





认知负荷理论表明,工作记忆的超负荷可能会对人在认知要求较高的任务中的表现产生负面影响。评估认知负荷是一项困难的任务;它通常通过专家的反馈和评估来进行评定。近年来,基于功能性近红外光谱(fNIRS)的认知负荷分类已成为关键研究领域之一,这得益于其抗干扰性、成本效益和便携性。为了使fNIRS在各种应用中更具实用性,有必要开发能够自动分类fNIRS信号且较少依赖训练信号的稳健算法。认知科学中使用的许多分析工具都采用深度学习(DL)模式来发现与心理工作负荷分类相关的信息。本综述探讨了关于深度学习设计和整体有效性及其关键特征的研究问题。
我们确定了2011年至2023年间发表的45项研究,这些研究特别提出了使用fNIRS设备获得的数据来分类认知负荷的机器学习(ML)模型。这些研究基于特征选择方法、输入和深度学习模型架构进行了分析。现有的大多数认知负荷研究都基于机器学习算法,这些算法遵循信号过滤和手工制作特征的方法。研究发现,整合卷积和LSTM算子的混合深度学习架构与其他模型相比表现显著更好。然而,深度学习模型,特别是混合模型,在fNIRS设备捕获的认知负荷分类方面还没有被广泛研究。文章强调了当前的趋势和挑战,为开发与fNIRS研究相关的深度学习模型提供了方向。本文发表在Expert Systems with Applications杂志。
关键词: 功能性近红外光谱(fNIRS) 深度学习 机器学习 认知负荷 人工智能
1.引言
认知负荷理论(CLT)被认为是实验心理学(Kirschner, Ayres, & Chandler, 2011)、教育心理学(Sweller, 2016)、发展心理学(Sepp, Howard, Tindall-Ford, Agostinho, & Paas, 2019)和医学教育(Skulmowski & Xu, 2021)领域最重要的学习理论之一。认知负荷理论表明,人类在处理新信息时,思维能力是有限的(Castro-Alonso等,2021,Curum和Khedo,2021)。该理论利用了人类认知结构的教学含义和学习程序。通常,认知架构假设所有新信息最初由人类的工作记忆处理,而工作记忆的容量和持续时间是有限的。这些信息随后被储存在无限的长期记忆中。然而,当信息从先前组织的长期记忆中检索时,我们的工作记忆是有限的(Buchner, Buntins, & Kerres, 2021)。心理工作负荷降低表现的程度取决于个人在特定领域工作的经验。认知负荷的增加会通过降低动力、增加反应时间、疲劳和错误率来损害表现。现代行为科学研究强调,在教学和学习过程中必须考虑认知负荷的影响,以便进行有效的知识获取(Heitmann等,2022,Tugtekin和Odabasi,2022)。
认知负荷的测量在提高各种任务的技能方面起着重要作用,例如在航空(Wilson, Nair, Scielzo, & Larson, 2021;R. Zhu, Wang, Ma, & You, 2022)、半自动驾驶汽车(H. Zhang等,2022,Zhang等,2022)、国防训练(Buckley等,2022)、航空航天(Magnusdottir, Johannsdottir, Majumdar, & Gudnason, 2022)、电子学习(R. Liu等,2022,Liu等,2022)、基于虚拟现实的训练器(Zhao等,2022)和装配操作(Fournier等,2022)中。在过去的几十年里,已经开发了几种非侵入性模式来通过获取人体信号来测量认知负荷。认知负荷的变化可以通过各种生理参数来检测,例如脑电图(EEG)(Farkish, Bosaghzadeh, Amiri, & Ebrahimpour, 2022)、心电图(ECG)(Lagomarsino, Lorenzini, De Momi, & Ajoudani, 2022)、眼动追踪(Yan等,2022)、功能性近红外光谱(fNIRS)(Agbangla, Audiffren, Pylouster, & Albinet, 2022)、皮肤电导水平(Saha, Jindal, Shakti, Tewary, & Sardana, 2022)和正电子发射断层扫描(PET)(Canário, Jorge, Martins, Santana, & Castelo-Branco, 2022)。每个生理参数负责观察不同的生物过程。然而,体积庞大、成本高昂和对不同干扰的敏感性限制了这些设备在普适计算中的能力。例如,虽然眼动追踪被广泛使用且不会造成干扰,但它只提供了大脑活动的间接测量(Anderson等,2011)。
与fMRI和PET相关的神经成像研究已经对血氧和代谢功能的病理变化产生了深入的认识(Catana, Drzezga, Heiss, & Rosen, 2012)。除了昂贵之外,fMRI和PET还要求受试者在一个严格受限的环境中保持不动(Fujikawa等,2022,Harauzov等,2022)。此外,这两种模式都会使受试者暴露在危险材料和噪音中。EEG的电极容易受到内部和外部伪影的影响,如心跳、运动和其他电磁干扰。这些干扰使得很难区分信号和噪音(H. Wang等,2022,Wang等,2022)。皮肤温度、眼动追踪和皮肤电导水平也被广泛用作工作负荷的非侵入性测量;但研究结果表明传感器数据与主观工作负荷测量之间的相关性不显著(Cosme等,2022,Žagar等,2022)。
fNIRS有潜力克服上述问题,并且在广泛的应用中都有用且可用(Klein, Debener, Witt, & Kranczioch, 2022)。作为一种强大且非侵入性的工具,fNIRS可以安全地研究浅表皮质区域的血液动力学反应。fNIRS使用基于光纤的光源在600至1000 nm的光谱窗口发射红外线,并使用探测器来检测光密度变化(Li等,2022)。神经活动的变化导致血氧水平的变化。基于修正的比尔-朗伯定律原理(Baker等,2014),fNIRS通过监测皮质微循环血液水平中氧合血红蛋白(HbO2)和脱氧血红蛋白(dHb)的浓度变化来测量认知负荷,如图1所示。fNIRS的主要优势包括高空间分辨率、安全性、运动耐受性、便携性以及与EEG、PET或ECG集成的能力(Krampe, 2022;Y. Liu等,2022,Liu等,2022)。
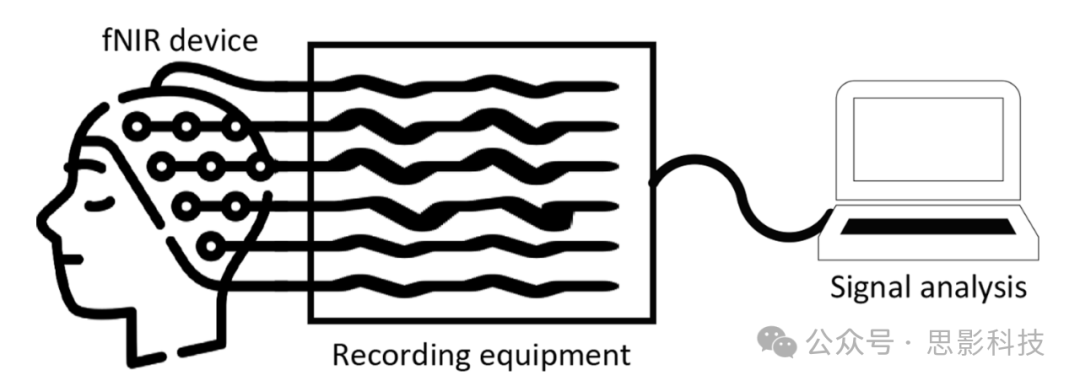
图1. 用于生成皮质激活图的多通道数据采集
虽然fMRI提供了关于血氧水平的高分辨率和深入信息,但价格低廉的fNIRS针对感兴趣的皮质区域。fNIRS还能耐受运动伪影,这使其成为检测认知负荷相关任务中大脑活动的更好候选者(Zhuang等,2022)。因此,在我们的综述中,我们只关注使用现成设备捕捉前额叶皮质血液动力学变化的基于fNIRS的数据收集活动。fNIRS信号天然复杂、非线性,且具有高维度。这种数据格式使我们难以用肉眼识别异常。这些特性使fNIRS数据适合使用深度学习(DL)和机器学习(ML)模型进行分析。
DL/ML模型有能力通过直接从数据中的复杂映射函数分层学习特征。它们是几个领域中领先的人工智能(AI)工具,如图像处理(Suganyadevi, Seethalakshmi, & Balasamy, 2022)、模式识别(Bai等,2021)、图像分割(Picon等,2022)、语音分析(Bhangale & Kothandaraman, 2022)和生理数据处理(Patlar Akbulut, 2022)。从fNIRS设备记录的信号通常包含混合伪影和噪音。传统方法需要将fNIRS信号分解为频率或小波变换以去除噪音。深度学习模型,特别是人工神经网络(ANNs)或卷积神经网络(CNNs),有时只需要最少的预处理工作,通过生成机器学习特征进行分类和模式识别(Wani等,2022)。
在各个工程领域的人工智能成功应用为开发具有稳健性能的无模型方法提供了保证。因此,在本综述中,我们关注可穿戴fNIRS传感器在记忆要求任务期间记录和追踪认知负荷方面的实施、验证和开发。
尽管已经存在几篇关于使用生理传感器评估认知负荷的综述,但据我们所知,还没有研究论文深入涵盖DL/ML模型在基于fNIRS的认知负荷分析中的应用。本综述第2节详细讨论了认知负荷和生理信号研究领域内以往的调查和综述文章。这些文章主要侧重于传统的ML、DL和统计技术,特别强调用于分析fNIRS数据的手工特征工程方法。这些文章的重点是利用fNIRS技术研究与神经系统疾病、压力和情绪反应相关的应用。值得注意的是,不同的认知任务会在大脑各个区域引起特定的皮质激活,这就需要为每个特定任务定制ML和DL算法的超参数。虽然现有的综述涵盖了人工智能在fNIRS数据分析中的广泛应用,但在突出和理解特别是用于分析从fNIRS测量获得的认知负荷数据的ML和DL技术的进展方面仍然存在挑战。认识到这一研究空白,我们对认知负荷和fNIRS人工智能文献进行了调查,明确目标是突出在认知负荷识别中使用ML/DL方法所取得的进展。
