







来源:图灵人工智能
Causal Abstraction:A Theoretical Foundation for Mechanistic Interpretability
https://arxiv.org/pdf/2301.04709 v3 2024

摘要
因果抽象为机制可解释性提供了理论基础,该领域涉及提供可理解的算法,这些算法是对已知但不透明的黑盒AI模型低层次细节的忠实简化。我们的贡献包括:(1) 将因果抽象理论从机制替换(即硬干预和软干预)推广到任意机制转换(即从旧机制到新机制的泛函),(2) 提供了一种灵活且精确的形式化定义,用于模块化特征、多义性神经元和分级忠实度的核心概念,以及(3) 在因果抽象的共同语言下统一了多种机制可解释性方法,即激活和路径修补、因果中介分析、因果清洗、因果追踪、电路分析、概念擦除、稀疏自编码器、差分二进制掩蔽、分布式对齐搜索和激活引导。
关键词:机制可解释性、因果关系、抽象、可解释AI、可解释性


1. 引言
我们将可解释人工智能的基本目标视为解释AI模型为何做出其预测。在许多情况下,解释的范式是因果解释(Woodward, 2003; Pearl, 2019),阐明了模型行为背后机制的反事实差异制造细节。然而,并非任何因果解释都是恰当的。我们显然已经知道所有关于深度学习模型的低级因果事实。毕竟,我们可以从实数值向量、激活函数和权重张量的角度解释模型行为的每个方面。当然,问题在于这些低级解释通常对人类来说并不透明——它们未能灌输对模型行为背后高级原则的理解(Lipton, 2018; Creel, 2020)。
在许多情境中,可以很容易地为任务设计简单的算法,这些任务在人类可理解的概念上操作。关键问题是,在什么条件下,这样一个透明的算法构成了对已知但不透明的黑盒模型低级细节的忠实解释(Jacovi和Goldberg, 2020)?这是可解释AI子领域即解释性的研究动机所在,并且这个问题对于机制解释性尤其重要,机制解释性专门旨在分析黑盒模型的组成部分,以透明算法为术语(Vig等人,2020; Olah等人,2020; Geiger等人,2020; Finlayson等人,2021; Elhage等人,2021; Chan等人,2022b; Wang等人,2023; Nanda等人,2023a)。
机制解释性研究与认知科学家在理解人类大脑如何工作所面临的问题非常相似。在一个极端,我们可以尝试在非常低的层次上理解心智,例如大脑中的生化过程。在另一个极端,我们可以只关注系统的输入输出事实,大致上讲,关注“可观察行为”。类似地,对于深度学习模型,我们可以关注低级特征(权重张量、激活函数等),或者关注计算的输入输出函数。然而,在这两种情况下,研究将输入转换为输出的中介过程和机制可能都是有启发性的,这在稍微高层次的抽象中是Marr(1982)著名的算法分析层次。到这些算法层次的假设对科学家来说是透明的程度,我们可能对代理的内部工作有了有用的阐释。
然而,至关重要的是,机制解释性方法要避免讲述与模型内部工作完全脱节的“就是这样”的故事。为了澄清这到底意味着什么,我们需要一种共同语言来阐释和比较方法论,并精确化核心概念。我们认为因果抽象理论提供了这种共同语言。
在某些方面,研究现代深度学习模型就像研究天气或经济:它们涉及大量密集连接的“微观变量”和复杂的非线性动态。控制这种复杂性的一种方法是通过更高级别的、更抽象的变量(“宏观变量”)来理解这些系统。例如,许多微观变量可能被聚集成更抽象的宏观变量。一些研究人员一直在探索因果抽象理论,为在多个细节层次上因果分析系统提供了数学框架(Chalupka等人,2017; Rubenstein等人,2017; Beckers和Halpern,2019; Beckers等人,2019; Rischel和Weichwald,2021; Massidda等人,2023)。这些方法告诉我们,何时一个高级因果模型是简化的(通常更细粒度的)低级模型。
迄今为止,因果抽象已被用于分析天气模式(Chalupka等人,2016)、人脑(Dubois等人,2020a,b)和深度学习模型(Chalupka等人,2015; Geiger等人,2020, 2021; Hu和Tian,2022; Geiger等人,2023; Wu等人,2023)。
2.因果关系和抽象
本节提出了一般性的因果抽象理论。尽管我们在很大程度上基于近期文献中的已有工作,但我们的表述在某些方面更为普遍,而在其他方面则较为具体。由于我们专注于(确定性的)神经网络模型,因此并未将概率纳入其中。同时,因为现代机器学习系统的研究中使用的操作超出了替换模型机制的“硬”干预和“软”干预(见下文的定义9和10),我们定义了一种非常广泛的干预类型,即“干预映射”,它是从旧机制到新机制的函数映射(见定义11)。为了在这个不受约束的模型变换类中施加结构,我们对形成所谓“干预代数”的干预类提出了一些新的结果(特别见定理20、21)。
接下来,我们探讨了因果模型之间可能存在的关键关系。我们首先从精确变换(Rubenstein等,2017年)入手,这种变换描述了一个因果模型的机制何时由另一个模型的机制实现(“因果一致性”)。我们将精确变换从硬干预推广到形成干预代数的干预映射(见定义25)。双射变换(见定义28)是一种保留原始模型所有细节的精确变换,保持在相同的粒度水平。另一方面,构造性因果抽象(见定义33)是一种“有损”的精确变换,它将微观变量合并为宏观变量,同时保持对原始模型的精确和准确的描述。此外,我们(1)将构造性因果抽象分解为三种操作,即边缘化、变量合并和值合并(见命题40),并且(2)提供了理解近似变换的一般框架(见定义41)。
最后,我们定义了一组互换干预操作,它们是通过因果抽象理解机制可解释性的核心。我们从简单的互换干预开始(见定义44),在这种干预中,具有输入和输出变量的因果模型将某些变量固定为它们在不同输入条件下的值。我们将这些扩展到递归互换干预(见定义45),这种干预允许基于先前互换干预的结果固定变量。至关重要的是,我们还定义了分布式互换干预,这种干预目标变量分布在多个因果变量之间,并涉及到变换变量空间的双射变换(见定义46)。最后,我们阐述了如何构建用于互换干预分析的对齐方法,以及如何使用互换干预准确性来量化近似抽象。
2.1 具有隐含图结构的确定性因果模型
我们从一些基本符号开始。





未受约束的干预映射空间 FuncV 是混乱的,且无法保证干预映射能够被视为隔离自然模型组件。我们希望描述那些“表现得像硬干预”的干预映射空间,因为它们具有基本的代数结构。我们将在下一节对此进行详细说明。
以下是一个因果模型的示例,其中定义了硬干预、软干预和干预映射。


