





本文介绍了一种根据脑电图信号和面部表情检测情绪(观众观看视频时的情绪)的方法,使用数据为被试观看一组情绪诱发视频时的面部表情和生理反应。被试观看视频时的面部表情所表达的情绪效价(消极到积极情绪)由五个注释者进行注释,视频内容在效价、唤醒维度上进行连续注释。长短期记忆循环神经网络 (LSTM-RNN) 和连续条件随机场 (CCRF) 被用于自动、连续地检测情绪,文章发现面部表情的结果优于脑电信号。文章还分析了面部肌肉活动噪音对脑电信号的影响,发现脑电图特征中大部分情绪信息都来自这种噪音,不过统计分析表明脑电信号在存在面部表情的情况下仍带有互补信息。(注意名词: 基本事实、表达情绪、感受情绪、预期情绪) ,本文发表在IEEE TRANSACTIONS ON AFFECTIVE COMPUTING杂志。
1.介绍
视频是一种视觉艺术形式,可以通过内容传达情绪。观众在不同心情和处境会偏好相应的情感内容,例如处于消极情绪的观众可能更喜欢悲伤的视频。多媒体情感表征可用于改进多媒体平台的检索和推荐。情绪检测是一种在不打扰观众的情况下,不显眼地识别视频或其他内容情绪痕迹的方法。客观采集到的情绪痕迹比情绪自我报告更可靠,不受不同社会、人格因素的影响,例如男性被试不太可能报告恐惧情绪。本文关注的重点是视频诱发情绪的连续识别,以及脑电信号和面部表情间的跨模态干扰。基于观众表达的情绪可以检测视频的情感亮点,这些情绪表达的时刻可以通过视频摘要、索引、评分估计的平台来建立情绪档案或轨迹,例如根据诱发观众最强烈情绪反应的时刻来制作电影预告片。
多媒体情绪处理有三类:表达情绪、感受情绪、预期情绪(expressed/felt/expected emotion)。表达情绪(刻意情绪)是艺术家/内容创作者打算通过作品诱发的情绪,与观众是否能感受到这些情绪无关;预期情绪是大多数观众因内容而产生的情绪;感受情绪是观众个人感受到的情绪。本研究的主要目标是通过标记、检测表情和生理反应来检测感受情绪,我们也用预期情绪对视频进行了注释,并试图从观众的反应中检测出表达情绪。
心理学家提出并确定了情绪的不同模型,诸如快乐、厌恶一类的离散情绪(discrete emotion)更容易理解,因为它们是基于语言产生的。不过这些情绪在用不同语言表达时可能有所不足,例如波兰语没有准确的表达厌恶的词汇。另一方面,情绪可以在多维空间中呈现,该空间根据研究得出,确定了携带所有可能情绪的最大方差的维度。效价、唤醒、支配 (VAD,valence、arousal、dominance) 空间是最广为人知的情绪维度之一,效价的范围从不愉快到愉快;唤醒的范围从平静到激活,描述情绪强度;支配的范围从不受控制到占主导地位。鉴于大部分情绪变化来自两个维度(唤醒和效价),因此通常使用这两维度进行情绪的连续注释和识别。
本研究的目标是通过EEG(脑电)信号和面部表情进行连续的情绪识别,使用的数据集是观众对一组情感视频的反应。首先,五位注释者连续注释被试观看视频的面部表情可见情绪反应,据此连续注释刺激材料的效价和唤醒,以此标示预期的唤醒和效价的水平,我们将平均连续注释结果作为连续情绪识别系统的基本事实。而后我们分析了多个被试的EEG信号和面部表情,提取了情绪特征以进行连续情绪识别,提取EEG信号的PSD(功率谱密度)和面部标记点坐标作为特征,应用了不同的回归模型(包括线性回归、支持向量回归、连续条件随机场、循环神经网络,这些模型已在先前研究中成功使用)。我们使用平均相关系数和RMSE(均方根误差) ,10折交叉验证评估检测结果。我们还通过统计分析确定了EEG信号和面部表情的关系,关注基于EEG信号的情绪检测多大程度可以归因于面部表情引起的肌电伪迹。我们使用线性混合效应模型和格兰杰因果分析的因果关系来研究该问题。
