






⇧点蓝色字关注“AI小小将”
没想到,字节seed团队竟然公开了他们文生图模型Seedream 2.0的技术报告,据我所知,目前字节在豆包和即梦上线的最新文生图模型应该是国内最强的文生图模型,无论模型出图质量,还是指令跟随能力都特别强,而且模型能很好地生成中文文字,我平时出中文文字基本都是用这个模型。所以这里,我们也第一时间给大家带来关于Seedream 2.0模型技术报告解读。
技术报告:https://arxiv.org/abs/2503.07703



模型架构
Seedream 2.0采用DiT架构,整体架构如下所示。
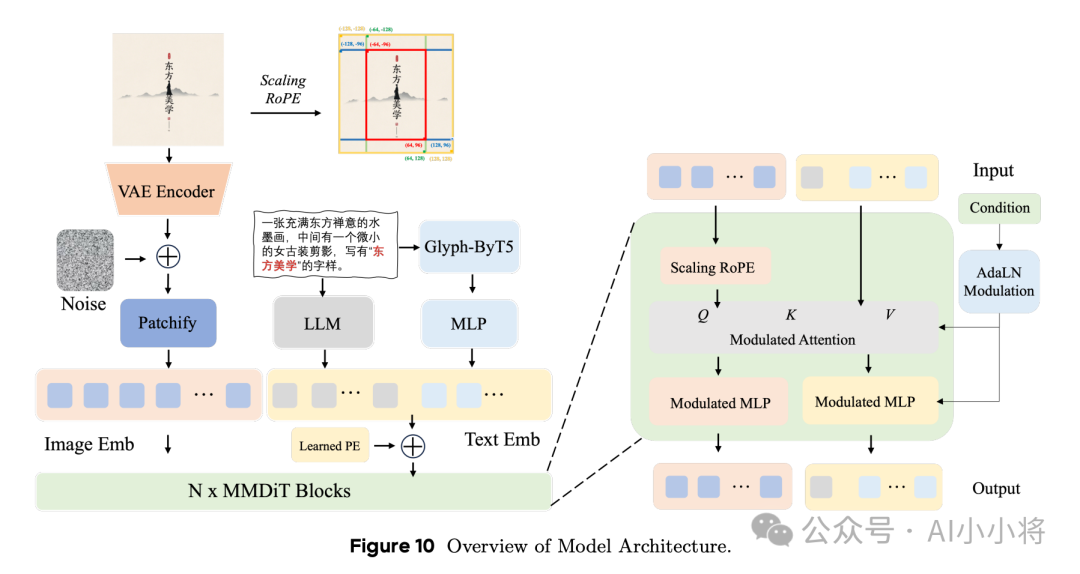
其中DiT采用SD3的MMDiT,文本tokens和图像tokens统一进行attention,但是参数不共享。这里的位置编码采用2D RoPE,这里新设计了一种2D RoPE:Scaling RoPE。从图中可以看到,这里的RoPE是以图像的中心来编码位置,同时不同分辨率图像设置不同的缩放因子,这样图像中心可以在不同分辨率下共享相似的位置ID,这使得模型在推理过程中能够在一定程度上泛化到未经训练的宽高比和分辨率。对于DiT的模型大小,技术报告里面没有说明。另外,这里的DiT只生成512的图像,要生成1024的图像,后面还专门接了一个refiner,这个refiner不仅提升图像分辨率,还可以优化结构细节(例如人脸的细节)并丰富纹理质量。猜测这里的refiner和SDXL的refiner一样,是单独训练了一个支持更大分辨率的文生图模型。

