









目录
一、理论基础
在神经网络模式识别系统中,用得最广泛的要算是BP网络,它是基于误差反向传播(Error Back Propagation,简称BP)算法的一种具有非线性连续转移函数的多层前馈网络。由于多层前馈网络的训练经常采用误差反向传播算法。人们也常把将多层前馈网络直接称为BP网。
BP算法的基本思想是,学习过程由信号的正向传播与误差的反向传播两个过程组成。正向传播时,输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出(教师信号)不符,则转入误差的反向传播阶段。误差反传是将输出误差以某种形式通过隐层向输入层逐层反传、并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。这种信号正向传播与误差反向传播的各层权值调整过程,是周而复始地进行的。权值不断调整的过程,也就是网络的学习训练过程。此过程一直进行到网络输出的误差减少到可接受的程度,或进行到预先设定的学习次数为止。
采用BP算法的多层前馈网络是至今为止应用最广泛的神经网络,它具有一个输入层、一个或多个隐层和一个输出层的多层网络。隐层和输出层上的每个神经元都对应于一个激发函数和一个阀值,每一层上的神经元都通过权重与其相邻层上的神经元互相连接。对于输入层上的神经元其阀值为零,其输出等于输入。BP神经网络隐层和输出层上的某神经元j的输出由下式确定:
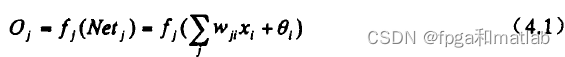

BP网络学习的目的是要使网络以给定的精度实现所需要的映射。设有P个n维输入样本![]() 和对应的m维期望目标输出
和对应的m维期望目标输出![]() ,若构造网络的误差函数如下:
,若构造网络的误差函数如下:
![]()
则采用后向传播学习算法(BP学习算法)总能使E在学习中按梯度下降,BP学习算法可以简述如下:

步6、判断误差函数E是否收敛到所给学习精度 ,若满足学习精度要求则接受学习,否则转步2继续进行。
将BP算法用于具有非线性转移函数的多层前馈网,可以以任意精度逼近任何非线性函数,这一非凡优势使BP多层前馈网络得到越来越广泛的应用。然而标准的BP算法在应用中暴露出不少内在的缺陷:(1)易形成局部极小而得不到全局最优;(2)训练次数多使得学习效率低,收敛速度慢;(3)隐节点的选取缺乏理论指导;(4)训练时学习新样本有遗忘旧样本的趋势。
针对上述问题,国内外已提出不少有效的改进算法,下面是两种较常用的方法。
1增加动量项
一些学者于1986年提出,标准BP算法在调整权值时,只按t时刻误差的梯度下降方向调整,而没有考虑t时刻以前的梯度方向,从而常使训练过程发生振荡,收敛缓慢。为了提高网络的训练速度,可以在权值调整公式中增加一动量项。若用W代表某层权矩阵,X代表输入层输入向量,则含有动量项的权值调整向量表达式为:
可以看出,增加动量项即从前一次权值调整量中取出一部分迭加到本次权值调整量中,称为动量系数,一般。动量项反映了以前积累的调整经验,对于t时刻的调整起阻尼作用。当误差曲面出现骤然起伏时,可减小振荡趋势,提高训练速度。目前,BP算法中都增加了动量项,以至于有动量项的BP算法成为一种新的标准算法。
2自适应调节学习率
学习率也称为步长,在标准BP算法中定为常数。然而在实际应用中,很难确定一个从始至终都合适的最佳学习率。太小会使训练次数增加,因而希望增大叮值;而在误差变化剧烈时,太大会因调整量过大而跨过较窄的“坑凹”处,使训练出现振荡,反而使迭代次数增加。为了加速收敛过程,一个较好的思路是自适应改变学习率,使其该大时增大,该小时减小。
改变学习率的办法很多,其目的都是使其在整个训练过程中得到合理调节。这里介绍其中一种方法,可变学习速度反向传播算法,其规则如下:
(1)如果均方误差(在整个训练集上)权值在更新后增加了,且超过了某个设置的百分数(典型值为1%到5%),则权值更新被取消,学习速度被乘以一个因子p(0<p<l),并且动量系数(如果有的话)被设置为0。
(2)如果均方误差在权值更新后减少,则权值更新被接受,而且学习速度将被乘以一个因子>l。如果动量系数。被设置为0,则恢复到以前的值。