本研究的主要贡献:
1.使用EEG信号和面部表情检测了时间和空间上的连续效价。
2.研究了EEG功率谱特征与面部表情特征、连续效价注释特征的相关性,以寻找肌肉EMG(肌电图)活动可能的交叉模态效应,分析方法包括格兰杰因果分析来确定面部表情、脑电图特征间的因果关系。
3.进行了统计分析,验证EEG特征是否在存在面部表情特征时显示附加信息。
4.应用了连续注释数据训练的模型,这些数据由于缺乏面部表情而无法解释。我们发现面部表情分析与长短期记忆神经循环网络(LSTM-RNN)相结合能提供了最好结果,EEG信号中的情感信息大部分由面部表情肌电干扰引发(不过不能完全排除独立于面部表情分析的EEG信号存在的情绪信息)。
本研究拓展/添加的分析方法:
1.简化了面部表情分析方法,提高了性能,添加了面部特征的扩展描述;
2.添加了有关面部表情对脑电信号影响的统计分析和讨论,并在脑电图预处理中去除了带宽滤波(4Hz-45H);
3.分析了注释延迟(annotation delay)及其对性能的影响;
4.测试了LSTM-RNN的不同架构及参数;
5.添加了脑电信号情感信息与面部表情间的关系的统计分析;
6.连续注释了唤醒、效价维度的刺激材料,报告了预期情绪的痕迹检测结果。
2.背景
2.1.连续情绪识别
Wollmer等人建议放弃在情绪维度上分类情绪,并将其应用于语音的情绪识别,Nicolaou等人使用视-听模式在SEMAINE数据库上检测情绪的效价和唤醒,使用SVR(支持向量回归)和BLSTM-RNN(双向长短期记忆循环神经网络)在时间、情绪维度上连续检测情绪。Nicolaou等人提出使用输出关联(output-associative)的RVM(关联向量机)来平滑处理RVM输出,进行连续情绪检测,不过他们没有将RVM的表现与BLSTM-RNN进行比较。推进连续情感检测技术的一个尝试是2012年音频/视觉情绪挑战赛(AVEC, Audio/Visual Emotion Vhallenge)。比赛使用的SEMAINE数据库包含了被试者与SAL(Sensitive Affective Listeners)代理互动时的视听反应,该反应在效价、激活、力量、期望四个维度上有连续注释。AVEC2012的目标是使用视听信号进行连续的情绪检测,Baltrusaitis等人使用CCRF(连续条件随机场)进行的情绪检测有卓越表现(与SVR相比)。
2.2.隐式标签: 标记、总结视频
隐式标签(implicit tagging),如标签、痕迹,从观众的自发反应中识别用来描述内容的元数据。电影评分代表了观众对电影的期望,自发反应可以用来估计该评分,一项估计电影收视率的研究记分析了皮肤电反应(GSR),三分之二的人口统计信息结合GSR响应进行分析可获得更好的结果。Bao等人使用手机、平板电脑上捕捉的面部表情、声学、运动、用户交互特征来估计电影评分,他们发现个体反应非常多样化且不可靠,不适合进行群体反应处理。McDuff等人测量了观看视频广告时观众的微笑,以此评估他们对内容的偏好,他们通过网络摄像头采集大量样本,最终能相当准确地检测出用户再次观看视频的愿望,以及是否喜欢观看视频。
自发行为反应也被用于视频亮点(video highlight)检测。Joho等人开发了一种使用面部表情的视频摘要工具,基于面部表情进行概率性情绪识别,检测观看8个视频片段的10名参与者的情绪,不同情绪性表情的变化率、发音水平(包含高度表达的情绪如惊讶、幸福,以及没有表达或中性情绪)被作为特征来检测视频中的个人亮点(personal highlight)。Chenes等人使用观众间的生理联系来检测视频亮点,皮肤温度和GSR在此提供了丰富信息,该方法在检测亮点方面达到了78.2%的准确率。Fleureau等人使用一组观众同时期的GSR来创建电影情感痕迹,发现生理上的休息(physiological repose)生成的痕迹与用户报告亮点相匹配。
