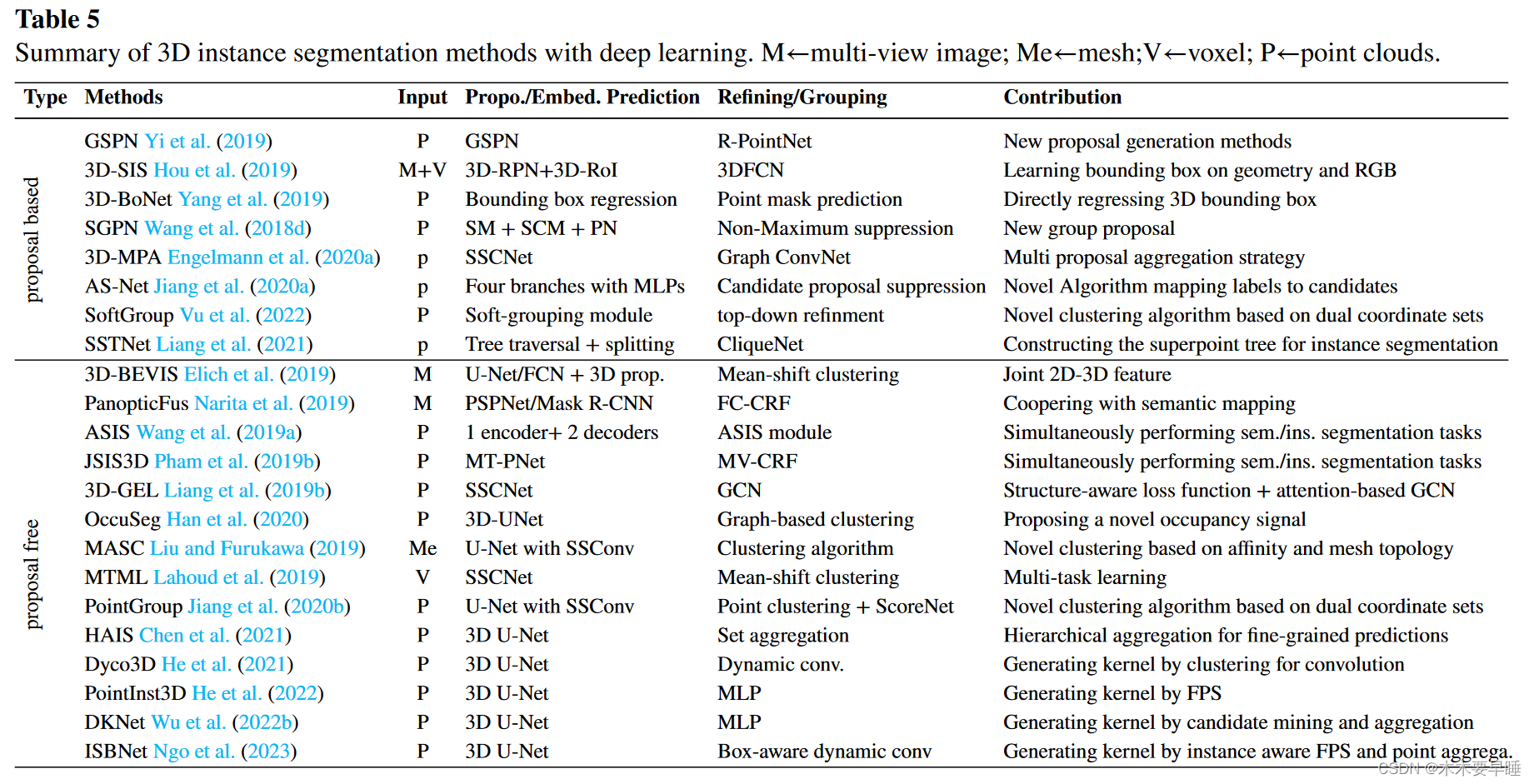
基于动态卷积:这些方法通过生成内核,然后利用内核与点特征卷积生成实例掩码,从而克服了基于聚类的方法的局限性。Dyco3D He、Shen 和 Van Den Hengel(2021 年)采用聚类算法生成卷积核。同样,PointInst3D He、Yin、Shen 和 van den Hengel(2022)使用 FPS 生成内核。DKNet Wu、Shi、Du、Lu、Cao 和 Zhong(2022b)引入了候选挖掘和候选聚合来生成更多实例内核。此外,ISBNet Ngo、Hua 和 Nguyen(2023 年)提出了一种新的实例编码器,将实例感知 PFS 与点聚合层结合起来生成内核,以取代 DyCo3D 中的聚类。表 5 总结了三维实例分割方法。
5. 3D Part Segmentation
三维部件分割是继实例分割之后的又一个更精细的层次,其目的是对实例的不同部分进行标注。部件分割的流程与语义分割的流程十分相似,只是现在的标签是针对单个部件的。因此,现有的一些三维语义分割网络Li等人(2018b)、Wang等人(2019b)、Lei等人(2020)、Xie等人(2020b)、Wang等人(2018c)、Groh等人(2018)、Lei等人(2019)、Su等人(2018)、Rosu等人(2019)也可以进行部件分割训练。然而,这些网络并不能完全解决零件分割的难题。例如,具有相同语义标签的各种零件可能形状各异,而具有相同语义标签的实例的零件数量也可能不同。我们将三维零件分割方法分为两类:基于规则数据的方法和基于不规则数据的方法。
5.1. Regular Data Based
常规数据通常包括投影图像 Kalogerakis、Averkiou、Maji 和 Chaudhuri(2017 年),体素 Wang 和 Lu(2019 年),Le 和 Duan(2018 年),Song、Chen、Li 和 Zhao(2017 年)。至于投影图像,Kalogerakis 等人(2017 年)从多个视角获取一组最佳覆盖物体表面的图像,然后使用多视角全卷积网络(FCN)和基于表面的条件随机场(CRF)分别预测和完善部件标签。体素是一种有用的几何数据表示方式。然而,像零件分割这样的细粒度任务需要具有更详细结构信息的高分辨率体素,这就导致了高计算成本。Wang 等人和 Lu(2019)提出了 VoxSegNet,以利用有限分辨率体素的更多详细信息。他们利用空间密集提取技术在子采样过程中保留空间分辨率,并利用注意力特征聚合(AFA)模块自适应地选择尺度特征。