







 HCFormer是一种新的图像分割方法,采用自下而上的分层聚类策略,简化了架构设计并提高了可解释性。这种方法适用于语义、实例和全景分割,通过注意力机制实现像素聚类,并且可以被可视化和评估。与传统的神经网络分割方法相比,HCFormer在保持或提高分割精度的同时,提供了更好的可解释性。
HCFormer是一种新的图像分割方法,采用自下而上的分层聚类策略,简化了架构设计并提高了可解释性。这种方法适用于语义、实例和全景分割,通过注意力机制实现像素聚类,并且可以被可视化和评估。与传统的神经网络分割方法相比,HCFormer在保持或提高分割精度的同时,提供了更好的可解释性。
题目:HCFormer: 具有层次聚类的统一图像分割
Abstract
分层聚类是一种有效有效的方法,广泛用于经典图像分割方法。但是,许多使用神经网络的现有方法直接从每个像素特征生成分割掩模,这使体系结构设计复杂化并降低了可解释性。在这项工作中,我们提出了一种更简单,更可解释的体系结构,称为HCFormer。HCFormer通过自下而上的分层聚类来完成图像分割,并使我们能够将中间结果解释,可视化和评估为分层聚类结果。HCFormer可以使用相同的体系结构来解决语义,实例和全景分割,因为像素聚类是各种图像分割任务的通用方法。在实验中,与语义分割 (ad20k上的55.5 mIoU) 、实例分割 (COCO上的47.1 AP) 和泛光分割 (COCO上的55.7 PQ) 的基线方法相比,HCFormer实现了相当或更高的分割精度。
1. Introduction
最近提出的图像分割方法基本上建立在神经网络上,包括卷积神经网络 [39] 和变压器 [17,58],并直接从每个像素特征生成分割掩模。但是,经典的图像分割方法通常使用分层方法 (例如,分层聚类) [13,18,48,56,68],并且分层策略提高了分割精度和计算效率。尽管如此,基于神经网络的方法并未采用分层方法,这会使体系结构设计复杂化并降低可解释性。因此,我们从层次聚类的角度研究了更简单,更可解释的图像分割管道。
通常,使用神经网络的分割模型包括三个部分 :( i) 从原始像素中提取有意义的特征的骨干模型,(ii) 像素解码器恢复主干中丢失的空间分辨率,以及 (iii) 分段头,该分段头通过分类器或查询 (或内核) 和特征图之间的交叉注意 (或互相关) 生成分段掩码。与其他方法不同,像素解码器是固有的不必要模块来进行图像分割; 实际上,某些方法不采用它 [7,39,72]。尽管如此,像素解码器仍用于许多分割模型中,因为模型需要每个像素的特征来生成高分辨率掩模。问题在于解码是在高维特征空间中执行的,高维使得解码过程难以解释、可视化和评估,这是导致分割模型可解释性降低的原因之一。
