







✅ 博主简介:擅长数据处理、建模仿真、程序设计、仿真代码、论文写作与指导,毕业论文、期刊论文经验交流。
✅ 具体问题可以私信或扫描文章底部二维码。
(1)移动边缘计算(Mobile Edge Computing, MEC)在智能驾驶等应用领域中扮演着至关重要的角色,它通过在网络中靠近用户的边缘节点上进行数据处理和存储,能够满足低时延、低能耗和高可靠性的需求。本文聚焦于MEC系统中的任务分解与资源分配问题,旨在提高多用户设备与多MEC服务器系统下的任务卸载效率。首先,本文综合考虑了任务粒度、内聚性以及子任务之间的关联程度等多个因素,形式化地描述了任务分解过程。为了解决这一复杂的优化问题,本文引入并改进了蚁群算法。
改进的蚁群算法主要针对以下几个方面进行了调整:初始信息素分布、状态转移规则以及挥发因子。具体来说,为了更好地引导蚂蚁找到最优解路径,本文重新设置了初始信息素分布,使其更加均匀地覆盖整个搜索空间。同时,状态转移规则也进行了修改,以增强蚂蚁探索新路径的能力,避免过早收敛到局部最优解。此外,动态调整挥发因子可以使得信息素更新机制更加灵活,从而进一步提升算法的搜索效率。实验仿真结果显示,在相同数量的任务下,改进后的蚁群算法显著降低了系统带宽占用率,仅为25%左右,而其他传统算法的系统带宽占用率则超过50%。随着任务数量的增加,该算法在任务开销总时延方面的表现也越来越好,相较于其他算法,可以节省至少3秒的任务执行时间。这表明改进的蚁群算法不仅提高了任务分解的精度,还有效地减少了系统的通信成本和延迟。
(2)除了任务分解之外,合理的资源分配策略也是确保MEC系统高效运行的关键。为此,本文提出了一种基于多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)的改进Res MADDPG(Residual Multi-Agent Deep Deterministic Policy Gradient)算法,并利用该算法设计了高效的资源分配策略。Res MADDPG算法是在MADDPG的基础上引入了残差网络结构,以加速模型的训练过程和提高算法的收敛速度。
在资源分配过程中,移动设备和边缘服务器被视为智能体,它们通过与周围环境不断交互来学习如何优化资源分配。每个智能体根据当前的状态(如可用资源、任务队列等)采取行动(如分配计算资源、选择卸载目标等),并通过奖励函数获得反馈,逐步优化自身的策略。这种基于MARL的方法能够适应异构的MEC系统网络架构,实现动态且自适应的资源分配。
为了验证Res MADDPG算法的有效性,本文进行了大量的实验对比。实验结果表明,在处理100个任务时,Res MADDPG算法将任务执行总时延缩短至3.2秒,比其他基线算法减少了近一倍的时延开销。当处理大规模任务时,Res MADDPG算法的优势更为明显,其任务执行总时延比其他基线算法减少了4秒以上,能耗开销减少了150焦耳以上。这些结果充分证明了Res MADDPG算法在降低系统开销成本方面的优越性能。
(3)本文的研究不仅提高了MEC系统中任务卸载的效率,也为相关领域的研究提供了新的思路和方法。通过结合任务分解和资源分配两方面的优化,本文提出的方案能够在保证低时延的同时,最大限度地减少能耗和通信成本,这对于智能制造、智能交通、智能医疗等需要实时计算和决策的应用场景具有重要意义。
具体而言,对于智能制造领域,MEC技术可以用于生产线上的实时监控和控制,通过快速响应生产过程中的异常情况,提高生产效率和产品质量。在智能交通领域,MEC可以帮助自动驾驶车辆实现实时的数据处理和决策,确保行车安全。而在智能医疗领域,MEC可以在紧急情况下提供快速的诊断支持,为患者争取宝贵的救治时间。
此外,本文提出的改进蚁群算法和Res MADDPG算法也可以应用于更广泛的场景中。例如,在云计算环境中,可以通过类似的方法对大规模计算任务进行有效的管理和调度;在物联网系统中,可以利用这些算法优化传感器数据的采集和处理,提高系统的整体性能。
% 基于改进蚁群算法的任务分解与基于Res MADDPG算法的资源分配策略
% 参数设置
numTasks = 100; % 任务数量
numServers = 10; % 服务器数量
pheromoneInit = 0.1; % 初始信息素浓度
alpha = 1; % 信息素重要程度因子
beta = 5; % 启发式信息重要程度因子
rho = 0.1; % 挥发因子
maxIterations = 100; % 最大迭代次数
numAnts = 50; % 蚂蚁数量
Q = 1; % 信息素增量系数
% 生成随机任务和服务器
tasks = rand(numTasks, 2); % 任务大小和优先级
servers = rand(numServers, 2); % 服务器处理能力和带宽
% 初始化信息素矩阵
pheromoneMatrix = pheromoneInit * ones(numTasks, numServers);
% 改进的蚁群算法任务分解
for iter = 1:maxIterations
% 清空蚂蚁路径
antPaths = cell(numAnts, 1);
% 每只蚂蚁构造一条路径
for ant = 1:numAnts
currentTask = randi([1, numTasks]);
path = [];
while ~isempty(currentTask)
% 计算状态转移概率
probabilities = (pheromoneMatrix(currentTask, :) .^ alpha) .* ...
