







📌 摘要
本文为医疗领域从业者提供一份全网最全的DeepSeek大模型选型手册,深度解析7B/32B/70B/671B(参数量通常用“B”表示,即“Billion”(十亿)的缩写)四大版本的性能差异、落地场景与硬件成本。通过医疗AI应用场景倒推模型选型策略,助您用最低成本实现精准诊断、智能病历、科研加速三重突破!
🚀 医疗AI革命:为什么选择DeepSeek?
在DRG付费改革与精准医疗双重驱动下,DeepSeek通过以下能力重构医疗流程:
- 智能病历生成:3秒生成结构化病历
- 多模态分析:融合影像/病理/检验数据
- 临床决策支持:实时更新最新诊疗指南
- 科研加速引擎:文献挖掘与试验设计优化
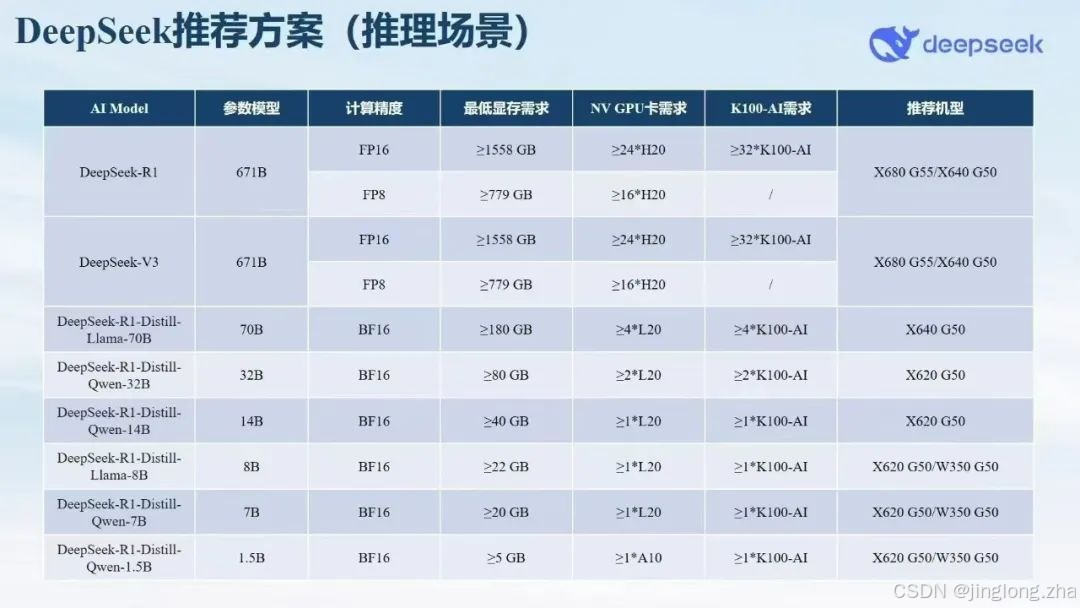
🧠 四大版本核心参数对比(医疗场景特供版)
| 版本 | 参数量 | 类比学历 | 医疗NLP任务 | 典型响应速度 | 推荐GPU配置 | 适用机构预算 |
|---|---|---|---|---|---|---|
| 7B | 70亿 | 初中 | 基础问答/模板生成 | 200ms | RTX 3090*1 | 2万以内 |
| 32B | 320亿 | 高中 | 病历质控/初阶CDSS | 500ms | A6000*2 | 5-10万 |
| 70B | 700亿 | 硕士 | 多模态诊断/科研辅助 | 1.2s | A100*4+512G内存 | 20-50万 |
| 671B | 6710亿 | 博士 | 基因组分析/新药研发 | 3.5s | HGX H100集群 | 百万级 |
🏥 场景化选型指南(含硬件避坑指南)
🔍 基层医疗机构(社区医院/诊所)
- 核心需求:门诊病历自动化、医保合规检查
- 黄金组合:7B+结构化模板引擎
- 💻 硬件方案:
- 最低配置:RTX 3090(24G显存)+ 64G内存
- 优化建议:搭配医疗术语校验模块,错误率降低40%
🏨 三级医院(日均门诊>3000)
- 刚需场景:
- DRG智能编码(32B版准确率达93%)
- 危急值预警(支持LIS/PACS数据流)
- ⚙️ 部署方案:
- 混合架构:32B临床版+7B门诊版
- 显存要求:建议配置NVIDIA A6000(48G显存)
🔬 顶尖医疗中心(复旦榜TOP100)
- 科研突破场景:
- 70B版:影像组学特征提取(CT/MRI)
- 671B版:靶点发现(需千亿级化合物库)
- 🌐 集群方案:
- 70B推荐:4*A100+RDMA网络
- 671B方案:H100+InfiniBand组网(吞吐量提升5倍)
💡 进阶选型策略(90%医院不知道的隐藏技巧)
- 混合部署方案:
- 门诊部用7B处理轻量任务
- 住院部部署32B进行MDT会诊支持
- 模型蒸馏技术:
- 将70B知识蒸馏到32B(性能保留85%)
- 联邦学习架构:
- 多家医院联合训练专科模型(如肿瘤版32B)
❗ 重要避坑指南
- 显存黑洞:32B模型加载需至少40G显存(警惕消费级显卡)
- 响应延迟:70B版单次推理超2秒需检查TensorRT优化
- 数据安全:医疗私有化部署必须通过等保三级认证
🌟 未来展望:2024医疗AI趋势
- 多模态70B+:即将支持DICOM影像直接解析
- 轻量化突破:7B版本即将推出医疗特化版(参数压缩30%)
- 医保智能体:32B版本接入省级医保平台
您在医疗AI落地中遇到哪些痛点?欢迎在评论区留言,我们将抽取3位读者赠送《医疗大模型实施白皮书》!
(注:文中所涉硬件配置均为参考方案,实际部署需联系DeepSeek官方技术支持)



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