本综述的主要贡献如下:
-
全面覆盖2011年至2023年关于使用最新DL和ML方法对认知负荷进行分类的fNIRS相关发表文献;
-
包括现有模型的设计和训练在内的DL和ML流程的基本概念,用于分析fNIRS信号;
-
对所有已审查文献的简明总结,以及对未来开发用于推断认知负荷的ML和DL模型的建议。
本文的其余部分组织如下。第2节回顾了认知负荷的研究。在第3节中,我们概述了文献搜索策略,详细说明了纳入和排除标准。第3节总结了诱导认知负荷的方法。第4节是用fNIRS捕捉认知活动,第5节是fNIRS分析中的人工智能,第6节是应用于fNIRS数据的ML和DL模型的文献计量学检查,深入探讨了ML/DL方法的基础。第7节介绍了已审查文章的讨论,而第8节讨论了未来的影响和挑战。最后,第9节以结束语作为总结。
2.相关工作
在过去几年中,众多研究者对认知负荷进行了综述和调查,旨在了解监测认知负荷的当前趋势。这些综述的发现强调了认知负荷评估的复杂性,揭示了它可以通过各种方式进行评估,包括主观和生理测量。虽然主观测量(如问卷)传统上是收集认知负荷见解的常用方法,但R. A. Block等人(Block, Hancock, & Zakay, 2010)进行的元分析表明这种方法存在某些局限性。他们对117项实验数据的分析表明,仅依靠主观测量可能会引入偏差,并受到个体认知能力差异的影响。该领域的大多数综述一致强调了使用生理测量的重要性,以获得对任务执行过程中认知表现的宝贵见解。这些测量包括但不限于ECG、EEG、眼动追踪、fNIRS和皮肤电导水平。这些测量提供了直接和客观的方法来评估与任务表现相关的复杂认知功能。
深度学习技术的发展对神经学研究的方向产生了重大影响。当前深度架构的普及带来了需要回顾和分析生理信号领域现有深度学习研究的需求。已经进行了几项研究来讨论和调查DL模型在分析生理数据中的作用。例如,Y. Roy等人(Roy等,2019)强调了EEG在临床应用中的作用,如睡眠障碍诊断、癫痫监测和脑-机接口。他们强调了DL在解决自动化耗时任务和改善跨受试者泛化等挑战方面的日益采用。该综述确定了主要趋势,包括DL在各个领域EEG分类中的普及。
值得注意的是,各项研究在数据量、架构选择和原始EEG数据的使用方面差异很大。该综述提出了需要针对性地研究EEG处理中DL所需的最佳数据量。为了提高结果的可重复性,提供了建议,包括清晰的架构和数据描述、使用现有数据集和代码共享。E. Banuelos-Lozoya等人(Banuelos-Lozoya, Gonzalez-Serna, Gonzalez-Franco, Fragoso-Diaz, & Castro-Sanchez, 2021)在体验质量/用户体验(QoE/UX)评估的背景下突出了相关研究,重点关注从各种生理数据源识别认知状态。研究发现,虽然已经分析了心理工作负荷、压力和注意力等认知状态,但仍需要理解它们与影响整体用户体验的具体元素之间的关系。主要发现强调了对刺激的一般生理和行为反应,而不是界面或交互的个别组成部分。Y. Zhou等人(Y. Zhou等,2021, Zhou等,2021)对基于EEG的认知工作负荷识别使用机器学习进行了全面综述。该文章涵盖了经典机器学习的步骤,包括数据采集、预处理、特征提取和选择、分类和评估。此外,还探讨了广泛使用的工作负荷识别深度学习模型。Adil等人(Saleem等,2023)的综述围绕驾驶员疲劳检测,强调了驾驶的复杂性,其中由于疲劳导致的认知表现下降可能导致事故。该研究回顾了检测驾驶员疲劳的最新技术,强调使用生理信号,特别是EEG和ECG传感器,以及GSR和热成像相机。这篇综述指出了一些挑战,如缺乏定制的深度学习架构、由于复杂性和实时约束导致的多模态方法有限,以及在异构硬件传感器之间比较性能的困难。作者建议需要新的解决方案,包括物联网和移动设备、非侵入性传感器、迁移学习和定制深度学习架构,以提高驾驶员疲劳检测系统的稳健性、可靠性、韧性和实时能力。
同样,还有许多其他关于DL/ML的综述和调查,它们关注特定领域或应用。这些包括对应用于各种领域的深度学习方法的深入探索,如眼动追踪、ECG、EEG和fNIRS,以及特定任务如压力、情绪识别、睡眠障碍、认知负荷、贫血和多媒体学习。这些综合性的综述论文主要集中在ML/DL在分析各种生理信号中的多样化应用。尽管有大量文献探讨了使用生理测量进行认知负荷分析的ML/DL技术应用,但在系统检查这些技术专门用于fNIRS信号方面仍存在明显的空白。据我们所知,我们没有找到任何全面涵盖ML/DL技术在使用fNIRS信号进行认知负荷分析背景下应用的深入文献综述。虽然现有的综述深入探讨了ML/DL在使用EEG和其他生理信号进行认知负荷评估中的应用,但缺乏解决fNIRS信号在这一领域中独特特征和挑战的文献。值得一提的是,C. Eastmond等人(Eastmond, Subedi, De, & Intes, 2022)进行的综述对DL技术在分析fNIRS信号方面取得的进展进行了更广泛的分析。然而,这项研究并未探讨使用fNIRS进行认知负荷评估的具体复杂性。其次,值得注意的是,这些综述研究分析了使用公开可用数据集或重新利用先前研究数据的生理信号。然而,这些综述并未关注与用于后续ML和DL分析的初始数据收集过程相关的可能挑战和问题。因此,为了弥补文献中存在的空白,我们的综述旨在突出在使用fNIRS信号识别认知工作负荷方面应用ML和DL方法所取得的重大进展。这包括对在这一特定领域发表的所有研究进行审查,提供有关技术、方法和发现发展的信息。
3.材料和方法
本综述根据系统综述和元分析首选报告项目(PRISMA)(Page等,2021)协议提供的指南,涵盖了在认知要求任务期间大脑活动的研究。我们制定了一个可理解的搜索策略,旨在回答特定的研究问题。为了将重点放在与ML和DL相关的神经人因工程学研究上,我们首先确定了初步搜索的关键词。因此,我们在表1中呈现的最终搜索字符串中,将认知负荷的常用术语与fNIRS结合在一起。
表1. 用于每个主题的搜索字符串

我们特别将出版物限制在2011年以后的知名来源,即ACM数字图书馆、Web of Science、PubMed、IEEE Explore、Scopus、PubMed、Google Scholar和EuropePMC。我们在这些电子数据库中使用搜索关键词,然后根据以下纳入和排除标准初步筛选标题和摘要。
3.1. 纳入标准
本综述的目标是探索基于ML/DL的技术来解码fNIRS信号中的大脑活动。本文包含的研究应符合以下标准:
-
认知要求任务;
-
用于分析的人工智能技术;
-
用fNIRS信号训练的人工智能模型;
-
数据集考虑健康受试者,以便探索fNIRS信号在开发与人类表现、负荷管理和训练目的相关的应用方面的真正潜力;
-
2011年1月1日至2023年12月31日期间在同行评议期刊和高引用会议论文集上发表的文章。
3.2. 排除标准
已考虑以下标准来确定是否需要排除某篇文章:
-
不包含足够细节以评估研究质量或仅以摘要形式出现的文章;
-
学位论文、案例研究、论文、预印本、概述和书籍章节;
-
关于患者的研究;
-
关于公开可用数据集的系统研究;
-
基于数据统计分析的研究;
-
英语以外语言的研究。
3.3. 搜索结果
选择过程分两个主要步骤进行。第一步涉及删除所有重复项;第二步应用先前指定的纳入和排除标准。还排除了没有关于特征分析、比较、研究设计和结果信息的文章。图2总结了识别、筛选和资格审查过程中涉及的具体步骤。
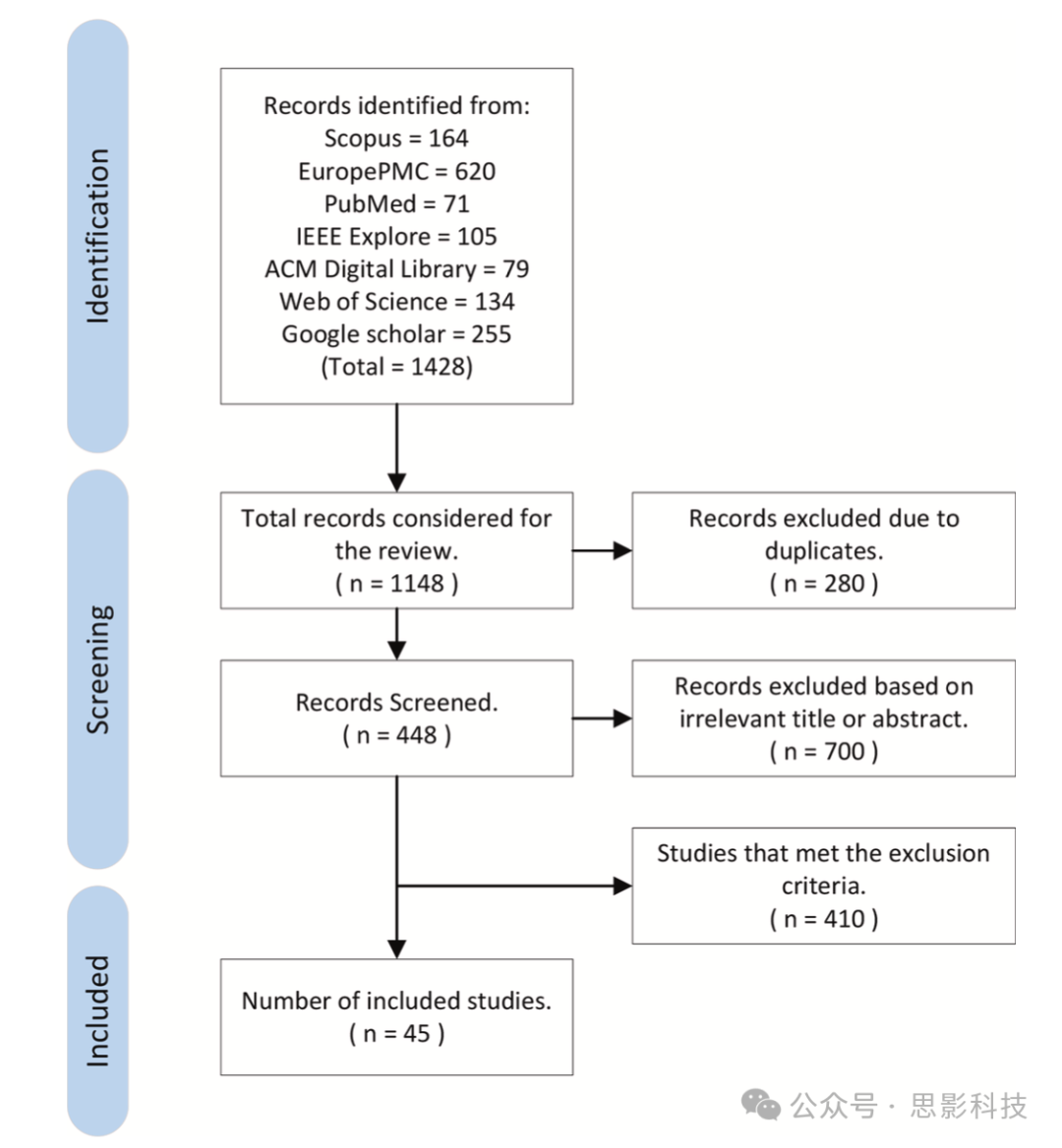
图2. 根据PRISMA(Page等,2021)指南的文献搜索流程图
根据关键词搜索共检索到1428项研究,删除了近280项重复研究。然后,删除了符合排除标准的410项研究,同时提取了符合全部纳入标准、包含认知任务信息、模型设计和结果的研究。本综述包含的文章中超过50%发表于过去三年。此外,在随后的章节中总结了所有45篇关于fNIRS和ML/DL的认知负荷文章的主要结果。
4.用fNIRS捕捉认知活动
认知活动表示基于表现结果对任务的评估。尽管我们研究的主要目的是调查认知负荷的生理测量,但研究人员也使用主观测量进行分析。主观测量要求参与者使用多项量表对学习过程的不同方面进行评分。特别是,NASA任务负荷指数(TLX)(Hart & Staveland,1988)被认为是人机系统评估中测量工作负荷的金标准。NASA-TLX测量基于心理需求、体力需求、时间需求、表现、挫折感和努力计算全局指数得分。这些得分被转换为0-100范围(Nasirizad Moghadam等,2021)用于任务评估目的。然而,当多个认知过程相互作用时,学习者可能无法识别不同形式的认知负荷。由于缺乏与模拟认知环境相关的外部世界事件的对应和评估,主观测量的有效性受到质疑。因此,提高主观测量的可信度很重要,这样外部世界以及内部感觉和感受才能在认知负荷测量中相互关联。
