







文章目录
主成分分析PCA
- 降维(Dimensionality Reduction,DR)是指采用线性或者非线性的映射方法将高维空间的样本映射到低维空间中。
- 主成分分析:最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中
- PCA是丢失原始数据信息最少的一种线性降维方法,最接近原始数据
- PCA算法目标是求出样本数据的协方差矩阵的特征值和特征向量
- 特征向量方向:降维投影方向
- 特征值:N维数据特征值从大到小排列,选取前K个维度的特征作为降维后的特征。(N–>K)
没有改变样本之间的线性关系,只是应用了新的坐标系。
N–>K维,取前K个特征值对应的特征向量。
缺点:不适合数据量和数据维度非常大的时候
数学计算过程
设有m条n维数据,PCA的一般步骤如下:
- 将原始数据按列组成n行m列矩阵X
- 计算矩阵X中每个特征属性(n维)的平均向量M(平均值)
- 将X的每行(代表一个属性字段)进行零均值化,即减去M
- 按照公式𝐶=1/m 𝑋𝑋^𝑇求出协方差矩阵
- 求出协方差矩阵的特征值及对应的特征向量
- 将特征向量按对应特征值从大到小按行排列成矩阵,取前k(k < n)行组成基向量P
- 通过𝑌=𝑃𝑋计算降维到k维后的样本特征
纯数学实现代码
- 数据准备
- PCA降维实现
- 可视化
# -*- coding: utf-8 -*-
import numpy as np
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
#1.数据准备
np.random.seed(1) # random seed for consistency
mu_vec1 = np.array([0,0,0])#均值
cov_mat1 = np.array([[1,0,0],[0,1,0],[0,0,1]])#方差
class1_sample = np.random.multivariate_normal(mu_vec1, cov_mat1, 20).T#多变量正态分布
mu_vec2 = np.array([1,1,1])
cov_mat2 = np.array([[1,0,0],[0,1,0],[0,0,1]])
class2_sample = np.random.multivariate_normal(mu_vec2, cov_mat2, 20).T
# 创建一个3D图形窗口并绘制散点图
fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(111, projection='3d')
plt.rcParams['legend.fontsize'] = 10
ax.plot(class1_sample[0,:], class1_sample[1,:], class1_sample[2,:], 'o', markersize=8, color='blue', alpha=0.5, label='class1')
# ax.plot(class1_sample[:,0], class1_sample[:,1], class1_sample[:,2], 'o', markersize=8, color='blue', alpha=0.5, label='class1')
ax.plot(class2_sample[0,:], class2_sample[1,:], class2_sample[2,:], '^', markersize=8, alpha=0.5, color='red', label='class2')
plt.title('class1 and class2 ')
ax.legend(loc='upper right')
plt.show()
#################################################################
# 2. 降维(模型构建)过程
# 合并所有样本数据,计算均值向量
all_samples = np.concatenate((class1_sample, class2_sample), axis=1)