((1 ./ (sum(abs(tasks(currentTask, :) - servers), 2))) .^ beta);
probabilities = probabilities / sum(probabilities);
% 选择下一个服务器
nextServer = randsample(1:numServers, 1, true, probabilities);
path = [path, nextServer];
% 更新信息素
deltaPheromone = Q / (abs(tasks(currentTask, 1) - servers(nextServer, 1)) + 1e-6);
pheromoneMatrix(currentTask, nextServer) = (1 - rho) * pheromoneMatrix(currentTask, nextServer) + deltaPheromone;
% 移除已分配的任务
tasks(currentTask, :) = Inf;
[~, currentTask] = min(tasks(:, 1));
end
antPaths{ant} = path;
end
% 更新全局最优路径
bestPath = antPaths{1};
for i = 2:numAnts
if length(bestPath) > length(antPaths{i})
bestPath = antPaths{i};
end
end
% 显示当前迭代的最佳路径
disp(['Iteration ', num2str(iter), ': Best Path Length = ', num2str(length(bestPath))]);
end
% Res MADDPG算法资源分配策略
function [actions, rewards] = resMADDPG(servers, tasks, maxEpisodes)
% 定义网络参数
numAgents = numServers;
stateDim = 2; % 服务器状态维度
actionDim = 2; % 动作维度(分配计算资源和带宽)
hiddenLayerSize = 64;
learningRate = 1e-4;
batchSize = 64;
memoryCapacity = 10000;
gamma = 0.99;
tau = 0.005; % 软更新参数
% 创建经验回放缓冲区
memory = rlReplayMemory(memoryCapacity, 'Observation', {stateDim}, 'Action', {actionDim}, 'Reward', {}, 'NextObservation', {stateDim}, 'Done', {});
% 创建神经网络
actorNet = createActorNetwork(stateDim, actionDim, hiddenLayerSize);
criticNet = createCriticNetwork(stateDim, actionDim, hiddenLayerSize);
targetActorNet = createActorNetwork(stateDim, actionDim, hiddenLayerSize);
targetCriticNet = createCriticNetwork(stateDim, actionDim, hiddenLayerSize);
% 设置优化器
actorOptimizer = adamupdate(actorNet, learningRate);
criticOptimizer = adamupdate(criticNet, learningRate);
% 初始化动作和奖励
actions = zeros(maxEpisodes, numAgents, actionDim);
rewards = zeros(maxEpisodes, numAgents);
% 开始训练
for episode = 1:maxEpisodes
% 重置环境
states = servers;
done = false;
totalReward = 0;
while ~done
% 获取动作
[actions(episode, :, :), _] = getActions(actorNet, states);
% 执行动作并获取奖励
[nextStates, rewards(episode, :), done] = stepEnvironment(states, actions(episode, :, :), tasks);
totalReward = totalReward + sum(rewards(episode, :));
% 存储经验
for i = 1:numAgents
experience = struct('Observation', states(i, :), 'Action', actions(episode, i, :), 'Reward', rewards(episode, i), 'NextObservation', nextStates(i, :), 'Done', done);
add(memory, experience);
end
% 更新状态
states = nextStates;
end
% 训练网络
if memory.NumEntries >= batchSize
minibatch = sample(memory, batchSize);
trainNetworks(minibatch, actorNet, criticNet, targetActorNet, targetCriticNet, actorOptimizer, criticOptimizer, gamma, tau);
end
% 显示每轮训练的结果
disp(['Episode ', num2str(episode), ': Total Reward = ', num2str(totalReward)]);
end
end
% 辅助函数定义
function net = createActorNetwork(stateDim, actionDim, hiddenLayerSize)
layers = [