相比之下,生理测量尤其是fNIRS提供不间断的评估,提供更客观的工作负荷评估。基于fNIRS的系统被广泛用于研究模拟认知环境中的神经变化。HbO2和dHb的浓度变化与脑血容量的变化成正比,提供了神经活动的有用测量。一些研究实施了主观调查,并使用DL和ML分类技术对fNIRS信号进行分类(Asgher等,2020,Keles等,2021)。仅依赖生理信号的主要原因是调查会中断基本操作流程,延长操作时间,且仅在任务后可用(T. Zhou等,2020),导致本文讨论的场景中的测量存在组内和组间变异性、不一致性、中断和不充分。
开发基于fNIRS的系统的首要步骤是选择产生脑信号的脑区。这些信号通常从前额叶皮质或运动皮质获取。运动皮质主要对身体部位的运动作出反应,如腿、手臂、手指、手等。相比之下,本调查中包含的大多数研究表明,来自前额叶皮质的信号与认知任务高度相关。此外,从前额叶皮质获取的信号对运动伪影和高频影响的敏感性较低(Gemignani & Gervain,2021)。图3描述了本综述中基于认知任务的研究分布。导致大脑前额叶区域HbO2和dHb变化的认知要求活动可分为四组:心算(16%)、n-back任务(24%)、Stroop任务(5%)和基于模拟的任务(55%)。这些任务的一般协议描述如下:
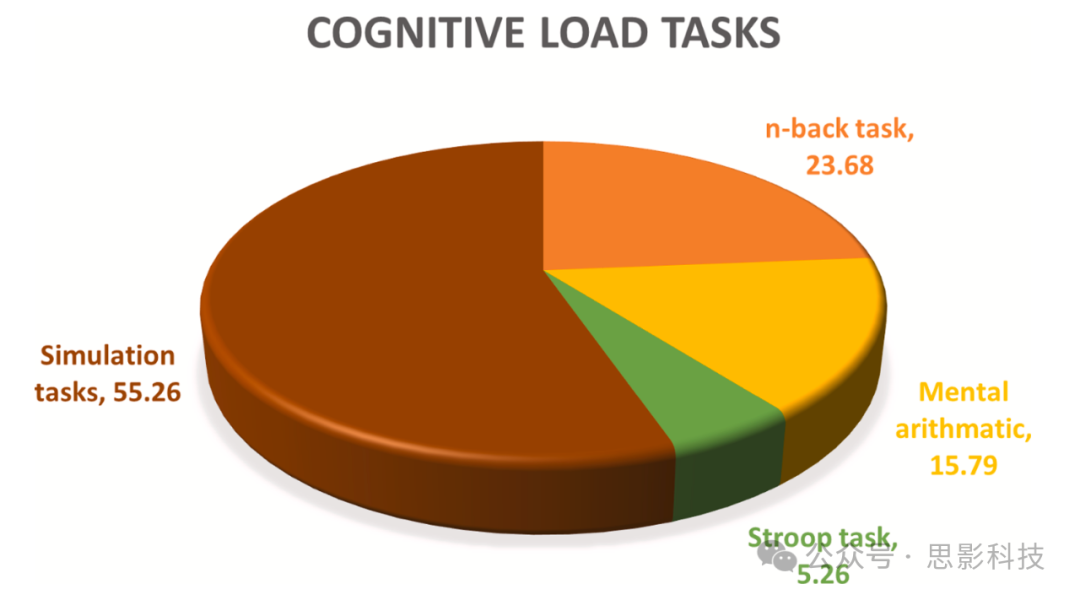
图3. 基于任务的研究分布
4.1. 心算
算术任务涉及在不使用纸张、计算器或计算机帮助的情况下进行数学计算。算术任务通常包括在预定时间内向参与者呈现一系列数字以进行加法、减法、乘法或除法。不同复杂度级别的数学方程需要同时进行心理处理和信息存储,这在处理复杂实验场景时会引起低级和高级心理工作负荷。
4.2. N-back任务
N-back任务由Kirchner(Kirchner,1958)于1958年提出,在神经科学中被最广泛地用于理解工作记忆的神经基础。作为视觉-空间任务,神经成像研究人员利用n-back任务来诱导不同级别的记忆负荷。它作为视觉或听觉刺激,向参与者呈现一系列随机数字、图片或数位。参与者需要记住它们,然后在被询问时需要确定与N项之前看到的刺激是否匹配。通过改变N的值可以修改认知负荷。在0-back任务中,参与者需要识别单个预先指定的数字、字母或图像。在1-back任务中,每个新项目与其前一个相同。类似地,对于2-back、3-back、...或n-back任务,每个新项目与2、3、...或n个试验之前呈现的项目相同。图4显示了1-、2-和3-back任务的示意图。系统地改变N的值会增加处理负荷,这导致反应时间和准确性的变化(Lamichhane、Westbrook、Cole和Braver,2020)。
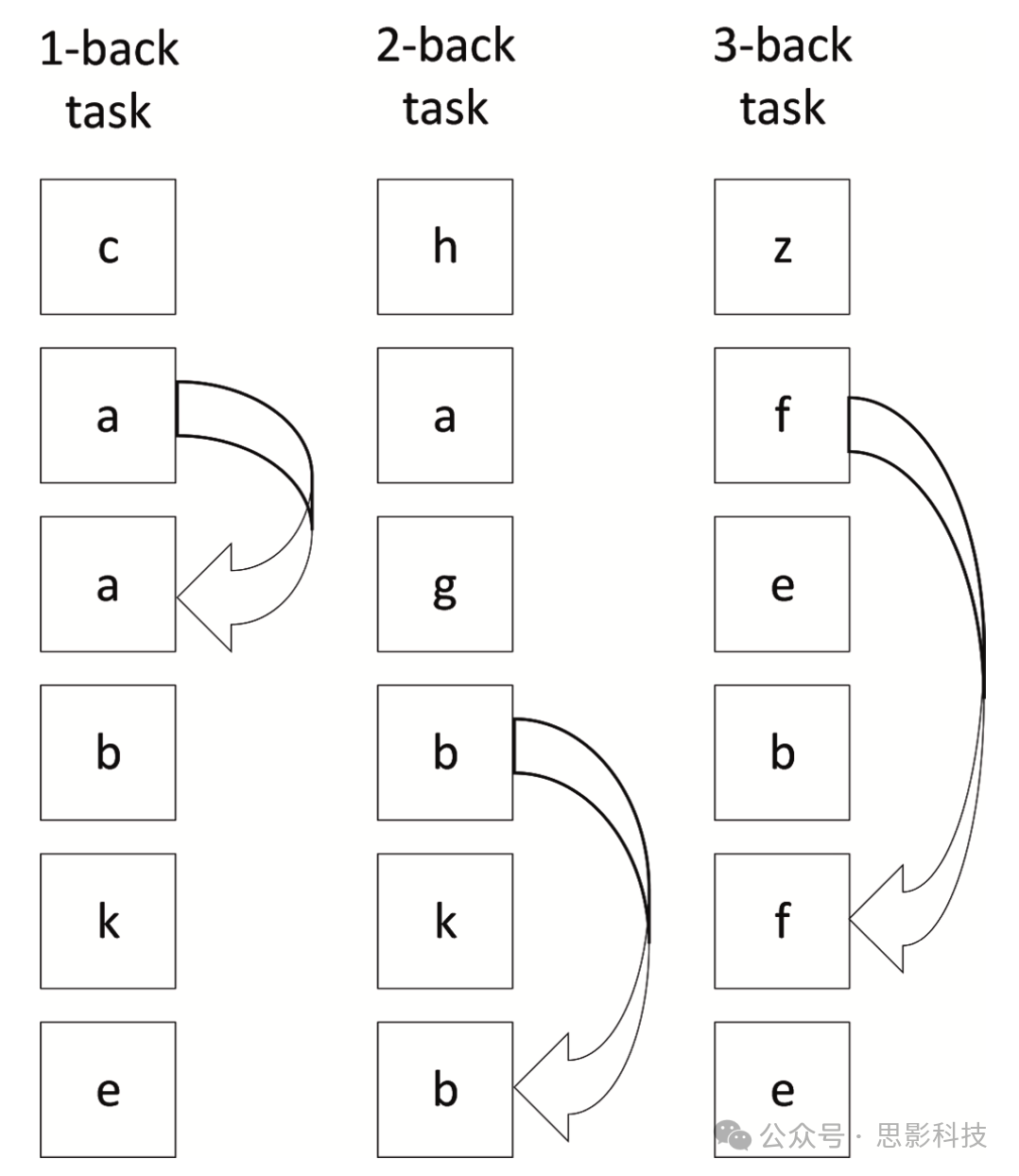
图4. 1、2和3-back任务的示意图
4.3. Stroop任务
Stroop任务(Stroop,1935)于1935年开发,用于研究认知抑制的效应。从那时起,已提出了许多Stroop任务的变体。其中一些已在临床神经心理学中用于研究患者的神经系统疾病(Fischer-Jbali等,2022,Lewis等,2022)。如图5所示,传统的Stroop任务包括呈现用红色、绿色、蓝色和黄色显示的四色单词。例如,"绿色"这个词可能以绿色、黄色、红色或蓝色显示。Stroop效应在神经学研究中被广泛使用,准确和快速的反应可以获得奖励积分。在Stroop测试中,要求参与者识别字体颜色而忽略单词本身。这导致颜色识别延迟、反应时间变慢和认知工作负荷增加。

图5. 经典Stroop测试
4.4. 基于模拟器的认知负荷研究
在基于模拟器的环境中研究人类大脑提供了最安全的方式,可以让参与者接触模拟危险而不会危及生命或造成财产损失(Frederiksen等,2020)。驾驶/飞行模拟器(Asadi等,2023,Asadi等,2019)、虚拟现实(Kooijman等,2022,Kooijman等,2023)和认知要求高的游戏等技术可用于创建将真实环境的周围环境整合到虚拟系统中的模拟。如图6所示,这些模拟与不同类型的商业操纵杆或定制控制器具有高度连接性。此外,模拟过程中的干扰因素,如能见度、湍流、心理状态或可预编程的操作特性,会给参与者增加认知负荷。在基于模拟器的研究中,飞行/驾驶任务构成了神经人因工程应用的主要部分(例如,飞机控制系统、驾驶汽车或在复杂模拟场景中驾驶飞机)(Mejia-Puig和Chandrasekera,2022,Reddy等,2022)。然后监测和评估人类在复杂认知任务(例如,手术模拟、视频讲座、实验室环境中的危险识别)中的注意力。然而,不容易复制的非真实场景会对认知和表现结果产生不利影响。
图6. 认知负荷模拟环境
5.fNIRS分析中的人工智能
人工智能(AI),包括ML和DL,利用具有学习能力的计算算法来识别数据中的模式。有时,很难从数据样本中解释确切信息(Mehta & Shukla,2022)。在这方面,DL和ML提供了底层算法,可以在不需要专门编程的情况下从数据中学习。基于AI的模型存在计算时间长和梯度消失问题(Khademi、Ebrahimi和Kordy,2022),这使研究人员使用统计和其他方法进行数据分析。然而,AI的最新进展和图形处理单元(GPU)的可用性使神经科学家能够以前所未有的细节解码和分类fNIRS信号。
在神经成像中,ML/DL模型将fNIRS信号作为训练数据来学习和预测相关的类别标签。在训练阶段,ML/DL算法以最优方式配置超参数,使训练好的模型在遇到未见过的数据样本时能够泛化以产生所需的结果。图7描述了DL/ML模型实现的一般流程。第一步是捕获原始fNIRS信号。这些信号通常包含由心率、血压等变化引起的噪声。在预处理阶段,去除数据集中的信号伪影和其他异常值。本综述中介绍的大多数研究采用带通滤波器和Butterworth滤波器以及其他方法来实现这一目的。在可选的特征提取过程中确定输入谱及其对应关系。特征选择通过减少数据维度和计算复杂性来提高分类性能。它通常与ML算法一起使用,有时与DL算法一起使用,以提高模型的稳健性。有少数论文将特征提取与DL算法结合使用,但大多数研究将原始fNIRS信号作为模型输入。
文献中报告的大多数研究使用基于统计摘要的特征(如均值、方差、最大值、最小值、斜率、偏度、峰度和归一化)或参数化技术(如Wigner-Ville分布、连续小波变换和霍夫变换)从数据中提取有用特征。训练良好的模型可以提供与不同级别心理工作负荷相关的预测。为进一步提高模型的泛化能力,大多数研究要么使用n折交叉验证(CV)要么使用留一法。
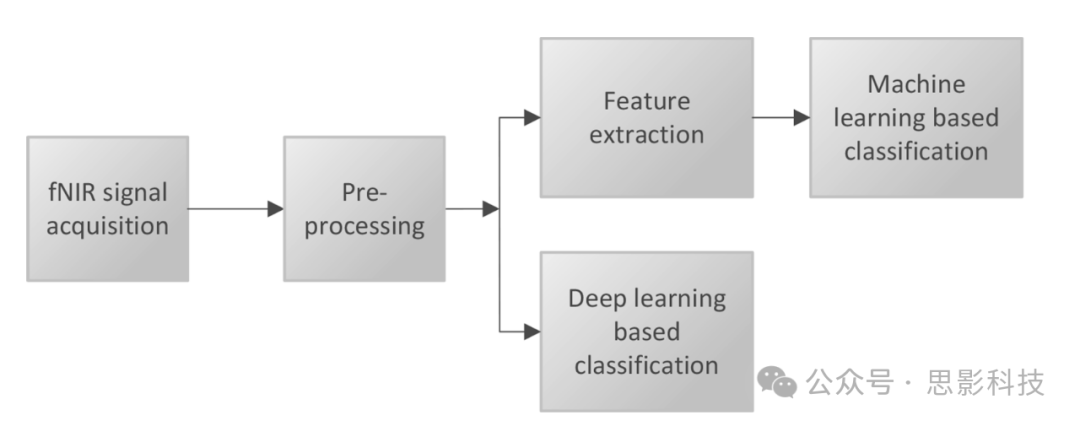
图7. 使用ML和DL进行fNIRS分析的总体步骤包括信号采集、预处理、特征提取和分类。
分类任务差异很大,可以分为三个主要组:(a)监督学习(b)无监督学习,和(c)强化学习。在监督学习中,标签(目标输出)通常由人类确定,监督算法将输入特征映射到期望的输出(标签)。监督学习算法需要以手工制作的标记数据形式的外部帮助用于训练和测试阶段。因此,算法从训练数据中学习模式,并在测试数据上验证模型以进行分类和预测。分类方法,如CNNs(Albawi、Mohammed和Al-Zawi,2017)、ANNs(Abiodun等,2018)、支持向量机(SVM)(Vapnik,1999)、决策树(Kotsiantis,2013)、随机森林(Breiman,2001)、朴素贝叶斯(Fix & Hodges,1951)、逻辑回归(DeMaris,1995)和线性回归(Su、Yan和Tsai,2012)是常见的监督学习算法。
相比之下,无监督学习算法使用未标记数据进行推理。这些算法从原始数据中学习特征,并开发预测模型,通过降维将输入数据分类到不同的聚类中。无监督学习算法的例子包括K均值聚类(Hartigan & Wong,1979)、主成分分析(PCA)(Maćkiewicz & Ratajczak,1993)和独立成分分析(ICA)(Stone,2002)。
强化学习(RL)基于序贯决策原理工作。它使用学习代理与动态环境交互,在成功完成任务时最大化奖励。影响RL的主要因素是环境模型、策略、原始信号和奖励函数。传统的RL模型只能解决具有低维空间的问题。然而,最近在强化代理方面引入深度神经网络(DNNs)使模型能够从多维输入中学习(Ibarz等,2021)。随着时间推移,越来越多的DNNs与RL相结合,使其能够解决高维空间中的问题,导致出现了机器人技术(Bhagat、Banerjee、Ho Tse和Ren,2019)和自动驾驶(Kiran等,2021)等各种新的RL研究领域。在所有三种学习方法中,监督学习主要用于预测和分类与fNIRS信号相关的认知负荷。