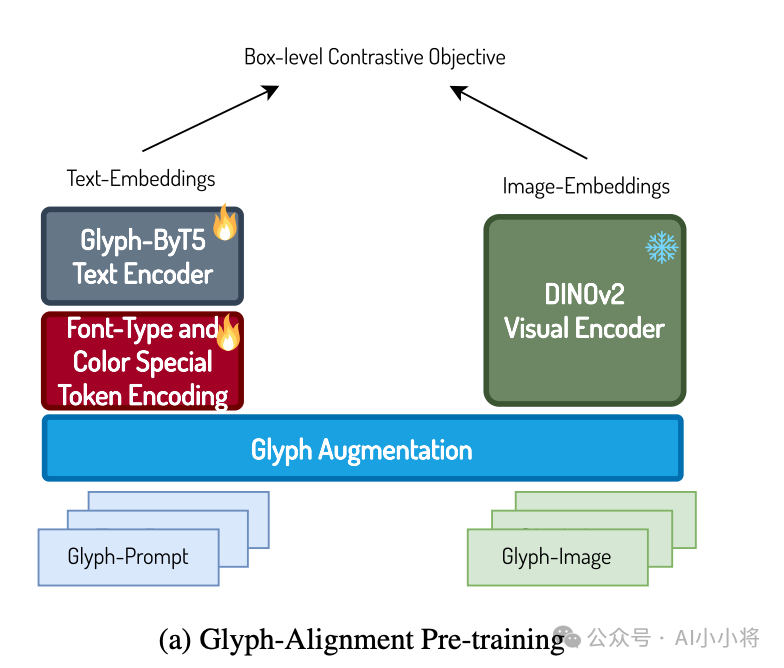
文本编码器没有采用T5,而是采用LLM,因为T5在理解中文文本方面的能力较弱,而主流的LLM通常具有出色的多语言能力,这对于模型能够更好地理解中文概念非常关键。另外,基于LLM的文本编码器训练扩散模型时容易出现不稳定,所以这里采用文本-图像对数据对LLM进行微调(可能按照CLIP的方法)。此外,除了LLM,这里还采用Glyph-ByT5来提取文本中文字的特征,然后和LLM文本特征拼接在一起送入DiT中。Glyph-ByT5在字符级的文本编码器ByT5基础上用字形图像和文字文本数据集按照CLIP的方法进行微调得到的,该模型不仅能够提供准确的字符级特征,而且提取的文本提示的字形特征已经和渲染文本的字形图像特征对齐,所以可以让模型更好地学习渲染文本的准确字形特征,从而提升模型生图的文字渲染准确性。
预训练数据
预训练数据主要包括四个部分:高质量数据、分布维护数据、知识注入数据以及针对性补充数据。高质量数据是极高图像质量和丰富知识内容的数据,这些数据基于清晰度、美学和来源分布进行筛选。分布维护数据应该是占比最多的数据,是从通用数据是采样得到,这里在减少低质量数据的同时,保持原始数据的有用分布。知识注入数据是包含鲜明中文语境的数据,以提高模型在中文特定场景中的表现。针对性补充数据是文生图任务中表现欠佳的数据,例如面向动作的数据和反事实数据(例如,“一个脖子上长着气球的男人”)。感觉字节在数据构建这方面确实下了很大的功夫。