featureInputLayer(stateDim, 'Name', 'observation')
fullyConnectedLayer(hiddenLayerSize, 'Name', 'fc1')
reluLayer('Name', 'relu1')
fullyConnectedLayer(actionDim, 'Name', 'fc2')
tanhLayer('Name', 'tanh1')];
net = dlnetwork(layers);
end
function net = createCriticNetwork(stateDim, actionDim, hiddenLayerSize)
inputState = featureInputLayer(stateDim, 'Name', 'observation');
inputAction = featureInputLayer(actionDim, 'Name', 'action');
fc1 = fullyConnectedLayer(hiddenLayerSize, 'Name', 'fc1');
relu1 = reluLayer('Name', 'relu1');
fc2 = fullyConnectedLayer(1, 'Name', 'fc2');
layers = [inputState, inputAction, concatenationLayer(1, 2, 'Name', 'concat'), fc1, relu1, fc2];
net = dlnetwork(layers);
end
function [actions, logProbs] = getActions(net, states)
observations = dlarray(states, 'SSC');
[actions, logProbs] = forward(net, observations);
actions = extractdata(actions);
logProbs = extractdata(logProbs);
end
function [nextStates, rewards, done] = stepEnvironment(states, actions, tasks)
% 模拟环境步骤
nextStates = states + actions * 0.1; % 简单模拟状态变化
rewards = -sum(abs(tasks - nextStates), 2); % 简单奖励函数
done = all(sum(abs(tasks - nextStates), 2) < 1e-3, 1); % 简单终止条件
end
function trainNetworks(minibatch, actorNet, criticNet, targetActorNet, targetCriticNet, actorOptimizer, criticOptimizer, gamma, tau)
% 提取小批量数据
observations = cat(1, minibatch.Observation{:});
actions = cat(1, minibatch.Action{:});
rewards = cat(1, minibatch.Reward{:});
nextObservations = cat(1, minibatch.NextObservation{:});
dones = cat(1, minibatch.Done{:});
% 计算目标值
nextActions = getActions(targetActorNet, nextObservations);
nextValues = forward(targetCriticNet, nextObservations, nextActions);
targets = rewards + (1 - dones) * gamma * nextValues;
% 训练批评者网络
criticLoss = meanSquaredError(forward(criticNet, observations, actions), targets);
gradients = dlgradient(criticLoss, criticNet.Learnables);
criticNet = updateNetwork(criticNet, gradients, criticOptimizer);
% 训练演员网络
actorLoss = -mean(forward(criticNet, observations, getActions(actorNet, observations)));
gradients = dlgradient(actorLoss, actorNet.Learnables);
actorNet = updateNetwork(actorNet, gradients, actorOptimizer);
% 软更新目标网络
targetActorNet = softUpdate(targetActorNet, actorNet, tau);
targetCriticNet = softUpdate(targetCriticNet, criticNet, tau);
end
function net = updateNetwork(net, gradients, optimizer)
[net, ~] = adamupdate(net, gradients, optimizer);
end
function net = softUpdate(targetNet, sourceNet, tau)
for i = 1:numel(targetNet.Learnables)
paramName = targetNet.Learnables{i}.Name;
targetNet.Learnables{i}.Value = (1 - tau) * targetNet.Learnables{i}.Value + tau * sourceNet.Learnables{i}.Value;
end
end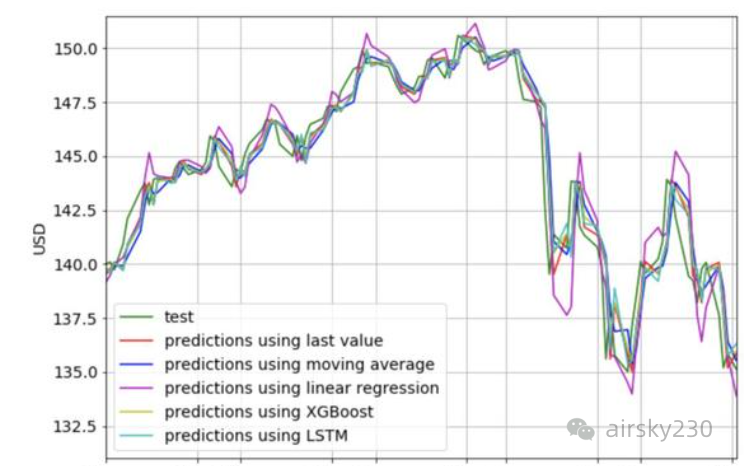


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