6.应用于fNIRS数据的机器学习和深度学习模型的文献计量学检查
本节讨论在fNIRS数据上执行的机器学习/深度学习模型的趋势。表2中提供了深度学习设计、架构和实验范式的全面总结。
表2. 从纳入研究中收集的数据描述(略,篇幅较长,请见原文,可添加微信号19962074063或18983979082获取原文)
神经科学中的大多数文章使用的fNIRS数据集都不是公开可用的。性能测量指标,如简单的准确率或其他指标如均方误差(MSE)、均方根误差(RMSE)、F1分数、真阳性或假阳性,都无法泛化,因为每项研究都有不同的测试对象、数据获取协议和不同的认知要求任务。关于心理工作负荷的fNIRS指标的研究可以分为三类,如图8所示:(1)基于ML的fNIRS分析;(2)基于DL的fNIRS分析;以及(3)用于fNIRS分析的混合AI模型。
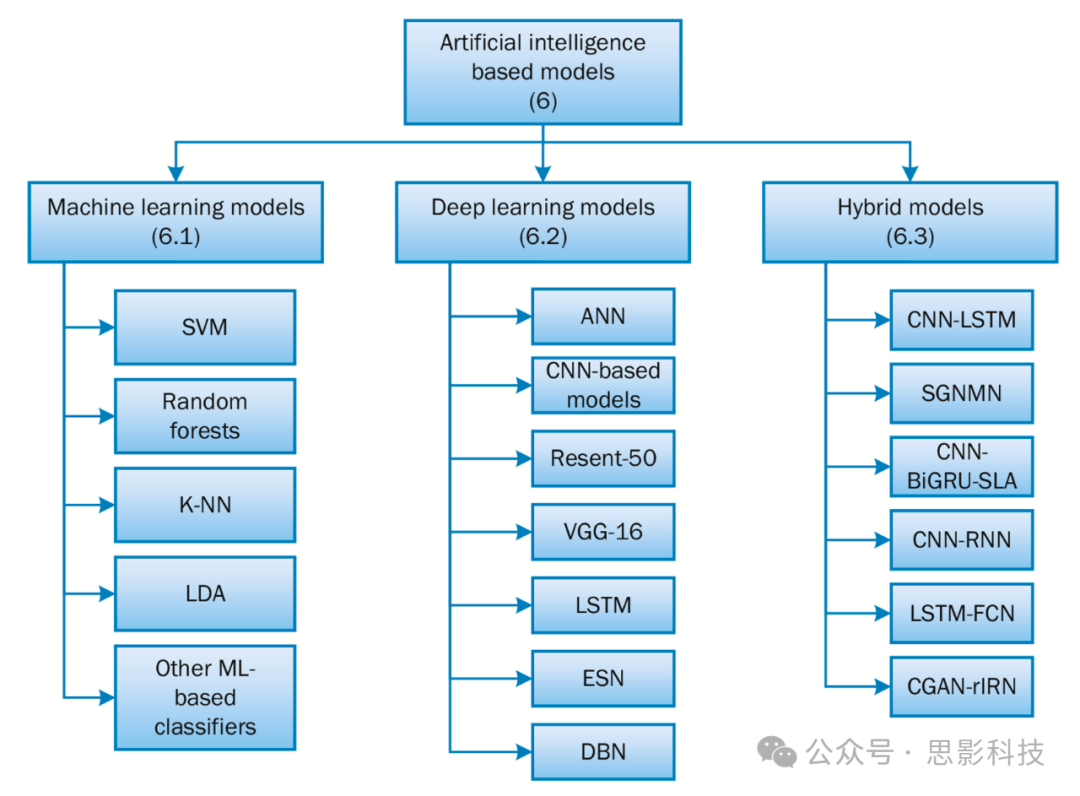
图8. 应用于认知负荷fNIRS数据的基于人工智能的模型分类法
6.1. fNIRS分析中的机器学习趋势
ML作为AI的一个子集,能够处理患者数据并模仿人类识别模式的能力。本节涵盖了分析fNIRS数据的ML方法。共回顾了25项研究,这些研究应用ML来客观评估心理工作负荷。文献中基于ML的算法总结如下。图9显示了使用ML分类器进行fNIRS数据分析的研究分布。SVM在fNIRS研究群体中成为突出的选择,其次是以处理高维数据效率著称的随机森林。在fNIRS基于机器学习的研究中,LDA和k-NN也被注意到作为应用方法。
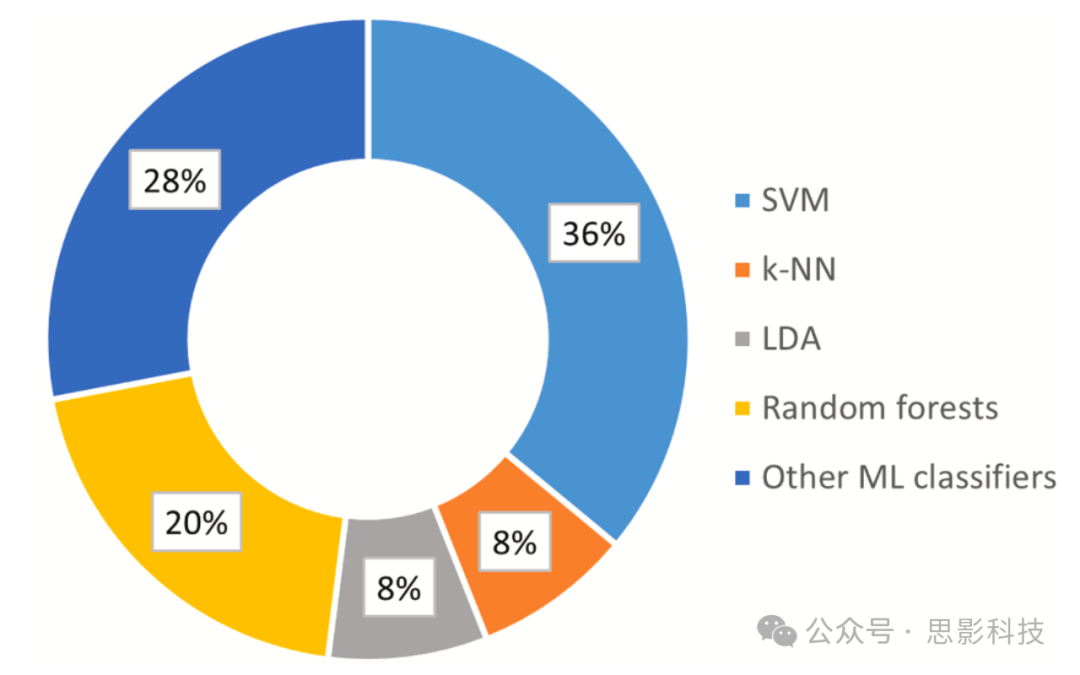
图9. 用于fNIRS数据分类的ML研究分布
6.1.1. 支持向量机(SVM)
根据我们的调查,由于其实现简单和高准确性,SVM在fNIRS信号分析中被广泛使用。SVM的理念基于结构最小化原理。它主要用于模式识别和回归分析。在高维分类空间中对数据样本进行分类时,它试图找到类之间间隔最大的最优超平面。这些超平面通过算法训练,以便分离不同类别的输入数据点。多位研究者如Gateau等(Gateau等,2015)、Asgher等(Asgher等,2019)、Keles等(Keles等,2021)、Derosiere等(Derosiere等,2014)、Dong等(Dong & Jeong,2018)、Abibullaev等(Abibullaev & An,2012)和Kurihara等(Kurihara等,2020)使用SVM来对fNIRS信号中的心理工作负荷进行分类。
Khanam等人(Khanam等,2022)对所有36个通道的传统均值、最小值、最大值、标准差(SD)、斜率和偏度特征应用了ANOVA测试。ANOVA分析表明,只有额叶和运动区域的两个通道在不同工作负荷水平之间显示出统计干扰。SVM在从两个显著通道获得的特征上进行训练,达到了71.48%的准确率。
Zhu等人(Q. Zhu等,2021)采用传统特征提取方法,基于Sternberg实验(Sternberg,1969)探究fNIRS信号与认知负荷之间的关系。实验结果强调,使用SVM预测认知负荷的显著特征因参与者而异,因为每个人处理信息的方式不同。因此,需要个性化模型而不是泛化模型来从fNIRS信号预测认知。该研究还提出了一个用于过滤、清理和建模fNIRS数据的进一步流程。
为了减少假阳性的数量,Lim等人(Lim等,2020)引入了一种名为深度贡献率的特征提取方法,该方法使用k-means聚类方法和欧几里得距离方法来识别激活和非激活通道。实验结果表明,深度贡献率获得了更好的准确率(80%),相比之下,传统基于斜率的特征获得的准确率为59.8%。
Asgher等人(Asgher等,2019)使用提出的固定值修正的比尔-朗伯定律(FV-MBLL)和传统MBLL处理fNIRS数据。结果强调,当数据样本用FV-MBLL或传统MBLL处理时,均值和峰值的组合在心算任务中产生了更好的结果。通过平衡认知任务的特征数量进行过采样,也可以提高低分类分数。
Durantin等人(Durantin等,2016)优化了卡尔曼滤波器以去除fNIRS信号中的噪声和其他伪影。为了估计模拟飞行环境中飞行员的心理状态,SVM在经卡尔曼滤波器、IIR滤波器和移动平均收敛发散(MACD)滤波器(Durantin、Scannella、Gateau、Delorme和Dehais,2014)过滤的fNIRS信号上进行训练。实验结果表明,卡尔曼滤波数据的预测准确率为77.8%,高于IIR滤波器和MACD滤波器过滤的数据。
到目前为止提出的研究并未比较SVM和ML技术。Kornev等人(Kornev等,2022)进行的研究不仅使用了SVM径向基函数进行分类,还将结果与多重回归、人工神经网络、随机森林以及分类和回归树(CART)进行了比较。虽然这项研究未能报告每种算法的平均准确率,但它从均方根误差(RMSE)和相关系数(R²误差)方面展示了SVM的高性能。
尽管SVM在fNIRS信号分析方面提供了令人期待的结果,但大多数使用SVM进行分类的研究都使用了正常大小和平衡的数据集。随着样本数量的增加,训练时间也会增加。其次,当数据中的非线性增加时,很难找到合适的核函数,因此在使用SVM进行fNIRS信号分类之前,建议始终使用适当的噪声去除技术。
6.1.2. k-近邻(k-NN)分类器
k-近邻(k-NN)算法是一种广泛用于分类和回归任务的ML方法。它基于近邻实例原理,这意味着它依靠新数据点与现有数据点之间的相似性来分类或预测其标签或值。它存储所有训练样本,每个输入实例都表示为一个向量。在k-NN中,"k"指的是在分类新数据点时要考虑的最近邻数量。该算法通过计算新数据点与数据集中所有现有数据点之间的距离来工作。然后选择k个最近邻作为与新数据点距离最近的数据点。新数据点的分类或预测基于这些k个最近邻的标签或值。k-NN中使用的距离度量可能因数据类型和具体问题而异。最常用的距离度量是欧几里得距离(Durtschi等,2021)、曼哈顿距离(Ehsani & Drabløs,2020)和闵可夫斯基距离(Iswanto、Tulus和Sihombing,2021)。距离度量的选择可能对算法性能产生重大影响(Shalika & Kumar,2021)。
与其他算法相比,k-NN需要的训练较少。它适用于输入和输出关系复杂到无法用线性模型表达的数据。为了对n-back任务期间的五个不同工作负荷水平进行分类,Saikia等人(Saikia等,2021)评估了Fine k-NN、Medium k-NN、Coarse k-NN、Cosine k-NN、Cubic k-NN和Weighted k-NN的训练时间和准确率。在分类任务中,Fine k-NN和Weighted k-NN都能达到75%的准确率,而Weighted k-NN的训练时间(4.93秒)比Fine k-NN(5.59秒)更短。
尽管k-NN与其他训练算法相比需要较少的训练时间,但它在分类过程和确定结果时需要更多的计算时间。Naseer等人(Naseer等,2016)进行的研究报告称,k-NN分类器产生的分类结果比其他ML算法的结果准确率更低。
6.1.3. 线性判别分析(LDA)
LDA是一种著名的降维和特征提取技术。它用于通过将属于不同类的向量降维到较低维特征空间来识别类的线性组合,使得每个类的特征向量与其他类分开。这种技术易于实现,计算需求较低。一些研究者如Zhou等人(X. Zhou等,2021,Zhou等,2021)和Cakır等人(Çakır等,2016)使用LDA对不同水平的心理工作负荷进行分类。LDA的主要限制是其线性特性,这阻止了在非线性fNIRS信号上产生有竞争力的结果。
Cakır 等人(Çakır et al., 2016)评估了8名飞行员的3个级别的心理工作负荷。结果表明,当LDA仅使用单个飞行员的数据进行训练时,该模型可以推广用于评估其他飞行员的心理工作负荷。该模型在预测低水平工作负荷时具有较高的准确性,但由于频繁的头部运动,在预测高水平工作负荷时准确性较低。Zhou等人(X. Zhou et al., 2021, Zhou et al., 2021)在实验室环境中研究了危险感知任务,表明当模型使用左前额叶皮层获得的特征进行训练时,LDA可以达到70%的准确率。研究使用Fisher准则从数据中选择前五个最优特征,结果表明与大脑其他区域相比,左前额叶皮层在危险感知任务中的参与度更高。
6.1.4. 随机森林