我们建立了基于层次聚类策略的细分模型。用于图像分割的聚类是对具有相同语义或基本真相标签的像素进行分组。如果聚类为每个聚类分配一个代表值 (例如,代表聚类的类标签或特征向量),我们可以将其视为降采样的特例。特别是,如果基于固定窗口对元素进行分组,并且从每个组中采样一个代表值,则它与降采样方案相同。从这个角度来看,我们在分割头之前没有像素解码器即可完成图像分割。如果我们构建主干模型,使其下采样层对像素和样本代表值进行分组,图像分割可以以分层聚类的方式完成,如图1所示。该框架简化了架构设计,并允许我们将中间结果解释、可视化和评估为聚类结果。允许可视化和评估增强了细分模型的可解释性,即人类可以理解决策原因的程度 [43]。
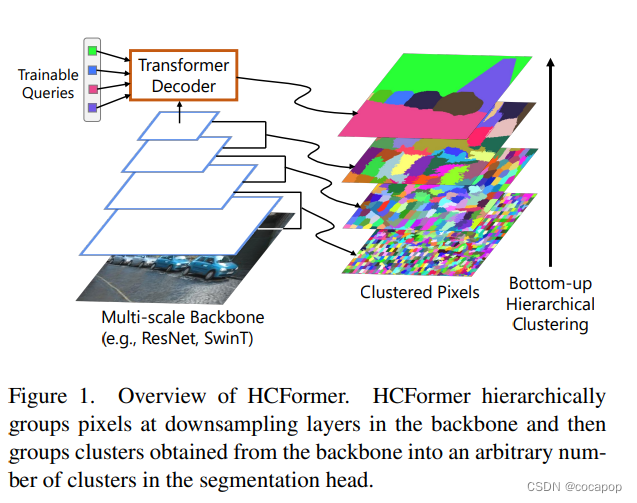
图1。HCFormer概述。HCFormer对主干中下采样层的像素进行分层分组,然后将从主干获得的群集分组为分段头中的任意数量的群集。
为了完成深度神经网络中的分层聚类,我们提出了一个使用注意力函数 [58] 作为分配求解器的聚类模块,以及一个使用该模块的模型,称为HCFormer。HCFormer通过聚类模块对下采样层的像素进行分组,并通过分层聚类实现图像分割,如图1所示。我们专注地设计聚类模块,以便与现有的主干模型 (例如,ResNet [20] 和Swin Transformer [38]) 相结合。结果,可以将分层聚类方案合并到现有的骨干模型中,而无需更改其前馈路径。
HCFormer通过分配矩阵之间的矩阵乘法生成分割掩模,并且可以通过一些用于评估像素聚类方法的度量来评估此解码过程的准确性,例如超像素分割 [51]。这些属性可以进行错误分析,并提供一些体系结构级别的见解,以提高细分精度,尽管人们可能无法理解为什么做出了某些决定或预测。例如,当HCFormer中的某个聚类级别发生错误时,至少我们知道原因存在于主干中相应的下采样层之前的层中。因此,我们可以通过将层或模块添加到主干中的相关阶段来解决错误。相反,传统模型很难评估解码精度,因为像素解码器在高维特征空间中对像素进行上采样,并且中间结果与基本真相标签不具有可比性。我们相信,即使不是一大步,我们的分层聚类也将细分模型的可解释性向前迈出了一步。
由于聚类是各种图像分割任务的常用方法,因此它可以在同一体系结构中处理许多分割任务。因此,我们评估HCFormer的三个主要分割任务: 语义分割 (ADE20K [73] 和Cityscapes [12]),实例分割 (COCO [37]) 和泛光分割 (COCO [37])。与最近提出的统一分割模型 (例如MaskFormer [11],Mask2Former [10] 和K-Net [71]) 和每个任务的专用模型 (例如Mask r-cnn [19],SOLOv2 [61] 、SegFormer [63] 、CMT-Deeplab [70] 和泛光FCN [32]。
2. Method
我们通过为下采样层提供聚类属性来实现深度神经网络中的分层聚类。我们可以通过对像素进行聚类,然后从获得的聚类中采样代表值,而不是传统的下采样来做到这一点。但是,所获得的群集通常不会形成规则的网格结构,并且基于CNN的主干不允许输入这样的不规则网格数据。因此,简单的方法 (例如聚类后的降采样) 不适用。
