







目录
1 AlphaStar及背景简介
相比于之前的深蓝和AlphaGo,对于《星际争霸Ⅱ》等策略对战型游戏,使用AI与人类对战的难度更大。比如在《星际争霸Ⅱ》中,要想在玩家对战玩家的模式中击败对方,就要学会各种战术,各种微操和掌握时机。在游戏中玩家还需要对对方阵容的更新实时地做出正确判断以及行动,甚至要欺骗对方以达到战术目的。总而言之,想要让AI上手这款游戏是非常困难的。但是DeepMind做到了。
AlphaStar是DeepMind与暴雪使用深度强化学习技术实现的计算机与《星际争霸Ⅱ》人类玩家对战的产品,其因为近些年在《星际争霸Ⅱ》比赛中打败了职业选手以及99.8%的欧服玩家而被人所熟知。北京时间2019年1月25日凌晨2点,暴雪公司与DeepMind合作研发的AlphaStar正式通过直播亮相。按照直播安排,AlphaStar与两位《星际争霸Ⅱ》人类职业选手进行了5场比赛对决演示。加上并未在直播中演示的对决,在人类对阵AlphaStar的共计11场比赛中,人类仅取得了1场胜利。DeepMind也将研究工作发表在了2019年10月的 Nature 杂志上。本章将对这篇论文进行深入的分析,有兴趣的读者可以阅读原文。
2 AlphaStar的模型输入与输出 —— 环境建模
在构建深度强化学习模型时,第一步是定义模型的输入与输出。在《星际争霸Ⅱ》这一复杂环境中,AlphaStar团队首先将游戏环境抽象为多个独立的数据信息,以便神经网络能够有效地学习和决策。
状态(网络输入)
AlphaStar将《星际争霸Ⅱ》的环境状态划分为四个主要部分:实体信息、地图信息、玩家数据和游戏统计数据。
- 实体信息(Entities):该部分描述了当前环境中的所有单位(建筑、兵种等)。每个单位的属性信息均以向量形式表示。例如,一个建筑的向量信息可能包括其生命值、等级、位置、冷却时间等。因此,当前帧的全部实体信息可以表示为多个定长的向量,每个向量对应一个可见实体。
- 地图信息(Map):这部分描述全局地图状态。地图信息通常以矩阵或图像的形式输入神经网络,涵盖诸如地形、资源点、敌我单位分布等信息。
- 玩家数据(Player Data):该部分存储玩家的全局属性,例如种族、等级等。这些数据通常以标量的形式输入网络。
- 游戏统计信息(Game Statistics):包括**视野位置(小地图窗口位置)、游戏进程(游戏开始时间等)**等标量信息。这些数据为智能体提供当前战局的额外背景信息,以辅助决策。
动作(网络输出)
AlphaStar的动作由六个部分组成。这些部分构成了一系列有序的决策步骤,共同定义了智能体在当前环境中的行为。
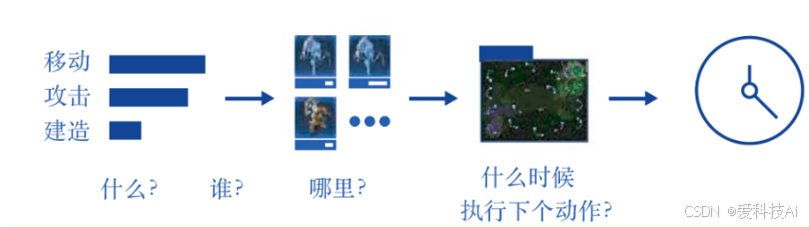
- 动作类型(Action Type):决定下一步执行的具体行为,例如移动单位、建造建筑、调整视角等。
- 选中的单元(Selected Units)
在执行特定动作之前,首先需要选择作用对象。例如,若动作类型是“移动单位”,则需确定具体的单位(如某个士兵)。 - 目标(Target)
选定单位后,需要决定执行动作的目标。目标可以是地图上的某个位置(移动、巡逻)或敌方单位(攻击、干扰)。 - 执行队列(Queued)
指定该动作是立即执行还是排队等待。例如,一个单位可以执行“到达目标后自动攻击”或“等待进一步指令”等不同策略。 - 是否重复(Repeat)
如果某个动作需要连续执行,则可以直接重复上一个动作,而无需每次都重新计算。 - 延时(Delay)
指定智能体在执行下一个操作前的等待时间,以模拟人类玩家的操作节奏,避免指令过于频繁。