2.2 干预代数




2.3 使用干预性的精确转换
研究者们对这样一个问题感兴趣:两个模型——可能在不同的签名上定义——在什么情况下是相互兼容的,即它们都能够准确地描述相同的靶标因果现象。下一个定义呈现了Rubenstein等人(2017年)提出的“精确转换”概念的推广。我们在本文中研究的其他概念——即双射转换和构造性抽象——是精确转换的特殊情况。




2.3.2 构造性因果抽象
假设我们有一个由“低级变量”VL构建的“低级模型” 和一个由“高级变量”VH构建的“高级模型”
和一个由“高级变量”VH构建的“高级模型”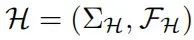 。为了使H成为低级模型L的高级抽象,必须具备哪些结构条件?至少,这要求高级干预能够表示低级干预,正如定义25中所述。也就是说,H应该是L的精确变换。那么,还需要满足哪些条件呢?
。为了使H成为低级模型L的高级抽象,必须具备哪些结构条件?至少,这要求高级干预能够表示低级干预,正如定义25中所述。也就是说,H应该是L的精确变换。那么,还需要满足哪些条件呢?
关于抽象的一个重要直觉是,它可能涉及将特定的高级变量与低级变量的聚类相关联。即,将低级变量聚集在一起形成“宏变量”,以抽象掉低级细节。为了系统化这个概念,我们引入了低级签名与高级签名之间对齐的概念:


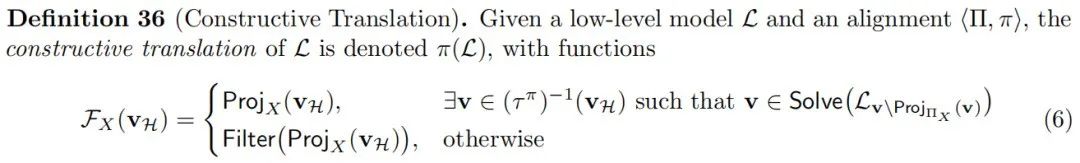

构造性翻译产生的高级模型何时构成构造性抽象的充分和必要条件是可以刻画的,我们将把这一问题留待未来的工作中探讨。
2.3.3 模型之间对齐的分解
鉴于这种相对简单的抽象概念的重要性和普遍性,从不同角度理解这一概念是值得的。对齐 ⟨Π,π⟩⟨Π,π⟩ 可以通过以下三个基本操作进行分解。边缘化从因果模型中移除一组变量;变量合并将因果模型中的变量分区合并,每个分区单元成为一个单一变量;值合并将因果模型中每个变量的值的分区合并,每个分区单元成为一个单一值。前两个操作与科学哲学文献中被认为对于解决变量选择问题至关重要的概念密切相关(Kinney, 2019; Woodward, 2021)。
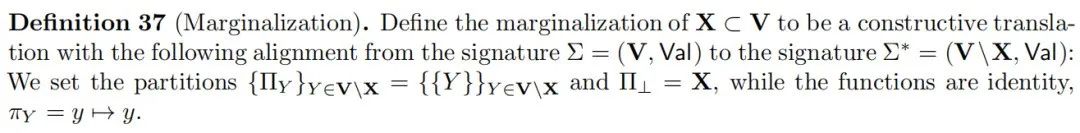
边缘化本质上是忽略变量子集 \(X\) 的问题。科学哲学家关注的是在某些情况下,一个因果因素对“背景变量”的变化相对不敏感或稳定的情境(Lewis, 1986; Woodward, 2006)。也就是说,如果我们简单地忽略那些对某个效应也有影响的其他变量,那么一个特定因素在多大程度上能可靠地导致该效应?我们在这里给出的边缘化定义基本上保证了这种意义上的完美不敏感性/稳定性。

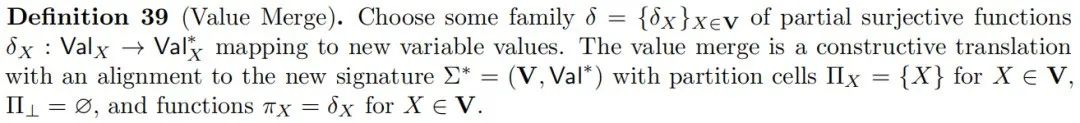



2.4 近似转换
构造性因果抽象和其他精确转换都是全有或全无的概念。精确转换关系要么成立,要么不成立。这种二元概念阻止了我们在实践中更有用的分级忠实解释概念。我们定义了一个可以灵活适应的近似抽象概念:


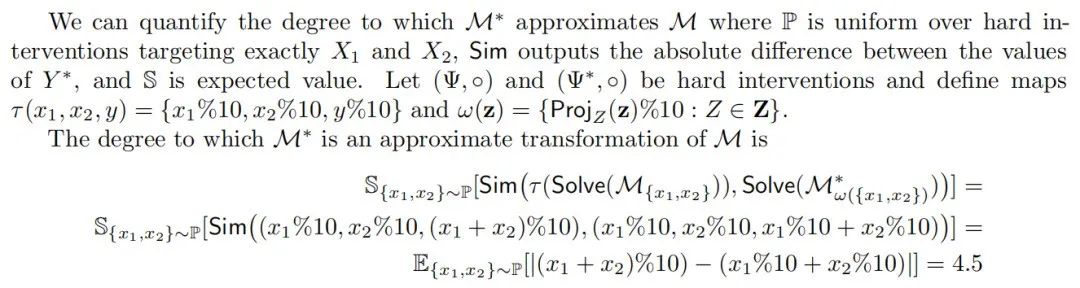
2.5 交换干预
交换干预(Geiger等人,2020年,2021年)是对具有输入和输出变量的因果模型(即无环模型;回顾备注7)的操作。具体来说,因果模型被赋予一个“基础”输入,然后执行一个干预,将某些变量固定为如果提供不同的“源”输入它们将具有的值。这种干预将对在因果抽象中确立机制解释性至关重要。