随机森林是一种基于树的集成学习方法。它通过构建多个随机决策树来建立分类器(Khan, Asadi, Hoang, Lim, & Nahavandi, 2023)。集成分类器中的每个决策树对预测类别进行投票,然后根据特定类别标签的最多票数确定预测类别。模型的集成特性帮助随机森林处理高维数据和复杂特征空间,成为处理非线性fNIRS信号的理想选择。随机森林相对于单个决策树的主要优势之一是不太可能过拟合数据。过拟合发生在模型过于复杂并捕捉训练数据中的噪声或无关模式时,导致在新的未见数据上表现不佳。通过结合多个决策树,随机森林可以减少模型的方差并防止过拟合(Balyan et al., 2022)。每棵树的随机特征选择也有助于减少树之间的相关性并增加其多样性,从而带来更好的整体性能。(Z. Khan et al., 2020, Khan et al., 2020)的研究还发现,与SVM和k-NN等其他机器学习算法相比,在随机森林中确定超参数更容易。使用随机森林进行fNIRS信号分析的示例研究包括Oku等人(Oku & Sato, 2021)、Lamb等人(Lamb et al., 2022)、M. Hasan等人(Hasan et al., 2023)、Le等人(Le et al., 2022)、Le等人(Le et al., 2018)和Varandas等人(Varandas et al., 2022)。
Varandas等人(Varandas et al., 2022)使用Corsi方块任务(Milner, 1971),而Lamb等人(Lamb et al., 2022)使用基于虚拟现实的环境来诱发认知负荷。两项研究都报告称使用随机森林对不同水平的心理工作负荷进行分类时准确率超过70%。Le等人(Le et al., 2018)使用听觉n-back任务来分类以约40公里/小时驾驶汽车时的不同水平心理工作负荷。实验结果(Le et al., 2018)显示,当使用所有通道的数据进行分类时,随机森林表现更好,通道位置对准确率没有显著影响。在另一项研究中,Le等人(Le et al., 2022)分析了老年驾驶员的心理状态,表明在轻松环境、试驾和停车场驾驶时观察到显著变化。结果表明,随机森林在准确率、真阳性率和F1分数方面的表现优于朴素贝叶斯、判别分析、SVM、决策树和K-NN方法。
尽管随机森林通过使用大量决策树能够处理fNIRS高维和非线性数据,但它们仍有一些局限性。根据数据的性质和复杂性,需要大量的树来克服大方差问题。如果参数选择不当,随机森林可能产生虚假结果。因此,始终建议使用交叉验证方法来优化随机森林模型的参数(Sundararajan et al., 2021)。
6.1.5. fNIRS研究中认知负荷分析的多样化机器学习方法
除了广泛使用的机器学习分类器(如SVM、k-NN、LDA和随机森林)外,逻辑回归和gentle boost也被用于fNIRS认知负荷分析。虽然这些方法可能不那么普遍,但最近的研究表明它们在增进对认知负荷动态的理解方面的有效性。例如,A. Howell-Munson等人(Howell-Munson et al., 2023)将行为数据(包括反应时间和任务难度)与fNIRS结合起来,全面分析认知负荷。他们的方法采用逻辑回归,与其他分类器相比表现出更优异的结果。同样,T. I. Touhid等人(Touhid et al., 2023)进行的研究深入比较了Gentle Boost算法与LDA、SVM和随机森林等传统分类器。实验结果表明,Gentle Boost,特别是在使用基于Haar小波的特征时,表现优于其他方法。这表明Gentle Boost的独特特征,结合创新的信号处理技术(如Haar小波变换),有助于更好地理解fNIRS数据捕获的认知负荷动态。
除了广泛认可的机器学习分类器外,一些研究人员提出了自己的基于机器学习的分类方法来分析fNIRS数据中的认知负荷动态。例如,Y. Zhang等人(Y. Zhang et al., 2022, Zhang et al., 2022)引入了一种结合卡尔曼滤波和自适应高斯混合模型的新型分类方法。该方法旨在识别fNIRS信号中的复杂模式。他们的研究结果显示分类准确率显著提高,相比传统的GMM、SVM和LDA分类器,他们的分类器提高到了87%。这表明卡尔曼滤波和自适应高斯混合模型的整合为从fNIRS数据中提取有意义的信息提供了一个稳健的框架,并提高了认知负荷分析的效果。同样,S. Cakar等人(Cakar & Yavuz, 2023)提出了广义线性混合效应模型树,该模型将线性混合模型(LMM)与专门设计用于分析fNIRS重复数据的机器学习模型相结合。通过利用LMM和机器学习方法的优势,该研究旨在解决fNIRS实验中与重复测量相关的复杂性。
6.1.6. 使用机器学习算法的fNIRS功能连接性
大脑的确切工作机制尚未完全了解。多项研究基于大脑关键区域的fNIRS反应来研究认知任务。Derosiere等人(Derosiere et al., 2014)分析了大脑右顶叶区域的氧合血红蛋白(HbO2)特征,发现与大脑其他部位相比,这些特征对认知负荷的分类更敏感。同时,Keles等人(Keles et al., 2021)对学生和外科医生在模拟手术任务期间进行的研究表明,背外侧和腹外侧区域附近的左前额叶皮层神经激活明显高于其他区域。Izzetoglu等人(Izzetoglu et al., 2021)在模拟驾驶任务中也评估了HbO2特征与前额叶皮层区域之间的关系。在慢速驾驶任务期间,HbO2特征与右前额叶皮层激活之间观察到高度负相关。使用这些特征训练的逻辑回归模型达到了97.5%的准确率。
6.2. fNIRS分析中的深度学习趋势
与机器学习不同,DNN架构包含许多隐藏层。多层网络具有有限数量的非线性元素(即激活函数和神经元),这使它们比机器学习算法更灵活和稳健。第一层和最后一层分别定义为输入层和输出层,而中间层定义为隐藏层。根据神经元和隐藏层的数量,这些模型可以轻松达到数千甚至数百万个可训练的超参数。在处理较小数据集时,深度学习容易过拟合;因此它们更适合处理大规模数据集(J. Wang et al., 2021)。尽管如此,深度学习可以自动从数据中学习有用的特征,减少人工特征工程的工作。我们确定了11项关于深度学习用于fNIRS信号分类的研究。近一半的研究使用了CNN模型,而四项研究利用了深度信念网络(DBN)、长短期记忆网络(LSTM)、人工神经网络(ANN)和回声状态网络(ESN)。根据我们提出的分类,在fNIRS信号中使用CNN和LSTM以外的算法较少见。使用深度学习算法进行分类的研究总结如下:
CNN的设计方式是专门将图像作为输入。迄今为止已经提出了许多CNN变体,在计算机视觉(Balasundaram et al., 2023)、自然语言处理(NLP)(Ahmed & Wang, 2023)、图像分割(M. A. Khan et al., 2020, Khan et al., 2020)、遥感(Boulila, Ghandorh, Khan, Ahmed, & Ahmad, 2021)和信号处理(Ghandorh et al., 2021)领域都取得了出色的结果。在fNIRS信号分类中,输入公式策略、特征提取和特征选择方法会随架构的不同而显著变化。深度学习模型层次化地从数据样本中提取特征。任何CNN架构的性能都取决于卷积层、池化层和全连接层的数量。卷积层使模型能够从数据中学习复杂特征,池化层不仅提高模型性能,还降低特征图的维度,最后全连接层将复杂特征映射到输出。在训练过程中,CNN不断优化权重和其他参数,这需要时间,但一旦模型训练完成,分类所需时间就会减少。
Khalil等人(Khalil et al., 2022)提出了一个6层CNN来分类四个级别的n-back任务。首先使用少数参与者的数据来训练CNN模型,然后使用同一个预训练模型从数据中提取特征并采用迁移学习重新训练模型。虽然这项工作没有与其他机器学习/深度学习方法进行比较,但它比较了所提方法与传统训练方法的训练时间。结果表明他们的方法有助于减少训练时间。
Wang等人(Wang et al., 2022, Wang et al., 2022)使用VGG-16模型研究大脑的血流动力学变化。作者没有使用传统特征,而是将52个通道的fNIRS信号转换为图像,然后用于训练CNN模型。据报道,他们的工作使用所提出的特征提取模型达到了100%的准确率。这项工作没有与其他机器学习/深度学习模型进行比较,但从准确率、真阳性率(TPR)和假阳性率(FPR)方面评估了模型。
Liu等人(R. Liu et al., 2021)评估了自编码器在分析fNIRS数据方面的性能。该研究通过在手工制作的特征和从卷积自编码器获得的特征上训练模型,展示了从回声状态网络(ESN)提取的特征的重要性。实验结果表明,从ESN自编码器提取的特征产生了更好的结果,准确率为80.61%。