mean_x = np.mean(all_samples[0,:])
mean_y = np.mean(all_samples[1,:])
mean_z = np.mean(all_samples[2,:])
mean_vector = np.array([[mean_x],[mean_y],[mean_z]])#均值向量
print('Mean Vector:\n', mean_vector)
#计算散度矩阵
scatter_matrix = np.zeros((3,3))
for i in range(all_samples.shape[1]):
scatter_matrix += (all_samples[:,i].reshape(3,1) - mean_vector).dot((all_samples[:,i].reshape(3,1) - mean_vector).T)
print('Scatter Matrix:\n', scatter_matrix)
#计算协方差矩阵
sample_x =all_samples[0,:]
sample_y =all_samples[1,:]
sample_z =all_samples[2,:]
cov_mat = np.cov([sample_x,sample_y,sample_z])
print('Covariance Matrix:\n', cov_mat)
# np.linalg.eig:计算特征值和特征向量
eig_val_sc, eig_vec_sc = np.linalg.eig(scatter_matrix)#计算散度矩阵的特征值和特征向量
eig_val_cov, eig_vec_cov = np.linalg.eig(cov_mat)#计算协方差矩阵的特征值和特征向量
#print("eig_val_cov:",eig_val_cov)
print("eig_vec_sc:",eig_vec_sc)
print("eig_val_sc",eig_val_sc)
# 检查散点矩阵特征向量、协方差矩阵特征向量是否一致并输出特征向量和特征值
for i in range(len(eig_val_sc)):
eigvec_sc = eig_vec_sc[:,i].reshape(1,3).T
eigvec_cov = eig_vec_cov[:,i].reshape(1,3).T
assert eigvec_sc.all() == eigvec_cov.all(), 'Eigenvectors are not identical'
print('Eigenvector {}: \n{}'.format(i+1, eigvec_sc))
print('Eigenvalue {} from scatter matrix: {}'.format(i+1, eig_val_sc[i]))
print('Eigenvalue {} from covariance matrix: {}'.format(i+1, eig_val_cov[i]))
print('Scaling factor: ', eig_val_sc[i]/eig_val_cov[i])
print(40 * '-')
for i in range(len(eig_val_sc)):
eigv = eig_vec_sc[:,i].reshape(1,3).T
np.testing.assert_array_almost_equal(scatter_matrix.dot(eigv), eig_val_sc[i] * eigv,
decimal=6, err_msg='', verbose=True)
# 对特征值和特征向量对进行排序并构建转换矩阵W
eig_pairs = [(np.abs(eig_val_sc[i]), eig_vec_sc[:,i]) for i in range(len(eig_val_sc))]
print("eig_pairs:",eig_pairs)
# 将特征值和特征向量从高到底进行排序:选择最大的特征值对应的特征向量作为主成分,构建投影矩阵matrix_w。
eig_pairs.sort(key=lambda x: x[0], reverse=True)