(3)如果均方误差的增长小于,则权值更新被接受,但学习速度保持不变。如果动量系数被设置为O,则恢复到以前的值。
二、核心程序
算法的基本思想是 学习过程由信号的正向传播与误差的反向传播两个过程组成正向传播时输入样本从输入层传入经各隐层逐层处理后 传向输出层 若输出层的实际输出与期望的输出教师信号不符则转入误差的反向传播阶段误差反传是将输出误差以某种形式通过隐层向输入层逐层反传并将误差分摊给各层的所有单元从而获得各层单元的误差信号此误差信号即作为修正各单元权值的依据这种信号正向传播与误差反向传播的各层权值调整过程是周而复始地进行的权值不断调整的过程也就是网络的学习训练过程此过程一直进行到网络输出的误差减少到可接受的程度或进行到预先设定的学习次数为止。
NodeNum = 10; % 隐层节点数
TypeNum = 3; % 输出维数
p1 = xn_train; % 训练输入
t1 = dn_train; % 训练输出
Epochs = 1000; % 训练次数
P = xn_test; % 测试输入
T = dn_test; % 测试输出(真实值)
其中隐层节点数的确定是神经网络设计中非常重要的一个环节,一个具有无限隐层节点的两层BP网络可以实现任意从输入到输出的非线性映射。但对于有限个输入到输出的映射,并不需要无限个隐层节点,这就涉及到如何选择隐层节点数的问题,而这一问题的复杂性,使得至今为止尚未找到一个很好的解析式,隐层节点数往往根据前人设计所得的经验和自己进行试验来确定。
net.trainParam.show = 1; % 训练显示间隔
net.trainParam.lr = 0.3; % 学习步长 - traingd,traingdm
net.trainParam.mc = 0.95; % 动量项系数 - traingdm,traingdx
net.trainParam.mem_reduc = 10; % 分块计算Hessian矩阵
net.trainParam.epochs = 1000; % 最大训练次数
net.trainParam.goal = 1e-8; % 最小均方误差
net.trainParam.min_grad = 1e-20; % 最小梯度
net.trainParam.time = inf; % 最大训练时间
通过以上的这只,我们基本完成了BP神经网络的基本参数设置,下面就开始测试。
................................................
% 判别函数
TF1 = 'logsig';TF2 = 'purelin';
net = newff(minmax(p1),[NodeNum TypeNum],{TF1 TF2},'trainlm');
net.trainParam.show = 1; % 训练显示间隔
net.trainParam.lr = 0.3; % 学习步长 - traingd,traingdm
net.trainParam.mc = 0.95; % 动量项系数 - traingdm,traingdx
net.trainParam.mem_reduc = 10; % 分块计算Hessian矩阵(仅对Levenberg-Marquardt算法有效)
net.trainParam.epochs = 1000; % 最大训练次数
net.trainParam.goal = 1e-8; % 最小均方误差
net.trainParam.min_grad = 1e-20; % 最小梯度
net.trainParam.time = inf; % 最大训练时间
%%
% 训练与测试
fprintf('开始训练......\n');
net = train(net,p1,t1); % 训练
fprintf('开始测试......\n');
X = sim(net,P); % 测试 - 输出为预测值
fprintf('网络的实际输出结果显示:\n');
X = full(compet(X)) % 竞争输出
%---------------------------------------------------
% 结果统计