Geiger等人(2022年)提出了交换干预准确性,它简单地是低级和高级因果模型在交换干预下具有相同输入-输出行为的比例(参见第2.6节的示例)。


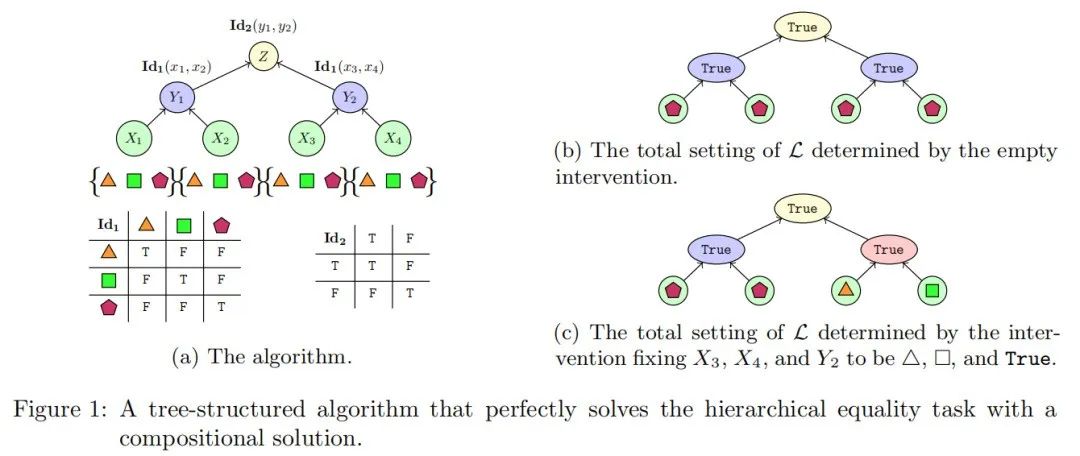
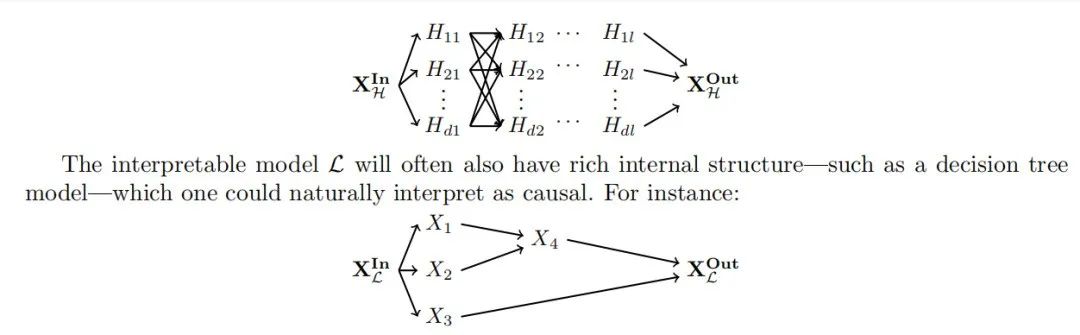
2.6 示例:机械解释中的因果抽象
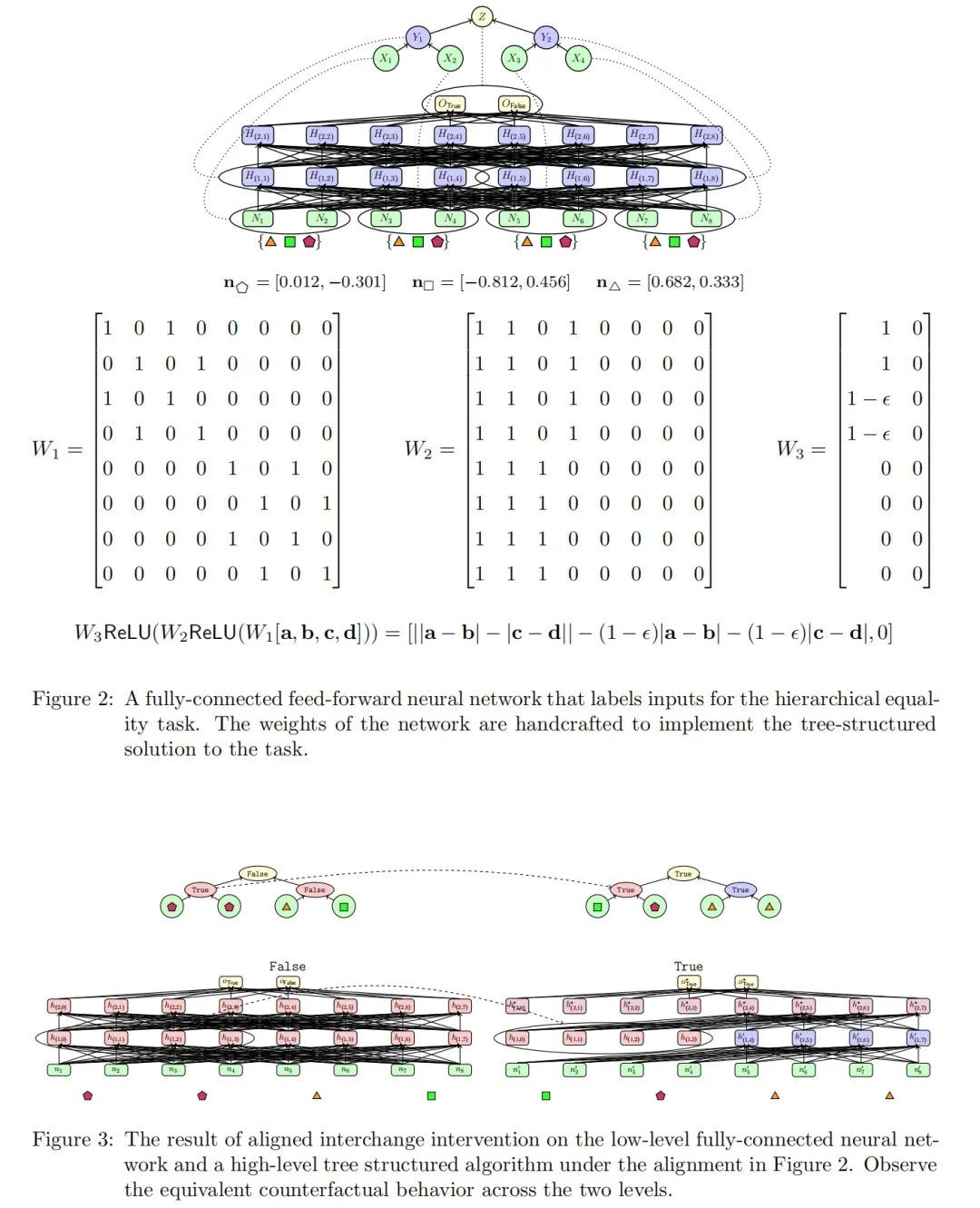
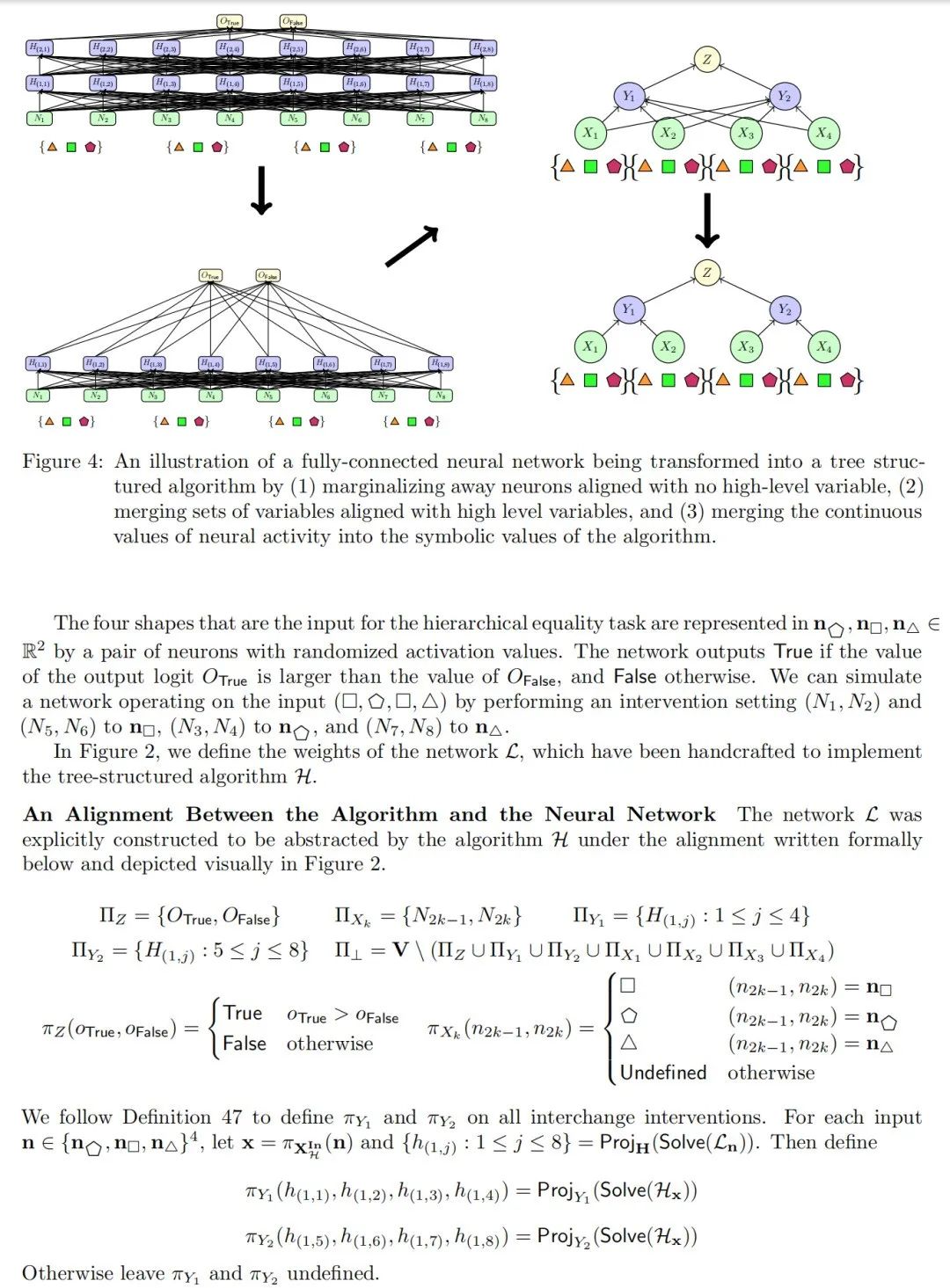
在阐述了理论之后,我们现在可以展示一个来自机械解释领域的因果抽象示例。我们首先定义两个基本的因果模型,这些模型展示了建模多种计算过程的潜力;第一个因果模型表示一个树结构算法,第二个是全连接前馈神经网络。网络和算法都解决了相同的“层次等式”任务。
基本的等式任务是确定一对对象是否相同。层次等式任务是确定一对对象对是否具有相同的关系。层次任务的输入是两对对象,如果两对对象都相等或都不相等,则输出为 True,否则为 False。例如,输入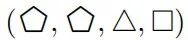
被分配为 False,输入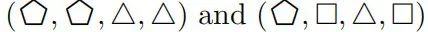 都被标记为 True。
都被标记为 True。
我们选择层次等式任务有两个原因。首先,解决该任务的显而易见的树结构符号算法是:计算第一对是否相等,计算第二对是否相等,然后计算这两个输出是否相等。我们将这个算法编码为一个因果模型。其次,等式推理是普遍存在的,并且作为生物体中关系推理的表示的广泛问题的案例研究(Marcus et al., 1999; Alhama 和 Zuidema, 2019; Geiger et al., 2022a)。
我们提供了一个配套的 Jupyter Notebook,逐步演示这个示例。



