







1. parser.add_argument
① 像运行Tensorboar一样,在Terminal终端,可以命令运行.py文件。
② 如下图所示,Terminal终端运行.py文件时,--变量 后面的值是给变量进行赋值,赋值后再在.py文件中运行。例如 ./datasets/maps 是给前面的dataroot赋值,maps_cyclegan是给前面的name赋值,cycle_gan是给前面的model赋值。
③ required表示必须需要指定参数,default表示有默认的参数了。Terminal终端命令语句,如果不对该默认变量新写入,直接调用默认的参数;如果对该默认变量新写入,则默认的参数被新写入的参数覆盖。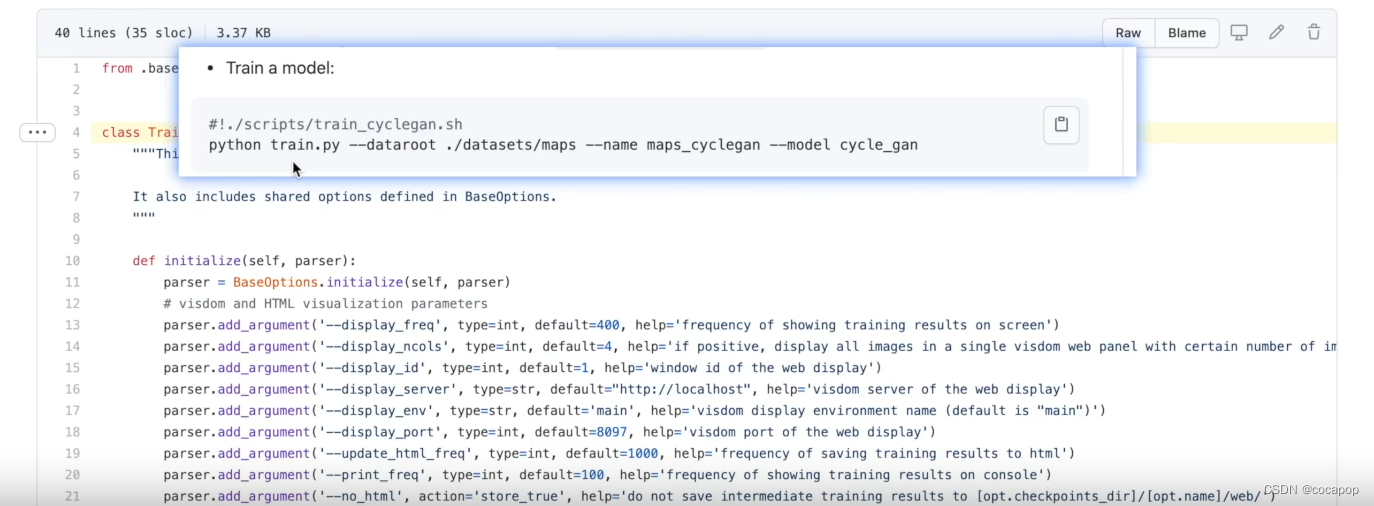
1. 利用GPU训练(方式一)
① GPU训练主要有三部分,网络模型、数据(输入、标注)、损失函数,这三部分放到GPU上。
import torchvision
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# from model import * 相当于把 model中的所有内容写到这里,这里直接把 model 写在这里
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3,32,5,1,2), # 输入通道3,输出通道32,卷积核尺寸5×5,步长1,填充2
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(), # 展平后变成 64*4*4 了
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,则打印:训练数据集的长度为:10
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
# 利用 Dataloader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
if torch.cuda.is_available():
tudui = tudui.cuda() # 网络模型转移到cuda上
# 损失函数
loss_fn = nn.CrossEntropyLoss() # 交叉熵,fn 是 fuction 的缩写
if torch.cuda.is_available():
loss_fn = loss_fn.cuda() # 损失函数转移到cuda上
# 优化器
learning = 0.01 # 1e-2 就是 0.01 的意思
optimizer = torch.optim.SGD(tudui.parameters(),learning) # 随机梯度下降优化器
# 设置网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮次
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("logs")
for i in range(epoch):
print("-----第 {} 轮训练开始-----".format(i+1))
# 训练步骤开始
tudui.train() # 当网络中有dropout层、batchnorm层时,这些层能起作用
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda() # 数据放到cuda上
targets = targets.cuda() # 数据放到cuda上
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 计算实际输出与目标输出的差距
# 优化器对模型调优
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播,计算损失函数的梯度
optimizer.step() # 根据梯度,对网络的参数进行调优
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step,loss.item())) # 方式二:获得loss值
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始(每一轮训练后都查看在测试数据集上的loss情况)
tudui.eval() # 当网络中有dropout层、batchnorm层时,这些层不能起作用
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 没有梯度了
for data in test_dataloader: # 测试数据集提取数据
imgs, targets = data # 数据放到cuda上
if torch.cuda.is_available():
imgs = imgs.cuda() # 数据放到cuda上
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 仅data数据在网络模型上的损失
total_test_loss = total_test_loss + loss.item() # 所有loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "./model/tudui_{}.pth".format(i)) # 保存每一轮训练后的结果
#torch.save(tudui.state_dict(),"tudui_{}.path".format(i)) # 保存方式二
print("模型已保存")
writer.close()
'''
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度:50000
测试数据集的长度:10000
-----第 1 轮训练开始-----
训练次数:100,Loss:2.289992094039917
训练次数:200,Loss:2.2927844524383545
训练次数:300,Loss:2.2730984687805176
训练次数:400,Loss:2.2006278038024902
训练次数:500,Loss:2.1675028800964355
训练次数:600,Loss:2.116072416305542
训练次数:700,Loss:2.04477596282959
整体测试集上的Loss:317.0560564994812
整体测试集上的正确率:0.28700000047683716
模型已保存
-----第 2 轮训练开始-----