for i in eig_pairs:
print(i[0])
# 构建投影矩阵matrix_w
matrix_w = np.hstack((eig_pairs[0][1].reshape(3,1), eig_pairs[1][1].reshape(3,1)))
print('Matrix W:\n', matrix_w)
# 使用投影矩阵将原始数据投影到主成分空间,得到降维后的数据transformed。
transformed = matrix_w.T.dot(all_samples)
###################################################################################################
#3.绘制降维后的数据
plt.plot(transformed[0,0:20], transformed[1,0:20], 'o', markersize=7, color='blue', alpha=0.5, label='class1')
plt.plot(transformed[0,20:40], transformed[1,20:40], '^', markersize=7, color='red', alpha=0.5, label='class2')
plt.xlim([-4,4])
plt.ylim([-4,4])
plt.xlabel('x_values')
plt.ylabel('y_values')
plt.legend()
plt.show()
原始数据:
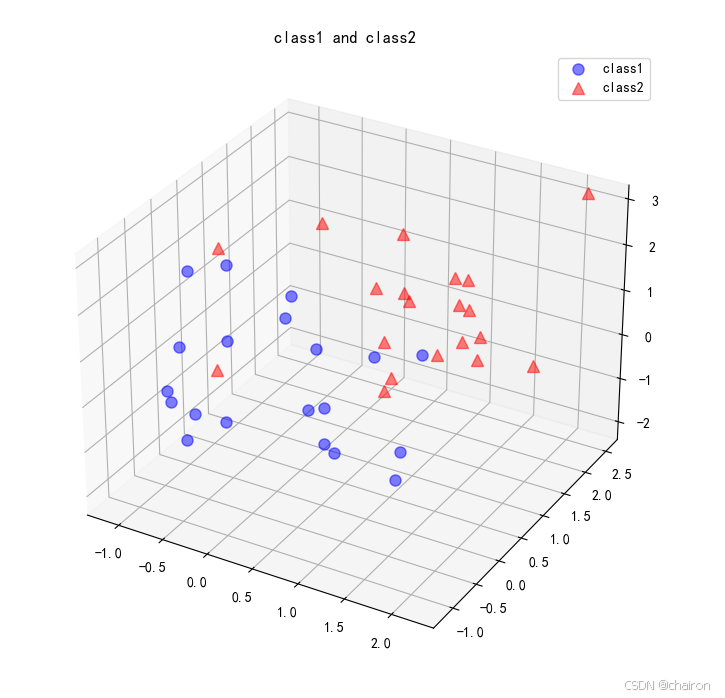
降维后数据:
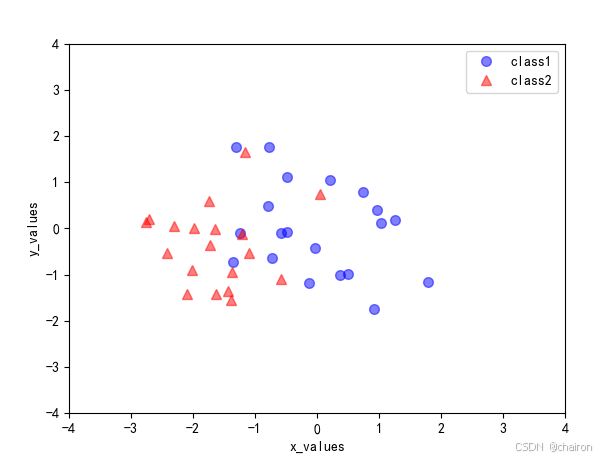
Sklearn 库实现
# -*- coding: utf-8 -*-
import numpy as np
from matplotlib import pyplot as plt
from sklearn.decomposition import PCA
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
np.random.seed(1) # random seed for consistency
#类别1数据20个
mu_vec1 = np.array([0,0,0])#均值
cov_mat1 = np.array([[1,0,0],[0,1,0],[0,0,1]])#方差
class1_sample = np.random.multivariate_normal(mu_vec1, cov_mat1, 20).T#多变量正态分布
#类别2数据20个
mu_vec2 = np.array([1,1,1])
cov_mat2 = np.array([[1,0,0],[0,1,0],[0,0,1]])
class2_sample = np.random.multivariate_normal(mu_vec2, cov_mat2, 20).T
# 创建一个3D图形窗口并绘制散点图
fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(111, projection='3d')
plt.rcParams['legend.fontsize'] = 10
#因为进行了转置,所以行列互换:行:特征、列:个数
ax.plot(class1_sample[0,:], class1_sample[1,:], class1_sample[2,:], 'o', markersize=8, color='blue', alpha=0.5, label='class1')
ax.plot(class2_sample[0,:], class2_sample[1,:], class2_sample[2,:], '^', markersize=8, alpha=0.5, color='red', label='class2')
plt.title('class1 and class2 ')
ax.legend(loc='upper right')
plt.show()