Le et al. Le 和 Duan(2018 年)引入了一种名为 PointGrid 的新型 3D CNN,在每个单元中加入恒定数量的点,使网络能够更好地学习局部几何形状细节。此外,多模型融合还能提高分割性能。Song 等人(2017)结合图像和体素的优势,提出了一种称为 AppNet 和 GeoNet 的双流 FCN,用于从二维图像中探索二维外观和三维几何特征。其中,他们的 VolNet 从三维体积中提取三维几何特征,而 GeoNet 则从单幅图像中提取特征。
5.2. Irregular Data Based
不规则数据表示通常包括网格 Xu 等人(2017 年)、Hanocka 等人(2019 年)和点云 Li 等人(2018a)、Shen 等人(2018 年)、Yi 等人(2017 年)、Verma 等人(2018 年)、Wang 等人(2018b)、Yu 等人(2019 年)、Zhao 等人(2019b)、Yue、Wang、Tang 和 Chen(2022 年)。网格能有效地近似三维形状,因为它能捕捉到平面、尖锐和错综复杂的表面形状曲面和拓扑结构。Xu 等人(2017)将人脸法线和人脸距离直方图作为双流框架的输入,并使用 CRF 优化最终标签。受传统 CNN 的启发,Hanocka 等人(2019)设计了新颖的网格卷积和池化来对网格边缘进行操作。
对于点云,图卷积是最常用的管道。在光谱图领域,SyncSpecCNN Yi 等人(2017)引入了同步光谱 CNN 来处理不规则数据。特别是提出了多通道卷积和参数化扩张卷积核,以分别解决多尺度分析和跨形状信息共享问题。在空间图域,类比于图像的卷积核,KCNet Shen 等人(2018)提出了点集核及最近邻图,以高效的局部特征利用结构改进 PointNet。SpiderCNN Xu 等人(2018)应用了一种特殊的卷积滤波器系列,它将简单的阶跃函数与泰勒多项式相结合,使得滤波器能够有效捕捉错综复杂的局部几何变化。此外,FeastNet Verma 等人(2018)使用动态图卷积算子来建立过滤器权重与图邻域之间的关系,而不是依赖于上述网络的静态图。
树(如 Kd-tree 和 Octree)是一种特殊的图,可用于具有不同表示方法的三维图形,并可支持各种 CNN 架构。Kd-Net Klokov 和 Lempitsky(2017 年)使用 Kd 树数据结构来表示点云连接性。然而,该网络的计算成本较高。O-CNN Wang 等人(2017)根据三维形状设计了一种八叉树数据结构。然而,O-CNN 的计算成本随着树的深度增加而呈二次增长。
