









论文研读_基于网格的多目标优化进化算法
- 此篇文章为 S. Yang , M. Li , X. Liu , J. Zheng , A grid-based evolutionary algorithm for many-objective optimization, IEEE Trans. Evol. Comput. 17 (5) (2013) 721–736 . 的论文学习笔记,只供学习使用,不作商业用途,侵权删除。并且本人学术功底有限如果有思路不正确的地方欢迎批评指正!
本文引入了两个概念—网格优势和网格差异—来确定网格环境中个体之间的相互关系。三种基于网格的准则,即==网格排序、网格拥挤距离和网格坐标点距离==,被纳入到个体的适应度中,以便在配对和环境选择过程中区分它们。此外,我们还开发了一种适应性惩罚个体的适应度调整策略,基于邻域和网格优势关系,以避免部分过度拥挤以及引导搜索朝向归档中的不同方向。
引言
本文提出了一个==基于网格的进化算法(GrEA)==来解决多目标优化问题。本文的目标是利用基于网格的方法的潜力,以在保持解集之间广泛且均匀分布的同时,增强向最优方向的选择压力。
网格具有同时反映收敛性和多样性信息的内在属性。网格中的每个解都有一个确定的位置。通过比较其网格位置与其他解的网格位置,可以估计一个解的收敛性表现,通过计算其网格位置与其他解的网格位置相同或相似的解的数量,可以估计一个解的多样性表现。此外,与帕累托优越标准相比,基于网格的标准不仅可以定性地比较解,而且还可以给出它们之间每个目标的定量差异。考虑到从解之间的目标值的定量比较中增加选择压力,这似乎更适合处理多目标问题[9]、[31]。然而,到目前为止,文献中尚未充分利用网格的优势(参见第二节对现有研究的概述)。大多数现有的基于网格的进化多目标优化算法在处理两个或三个目标的问题上表现良好,但常常无法处理多目标问题。另外,一些已被发现在多目标和多目标问题中都成功的基于聚合的算法,如细胞自动机进化算法[54]和基于分解的多目标进化算法(MOEA/D)[71],也使用网格结构来引导搜索。然而,与此处的基于网格的方法的本质区别在于,它们通过一组具有网格结构的权重向量,将一个多目标优化问题分解为多个单目标问题,并根据这些均匀分布的权重向量,将搜索引向不同方向的帕累托前沿。
作为首次尝试捕捉并利用网格属性进行进化多目标优化,我们最近开发了一个==基于网格的适应度策略[50]==。利用个体的网格坐标,我们使用三种基于适应度分配的标准来增强向最优解方向的选择压力。在[50]中的比较研究表明,我们提出的策略在处理测试的多目标问题时,与若干进化多目标优化算法具有竞争性。受到初步尝试取得鼓舞人心的实验结果的鼓舞,本文沿着这个方向进行了进一步和深入的研究,并提出了GrEA来处理多目标优化问题。

