







code: https://github.com/bradyz/cross_view_transformers
一、创新点和贡献
提出了一种轻量的多相机视图到统一的地图视图的转换模型
该模型相对轻量,能在2080Ti上实时运行
二、精度/速度

精度soat, 速度是相同精度情况下的4倍(on 2080ti)
三、实现:跨视图注意力机制
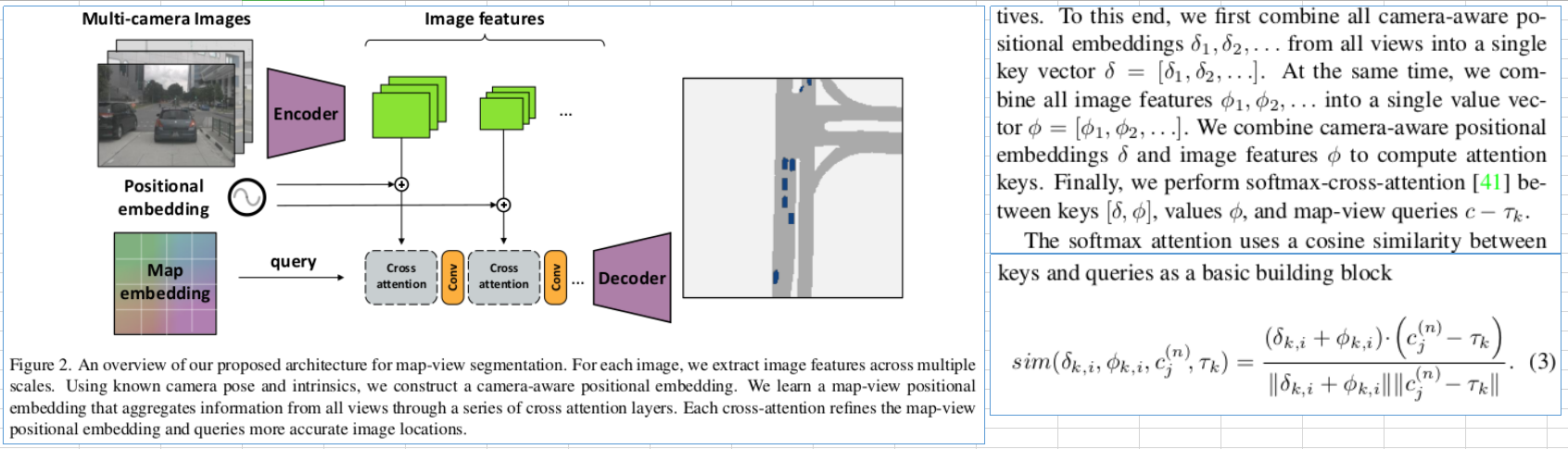
每个相机每个像素过了backbone之后形成每个相机每个像素的feature上的Embedding, 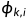
每个相机的内参, 每个相机的旋转,每个相机上每个像素的位置通过一个共用的MLP1后形成每个像素的Camera_Aware_Positional_Embedding,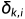
每个相机的位置通过一个共用的MLP2形成Camera_Location_Embedding, 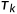
地图上各个位置的初始Embedding是学出来的,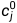
-作为query; 和对应位置element-wise相加作为key; 作为value进行cross view attention,相似度计算如下图,并从低分辨率到高分辨率多次计算cross-view-attention
训练完成以后就定了,模型不变,部署的时候所有车都一样(我猜的, 还没看代码)
, ,模型不变,部署的时候每个车标定好了只用算一次(我猜的, 还没有看代码)
attention可视化,可以看到网络学到了正确的几何关系:

五、重要参考文献
(2021, iccv) FIERY: Future Instance Prediction in Bird's-Eye View from Surround Monocular Cameras















 2709
2709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









