







✅博主简介:本人擅长建模仿真、数据分析、论文写作与指导,项目与课题经验交流。项目合作可私信或扫描文章底部二维码。
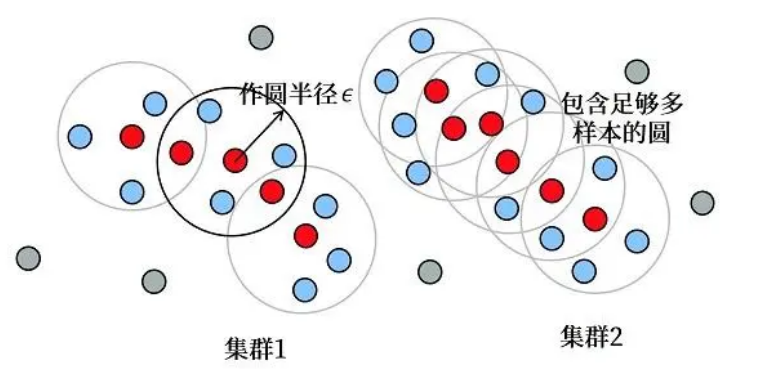
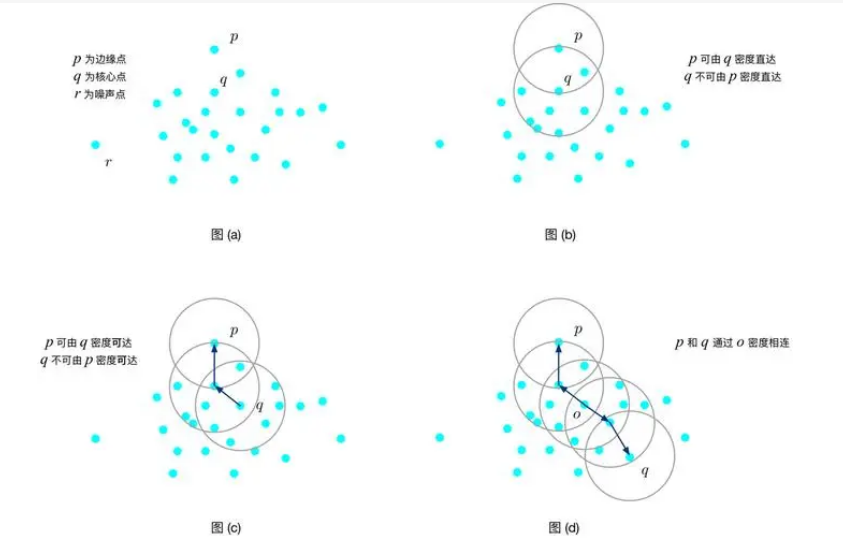
数据挖掘是当前人工智能和数据库领域的一个关键技术,其核心任务是从大量数据中挖掘出有潜在价值的信息。在数据挖掘的众多方法中,聚类分析是一项重要任务,其目标是在相似性基础上将数据分组。DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是其中一种基于密度的聚类算法,它不依赖于预设的簇数,能够有效识别任意形状的簇,并能够处理噪声数据。然而,DBSCAN算法的性能高度依赖于两个参数:Eps(邻域半径)和MinPts(最小点数)。传统的DBSCAN算法要求用户手动设置这两个参数,参数的选择不当可能导致聚类效果不佳。
本文提出了一种基于K-dist图的自适应参数改进的DBSCAN算法,简称X-DBSCAN,旨在通过自动化方法选取Eps和MinPts参数,从而提升算法的稳定性和准确性。通过K-dist图分析、最小二乘多项式曲线拟合和数学期望法等技术,X-DBSCAN实现了对参数的自适应选择,并在多个实验中展现了较好的性能。
1. 传统DBSCAN算法的不足
DBSCAN算法基于密度的思想,将具有足够密度的点划分为同一簇,同时将稀疏的点标记为噪声点。算法的核心在于两个参数的设定:
- Eps:定义了点的邻域半径。
- MinPts:规定了形成簇的最小邻域点数。
这两个参数直接影响了聚类结果,但传统DBSCAN算法要求用户手动设置这两个参数,且缺乏针对数据集特点的适应性。具体表现为:
- 参数选取不当时,聚类结果可能过于稀疏或过于密集,导致较高的噪声点或合并簇。
- 在高维数据集或复杂结构的数据集上,传统DBSCAN难以提供稳定的聚类效果。
因此,自动化选择Eps和MinPts成为提升DBSCAN聚类性能的重要方向。
2. 基于K-dist图的自适应参数选取方法
为了改善参数设定对聚类结果的影响,本文提出了一种基于K-dist图的自适应参数改进的DBSCAN算法。K-dist图是一种常用于辅助选择Eps参数的工具,展示了数据集中每个点到其最近K个邻居的距离分布。在K-dist图中,Eps的理想值通常位于曲线的“拐点”处。
2.1 K-dist图的构造与分析
K-dist图是通过以下步骤构建的:
- 对数据集中的每个数据点,计算其到最近K个邻居的距离。
- 通过K值的变化,绘制出数据点的K邻近距离图,生成K-dist图。
在K-dist图中,曲线的拐点通常表明数据密度的变化,拐点之前的区域表示数据密集的簇,之后的区域则可能代表噪声点。因此,寻找K-dist图中的拐点能够帮助确定Eps的合理取值。
2.2 多项式曲线拟合
为了自动化确定Eps参数,本文采用了最小二乘多项式曲线拟合技术。具体步骤为:
- 使用多项式拟合K-dist图曲线,生成候选Eps参数列表。
- 通过数学期望法结合曲线的变化率,确定Eps的最佳取值。
这种方法避免了传统手动选择Eps参数的主观性,能够更加准确地反映数据集的密度分布特点。
2.3 MinPts参数的自适应选择
MinPts参数规定了形成簇的最小邻域点数,它通常与Eps相关。本文通过以下方法自适应确定MinPts值:
- 通过数学期望法和降噪阈值,生成一个MinPts参数列表。
- 根据不同Eps值对应的聚类结果,分析簇数的变化趋势,选取簇数变化稳定范围内最大K值对应的MinPts作为最优值。
这种方法确保了MinPts参数与Eps参数的协调性,从而在不同数据集上能够提供更为稳定和高效的聚类结果。
3. 实验验证与性能分析
为了验证X-DBSCAN算法的有效性,本文在多个数据集上进行了实验,包括人工数据集和UCI真实数据集。在实验中,X-DBSCAN算法与传统DBSCAN以及其他几种聚类算法进行了对比。
3.1 实验设计
本文的实验主要包括以下几个方面:
- 人工数据集实验:通过人工生成的二维和三维数据集,验证X-DBSCAN在处理不同形状和密度的簇时的效果。
- 真实数据集实验:在UCI真实数据集上,评估X-DBSCAN与其他聚类算法的准确性和性能。