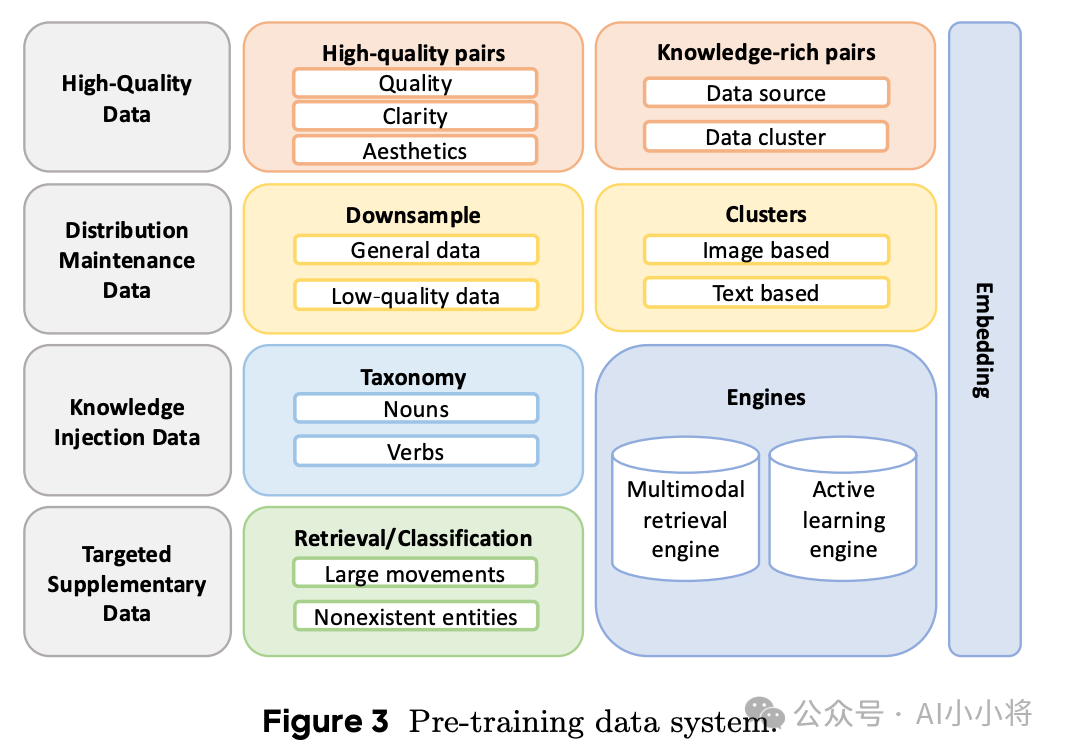
数据清洗也很重要,这里分成三个阶段。第一个阶段进行通用质量筛选,这里的质量标准包括通用质量评分(图像清晰度、运动模糊和无意义内容)、通用结构评分(水印、文本叠加、贴纸和徽标等元素)以及OCR检测。第二个阶段会进行聚类和去重,最后一个阶段给图像进行文本描述标注。
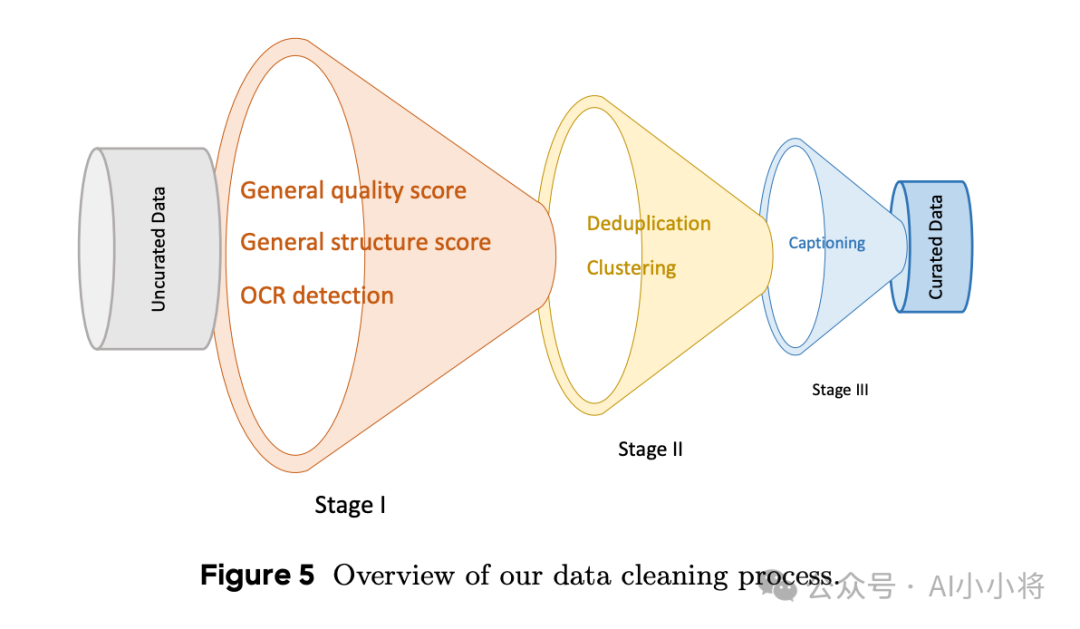
这里的文本描述标注会生成通用和专门的标注。其中通用的标注,包含中文和英文的简短和详细描述。
 除了通用标注外,这里还设计了针对不同场景的专门标注,比如描述美学元素如风格、色彩、构图和光影互动的艺术标注,专注于图像中存在的文本信息的文本标注、以及捕捉图像中超现实和奇幻的方面,提供更具想象力的视角的超现实标注。
除了通用标注外,这里还设计了针对不同场景的专门标注,比如描述美学元素如风格、色彩、构图和光影互动的艺术标注,专注于图像中存在的文本信息的文本标注、以及捕捉图像中超现实和奇幻的方面,提供更具想象力的视角的超现实标注。
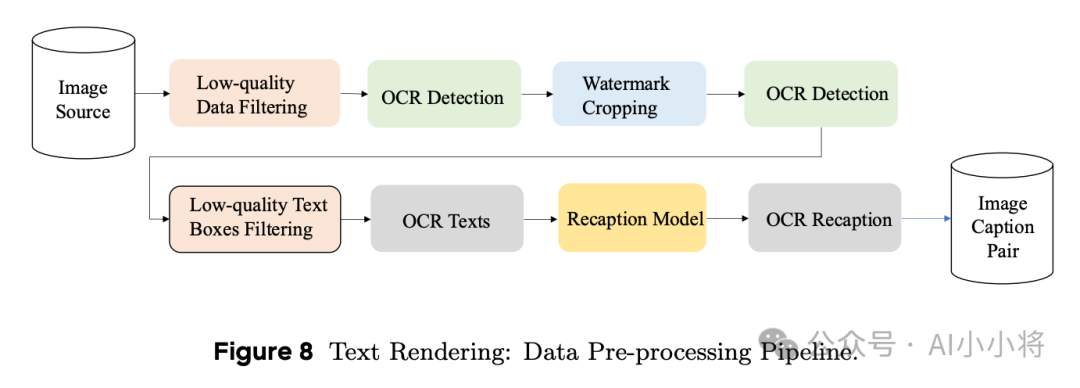