2.7 示例:具有循环和无限变量的因果抽象
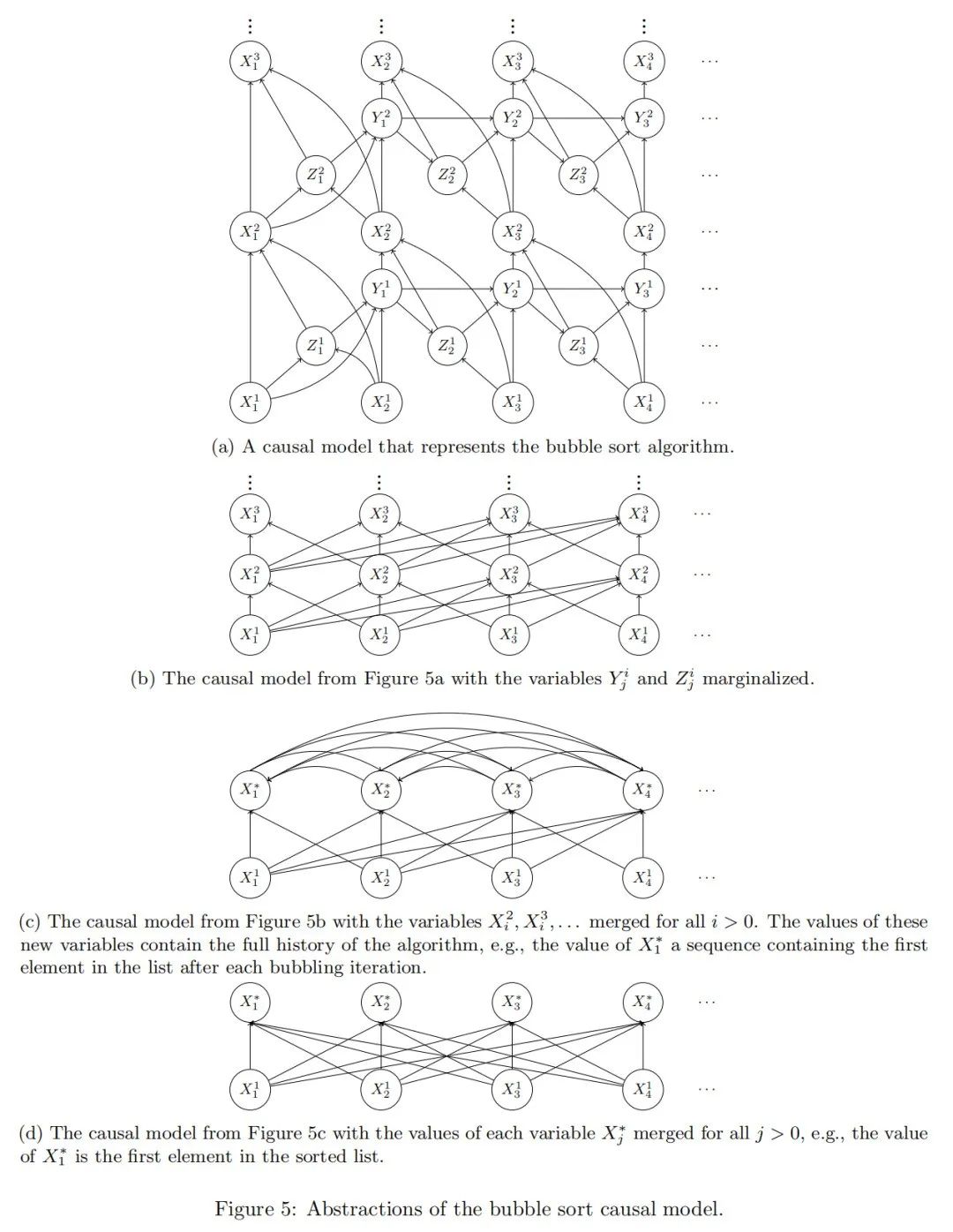
因果抽象是一个高度表达性的通用框架。然而,我们在第2.6节的示例中仅涉及了有限且无环的模型。为了展示这个框架的表达能力,我们将定义一个具有无限多个变量和无限值范围的因果模型,该模型实现了任意长度列表上的冒泡排序算法,并展示如何将这个无环模型抽象为一个具有平衡状态的循环过程。
冒泡排序的因果模型 冒泡排序是一种迭代算法。在每次迭代中,比较序列的前两个成员,并在左侧元素大于右侧元素时交换它们;然后对结果列表中的第二和第三个成员进行比较并可能交换,依此类推,直到列表的末尾。这个过程会重复,直到不再需要交换。



