







目录
1)Mini-batch gradient descent(重点)
2)Understanding mini-batch gradient descent
3)Exponentially weighted averages
4)Understanding exponetially weighted averages
5)Bias correction in exponentially weighted average
6)Gradient descent with momentum(重点)
8)Adam optimization algorithm(重点)
10)The problem of local optima
以下笔记是吴恩达老师深度学习课程第二门课第二周的的学习笔记:Optimization algorithms。笔记参考了黄海广博士的内容,在此表示感谢。
深度学习难以在大数据领域发挥最佳效果的一个原因是:在巨大的数据集上进行训练速度很慢。而优化算法能够帮助快速训练模型,大大提高效率。本周,我们将讨论深度神经网络中的一些优化算法,通过使用这些技巧和方法来提高神经网络的训练速度。
1)Mini-batch gradient descent(重点)
我们之前一直使用的梯度下降算法是同时处理整个训练集,在更新参数的时候使用所有样本来进行更新;即每一步梯度下降需要对整个训练集进行一次处理,如果训练数据集很大的时候,处理速度就会比较慢。这种梯度下降算法被称为 Batch Gradient Descent。
为了解决批量梯度下降算法处理慢的问题,我们可以把训练样本划分为若干个子集,即 mini-batchs。然后在单一子集上进行神经网络训练,速度就会大大提升,这种梯度下降算法称为 Mini-batch Gradient Descent。
吴恩达老师在课程里介绍:假设我们有 m=5000000 个训练样本,维度为 ,将其分成 5000 个子集,每个子集含有 1000 个样本。我们将每个 mini-batch 记为
,维度为
;相应的每个mini-batch的输出为
,维度为
。
针对每一个 Mini-batch,神经网络进行一次训练,包含前向传播,计算代价函数,反向传播。经过多次训练之后,所有m个训练样本都进行了梯度下降计算。对所有训练样本进行一次梯度下降计算,称为一个 epoch。
2)Understanding mini-batch gradient descent
我们先来看一下批量梯度下降和小批量梯度下降的成本曲线图:

可以看出,对于Batch梯度下降而言,Mini-batch梯度下降随着迭代次数增加,cost不是单调下降,而是存在噪声,出现噪声的原因可能是不同的Mini-batch之间存在差异。
我们来看看不同的Mini-batch大小带来的影响。下图为:Batch,Mini-batch,SGD梯度下降的影响:

batch 梯度下降法:
- 对所有 m 个训练样本执行一次梯度下降,每一次迭代时间较长,训练过程慢;
- 相对噪声低一些,幅度也大一些;
- 成本函数总是向减小的方向下降。
随机梯度下降法:
- 对每一个训练样本执行一次梯度下降,训练速度快,但丢失了向量化带来的计算加速;
- 有很多噪声,减小学习率可以适当;
- 成本函数总体趋势向全局最小值靠近,但永远不会收敛,而是一直在最小值附近波
不同的Mini-batch大小对梯度下降的影响是不同的,一般Mini-batch大小的选择建议是这样的:
- 如果训练样本的大小比较小,如 m ⩽ 2000 时,选择 batch 梯度下降法;
- 如果训练样本的大小比较大,选择 Mini-Batch 梯度下降法。为了和计算机的信息存储方式相适应,代码在 mini-batch 大小为 2 的幂次时运行要快一些。典型的大小为
;
- mini-batch 的大小要符合 CPU/GPU 内存。
3)Exponentially weighted averages
这一节我们介绍指数加权平均的概念。
如图所示,为伦敦城市的气温变化:

看上去,温度变化噪声很大,如果想看到气温的整体变化趋势,可以通过移动平均的方法对气温进行平滑处理。
设第t天与第t-1天的气温变化关系为:,经过处理后得到的气温如下图红色曲线所示:

这种方法称为指数加权平均法,一般形式为:,其中
决定了指数加权平均的天数,近似表示为:
,当
为0.9时,表示将前10天的数据进行指数加权平均,为0.98是,表示将前50天的数据进行指数加权平均。下图黄色和绿色曲线分别标识了
和
的指数加权平均结果。

4)Understanding exponetially weighted averages
指数加权平均公式的一般形式为:
由公式可得, 为原始数据,
类似于指数曲线,
的值就是这两个式子的点乘。

指数平均加权并不是最精准的计算平均数的方法,你可以直接计算过去 10 天或 50 天的平均值来得到更好的估计,但缺点是保存数据需要占用更多内存,执行更加复杂,计算成本更加高昂。
指数加权平均数公式的好处之一在于它只需要一行代码,且占用极少内存,因此效率极高,且节省成本。
5)Bias correction in exponentially weighted average
上文中提到当β=0.98时,指数加权平均结果如下图绿色曲线所示。但是实际上,真实曲线如紫色曲线所示。

