






论文题目:A Survey on Evolutionary Constrained Multiobjective Optimization
进化约束多目标优化研究综述(Jing Liang , Senior Member, IEEE, Xuanxuan Ban, Graduate Student Member, IEEE, Kunjie Yu , Member, IEEE,BoyangQu , Member, IEEE, Kangjia Qiao , Member, IEEE, Caitong Yue , Member, IEEE,KeChen , Member, IEEE, and Kay Chen Tan , Fellow, IEEE)IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION, VOL. 27, NO. 2, APRIL 2023
刚开始学习多目标优化算法,不作商业用途,如果有不正确的地方请指正!
个人总结:
主要内容

现有的CMOEAs分为7类
基于惩罚函数的方法
基于约束违反度来构造惩罚项。通过在目标函数中加入惩罚项,将约束优化问题转化为无约束优化问题。
如何设置惩罚系数是惩罚函数法中最关键的问题,对算法的效率起着决定性的作用。根据设置方法的不同,惩罚方法可以分为静态法、动态法和自适应法。
| 分类 | 特点与优点 | 缺点 |
| 静态法 | 惩罚系数不变,能有效解决简单问题 | 在算法后期不利于目标和约束之间的平衡处理复杂问题时不能达到理想效果 |
| 动态法 | 惩罚系数随着进化代数或者其他指标增加而变化。 | 需要针对不用的问题设置不同的变更规则 |
| 自适应法 | 在进化过程中通过种群的信息来调整惩罚系数,能够有效处理复杂的问题 | 设置比较复杂 |
基于目标与约束分离的方法
这些方法分别对目标和约束进行比较,主要包括CDP 、ε约束法、和随机排序( SR )
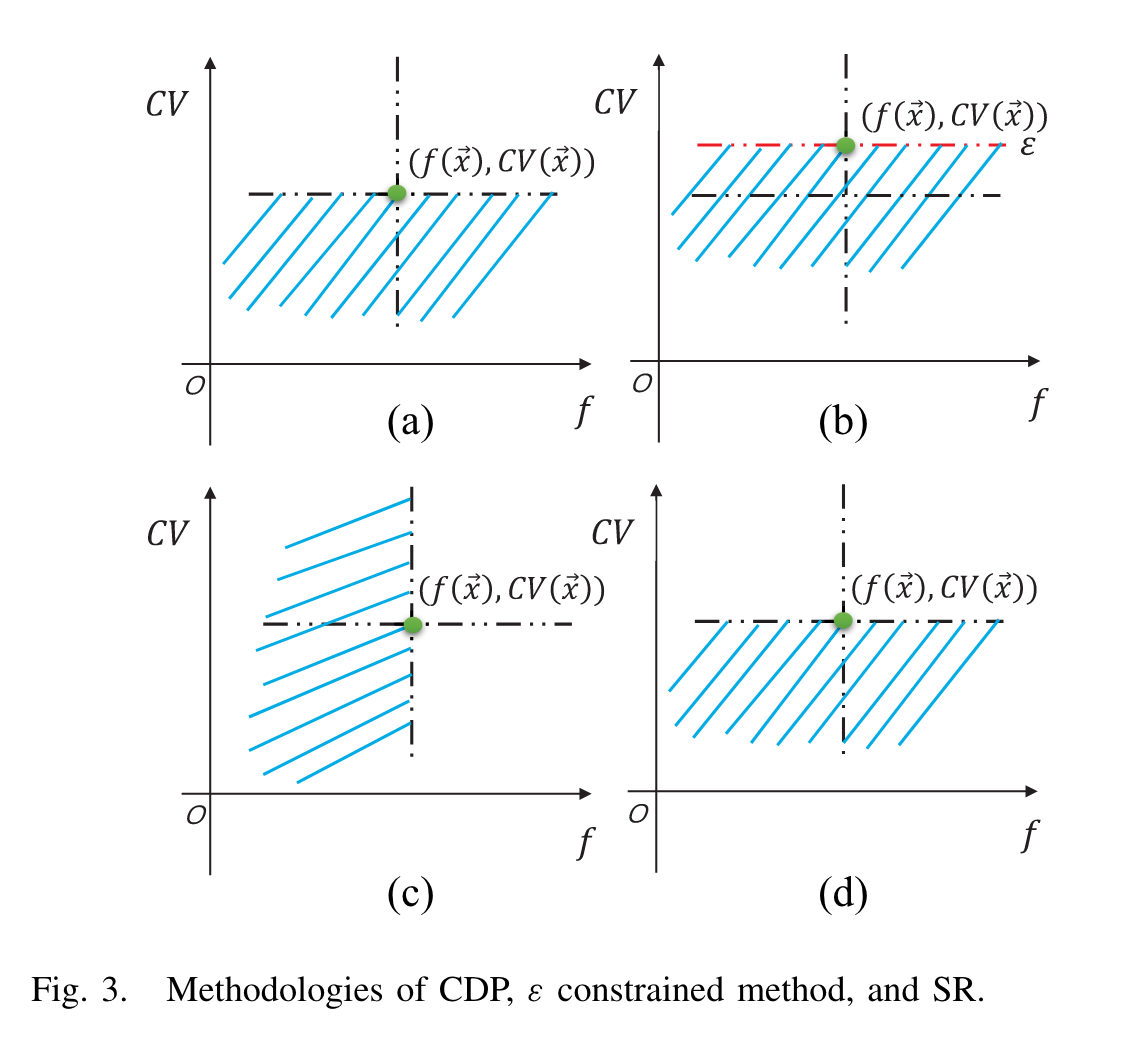
| 分类 | 特点与优点 | 缺点 |
| CDP | 在非支配排序时加入约束,操作简单。 | 偏好可行解,当问题存在离散可行域或不可行障碍时会陷入局部最优 |
| ε约束法 | 利用一个参数ε来松弛约束,ε是逐渐减小的,当个体的约束违反度小于ε时,认为是可行解 | ε需要设置,当ε为0时等于CDP算法 |
| 随机排序 | 引入一个概率参数PF,两个个体比较时以PF概率选择比较个体值还是约束值。 该方法能够在一定程度上利用目标函数的信息 | PF值设置需要考虑 |
多目标方法
在多目标优化中,约束被视为一个附加目标或多个附加目标,CMOP被转化为一个无约束问题。
将CMOPs转化为其他问题的方法
如将一个CMOP转化为协同优化问题或两阶段优化问题。经过转换后,协同进化等一些有前途的算子可以帮助种群更好地探索搜索空间,发现一些新的、潜在的信息,最终得到完整的CPF。
混合方法
一些研究者将EA与MP结合起来处理CMOPs。
改变繁殖算子的方法
这类方法侧重于在复制过程中设计高效、具体的算子
其他方法
注意点
CMOPs可以基于多任务优化原理进行求解。基于知识迁移,进化多任务( EMT )在同时解决多个不同但相关的任务时表现出了非常有前景的性能。当然,目标的优化和约束的满足可以看作是两个相互关联的任务,因此EMT中的一些知识转移机制可以很容易地用于求解CMOPs。
为了辅助CMOPs的求解,可以通过动态地考虑所有约束中的某些约束来创建一些辅助任务。此外,对于不同的辅助任务,可以采用不同的CHT来发挥互补效应。
可以对CMOPs的适应度景观进行分析。基于适应度景观的特点,可以向特定的CMOP推荐更合适的CHT和进化算子。
超启发式算法的思想也有利于CHTs的利用。超启发式算法具有自学习能力,利用启发式算法的反馈信息来提高其性能。因此,一些超启发式策略有望被设计来高效利用不同CHT在演化过程中的优势。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









