






Self-Path: Self-supervision for Classification of Pathology Images with Limited Annotations
Self-Path:有限注释病理图像分类的自监督学习
方法核心:用自监督的辅助任务来提升半监督的性能;
发表时间:October 2021;
发表期刊/会议:IEEE Transactions on Medical Imaging(IF:10.048)
论文地址:https://ieeexplore.ieee.org/document/9343323
代码地址:
关键词:计算病理学 有限注释 半监督学习 领域自适应
0 摘要
【挑战】得到病理学高分辨率的注释数据非常难。
本文提出一种自监督CNN,称为Self-Path,利用没有标注的数据来学习病理图像中的泛化(generalizable) 和领域不变表示 (domain invariant representations)。
Self-Path是一种多任务学习方法,主任务是分类,辅助任务(pretext task)是各自带有标签数据的自监督任务。
pretext task:自监督学习中的概念;
本文引入新的领域特定(3个)和非领域特定(5个)的自监督任务,利用病理图像中的上下文、多分辨率和语义特征进行半监督学习和领域适应。
研究了Self-Path在3个不同病理数据集上的有效性。
1 简介
【挑战】
计算病理学数据的限制;
病理学注释数据的困难;
为了克服这些困难,可以采样以下策略:
- (a) 标记少量数据来辅助训练(半监督);
- Mean Teacher算法;
- Virtual Adversarial Training算法;
- (b) 使用与新数据集密切匹配的现有标记数据集(迁移学习分支领域适应)
- 罕见肿瘤没有现成数据等;
【贡献】
-
在本文中,提出了Self-Path——一种基于WSI自监督任务的通用框架,用于在有限或无注释的情况下对病理图像进行分类;
-
提出了3个新的病理领域特定的自监督任务,旨在利用组织病理学图像中的上下文、多分辨率和语义特征;
-
在三种不同类型的病理学图像分类数据集上证明Self-Path有效;
-
证明了Self-Path在有限的注释下(1%~2%的注释数据)实现了半监督学习的最先进性能;
-
进一步展示了Self-Path可以在相关任务上利用现有的带注释的资源,启用域适应,并在目标任务没有带注释的数据可用时实现具有竞争力的性能;
【相关工作】
- Semi-supervised Learning半监督学习方面工作:
- 利用数据分布上的模型假设建立学习器对未标签样例进行标签;
- 通常是两阶段的训练:
- 使用可用的标签来训练模型,并给未标记的样本预测伪标签;
- 然后在训练中使用这些标签;
- Domain Adaptation领域自适应方面工作:
- 邻域适应是迁移学习中很重要的一部分内容;
- 目的是把分布不同的源域和目标域的数据,映射到一个特征空间中,使其在该空间中的距离尽可能近;
- 在特征空间中对source domain训练的目标函数,就可以迁移到target domain上,提高target domain上的准确率;
- Self-Supervision自监督学习方面工作:
- 模型直接从无标签数据中进行学习,无需标注数据;
- 自监督学习的核心:如何自动为数据产生标签?例如:一张图,把图随机旋转一个角度,把旋转后的图作为输入,随机旋转的角度作为标签;
- 自监督学习的研究套路:首先提出一个新的自动打标签的辅助任务(pretext task,如旋转图像、打乱patches顺序等),用辅助任务自动生成标签,然后做实验,测性能;
- 重点在如何提出辅助任务;
2 问题表述
x:输入图像;
y:图像对应的标签;
(a) Semi-supervised Learning 半监督
一些有标签的图像:
S
L
=
{
(
x
i
,
y
i
)
}
i
=
1
N
S_L = \{(x_i,y_i) \}^N_{i=1}
SL={(xi,yi)}i=1N
一些没有标签的图像:
S
U
=
{
(
x
i
)
}
i
=
1
M
S_U = \{(x_i) \}^M_{i=1}
SU={(xi)}i=1M
半监督框架旨在利用未标记数据 S U S_U SU来增强使用标记数据 S L S_L SL学习的可推广性;
(…根据已知的图像和标签,为未知标签的图像打标签)
通常,在半监督环境中, S L S_L SL和 S U S_U SU都来自同一分布;
(b) Domain Adaptation 域适应
源域source domain S包含一组 n s n_s ns个样本: D s = { X i s , y i s } i = 1 n s D_s = \{X^s_i,y^s_i \}^{n_s}_{i=1} Ds={Xis,yis}i=1ns;
目标域target domain T包含一组 n t n_t nt个没有标签的样本: D t = { X i t } i = 1 n t D_t = \{X^t_i \}^{n_t}_{i=1} Dt={Xit}i=1nt;
源域的标签空间与目标域的标签空间是相同的 Y s ≈ Y t Y_s≈Y_t Ys≈Yt;
此外,源域和目标域是相关的,但它们的分布是不同的;
(…在源域训练的结果(或目标函数)迁移到目标域)
3 方法