Benerradi等人(Benerradi et al., 2019)使用7层CNN来分类两个和三个级别的心理工作负荷。分类结果也与SVM和逻辑回归的结果进行了比较。在3类模态分类中,SVM的表现优于其他模型,但在两类模态中,CNN达到了最高的准确率。准确率低的原因可能是数据量小(9名参与者)且样本大小仅为9秒。其次,他们的模型架构只有两个卷积层,这限制了从数据中提取特征的能力,导致CNN在三类分类任务上表现较差。
Kwon等人(Kwon & Im, 2021)采用CNN模型对心算任务和空闲状态下的fNIRS信号进行分类。该架构使用了进化归一化-激活层(H. Liu, Brock, Simonyan, & Le, 2020),而不是传统的归一化层。dropout概率设置为0.5。在不使用任何特征提取方法的情况下,所提出的CNN架构优于EEGNet和其他机器学习分类器。
Qing等人(Qing et al., 2021)利用CNN输入层作为解码数据矩阵来处理15秒、30秒和60秒fNIRS信号长度的常规特征。该方法达到了86.3%的准确率。Zaman等人(Zaman & Islam, 2021)使用Wigner-ville分布将不同窗口大小的fNIRS信号转换为2D图像,并使用ResNet50(He, Zhang, Ren, & Sun, 2016)评估结果。所提出的特征提取方法将准确率从89%提高到98%。同样,在他们的研究中,Ho等人(Ho, Gwak, Park, Khare, et al., 2019)比较了9层CNN与5层DBN的性能。对数据集应用PCA以降低维度。结果表明,当使用血红蛋白差异(HbT)特征训练时,两种模型都表现出更好的性能。然而,使用氧合血红蛋白(HbO)和脱氧血红蛋白(HbR)特征时观察到较低的准确率。尽管给出了出色的分类准确率,CNN也有其缺点。CNN需要大量数据进行训练,但研究(Cascianelli et al., 2018)使用的测试对象数量有限。因此,在使用CNN时需要招募更多的测试对象以增加数据集的大小。CNN可能在较小的数据集上获得高准确率,但可能会导致过拟合(Ma et al., 2020)。由于fNIRS信号高度依赖于时间,信号变化发生在一系列时间尺度上。然而,CNN设计用于捕捉数据的局部特征,而没有明确建模时间动态。fNIRS信号的固有性质与CNN捕捉时间依赖性的有限能力之间的这种不匹配可能会限制CNN模型在fNIRS数据集上的性能。此外,由于涉及大量参数,无法表达分类过程中涉及的推理过程的逻辑和实际机制。
为克服基于CNN模型的时间序列分类问题,提出了LSTM和RNN模型。通常,LSTM模型在神经人机工程学研究中常用,因为RNN中存在梯度消失问题。LSTM模型具有输入门、遗忘门和输出门,使模型能够处理序列数据,因此与其他模型相比更适合fNIRS信号。这些模型通过考虑过去和未来来预测未来信息,这在使用CNN和其他模型时是不可能的。Asgher等人(Asgher et al., 2020)使用具有4个LSTM层和4个密集层的模型来分类四个不同层次的心理工作负荷。该模型在进行心算任务时从血流动力学响应中提取的均值和斜率特征上进行训练。分类结果与SVM、k-NN、具有3层网络拓扑的ANN以及具有2个卷积层、1个最大池化层和4个密集层的CNN进行了比较。开发的LSTM优于其他模型,达到89.01%的准确率,其次是CNN的87.45%。与众所周知的CNN架构(如VGG-16或ResNet)相比,他们工作中使用的CNN模型实际上包含很少的层。在这项研究中可以使用具有复杂层的CNN以获得更好的结果。在他们的工作中,LSTM模型优于CNN,但由于缺乏关注将时间序列数据转换为分类任务的研究,CNN模型可能比其他深度学习方法表现更好。
6.3. fNIRS分析中的混合模型趋势
通常,机器学习方法在用于分析较小数据集或手工制作的特征时较为可靠。同样,深度学习技术倾向于作为黑盒运作,并通过可训练的超参数在特征提取方面表现更高效(E. Q. Wu et al., 2021)。仅通过改进机器学习的数学模型或增加深度学习模型中的神经元或隐藏层数量,都无法实现性能的提升。通过分析数据集的信息来结合两种方法的方式导致了混合模型。我们发现了四项关于用于fNIRS信号分类的混合模型的研究。本综述中的大多数混合模型将CNN层的卷积运算符与RNN、LSTM或GRU相结合(Lu et al., 2020, Saadati et al., 2021, Wang et al., 2021)。CNN的主要目的是提取特征,而RNN、LSTM或GRU可用于处理数据依赖性。两者的结合使其非常适合从fNIRS信号中提取特征,同时利用当前和过去的数据样本来学习工作负荷模式的性质。文献表明,这些混合模型能够在有噪声数据的情况下对受试者的心理工作负荷进行分类,并将模型效率提高10%至15%。此外,我们还发现了一项使用GAN进行分析的研究。Gt等人[5]提出了一个基于GAN的网络来分类fNIRS信号,特别是使用基于卷积的生成对抗网络(CGAN)来生成合成fNIRS信号。他们还提出了修改版的Inception Net(rIRN)来分类fNIRS信号。该模型在大小为160x10的真实和合成特征上进行训练。通过最大平均差异(MMD)、结构相似性指数度量(SSIM)和峰值信噪比(PSNR)评估了生成信号的质量。实验表明,将数据集增加到两倍可以提高模型的准确率,而进一步增加数据集大小会降低准确率。他们还比较了rIRN与IRN和具有不同层的CNN的性能,注意到每个模型对准确率的影响相似,但rIRN产生了最高的准确率。对于数据集的分布,既没有应用k折交叉验证也没有应用LOOC交叉验证。
到目前为止提出的大多数研究都使用各种分类算法测试了收集的数据集。通过比较准确率指标或特征提取方法来强调最佳算法是不恰当的。每项研究都有其自己的架构设计、输入处理方法和独特的特征选择技术。识别最佳分类算法是一项具有挑战性的任务,因为研究人员通过使用一个以上的机器学习或深度学习方法来评估算法的有效性,并找到最合适的方法。尽管如此,本综述提供的分析有助于揭示用于认知负荷分析的基于机器学习/深度学习的算法的未来研究方向。
7.讨论和挑战
本文全面概述了采用机器学习和深度学习方法进行认知负荷分类的研究方法。我们确定了45项利用fNIRS信号来识别不同水平认知负荷的实验研究。在我们的系统综述中,我们进行了初步分析,以确定每个采样研究中使用的认知任务。观察到了一系列认知任务,一些研究采用了传统范式,如n-back任务、stroop任务和心算任务。此外,所研究文献的一个值得注意的方面显示出一种分歧,某些研究设计了与飞行、驾驶和基于游戏的场景等活动相关的独特任务。这些研究中的一个一致发现与大脑皮质激活增加和认知负荷增加之间的观察到的相关性有关。这与认知负荷理论的概念框架相一致,证实了认知负荷随着当前任务所施加的需求而成比例增加的前提。结果强调了fNIRS信号作为认知负荷指标的稳健性。
在应用机器学习方法时遇到的一个普遍问题是与数据需求相关的固有挑战,通常需要比传统方法更大的数据集才能达到相似的性能水平。这已成为一种范式转变,它简化了fNIRS信号处理流程并将其转变为端到端任务。这种范式转变具有重要的前景,简化了与数据处理和分析相关的复杂性。深度学习技术的整合有潜力通过不仅缓解fNIRS数据带来的挑战,还通过提供更有效的信号处理方法来革新认知负荷分类。
为了超越各种方法之间的竞争,并提供一个全面的框架来指导未来在自动认知负荷推断领域的努力,以及解决与fNIRS数据相关的某些特殊性(如图10所示),阐明构建认知负荷推断流程的独特方法变得非常重要。这些考虑意味着一组特定的指导原则和方法应该被纳入认知负荷推断的人工智能算法的设计和实现中。
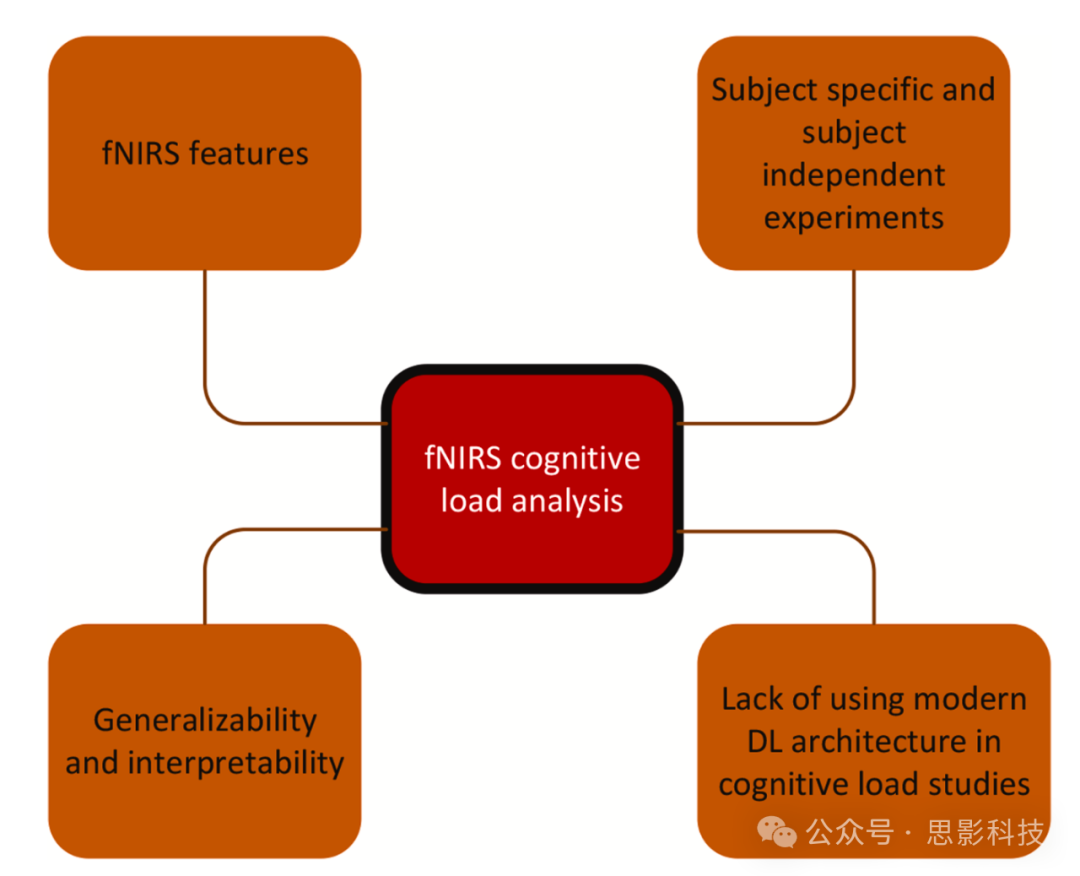
图10. 与fNIRS数据认知负荷分析相关的挑战
7.1. fNIRS特征
不同脑活动的分类很大程度上依赖于从血流动力学信号中提取的特定特征。目前,许多研究利用机器学习技术有效地使用fNIRS数据来分类不同水平的心理工作负荷。通过分离出与特定类别特征紧密对应且与其他类别特征显著不同的特征,分类过程在捕捉血流动力学信号差异方面变得更加有效(L. Wu, Liu, Ward, Wang, & Chen, 2023)。然而,由于众多的fNIRS通道,fNIRS数据的高维度性带来了重大挑战,引入了机器学习中众所周知的维度灾难问题。在fNIRS信号领域,研究人员往往缺乏对相关特征的全面了解,导致包含了大量候选特征以更好地表示该领域。血流动力学信号(如HbO2、dHb和HbT)由于其包含大脑活动相关信息的能力,为特征选择提供了广泛的选择(Z. Wang, Fang, & Zhang, 2023)。这些特征的不同组合提供了分类所需的区分信息。特征选择也取决于个体活动,HbO2、dHb和HbT的平均值、峰值、方差、偏度、峰度和斜率值在fNIRS研究中经常被使用。在fNIRS研究的初始阶段,研究人员通常计算整个任务期间血红蛋白氧合作用的浓度变化(Murata, Sakatani, Katayama, & Fukaya, 2002)。这种方法涉及呈现显示大脑氧合变化的时间序列数据以供视觉检查。然而,这些方法容易出错,特别是在噪声和干扰水平增加的情况下。为了解决这个问题,已经应用了各种统计分析方法来提高从fNIRS信号中提取特征的准确性和可靠性。
