




文章目录
LoRA概念
LoRA(全称 Low-Rank Adaptation,低秩适应)是一种针对大型 AI 模型(如大语言模型 LLM、扩散模型等)的高效微调技术,核心目标是在不全量更新预训练模型参数的前提下,通过少量参数调整实现模型在特定任务 / 领域的适配,解决了大模型全量微调 “参数多、成本高、显存占用大” 的痛点。
LoRA 优势
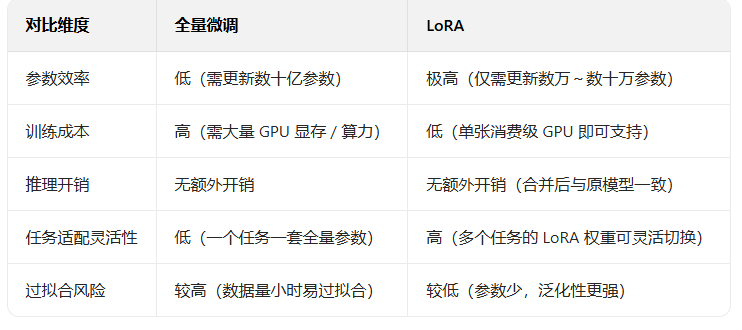
LoRA典型应用场景
- 大模型的领域适配:将通用大模型(如 GPT-3.5、LLaMA)微调为 “领域专用模型”,例如医疗领域(理解病历、医学问答)、法律领域(合同分析、法条解读)、代码领域(特定语言代码生成)。
- 个性化定制:为模型注入 “个性化特征”,例如让 LLM 生成特定风格的文本(如古风、学术论文)、让扩散模型(如 Stable Diffusion)生成特定风格的图像(如动漫、写实人像)。
- 多任务轻量化部署:一个基础预训练模型可搭配多个 LoRA 权重,针对不同任务(如翻译、摘要、情感分析)动态加载对应的 LoRA,无需为每个任务部署独立的全量模型,大幅降低部署成本。
我们为什么要使用LoRA
通用大模型+LoRA,生成的图片可用性会大大增强。
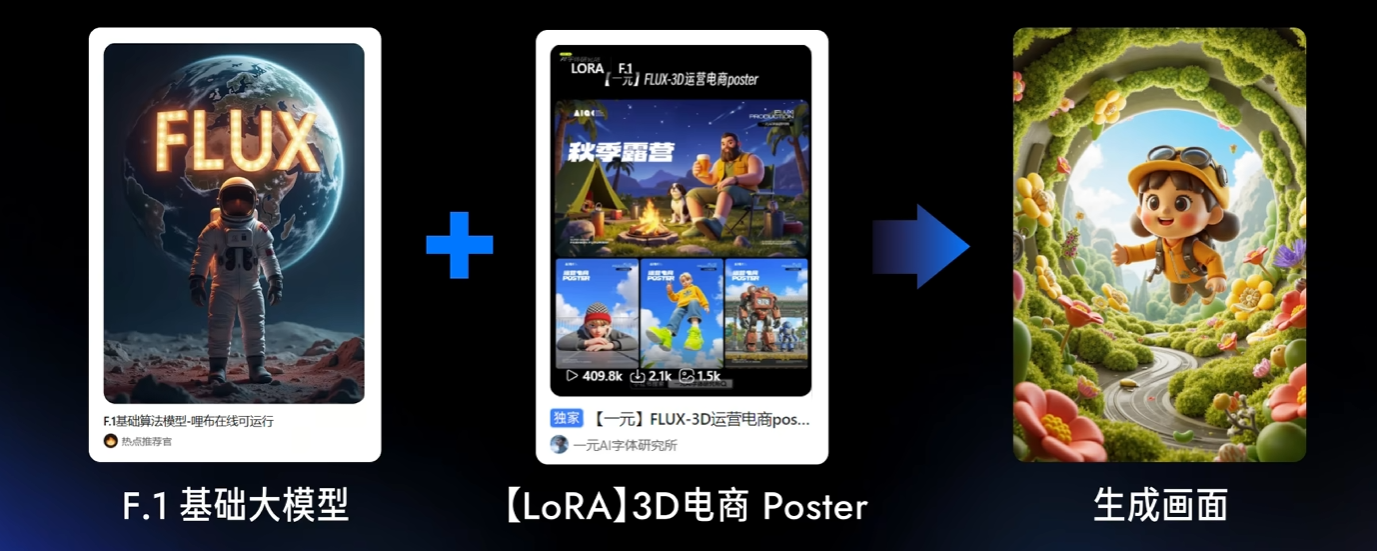
LoRA可以实现各类型的风格,让图像具有特定氛围,为画面添加指定元素,实现特定材质,提升画面质感,甚至调节人物年龄、肤色等特征