自发反应也可以转化为情绪标签,例如“悲伤的”。生理信号已被研究用于检测情绪,进行隐式情绪标记。Soleymani等人提出了一种使用外周生理信号对电影场景进行情感表征的方法,8名被试观看了64个电影场景并自我报告情绪反应,由RVM训练的线性回归用于估计各视频片段对生理特征的影响。Kierkels等人扩展了这些结果并分析生理信号检测对视频个性化情感标记的有效性,他们将视频片段的唤醒度和效价水平映射到情绪标签上。一项研究采用类似方法,用线性岭回归对音乐视频进行情感表征,从生理信号和视频内容中检测到唤醒、效价、支配,还有喜欢/不喜欢评级。Koelstra等人使用EEG和外周生理信号对音乐视频进行情感标记,一项类似研究使用EEG和瞳孔反射进行多模态情感标记,Khomami Abadi等人记录、分析了MEG(脑磁图)信号,作为EEG的替代方案来监测大脑活动。
3.数据集和标记
本研究使用的数据集来自MAHNOB-HCI数据库,该数据库是一个公开、可用的多媒体隐式标签数据库。MAHNOB-HCI数据库包含两个实验的数据,本文中使用的数据来自一项记录短视频情绪反应的实验。
3.1.刺激视频片段
我们选择20个视频作为情绪唤起刺激,涵盖整个情绪谱。视频中有14个是电影节选,根据初步研究选择。在初步研究中,被试通过九点量表报告自己感受到的情绪唤醒(从平静到兴奋/活跃)和效价(从不愉快到愉快)。初步研究使用的视频集包含著名商业电影的155个电影场景,包含《钢琴家》、《真爱》、《闪灵》等。视频材料还包括来自在线资源的三个流行视频片段(两个快乐的,一个厌恶的)、YouTube上的三份过去天气预报(用作中性情绪片段)。将在线资源视频添加到数据集中是为了能够自由传播一些情绪视频样本(电影受版权保护不能传播)。最终我们选择20个视频,长度在34.9s到117s之间(M=81.4s,SD=22.5s)。心理学家推荐1到10分钟长度的视频来激发单个情绪,因此材料视频片段尽可能短时,以避免产生多种情绪或习惯刺激材料,同时保持足够时间来观察效果。
3.2.数据采集
实验数据来自28名健康志愿者,男性12名,女性16名,年龄在19-40岁之间。使用Biosemi Active II(BIOSEMI脑电系统介绍),32个有源电极记录EEG,10-20国际系统定位。以每秒60帧的速度拍摄被试正脸,记录面部表情。
大量正脸视频记录没有可见的面部表情,本研究选择了有可见面部表情的239个trial子集进行标注(单个被试观看一个视频的表情响应算作1个trial)。我们训练了5名注释者,他们是本文的作者和研究人员,在实验室使用基于Feeltrace实现的软件和操纵杆对视频的情绪效价进行连续注释。与SEMAINE数据库中被试与代理进行对话的模式不同,本研究中被试安静、被动地观看视频,因此注释者无法标注情绪的激活、力量、期望(感受情绪)。图1显示了连续注释及其平均曲线的示例。5名注释者还标注了20个刺激视频的预期情绪的效价、唤醒水平。
成对相关系数中计算了克隆巴赫系数(Cronbach’s alpha)以测量不同注释者给出基于面部表情的注释间的评分一致性(M=0.53,SD=0.41);48.7%的序列一致性高于0.7,比SEMAINE数据库报告的低,这是由于数据库的性质不同以及本数据库缺少语音。视频期望情绪注释的克隆巴赫系数在唤醒度上50%的序列一致性高于0.7(M=0.58,SD=0.38),在效价上70%的序列一致性高于0.7(M=0.64,SD=0.40)。