图1:一个在双目标空间中以网格形式呈现个体的插图。
GrEA相较于其前身的主要贡献可以总结如下。
• 引入了网格优势的概念,用于在配对和环境选择过程中比较个体。
• 设计了一种精细的种群中个体密度估计器,它不仅考虑了其邻居的数量,而且考虑了它自身与这些邻居之间的距离差异。
• 开发了一种改进的适应度调整技术,用于避免部分过度拥挤,同时引导存档集合中的搜索向不同的方向进行。
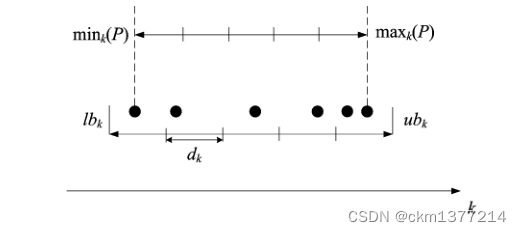
图2:第 k 个目标中的网格设置。
动机和相关工作
网格具有自然的能力通过自身的网格位置(即,网格坐标)来反映进化过程中解的分布。解的网格坐标之间的差异指示了解之间的距离,并进一步描绘了种群中解的密度信息。例如,图1展示了在双目标空间中网格内的个体。对于图中的个体A、B和C,他们的网格坐标分别是(0,4)、(1,1)和(3,1)。显然,A和C之间的网格坐标差(即,(3 − 0) + (4 − 1) = 6)大于A和B之间的差(即,(1 − 0) + (4 − 1) = 4),这表明C比B离A更远。另外,考虑到存在另一个与C具有相同网格坐标的个体(D)(即,他们之间的网格坐标差为0),可以认为C相比于A和B具有更大的拥挤度。
另一方面,网格也能够从收敛的角度来指示解的进化状态。网格坐标不仅考虑了一种解是否优于另一种解,还考虑了他们之间目标值的差异。例如,考虑图1中具有自身网格坐标(0,4)和(1,1)的个体A和B,他们之间目标f2的差异明显大于目标f1的差异(即,(4 − 1) > (1 − 0))。这意味着,当解在帕累托优势意义上相同时,网格可以进一步区分这些解,从而在进化的多目标优化过程中提供更高的选择压力。
总的来说,以上基于网格的EMO算法非常成功,其中大部分在具有两个或三个目标的问题上表现得非常出色。然而,有趣的是,他们对于多目标问题的应用却鲜少受到关注和考虑。这种情况主要可能归因于以下三个原因,概述如下:
- 数据存储和计算时间的需求呈指数级增长。大多数现有的基于网格的算法的计算都围绕着网格中的超立方体进行。这种以立方体为中心的计算通常需要存储网格中每个超立方体的信息(例如,每个超立方体中的个体数量)。正如Corne和Knowles[9]指出的,这些算法可能不适合解决多目标问题,因为它们的运算依赖于随着目标数量的增加而指数级增长的数据结构。另外,当实施以立方体为中心的计算时,高维问题的计算成本也会极大[39]。如果我们遍历一个m维网格中的每个超立方体,那么将有r^m个超立方体需要被访问,其中r是每个维度中的划分数量。
- 网格的属性没有得到充分的利用或开发。一些基于网格的EMO算法(如PAES、DMOEA和TDEA)的选择标准,在收敛性意义上,是基于帕累托优势关系的,因此在多目标优化的演化过程中,可能无法提供足够的选择压力以指向期望的方向。
- 密度估计器可能无法准确反映解决方案的分布。由于网格中超立方体的数量随目标数量的增加而指数级增长,对于多目标问题的解决方案很可能会分散在不同的超立方体中。因此,现有的只考虑单个超立方体中个体数量的基于网格的EMO算法,无法通过他们的分布来区分个体,因为基于这种密度估计方法,值几乎相等。
显然,上述困难在很大程度上限制了现有基于网格的EMO算法应用于多目标问题。然而,我们认为这些困难并非无法克服。首先,可以用以个体为中心的计算替换以立方体为中心的计算。在这种情况下,网格仅被视为描述个体地址的指针。其次,可以引入一种基于网格坐标差异的选择标准来增强选择压力。最后,如果个体的密度值依赖于不在单个超立方体中,而是在由一组其范围随目标数量增加的超立方体构成的区域中的记录,那么密度估计的失败也可能得到解决。
在牢记这些思想和动机的基础上,本文将在接下来的章节中提出、研究和讨论一种基于网格的多目标进化优化算法。
算法
在本部分,我们首先介绍GrEA中使用的一些定义。然后,我们展示了提出的算法的框架。接下来,我们描述了适应度分配过程。最后,我们在第三部分的D和E小节中分别给出了配对和环境选择过程的策略。
定义和概念
不失一般性,一个多目标优化问题可以被陈述为一个最小化问题,并以下述方式定义:

其中,x表示可行解空间Ω中的解向量,Fi(i = 1,2,…,M)是要最小化的第i个目标函数。
定义(帕累托支配):

其中,x ≺ y表示x支配y。帕累托支配关系反映了决策者对首选结构的最弱假设。一个不被其他向量所支配的决策向量称为帕累托最优解。在决策空间中最优解的集合被称为帕累托集,相应的目标向量集合被称为帕累托前沿。
在GrEA中,网格被用作一个框架,用来确定目标空间中个体的位置。因此,它与进化群体的适应性似乎是明智的。换句话说,当生成一个新的群体时,网格的位置和大小应该是可适应和可调整的,以便刚好包住群体。在这里,我们借鉴了Knowles和Corne[41]提出的自适应遗传算法的思想,采用了自适应构建网格的方法。
图2展示了第k个目标中的网格设置。 首先,找到并标记出种群P中第k个目标中的最小和最大值,分别记为min k § 和 max k §。然后,根据以下公式确定第k个目标中网格的下界和上界:

其中 div 表示在每个维度上目标空间的划分数(例如,在图2中,div = 5)。因此,原始的 M 维目标空间将被划分为 div M 个超立方体。于是,第k个目标中的超立方体宽度 d k 可以按照下列方式形成:

在这种情况下,第k个目标中个体的网格位置可以通过lb k和d k来确定:

其中⌊·⌋表示向下取整函数,G k (x)是第k个目标中个体x的网格坐标,F k (x)是第k个目标中x的实际目标值。例如,在图2中,第k个目标中个体(从左到右)的网格坐标分别为0、1、2、3、4和4。接下来,根据它们的网格坐标定义了两个用于比较个体之间的概念。
定义(网格支配):

其中,x ≺ grid y 表示 x 在网格上主导 y,M 是目标的数量,网格环境由种群 P 构建。显然,如果将个体的网格坐标替换为其实际目标值,网格主导的概念与帕累托主导的概念相同。它们的具体关系如下。如果一个解决方案帕累托主导另一个解决方案,后者将不会在网格上主导前者,反之亦然。另一方面,网格主导关系允许一个解决方案在某些目标上稍逊于另一个解决方案,但在其他一些目标上远远优于后者,从而主导后者,例如,图1中的个体B和C。
网格主导关系也与 ε- 主导关系类似,因为它们都是帕累托主导关系的放松形式。但是,一个重要的区别在于网格主导的放松程度由种群的进化状态决定。GrEA中的划分数div是用户预先设置的固定参数,这导致收敛性和多样性需求能够随着种群的进化自适应地调整。在目标空间中广泛分布的种群(通常出现在进化的初始阶段)具有更大的放松程度(即,网格中单元的尺寸更大),因此提供更高的选择压力。随着种群向更集中的帕累托前沿区域进化,放松程度变得更低,使得多样性得到更大的重视。

此外,我们在研究中对网格主导的使用与在基于ε主导的算法中对ε主导的使用完全不同。在基于ε主导的算法中,ε主导用于决定个体的存活。只有非主导的个体才能被保留在存档集中。然而,在GrEA中,网格主导主要用于防止个体早于网格主导它们的竞争者被存档(参见第III-E节中的适应性调整策略)。这意味着被网格主导的个体也有机会进入存档集,这在一定程度上有利于维护种群中的边界解决方案。
定义(网格差):

网格差受分割数div的影响,分割数div的范围为0到M(div-1)。分割数div越大,单元格大小越小,个体之间的网格差值越高。
算法的框架
算法1给出了GrEA的框架。该算法的基本步骤与大多数世代EMO算法(如NSGA-II[11]和SPEA2[73])类似。
首先,随机生成N个个体以形成初始种群P。
然后,按照前一节所述,设置当前种群P的网格环境,并根据个体在网格中的位置为P中的个体分配适应度。
接下来,执行配对选择以挑选出变异的有前途的解决方案。
最后,执行环境选择程序,以保留N个最佳解决方案(精英)的记录,以便存活。
适应度分配
为了使群体向最优方向演化,同时使个体在得到的权衡表面上均匀分布,个体的适应度应包含收敛性和多样性的信息。本文考虑了三个基于网格的标准来分配个体的适应度,它们是==网格排名(GR)、网格拥挤距离(GCD)和网格坐标点距离(GCPD)==。第一和最后一个标准用来评估个体的收敛性,而中间的标准关注的是群体中个体的多样性。

图3:适应度分配的示例。括号中的数字与每个解决方案的GR和GCD对应。
GR是一个收敛估计器,根据个体在网格位置上的排名来对其进行排序。对于每个个体,GR定义为其在每个目标上的网格坐标的总和:

其中,G k (x)表示个体x在第k个目标上的网格坐标,M是目标的数量。
网格排名(GR)可以被视为单一目标两个解之间的值差异和一种解优于另一种解的目标数量之间的自然权衡。一方面,如果一个个体在大多数目标上的表现优于其竞争者,它就有更大的可能性获得较低的GR值。另一方面,单一目标中的差异也是影响GR值的重要部分。例如,考虑图3中的个体C和A,C会获得比A更差的GR值(6对4),因为在f2中的优势小于在f1中的劣势。
请注意,GR的行为与多目标问题的帕累托前沿形状密切相关。例如,当形状为凸形时,位于帕累托前沿中心附近的个体具有良好的评估,当形状为凹形时,位于帕累托前沿边缘的个体更为优选。这可能会驱动种群向帕累托前沿的某个区域,如帕累托前沿的膝部移动。在我们的研究中,将引入一种GR调整策略,以在环境选择过程中处理这个问题。
解决方案的密度估计在适应度分配过程中是一个重要环节,因为一组分布良好的解决方案将在驱动搜索朝向整个帕累托前沿方向上起关键作用。然而,现有的基于网格的密度估计器,它们记录了占据单个超立方体的解决方案的数量,可能由于随着目标数量的指数增长而导致超立方体数量的增加,而无法揭示它们的分布情况。在此,我们扩大了被考虑的区域范围,并引入了解决方案的邻居的概念。如果GD(x, y) < M,那么解决方案y被视为解决方案x的邻居,其中GD(x, y)表示x和y之间的网格差异,M是目标的数量。GrEA考虑了解决方案的邻居的分布对其密度估计的影响。具体来说,x的密度估计器,即GCD,定义如下:

这里,N(x)表示个体x的邻居集合。例如,在图3中,个体G的邻居是E和F,而G的GCD为3,即(2-1)+(2-0)=3。
显然,一个解的GCD既取决于邻域范围(即,其他解被视为其邻居的区域)也取决于它与其他解之间的网格差异。一方面,更大的邻域范围通常包含更多的解,因此有助于提高GCD值。请注意,邻域范围由M决定。随着目标数量的增加,被考虑的超立方体的数量将逐渐增加,这将与网格环境中超立方体的总数保持一致,从而明确区分个体间的拥挤程度。另一方面,由于涉及到网格差异度量,GCD也显示了解在邻域中的位置信息。邻居位置越远,对GCD的贡献就越小。例如,考虑图3中的个体C和F,尽管它们的邻居数量完全相等,但C的GCD小于F的(2对3)。
尽管GR和GCD已经在收敛性和多样性方面为个体提供了良好的度量,但它们可能仍然无法区分个体。由于他们的计算基于个体的网格坐标,因此GR和GCD都有一个整数值,这意味着一些个体可能具有相同的GR和GCD值,例如,图3中的个体B和D。在此,受到ǫ-MOEA[15]策略的启发,我们计算个体与其超立方体中的乌托邦点(即,其超立方体的最佳角点)之间的归一化欧几里得距离,称为GCPD,如下所示:

其中,Gk(x) 和 Fk(x) 分别表示第k个目标中个体x的网格坐标和实际目标值,lbk 和 dk 分别代表第k个目标的网格的下界和超立方体的宽度,M是目标的数量。显然,较低的GCPD是优先的。图3中的个体F和G也说明了这一准则。
交配选择
配对选择旨在为交换个体信息做好准备,在EMO算法中起到重要作用。它通常通过从当前种群中选择有前景的解决方案来形成配对池。在这里,我们使用一种基于优势关系和密度信息的二元锦标赛选择策略来挑选变异的个体。