为了在保留数据结构的同时将聚类过程合并到现有的骨干模型中,我们提出了一种降采样后的聚类策略。我们在图2中展示了我们的聚类和解码管道。我们假设现有骨干模型中使用的降采样是聚类原型采样。因此,我们将下采样后的特征图中的像素视为集群原型,并将下采样前的特征图中的像素分组。我们首先展示了这个聚类过程可以通过2.1中的注意力 [58] 来实现。然后,我们在Sec2.2中制定了基于注意力的聚类模块。最后,我们在Sec2.3中描述了我们的解码过程在。
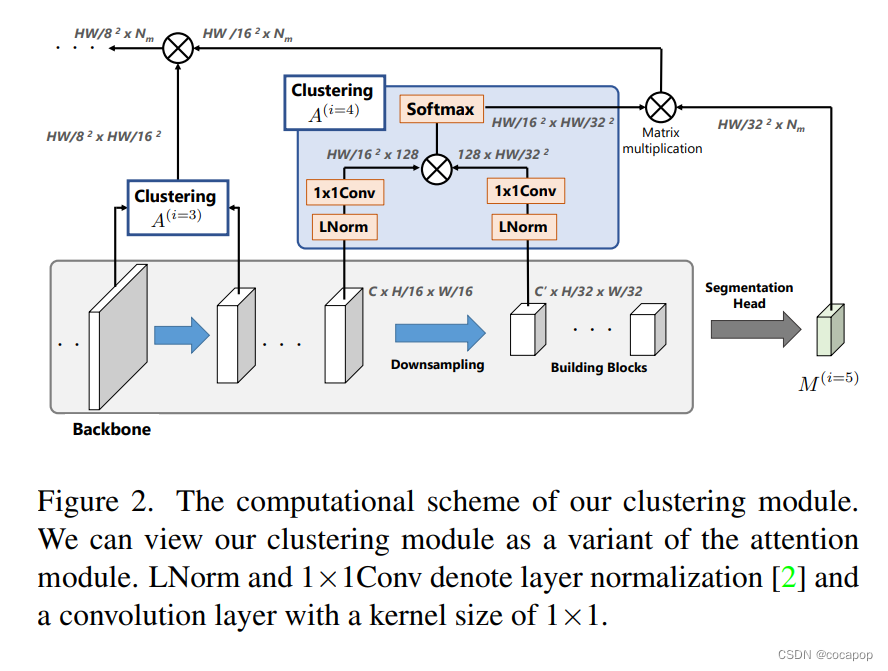
图2。我们的聚类模块的计算方案。我们可以将我们的聚类模块视为注意力模块的变体。LNorm和1 × 1Conv表示层归一化 [2] 和内核大小为1 × 1的卷积层。
【ps. 2.1为聚类过程可以在注意力中实现 2.2为制定了基于注意力的聚类模块 2.3为解码过程】
2.1. Clustering as Attention 作为注意力的聚类
我们从聚类的角度看待注意力函数 [58]。令q ∈ rc × nq和k ∈ rc × nk是一个查询和一个键。Nq和Nk是查询和密钥的令牌数量,C表示特征维度。那么,Attention定义如下:

其中,T 表示矩阵的转置,s表示通常定义为 √ C的比例参数 [17,58]。Softmaxrow(·) 表示逐行softmax函数。注意力函数一般用查询、键和值来定义,但为了简单起见,这里省略了该值。当s → 0时,等式(1) 等价于以下最大化问题:
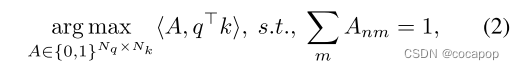
其中 <`,`>·表示Frobenius内积。我们在附录A中提供了详细的推导。此最大化问题被解释为q的聚类问题,其中k为聚类原型。以内积作为相似性函数,如果第n个查询qn与所有密钥令牌中的第m个密钥km具有最大相似性,则Anm = 1; 否则,Anm = 0。换句话说,A的每一行指示分配给qn的群集的索引,称为分配矩阵。因此,等式(2) 是一个赋值问题,它是特殊情况或聚类的一部分 (例如,具有一级和一步K-means聚类的分层级的聚集级分层聚类),并且在等式(1) 中attention解决了方程(2)的松弛问题。这种见解表明,我们可以通过将降采样前后的特征图中的像素分别对应到查询和键,以可区分的形式使用注意力来完成降采样后的聚类。
2.2 分层聚类图像分割
我们在图2中展示了所提出的聚类模块的计算方案。我们从用于聚类的骨干模型中获得了中间特征图及其下采样特征图。这些被馈送到层归一化 [2] 和内核大小为1 × 1的卷积层中,如变压器块 [17,58]。我们将获得的特征图定义为F(i) ∈ Rcf × N(i) 和F(i) d ∈ rcf × N(i) d,其中i ∈ N表示空间分辨率的降采样因子,该降采样因子对应于应用的降采样层数,N(i) 和N(i) d表示下采样前后特征图中的像素数 (即N(i) = H/2i W/2i和N(i) d = H /2i 1 W /2i+1,其中H和W是输入图像的高度和宽度)。CF是在我们的实验中设置为128的通道数。请注意,我们假设下采样的两半高度和宽度分别,以及每个像素的特征向量的 l2范数被归一化为1,以使内积具有余弦相似性。