通过上述输入与输出设计,AlphaStar能够在《星际争霸Ⅱ》中进行高效的策略学习,并逐步优化其战术决策能力。
3 AlphaStar 模型解析——网络结构
在 AlphaStar 的计算模型中,核心任务是从输入的状态信息生成合理的动作决策。其整体网络架构可以划分为三个主要部分:输入处理、信息融合与状态表示、输出决策。
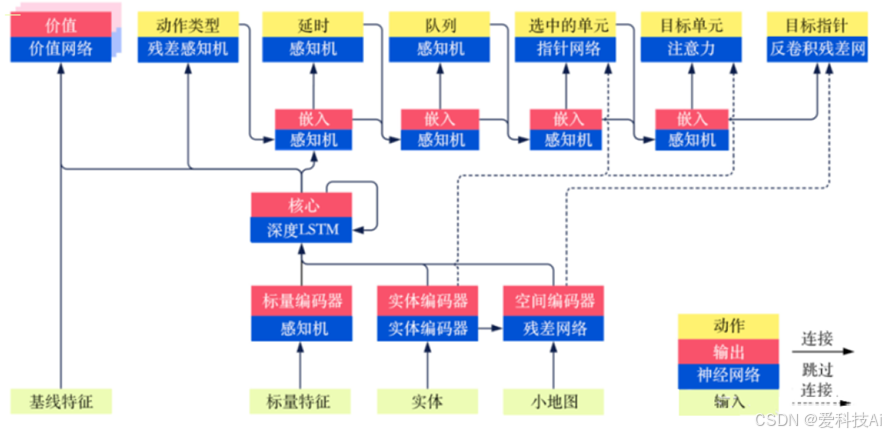
输入处理
AlphaStar 的输入由三类数据构成:标量特征、实体信息和小地图数据。它们分别对应不同的编码方式,以便提取有效特征:
- 标量特征(Scalar Features):该部分包含玩家的等级、资源量、当前游戏时间等关键信息,采用**多层感知机(MLP)**进行编码,将其转换为适合后续计算的向量表示。
- 实体信息(Entities)
包括地图上的单位或建筑(如兵种、基地)的属性信息,如位置、血量、攻击力等。AlphaStar 采用Transformer 结构来处理这类数据,以捕捉单位间的复杂关系,并有效建模个体与整体的交互特性。 - 小地图数据(Minimap)
该部分由整个战场的全局视图构成,提供空间布局及单位分布信息。为了高效提取图像特征,AlphaStar 使用残差网络(ResNet) 进行编码,最终生成定长的向量表示。
信息融合与状态表示
在完成输入特征的提取后,AlphaStar 采用深度长短期记忆网络(LSTM) 作为核心模块,融合上述不同类型的特征数据,并形成对当前状态的完整表示。LSTM 具备时间依赖性处理能力,能够追踪历史信息,帮助 AI 在决策时考虑长期影响。
这一融合后的状态表示不仅用于决策动作,还会被传递至价值网络(Value Network) 来评估局势的长期收益,同时输入残差 MLP 进行进一步的特征提取,为后续的动作选择提供支持。
输出决策
AlphaStar 的决策过程是一个层级化的自回归生成过程,每个动作由多个步骤依次确定,如下:
- 确定动作类型:以 LSTM 生成的状态向量为输入,利用残差 MLP 计算可能的动作类型,并通过 Softmax 输出概率分布。
- 确定执行延迟(Delay)
结合 LSTM 输出和动作类型的嵌入向量,使用 MLP 预测该动作的执行时机。 - 确定执行队列(Queue)
通过 MLP 计算该动作是立即执行,还是加入队列等待执行。 - 选定操控单位(Select Units)
在需要操作特定单位时,使用指针网络(Pointer Network) 进行单位筛选。指针网络本质上是一种序列到序列的映射机制,使得模型可以高效地从当前单位列表中选取目标单位。 - 选择目标(Target Selection):目标单位(Target Unit) 通过注意力机制(Attention) 确定最佳攻击或交互对象。目标位置(Target Point) 采用反卷积残差网络(Deconvolutional Residual Network) 将嵌入的向量转换为地图上的具体坐标,实现精确定位。
这一层级化的动作决策机制确保了 AlphaStar 在应对不同局势时具备灵活性,同时能够执行复杂且合理的操作。
4 AlphaStar的训练方法解析
AlphaStar的训练方法可以归纳为四个主要部分:监督学习、强化学习、模仿学习,以及多智能体学习(或自学习)。这些训练策略相互配合,使得AlphaStar能够在《星际争霸II》的复杂环境中逐步优化自身策略,达到高水平的竞技能力。
监督学习:基于人类数据的初始化
在训练的初始阶段,AlphaStar采用监督学习的方法,以人类玩家的对局数据作为参考,对神经网络进行初步优化。具体方法如下:
1)输入数据:收集到的《星际争霸II》人类玩家对局数据,包括各个时间步的游戏状态(State)和对应的玩家动作(Action)。
2)训练方式:
- 通过解码每个时间步的游戏状态,将其送入神经网络,计算智能体预测的动作概率分布。
- 计算模型输出的概率分布与人类玩家实际动作分布的KL散度(Kullback-Leibler Divergence)。
- 采用不同的损失函数优化网络:
- 交叉熵损失(Cross-Entropy Loss):用于分类任务,如动作类型的选择(攻击、移动、建造等)。
- 均方误差(MSE):用于回归任务,如目标坐标预测等。
通过监督学习,AlphaStar的动作选择模式初步向人类玩家对齐,使得其决策更具合理性,从而加速后续强化学习的收敛。
强化学习:基于策略优化的智能体训练
强化学习的核心目标是优化智能体的策略,使其在对局中获得尽可能高的奖励。AlphaStar采用了一种基于非采样(off-policy)的强化学习架构,即免策略学习(off-policy learning),以提高训练效率。其强化学习框架主要包括以下几部分:
演员-评论员(Actor-Critic)架构
AlphaStar采用Actor-Critic结构,即:
策略网络(Actor):根据当前状态选择动作。
价值网络(Critic):估计当前状态的预期奖励 V(s),用于衡量该状态下动作的价值。
策略优化的核心思想是计算优势函数(Advantage Function),即某个动作相较于“平均动作”能额外获得的奖励。在 AlphaStar 中,还引入了向上移动的策略更新(UPGO,Upgoing Policy Update),从而将未来更有利的信息纳入奖励计算,鼓励智能体朝着长期收益更高的方向优化策略。
策略梯度优化
在 AlphaStar 的强化学习过程中,由于智能体的策略在训练过程中不断更新,采集到的数据可能来自不同的策略分布。直接使用这些数据进行策略梯度优化可能会引入偏差,导致模型学习的方向发生偏移。因此,需要对数据进行修正,以确保训练的稳定性和有效性。
为了解决这一问题,AlphaStar 采用了重要性采样的方法。重要性采样的核心思想是对采集到的数据进行加权调整,使得它们在训练过程中能够更好地匹配当前智能体的策略。通过计算当前策略与采样策略之间的概率比值,可以衡量某个动作在训练时的重要程度,并据此调整训练信号,以减少偏差带来的影响。
然而,如果不加限制,某些数据点可能会获得过高的权重,导致训练不稳定,甚至使模型的优化方向发生剧烈波动。为此,AlphaStar 采用了 V-trace 方法,对重要性权重进行裁剪,将其最大值限制在合理范围内。这种方法可以有效防止某些样本对梯度更新造成过大的影响,从而提高训练的稳定性,使智能体能够更加稳健地进行策略优化和学习。
价值网络优化
在强化学习中,价值网络的优化通常采用时序差分(TD,Temporal Difference)方法,其中常见的几种策略包括:
TD(0)(一步时序差分):仅依赖当前奖励进行更新,方差较小但偏差较大。
蒙特卡洛(Monte Carlo)方法:累积整个未来奖励进行更新,无偏但方差较大。
TD(λ):结合 TD(0) 和蒙特卡洛方法的优势,以权重 λ 控制未来奖励对当前更新的影响,达到平衡。
通过这些优化方法,AlphaStar 能够有效地学习长期决策,并对复杂的策略进行建模。
模仿学习:结合人类策略优化
在强化学习之外,AlphaStar 还引入了模仿学习(Imitation Learning),进一步利用人类玩家数据优化策略。其关键措施包括:
- 额外的监督损失:在强化学习的目标函数中,加入基于人类数据的监督损失,确保智能体的学习方向更接近人类策略。
- 人类统计特征奖励:
- 统计人类玩家的建造顺序(Build Order)、单位生产(Build Unit)、技能使用(Effect)等特征。
- 设定奖励函数,使得智能体的行为模式与人类更接近。
这一部分的训练进一步提高了 AlphaStar 在实际对战中的策略合理性,使其更符合高水平人类玩家的决策方式。
联盟对抗:对战驱动的进化训练
在强化学习中,模型的鲁棒性是一个关键问题,尤其是在星际争霸这样的复杂对抗环境下。简单的策略可能会针对特定对手取得优势,但要做到应对所有可能的战术变化,则需要更为完善的训练方法。AlphaStar 通过两种核心思想来提升策略的鲁棒性:
1)基于种群的训练(Population Based Training)
AlphaStar 的智能体并不是仅与自身进行对抗,而是面对一个由不同策略组成的“联盟”(League)。这一策略池中的对手具有不同的战术风格,智能体的训练目标是能够战胜联盟中的所有对手,而不仅仅是战胜自身历史版本。这种方法能够有效防止策略陷入局部最优,确保模型具备更广泛的适应性。
2) 对抗性训练(Adversarial Training)
对抗性训练的目标是提升联盟的整体鲁棒性,确保没有单一策略可以完全击败联盟中的所有策略。这种方法不仅提高了联盟的整体竞争力,也促使主智能体(Main Agent)不断优化自身,使其在面对不同类型的对手时都能保持较强的对抗能力。
具体方法为联盟对抗:
1)优先级虚拟自学习(Prioritized Fictitious Self-Play, pFSP)
pFSP 是一种高效的种群策略采样机制,包含两个关键点:
- 虚拟自学习(Fictitious Self-Play):智能体的训练目标是战胜历史上所有的对手,而不仅仅是自己过去的版本。这样能够保证策略不会被特定对手克制,而是具备更广泛的适应性。
- 优先级对手选择(Priority):在选择训练对手时,系统会优先选择更难战胜的对手,而不是随机选择。这种方式通过一个胜率矩阵(payoff estimation)来衡量智能体与不同对手的对战结果,并动态调整对手的选择概率,使训练更具针对性。
2)三种智能体
AlphaStar 训练过程中,采用了三类不同的智能体,每种智能体的训练目标不同,以保证策略的鲁棒性:
- 主智能体(Main Agents):目标是训练出最终部署的最强鲁棒策略。
使用PFSP(prioritized fictitious self-play)进行对手选择。其会倾向于选择联赛中胜率高的对手,同时其也会基于一个固定的概率选择到其他Main Agent作为对手。总的来说这类智能体需要面对最严峻的挑战也承担了最重要的使命。联盟利用者(League Exploiters):专门寻找联盟的漏洞,尝试发现能够击败联盟所有策略的新战术。这些智能体不需要具备鲁棒性,而是用于不断暴露联盟的弱点,并将找到的新策略加入联盟,以增强整体鲁棒性。
- 主利用者(Main Exploiters):专门针对当前的主智能体进行对抗,目的是找出其弱点,使其不断优化自身策略。
- 50% 概率使用 pFSP 方法与主智能体对抗。
- 50% 概率直接挑战当前的主智能体。
- 当能够以 70% 胜率击败主智能体时,该策略会被加入联盟。