算法2详细描述了这种策略。
首先,随机从种群中选择两个个体。如果一个Pareto(帕累托前沿)或网格主导另一个,那么选择前者。否则,这表明这两个解决方案在Pareto优势和网格优势关系方面都不对彼此占优。
在这种情况下,我们更倾向于具有较低密度估计值(即,GCD)的解决方案。最后,如果GCD仍然无法区分这两个解决方案,那么将随机分配平局。
环境选择
环境选择的目标是从先前的种群和新创建的种群中挑选出“最佳”解决方案,以获得一个近似好且分布均匀的存档集。执行选择的一种直接方法是基于解决方案的适应性。然而,这种方式的一个缺点是它可能导致多样性的丧失,因为相邻的解决方案通常具有相似的适应值。例如,图3中的解决方案E、F和G具有相似的适应值,因此它们被同时淘汰或保留的可能性很高。在此,我们引入了一个适应性调整机制来解决这个问题。
1) 适应性调整:
GrEA通过根据三个适应性标准(GR、GCD和GCPD)层次比较个体来选择个体。GR是主要标准,当个体的GR值不可比较(即相等)时,GCD被视为次要标准,当前两个标准无法区分个体时,第三个标准GCPD被用来打破平局。在这里,我们将调整的重点放在主要标准上。
GR>GCD>GCPD
当一个个体被选入存档时,其“相关”个体的GR值将受到惩罚。为了在存档中实现收敛性和多样性之间的良好平衡,需要考虑几个关键因素。
- 对与选定个体具有相同网格坐标的个体应施加严厉的惩罚
- 对于被选定个体控制的个体,应比未被其控制的个体受到更严重的惩罚。例如,考虑一组个体A、B和C,它们的网格坐标分别为(0,3)、(0,5)和(5,0)。显然,当A已经进入存档后,C比B更可取,因为C有助于朝不同的方向进化。
- 为了进一步防止拥挤,应对选定个体的邻居进行惩罚,并且惩罚程度应随着它们与选定个体之间的距离减小而降低。
- 在对选定个体的邻居实施惩罚时,可能也需要对它们网格支配的个体进行惩罚。例如,对于一组四个个体A(0,0,1),B(0,1,0),C(1,0,0)和D(3,0,0),假设需要选择三个个体进入存档。显然,最好的选择是消除最后一个个体D。然而,当A和B已经在存档中后,C可能无法被选中,因为C作为A和B的邻居受到了惩罚,导致C的GR值比D差。因此,对选定个体的邻居所网格支配的个体进行惩罚是可取的,这可以大大提高存档集的收敛性。

考虑到以上因素,我们在算法3中提出了一种GR调整程序。显然,个体在GR调整过程中可以被分为三组:
其网格坐标等于选定个体的个体(行1-3),
被选定个体网格支配的个体(行4-6),
以及既未被选定个体网格支配且其网格坐标与选定个体不同的个体(行7-22)。
它们对应的惩罚度分别为M+2、M和**[0, M-1]范围内,其中M**表示目标的数量。
具体地,对于最后一组中的个体,被选定个体q的邻居p被赋予至少M-GD(p,q)的惩罚度(行11和12),
相应地,被p网格支配的个体被赋予的惩罚度大于或等于p的惩罚度(行13-17)。
这可以防止个体在网格支配关系方面早于其更优的竞争者被存档。
总的来说,通过适应度调整操作,GR不会被视作一个简单的收敛指标,而是被视为存档集中个体的邻近性、密度和演化方向信息的结合。接下来,我们将给出环境选择的主要程序。
2) 主要过程:
算法4显示了环境选择的主要过程。类似于NSGA-II [11],GrEA考虑了候选集中的关键Pareto非支配面。使用快速非支配排序方法,将候选解决方案划分为不同的前沿(F1 ,F2 ,…,Fi ,…)。找到关键前沿F i (|F 1 ∪F 2 ∪…∪F i−1 | ≤ N 和 |F 1 ∪ F 2 ∪ … ∪ F i−1 ∪ F i | > N,其中N表示存档大小),相应地,将前(i − 1)个非支配前沿(F 1 ,F 2 ,…,F i−1 )移入存档(行2-6)。实际上,由于多目标问题中的解决方案彼此是Pareto非支配的,所以关键前沿通常是第一个前沿,即 i = 1。

在算法4中,函数初始化(行8)用于初始化网格环境集中个体的信息(行7)。个体关于收敛性(即,GR和GCPD)的适应度通过等式(9)和(11)计算。需要指出的是,在函数中,个体的初始密度值(即GCD)被赋值为零。与可以通过个体自身的位置直接计算的收敛估计器不同,多样性需要通过与其他个体的关系来估计。在候选集中而非存档集中考虑个体的拥挤关系可能没有意义,因为后者才是需要保存的群体。在这里,GrEA通过计算其在存档中的拥挤度来估计个体的密度(行13)。算法5和6分别给出了函数初始化和GCD计算的伪代码。
算法4中的函数Findout best(第10行)的设计目的是找出被考虑的前沿中的最佳个体。伪代码显示在算法7中。如前所述,该函数层次比较三个标准GR、GCD和GCPD。在所有标准中,较低的值更为可取。
- 非支配排序,得到不同的前沿面
- 在最后一层前沿面上,使用网格选择方法选择个体
- 生成下一代种群
本文的补充文件中给出了一个示例,以说明整个环境选择过程的工作原理。这个补充文件没找到

