









之前给你的录像对应版本是将你之前提供Xilinx下的那个工程,后来客服和你交流了下,你的目的就是需要实现mpeg2解码部分,而对音频等模块不需要。
这里,我们将其中的涉及的部分提取,进行仿真说明。并映射到DE2-115开发板。MPEG2解码的整个结构如下所示:

即,我们需要实现如上框图中的红色部分。即从视频流输入到最后的视频输出这两个部分。而原始的视频输入是事先将视频保存到开发板中的SDRAM中,此外,由于ALTERA开发板中的外部存储器为:

即该开发板外部用于两个SDRAM。
因此,这里的方法和你提供的那个方法有很大的不同,这里,由于只有两个外部存储器,所以本方法相对于你下载的那个代码而言,有一定程度的简化。
整个软件的流程如下所示:
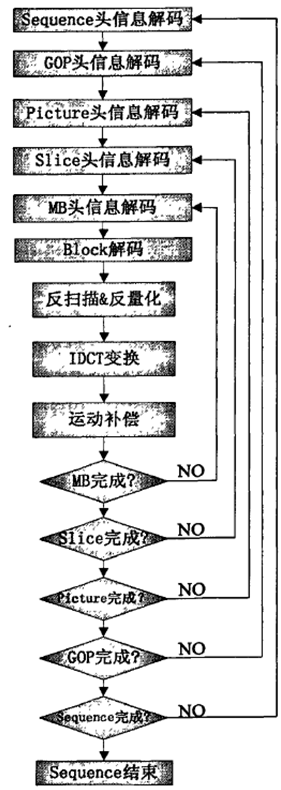
代码的原始输入流为MPEG2的编码输入。
通过上面的分析,本方案可以用如下的结构进行标示:

