







 本文详细介绍了CUDA编程中的通信机制,包括host与device间的数据拷贝、块内的通信与同步。CUDA内存拷贝函数如cudaMemcpy()确保数据同步传输,而线程同步主要依靠__syncthreads()函数。此外,还讨论了其他同步函数如cudaDeviceSynchronize()、cudaStreamSynchronize()和cudaEventSynchronize(),以及如何利用事件进行跨流同步。通过实例展示了如何在CUDA程序中正确管理和同步数据,以避免竞争条件和数据不一致问题。
本文详细介绍了CUDA编程中的通信机制,包括host与device间的数据拷贝、块内的通信与同步。CUDA内存拷贝函数如cudaMemcpy()确保数据同步传输,而线程同步主要依靠__syncthreads()函数。此外,还讨论了其他同步函数如cudaDeviceSynchronize()、cudaStreamSynchronize()和cudaEventSynchronize(),以及如何利用事件进行跨流同步。通过实例展示了如何在CUDA程序中正确管理和同步数据,以避免竞争条件和数据不一致问题。
通信机制
- 数据传输:比如host和device内存之间的拷贝函数,直接将数据拷贝过去
- 通过共享内存,比如shared_memory在块内线程共享,unified memory在host和devie间共享内存
同步
- 因为核函数异步执行,所以内存拷贝函数是默认同步的。
- 当使用共享内存时,要考虑同步,否则会出现竞争问题
host和device间的数据拷贝
host和device之间的数据拷贝可以使用cudaMemcpy()
比如
cudaMemcpy(d_x, x, N*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, N*sizeof(float), cudaMemcpyHostToDevice);
saxpy<<<(N+255)/256, 256>>>(N, 2.0, d_x, d_y);
cudaMemcpy(y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost);
这个拷贝是同步的,比如cudaMemcpy(d_y, y, N*sizeof(float), cudaMemcpyHostToDevice);从host拷贝到device,会将host中指针y的所有数据拷贝给device完成时,程序才会继续向下执行。
所以上面例子中,kernel函数会等到拷贝到device数据全部完成才会执行。
然后kernel函数是异步的,也就是这个kernel函数会在GPU启动,这时控制权立刻回到CPU继续向下执行程序。
也就是这时执行来到最后一行,但是cudaMemcpy是同步的,他不会开始执行,因为device端在运行,所以他会等到device端运行完了,再开始执行拷贝操作。这就保证了同步。
块内的通信与同步
线程通信
块内通信:通过共享内存进行通信,块内每个线程都能访问shared_memory,不同块的线程不能通信。
线程同步: __syncthreads();当某个线程执行到该函数时,进入等待状态,直到同一线程块(Block)中所有线程都执行到这个函数为止,即一个__syncthreads()相当于一个线程同步点,确保一个Block中所有线程都达到同步,然后线程进入运行状态。
同步函数
_syncthreads()线程块内线程同步;
当整个线程块走向同一分支时才可以使用_syncthreads(),否则造成错误;一个warp内的线程不需要同步;即当执行的线程数小于warpsize时,不需要同步函数,调用一次至少需要四个时钟周期,一般需要更多时钟周期,应尽量避免使用。每个SM包含8个CUDA内核,并且在任何一个时刻执行32个线程的单个warp , 因此需要4个时钟周期来为整个warp发布单个指令。你可以假设任何给定warp中的线程在锁步(LOCKSTEP)中执行,。LOCKSTEP技术可以保持多个CPU、内存精确的同步,在正确的相同时钟周期内执行相同的指令。但要跨warp进行同步,您需要使用 _syncthreads()
块内同步函数:__syncthreads ()
线程调用此函数后,该线程所属块中的所有线程均运行到这个调用点后才会继续往下运行。
#include
__global__ void staticReverse(int *d, int n)
{
__shared__ int s[64]; //数组在shared memory
int t = threadIdx.x;
int tr = n-t-1;
s[t] = d[t]; //将数组d中数据赋值给s
//因为数组s是所有线程共享的,所以可能出现数据竞争问题。
// Will not conttinue until all threads completed
//调用同步函数,只有当前block中所有线程都完成之后,再往下走
__syncthreads();
d[t] = s[tr]; //将s中数据其他数据给d
}
int main(void)
{
const int n = 64;
int a[n], r[n], d[n];
for (int i = 0; i < n; i++) {
a[i] = i;
r[i] = n-i-1;
d[i] = 0;
}
int *d_d;
cudaMalloc(&d_d, n * sizeof(int));
// run version with static shared memory
cudaMemcpy(d_d, a, n*sizeof(int), cudaMemcpyHostToDevice);
staticReverse<<<1,n>>>(d_d, n);
cudaMemcpy(d, d_d, n*sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < n; i++)
if (d[i] != r[i]) printf("Error: d[%d]!=r[%d] (%d, %d)n", i, i, d[i], r[i]);
}
其他同步函数
这里主要区别几个个同步函数:
- cudaDeviceSynchronize() :该方法将停止CPU端线程的执行,直到GPU端完成已分配的所有任务,包括kernel函数、数据拷贝等。heavy。 cudaThreadSynchronize()(后期版本删除)
- cudaStreamSynchronize():这个方法接受一个stream ID,它将阻止CPU执行直到GPU端完成相应stream ID的所有任务,但其它stream中的CUDA任务可能执行完也可能没有执行完。
- cudaEventSynchronize(stop):会阻塞CPU,直到特定的event被记录。而event的记录是在GPU中串行执行的。
在CUDA里面,不同线程间的数据读写会彼此影响,这种影响的作用效果根据不同的线程组织单位和不同的读写对象是不同。
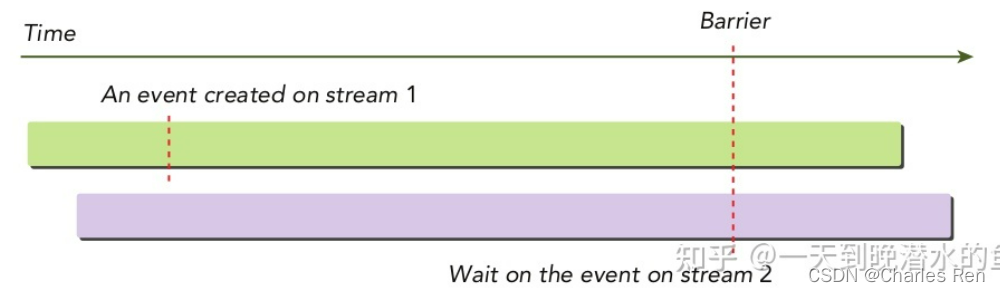
流与流之间同步(Events)
除此之外,CUDA还提供了下面的函数使用事件进行跨流同步:
cudaError_t cudaStreamWaitEvent(cudaStream_t stream, cudaEvent_t event);
该函数可以使指定的流等待指定的事件,该事件可能与同一个流相关,也可能与不同的流相关,如果是不同的流那么这个函数就是执行跨流同步功能。


















 1531
1531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