除了通用数据集,这里还专门基于OCR构建了一个大规模的视觉文本渲染数据集,应该主要是为了让模型能更好地学习文字渲染能力。
模型训练
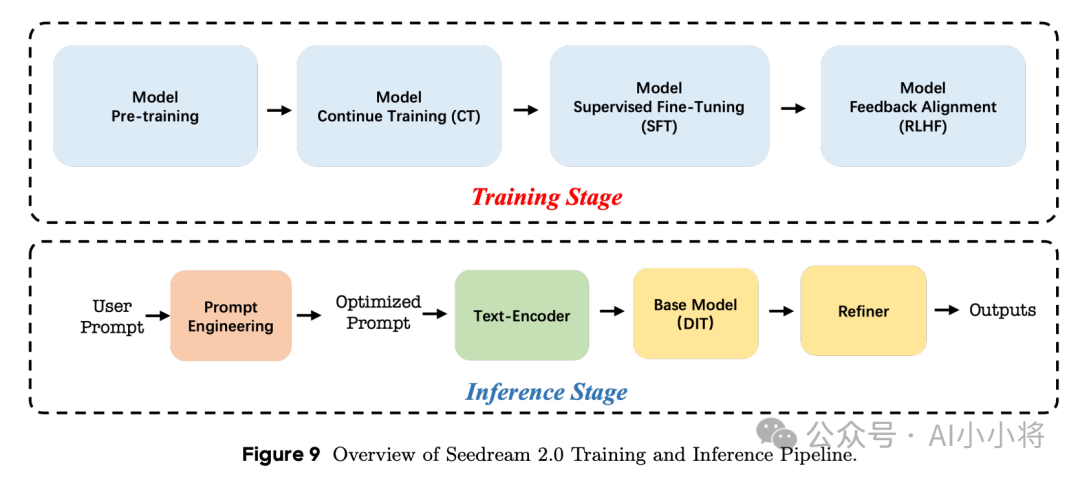
Seedream 2.0的训练过程包括四个阶段:预训练、继续训练(CT)、监督微调(SFT)和RLHF。后三个阶段都属于后训练过程(post-trainning)。
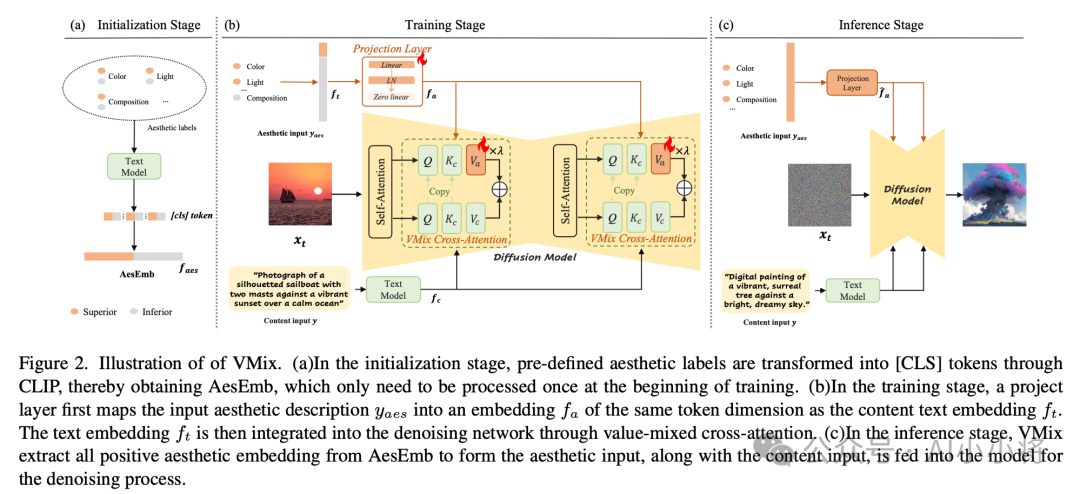
CT阶段使用更小但质量更高的数据集来延长预训练阶段来提升模型出图的美学质量。CT阶段的数据由两部分组成:从预训练数据集中筛选的高质量图像,以及人工精选数据(百万级别)。这里是按照比例混合两部分数据来防止模型对小数据集的过拟合。这里的训练方法采用之前字节已经发布的VMix,具体来说,这里会根据多个美学维度(即色彩、光影、纹理和构图)对每张图像进行标注,然后将这些标注作为补充条件用于CT训练过程中。VMix相当于通过条件注入的方式让模型更容易学习到图像美学特征。
SFT阶段是进一步采用少量精选的图像微调模型来提升模型出图美感。这里还专门训练了一个能够通过多轮人工修正精确描述美感和艺术性的caption模型来给图像标注,这些图像也分配了风格标签和细粒度的美学标签(用于VMix方法)。另外,SFT阶段还在训练中还加入了一定数量的模型生成的图像,这些图像被标记为“负样本”。这里的“负样本”应该指的是VMix中负美感的样本?