fprintf('测试样本正确分类的显示为1,错误为0:\n');
Result = ~sum(abs(X-T2)) % 正确分类显示为1
Percent = sum(Result)/length(Result); % 正确分类率
fprintf('正确分类率:%f\n',Percent);
A05-01三、测试结果
·训练数据和测试数绝相同的情况
P1 = [rand(3,5),rand(3,5)+1,rand(3,5)+2]
P2 = [rand(3,5),rand(3,5)+1,rand(3,5)+2]
我们可以得到如下结果:
表一:训练样本
| P1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 1 | 0.8147 | 0.9134 | 0.2785 | 0.9649 | 0.9572 | 1.1419 | 1.7922 | 1.0357 |
| 2 | 0.9058 | 0.6324 | 0.5469 | 0.1576 | 0.4854 | 1.4218 | 1.9595 | 1.8491 |
| 3 | 0.1270 | 0.0975 | 0.9575 | 0.9706 | 0.8003 | 1.9157 | 1.6557 | 1.9340 |
| P1 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 1 | 1.6787 | 1.3922 | 2.7060 | 2.0462 | 2.6948 | 2.0344 | 2.7655 | |
| 2 | 1.7577 | 1.6555 | 2.0318 | 2.0971 | 2.3171 | 2.4387 | 2.7952 | |
| 3 | 1.7431 | 1.1712 | 2.2769 | 2.8235 | 2.9502 | 2.3816 | 2.1869 |
表二:测试样本
| P2 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 1 | 0.4898 | 0.7094 | 0.6797 | 0.1190 | 0.3404 | 1.7513 | 1.6991 | 1.5472 |
| 2 | 0.4456 | 0.7547 | 0.6551 | 0.4984 | 0.5853 | 1.2551 | 1.8909 | 1.1386 |
| 3 | 0.6463 | 0.2760 | 0.1626 | 0.9597 | 0.2238 | 1.5060 | 1.9593 | 1.1493 |
| P2 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 1 | 1.2575 | 1.8143 | 2.3500 | 2.6160 | 2.8308 | 2.9172 | 2.7537 | |
| 2 | 1.8407 | 1.2435 | 2.1966 | 2.4733 | 2.5853 | 2.2858 | 2.3804 | |
| 3 | 1.2543 | 1.9293 | 2.2511 | 2.3517 | 2.5497 | 2.7572 | 2.5678 |
显示如下结论:
X =
1,1,1,1,1,0,0,0,0,0,0,0,0,0,0
0,0,0,0,0,1,1,1,1,1,0,0,0,0,0
0,0,0,0,0,0,0,0,0,0,1,1,1,1,1
测试样本正确分类的显示为1,错误为0:
Result =
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1
正确分类率:1.000000
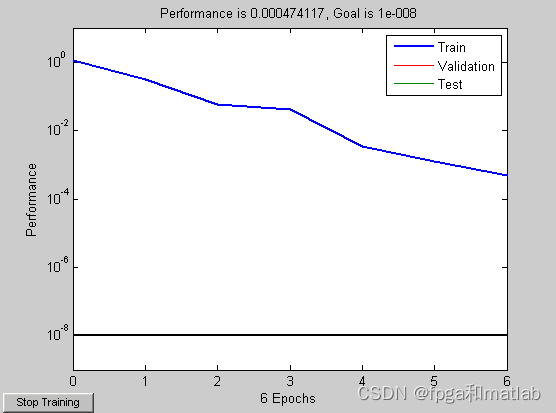
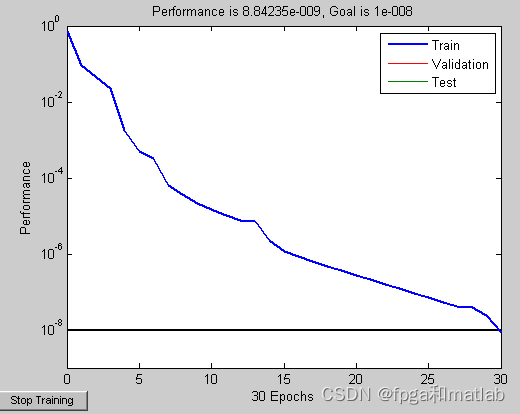
其波形的变化规律如下所示(其只过了30个检测周期就完成识别):
















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