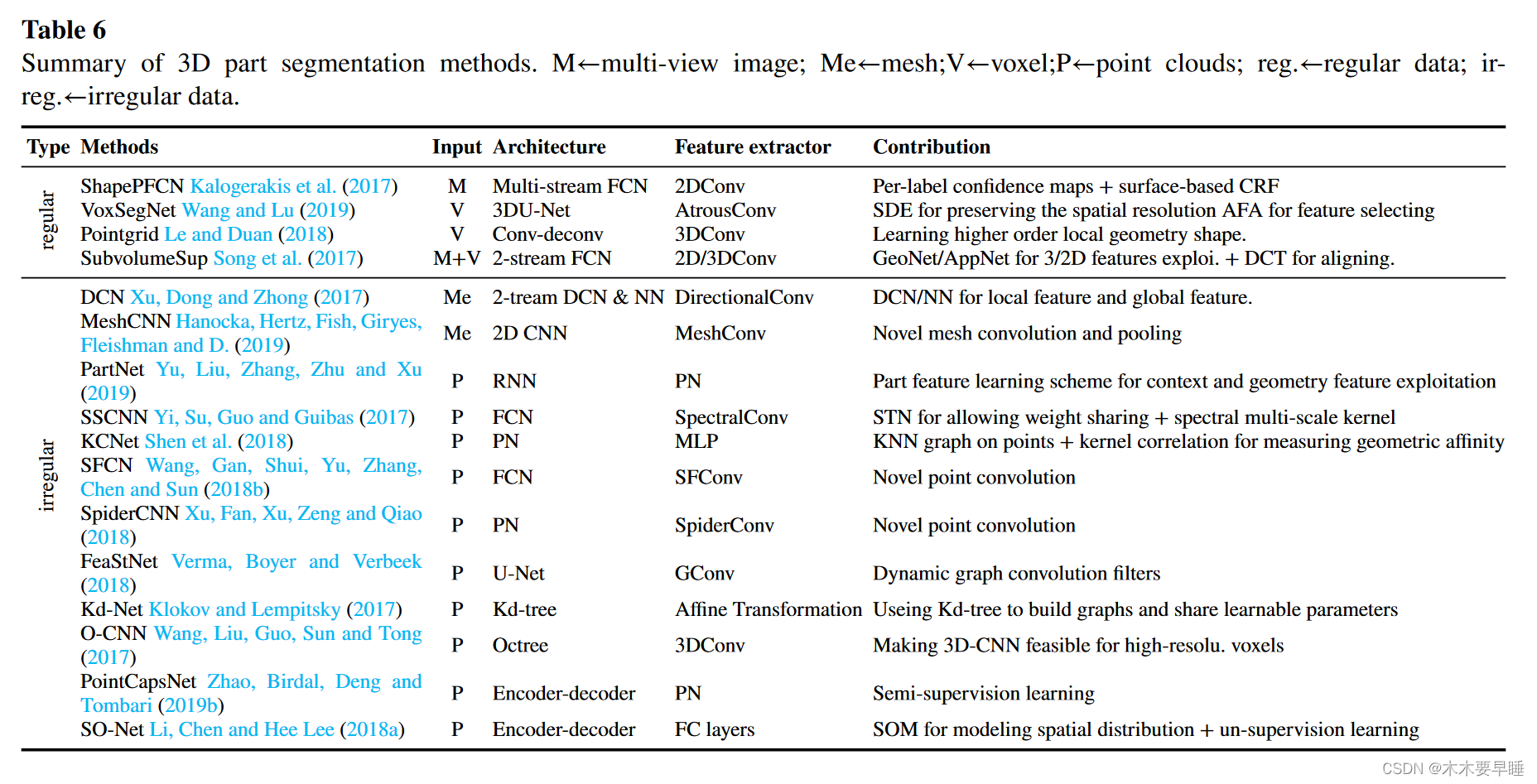
SO-Net Li 等人(2018a)根据点云建立了一个自组织图(SOM),并利用 PointNet 架构在该图上分层学习节点特征。然而,它未能充分利用局部特征。PartNet Yu 等人(2019)以自上而下的方式分解三维形状,并提出了一种递归神经网络(RvNN)来学习细粒度零件的层次结构。Zhao 等人(2019b)介绍了一种编码器-解码器网络--3D-PointCapsNet,用于处理几种常见的点云相关任务。在他们的模型中,胶囊网络部署的动态路由方案和独特的二维潜空间提高了性能。表 6 总结了三维部件分割方法。
6. Applications of 3D Segmentation
我们回顾了用于无人驾驶系统这两大应用的三维语义分割方法。
6.1. Unmanned Systems
随着激光雷达扫描仪和深度摄像头的普及和价格的降低,它们越来越多地被应用于无人驾驶系统,如自动驾驶和移动机器人。这些传感器可提供实时三维视频(一般为每秒 30 帧),作为系统的直接输入,从而使三维视频语义分割成为了解场景的首要任务。此外,为了更有效地与环境互动,无人驾驶系统通常会建立一个场景的三维语义地图。下面我们将回顾基于三维视频的语义分割和三维语义图构建。
6.1.1. 3D video semantic segmentation
与第 3.1 节中介绍的三维单帧/扫描语义分割方法相比,三维视频(连续帧/扫描)语义分割方法考虑到了帧与帧之间的时空连接信息,这对于稳健、连续地解析场景更为有力。传统的卷积神经网络(CNN)并不是为利用帧间的时空信息而设计的。一种常见的策略是调整递归神经网络或时空卷积网络。
基于递归神经网络:RNN 通常与二维 CNN 结合使用,以处理 RGB-D 视频。二维 CNN 学习提取帧的空间信息,而 RNN 则学习提取帧之间的时间信息。Valipour 等人 Valipour、Siam、Jagersand 和 Ray(2017 年)提出了循环全神经网络在 RGB-D 视频帧的滑动窗口上运行。具体来说,卷积门控递归单元保留了空间信息并减少了参数。同样,Yurdakul 等人,Emre Yurdakul and Yemez(2017)结合全卷积和递归神经网络,分别研究了合成 RGB-D 视频中深度和时间信息的贡献。
