







✅博主简介:本人擅长数据处理、建模仿真、论文写作与指导,科研项目与课题交流。项目合作可私信或扫描文章底部二维码。
(1)多服务器多设备场景的卸载决策研究
- 问题背景与目标:随着智能设备和应用的增多,终端设备计算能力有限,集中式云计算难以满足低能耗、低时延等要求,边缘计算成为解决方案。在多边缘服务器为多终端设备服务的场景中,目标是求解最小化综合考虑时延和能耗的系统成本问题。时延包括任务传输到边缘服务器的时间以及服务器处理任务的时间,能耗涉及终端设备传输任务和自身运行的能耗等。合理的卸载决策对于降低系统成本至关重要,需要决定哪些任务应该卸载到哪个边缘服务器以及卸载多少数据量。
- 改进的差分进化算法应用:采用改进的差分进化算法来解决卸载决策问题。差分进化算法是一种基于种群的优化算法,通过变异、交叉和选择操作来搜索最优解。在改进过程中,可能对算法的参数设置、变异策略等进行调整,以更好地适应问题的特点。例如,调整变异率和交叉率,使其能够在搜索过程中平衡全局探索和局部开发能力。对于种群的初始化,可能采用更合理的方式,使其能够覆盖更广泛的解空间。在算法运行过程中,根据终端设备的任务特点、边缘服务器的资源状况以及时延和能耗的约束条件,不断更新种群中的个体,即卸载决策方案。通过迭代计算,逐渐找到使系统成本最小化的最优卸载决策。
- 仿真实验与结果分析:通过仿真实验来验证改进差分进化算法的有效性。在实验中,设置不同的参数变化情况,如终端设备数量的增加、任务复杂度的变化、边缘服务器资源的限制等。对比改进算法与其他传统算法或基准算法在不同参数下的系统成本表现。结果显示,在各种情况下,改进的差分进化算法能够更有效地降低系统成本。例如,当终端设备数量增加时,改进算法能够更快地找到合适的卸载方案,避免任务在设备端过度积压导致的高能耗和长时延;当任务复杂度提高时,算法能够智能地分配任务到具有相应处理能力的边缘服务器,减少处理时间和能耗。这些结果表明改进算法在优化卸载决策方面具有明显优势,能够适应不同的实际场景需求,提高边缘计算系统的性能和效率。
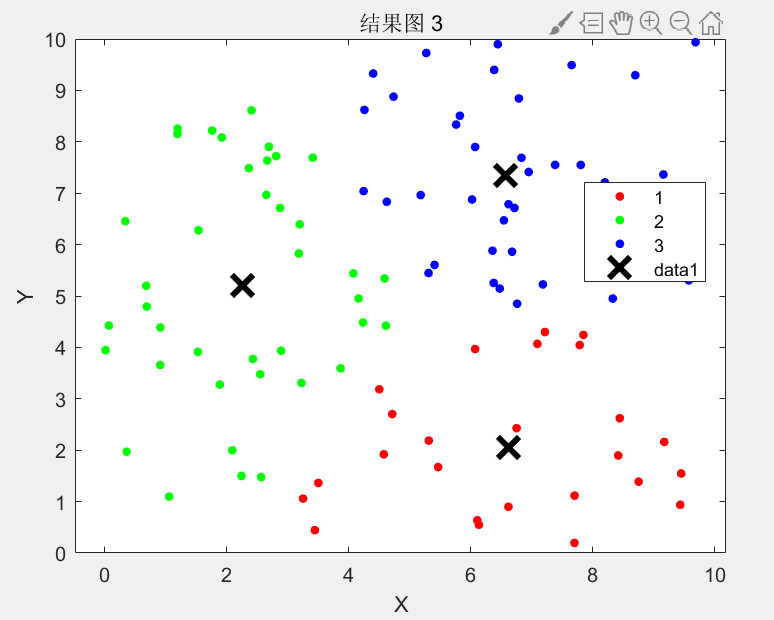
(2)单服务器多设备场景的资源分配研究 - 问题背景与目标:在一个边缘服务器为多移动终端提供卸载服务并收取服务费的场景中,目标是求解最大化服务器收益的问题,可看作组合资源分配问题。服务器需要在满足终端设备任务需求的前提下,合理分配资源以获取最大收益。这里的收益可能与服务器处理的任务量、服务质量以及收取的费用等因素相关。资源分配不仅要考虑每个终端设备的任务需求和资源请求,还要考虑不同任务之间的优先级和相互关系。例如,对于一些付费较高或对时延要求较低的任务,可以给予更多的资源分配;而对于一些紧急且重要的任务,即使付费较低,也需要保证一定的资源以满足其服务质量要求。
- 改进的正弦余弦算法应用:采用改进的正弦余弦算法来求解该目标问题。正弦余弦算法是一种基于正弦和余弦函数的优化算法,通过不断调整搜索方向和步长来寻找最优解。在改进过程中,可能针对资源分配问题的特点对算法进行定制化。例如,根据服务器的资源总量和终端设备的任务需求,合理设置算法的搜索范围和初始参数。在搜索过程中,利用正弦余弦函数的周期性和波动性来探索不同的资源分配组合,以找到能够使服务器收益最大化的方案。同时,考虑到资源分配的公平性和效率性,可能引入一些约束条件或惩罚机制,确保在追求最大收益的同时,不会过度忽视某些终端设备的需求,保证整体系统的稳定性和可持续性。
- 仿真实验与算法比较:通过仿真实验进行算法比较,以证明改进正弦余弦算法在解决组合资源分配问题的有效性。在实验中,将改进的正弦余弦算法与其他常见的资源分配算法,如贪心算法、遗传算法等进行对比。设置不同的实验场景,包括不同数量的移动终端设备、不同类型的任务负载以及不同的服务费收取策略等。比较各算法在不同场景下的服务器收益表现、资源分配的合理性以及算法的运行时间等指标。结果显示,改进的正弦余弦算法在大多数情况下能够获得更高的服务器收益。它能够更有效地利用边缘服务器的资源,根据终端设备的需求和任务特点进行灵活的资源分配。与贪心算法相比,改进算法能够考虑到全局最优解,而不仅仅是局部最优;与遗传算法相比,改进算法可能在运行时间和收敛速度上具有一定优势,同时能够保证较好的解质量。这些结果表明改进的正弦余弦算法是一种有效的方法,可以为边缘服务器在单服务器多设备场景下的资源分配提供良好的决策支持,提高服务器的运营效率和经济效益。