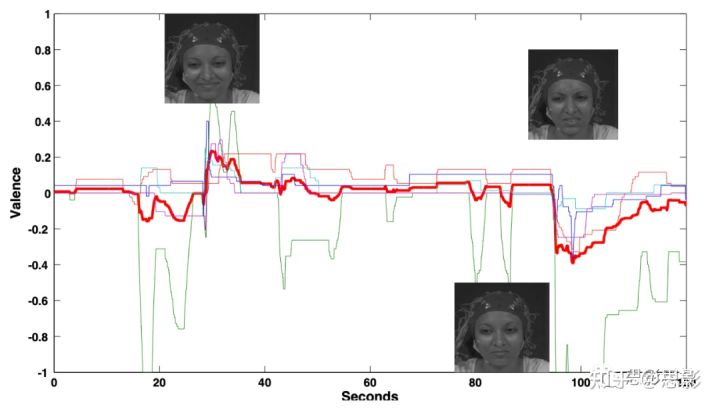
图1.观看一个视频的基于面部表情的效价连续注释及平均曲线(粗红线)
4.方法
4.1.脑电信号
EEG采样率256Hz,进行重参考来提高信噪比,没有参考电极时进行重参考平均(单个电极记录的所有EEG减去所有电极记录EEG的平均幅值)。平均信号包含可在头皮上检测到的非大脑信号的噪声和伪迹,例如来自心脏活动的电信号。不同频段脑电信号的PSD(功率谱密度)与情绪相关。功率谱密度从1秒时间窗口提取,重叠率50%,我们使用全部32个电极进行EEG特征提取,提取来自theta (4Hz < f < 8Hz)、alpha (8Hz < f < 12Hz)、beta (12Hz < f < 30Hz) 和gamma (30Hz < f) 波段的PSD对数。32个电极、4个波段的EEG特征总数为32×4=128个。由于STFT(短时傅里叶变换)窗口大小为256,这些特征在2Hz时间分辨率下可用。
4.2.面部表情分析使用面部跟踪器来跟踪49个面部基准点或坐标点
跟踪器中的回归模型用于检测坐标点,然后计算初始和真实坐标位置间的平移、缩放差异。特征跟踪通过前一帧的坐标点位置进行估计,每一帧使用SDM(有监督下降法)进行检测,该模型使用66个坐标点进行训练,并在输出中提供49个点坐标(见图2),修正头部姿态后提取面部坐标点。每个受试的中性脸和所有受试的平均脸之间发现仿射变换(affine transformation),使用该变换记录所有坐标点,平均眼睛内角、鼻子的坐标来生成参考点,假设参考点静止不动。我们计算了包括眉毛、眼睛、嘴唇在内的38个坐标点到参考点的距离,取平均值作为特征。
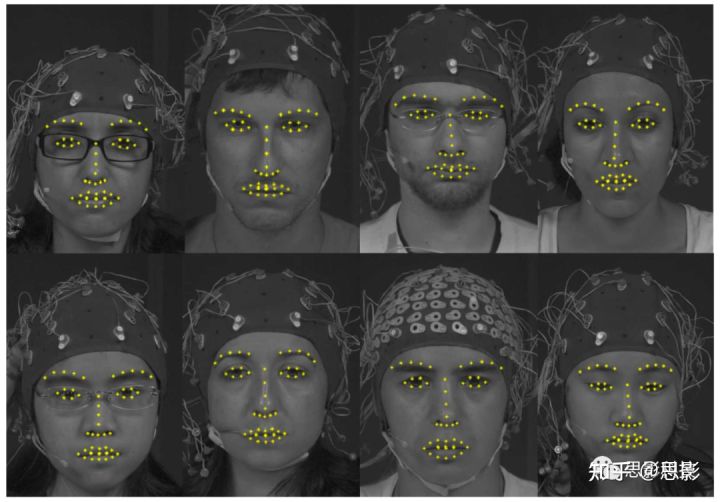
图2.面部表情捕捉示例
4.3.不同维度的情绪检测
研究选择四种常用回归模型进行连续情绪检测,分别为MLR(多元线性回归) 、SVR(支持向量回归)、CCRF(连续条件随机场)、LSTM-RNN(长短期记忆循环神经网络)。
4.3.1.长短期记忆循环神经网络
研究已证明LSTM-RNN在视听模式下的情感识别表现最佳。LSTM-RNN具有一个/多个隐藏层,包括LSTM单元,这些单元包含一个内存块(memory block)、一些乘法门(multiplicative gate),它们决定了单元是否存储、保持或重置现状。通过这种方式,网络随时间推移学习何时记住/忘记序列信息,以此保持序列长期相关性。RNN(循环神经网络)能够通过反馈连接记忆短期输入事件,而LSTM使用门控记忆单元可记忆更长时期的输入事件。本文使用NVIDIA提供支持的LSTM2开源工具CUDA(Compute Unified Device Architecture),根据不同配置获得结果(见第6.3节),最后选择2个包含LSTM单元的隐藏层,隐藏神经元的数量设置为输入层神经元/特征数量的1/4。学习率为1E-4,动量为0.9,序列在训练中以随机顺序呈现,输入信息中添加标准差为0.6的高斯噪声以减少过拟合问题,训练最多用100个epoch,如果20个epoch后验证集的性能(如误差平方和)没有改善,使用早停策略停止训练。
4.3.2.连续条件随机场CRF用于构建概率模型
对顺序数据进行分割和分类。CRF与HMM(隐马尔可夫模型)不同,不假设观察结果是条件独立的,因此适用于观察结果间存在强依赖性的情况。先前研究开发了CCRF(连续条件随机场)来扩展CRF以进行回归,其中CCRF作为另一个模型的样本估计平滑算子。我们给CCRF提供由多元线性回归所估计的输出信息,CCRF使用概率密度函数对条件概率分布建模(见公式1)。