Self-Path采用多任务学习的方法来学习类区分性和领域不变性的特征,将辅助任务添加到共享编码器,以学习有用的表示,从而增强半监督学习或领域自适应。
A 多任务学习
本文提出的方法结合不同的任务(主任务+辅助任务)来训练模型,这有助于模型泛化,并可以提高主任务的相关性能。
说人话:把主任务损失函数和辅助任务损失函数结合,一起训练,所有任务同时优化;(具体辅助任务见后文)

L
c
L_c
Lc:主要任务的损失函数;
L
p
k
L_{pk}
Lpk:辅助任务的损失函数;
r
r
r:辅助任务的标签;
H
e
H_e
He:共享编码器;
H
c
H_{c}
Hc:主任务的函数;
H
p
k
H_{pk}
Hpk:第
k
t
h
k^{th}
kth个辅助任务的函数;
α
p
k
α_{pk}
αpk:不同辅助任务之间的权重参数;
n
l
n^l
nl:有标签数据的个数;
n
u
n^u
nu:无标签数据的个数;
(说人话:总损失函数=主任务损失函数+辅助任务损失函数)
B 自监督学习
自监督学习包含一系列辅助任务(pretext task),这些辅助任务可以利用来自无标签数据的信息来提高用于监督的标签很少的主任务中的性能。
函数 g ( x , r ) g(x,r) g(x,r)可以把输入图像 x x x根据 r r r进行变换,得到输出 x ~ \widetilde{x} x 。
举个栗子:
g
(
⋅
)
g(·)
g(⋅)是一个旋转函数,
x
x
x是输入的图像,
r
r
r是旋转值( r = 1,2,3,分别代表旋转90°,180°,270°),
x
~
\widetilde{x}
x
是输出的旋转后的图像;
自监督分类任务的目标函数为:

x
∼
D
r
e
a
l
x \sim D_{real}
x∼Dreal:x是真实数据,服从真实数据的分布
D
r
e
a
l
D_{real}
Dreal;
P
S
P_S
PS:自监督预测类别的概率;
(上式不就是 L o s s = − l o g P ( y ∣ x ) Loss = -log P(y|x) Loss=−logP(y∣x) )
C 特定领域的自监督辅助任务
1)预测图像的放大倍数(称为magnification);
组织病理学具有金字塔结构,在图像大小固定的情况下,放大倍率越高,组织区域的细节越多,背景越少,放大倍率越小,组织区域细节越小,背景越丰富。
核心思想:通过让模型猜测图像的放大倍率来学习一些语义信息;
定义一个辅助任务 H m a g H_{mag} Hmag:给定4个放大级别(40x/20x/10x/5x),猜测图像是哪个级别的;

2)预测patch的顺序(称为puzzle或者jigmag);
从被打乱的部分中检索原始图像的任务是模式识别的一个基本问题。
对于jigmag问题,网络应该专注于tile之间的差异和tile之间的位置特征,应避免低级特征而应该学习图像的全局语义表示。
在组织学图像中,物体(其实就是细胞组织啥的…)相对自然图像更小,并且物体之间没有特定的顺序(比如狗的头和脚有固定的相对位置,不能错,但组织学图像的细胞与细胞之间没有这种固定关系)。所以常规的puzzle问题不适合病理图像,将问题转化为以下形式:
给定2×2 = 4个patch,4个patch是同一区域的不同放大倍数,让模型预测从左至右,从上至下预测4个patch的放大倍率,一共有12种顺序 C 1 , C 2 , . . . C_1,C_2,... C1,C2,...