(3)系统状态时变场景的资源在线分配研究 - 问题背景与目标:在一个边缘服务器服务多个无任务处理能力的用户设备且系统状态时变的场景中,目标是求解最大化实时任务处理成功率的问题。由于系统状态不断变化,如用户设备的任务请求频率、任务类型的变化以及网络状况的波动等,需要一种能够实时适应这些变化的资源在线分配方法。传统的静态资源分配方法难以应对这种动态性,可能导致在某些时刻资源分配不足或过剩,影响任务处理成功率。因此,需要设计一种能够根据实时情况动态调整资源分配的策略,以确保在不同的系统状态下都能尽可能提高任务处理的成功率。
- 基于 D3QN 的资源在线分配方法:采用基于深度强化学习中的 D3QN(Double Dueling Deep Q-Network)算法的资源在线分配方法。D3QN 算法结合了深度神经网络和强化学习的优势,能够通过与环境的不断交互学习到最优的资源分配策略。在该场景中,将边缘服务器和用户设备看作强化学习的环境,服务器的资源分配动作作为智能体的决策。智能体通过观察系统的当前状态,如任务队列长度、设备资源需求、网络带宽等信息,选择合适的资源分配动作,并根据任务处理的结果获得奖励反馈。通过不断地调整神经网络的参数,智能体逐渐学习到在不同系统状态下如何分配资源以最大化任务处理成功率。例如,当任务队列较长且网络带宽较窄时,智能体可能会选择优先分配资源给对时延要求较低的任务,以避免任务积压导致的失败;当设备资源需求突然增加时,智能体能够及时调整资源分配,满足关键任务的需求。
- 仿真实验与收敛性分析:通过仿真实验说明基于 D3QN 的在线分配方法的收敛性和有效性。在实验中,模拟不同的系统状态变化情况,观察算法在运行过程中的性能表现。分析任务处理成功率随着算法迭代次数的增加而变化的趋势,以验证其收敛性。结果表明,基于 D3QN 的在线分配方法具有较好的收敛性。在经过一定数量的迭代训练后,任务处理成功率能够逐渐稳定在一个较高的水平。这说明智能体能够有效地学习到适应系统状态变化的资源分配策略,随着时间的推移,不断优化自己的决策,提高任务处理的成功率。与其他在线资源分配方法相比,基于 D3QN 的方法能够更好地应对系统的动态性,具有更强的自适应能力和鲁棒性。它能够根据实时的环境变化及时调整资源分配,减少因系统状态波动而导致的任务处理失败,为边缘计算系统在时变场景下的资源管理提供了一种有效的解决方案,提高了系统的整体性能和可靠性。
% 定义问题参数
num_devices = 10; % 终端设备数量
num_servers = 3; % 边缘服务器数量
task_data_sizes = rand(num_devices, 1); % 每个设备的任务数据大小
device_compute_capacities = rand(num_devices, 1); % 每个设备的计算能力
server_compute_capacities = rand(num_servers, 1); % 每个服务器的计算能力
transmission_rates = rand(num_devices, num_servers); % 设备到服务器的传输速率
energy_costs = rand(num_devices, 1); % 设备的能耗成本系数
latency_weights = rand(); % 时延和能耗的权重比例
population_size = 50; % 种群大小
max_generations = 100;
% 初始化种群
population = initializePopulation(population_size, num_devices, num_servers);
% 迭代优化
for generation = 1:max_generations
% 计算适应度
fitness_values = calculateFitness(population, task_data_sizes, device_compute_capacities, server_compute_capacities, transmission_rates, energy_costs, latency_weights);