然后,建议的聚类定义如下:
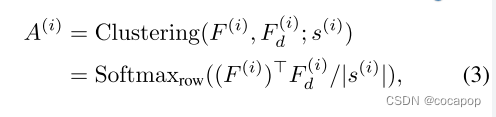
其中A(i) ∈ (0,1) N(i)× N(i) d是赋值矩阵。我们将比例参数s(i) ∈ R定义为可训练参数。正如已经在第二节2.1中描述的那样,当s(i) → 0时,等式(3) 对应于以F(i) d为聚类原型的F(i) 的聚类问题。因此,通过计算等式(3) 在每个下采样层,HCformer对像素进行分层分组,如图1所示。
从骨干模型获得的特征图被馈送到 [11] 中使用的分割头 (图4)。具体地,特征图被馈送到具有可训练查询Q ∈ Rcq × nm的变压器解码器中,并且掩码查询Emask ∈ Rcm × nm被生成。查询数量Nm是一个超参数。请注意,变压器 “解码器” 不同于像素解码器,因为它的作用之一是生成掩码查询,而不是对特征图进行上采样。特征图也通过线性层映射到cm维空间中,我们将它们定义为E(i = 5) 特征 ∈ rcm × n (i)。然后,分段头的输出计算如下:
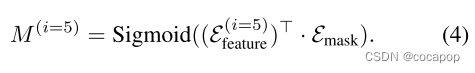
请注意,我们假设比例i为5,因为常规主干具有五个下采样层。该分割头可以看作是聚类,将特征图中的N(i) 个像素分组为Nm聚类。2因此,我们也将M(i = 5) 称为分配矩阵。与以前的工作 [11] 不同,我们将低分辨率的特征图输入到分割头 (公式 (4)) 中,这有助于减少分割头中的翻牌。
2.3. Decoding 解码
作为HCFormer的输出,我们获得从主干获得的赋值矩阵 {A(i)}i和分段头M(5) 的输出。我们需要将它们解码为输入图像的分割掩模以进行评估。
解码过程的一个步骤定义为a (i) 和M(i 1) 之间的矩阵乘法:
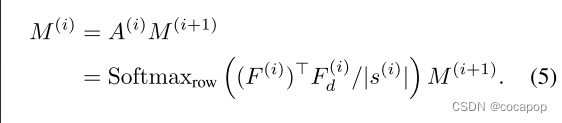
通过在A(i) 中明确写下计算,我们可以注意到它等效于注意函数 [58],尽管查询,键和值是从不同的层获得的。通过将所有 {A(i)}i乘以M(5) 作为 i A(i)M(5) 来计算分割掩码 (即,输入图像中的像素与掩码查询之间的对应关系)。
从硬聚类的角度来看,等式(2),我们可以将A(i) 乘以为将群集的代表值复制到其元素。因此,如果每个簇由用相同的地面真相标签注释的像素组成,则此解码过程将是准确的。换句话说,我们可以通过用于评估超像素分割的分割误差 [51] 从硬聚类的角度评估解码的准确性。
2.4. Efficient Computation高效计算
令N为像素数,然后提出的聚类的计算成本为O(N2),这与公共注意函数 [58] 的复杂度相同,并且对于高分辨率图像而言是难以解决的。关于降低复杂性的各种研究 [4,38,47,50,57,60,65],我们采用局部关注策略来解决。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









