







这几天收拾准备准备GUP“库达”计算,开学搞搞计算机图形图像处理。安装问题在另一篇博文里有记载。在学习库达前,首先来阐明一些计算机体系结构概念知识,方便入手:
CPU体系架构
什么是CPU?
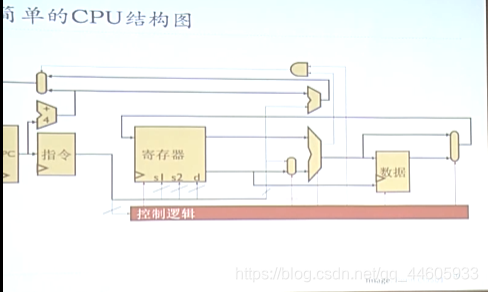
工作流程简化为:取指——>译码——>执行——>访存——>写回
流水线
上述的内部工作流程可以简化成一个流水线
极大地减少了时钟周期,但增加了一些芯片面积。
打个比方,工厂进行加工要走一系列流程,如果它的每个细节处理都安排员工来专门做这事,就做的越来越快,减少了制造这个产品的总时间,但是同时工厂也得雇佣更多的员工增加了工厂的规模和开支。
在流水线处理时,要注意依赖关系,并不是流水线越长越好
旁路:相互依赖的指令操作时,可以开一个(旁路)后门不进行上述的写回等工序直接引用到下一个指令,
停滞:流水线的停滞,就拿工厂来说,中间的一个步骤罢工,后面的步骤只能等待。
分支预测
不能消极的等待,所以我们做了分支预测,根据停滞前的那条指令来猜测下一条指令。
猜测还是要有一定的策略基础并非完全玄学,考试遇到不会的题,有的人猜对那可能是玄学,但有的人还是根据自己平时的积累进行排除选项提高预测概率。
具体方法给社会贡献了多少博士与论文啊(嘎嘎嘎)
超标量superscalar
提升IPC( CPU 每一时钟周期内所执行的指令多少),增大流水线宽度。也就如工厂一道工序进行加工的产品数目增加
但同时用的资源也多了,旁路网路增多,寄存器,存储器增多。工序占得地方大了,运载的车也就多了
乱序执行OoO(OUT of Order)
我们写的一个程序逻辑上认为计算机也会按照我们的步骤来进行,但是为了充分挖掘计算机内部的吞吐率,CPU进行重排指令。
存储器层次
计算机的主要工作占绝大数是进行访问存储器——数据的搬来搬去 。但存储器的访问速度又很慢,所以进行改良:
缓存:利用将数据放在尽可能接近的位置来供下一次更快的使用。(举个难忘的例子:我大学体育选的是乒乓球,到了期末考试,要进行一分钟55次攻防球来回,我准备了俩球,把另一个球放在了裤兜里,重要的是我还把拉链拉上了,再次取 的时候我花了好几秒,导致那次没有达成目标,第二次我直接找旁边的一女生借,虽然事先没有说明,但不得不说快多了!不出意外,有点懵逼)大概就是这么个意思。
有了前面一些简单概念的铺垫,接下来开始正式的cuda介绍。其实,cuda 的产生就是为了给CPU 分担一些计算的任务等,加快程序数据的吞吐率:
CUDA编程
1.0 编程模型
CUDA程序构架分为两部分:Host和Device。一般而言,Host指的是CPU,Device指的是GPU。在CUDA程序构架中,主程序还是由CPU来执行,而当遇到数据并行处理的部分,CUDA 就会将程序编译成GPU能执行的程序,并传送到GPU。而这个程序在CUDA里称做核(kernel)。CUDA允许程序员定义称为核的C语言函数,从而扩展了C语言,在调用此类函数时,它将由N个不同的CUDA线程并行执行N次,这与普通的C语言函数只执行一次的方式不同。执行核的每个线程都会被分配一个独特的线程ID,可通过内置的threadIdx变量在内核中访问此ID。在 CUDA 程序中,主程序在调用任何GPU内核之前,必须对核进行执行配置,即确定线程块数和每个线程块中的线程数以及共享内存大小。
1. 1核函数
- 定义:在GPU进行的函数通常称为核函数
- 一般通过__global__修饰(在核函数里,都用双下划线来修饰),调用通过<<<参数1,参数2 >>>,第一个参数代表block线程块数目,第二个参数代表线程块内含有的线程数目thread。
- 根据2可以看出它的操作单位是总的线程格的block。
- 调用时必须声明核函数的执行参数。
- 正式编程前必须使用cudaMalloc()函数先为wrap分配适当的内存空间。分配前要精打细算,因为总的内存空间一定,一个wrap分配不当的空间会导致其他线程内存不够用导致越界报错甚至死机。(字面上 还是蛮难的)。
任何程序入门编程:
#include<cuda_runtime.h>
#include<stdio.h>
int main()
{
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