% 选择操作
selected_population = selection(population, fitness_values);
% 变异操作
mutated_population = mutation(selected_population);
% 交叉操作
crossed_population = crossover(mutated_population, selected_population);
% 更新种群
population = crossed_population;
end
% 输出结果
best_solution = findBestSolution(population, fitness_values);
disp(['最优卸载决策:', num2str(best_solution)]);
disp(['最小系统成本:', num2str(fitness_values(best_solution))]);
% 函数定义
function population = initializePopulation(population_size, num_devices, num_servers)
% 随机生成初始种群,每个个体表示一种卸载决策方案(0表示不卸载,1表示卸载到服务器1,2表示卸载到服务器2,以此类推)
population = randi(num_servers + 1, population_size, num_devices);
end
function fitness_values = calculateFitness(population, task_data_sizes, device_compute_capacities, server_compute_capacities, transmission_rates, energy_costs, latency_weights)
% 计算每个个体的适应度(系统成本)
num_individuals = size(population, 1);
fitness_values = zeros(num_individuals, 1);
for i = 1:num_individuals
total_latency = 0;
total_energy_cost = 0;
for j = 1:num_devices
if population(i, j) > 0 % 如果设备j选择卸载
server_index = population(i, j) - 1;
transmission_time = task_data_sizes(j) / transmission_rates(j, server_index);
processing_time = task_data_sizes(j) / server_compute_capacities(server_index);
latency = transmission_time + processing_time;
total_latency = total_latency + latency;
energy_cost = energy_costs(j) * (task_data_sizes(j) * transmission_time);
total_energy_cost = total_energy_cost + energy_cost;
else % 如果设备j不卸载
processing_time = task_data_sizes(j) / device_compute_capacities(j);
total_latency = total_latency + processing_time;
energy_cost = energy_costs(j) * task_data_sizes(j) * processing_time;
total_energy_cost = total_energy_cost + energy_cost;
end
end
fitness_values(i) = latency_weights * total_latency + (1 - latency_weights) * total_energy_cost;
end