# 合并所有样本数据
all_samples = np.concatenate((class1_sample, class2_sample), axis=1).T
####################################################################################################
# 初始化PCA,设置主成分数量为2
pca = PCA(n_components=2)
# 对样本数据进行PCA拟合和转换
transformed = pca.fit_transform(all_samples)
################################################################################
# 绘制降维后的数据:PCA降维之后,行列是正常的
plt.plot(transformed[0:20,0], transformed[0:20,1], 'o', markersize=7, color='blue', alpha=0.5, label='class1')
plt.plot(transformed[20:40,0], transformed[20:40,1], '^', markersize=7, color='red', alpha=0.5, label='class2')
plt.xlim([-4,4])
plt.ylim([-4,4])
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.legend()
plt.show()
# 输出PCA模型的特征值和特征向量
print('Explained variance ratio:', pca.explained_variance_ratio_)
print('Components:', pca.components_)
pca = PCA(n_components=2)
transformed = pca.fit_transform(all_samples)
其实核心代码就这两行。
初始化模型;训练(在这里就是降维的过程)
实训:全球气候数据的PCA降维分析

数据采用随机函数生成:
np.random.seed(42)
climate_data = np.random.rand(50, 4) # 50个地区,每个地区4个气候指标
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 假设climate_data是一个包含气候指标的NumPy数组
# 这里我们使用随机数据作为示例
np.random.seed(42)
climate_data = np.random.rand(50, 4) # 50个地区,每个地区4个气候指标
# # 标准化数据
# scaler = StandardScaler()
# climate_scaled = scaler.fit_transform(climate_data)
# 应用PCA降维
pca = PCA(n_components=2) # 降维到2维
# climate_pca = pca.fit_transform(climate_scaled)
climate_pca = pca.fit_transform(climate_data)
# 绘制降维后的气候特征分布
plt.figure(figsize=(8, 6))
plt.scatter(climate_pca[:, 0], climate_pca[:, 1])
plt.title('PCA降维后的全球气候特征分布')
plt.xlabel('第一主成分')
plt.ylabel('第二主成分')
plt.grid(True)
plt.show()
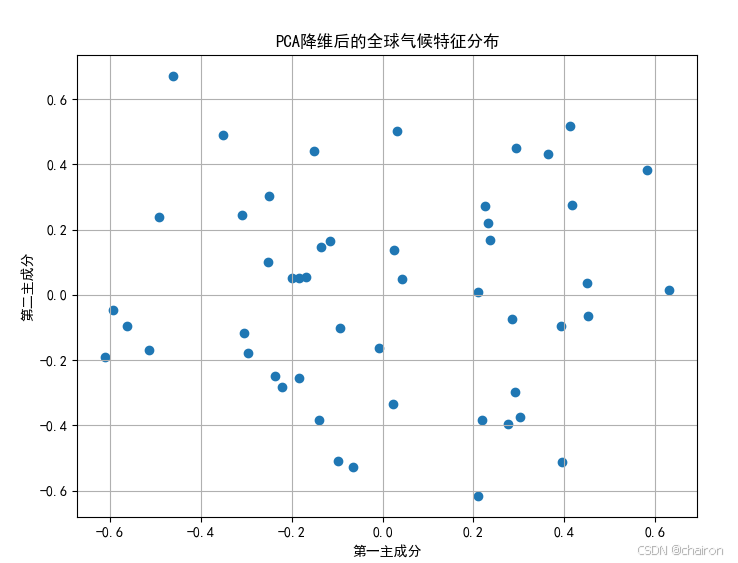
奇异值分解SVD

奇异值分解(Singular Value Decomposition) 是矩阵低秩分解的一种方法,在机器学习领域具有广泛的应用。它不光可以用于图像压缩,降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域。是许多机器学习算法的基石。