训练次数:800,Loss:1.893830418586731
训练次数:900,Loss:1.8772207498550415
训练次数:1000,Loss:1.9800275564193726
训练次数:1100,Loss:2.007078170776367
训练次数:1200,Loss:1.7352533340454102
训练次数:1300,Loss:1.6947956085205078
训练次数:1400,Loss:1.756855845451355
训练次数:1500,Loss:1.8372352123260498
整体测试集上的Loss:299.94190883636475
整体测试集上的正确率:0.31619998812675476
模型已保存
-----第 3 轮训练开始-----
训练次数:1600,Loss:1.7673416137695312
训练次数:1700,Loss:1.6654351949691772
训练次数:1800,Loss:1.9246405363082886
训练次数:1900,Loss:1.7132933139801025
训练次数:2000,Loss:1.93990159034729
训练次数:2100,Loss:1.4903961420059204
训练次数:2200,Loss:1.4754142761230469
训练次数:2300,Loss:1.7652970552444458
整体测试集上的Loss:272.9526561498642
整体测试集上的正确率:0.37139999866485596
模型已保存
-----第 4 轮训练开始-----
训练次数:2400,Loss:1.7254819869995117
训练次数:2500,Loss:1.3386430740356445
训练次数:2600,Loss:1.5852587223052979
训练次数:2700,Loss:1.648303508758545
训练次数:2800,Loss:1.4971883296966553
训练次数:2900,Loss:1.5891362428665161
训练次数:3000,Loss:1.3380193710327148
训练次数:3100,Loss:1.542701005935669
整体测试集上的Loss:278.19843327999115
整体测试集上的正确率:0.36139997839927673
模型已保存
-----第 5 轮训练开始-----
训练次数:3200,Loss:1.3419318199157715
训练次数:3300,Loss:1.468044400215149
训练次数:3400,Loss:1.484485149383545
训练次数:3500,Loss:1.54210364818573
训练次数:3600,Loss:1.5797978639602661
训练次数:3700,Loss:1.3390973806381226
训练次数:3800,Loss:1.3077597618103027
训练次数:3900,Loss:1.4766919612884521
整体测试集上的Loss:269.36583971977234
整体测试集上的正确率:0.3871999979019165
模型已保存
-----第 6 轮训练开始-----
训练次数:4000,Loss:1.439847469329834
训练次数:4100,Loss:1.436941146850586
训练次数:4200,Loss:1.5766061544418335
训练次数:4300,Loss:1.249019742012024
训练次数:4400,Loss:1.164270281791687
训练次数:4500,Loss:1.4175126552581787
训练次数:4600,Loss:1.4056789875030518
整体测试集上的Loss:252.13275730609894
整体测试集上的正确率:0.4244000017642975
模型已保存
-----第 7 轮训练开始-----
训练次数:4700,Loss:1.3679763078689575
训练次数:4800,Loss:1.526027798652649
训练次数:4900,Loss:1.3590809106826782
训练次数:5000,Loss:1.4296003580093384
训练次数:5100,Loss:0.9916519522666931
训练次数:5200,Loss:1.3147145509719849
训练次数:5300,Loss:1.2122020721435547
训练次数:5400,Loss:1.3860883712768555
整体测试集上的Loss:235.14292180538177
整体测试集上的正确率:0.46209999918937683
模型已保存
-----第 8 轮训练开始-----
训练次数:5500,Loss:1.2311736345291138
训练次数:5600,Loss:1.2175472974777222
训练次数:5700,Loss:1.2189043760299683
训练次数:5800,Loss:1.2750414609909058
训练次数:5900,Loss:1.3556095361709595
训练次数:6000,Loss:1.5370352268218994
训练次数:6100,Loss:1.025504231452942
训练次数:6200,Loss:1.0661875009536743
整体测试集上的Loss:222.47956597805023
整体测试集上的正确率:0.4927999973297119
模型已保存
-----第 9 轮训练开始-----
训练次数:6300,Loss:1.4051152467727661
训练次数:6400,Loss:1.1392022371292114
训练次数:6500,Loss:1.6226587295532227
训练次数:6600,Loss:1.0815491676330566
训练次数:6700,Loss:1.048026442527771
训练次数:6800,Loss:1.1510660648345947
训练次数:6900,Loss:1.1476961374282837
训练次数:7000,Loss:0.9481611847877502
整体测试集上的Loss:212.00453734397888
整体测试集上的正确率:0.5181999802589417
模型已保存
-----第 10 轮训练开始-----
训练次数:7100,Loss:1.2802095413208008
训练次数:7200,Loss:0.9643581509590149