实验中,使用了多个聚类评价指标,包括准确率、纯度、轮廓系数等,来全面评估算法的性能。
3.2 实验结果
实验结果显示,X-DBSCAN算法在多个数据集上的聚类性能均优于传统DBSCAN和其他对比算法。具体表现为:
- 在人工数据集上,X-DBSCAN算法能够准确识别出任意形状的簇,并有效处理密度不均的数据,聚类准确度比传统DBSCAN提高了21.83%。
- 在UCI真实数据集上,X-DBSCAN算法的聚类效果比DBSCAN提高了15.52%,且在高维数据集上表现出更好的聚类效果。
此外,X-DBSCAN在处理大规模数据时,能够避免传统DBSCAN中的内存溢出问题,表现出了良好的鲁棒性和计算效率。
4. X-DBSCAN在客户细分领域的应用
客户细分是指根据客户的行为、特征等信息,将客户划分为不同的群体,以便企业能够针对不同的客户群体提供个性化服务。本文将X-DBSCAN算法应用于客户细分领域,通过实际商城客户数据验证了其有效性。
4.1 客户细分的意义
客户细分能够帮助企业更好地理解客户需求,提供个性化的产品和服务,提高客户满意度和忠诚度。通过聚类分析,企业能够识别出不同客户群体的特征,从而制定差异化的营销策略。
4.2 X-DBSCAN在客户细分中的应用
本文使用实际商城的客户行为数据进行聚类分析,数据包括客户的购买历史、消费金额等信息。通过X-DBSCAN算法的自适应参数选择,本文对客户进行了细分,将具有相似购买行为和消费能力的客户聚为一类。
实验结果表明,X-DBSCAN在客户细分任务中表现出了较高的准确性,能够有效识别出不同客户群体,并为企业提供了有价值的客户分析结果。与传统DBSCAN相比,X-DBSCAN的聚类结果更加稳定,且能够处理数据中的噪声点。
import numpy as np
from sklearn.neighbors import NearestNeighbors
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt
# 计算K-dist图
def compute_kdist(data, k):
neighbors = NearestNeighbors(n_neighbors=k)
neighbors_fit = neighbors.fit(data)
distances, indices = neighbors_fit.kneighbors(data)
k_distances = distances[:, k-1]
return k_distances
# 绘制K-dist图
def plot_kdist(k_distances):
k_distances = np.sort(k_distances)
plt.plot(k_distances)
plt.title("K-dist Plot")
plt.show()
# 基于K-dist图的自适应DBSCAN算法
def x_dbscan(data, k):
k_distances = compute_kdist(data, k)
plot_kdist(k_distances)
# 根据K-dist图自动选择Eps
eps = np.median(k_distances) # 简化示例,自适应选取eps
min_samples = k # 通常设置为k
# 使用DBSCAN进行聚类
db = DBSCAN(eps=eps, min_samples=min_samples).fit(data)
labels = db.labels_
return labels
# 数据
if __name__ == "__main__":
# 执行X-DBSCAN
labels = x_dbscan(data, k=5)
# 可视化聚类结果
plt.scatter(data[:, 0], data[:, 1], c=labels)
plt.title("X-DBSCAN Clustering Result")
plt.show()


















 3135
3135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