使用SVD对鸢尾花数据进行降维
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.decomposition import TruncatedSVD
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data # 提取特征数据
y = iris.target # 提取目标标签
# 创建截断奇异值分解对象,设置保留的主成分数量为2
svd = TruncatedSVD(n_components=2)
# 对特征数据进行降维处理
X_reduced = svd.fit_transform(X)
# 绘制降维后数据的散点图
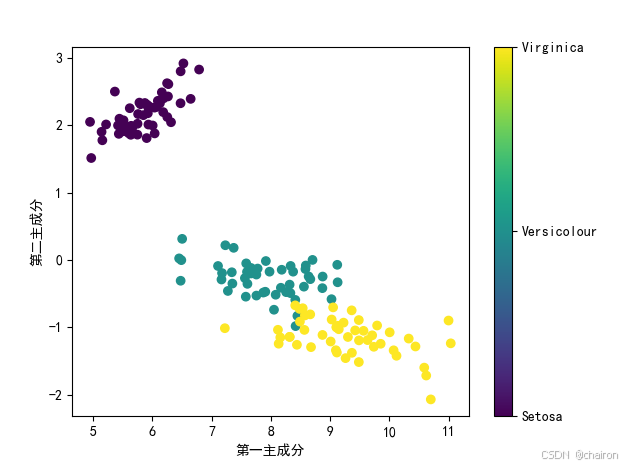
sc = plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=y, cmap='viridis')
plt.xlabel('第一主成分') # 设置x轴标签
plt.ylabel('第二主成分') # 设置y轴标签
# 创建颜色条
cbar = plt.colorbar(sc)
# 设置颜色条的刻度标签
categories = ['Setosa', 'Versicolour', 'Virginica']
cbar.set_ticks(np.unique(y)) # 确保颜色条上的刻度与类别数一致
cbar.set_ticklabels(categories) # 设置每个刻度的标签
plt.show() # 显示绘制的散点图
线性判别分析LDA
- LDA(线性判别分析)是一种常用的监督性降维技术,通过最大化类间差异和最小化类内差异来实现数据的降维。
- LDA(线性判别分析) :找到一条直线(低维空间),使得将平面(高维空间)中的样本点投影到直线(低维空间)中,尽量使得同类样本点接近,异类样本点远离,判断新样本:当将新样本投影后,根据其投影后的位置判断其类别。
数学实现
#coding=utf-8
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import LatentDirichletAllocation
# 1. 获取数据
#读取数据文件iris.data.txt,并将其转换为DataFrame,header=None表示文件没有列名
df = pd.read_csv('iris.data.txt', header=None)
# 将DataFrame的第5列(索引从0开始)中的类别标签映射为数字
# 'Iris-setosa'映射为0,'Iris-versicolor'映射为1,'Iris-virginica'映射为2
df[4] = df[4].map({'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2})
# 打印数据的最后几行,以查看数据是否正确加载和转换
print(df.tail())
# 提取目标向量y(第5列,即类别标签)和特征矩阵X(前4列,即特征数据)
X = df.iloc[:, 0:4].values#iloc:通过索引获取数据
y = df.iloc[:, 4].values
# 2. 降维过程
lda= LatentDirichletAllocation(n_components=2)
X_lda=lda.fit_transform(X)
###########################################
# 2.降维过程
# 标准化特征矩阵X,使其具有0均值和单位标准差
X_cent = X - X.mean(axis=0) # 减去每列的均值
X_std = X_cent / X.std(axis=0) # 除以每列的标准差
# 定义函数计算每个类别的均值向量
def comp_mean_vectors(X, y):
class_labels = np.unique(y) # 获取所有唯一的类别标签
n_classes = class_labels.shape[0] # 类别数量