训练次数:7300,Loss:1.098695993423462
训练次数:7400,Loss:0.8831453323364258
训练次数:7500,Loss:1.19520902633667
训练次数:7600,Loss:1.2724679708480835
训练次数:7700,Loss:0.8894400000572205
训练次数:7800,Loss:1.205102801322937
整体测试集上的Loss:202.72463756799698
整体测试集上的正确率:0.54339998960495
模型已保存
'''2. GPU训练时间
start_time = time.time()
end_time = time.time()
if total_train_step % 100 == 0:
print(end_time - start_time) # 运行训练一百次后的时间间隔
import torchvision
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
# from model import * 相当于把 model中的所有内容写到这里,这里直接把 model 写在这里
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3,32,5,1,2), # 输入通道3,输出通道32,卷积核尺寸5×5,步长1,填充2
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(), # 展平后变成 64*4*4 了
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,则打印:训练数据集的长度为:10
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
# 利用 Dataloader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
if torch.cuda.is_available():
tudui = tudui.cuda() # 网络模型转移到cuda上
# 损失函数
loss_fn = nn.CrossEntropyLoss() # 交叉熵,fn 是 fuction 的缩写
if torch.cuda.is_available():
loss_fn = loss_fn.cuda() # 损失函数转移到cuda上
# 优化器
learning = 0.01 # 1e-2 就是 0.01 的意思
optimizer = torch.optim.SGD(tudui.parameters(),learning) # 随机梯度下降优化器
# 设置网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮次
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("logs")
start_time = time.time()
for i in range(epoch):
print("-----第 {} 轮训练开始-----".format(i+1))
# 训练步骤开始
tudui.train() # 当网络中有dropout层、batchnorm层时,这些层能起作用
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda() # 数据放到cuda上
targets = targets.cuda() # 数据放到cuda上
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 计算实际输出与目标输出的差距
# 优化器对模型调优
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播,计算损失函数的梯度
optimizer.step() # 根据梯度,对网络的参数进行调优
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time) # 运行训练一百次后的时间间隔
print("训练次数:{},Loss:{}".format(total_train_step,loss.item())) # 方式二:获得loss值
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始(每一轮训练后都查看在测试数据集上的loss情况)
tudui.eval() # 当网络中有dropout层、batchnorm层时,这些层不能起作用
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 没有梯度了
for data in test_dataloader: # 测试数据集提取数据
imgs, targets = data # 数据放到cuda上
if torch.cuda.is_available():
imgs = imgs.cuda() # 数据放到cuda上
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 仅data数据在网络模型上的损失
total_test_loss = total_test_loss + loss.item() # 所有loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "./model/tudui_{}.pth".format(i)) # 保存每一轮训练后的结果
#torch.save(tudui.state_dict(),"tudui_{}.path".format(i)) # 保存方式二
print("模型已保存")
writer.close()3. CPU训练时间
代码一样,可以查看一下时间上的对比。
4. 利用GPU训练(方式二)
① 电脑上有两个显卡时,可以用指定cuda:0、cuda:1。
import torchvision
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
# 定义训练的设备
#device = torch.device("cpu")
#device = torch.device("cuda") # 使用 GPU 方式一
#device = torch.device("cuda:0") # 使用 GPU 方式二
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# from model import * 相当于把 model中的所有内容写到这里,这里直接把 model 写在这里