这个模块分为三个部分,一个是上半部分的MPEG2解码部分,一个是下面的视频显示,最后一个是系统的控制管理部分。
二、MPEG2原理简介
MPEG-2系统是将视频、音频及其它数据基本流组合成一个或多个适宜于存储或传输的数据流的规范,如图1所示。符合ITU-R. 601标准的、帧次序为I1B2B3P4B5B6P7B8B9I10数字视频数据和符合AES/EBU标准的数字音频数据分别通过图像编码和声音编码之后,生成次序为I1P4B2B3 P7B5B6I10 B8B9视频基本流(ES)和音频ES。在视频ES中还要加入一个时间基准,即加入从视频信号中取出的27MHz时钟。然后,再分别通过各自的数据包形成器,将相应的ES打包成打包基本流(PES)包,并由PES包构成PES。最后,节目复用器和传输复用器分别将视频PES和音频PES组合成相应的节目流(PS)包和传输流(TS)包,并由PS包构成PS和由TS包构成TS。显然,不允许直接传输PES,只允许传输PS和TS;PES只是PS转换为TS或TS转换为PS的中间步骤或桥梁,是MPEG数据流互换的逻辑结构,本身不能参与交换和互操作。
将MPEG-2压缩编码的视频基本流(ES-Elementary Stream)数据分组为包长度可变的数据包,称为打包基本流(PES- Packetized Elementary Stream)。广而言之,PES为打包了的专用视频、音频、数据、同步、识别信息数据通道。所谓ES,是指只包含1个信源编码器的数据流。即ES是编码的视频数据流,或编码的音频数据流,或其它编码数据流的统称。每个ES都由若干个存取单元(AU-Access Unit)组成,每个视频AU或音频AU都是由头部和编码数据两部分组成的。将帧顺序为I1P4B2B3P7B5B6 的编码ES,通过打包,就将ES变成仅含有1种性质ES的PES包,如仅含视频ES的PES包,仅含音频ES的PES包,仅含其它ES的PES包。PES包的组成见图2。
由图2可见,1个PES包是由包头、ES特有信息和包数据3个部分组成。由于包头和ES特有信息二者可合成1个数据头,所以可认为1个PES包是由数据头和包数据(有效载荷)两个部分组成的。
包头由起始码前缀、数据流识别及PES包长信息3部分构成。包起始码前缀是用23个连续“0”和1个“1”构成的,用于表示有用信息种类的数据流识别,是1个8 bit的整数。由二者合成1个专用的包起始码,可用于识别数据包所属数据流(视频,音频,或其它)的性质及序号。例如:
比特序1 1 0 ×××××是号码为××××的MPEG-2音频数据流;
比特序1 1 1 0 ××××是号码为××××的MPEG-2视频数据流。
PES包长用于包长识别,表明在此字段后的字节数。如,PES包长识别为2 B ,即2×8 = 16 bit字宽,包总长为216-1=65535 B,分给数据头9 B(包头6 B + ES特有信息3 B ),可变长度的包数据最大容量为65526 B。尽管PES包最大长度可达(216 -1)=65535 B(Byte),但在通常的情况下是组成ES的若干个AU中的由头部和编码数据两部分组成的1个AU长度。1个AU相当于编码的1幅视频图像或1个音频帧,参见图2右上角从ES到PES的示意图。也可以说,每个AU实际上是编码数据流的显示单元,即相当于解码的1幅视频图像或1个音频帧的取样。
ES特有信息是由PES包头识别标志、PES包头长信息、信息区和用于调整信息区可变包长的填充字节4部分组成的PES包控制信息。其中,PES包头识别标志由12个部分组成:PES加扰控制信息、PES优先级别指示、数据适配定位指示符、有否版权指示、原版或拷贝指示、有否显示时间标记(PTS-Presentation Time Stamp)/解码时间标记(DTS-Decode Time Stamp)标志、PES包头有否基本流时钟基准(ESCR-Elementary Stream Clock Reference)信息标志、PES包头有否基本流速率信息标志、有否数字存储媒体(DSM)特技方式信息标志、有否附加的拷贝信息标志、PES包头有否循环冗余校验(CRC-Cyclic Redundancy Check)信息标志、有否PES扩展标志。有扩展标志,表明还存在其它信息。如,在有传输误码时,通过数据包计数器,使接收端能以准确的数据恢复数据流,或借助计数器状态,识别出传输时是否有数据包丢失。
MPEG-2帧间编码结构
为了在高效压缩编码的条件下、获得可随机存取的高压缩比、高质量图像,MPEG定义了I、P、B三种图像格式,分别简称为帧内图(Intra Picture)、
预测图(Predicted Picture)及双向图(Bidirec tional Picture),即I图、P图及B图,用于表示1/30s时间间隔的帧序列画面。
因为,要满足随机存取的要求,仅利用I图本身信息进行帧内编码就可以了;要满足高压缩比和高质量图像的要求,单靠I图帧内编码还不行,
还要加上由P图和B图参与的帧间编码,以及块匹配运动补偿预测,即用前一帧图像预测当前图像的因果预测和用后一帧图像预测当前图像的内插预测。
这就要求帧内编码与帧间编码平衡,因果预测与内插预测间的平衡。平衡的结果是随机存取的高压缩比、高质量图像的统一。
为了提高压缩比及图像质量,MPEG-2视频编码采用运动补偿预测(时间预测+内插)消除时间冗余和不随时间变化的图像细节;
采用二维DCT(图像像素+量化传输系数)分解相邻像素,消除观众不可见、不重要的图像细节;采用熵值编码(已量化参数+编码参数的熵),使bit数减少到理论上的最小值。对以上3种压缩技术,作如下说明:
运动补偿预测:
将存储器中前一图像帧的重建图像中相应的块按编码器端求得的运动矢量进行位移,这就是运动补偿过程。为了压缩视频信号的时间冗余度(Temporal Redundancy),MPEG采用了运动补偿预测(Motion Compensated Prediction),图17是其运动处理过程示意图。运动补偿预测假定:通过画面以一定的提前时间平移,可以局部地预测当前画面。这里的局部意味着在画面内的每个地方位移的幅度和方向可以是不相同的。采用运动估值的结果进行运动补偿,以便尽可能地减小预测误差。运动估值包括了从视频序列中提取运动信息的一套技术,该技术与所处理图像序列的特点决定着运动补偿性能的优劣。与画面16×16像素宏块相关的运动矢量支持接收机解码器中的运动补偿预测。
二维DCT
MPEG采用了Ahmed N.等人于1974年提出的离散余弦变换(DCT-Discrete Cosine Transform)压缩算法,降低视频信号的空间冗余度(Spatial Redundancy)。因为静态图像和预测误差信号两者具有非常高的空间冗余度,为降低空间冗余度最广泛地采用的频率域分解技术就是DCT。DCT将运动补偿误差或原画面信息块转换成代表不同频率分量的系数集。这有两个优点:其一,信号常将其能量的大部分集中于频率域的1个小范围内,这样一来,描述不重要的分量只需要很少的比特数;其二,频率域分解映射了人类视觉系统的处理过程,并允许后继的量化过程满足其灵敏度的要求。视频信号的频谱线在0-6MHz范围内,而且1幅视频图像内包含的大多数为低频频谱线,只在占图像区域比例很低的图像边缘的视频信号中才含有高频的谱线。因此,在视频信号数字处理时,可根据频谱因素分配比特数:对包含信息量大的低频谱区域分配较多的比特数,对包含信息量低的高频谱区域分配较少的比特数,而图像质量并没有可察觉的损伤,达到码率压缩的目的。然而,这一切要在低熵(Entropy)值的情况下,才能达到有效的编码。能否对一串数据进行有效的编码,取决于每个数据出现的概率。每个数据出现的概率差别大,就表明熵值低,可以对该串数据进行高效编码。反之,出现的概率差别小,熵值高,则不能进行高效编码。视频信号的数字化是在规定的取样频率下由A/D转换器对视频电平转换而来的,以256层或1024层表示输入视频信号的幅度,每个像素的视频信号幅度随着每层的时间而周期性地变化。每个像素的平均信息量的总和为总平均信息量,即熵值。由于每个视频电平发生几乎具有相等的概率,所以视频信号的熵值很高。
由DCT正变换公式(2)及反变换公式(3)可见,计算有一定的复杂性。但是,实际上这个函数是用代码来实现的,即两个余弦项只在程序开始时进行1次计算,将计算的结果储存起来,而后通过查表就可以了,其它各项都可以通过查表解决,其程序采用了双层嵌套循环。图25是两个余弦项所构成的核函数Gu,v (x,y)计算的示意图,其中设N = 8, u = 2,v = 3;x = 4, y = 5,可求得G2,3(4,5) = G2,3(4)G2,3(5) = (-0.924) ×(+0.979)= - 0.905,以此类推可得到各个点的值,储存起来备查。通过查表,查出各个项的值,用代码来实现图24中DCT编码器输出的DCT系数。
量化
DCT系数采用量化(Quantization)进行压缩是1个关键性的运算,因为组合量化和游程长度编码可以提供最大的压缩量,也可以通过量化使编码器输出匹配成1个给定的比特率。实际上,自适应量化是实现视觉质量的关键性工具之一,在量化中会减少频率域中描述DCT系数的精度。这一点可从图26基本MPEG编码器的运动补偿预测编码过程简化电路图看出。
编码
编码是DCT压缩系统的最后一步。在对64个DCT系数均匀量化后,系数分成为直流(DC)和交流(AC)两个部分。DC系数代表了分量模块的平均亮度,可采用差值脉冲编码调制(DPCM)进行编码;对AC系数,由于非零的DCT系数大多数集中在矩阵的左上角,在进行编码之前先对量化后的DCT系数进行“之”字形扫描,有利于得到一个长的“0”序列,提高编码效率。DCT系数扫描方式有“之”字形和“准之” 字形两种。逐行扫描采用“之”字形传送量化后的DCT系数,隔行扫描采用“准之”字形传送量化后的DCT系数,两种扫描方式如图28所示。