GrEA
classdef GrEA < ALGORITHM
% <many> <real/integer/label/binary/permutation>
% Grid-based evolutionary algorithm
% div --- --- The number of divisions in each objective
%------------------------------- Reference --------------------------------
% S. Yang, M. Li, X. Liu, and J. Zheng, A grid-based evolutionary algorithm
% for many-objective optimization, IEEE Transactions on Evolutionary
% Computation, 2013, 17(5): 721-736.
%------------------------------- Copyright --------------------------------
% Copyright (c) 2023 BIMK Group. You are free to use the PlatEMO for
% research purposes. All publications which use this platform or any code
% in the platform should acknowledge the use of "PlatEMO" and reference "Ye
% Tian, Ran Cheng, Xingyi Zhang, and Yaochu Jin, PlatEMO: A MATLAB platform
% for evolutionary multi-objective optimization [educational forum], IEEE
% Computational Intelligence Magazine, 2017, 12(4): 73-87".
%--------------------------------------------------------------------------
methods
function main(Algorithm,Problem)
%% Parameter setting
Div = [0 45 15 10 9 9 8 8 10 12];
div = Algorithm.ParameterSet(Div(min(Problem.M,10)));
%% Generate random population
Population = Problem.Initialization();
%% Optimization
while Algorithm.NotTerminated(Population)
MatingPool = MatingSelection(Population.objs,div);
Offspring = OperatorGA(Problem,Population(MatingPool));
Population = EnvironmentalSelection([Population,Offspring],Problem.N,div);
end
end
end
end
MatingSelection
function MatingPool = MatingSelection(PopObj,div)
% The mating selection of GrEA
%------------------------------- Copyright --------------------------------
% Copyright (c) 2023 BIMK Group. You are free to use the PlatEMO for
% research purposes. All publications which use this platform or any code
% in the platform should acknowledge the use of "PlatEMO" and reference "Ye
% Tian, Ran Cheng, Xingyi Zhang, and Yaochu Jin, PlatEMO: A MATLAB platform
% for evolutionary multi-objective optimization [educational forum], IEEE
% Computational Intelligence Magazine, 2017, 12(4): 73-87".
%--------------------------------------------------------------------------
N = size(PopObj,1);
%% Calculate the grid location of each solution
fmax = max(PopObj,[],1);
fmin = min(PopObj,[],1);
lb = fmin-(fmax-fmin)/2/div;
ub = fmax+(fmax-fmin)/2/div;
d = (ub-lb)/div;
lb = repmat(lb,N,1);
d = repmat(d,N,1);
GLoc = floor((PopObj-lb)./d);
GLoc(isnan(GLoc)) = 0;
%% Calculate the GD value of each solution
GD = zeros(N)+inf;
for i = 1 : N-1
for j = i+1 : N
GD(i,j) = sum(abs(GLoc(i,:)-GLoc(j,:)));
GD(j,i) = GD(i,j);
end
end
%% Calculate the GCD value of each solution
GD = max(size(PopObj,2)-GD,0);
GCD = sum(GD,2);
%% Binary tournament selection
Parents1 = randi(N,1,N);
Parents2 = randi(N,1,N);
Dominate = any(PopObj(Parents1,:)<PopObj(Parents2,:),2) - any(PopObj(Parents1,:)>PopObj(Parents2,:),2);
GDominate = any(GLoc(Parents1,:)<GLoc(Parents2,:),2) - any(GLoc(Parents1,:)>GLoc(Parents2,:),2);
MatingPool = [Parents1(Dominate==1 | GDominate==1),...
Parents2(Dominate==-1 | GDominate==-1),...
Parents1(Dominate==0 & GDominate==0 & GCD(Parents1)<=GCD(Parents2)),...