3. 机制可解释性的共同语言
本文的核心主张是,因果抽象为机制可解释性提供了理论基础。通过一般的因果抽象理论,我们将为几个核心机制可解释性概念提供数学上精确的定义,并展示各种方法如何被视为因果抽象分析的特例。
3.1 通过干预代数理解多义神经元和模块化特征
在分析黑箱AI时,一个棘手的问题是如何将深度学习系统分解成组成部分。分析的单位应是实值激活、激活空间中的方向,还是整个模型组件?如果神经元是分析的充分单位,将会更容易将一个抽象概念定位到黑箱AI的某个组件上。然而,早已知道人工(和生物)神经网络具有多义神经元,这些神经元参与多个高层次概念的表示(Smolensky, 1986; Rumelhart et al., 1986; McClelland et al., 1986; Thorpe, 1989)。因此,单独的神经激活不足以作为机制可解释性的分析单位,这一点在最近的文献中得到了认可(Harradon et al., 2018; Cammarata et al., 2020; Olah et al., 2020; Goh et al., 2021a,b; Elhage et al., 2021; Bolukbasi et al., 2021; Geiger et al., 2023; Gurnee et al., 2023; Huang et al., 2023)。
最简单的多义神经元情况可能是,通过某种旋转可以使神经激活的维度在新的坐标系统中变得单义(Elhage et al., 2021; Scherlis et al., 2022; Geiger et al., 2023)。确实,线性表示假设(Mikolov et al., 2013; Elhage et al., 2022; Nanda et al., 2023b; Park et al., 2023; Jiang et al., 2024)表明,线性表示对于分析深度学习模型的复杂非线性构建块是足够的。我们担心这过于限制。理想的理论框架不会固守像线性表示假设这样的假设,而是支持任何和所有将深度学习系统分解为具有独立机制的模块化特征的方法。我们应该有灵活性来选择分析单位,而不受可能排除有意义结构的限制性假设的约束。特定的深度学习系统分解为模块化特征是否对机制可解释性有用,应被视为一个可以通过实验证伪的经验假设。
我们的因果抽象理论通过干预代数(第2.2节)支持一种灵活但精确的模块化特征概念。干预代数形式化了具有不同机制的可分组件的概念,满足交换律和左歼灭性这两个基本代数性质(见定义16中的(a)和(b))。在这种意义上,单独的激活、向量空间中的正交方向和模型组件(如注意力头)都是具有不同机制的可分组件。双射变换(第2.3.1节)提供了这样的特征,同时保留了模型的整体机制结构。我们建议将模块化特征定义为任何形成干预代数的变量集,这些变量集通过双射变换可以被访问。
如果线性表示假设是正确的,那么旋转矩阵应该足够作为机制可解释性的双射变换。如果不是,则可能需要非线性双射变换,例如正规化流网络(Kobyzev et al., 2021),来发现无法通过线性方式访问的模块化特征。我们对模块化特征的概念使我们能够保持对哪些分析单位将被证明是至关重要的观点的中立。
3.2 通过近似抽象实现分级忠实性
忠实性的定义:忠实性被定义为解释准确反映模型行为背后的“真实推理过程”的程度(Wiegreffe 和 Pinter, 2019;Jacovi 和 Goldberg, 2020;Lyu 等, 2022;Chan 等, 2022a)。忠实性应当是一个分级的概念(Jacovi 和 Goldberg, 2020),但具体的忠实性度量标准将取决于具体情况。例如,出于安全考虑,有些输入领域可能需要完全忠实的黑箱AI解释,而其他领域可能要求较低。理想情况下,我们可以根据使用案例来填补具体细节。这允许我们提供各种分级忠实性度量,以便在现有(和未来的)机制可解释性方法之间进行有效的比较。
近似变换的作用:近似变换(第2.4节)提供了所需的灵活分级忠实性概念。高层次和低层次状态之间的相似性度量、评估干预的概率分布以及用于汇总个体相似性得分的统计量都是可变因素,使我们的近似变换概念可以适应特定情况。通过近似变换可以理解的度量包括:
交换干预准确性(Geiger 等, 2022b, 2023;Wu 等, 2023)
概率或对数几率差异(Meng 等, 2022;Chan 等, 2022b;Wang 等, 2023;Zhang 和 Nanda, 2024)KL散度
3.3 行为评估作为通过两个变量链的抽象
行为的定义:AI模型的行为就是模型实现的输入到输出的函数。行为在因果术语中容易表征;任何输入-输出行为都可以用一个具有输入变量和输出变量的两变量因果模型来表示。
3.3.1 LIME:行为忠实性作为近似抽象
特征归因方法:特征归因方法将分数分配给输入特征,以捕捉特征对模型行为的“影响”。梯度基础的特征归因方法(Zeiler 和 Fergus, 2014;Springenberg 等, 2014;Shrikumar 等, 2016;Binder 等, 2016;Lundberg 和 Lee, 2017;Kim 等, 2018;Narendra 等, 2018;Lundberg 等, 2019;Schrouff 等, 2022)当它们满足一些基本公理时,可以测量因果属性。特别地,Geiger 等(2021)提供了集成梯度方法的自然因果解释,Chattopadhyay 等(2019)主张直接测量特征的个体因果效应。
LIME方法:LIME(Ribeiro 等, 2016)是一种学习可解释模型以局部近似不可解释模型的方法。LIME定义解释的忠实性为可解释模型与局部输入-输出行为的一致程度。虽然LIME最初并未被设想为因果解释方法,但当我们将模型的输入视为干预时,两个模型具有相同的局部输入-输出行为本质上是一个因果问题。
局限性:然而,LIME方法的可解释模型与不可解释模型的内部因果动态缺乏联系。实际上,LIME作为模型无关的方法,提供了对具有相同行为但内部结构不同的模型相同的解释,但这也是一种优点。没有进一步的因果抽象基础,像LIME这样的办法不能告诉我们输入和输出之间的抽象因果结构的有意义的信息。