解码部分和编码部分相对应,即反运算。
三、MPEG2各个模块设计
这里,我们开始对MPEG2的解码设计进行仿真分析。
根据算法流程,整个模块的设计按如下的几个模块进行,头信息解码模块,Slice头信息解码模块,运动预测模块,运动补偿模块,块解码模块,反扫描模块,反量化模块,反DCT模块,系统工作管理模块,SDRAM控制模块,VGA显示模块。
下面就这些模块进行设计,以下的模块我们均通过modelsim仿真验证其正确性。
IDCT模块:
该模块,采用的是流的处理形式,即串行的处理方法进行,整个模块使用四个双口RAM,其资源占用如下所示:

这个模块的仿真结果如下所示:


反量化模块:
这个模块就是对应MPEG2编码中的量化模块,其主要原理就是地址读取存储在ROM中的反量化数据,即通过查找表的方法得到反量化后的结果。
这个模块的资源占用情况为:

其RTL图为:

这个模块的仿真结果如下所示:

运动补偿模块:
这个模块是MPEG2中的核心模块,其主要由块估计,块预测模块组成。这个模块的资源占用如下所示:
其RTL图如下所示:

参数缓存模块:
将计算的一些中间结果保存到双口RAM中,再次使用的时候,从双口RAM中读出即可。
其RTL图如下所示:

这个模块主要由四个BRAM构成。
块解码模块:
块模块解码模块如下所示:
其中RTL图如下所示:

以上这些模块就是MPEG2中的图像帧的解密部分,整个模块整合起来结构如下所示:
其RTL图如下所示:

MPEG2的视频流数据,通过上面的模块,就可以进行解码了。
结合头信息解码的MPEG2解码总体结构模块:

加入SRAM控制器之后,整个系统的结构如下所示:
从上面的图可知,其中一个是SDRAM管理模块,一个是MPEG2解码的核心模块。
资源占用如下所示:

















 2402
2402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