Parents2(Dominate==0 & GDominate==0 & GCD(Parents1)>GCD(Parents2))];
end
EnvironmentalSelection
function Population = EnvironmentalSelection(Population,N,div)
% The environmental selection of GrEA
%------------------------------- Copyright --------------------------------
% Copyright (c) 2023 BIMK Group. You are free to use the PlatEMO for
% research purposes. All publications which use this platform or any code
% in the platform should acknowledge the use of "PlatEMO" and reference "Ye
% Tian, Ran Cheng, Xingyi Zhang, and Yaochu Jin, PlatEMO: A MATLAB platform
% for evolutionary multi-objective optimization [educational forum], IEEE
% Computational Intelligence Magazine, 2017, 12(4): 73-87".
%--------------------------------------------------------------------------
%% Non-dominated sorting
[FrontNo,MaxFNo] = NDSort(Population.objs,N);
Next = FrontNo < MaxFNo;
%% Select the solutions in the last front
Last = find(FrontNo==MaxFNo);
Choose = LastSelection(Population(Last).objs,N-sum(Next),div);
Next(Last(Choose)) = true;
% Population for next generation
Population = Population(Next);
end
function Choose = LastSelection(PopObj,K,div)
% Select part of the solutions in one front by the grid
[N,M] = size(PopObj);
%% Calculate the grid location of each solution
fmax = max(PopObj,[],1);
fmin = min(PopObj,[],1);
lb = fmin-(fmax-fmin)/2/div;
ub = fmax+(fmax-fmin)/2/div;
d = (ub-lb)/div;
lb = repmat(lb,N,1);
d = repmat(d,N,1);
GLoc = floor((PopObj-lb)./d);
GLoc(isnan(GLoc)) = 0;
%% Calculate GR, GCD, GCPD and GD values of each solution
GR = sum(GLoc,2);
GCD = zeros(1,N);
GCPD = sqrt(sum(((PopObj-(lb+GLoc.*d))./d).^2,2));
GD = inf(N);
for i = 1 : N-1
for j = i+1 : N
GD(i,j) = sum(abs(GLoc(i,:)-GLoc(j,:)));
GD(j,i) = GD(i,j);
end
end
%% Detect the grid-based dominance relation of each two solutions
G = false(N);
for i = 1 : N-1
for j = i+1 : N
k = any(GLoc(i,:)<GLoc(j,:))-any(GLoc(i,:)>GLoc(j,:));
if k == 1
G(i,j) = true;
elseif k == -1
G(j,i) = true;
end
end
end
%% Environmental selection
Remain = true(1,N);
while sum(Remain) > N-K
% Choose the best one among the remaining solutions in the front
CanBeChoose = find(Remain);
temp = find(GR(CanBeChoose)==min(GR(CanBeChoose)));
temp2 = find(GCD(CanBeChoose(temp))==min(GCD(CanBeChoose(temp))));
[~,q] = min(GCPD(CanBeChoose(temp(temp2))));
q = CanBeChoose(temp(temp2(q)));
Remain(q) = false;
% Update the GCD values
GCD = GCD+max(M-GD(q,:),0);
% Update the GR values
Eq = GD(q,:)==0 & Remain;
Gq = G(q,:) & Remain;
NGq = Remain.*(1-Gq);
Nq = GD(q,:)<M & Remain;
GR(Eq) = GR(Eq) + M+2;
GR(Gq) = GR(Gq) + M;
PD = zeros(N,1);
for p = find((Nq.*NGq).*(1-Eq))
if PD(p) < M-GD(q,p)
PD(p) = M - GD(q,p);
Gp = G(p,:) & Remain;
for r = find(Gp.*(1-(Gq+Eq)))
if PD(r) < PD(p)
PD(r) = PD(p);
end
end
end
end
pp = logical(NGq.*(1-Eq));
GR(pp) = GR(pp) + PD(pp);
end
Choose = ~Remain;
end
参考文献
https://ieeexplore.ieee.org/document/6400243
M. Li, J. Zheng, R. Shen, K. Li, and Q. Yuan, “A grid-based fitness
strategy for evolutionary many-objective optimization,” in Proc. 12th
Annu. Conf. Genetic Evol. Comput., 2010, pp. 463–470.
代码来自田野教授PlatEMO 4.2

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