end
function selected_population = selection(population, fitness_values)
% 选择操作,例如采用锦标赛选择
tournament_size = 5;
num_selected = round(population_size / 2);
selected_indices = zeros(num_selected, 1);
for i = 1:num_selected
tournament_indices = randperm(population_size, tournament_size);
tournament_fitness = fitness_values(tournament_indices);
[~, best_index] = min(tournament_fitness);
selected_indices(i) = tournament_indices(best_index);
end
selected_population = population(selected_indices, :);
end
function mutated_population = mutation(selected_population)
% 变异操作,例如对每个个体的某些基因进行随机扰动
mutation_rate = 0.1;
num_selected = size(selected_population, 1);
mutated_population = selected_population;
for i = 1:num_selected
for j = 1:num_devices
if rand < mutation_rate
mutated_population(i, j) = randi(num_servers + 1);
end
end
end
end
function crossed_population = crossover(mutated_population, selected_population)
% 交叉操作,例如采用单点交叉
crossover_rate = 0.8;
num_mutated = size(mutated_population, 1);
crossed_population = zeros(num_mutated, size(mutated_population, 2));
for i = 1:2:num_mutated
if rand < crossover_rate
crossover_point = randi(num_devices - 1);
parent1 = mutated_population(i, :);
parent2 = mutated_population(i + 1, :);
child1 = [parent1(1:crossover_point), parent2(crossover_point + 1:end)];
child2 = [parent2(1:crossover_point), parent1(crossover_point + 1:end)];
crossed_population(i, :) = child1;
crossed_population(i + 1, :) = child2;
else
crossed_population(i, :) = parent1;
crossed_population(i + 1, :) = parent2;
end
end
end
function best_solution = findBestSolution(population, fitness_values)
% 找到最优解
[min_fitness, best_index] = min(fitness_values);
best_solution = population(best_index, :);
end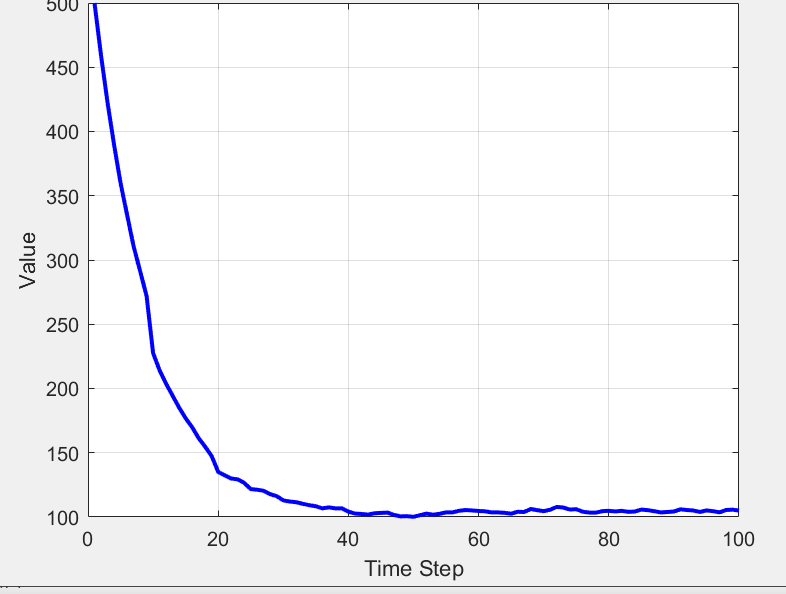


















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