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3,32,5,1,2), # 输入通道3,输出通道32,卷积核尺寸5×5,步长1,填充2
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(), # 展平后变成 64*4*4 了
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,则打印:训练数据集的长度为:10
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
# 利用 Dataloader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
tudui = tudui.to(device) # 也可以不赋值,直接 tudui.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss() # 交叉熵,fn 是 fuction 的缩写
loss_fn = loss_fn.to(device) # 也可以不赋值,直接loss_fn.to(device)
# 优化器
learning = 0.01 # 1e-2 就是 0.01 的意思
optimizer = torch.optim.SGD(tudui.parameters(),learning) # 随机梯度下降优化器
# 设置网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮次
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("logs")
start_time = time.time()
for i in range(epoch):
print("-----第 {} 轮训练开始-----".format(i+1))
# 训练步骤开始
tudui.train() # 当网络中有dropout层、batchnorm层时,这些层能起作用
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device) # 也可以不赋值,直接 imgs.to(device)
targets = targets.to(device) # 也可以不赋值,直接 targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 计算实际输出与目标输出的差距
# 优化器对模型调优
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播,计算损失函数的梯度
optimizer.step() # 根据梯度,对网络的参数进行调优
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time) # 运行训练一百次后的时间间隔
print("训练次数:{},Loss:{}".format(total_train_step,loss.item())) # 方式二:获得loss值
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始(每一轮训练后都查看在测试数据集上的loss情况)
tudui.eval() # 当网络中有dropout层、batchnorm层时,这些层不能起作用
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 没有梯度了
for data in test_dataloader: # 测试数据集提取数据
imgs, targets = data # 数据放到cuda上
imgs = imgs.to(device) # 也可以不赋值,直接 imgs.to(device)
targets = targets.to(device) # 也可以不赋值,直接 targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 仅data数据在网络模型上的损失
total_test_loss = total_test_loss + loss.item() # 所有loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "./model/tudui_{}.pth".format(i)) # 保存每一轮训练后的结果
#torch.save(tudui.state_dict(),"tudui_{}.path".format(i)) # 保存方式二
print("模型已保存")
writer.close()5. 运行Terminal语句
① 运行terminal上运行的命令,可以在代码块中输入语句,在语句前加一个感叹号。
② 输入 !nvidia-smi,可以查看显卡配置。
6.验证狗是否识别
① 完整的模型验证(测试,demo)套路,利用已经训练好的模型,然后给它提供输入。
import torchvision
from PIL import Image
from torch import nn
import torch
image_path = "imgs/dog.png"
image = Image.open(image_path) # PIL类型的Image
image = image.convert("RGB") # 4通道的RGBA转为3通道的RGB图片
print(image)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
model = torch.load("model/tudui_29.pth",map_location=torch.device('cpu')) # GPU上训练的东西映射到CPU上
print(model)
image = torch.reshape(image,(1,3,32,32)) # 转为四维,符合网络输入需求
model.eval()
with torch.no_grad(): # 不进行梯度计算,减少内存计算
output = model(image)
output = model(image)
print(output)
print(output.argmax(1)) # 概率最大类别的输出















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