基于时空卷积:附近的视频帧提供了不同的视角以及物体和场景的额外背景。STD2P He、Chiu、Keuper 和 Fritz(2017b)使用新颖的时空池化层来聚合通过光流和基于图像边界的超级像素计算出的区域对应关系。Choy 等人,Choy、Gwak 和 Savarese(2019)提出了 4D 空间-临时 ConvNet,直接处理三维点云视频。为了克服高维 4D 空间(3D 空间和时间)的挑战,他们引入了 4D 时空卷积、广义稀疏卷积和保持时空一致性的三边静态条件随机场。同样,基于三维稀疏卷积,Shi 等人(Shi, Lin, Wang, Hung and Wang,2020 年)提出了 SpSequenceNet,它包含两个新模块,即跨帧全局关注模块和跨帧局部插值模块,以利用四维点云中的空间和时间特征。PointMotionNet Wang、Li、Sullivan、Abbott 和 Chen(2022 年)提出了一种时空卷积,利用时间不变的空间邻域空间并提取时空特征,以区分运动和静态物体。
基于时空变换器:为捕捉点云视频中的动态,通常采用点跟踪。然而,P4Transformer Fan、Yang 和 Kankanhalli(2021 年)提出了一种四维卷积法,用于在点云视频中嵌入时空局部结构,并进一步引入了一个变换器,通过对这些嵌入的局部特征进行自我关注来利用整个视频中的运动信息。同样,PST2 Wei、Liu、Xie、Ke 和 Guo(2022 年)在相邻帧中执行时空自我关注以捕捉时空背景,并提出了一种分辨率嵌入模块,通过聚合特征来增强特征图的分辨率。
6.1.2. 3D semantic map construction
无人系统不仅需要避开障碍物,还需要对场景有更深入的了解,如物体解析、自我定位等。为了完成这些任务,无人系统需要建立一个三维场景语义地图,其中包括两个关键问题:几何重建和语义分割。三维场景重建传统上依赖于同步定位和映射系统(SLAM)来获取不含语义信息的三维地图。然后用二维 CNN 进行二维语义分割,再通过优化(如条件随机场)将二维标签转移到三维地图上,从而获得三维语义地图 Yang、Huang 和 Scherer(2017)。在复杂、大规模和动态场景中,这种常见的流水线并不能保证三维语义图的高性能。为了提高鲁棒性,人们努力利用多帧关联信息的开发、多模型融合和新颖的后处理操作。下文将对这些努力进行说明。
关联信息利用:主要取决于 SLAM 轨迹、递归神经网络或场景流。Ma 等人 Ma、Stückler、Kerl 和 Cremers(2017 年)通过使用 SLAM 轨迹将多视角的 CNN 特征图翘曲到一个共同的参考视图中,从而实现一致性,并在多个尺度上对训练进行监督。