在文献中,已经提出了各种方法从fNIRS数据中提取皮质活动,主要利用HbO2的变化。fNIRS研究中常用的统计技术包括Wilcoxon符号秩检验、Shapiro-Wilk检验、t检验和方差分析(Bak et al., 2022, Durantin et al., 2016, Keles et al., 2021, Khalil et al., 2022)。这些方法根据条件方差比较条件之间的差异。为了避免对刺激响应中HbO2和dHb时间变化的确切形状或时间做出假设,这些方法通常取任务期间的平均值。从fNIRS信号中提取的特征通常提供一个称为p值的度量,表示显著性水平。然而,重要的是要认识到与解释p值相关的潜在问题。例如,p值为0.05意味着如果零假设为真,则有5%的机会获得观察到的结果。简单来说,如果进行100次统计检验,并且零假设对所有检验都为真,预计会有5次在p<0.05水平上被认为显著。这种统计现象强调了谨慎解释p值的重要性,因为随着进行的统计检验数量增加,偶然获得显著结果的概率也会增加。
此外,GLM也是一种流行且适应性强的分析技术,用于在个体和群体水平上检查fNIRS信号(Y. Zhang et al., 2022, Zhang et al., 2022)。由于其对定量和定性自变量的适应性,它非常适合捕捉认知过程的复杂动态。在fNIRS研究中,GLM在分析数据的功能时间线方面发挥重要作用,与大脑中观察到的实际血流动力学响应相一致。GLM分析中的数据功能时间线涉及追踪HBO2和dhB信号随时间的变化。该方法涉及多重回归分析,其中GLM作为回归变量的线性组合来预测或解释相关变量。在fNIRS研究中,这些回归变量被精心选择以代表各种实验条件或认知状态,允许对潜在的神经过程进行全面检查。除了前面提到的传统特征提取方法外,脑活动分类领域的研究人员还探索了其他方法,融入了频域特征,例如基于小波的特征、Haar小波和Wigner-Ville分布,以揭示血流动力学信号中的不同模式。频域特征通常应用于信号处理,通过将时间序列数据分解为不同的频率成分来分析。在fNIRS研究中,频域分析被用来提取捕捉血流动力学信号时间变化的特征。这种方法允许识别与不同认知过程相关的特定频率成分,为分类任务提供有价值的信息。此外,一些研究人员提出了他们自己的无监督特征提取方法,引入了新技术来捕捉脑活动的独特方面。这些方法通常旨在识别通过传统方法可能无法发现的模式或特征,增强了可用于分类的信息丰富度。
前面描述的特征提取方法在认知负荷研究中得到了广泛应用。值得注意的是,这些方法在血流动力学信号、fNIRS数据的分析中发挥着关键作用。虽然t检验和方差分析等传统统计技术在提取特征方面一直占主导地位,但机器学习的进步引入了深度学习方法,由于其深层神经或基于卷积的架构,这些方法通常绕过了显式特征提取的需要。图11展示了fNIRS研究中机器学习和深度学习框架内特征提取策略的比较视图。这个图不仅说明了统计特征提取方法的使用,还突出显示了选择使用原始fNIRS数据的研究。有趣的是,深度学习方法的兴起并没有消除某些研究中特征提取的使用。尽管深度神经网络具有自动学习分层表示的固有能力,但在某些情况下,研究人员仍将特征提取方法整合到深度学习框架中。这种整合旨在提高模型的可解释性或从血流动力学信号中提取神经网络单独可能无法有效捕捉的特定信息。值得注意的是,每种特征提取方法,无论是传统的还是新颖的,都有其自身的优点和局限性。特定方法的选择取决于研究的目标和所考虑数据集的特征。t检验和方差分析等传统统计技术以其简单性和易于解释而闻名。它们提供了特定实验条件下特征平均值和方差的洞察,有助于理解脑活动的差异。另一方面,包括小波特征、Haar小波和Wigner-Ville分布在内的频域方法提供了对血流动力学信号时间和频率特征的更全面评估。这些应用于信号处理的方法允许将时间序列数据分解为不同的频率成分。在fNIRS研究中,频域分析变得特别有价值,因为它能够识别与不同认知过程相关的特定频率成分。传统和新颖特征提取方法的共存突出了脑活动分类领域所需的多功能性和适应性。研究人员继续探索和完善这些技术,以应对fNIRS数据维度带来的挑战,确保提取的特征不仅相关,而且对心理工作负荷和其他认知状态的准确分类有意义的贡献。
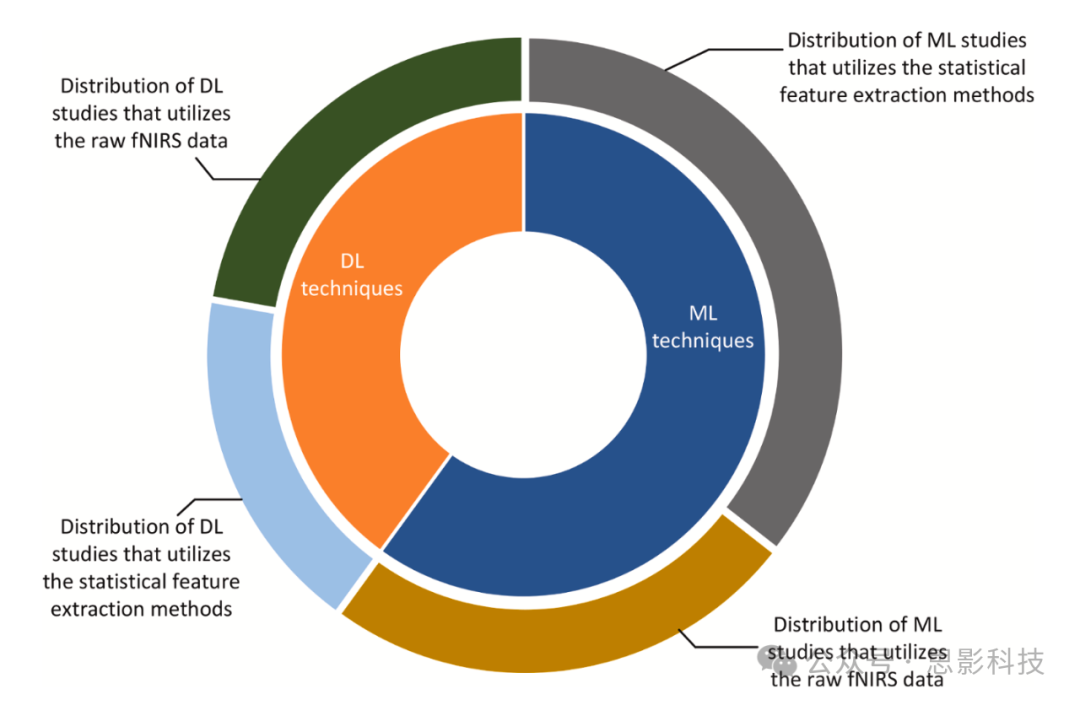
图11. 机器学习和深度学习fNIRS研究中特征提取策略的比较视图
7.2. 特定受试者和受试者独立实验
fNIRS数据分类性能的评估通常以离线方式进行,使用预先记录的数据集。在现有文献中,研究人员普遍采用k折交叉验证(k-fold CV)或留一交叉验证(LOOCV)方法来衡量其模型的有效性。在k折交叉验证的背景下,数据集被划分为k个子集或折。模型在k-1个折上训练,在剩余的一个折上评估。这个过程重复k次,每个折恰好作为一次测试集。然后对结果取平均值,以提供一个全面的性能指标,该指标考虑了训练和测试数据的变化。另一方面,LOOCV涉及将单个数据点留作测试集,同时在剩余数据集上训练模型。这个过程对数据集中的每个数据点进行迭代重复,确保每个实例恰好作为一次测试集。最终的性能指标是通过对所有迭代的结果取平均值得出的。LOOCV在处理较小的数据集时特别有用,因为它最大化了可用数据在训练和测试中的使用。图12说明了研究界使用不同交叉验证方法的普遍性。值得注意的是,在这些方法中,10折交叉验证已被研究人员广泛接受和频繁使用。其次是5折、8折、LOOCV和20折CV方法,每种方法在学术界都显示出不同程度的采用。尽管特定的交叉验证方法很受欢迎,但分析中一个值得注意的发现是,42%的研究没有明确提及所采用的验证方法。
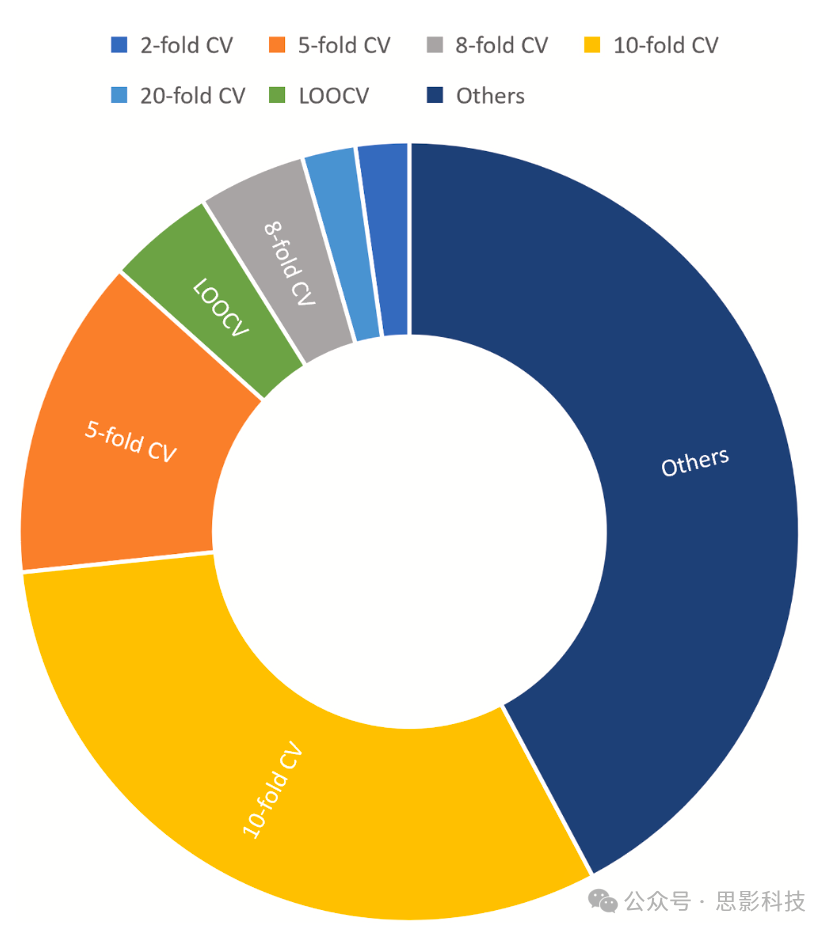
图12. 使用不同CV方法的研究分布
fNIRS数据表现出固有的受试者依赖性和会话依赖性,具有显著的受试者间和会话间可变性(Huang et al., 2021)。因此,当模型在相同受试者或会话上进行训练和测试时,性能结果可能与在训练阶段未遇到的新受试者或会话上测试时获得的结果有显著差异。为了解决受试者数据中受试者依赖性和会话依赖性带来的挑战,已经设计了各种技术。这些技术包括受试者内、特定受试者、受试者依赖、跨受试者和受试者独立方法。受试者内方法或特定受试者方法涉及在同一受试者上进行训练和测试,关注个体变化。另一方面,跨受试者方法涉及在一组受试者上训练并在另一组受试者上测试,旨在实现跨个体的泛化。受试者独立方法旨在创建可以在一组受试者上训练并无缝应用到完全新的一组受试者的模型,从而解决泛化的挑战。
尽管存在这些方法论进展,但当前关于认知负荷和fNIRS分类的文献中仍存在明显的差距。在该领域的研究中缺乏受试者内、特定受试者、受试者依赖和跨受试者方法的具体实施。使用fNIRS数据进行认知负荷分类时,显著的受试者间可变性构成了重大挑战。在大多数研究中,认知负荷的机器学习/深度学习模型通常使用k折或LOOCV方法进行训练和测试。这种训练方法因其能够产生更高的分类准确率而受到青睐(Y. Zhou et al., 2021, Zhou et al., 2021)。然而,一个显著的缺点是其跨不同受试者的泛化能力有限。尽管k折和LOOCV方法在训练认知负荷分类模型时很普遍,但在fNIRS社区中缺乏这些交叉验证技术与特定受试者方法之间的比较分析。相反,在EEG和其他生理信号领域等相关领域已经进行了这样的评估。为了有效地解决这个挑战,未来的研究应优先采用特定受试者方法,在训练和测试阶段明确考虑每个受试者的个体特征。
7.3. 认知负荷研究中的泛化性和可解释性挑战
fNIRS的可解释性缺乏在认知负荷研究中构成了重大障碍。虽然fNIRS是捕捉神经活动和理解认知过程的有价值工具,但它经常难以为其发现和背后的潜在机制提供透明的解释。fNIRS分析中的一种常见方法涉及使用传统机器学习和深度学习技术,将人工智能视为黑盒而不深入研究结果的可解释性。在没有充分可解释性的情况下普遍使用传统机器学习和深度学习方法限制了我们对fNIRS捕捉的认知负荷现象的理解。虽然这些方法可以基于fNIRS数据产生准确的预测或分类,但它们往往缺乏提供对驱动这些预测的神经过程和特征的有意义见解的能力。神经学领域的研究人员使用基于CNN、LSTM、GAN和自编码器的模型来分析fNIRS数据。然而,文献中存在明显的差距,因为缺乏专门研究使用fNIRS数据在认知负荷领域中深度学习模型的泛化性和可解释性的研究。