后训练的最后一个阶段是RLHF,文生图的RLHF其实用的并不多,但是这里的RLHF阶段在提升模型整体性能方面发挥了关键作用,包括图像-文本对齐、美学表现、结构准确性、文本渲染等多个方面。这里所使用的RLHF算法类似ImageReward中所提出的ReFL(Reward Feedback Learning),具体来说,需要训练reward模型,并用reward model以最大化模型生成图像的reward来微调模型。
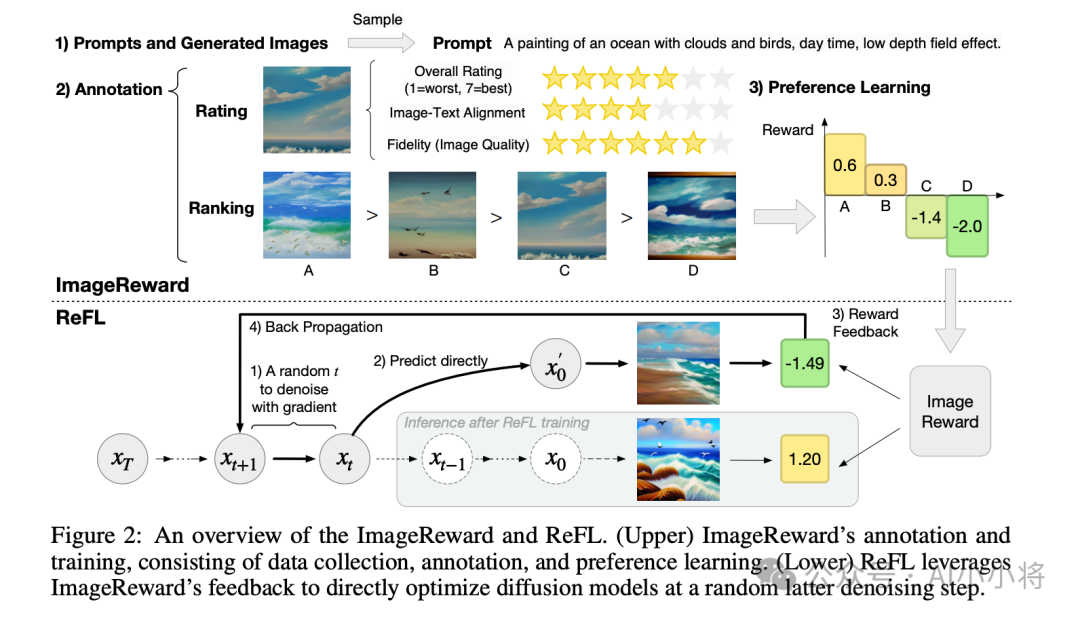
这里的reward model也和ImageReward类似,但是模型上采用支持中英双语的CLIP。而且训练了三个reward model:图像-文本对齐RM、美学RM和文本渲染RM。三个RM分别关注不同的方面。要想训练好RM,需要标注高质量的偏好数据,这里的文本提示词包含来源于训练标注和用户输入的多样化提示词,数据规模在百万级别。RLHF的训练过程还采用了迭代优化策略,具体来说是先基于当前的RM优化模型,然后用优化后的模型再进行偏好标注,并训练一个针对不良例子的RM,然后用更新后的RM进一步优化模型。这种迭代方法不仅可以提高RLHF过程中性能的上限,还可以实现更高的稳定性和可控性。另外,RLHF过程中还会打开LLM和DiT一起微调,这可以显著增强模型在图像-文本对齐和美学提升方面的能力。