SemanticFusion McCormac、Handa、Davison 和 Leutenegger(2017 年)将去卷积神经网络与最先进的密集 SLAM 系统 ElasticFusion 相结合,从而提供视频帧之间的长期对应关系。通过这些对应关系,可以将多视角的标签预测以概率方式融合到地图中。同样,Xiang 等人利用 RGB-D 视频中递归单元提供的帧间连接信息,提出了一种数据关联递归神经网络(DA-RNN),并将 DA-RNN 的输出与 KinnectFusion 集成,从而为 3D 场景提供了一致的语义标注。Cheng等人:Cheng、Sun和Meng(2020)使用基于CRF-RNN的语义分割来生成相应的标签。具体来说,作者提出了一种基于光流的方法来处理动态因素,以实现精确定位。Kochanov 等人,Kochanov、Ošep、Stückler 和 Leibe(2016 年)也使用场景流在三维语义图中传播动态对象。
多种模型融合:Jeong等人,Jeong、Yoon和Park(2018)通过基于GPS和IMU的里程估算建立了三维地图,并使用二维CNN进行语义分割。他们利用坐标变换和贝叶斯更新方案将三维地图与语义标签整合在一起。Zhao 等人:Zhao、Sun、Purkait、Duckett 和 Stolkin(2018 年)使用 PixelNet 和 VoxelNet 分别利用全局上下文信息和局部形状信息,然后通过自适应学习不同数据流贡献的 softmax 加权融合来融合得分图。最终的密集三维语义图是通过视觉里程测量和递归贝叶斯更新生成的。
7. Experimental Results
下面,我们将总结第 3、4 和 5 节中讨论的分割方法在一些典型公共数据集上的定量结果,并对这些结果进行定性分析。
7.1. Results for 3D Semantic Segmentation
我们报告了基于 RGB-D 的语义分割方法在 SUN-RGB-D Song 等人(2015 年)和 NYUDv2 Silberman 等人(2012 年)数据集上的结果,使用 mAcc(平均准确率)和 mIoU(平均交叉联合率)作为评估指标。各种方法的结果均来自原始论文,如表 7 所示。

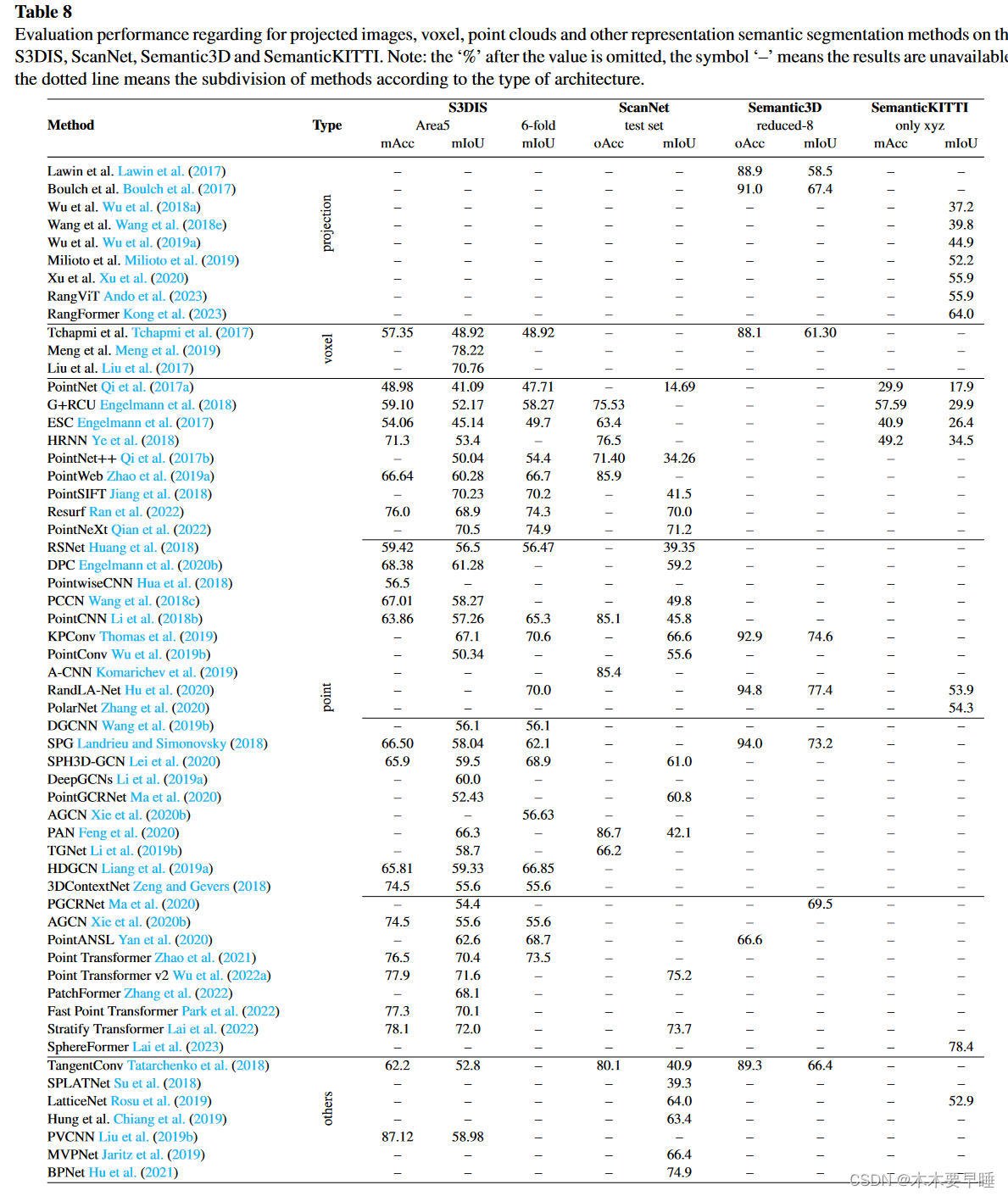
我们报告了投影图像/体素/点云/其他表示语义分割方法在S3DIS Armeni等人(2016年)(5区和6倍交叉验证)、ScanNet Dai等人(2017年)(测试集)、Semantic3D Hackel等人(2017年)(缩减-8子集)和SemanticKITTI Behley等人(2019年)(只有xyz,没有RGB)上的结果。我们使用 mAcc、oAcc(总体准确率)和 mIoU 作为评估指标。这些不同方法的结果均来自原始论文。表 8 报告了这些结果。