公式2中,Ψ是势函数,X= {x1,x2,...,xn} 是输入特征向量集合(矩阵以每帧观察为行,效价估计来自其他回归技术,如MLR),Y= {y1, y2, ..., yn} 是目标,αk是fk的可靠性,βk与边缘特征函数gk.fk相同,顶点特征函数(yi和Xi,k之间的依赖关系)定义见公式3,边缘特征函数gk(描述步骤i和j的估计间的关系)定义见公式4。相似度S(k)控制连接图中两个顶点间的连接强度,近邻相似度见公式5,距离相似度见公式6。CCRF可使用SGD(随机梯度下降)进行训练,由于CCRF模型可被视为多元高斯分布,因此可通过计算所得条件分布的平均值来进行推断,如P(y|X)。

5.伪迹与伪迹效应
EEG中经常存在面部肌肉活动和眼球运动干扰,面部肌肉和眼球运动信号通常存在于外围电极和更高频段(beta和gamma波段)。基于此,我们预计EEG信号中的面部表情噪音有助于检测效价。我们从全部32个电极(来自4个波段,共128个特征)中提取EEG特征。为研究该假设,我们使用线性混合效应模型测试EEG特征对效价评估的影响(效价通过面部表情来注释,见公式7)。线性混合效应模型使我们能够在研究自变量(EEG、面部、眼睛注视)对因变量(效价)之影响的同时也对被试间差异(随机效应)建模。眼球运动通过Tobii眼球注视跟踪器采集,采样率60Hz,重采样4Hz以匹配其他模式。面部标志点的运动由一个样本到后一个样本的移动量定义(见第4.2节)。
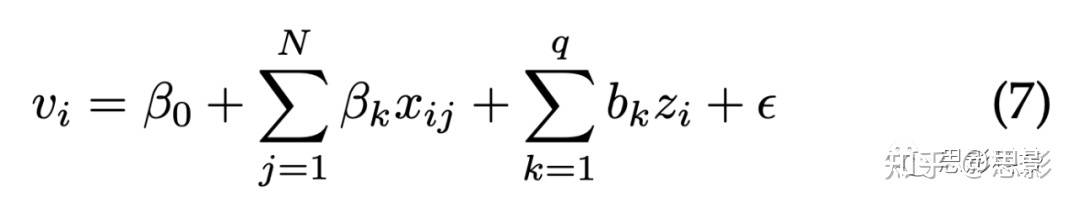
在公式7中,vi是第i个样本的效价,xij是特征,包括面部、EEG、眼睛注视;zi代表不同受试的随机效应量;ε是正态分布的随机误差,均值为零。分析结果表明大多数EEG特征的系数显著不为零,对不同波段的效价估计有显著影响的特征为:theta波段41%,alpha波段47%,beta波段50%,gamma81%;显著性经过ANOVA检验,拒绝p值小于0.05的零假设。总的来说,EEG系数显著不为零的百分比为55%。面部特征的(绝对)平均β值为0.057,EEG为0.002,凝视为0.0005。由于面部、眼睛注视特征作为固定效应存在于模型,EEG特征包含了面部运动没有的信息,且该信息对效价检测有用。然而,目前尚不清楚该信息是否与面部跟踪器未检测到的面部运动伪迹有关。
我们还计算了各电极不同波段的EEG谱功率与效价标签之间的相关性。如图3所示,位于额叶、顶叶、枕叶上电极的高频成分与效价标签具有更高相关性。
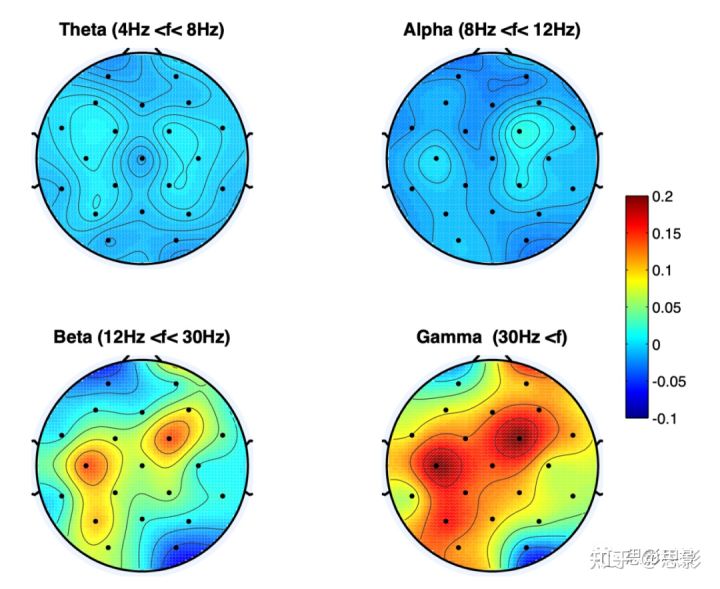
图3.PSD与theta、alpha、beta、gama波段连续效价的相关图,
相关值在所有序列上平均,图中额叶位于顶部 为了检查EEG变化多大程度与面部运动相关,我们使用多层线性回归模型通过眼睛注视、头部姿势、面部特征估计EEG特征。我们在分析使用了更大的样本集,包含被试没表现出可见面部表情的数据。眼睛注视和头部姿势不能预测EEG特征,但面部表情中提取的特征可以。眼球运动通常会影响EEG的低频成分,这些成分在EEG特征集中被去除了。从面部特征估计EEG特征的R方结果如图4。EEG信号和面部表情间的关联不会是运动皮层激活的结果,因为Mu节律与运动(9-11Hz)引起的运动皮层激活没有很强关联。Mu节律源自运动皮层,与alpha波频率相同(见图4)。比较图3、图4可以看到效价特征与具有强相关性、依赖于面部表情的特征很大程度重叠。尽管使用线性混合效应模型发现在有面部特征的情况下,EEG特征对于检测效价来说仍很重要,不过大多数可用于检测效价的方差与面部肌肉伪迹密切相关,对EEG信号检测最有效的面部坐标点包括嘴唇上的坐标点。

图4.R方地形图