3)预测HE染色通道(称为Hematoxylin);
HE染色,与细胞核结合,可以使细胞核变为蓝紫色。可以让网络感知图像中的细胞核及其形态信息来学习一些有用的特征。

D 非特定领域的自监督辅助任务
1)预测图像旋转(称为Rotation)
预测输入图像的翻转角度(90°,180°,270°);
2)预测图像翻转(称为Flipping)
预测图像是否翻转(0:未翻转;1翻转);
3)Autoencoder
为了重建图像,在共享编码器上使用卷积解码器,类似于预测HE通道的解码器。
(AutoEncoder把数据作为输入,将其编码转换为一个向量,并输出看起来像输入的数据。换句话说,它可以学习输入中的模式,通过反向传播,可以生成新的非常接近输入数据的东西。)
4)Real/Fake prediction(generative)
预测真实的图像和生成的图像。对于未标记的样本,生成网络可以以对抗的方式训练,以生成看起来像原始样本的生成样本。共享编码器可以用于提取特征,在这种情况下,主要任务是对标记子集进行图像分类,辅助任务是对给定的真实和生成的图像集进行真实与虚假预测。
真实数据来自分布 D r e a l D_{real} Dreal,生成函数学习出分布 D g e n D_{gen} Dgen使得两个分布对齐 D g e n ∼ D r e a l D_{gen} \sim D_{real} Dgen∼Dreal;
生成器 G ( ⋅ ) G(·) G(⋅)从均匀分布噪声 D n o i s e D_{noise} Dnoise中获取预定义的噪声变量 z z z。
目标函数定义为:

L
d
i
s
L_{dis}
Ldis:鉴别器的损失(判断图像是真实的还是生成的);
L
g
e
n
L_{gen}
Lgen:生成器的损失(根据真实图像以对抗的方式生成图像);
H
e
(
x
)
H_e(x)
He(x):特征提取器中间层的特征;
H
D
i
s
(
H
e
(
x
)
)
H_{Dis}(H_e(x))
HDis(He(x)):鉴别器的输出(真/假);
5)Domain prediction
领域对抗性神经网络(DANN)包括一个minimax game(极大极小之间的博弈),其中训练鉴别器 H d H_d Hd来区分源域和目标域,同时训练特征提取器来混淆鉴别器;
为了提取域不变特征 f f f,通过最大化域鉴别器 L d L_d Ld的损失来学习特征提取器 θ e θ_e θe的参数(多任务设置中的共享编码器),而通过最小化域鉴别器的损失来学习域鉴别器的参数;

d
i
d_i
di 是
x
i
x_i
xi 的域标签(target or source);
α
d
α_d
αd是鉴别器的一个系数;
4 实验
A 数据集
Camelyon16:共399张乳腺淋巴结WSI,公共数据集;
LNM-OSCC:口腔鳞状细胞癌转移到颈部淋巴结的图像,内部数据集;
Kather:人类结直肠癌(CRC),只有100k patch,没有WSI。patch大小为224 × 224,实验时resize到128 × 128;
实验所有patch:128 × 128 at 10x;
三个数据集具体数量见下表:

B 实验设置
1) 网络
提取特征backbone:Resnet50;
包含自适应平均池化/全连接层/softmax;
用于重建图像(Autoencoder)和预测HE通道的解码器:类似U-Net解码器;
预测真实与生成图像:参考文献[36]的网络;
2) 实现细节
用backbone作为共享编码器时:
- epoch:200;
- batch size:64;
- Adam优化器;
- learning rate: 1 0 − 3 10^{-3} 10−3;
预测真实与生成图像实验:
- epoch:500;
- batch size:32;
- Adam优化器;
- learning rate: 3 × 1 0 − 4 3×10^{-4} 3×10−4;
所有任务的权重均为1;
C 半监督实验
比较了不同的自监督任务对半监督学习的效果。
1) LNM-OSCC数据集比较结果
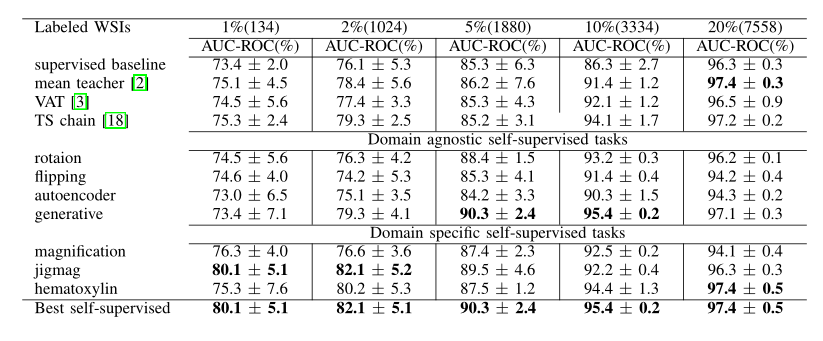
表2展示了不同模型,利用不同比率的标注数据(1%,2%,5%,10%,20%),添加不同的辅助任务得到的AUC-ROC;
Supervised baseline:只在标注数据上训练;
mean teacher/VAT/TS chain:三个半监督方法;
从表2中可以观察到,在注释较少的情况下(1%和2%),领域特定的自监督任务的性能优于Supervised baseline和三个半监督方法,其中jigmag性能最好;
当标注数据增加到5%时,generative辅助任务性能最好;
2) Camelyon16数据集
具体结果见表3,结果与之前类似;

3) Kather数据集
具体结果见表4,结果与之前类似;

D 域适应实验
1) patch-level 分析
将Camelyon16数据集作为标记集(源域 source domain),LNM-OSCC数据集作为未标记集(目标域 target domain)。在LNM-OSCC数据集测试集上对模型进行了测试。
所有标记数据都来自Camelyon16的训练集,LNM-OSCC训练数据不带任何标签。
结果见图4:

source only:baseline,仅使用Camelyon16数据集训练Resnet50;
magnification、jigmag和hematoxilyn,作为辅助任务,可以提高10%的AUC-ROC性能;
generative辅助任务性能最高,AUC-ROC达到91.54,比WDGRL高2%,比baseline高11%,证明generative任务有效;
2) WSI-level 分析
patch-level分类是WSI-level疾病预测的先决条件,在测试阶段,将属于组织区域的patch聚集起来,构建WSI的热图。然后,对热图进行后处理,得到WSI的标签。
评估LNM-OSCC数据集的WSI的域自适应性能,用最好的Self-Path设置(generative)应用于从测试集WSI提取的patch,将此方法与仅在Camelyon16数据集上训练的模型作为基线进行比较。
具体,提取10x 128×128,一半重叠的patch,将patch预测的结果聚合在一起,形成WSI的热图。
结果见表5:

仅在Camelyon16上训练的模型AUC-ROC为75.2%,generative模型为90.4%,提升15.2%,再一次证明了GAN生成图像和对抗性训练在patch-level和WSI-level都能实现高性能的能力;
比WDFRL方法相比,提升了4.8%(patch-level仅提升了2%),WSI-level同样有效;
WSI可视化结果见下图:

行:ground truth+3种方法,列:三个不同的WSI。圆圈表示使用基线模型遗漏的区域,箭头指向WDGRL生成的假阳性区域,使用generative辅助任务消除了这些区域。














 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