 8. Discussion and Conclusion
8. Discussion and Conclusion
近年来,利用深度学习技术进行 3D 分割取得了重大进展。然而,这仅仅是个开始,未来还将有重大发展。下面,我们将介绍一些悬而未决的问题,并确定潜在的研究方向。
合成数据集可为多种任务提供更丰富的信息:与真实数据集相比,合成数据集成本低且可生成多种场景,因此逐渐在语义分割中发挥重要作用 Brodeur 等人(2017)、Wu 等人(2018b)、Dai 等人(2017)、Armeni 等人(2016)、Hackel 等人(2017)。众所周知,训练数据中包含的信息决定了场景解析精度的上限。现有的数据集缺乏重要的语义信息,如材质和纹理信息,而这些信息对于具有相似颜色或几何信息的分割更为关键。此外,大多数现有数据集一般都是针对单一任务设计的。目前,只有少数语义分割数据集还包含实例标签 Dai 等(2017)和场景布局标签 Song 等(2015),以满足多任务目标。
适用于多种任务的统一网络:一个系统要通过各种深度学习网络完成不同的计算机视觉任务,成本高昂且不切实际。针对场景的基本特征开发,语义分割与一些任务具有很强的一致性,如深度估计 Meyer 等人(2019)、Liu 等人(2015)、Guo 和 Chen(2018)、Liu 等人(2018b)、场景补全 Dai 等人(2018)、Xia、Liu、Li、Zhu、Ma、Li、Hou 和 Qiao(2018)。(2018), Xia, Liu, Li, Zhu, Ma, Li, Hou and Qiao (2023), Zhang, Han, Dong, Li, Yin and Yang (2023), instance segmentation Liang et al. (2019b), Pham et al. (2019b), Han et al. (2020), and object detection Meyer et al. (2019), Lian, Li and Chen (2022).这些任务可以在统一网络中相互合作以提高性能,因为它们表现出一定的相关性和共享特征表征。