- 主探索者(Main exploiters):与当前Main Agents(的集合)进行对抗,用于寻找Main Agent的弱点,不要求该策略是robust的,但是该对抗策略可以使得Main Agent更加鲁棒,具体目标有两种:1)50%概率,或者和当前Main Agent 胜率低于20%时,与Main Agent的集合使用PFSP进行对抗 2)50%概率与当前的Main Agent进行对抗
3)策略存档与重设
在训练过程中,AlphaStar 会定期保存策略的快照(snapshot),确保智能体能够保留有效的策略,同时避免陷入局部最优。
- 主智能体、联盟利用者、主利用者在训练时,都会定期存档其策略快照。
- 当联盟利用者或主利用者在 70% 的对战中取得胜利时,它们的策略将被存入联盟。
- 除了主智能体外,所有加入联盟的智能体都有一定概率被重设为监督学习(SL)初始化的策略,以保证训练的多样性并防止过拟合。
5 AlphaStar 总结
AlphaStar 是一个突破性的深度强化学习系统,专注于星际争霸 II 游戏中的智能体训练。以下是 AlphaStar 的主要特点和总结:
1)高度融合的神经网络架构
AlphaStar 设计了一个能够融合图像、文本、标量等信息的神经网络架构。通过自回归(autoregressive)技巧,AlphaStar 成功解耦了结构化的动作空间,使得智能体能够在复杂的游戏环境中做出更准确的决策。
2)模仿学习与监督学习的结合
AlphaStar 融合了模仿学习与监督学习,通过人类统计量计算方法来帮助智能体学习。模仿学习使得智能体能够模拟人类玩家的策略,而监督学习则进一步提升了智能体的表现,特别是在面对复杂战术时。
3)深度强化学习与复杂训练策略
AlphaStar 采用了复杂的深度强化学习方法,并且拥有一系列精细化的训练策略。这些策略不仅提高了智能体在多变对抗中的表现,还使得其在长时间的训练过程中不断优化。
4)大规模计算资源需求
完整的 AlphaStar 训练过程消耗了大量的计算资源。每个智能体使用了 32 个第三代张量处理单元(TPUs)进行为期 44 天的训练。在训练期间,AlphaStar 创建了近 900 个不同的游戏玩家,并通过多种版本进行测试,其中 AlphaStar Final 的表现超过了 99.8% 的人类玩家。
5)ELO 分数的提升与策略优化
随着训练的进行,AlphaStar 的 ELO 分数逐渐提高,反映了其策略的不断优化和进步。通过与历史策略进行循环赛,AlphaStar 在逐步提升自身策略的同时,也证明了深度强化学习的优势。
6)Ablation Study 的设计影响
通过 ablation study,AlphaStar 研究了不同训练设计对智能体表现的影响。结果表明,League Exploiter 的训练对智能体表现有显著提升;与传统的自我对抗(self-play)相比,虚拟自学习(fictitious self-play)大幅提升了胜率;此外,神经网络结构的设计也对监督学习阶段的智能体表现起到了重要作用。
6 应用与启示
- 军事指挥系统
- 通过关系推理网络提升战场态势感知能力;
- 联盟训练机制可用于多兵种协同策略生成。
- 复杂决策场景
- 自动驾驶中的长周期规划;
- 机器人多任务协调。
AlphaStar证明,通过多模态感知架构+混合学习范式+大规模分布式训练,AI可攻克超复杂实时决策难题。其方法论对非完美信息博弈、工业控制系统等领域具有普适参考价值。
论文链接:https://www.nature.com/articles/s41586-019-1724-z

















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