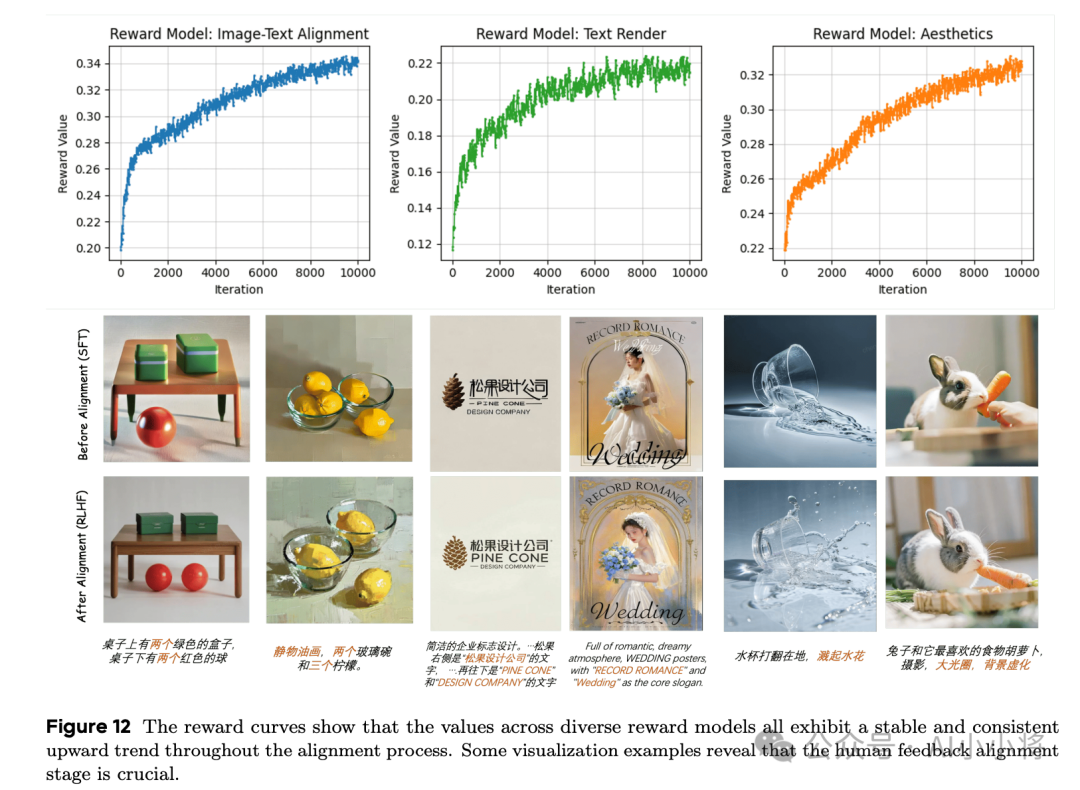
官方给出了RLHF训练过程的reward变化,可以看到随着训练过程,三个方面的reward均稳步提升,这说明好的RLHF确实可以提升文生图模型的上限。
此外,模型在推理阶段还会采用一个PE模型对输入的文本提示词进行改写来提升出图效果,因为用户输入的文本提示词往往很短。这里的PE模型其实就是一个定制化的LLM模型。这里的LLM会先用收集好的成对样本(输入简短文本和改写后的精细文本)来进行微调。然后会基于生图效果来进行RLHF,具体来说,会先用收集好的用户提示词来经过PE模型改写成不同的文本,并送入文生图模型出图,这里可以根据出图的美学以及图文匹配选择出一对<高质量,低质量>样本,然后基于DPO来微调PE模型。下面是PE模型对输入提示词改写后的出图效果,可以看到经过PE优化后,可以出多样化的高质量图像。

这里也有一些SFT、RLHF、PE以及Refiner出图的对比,可以看到随着优化,模型出图质量逐渐提升。