多种模式分割:使用投影图像、体素和点云等多种表示方法进行语义分割,有可能获得更高的精度。在某些实际场景中,由于场景信息有限,单一表示法限制了分割精度。例如,随着距离的增加,激光雷达的测量结果会变得越来越稀疏,而结合高分辨率的图像数据可以提高对远处物体的识别性能。因此,利用多种表征(也称为多种模态)是提高分割性能的另一种方法,Dai 和 Nießner (2018)、Chiang 等人 (2019)、Liu 等人 (2019b)、Hu 等人 (2021)。此外,使用大型图像模型(如 SAM Kirillov、Mintun、Ravi、Mao、Rolland、Gustafson、Xiao、Whitehead、Berg、Lo 等人(2023 年))和自然语言模型(如 ChatGPT)分割点云也是一种流行的方法。大型模型的高级功能使其能够捕捉复杂的模式和语义关系,从而提高分割任务的性能和准确性。
可解释的稀疏特征抽象:包括 MLP、卷积和变换器在内的各种特征抽象都得到了长足的发展。特征抽象模块可优先生成可解释的特征表示,使其能够为模型决策提供解释、可视化兴趣点和其他可解释性功能。此外,在涉及大规模数据和有限资源的情况下,特征抽象模块可提高计算效率。
弱监督和无监督分割:深度学习在三维分割方面取得了巨大成功,但这在很大程度上依赖于大规模标记的训练样本。弱监督学习指的是在有限或不完全监督的情况下训练模型的方法。弱监督苏、徐、贾(2023 年),史、魏、李、刘、林(2022 年)和无监督肖、黄、关、张、陆、邵(2023 年)范式被认为是放宽大规模标记数据集这一不切实际要求的替代方案。
实时分割:实时三维场景解析对于自动驾驶和移动机器人等应用至关重要。然而,现有的大多数三维语义分割方法主要侧重于提高分割精度,而很少关注实时性。少数轻量级三维语义分割网络通过将点云预处理成投影图像等其他表现形式来实现实时性,如 Wu 等人(2018a)、Wu 等人(2019a)、Park、Kim、Kim 和 Jo(2023)、Ando 等人(2023)。此外,增量分割将成为一个重要的研究方向,使模型能够在动态场景中增量更新和适应。
三维视频语义分割:与二维视频语义分割一样,也有少数研究尝试利用三维视频(也称为四维点云)的四维时空特征,如 Wei 等(2022 年)、Fan 等(2021 年)。从这些研究中可以看出,时空特征有助于提高三维视频或动态三维场景语义分割的鲁棒性。
我们全面考察了利用深度学习技术进行三维分割的最新进展,包括三维语义分割、三维实例分割和三维部件分割。我们全面比较了每个类别中各种方法的性能和优点,并列出了潜在的研究方向。



















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