然而,LIME只寻求找到可解释和不可解释模型的输入-输出行为之间的对应关系。因此,将H和L都表示为连接输入和输出的双变量因果模型足以描述LIME中的保真度度量。
为了使近似转换反映LIME保真度度量,定义

3.3.2 来自积分梯度的单源交换干预
积分梯度(Sundararajan等人,2017年)计算神经元对模型预测的影响。遵循Geiger等人(2021年)的方法,我们可以轻松地将原始的积分梯度方程翻译成我们的因果模型形式主义。

积分梯度最初并不是作为神经网络因果分析的方法而构思的。因此,积分梯度可以用来计算交换干预,这也许令人惊讶。这取决于对积分梯度的“基线”值的战略使用,该值通常设置为零向量。

然而,计算积分将是一种计算交换干预的低效方式。
3.3.3 估计现实世界概念的因果效应
可解释人工智能的最终下游目标是提供易于人类决策者理解的直观概念的解释(Goyal 等,2019;Feder 等,2021;Elazar 等,2022;Abraham 等,2022)。这些概念可以是抽象和数学的,比如真值命题内容、自然数或像身高或体重这样的实数值;它们也可以是具体的,比如狗的品种、求职者的种族,或者歌手声音的音调。一个基本问题是,如何估计现实世界概念对人工智能模型行为的影响。
可解释AI基准测试CEBaB(Abraham 等,2022)评估方法在估计食物质量、服务、氛围和噪音在现实世界就餐体验中的因果效应方面的能力,这些因素对基于餐厅评论作为输入数据的情感分类器的预测。以CEBaB作为示例,我们用单一因果模型MCEBaB表示现实世界数据生成过程和神经网络。现实世界概念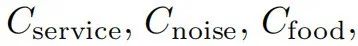 和
和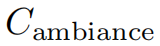 可以取三个值+、-和未知,输入数据
可以取三个值+、-和未知,输入数据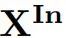 取餐厅评论文本的值,预测输出
取餐厅评论文本的值,预测输出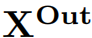 取五星评级的值,神经表示
取五星评级的值,神经表示 可以取实数值。
可以取实数值。
如果我们对食物质量对模型输出的因果效应感兴趣,那么我们可以对除了现实世界概念Cfood和神经网络输出XOut之外的每个变量进行边缘化,以得到一个包含两个变量的因果模型。这个边缘化的因果模型是MCEBaB的高级抽象,它包含一个单一的因果机制,描述了餐饮体验中的食物质量如何影响神经网络输出。

3.4 作为交换干预的抽象的激活修补
在文献中被称为“激活补丁”通常等同于交换干预(见2.5节),但这个术语有时被用来描述其他各种干预技术。Wang等人(2023年)使用激活补丁来表示(递归)交换干预,而Conmy等人(2023年)、Zhang和Nanda(2024年)、Heimersheim和Nanda(2024年)包括消融干预(见3.5节),Ghandeharioun等人(2024a)包括更类似于激活引导的任意变换(见3.7节)。
交换干预(2.5节)是跨越多种研究的基本操作(Geiger等人,2020年;Vig等人,2020年;Geiger等人,2021年;Li等人,2021年;Chan等人,2022b;Wang等人,2023年;Lieberum等人,2023年;Huang等人,2023年;Hase等人,2023年;Cunningham等人,2023年;Davies等人,2023年;Tigges等人,2023年;Feng和Steinhardt,2024年;Ghandeharioun等人,2024b)。它们的作用是揭示黑盒模型中的因果机制,阐明神经激活所代表的人类可理解的概念。许多现有的机制解释方法可以基于交换干预。我们建议将“激活补丁”和“交换干预”同义使用。
3.4.1 通过三变量链的因果中介作为抽象
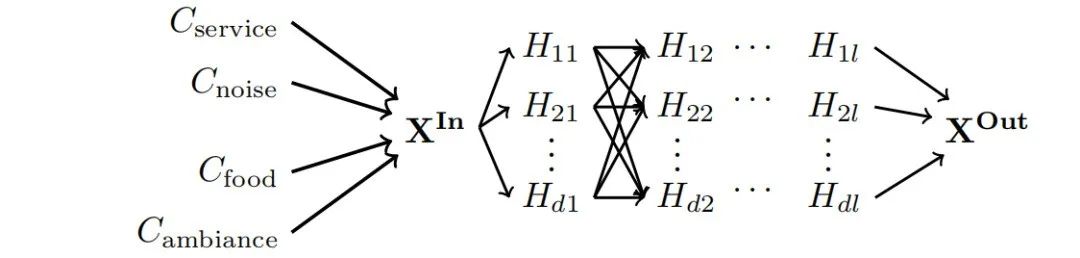
Vig等人(2020年)、Finlayson等人(2021年)、Meng等人(2022年)、Stolfo等人(2023年)将流行的因果推断框架—中介分析(Imai等人,2010年;Hicks和Tingley,2011年)—应用于理解神经网络的内部模型组件如何介导输入对输出的因果效应。很容易证明中介分析是因果抽象分析的一个特例。中介分析与消融干预(见3.5节)和交换干预兼容。在本节中,我们介绍使用交换干预的中介分析。
假设改变变量X的值从x变为x'对第二组变量Y有影响。因果中介分析确定这种因果效应是如何由第三组中介变量Z介导的。中介所涉及的基本概念是总效应、直接效应和间接效应,这些可以用交换干预来定义。