描述EEG功率谱特征可以多大程度估计效价,以及多大程度来自于面部表情与运动我们进一步研究这种影响是来自面部表情还是EEG信号,使用了格兰杰因果分析来检测这两个时间序列间的关系。Granger提出当y导致x时,把时间序列y添加到自回归时间序列将减少x预测误差的方差(见公式8)。
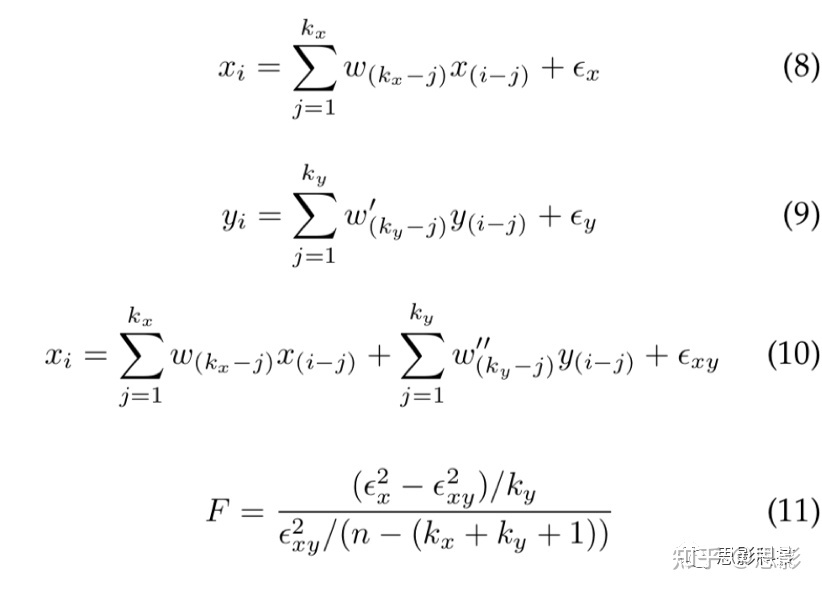
kx是自回归时间序列的模型阶数,使用模型选择标准计算,如贝叶斯信息准则(Baysian Information Criterion)或赤池信息准则 (Akaike Information Criterion)。时间序列y见公式9,重构x见公式10。公式10中第一个成分是自回归模型描述的x(见公式8),第二个成分是根据y的滞后值重建的x。格兰杰因果关系可通过F检验来确定(见公式11),然后可验证是否拒绝零假设,本文使用了5%的显著性水平。
我们生成了重采样到60Hz的EEG信号平方来表示它们的能量并匹配面部表情采样率,然后对38个面部坐标点、32个电极EEG信号进行格兰杰因果检验。我们发现测试面部表情是否由EEG信号引起时,平均28%的因果关系阳性,而测试EEG信号是否受面部表情影响时百分比为54%。图5显示了测试面部表情对EEG信号的因果关系时不同电极的平均百分比,我们可以观察到其与相关分析的结果相似,并且进一步强化了一个观点,就是脑电信号的方差很大一部分由面部表情伪迹造成。
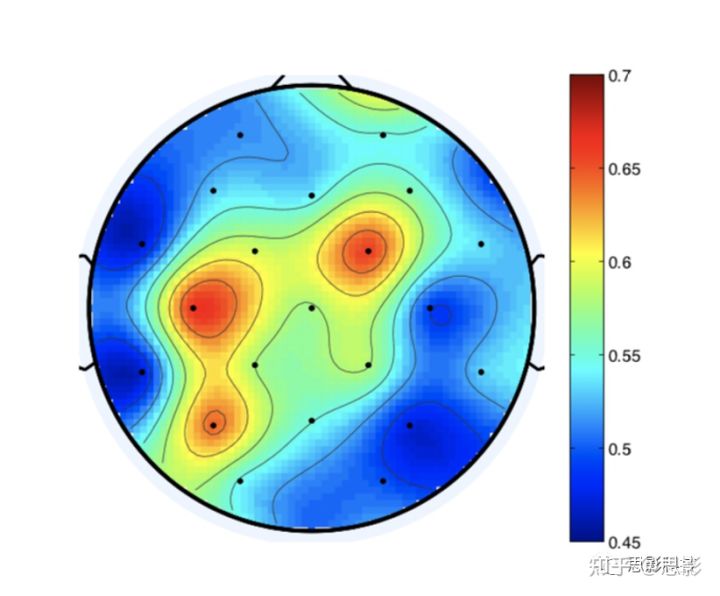
图5.面部表情(标记点坐标)对不同脑电信号的显著因果关系的平均百分比
6.实验结果
6.1.特征
我们计算了各序列不同面部表情特征与基本事实间的相关性,并对所有序列进行平均。相关系数最高的特征与嘴/唇坐标点相关,如下唇角(ρ = 0.23)、左右唇角距离(ρ = -0.23)等。结果显示唇坐标点是效价检测中信息量最大的特征,嘴巴和眼睛的张开程度也与效价密切相关。
6.2.标记延迟
Mariooryad和Busso在SEMAINE数据库分析了标记延迟对连续情绪检测的影响,发现延迟2秒会改善情绪检测结果。SEMAINE数据库由Feeltrace使用鼠标进行注释,相比之下我们的数据库使用操纵杆进行注释,我们认为其响应时间会更短且更合适。我们考虑了从250毫秒到4秒的延迟并计算了不同模式及其组合效价检测结果的平均相关系数。图6表明本研究中250毫秒延迟提高了检测性能,较长延迟降低性能,使用操纵杆的效果优于鼠标。
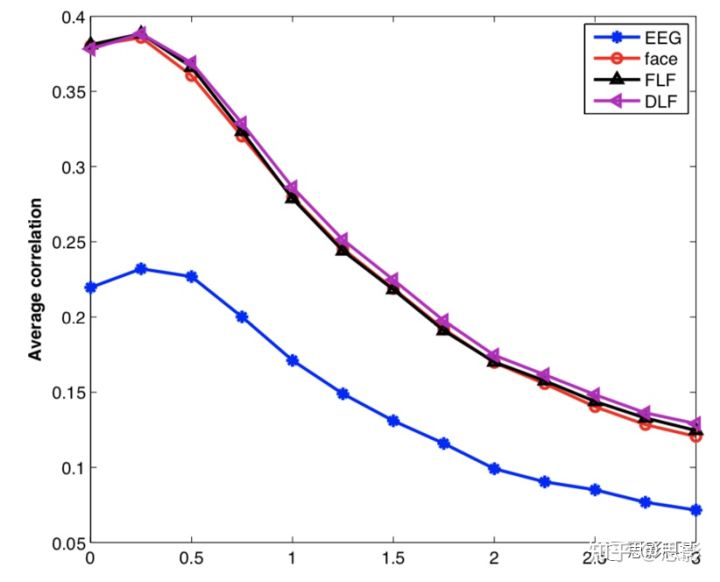
图6.注释延迟的情绪检测表现(x轴为时长)
6.3.LSTM结构
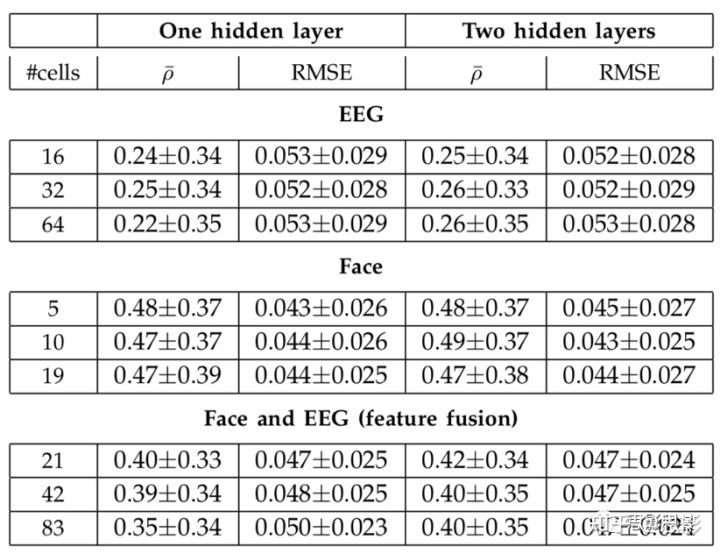
我们测试了不同的LSTM结构(不同数量LSTM单元,1或2个隐藏层)。如表1,与1个隐藏层相比,2个隐藏层具有更高的检测表现。我们测试了隐藏层中不同数量的神经元,包括输入层神经元或特征数量的1/8、1/4和1/2。我们通过单边非参数秩和检验证实了不同数量的神经元对结果没有显著影响。因此,我们选择了1/4、2个隐藏层的输入神经元作为最终设置。Weninger等人发现加入连续目标间的差异提高了模型的回归表现,能根据内容特征估计音乐情绪,他们认为添加目标差异就像对权重进行正则化。我们尝试了相同技术,在训练阶段将每个点的目标与其相邻样本(Δ(v)/Δ(t))间的差异相加,并在测试期间去除这些输出。与Weninger等人的发现不同,包含目标差异(Δ(v)/Δ(t))的结果对情绪检测性能没有任何显著影响。因此,我们没有在最终模型中使用额外的差异性目标。
表1.不同结构LSTM网络的连续效价检测表现