LoRA训练
基础大模型+少量风格数据集训练–>得到特定风格的LoRA模型,叠加大模型使用就可以得到理想画面
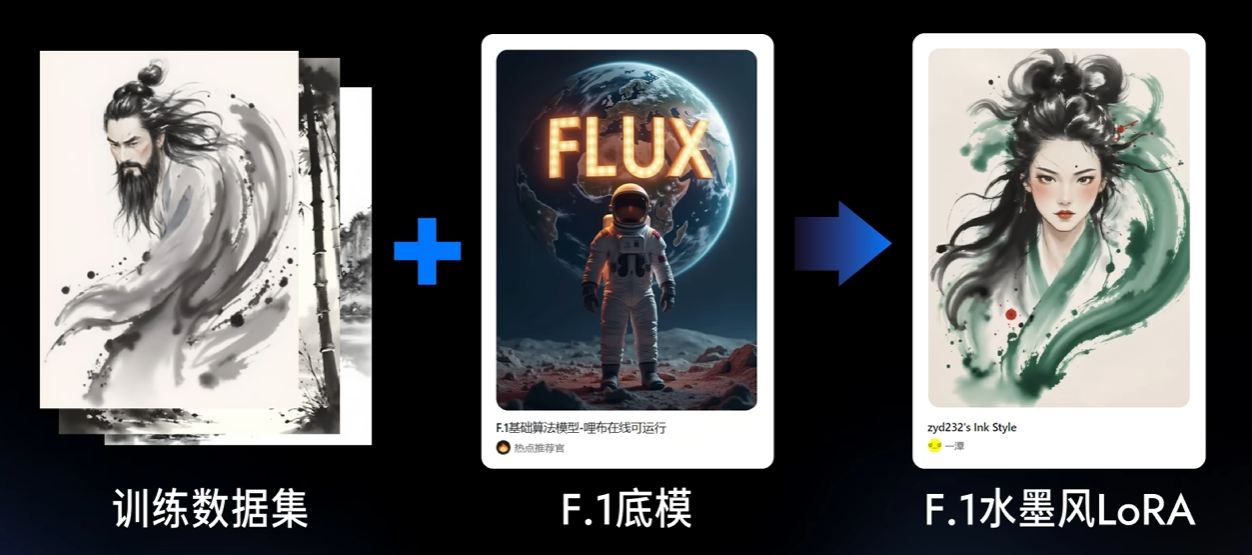
模型对比
LoRA风格效果多样,画面细节丰富,但是不能独立使用。

LoRA叠加使用
混合新风格

叠加效果
实现更精致更复杂的出图

单个LoRA的权重推荐0.8-1之间,多个LoRA权重根据实际效果调整



LORA生图
找到喜欢的风格,尝试用多个LoRA混合生图。
本次案例使用模型:http://liblib.art/sd?id=1759055590620


deepseek提示词效果
提示词可以借助deepseek等模型
可以复制示例的提示词,然后让AI给你模仿着写。
比如说:
1girl,solo,long_hair,looking_at_viewer,brown_hair,black_hair,hair_ornament,dress,jewelry,bare_shoulders,sitting,flower,earrings,parted_lips,detached_sleeves,sky,indoors,white_dress,blue_sky,cup,petals,window,chinese_clothes,facial_mark,table,curtains,tassel,purple_dress,shawl,mountain,forehead_mark,teapot,vase,hagoromo,lotus,hanfu,open_window,round_window,windowsill,
////,(simple_background:1.2),(sdwang:1.3),Visual impact,(rei (sanbonzakura):1.2),Depth of field,absurdres,realistic,best-quality,masterpiece,with a high-end texture,RTNS,masterpiece,amazing quality,Semi-realistic,fantasy,high contrast,detailed shading,perspective,depth of field,best quality,realistic anatomy,reoen,absurdres,realistic,best-quality,masterpiece,with a high-end texture,仿照这个提示词,我想要生成一个像是阴阳师的不知火舞的古风女子的形象,请写出提示词


chatGPT5提示词效果


自己创建一个模型
使用基础模型,这是一个古风写真:https://www.liblib.art/modelinfo/f9be61d77f47427595da128ed5821460?from=search&versionUuid=b6d960ffdae54f76abec16f689e331a3
粘贴提示词
1girl,masterpiece, best quality, ultra-detailed, 1girl, solo, hanfu, ancient Chinese style, Onmyōji aesthetic, dynamic pose, long flowing black hair, red and white color scheme, hair ornament, intricate jewelry, detached sleeves, bare shoulders, looking at viewer, parted lips, seductive expression, //// fantasy, flames, cherry blossoms, traditional Japanese architecture, depth of field, absurdres, realistic, high contrast, detailed shading, cinematic lighting, RTNS, masterpiece, amazing quality, semi-realistic, fantasy, perspective
生成图片:

加入多种其他LoRA风格混合,调整比重


正向提示词:
1girl, solo, photorealistic, ultra realistic, long flowing hair (black to dark brown), looking at viewer, original character inspired by Onmyoji / traditional Japanese/Chinese aesthetics (do not copy any specific copyrighted character), elegant hanfu-inspired outfit with bare shoulders and detached sleeves, deep red and purple silk with gold embroidery and tassels, shawl draped over shoulders, subtle forehead mark, delicate facial mark, natural makeup, parted lips, confident gaze, hair ornament (gold + floral + flame motif), realistic hair strands, fine jewelry and earrings, holding a flame-shaped fan, sitting on a wooden windowsill, round open window, distant mountains and blue sky outside, lotus petals drifting, porcelain vase and teapot on table, soft curtain, warm rim lighting, cinematic softbox + late-afternoon golden hour, shallow depth of field, realistic skin texture, visible pores and subsurface scattering, natural specular highlights, fabric microtexture, detailed folds, realistic anatomy, photoreal skin shading, 50mm lens, f1.8, high dynamic range, 8k, masterpiece, best quality, ultra-detailed face, high resolution, film grain (subtle), natural color grading, dramatic yet soft contrast
负向提示词:
lowres, bad anatomy, deformed, blurry, cartoon, painting, watermark, signature, text, nsfw, explicit, underage, character likeness, duplicate character, uncanny valley
调整LoRA风格和参数

调整图片大小


大家多尝试吧,生成其他东西也可以,不用全是美女!

















 1485
1485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