模型评测
模型评测方面,这里选择了GPT-4o(应该是DALLE-3)、Midjourney v6.1、FLUX1.1 Pro、Ideogram 2.0、快手的Kolors 1.5、美图的MiracleVision 5.0,以及腾讯的Hunyuan。对于中文提示词,只对比GPT-4o、Kolors 1.5、MiracleVision 5.0以及Hunyuan。
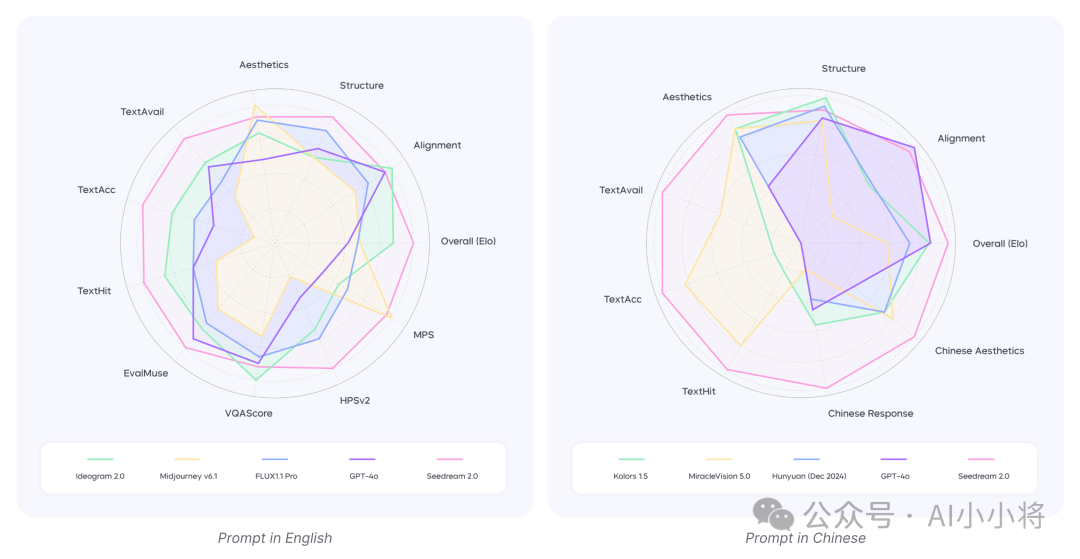
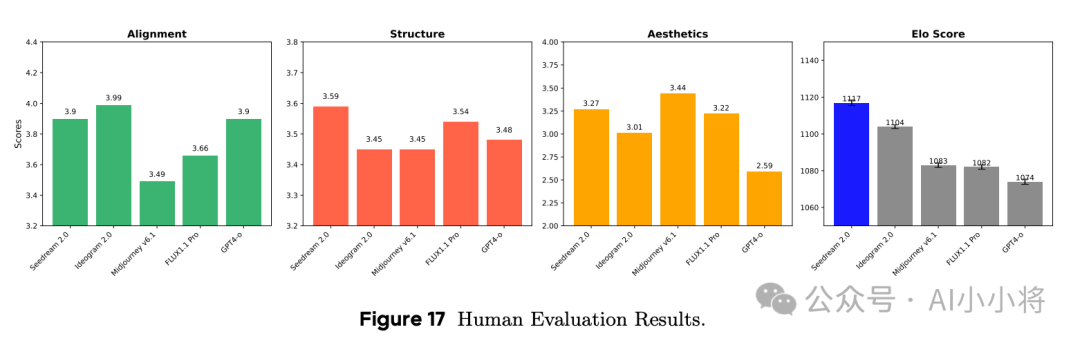
人工评测在包含240个提示词的Bench-240上进行,分成两个部分,第一部分是对图文对齐、结构正确性和美学质量三个方面人工打分(最高5分),第二个部分是进行两两偏好选择,最终计算Elo。评测结果如下所示,Seedream 2.0在三个维度均表现不错,其中图文对齐略低于Ideogram 2.0,图像美感略低于Midjourney v6.1,但Elo得分第一,超过其他模型。
自动化评测关注图文对齐以及图像美学质量两个维度。图文对齐方面采用EvalMuse和VQAScore,两个都是基于VLM模型来自动化评测。图像美学方面基于HPSv2、MPS以及内部的评估模型。自动化评测结果如下所示,其中VQAScore和人工评测结论是一致的,一些美学评估模型结果也和人工评测结论一致。