6.4.连续情绪检测(感受情绪)
本节展示感受情绪的连续情绪检测结果,所有特征和注释都从原始采样率重采样为4Hz。EEG特征为不同波段的功率谱密度,面部表情特征为每帧检测到的面部坐标点。重采样使我们能够执行多模式融合,训练集特征标准化后,结果通过非被试独立的10折交叉验证进行评估。训练集、验证集、测试集不包含来自相同实验的信息,每一折中样本被分成三组,10%作为测试集,剩余样本的60%(占样本总数的54%)作为训练集,其余作为验证集。对MLR仅使用训练集来训练回归模型,不使用验证集。使用来自Liblinear库的具有L2正则化的线性ε-SVR,根据验证集上的最低均方根误差找超参数。我们在训练LSTM-RNN的过程中使用了验证集来避免过拟合。MLR在验证集上的输出用于训练CCRF,将训练好的CCRF用作测试集的MLR输出。CCRF正则化超参数基于使用训练集的网格搜索选择,其余参数保持与参考文献17相同(参考文献见原文)。
我们采用两种融合策略融合两种模式:特征级融合(FLF, Feature Level Fusion)将这些模态特征连接起来形成更大的特征向量,然后输入模型。决策级别融合(DLF, Decision Level Fusion) 对来自不同模式效价值的估计结果进行平均。
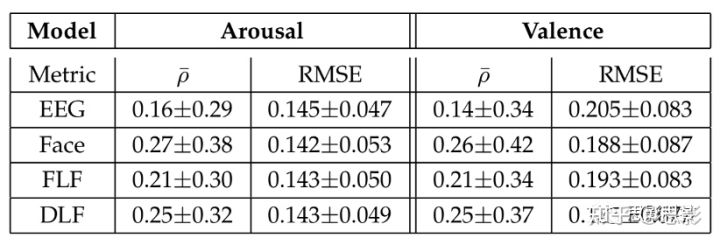
情绪识别结果如表,表2报告了平均皮尔逊相关系数以显示检测到的曲线和注释间的相似性,还报告了RMSE以显示估计值能多大程度反映基本事实,RMSE惩罚较大误差。结果显示面部表情的表现优于EEG特征,这可能是由于数据集偏向带表情的trial。我们证明与Koelstara和Patras的研究不同,面部表情在效价检测方面的表现优于EEG信号。值得注意的是,与参考文献45的技术相比,本研究使用的面部坐标点检测器是一种更新的标志跟踪技术(使用的EEG特征与参考文献45相同)。此外,与先前研究相比,我们使用了一组不同的标签,这些标签不基于自我报告;参考文献45是一项单个trial分类研究,而我们进行了连续的情绪检测。
为了评估不同模态和融合方案的检测性能,我们报告了平均皮尔逊相关系数(ρ̄)和均方根误差(RMSE)。在[-0.5, 0.5]之间缩放输出与标签后计算RMSE,报告的测量值对MLR、SVR、CCRF)和LSTM-RNN所有序列平均。ρ ̄越高表现越好,RMSE越低表现越好,最佳结果加粗显示。
表2.平均皮尔逊相关系数(ρ̄)和均方根误差(RMSE)

单边Wilcoxon检验显示,DLF的性能与使用LSTM-RNN单模态面部表情分析之间的差异不显著,因此我们认为EEG信号的融合无益,并且LSTM-RNN在单模态(面部表情)上的表现最好。使用非参数Wilcoxon检验发现LSTM-RNN和CCRF产生的相关性间的差异不显著,但LSTM-RNN的RMSE显著降低(p<1E-4)。尽管因为数据库性质不同,我们无法与其他研究直接比较性能,不过我们对情绪效价的检测表现与2012年AVEC赛的优胜者在同一范围内,且优于最近的一项研究。我们还测试了双边长短期循环神经网络(BLSTM-RNN)的表现,不过与LSTM-RNN相比,其性能反而较差。、
图7给出了两个检测结果示例。与消极情绪相比,积极情绪更容易被检测到。微笑是愉悦情绪的有效指标,我们的数据集中有大量微笑案例。先前文献也显示微笑检测在自发表情识别上的表现良好。我们对面部特征的分析还表明,大多相关度高的特征是嘴唇上的坐标点。
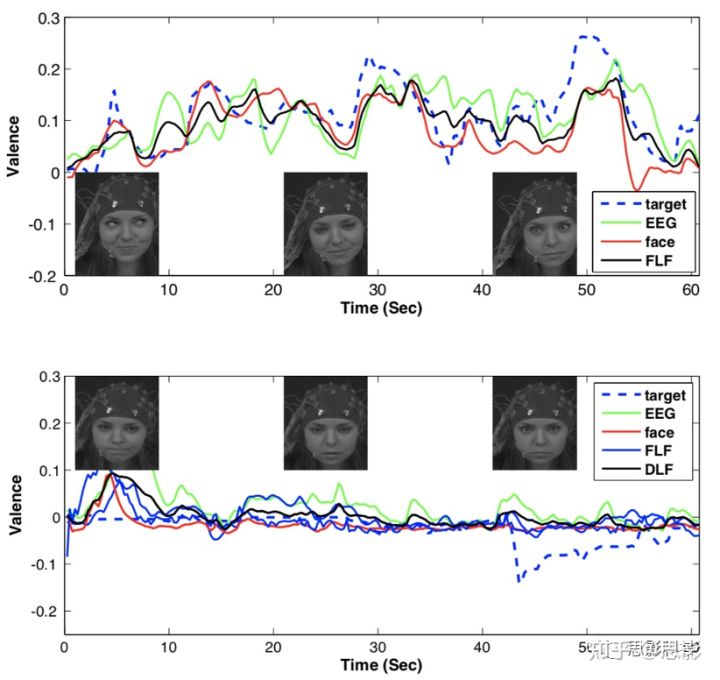
图7.检测到的效价痕迹。