为了解决这个差距,在分析fNIRS信号时利用逐层模型解释技术至关重要。这些技术提供了对深度学习模型内部工作原理的有价值见解,并对与认知过程相关的特定脑区、功能连接和神经模式提供了更深入的理解。几种逐层模型解释技术,如局部可解释模型无关解释(LIME)(Ribeiro, Singh, & Guestrin, 2016)、梯度加权类激活映射(GradCAM)(M. Han & Kim, 2019)和逐层相关性传播(LRP)(Bach et al., 2015),可以用于fNIRS数据的分析。通过将这些逐层模型解释技术应用于fNIRS数据,研究人员可以获得对认知过程潜在神经机制的有价值见解。这些技术能够识别对认知负荷、注意力、记忆或其他认知状态有贡献的特定脑区、功能连接和神经模式。此外,这些解释可以为深度学习模型做出的预测提供可解释的证据,增强对结果的理解和可信度。此外,将这些逐层模型解释技术与传统统计分析相结合可以导致对fNIRS的全面理解。通过整合两种方法的优势,研究人员可以以更稳健的方式验证和解释发现。这些知识使研究人员能够专注于大脑中最有信息量的区域或波长,实现对认知负荷更有针对性和可解释的研究。此外,结合传统机器学习/深度学习方法和XAI技术的混合模型在弥合fNIRS研究中准确性和可解释性之间的差距方面具有前景。这些模型可以保持机器学习/深度学习算法的预测能力,同时为其结果提供透明的解释。
7.4. 认知负荷研究中缺乏使用现代架构
各种分类器已与机器学习算法结合使用,以解决分类或标记任务并训练系统量化不同水平的认知工作负荷。使用fNIRS数据的认知负荷分类已通过各种机器学习算法进行探索,包括SVM、k-NN、LDA和随机森林。以其简单性和高准确性著称的SVM在fNIRS信号分析中被广泛使用,展示了其在心理工作负荷分类中的有效性。k-NN分类器以其较短的训练时间著称,尽管在分类过程中计算需求增加。LDA的简单性和低计算要求得到认可,但其线性特性在处理非线性fNIRS信号时面临挑战。随机森林因其处理高维和非线性数据的能力而受到赞扬,研究报告在心理工作负荷分类方面取得成功。
还讨论了深度学习模型,特别关注CNN和LSTM网络。CNN最初设计用于图像输入,研究探索了其将fNIRS信号转换为图像并分类大脑血流动力学变化的能力。CNN的优势,如高准确性,与其局限性形成对比,包括数据规模要求和潜在的过拟合。LSTM解决时间动态问题,在某些研究中表现优于其他机器学习方法。
在过去几年中,与早期模型相比,较新的深度学习架构如GhostNet(K. Han et al., 2020)、Densenet(Y. Zhu & Newsam, 2017)和Capsule Net(Sabour, Frosst, & Hinton, 2017)因其改进的稳健性、优化和更好的泛化能力而受到关注。这些架构在各种计算机视觉任务中取得了成功,但它们在使用fNIRS信号进行认知负荷分类方面的潜力在很大程度上仍未被探索。此外,最近基于transformer的模型的兴起(最初设计用于自然语言处理任务)为深度学习引入了新的维度。与传统架构如GAN相比,具有注意力机制的transformer展示了卓越的生成式AI能力。transformer中的注意力机制使它们能够捕捉数据中的复杂关系,这可能对涉及复杂模式的任务(如认知负荷研究中发现的)有潜在优势。必须专门在使用fNIRS技术进行认知负荷分类的领域评估这些现代深度学习架构和基于transformer的模型。它们在处理复杂关系和捕捉模式方面的增强能力可能导致在理解与认知过程相关的神经活动方面的准确性和可解释性的提高。随着认知负荷研究领域的持续发展,采用这些较新的深度学习架构和基于transformer的模型可以有助于更全面地理解大脑对认知任务的响应,为使用fNIRS数据进行认知负荷分类的复杂性提供新的见解。
8.未来影响和局限性
本文的主要局限性在于它仅关注AI和认知负荷与fNIRS的关系,而排除了运动想象、压力和情绪识别等领域。排除这些领域的主要原因是它们要么范围很广,要么已经被之前解释过。未来需要改进AI模型的解释和临床适用指标的工作,以将AI模型转化为日常使用。
在本综述中,我们探讨了使用fNIRS指标量化各种认知要求任务期间心理工作负荷的可行性。开源库的存在使科学界能够相对容易地设计深度学习架构。在深度学习研究中,使用自己的数据集的趋势有所增加。其次,fNIRS信号受年龄、性别、人口统计和数据集大小的影响很大(Huang et al., 2021)。如表2所示,迄今为止的研究考虑的参与者数量有限且性别分布不均。此外,对数据集的分析基于对fNIRS信号的一般解释;因此,很难根据已发表研究中使用的各种指标来比较模型性能。
尽管AI取得了惊人的发展,但fNIRS研究仍处于早期发展阶段。不同脑区之间以及不同认知要求任务之间的关系仍需要进一步研究。一些研究表明,在认知要求任务期间,左前额区域的神经激活较高,而一些研究表明右前额区域的特征最适合深度学习分析(Derosiere et al., 2014, Keles et al., 2021, Kornev et al., 2022)。第7节中提到的挑战列表不仅在神经学领域有效,而且适用于其他健康领域。近年来,AI已成为一个日益流行的研究主题,特别是在与认知负荷相关方面。本研究中关于认知负荷的大多数文章都关注AI这一新兴技术,这些文章都是在过去三年内发表的。几乎所有比较深度学习与机器学习或使用原始数据而不是手工制作特征的研究都报告了小但有意义的改进。我们观察到模型设计和设计深度学习模型方面有改进的空间,因为几乎所有研究都使用自己的数据集来对AI模型进行基准测试。不愿意共享数据或模型架构限制了工作范围在小规模。
迄今为止已经提出了各种分析fNIRS信号的机器学习和深度学习模型,这使得由于出版物中缺乏比较而难以识别表现最好的模型。fNIRS信号的延迟响应导致与在线分析同步困难。迄今为止的研究主要强调离线基础上的特征选择和分类。fNIRS研究的下一个重大飞跃可能是使用深度学习模型实现自动化。AI可能在不久的将来推进神经科学。研究机构应该在不损害参与者隐私的情况下以标准化格式提供人口统计丰富(年龄、性别、种族)的fNIRS数据。便携式可穿戴fNIRS传感器的进步将有效减少测量误差。数据的可用性也将帮助研究人员设计优化的模型架构,这些架构可以通过使用TensorFlow Lite等工具部署到移动设备上。这将使神经科学家能够通过使用廉价和便携的fNIRS设备开发实时应用程序。
9.结论
fNIRS是一个重要工具,可以对人类表现任务中的认知负荷进行分类。本研究使用PRISMA协议回顾了用于评估认知负荷的机器学习/深度学习方法。在本文中,我们回顾了将基于深度学习的分类方法应用于参与者在n-back任务、Stroop任务和模拟游戏任务期间收集的fNIRS信号的研究。综述研究中的模型架构根据输入公式和考虑的任务而显著变化。这些架构差异可能对模型的性能和AI系统的整体有效性产生重大影响。本文指出了机器学习/深度学习算法的关键优势,并调查了最先进的机器学习/深度学习方法对fNIRS信号的主要成就和局限性。通过分析45篇利用机器学习/深度学习模型基于fNIRS数据分类认知负荷的文章,得出结论:超过70%的研究直接或以混合架构的形式将CNN应用于fNIRS信号。推断出大多数研究人员采用了特征提取技术以充分利用机器学习/深度学习模型的潜力。一些研究人员还旨在利用卷积层分析数据的局部特征。特征提取方法确保输入可以直接用于模型训练。少数研究还表明,从大脑左或右前额叶皮层提取的特征可能是影响模型准确率的因素。AI模型可以使用各种方法进行训练,模型的效率取决于fNIRS信号预处理的质量。深度学习算法计算成本高,但在低预处理需求下优于机器学习算法。我们强调,认知负荷领域深度学习模型的未来研究不仅旨在提高模型的准确性,还检查实用性方面,如稳健性、解释和优化。
我们发现混合模型与传统模型相比通常能够获得更好的性能,并且在准确分类不同水平的心理工作负荷方面具有更大的潜力。将卷积层与循环层结合的混合模型能够优于传统方法。我们建议对混合模型进行深入研究是有益的,特别是卷积层、全连接层和循环层的数量和排列。由于认知研究仅关注客观和系统范式,没有任何分类技术可以被宣称为一般使用的最佳选择。文献中已经确定了几个挑战,包括模型可解释性和特征工程。我们期望AI通过将深度学习技术的最新进展转移到fNIRS信号的大规模多模态数据中,有潜力应对这些挑战。

















 1696
1696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