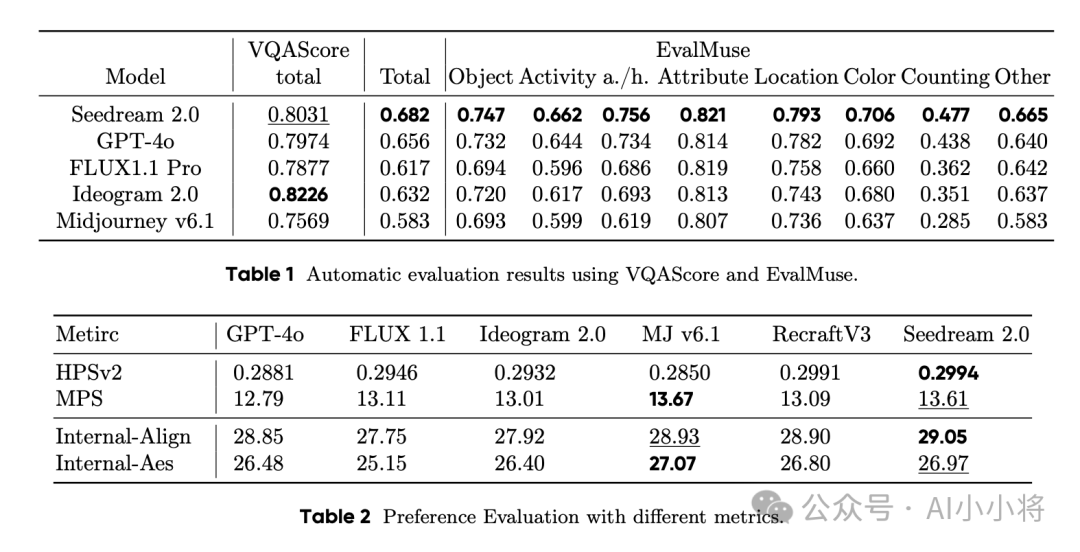
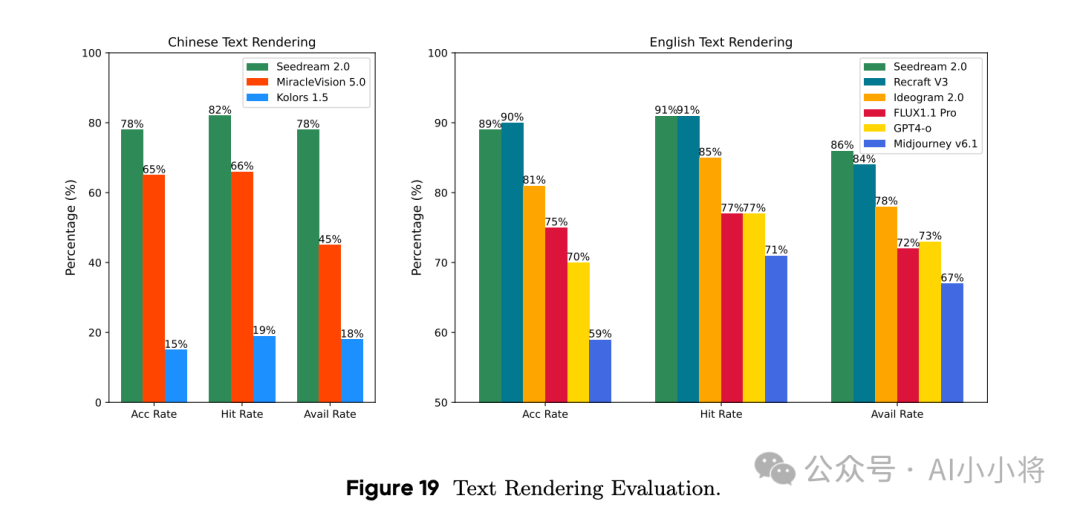
另外这里还评测模型渲染文字的能力,包括中文和英文,可以看到,中文方面Seedream 2.0领先其他中文模型,而英文方面也很强,和Recraft V3相当。
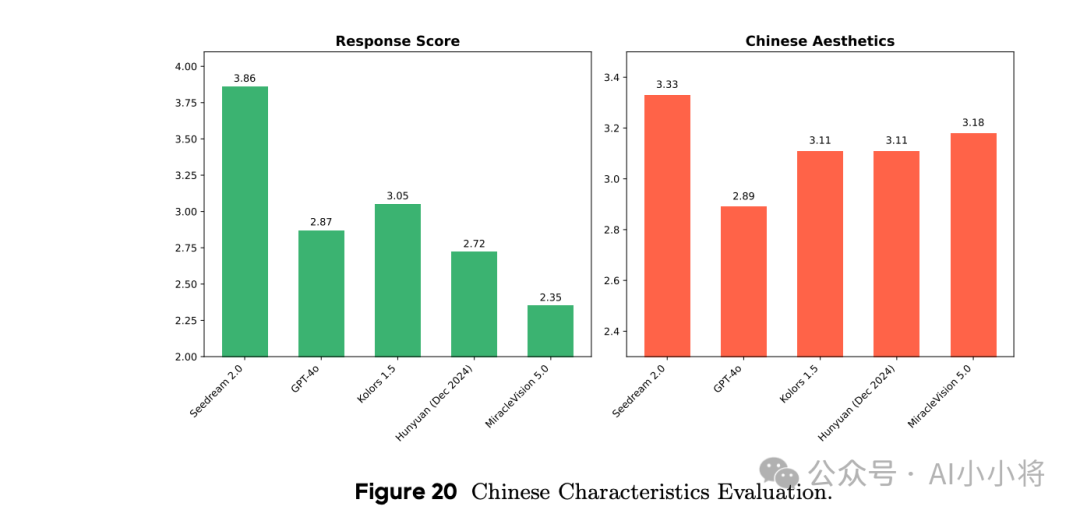
另外在对中国概念和特色生成方面,Seedream 2.0也领先其他模型。
下面是一些实例的对比:





读完技术报告,给我的感觉是,字节在文生图方面在数据、工程和算法方面都做的很细且很全面,这也是为啥国内能领先的主要原因吧,然后大家也应该特别注意RLHF在文生图上的价值。
如果觉得文章不错,欢迎点赞与转发!
进群,请公众号回复“进群”!

















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