上图(ρFLF=0.80,RMSEFLF=0.034)检测积极情绪刺激,检测表现理想;下图(ρFLF=-0.11,RMSEFLF=0.036)检测消极情绪刺激,但并未获得正确趋势。
6.5.预期情绪检测
情绪检测的目的是识别视频的情绪亮点和情绪痕迹,基础事实则反映了预期情绪。我们使用相同的程序来检测预期情绪,使用连续唤醒、效价作为标签。这里我们只报告性能最好的模型(即LSTM-RNN)的结果。如表3,和上一节的结果相同,面部表情结果再次优于EEG信号,两种模式的融合并不优于面部表情。值得注意的是,即使没有表情标签,面部表情在情绪检测上的表现也优于EEG信号。结果平均低于第6.4节中仅用可见表情的面部表情特征结果,这可能是因为并非所有的观众在任何时候都能感受到预期情绪,例如一个人可能已经看过电影场景中的一个令人惊讶的时刻,第二次看到就没有那么惊讶了,很多时候我们只表达/感受高水平的情感,习惯刺激后情绪反应会衰减。此外,个人和背景,如情绪、疲劳、对刺激的熟悉程度,都会影响我们对视频的反应。解决这些问题的一个方法是组分析,与单个用户的反映相比,多个用户的反映在生理分析视频情感方面取得了更好的结果。
表3.预期情绪检测结果
为了验证基于面部表情的注释训练模型是否可以反映无面部表情的情况,我们选择了一个具有明显情感亮点的视频,《真爱》中的教堂场景,并采集了13名没有任何明显表情的参与者的EEG反应。由于反应不包含可见表情,因此这些数据没有用于注释以及其他训练。我们从这些EEG反应中提取功率谱特征并输入到模型对输出曲线进行平均。如图8,尽管被试没有任何面部表情,并且可能没有非常强烈的情绪,但从他们的EEG反应中检测到的效价与视频亮点时刻和效价趋势共变。与其他方法相比,CCRF更平滑地进行跟踪,与整体趋势更好匹配。图8显示了三个不同时刻的帧,第一帧在20秒婚礼期间,第二帧和第三帧是被试将乐器放在视线范围内并意外演奏浪漫歌曲时令人惊讶、快乐的时刻。
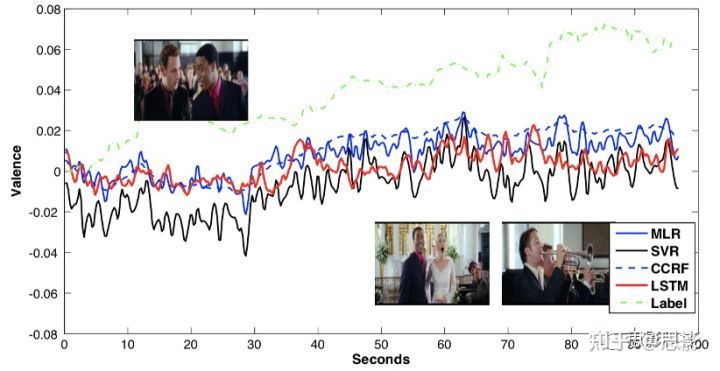
图8.平均效价曲线与情绪轨迹
由无面部表情的被试观看《真爱》片段时的EEG信号得出,总体趋势与情绪时刻相关。
7.结论
我们使用EEG信号和面部表情进行了连续的情绪效价检测,从EEG信号和面部表情中获得了理想结果。我们预测面部表情的表现会更好,因为基本事实是基于面部表情判断生成的。线性混合效应模型的统计检验结果表明,EEG携带有用的检测效价的信息,不过包含EEG信号的信息增益并没有提高检测性能。EEG信号中其余的效价相关信息也可能与(面部跟踪器未捕获的)细微面部表情有关。结果表明,与EEG信号相比,面部表情在情绪检测方面具有优越的性能。本研究使用的数据集由明显可见的面部表情响应组成,不过结果与先前研究不同,还不能推广到所有条件和情绪检测场景。
即使EEG的检测性能较差,无法记录被试面部时仍可以考虑EEG信号。当前的可穿戴耳机,例如EMO-TIV3,展示了EEG分析的潜力。此外,通过正确的电极放置,EEG的肌电信号和面部表情伪迹可用于检测面部表情,取代使用前置摄像头捕捉面部表情。EEG信号与基本事实之间的相关性分析表明,EEG较高频率成分携带了更多情绪愉悦度相关的重要信息。
EEG信号与面部表情之间的相关性和因果关系分析进一步表明,EEG特征主要来源于面部肌肉活动噪音。效价检测分析还表明,与消极情绪相比,积极情绪序列的结果更好。面部表情的连续注释存在滞后,我们证明使用操纵杆而非鼠标时响应时更快表现更好。在未来的工作中可以考虑用多模态技术研究面部表情和EEG信号间的相关性、因果关系,数据可以包括不同情况下表演出来和自发表达的反应。

















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