这种方法已经被应用到神经网络的分析中,以表征输入对输出的因果效应是如何通过中间神经表示介导的。这类研究的一个核心目标是识别一组神经元,这些神经元完全介导了输入值变化对输出的因果效应。这相当于一个简单的因果抽象分析。

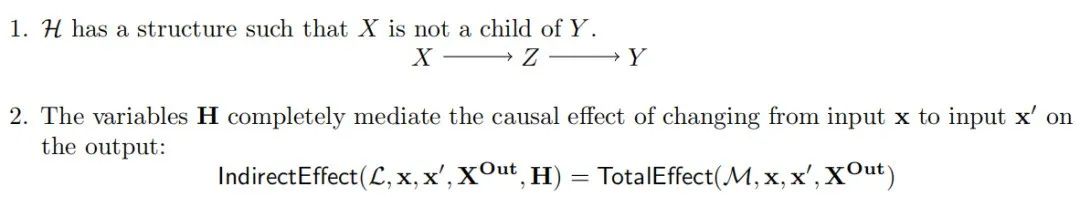
3.4.2 路径修补作为递归交换干预
路径修补(Wang等人,2023年;Goldowsky-Dill等人,2023年;Hanna等人,2023年;Zhang和Nanda,2024年;Prakash等人,2024年)是一种交换干预分析的变体,它针对变量之间的连接而不是变量本身。我们可以在处理基础输入b的模型M上执行递归交换干预,模拟“发送者”变量H取源输入s的干预值,将这种干预的效果限制在接收器变量R上,同时冻结变量F。
每个接收器变量取值由发送者变量H的s输入决定,同时将F固定为由b输入决定的值。对于接收器变量R ∈ R,定义一个交换干预

3.5 消融作为三变量碰撞的抽象
神经科学的损伤研究涉及对大脑某个区域的损伤,以确定其功能;如果损伤导致行为缺陷,那么人们就假定这个大脑区域参与了该行为的产生。在机制解释性中,这种干预被称为消融。常见的消融包括用零激活(Cammarata等人,2020年;Olsson等人,2022年;Geva等人,2023年)或一组输入数据上的平均激活(Wang等人,2023年)替换神经激活向量,向激活添加随机噪声(因果追踪;Meng等人,2022年,2023年),以及用不同输入的值替换激活(重采样消融;Chan等人,2022b)。为了将消融研究作为因果抽象分析的特例来捕捉,我们只需要一个高级模型,其中包含一个输入变量、一个输出变量和一个与消融目标变量对齐的二进制值变量。
3.5.1 概念擦除
概念擦除是消融在神经网络L中去除有关特定概念C的信息的常见应用(Ravfogel等人,2020年,2022年,2023b,a;Elazar等人,2020年;Lovering和Pavlick,2022年;Meng等人,2022年;Olsson等人,2022年;Belrose等人,2023年)。为了量化概念擦除实验的成功,每个概念C都与某种降级的行为能力相关联,这种行为能力被编码为部分函数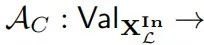
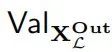 (例如,擦除概念“狗”将与在包含狗的图像中不准确地描述图片的行为相关联)。如果对H进行消融以擦除概念C导致L具有降级的行为AC而不改变其他行为,则消融是成功的。
(例如,擦除概念“狗”将与在包含狗的图像中不准确地描述图片的行为相关联)。如果对H进行消融以擦除概念C导致L具有降级的行为AC而不改变其他行为,则消融是成功的。
我们可以将L上的消融建模为通过三变量因果模型的抽象。定义一个高级签名为输入变量X,取自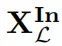 的值,输出变量Y,取自
的值,输出变量Y,取自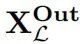 的值,以及一个指示概念C是否已被擦除的二进制变量Z。X的机制分配一个任意的默认输入,Z的机制分配0,Y的机制如果Z为1则产生降级的行为,否则模仿L:
的值,以及一个指示概念C是否已被擦除的二进制变量Z。X的机制分配一个任意的默认输入,Z的机制分配0,Y的机制如果Z为1则产生降级的行为,否则模仿L:


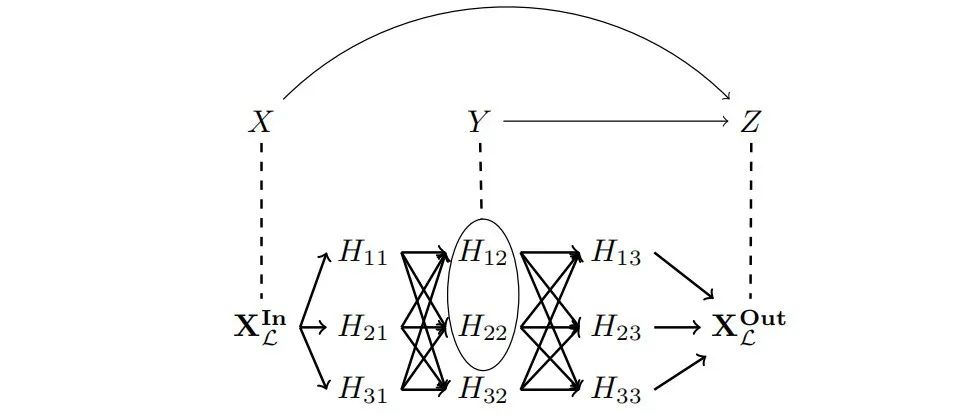
请注意,高层模型 H 没有编码概念 C 及其可能取值的变量。消融研究尝试确定模型是否使用了某个概念,但并不描述该概念是如何被使用的。
3.5.2 子电路分析


3.5.3 因果擦除
因果擦除(Chan等人,2022b)是一种消融方法,它提出要确定一个电路C是否足以产生行为B。它不适合我们通常的子电路分析范式有两个原因。首先,最小电路C是由一个高级因果模型H确定的,H与L具有相同的输入和输出空间,并且有一个满射的部分函数δ:VL → VH,为每个低级变量分配一个高级变量。具体来说,低级的最小电路是高级因果图拉回到低级C = {(G, H) : δ(G) ≺ δ(H)}。其次,除了C中的连接外,最小电路C中的连接也受到了干预。这意味着网络中的每一个连接都正在被干预。
给定一个基础输入b,因果擦除递归地对网络中的每一个连接进行干预。C中的连接被替换为随机抽样的源输入,并且连接(G, H) ∈ C被替换为随机抽样的源输入,这些输入在H中将δ(H)设置为相同的值。Chan等人(2022b)将这些交换干预—基础和源输入在高级变量上达成一致—称为重采样消融。每个目标连接的确切干预值是通过递归交换干预确定的,该干预通过调用下面定义的算法Scrub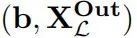 执行。
执行。