mean_vectors = [] # 初始化均值向量列表
for cl in class_labels: # 对每个类别
mean_vectors.append(np.mean(X[y==cl], axis=0)) # 计算均值向量并添加到列表
return mean_vectors
# 定义函数计算类内散布矩阵S_W
def scatter_within(X, y):
class_labels = np.unique(y) # 获取所有唯一的类别标签
n_classes = class_labels.shape[0] # 类别数量
n_features = X.shape[1] # 特征数量
mean_vectors = comp_mean_vectors(X, y) # 计算均值向量
S_W = np.zeros((n_features, n_features)) # 初始化类内散度矩阵
for cl, mv in zip(class_labels, mean_vectors): # 对每个类别和均值向量
class_sc_mat = np.zeros((n_features, n_features)) # 初始化类别散度矩阵
for row in X[y == cl]: # 对该类别的每行数据
row, mv = row.reshape(n_features, 1), mv.reshape(n_features, 1) # 重塑为矩阵
class_sc_mat += (row-mv).dot((row-mv).T) # 计算每个类别的协方差矩阵
S_W += class_sc_mat # 累加到总的类内散度矩阵
return S_W
# 定义函数计算类间散布矩阵S_B
def scatter_between(X, y):
overall_mean = np.mean(X, axis=0) # 计算所有数据的均值
n_features = X.shape[1] # 特征数量
mean_vectors = comp_mean_vectors(X, y) # 计算均值向量
S_B = np.zeros((n_features, n_features)) # 初始化类间散度矩阵
for i, mean_vec in enumerate(mean_vectors): # 对每个均值向量
n = X[y==i,:].shape[0] # 当前类别的数据数量
mean_vec = mean_vec.reshape(n_features, 1) # 重塑为矩阵
overall_mean = overall_mean.reshape(n_features, 1) # 重塑为矩阵
S_B += n * (mean_vec - overall_mean).dot((mean_vec - overall_mean).T) # 计算散度矩阵并累加
return S_B
# 定义函数获取特征值和特征向量,并选择前n个主成分
def get_components(eig_vals, eig_vecs, n_comp=1):
n_features = X.shape[1] # 特征数量
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:,i]) for i in range(len(eig_vals))] # 特征值和特征向量对
eig_pairs = sorted(eig_pairs, key=lambda k: k[0], reverse=True) # 按特征值大小排序
W = np.hstack([eig_pairs[i][1].reshape(4, 1) for i in range(0, n_comp)]) # 选择前n个特征向量并水平堆叠
return W
# 计算类内散布矩阵S_W和类间散布矩阵S_B
S_W, S_B = scatter_within(X, y), scatter_between(X, y)
# np.linalg.eig:计算特征值和特征向量;并选择前两个主成分
eig_vals, eig_vecs = np.linalg.eig(np.linalg.inv(S_W).dot(S_B))#np.linalg.inv(S_W)S_w的逆矩阵
