







 超级会员免费看
超级会员免费看
 本文介绍了大语言模型的预训练数据,包括维基百科、书籍、期刊、问答等内容,强调数据多样性和处理流程。此外,详细阐述了BPE(Byte Pair Encoding)方法在NLP中的应用,用于减少词汇表大小并保持语言表达能力。
本文介绍了大语言模型的预训练数据,包括维基百科、书籍、期刊、问答等内容,强调数据多样性和处理流程。此外,详细阐述了BPE(Byte Pair Encoding)方法在NLP中的应用,用于减少词汇表大小并保持语言表达能力。
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/136636105
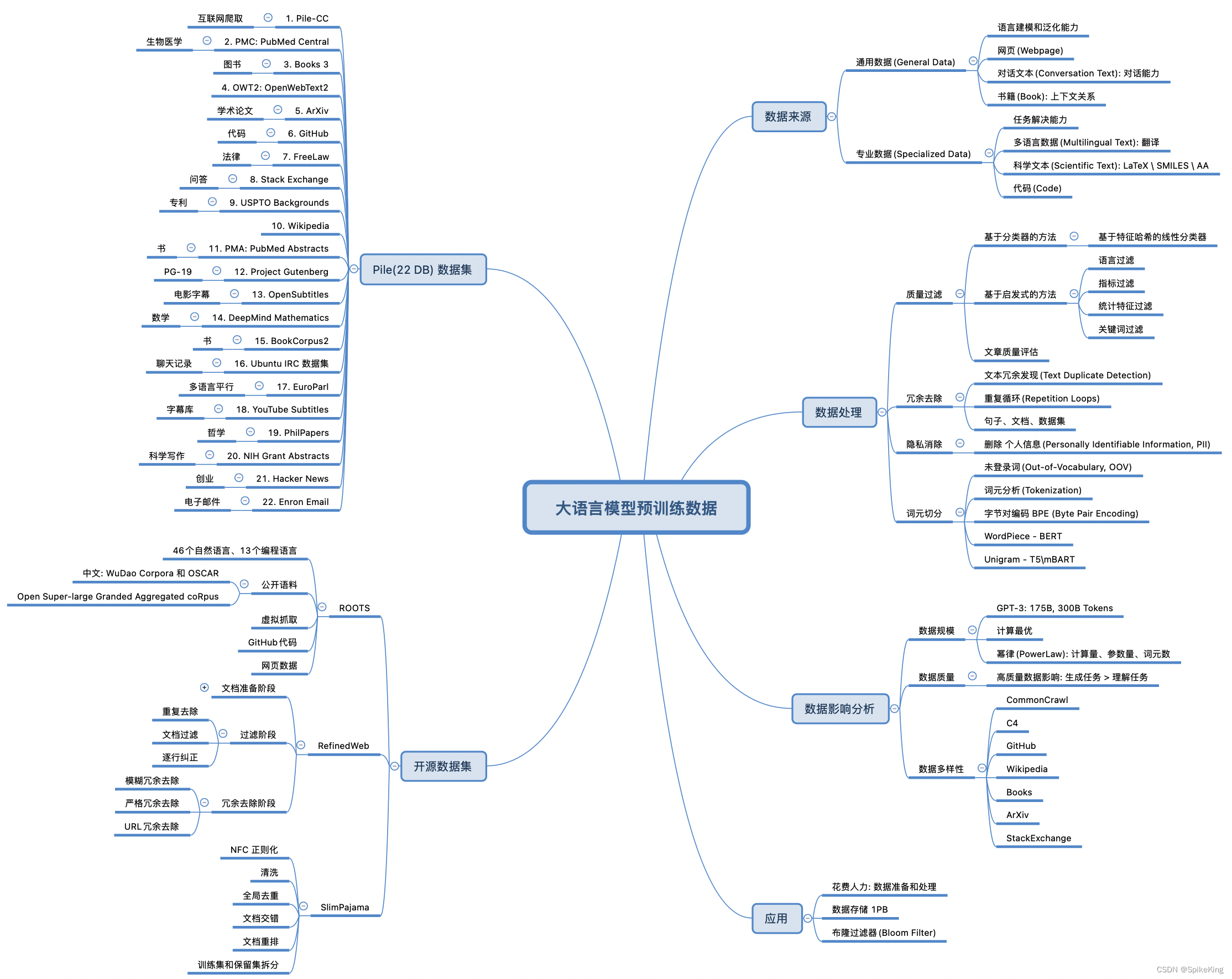
大语言模型的预训练数据通常包括网页数据、书籍、新闻、科学文章等多种类型的文本。这些数据帮助模型学习语言的语法、语义和上下文信息。预训练阶段是模型构建的基础,通过无监督学习从海量文本中提取知识。
大语言模型的预训练数据通常涵盖了广泛的文本类型,以确保模型能够理解和生成多样化的语言内容。开源的数据集被广泛用于大语言模型的预训练,即:
- 维基百科类:包括各种语言的维基百科文章,这些数据集通常用于训练模型以理解和生成百科全书式的内容。
- 书籍类:例如BookCorpus,包含大量的未出版书籍文本,有助于模型学习文学和叙述性语言。
- 期刊类:如Pubmed

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 4253
4253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