我们注意到,紫色曲线与绿色曲线的区别是,紫色曲线开始的时候相对较低一些。这是因为开始时我们设置,所以初始值会相对小一些,直到后面受前面的影响渐渐变小,趋于正常。
修正这种问题的方法是进行偏移校正(bias correction),即在每次计算完后,进行下式处理:。随着 t 的增大,β 的 t 次方趋近于 0。因此当 t 很大的时候,偏差修正几乎没有作用,但是在前期学习可以帮助更好的预测数据。在实际过程中,一般会忽略前期偏差的影响。
6)Gradient descent with momentum(重点)
动量梯度下降(Gradient Descent with Momentum)是计算梯度的指数加权平均数,并利用该值来更新参数值。具体过程为:
其中,将动量衰减参数 β 设置为 0.9 是超参数的一个常见且效果不错的选择。当 β 被设置为 0 时,显然就成了 batch 梯度下降法。
7)RMSprop(重点)
RMSprop是另外一种优化梯度下降速度的算法。每次迭代训练过程中,其权重W和常数项b的更新表达式为:
,
下面简单解释一下RMSprop算法的原理,仍然以下图为例,为了便于分析,令水平方向为W的方向,垂直方向为b的方向。
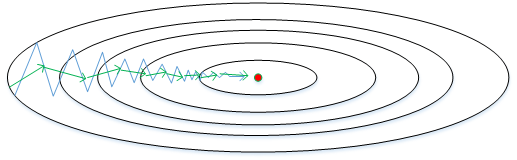
RMSProp 有助于减少抵达最小值路径上的摆动,并允许使用一个更大的学习率 α,从而加快算法学习速度。并且,它和 Adam 优化算法已被证明适用于不同的深度学习网络结构。注意,β 也是一个超参数。
还有一点需要注意的是为了避免RMSprop算法中分母为零,通常可以在分母增加一个极小的常数ε:
其中,ε,或者其它较小值。
8)Adam optimization algorithm(重点)
Adam 优化算法(Adaptive Moment Estimation,自适应矩估计)基本上就是将 Momentum 和 RMSProp 算法结合在一起,
算法流程为,初始化:
用每一个 mini-batch 计算 dW、db,第 t 次迭代时:
一般使用 Adam 算法时需要计算偏差修正:
,
;
所以,更新 W、b 时有:
,
Adam 优化算法有很多的超参数,其中
学习率 α:需要尝试一系列的值,来寻找比较合适的;
:常用的缺省值为 0.9;
:Adam 算法的作者建议为 0.999;
ϵ:不重要,不会影响算法表现,Adam 算法的作者建议为 $10^{-8}$;
β1、β2、ϵ 通常不需要调试
9)Learning rate decay
如果设置一个固定的学习率 α,在最小值点附近,由于不同的 Mini-batch 中存在一定的噪声,因此不会精确收敛,而是始终在最小值周围一个较大的范围内波动。
而如果随着时间慢慢减少学习率 α 的大小,在初期 α 较大时,下降的步长较大,能以较快的速度进行梯度下降;而后期逐步减小 α 的值,即减小步长,有助于算法的收敛,更容易接近最优解。
最常用的学习率衰减方法:
其中,为衰减率(超参数),
为将所有的训练样本完整过一遍的次数。 .
指数衰减方法:
其它方法:
除此之外,还可以设置α为关于t的离散值,随着t增加,α呈阶梯式减小。当然,也可以根据训练情况灵活调整当前的α值,但会比较耗时间。
10)The problem of local optima
在使用梯度下降算法不断减小cost function时,可能会得到局部最优解(local optima)而不是全局最优解(global optima)。之前我们对局部最优解的理解是形如碗状的凹槽,如下图左边所示。但是在神经网络中,local optima的概念发生了变化。准确地来说,大部分梯度为零的“最优点”并不是这些凹槽处,而是形如右边所示的马鞍状,称为saddle point。也就是说,梯度为零并不能保证都是convex(极小值),也有可能是concave(极大值)。特别是在神经网络中参数很多的情况下,所有参数梯度为零的点很可能都是右边所示的马鞍状的saddle point,而不是左边那样的local optimum。

-
鞍点(saddle)是函数上的导数为零,但不是轴上局部极值的点。当我们建立一个神经网络时,通常梯度为零的点是上图所示的鞍点,而非局部最小值。减少损失的难度也来自误差曲面中的鞍点,而不是局部最低点。因为在一个具有高维度空间的成本函数中,如果梯度为 0,那么在每个方向,成本函数或是凸函数,或是凹函数。而所有维度均需要是凹函数的概率极小,因此在低维度的局部最优点的情况并不适用于高维度。
结论:
- 在训练较大的神经网络、存在大量参数,并且成本函数被定义在较高的维度空间时,困在极差的局部最优中是不大可能的;
- 鞍点附近的平稳段会使得学习非常缓慢,而这也是动量梯度下降法、RMSProp 以及 Adam 优化算法能够加速学习的原因,它们能帮助尽早走出平稳段。
值得一提的是,上文介绍的动量梯度下降,RMSprop,Adam算法都能有效解决plateaus下降过慢的问题,大大提高神经网络的学习速度。
11)Summary
本周我们学习深度学习中的优化算法:
- Mini-batch梯度下降算法,动量梯度下降算法,RMSprop算法和Adam算法;
- 还介绍了学习率衰减和局部最优等问题。
















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