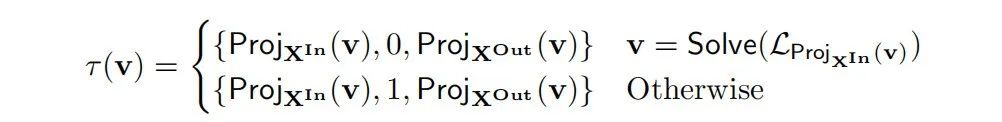

3.6 模块特征学习作为双射变换
机械解释性的一项核心任务是将激活向量解构为与人类可理解概念相对应的模块特征。我们将模块特征学习理解为构造一个双射变换(定义 28)。一些方法使用高层因果模型作为监督来源,以构造本地化在高层中间变量中编码的概念的模块特征。其他方法则完全是无监督的,产生的模块特征必须进一步分析以确定它们可能编码的概念。将模块特征学习形式化为双射变换提供了一个统一的框架,通过分布式互换干预来评估常用的机械解释性方法(参见 Huang et al. 2024 基于此框架的机械解释性基准)。
3.6.1 无监督方法
主成分分析 主成分分析(PCA)是一种将高维数据表示为低维空间的技术,同时最大限度地保留原始数据中的信息。PCA 已被用来识别与人类可解释概念相关的子空间,例如性别(Bolukbasi et al., 2016)、情感(Tigges et al., 2023)、真实性(Marks 和 Tegmark, 2023)以及涉及对象分类的视觉概念(Chormai et al., 2022)。

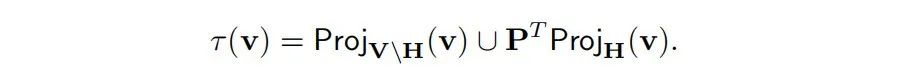


然而,在实际应用中,重建损失从未为零,因此稀疏自编码器只是对底层模型的近似变换。
3.6.2 将低级特征与高级变量对齐
一旦特征空间被学习到,还需要将特征与高级因果变量对齐。监督式的模块化特征学习技术会在设计特征空间时明确考虑与高级因果变量的对齐。然而,在无监督的模块化特征学习中,还需要额外的方法来将特征与高级因果变量对齐。
稀疏特征选择 一个简单的基准方法是训练一个带有正则化项的线性探测器,以选择与高级变量最相关的特征(Huang et al., 2024)。
差分二进制掩码 差分二进制掩码(DBM)通过优化一个二进制掩码来选择与高级变量相关的特征,该掩码的训练目标是使用干预定义的(De Cao et al., 2020; Csordás et al., 2021; De Cao et al., 2021; Davies et al., 2023; Huang et al., 2024)。DBM通常用于选择在特定因果角色中扮演角色的单个神经元,但只要双射变换是可微分的,它同样可以用于选择特征。
3.6.3 监督方法
探测器 探测器是一种技术,用于使用监督或无监督模型来确定概念是否存在于另一个模型的神经表示中。探测器是分析深度学习模型,特别是预训练语言模型的流行工具(Hupkes et al., 2018; Conneau et al., 2018; Peters et al., 2018; Tenney et al., 2019; Clark et al., 2019)。
虽然探测器非常简单,但我们对探测器的理论理解在它们最近引入领域后有了很大进展。从信息论的角度来看,使用任意强大的探测器等同于测量概念与神经表示之间的互信息(Hewitt and Liang, 2019; Pimentel et al., 2020)。如果我们根据探测模型的复杂性限制模型类,我们可以衡量信息的可用性(Xu et al., 2020; Hewitt et al., 2021)。
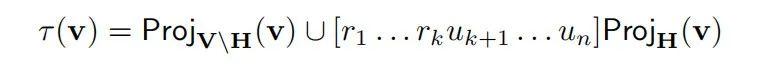

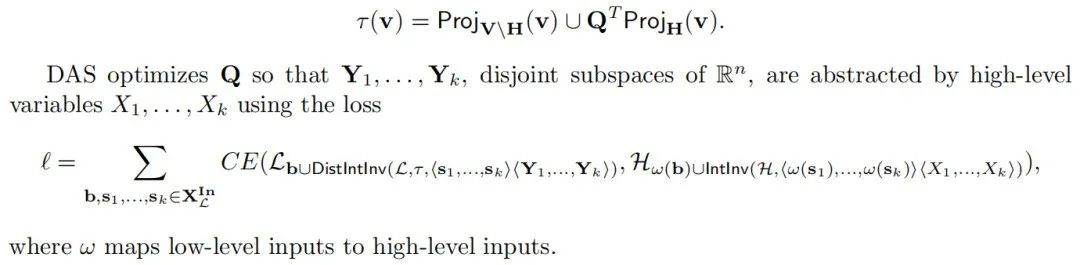
3.7 激活引导作为因果抽象
因果解释和操控本质上是相互关联的(Woodward, 2003);如果我们理解深度学习模型中哪些组件存储了高层因果变量,我们将能够通过对这些组件进行干预来控制深度学习模型的行为。
通过干预控制模型行为的研究最初集中在递归神经网络和生成对抗网络上(Giulianelli et al., 2018; Bau et al., 2019; Soulos et al., 2020; Besserve et al., 2020)。最近,许多研究关注于通过干预来引导大型语言模型的生成。例如,研究人员已证明,将固定的引导向量添加到变换器模型的残差流中,可以在不训练的情况下控制模型的生成(Subramani et al., 2022; Turner et al., 2023; Zou et al., 2023; Vogel, 2024; Li et al., 2024)。更近期的研究还表明,可以学习到加法干预来引导模型行为(Wu et al., 2024)。此外,像 Adaptor-tuning(Houlsby et al., 2019)这样的参数高效微调方法可以被视为一种表示干预方法,它对每个位置和层施加干预。
虽然成功的互换干预分析意味着能够控制低层模型,但反向并不成立。激活引导有可能将网络的内部表示从输入数据所诱导的分布中移开,可能会针对每个可能的模型输入都具有相同值的激活向量。对这个激活向量进行的互换干预将不会对模型行为产生任何影响。
然而,激活引导仍然可以在因果抽象的框架中进行表示。对于那些在特定方向上引导模型生成的有用激活向量,我们可以简单地将从低层干预到高层干预的映射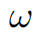 定义为引导干预而不是互换干预。关键点是,如果因果抽象分析未能在互换干预上定义
定义为引导干预而不是互换干预。关键点是,如果因果抽象分析未能在互换干预上定义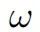 ,将无法揭示网络的推理过程。然而,它仍可能揭示如何控制网络的推理过程。
,将无法揭示网络的推理过程。然而,它仍可能揭示如何控制网络的推理过程。
4. 结论
我们认为,因果抽象为机制解释提供了理论基础,它澄清了核心概念,并为未来开发探讨 AI 模型内部推理复杂算法假设的方法奠定了有用的基础。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


















 2744
2744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