W = get_components(eig_vals, eig_vecs, n_comp=2)
X_lda = X.dot(W) # 使用特征向量W对X进行投影
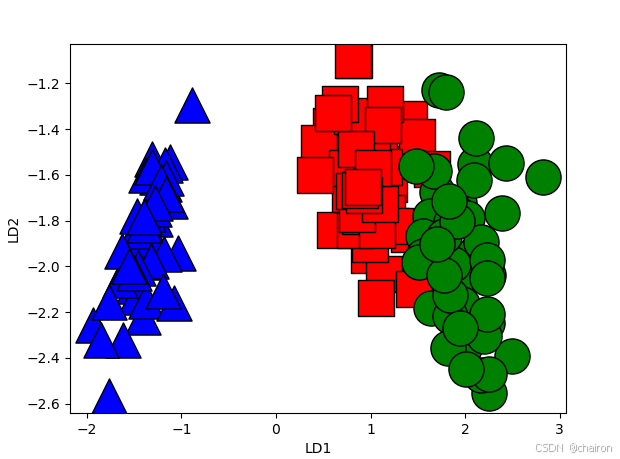
#3.降维可视化
# 绘制投影后的数据点,使用主成分进行降维
plt.xlabel('LD1') # 设置x轴标签为LD1(线性判别分析的第一主成分)
plt.ylabel('LD2') # 设置y轴标签为LD2(线性判别分析的第二主成分)
for label,marker,color in zip(np.unique(y),('^', 's', 'o'),('blue', 'red', 'green')): # 对每个类别
plt.scatter(X_lda[y==label, 0], X_lda[y==label, 1], c=color, edgecolors='black', marker=marker, s=640) # 绘制散点图
plt.show() # 显示图表
机器学习库实现
对鸢尾花数据进行降维
- 如果降维到3维,报错:
ValueError: n_components cannot be larger than min(n_features, n_classes - 1).
原因:LDA降维后的维度n必须不能大于min(特征数,类别数-1);类别是3,因此只能是2维度。
from sklearn import datasets
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import matplotlib.pyplot as plt
# 1.加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
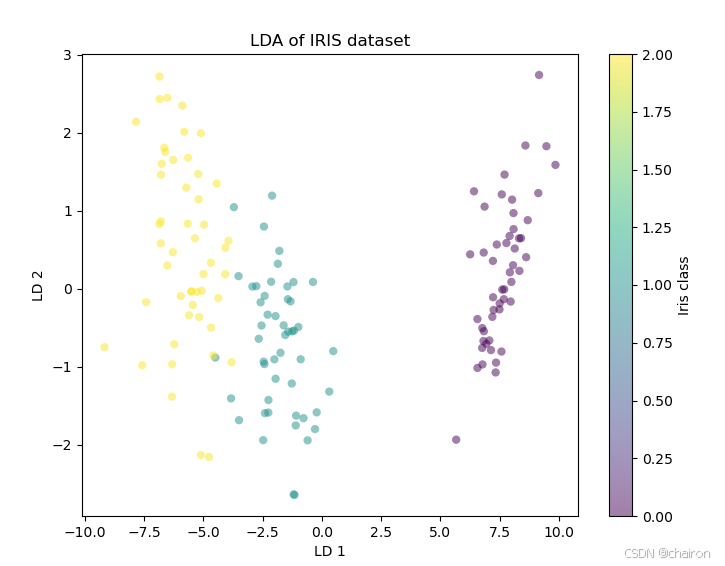
# 2.应用LDA降维,降到2维
lda = LinearDiscriminantAnalysis(n_components=2)
Reduced_lda = lda.fit_transform(X, y)
# 可视化降维结果
plt.figure(figsize=(8, 6))
plt.scatter(Reduced_lda[:, 0], Reduced_lda[:, 1], c=y, edgecolor='none', alpha=0.5, cmap='viridis')
plt.xlabel('LD 1')
plt.ylabel('LD 2')
plt.colorbar(label='Iris class')
plt.title('LDA of IRIS dataset')
plt.show()
降维练习
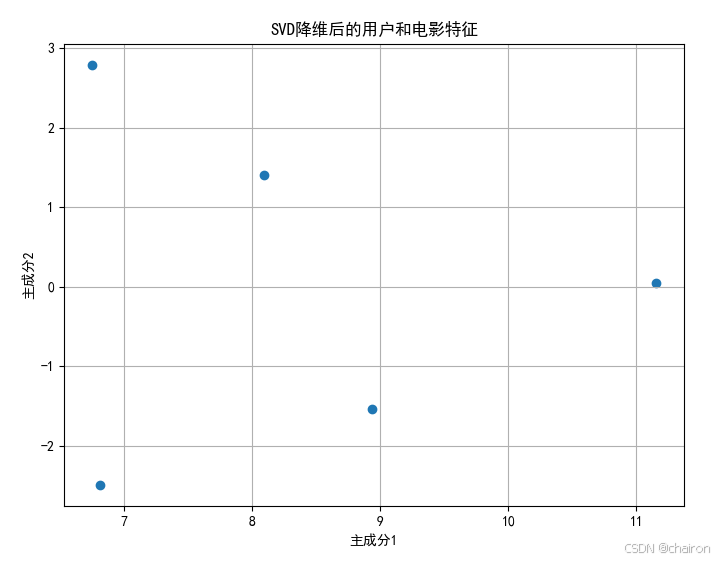
1. 用户-电影评分矩阵的SVD降维
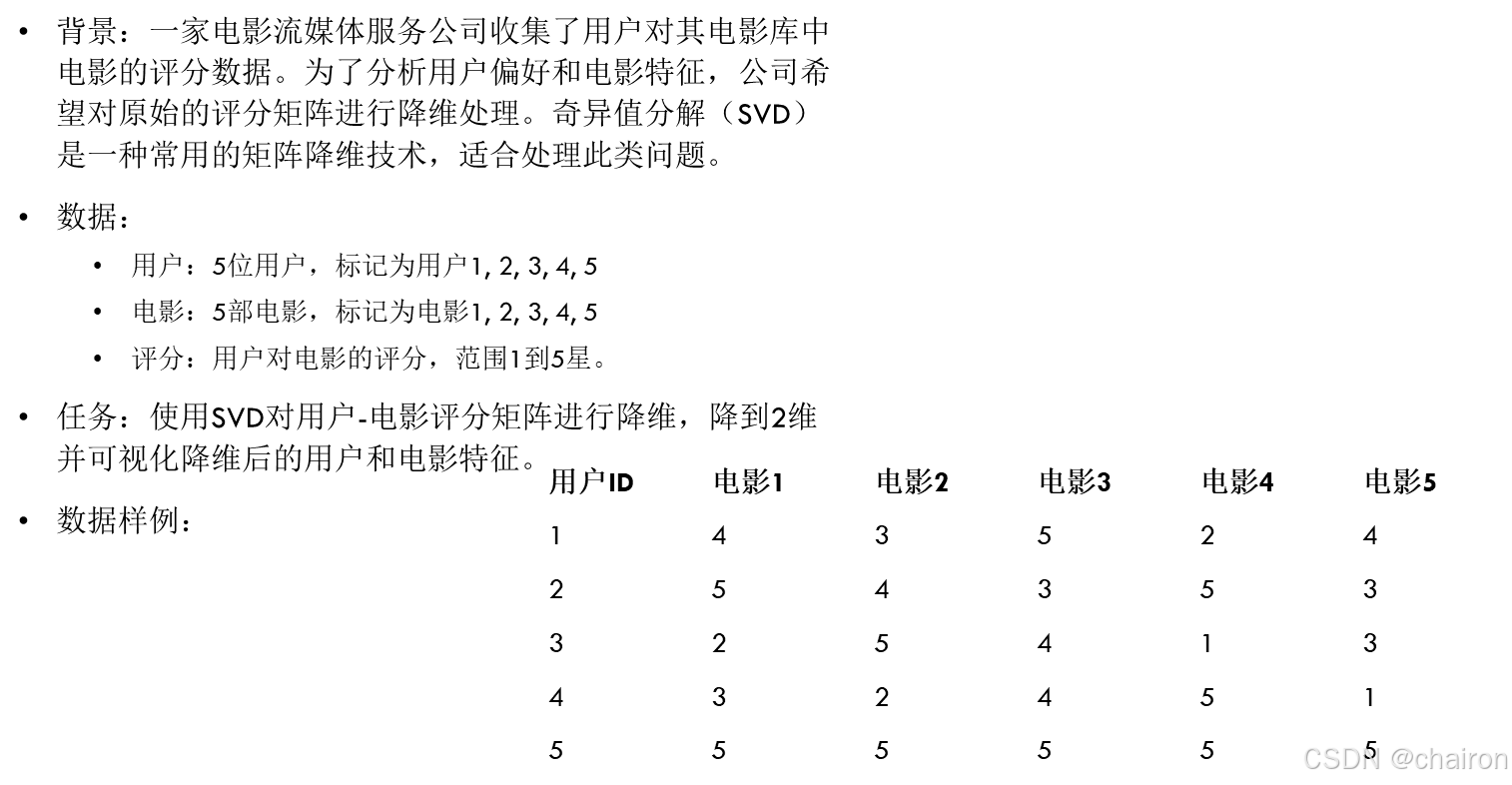
数据:
# 模拟用户-电影评分矩阵
ratings_matrix = np.array([
[4, 3, 5, 2, 4],
[5, 4, 3, 5, 3],
[2, 5, 4, 1, 3],
[3, 2, 4, 5, 1],
[5, 5, 5, 5, 5]
])
代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import TruncatedSVD
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 模拟用户-电影评分矩阵
ratings_matrix = np.array([
[4, 3, 5, 2, 4],
[5, 4, 3, 5, 3],
[2, 5, 4, 1, 3],
[3, 2, 4, 5, 1],
[5, 5, 5, 5, 5]
])
# 使用SVD进行降维
svd = TruncatedSVD(n_components=2) # 创建截断奇异值分解对象,设置保留的主成分数量为2
result_svd = svd.fit_transform(ratings_matrix)# 对特征数据进行降维处理
# 打印降维后的矩阵
print("降维后的矩阵:")
print(result_svd)
# 绘制降维后的用户和电影特征
plt.figure(figsize=(8, 6))
plt.scatter(result_svd[:, 0], result_svd[:, 1])
plt.title('SVD降维后的用户和电影特征')
plt.xlabel('主成分1')
plt.ylabel('主成分2')
plt.grid(True)
plt.show()
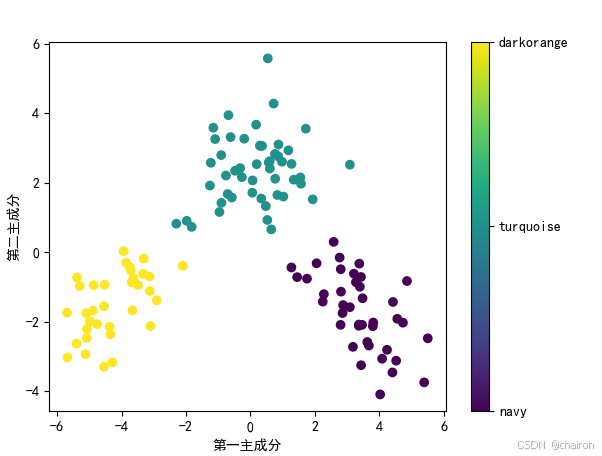
2. 葡萄酒质量评价数据集的LDA降维

import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import train_test_split
from mpl_toolkits.mplot3d import Axes3D
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载葡萄酒数据集
wine = load_wine()
X = wine.data
y = wine.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# # 应用LDA降维
lda = LinearDiscriminantAnalysis(n_components=2)
X_lda = lda.fit_transform(X_train, y_train)
###########################################2D
# 绘制降维后数据的散点图
sc = plt.scatter(X_lda[:, 0], X_lda[:, 1], c=y_train, cmap='viridis')
plt.xlabel('第一主成分') # 设置x轴标签
plt.ylabel('第二主成分') # 设置y轴标签
# 创建颜色条
cbar = plt.colorbar(sc)
# 设置颜色条的刻度标签
categories = ['navy', 'turquoise', 'darkorange']
cbar.set_ticks(np.unique(y)) # 确保颜色条上的刻度与类别数一致
cbar.set_ticklabels(categories) # 设置每个刻度的标签
plt.show() # 显示绘制的散点图
###########################################################
# # 创建一个3D图形
# fig = plt.figure(figsize=(10, 8))
# ax = fig.add_subplot(111, projection='3d')
# # 为每个类别绘制散点图
# colors = ['navy', 'turquoise', 'darkorange']
# target_names = wine.target_names
# for color, i, target_name in zip(colors, np.unique(y_train), target_names):
# # 筛选特定类别的样本
# indices = y_train == i
# ax.scatter(X_lda[indices, 0], X_lda[indices, 1], color=color, label=target_name)
#
# # 设置图形的标题和坐标轴标签
# ax.set_title('LDA降维后的葡萄酒数据集')
# ax.set_xlabel('主成分1')
# ax.set_ylabel('主成分2')
# # 由于我们现在是2D图形,不需要 ax.set_zlabel('主成分3')
#
# # 显示图例
# ax.legend(loc='upper left', shadow=False)
#
# # 显示图形
# plt.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









