







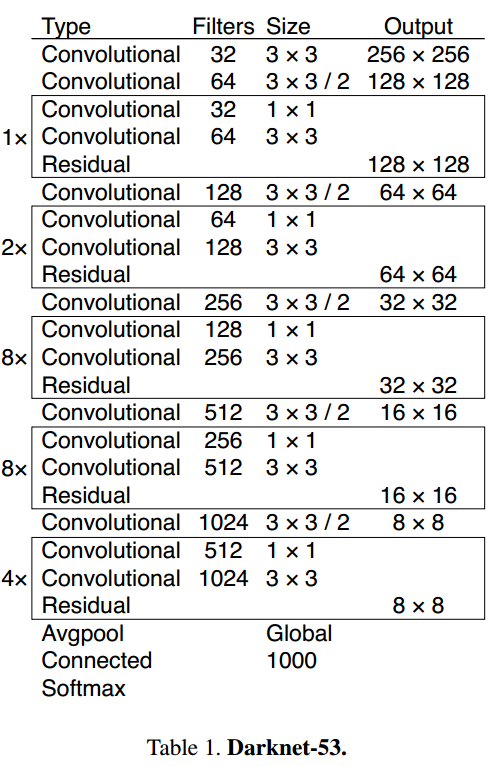
YOLOv3仅使用卷积层,使其成为一个全卷积网络(FCN)。文章中,作者提出一个新的特征提取网络,Darknet-53。正如其名,它包含53个卷积层,每个后面跟随着batch normalization层和leaky ReLU层。没有池化层,使用步幅为2的卷积层替代池化层进行特征图的降采样过程,这样可以有效阻止由于池化层导致的低层级特征的损失。
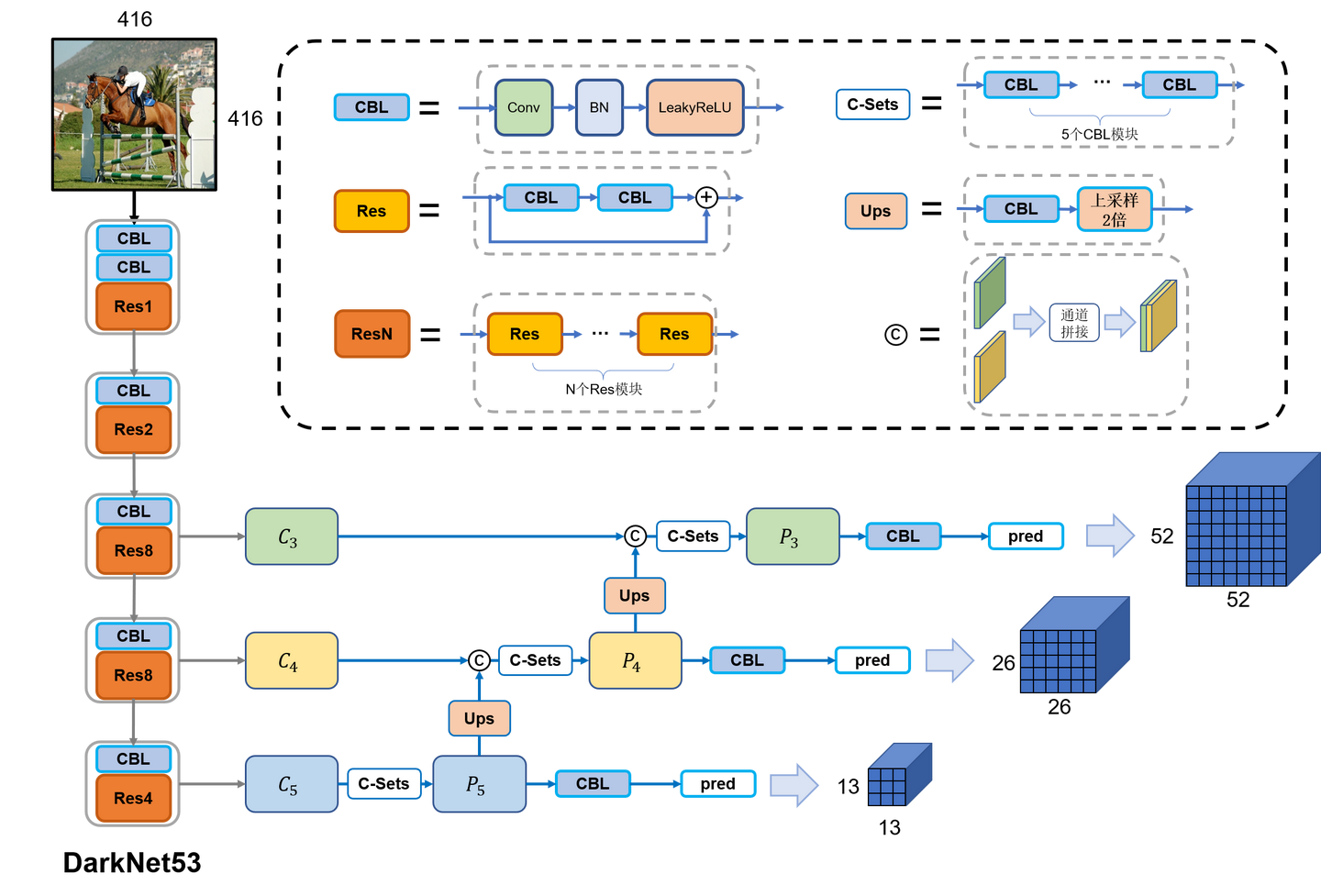
在没有 padding 的前提下,stride = 2 会让输入的尺寸高度和宽度各自减小一般,在最左列经过 5 次CBL中 stride = 2 的卷积核之后,在第三,四,五 Block层 特征图的尺寸分别为 52,26,13。
C
3
,
C
4
,
C
5
C_3,C_4,C_5
C3,C4,C5 是对应层输出的特征图,第五个 Block 层输出的特征图经过上采样高度和宽度变为原先 2 倍之后和第四个 Block 层输出的特征图 在通道维度上进行 concatenation 拼接。类似地,第四个 Block 层输出的特征图经过上采样扩大后和第三个Block 层的输出进行拼接。
不论是YOLOv1,还是YOLOv2,都有一个共同的致命缺陷:只使用了最后一个经过32倍降采样的特征图(简称C5特征图)。尽管YOLOv2使用了passthrough技术将16倍降采样的特征图(即C4特征图)融合到了C5特征图中,但最终的检测仍是在C5尺度的特征图上进行的,最终结果便是导致了模型的小目标的检测性能较差。
为了解决这一问题,YOLO作者做了第三次改进,不仅仅是使用了更好的主干网络:DarkNet-53,更重要的是使用了FPN技术与多级检测方法,相较于YOLO的前两代,YOLOv3的小目标的检测能力提升显著。
在3个不同尺度的每个特征图上,YOLOv3在每个网格处放置3个先验框。由于YOLOv3一共使用3个尺度,因此,YOLOv3一共设定了9个先验框,这9个先验框仍旧是使用kmeans聚类的方法获得的。在COCO上,这9个先验框的宽高分别是(10, 13)、(16, 30)、(33, 23)、(30, 61)、(62, 45)、(59, 119)、(116, 90)、(156, 198)、(373, 326)。
Bounding Box Prediction
YOLOv3 predicts an objectness score for each bounding box using logistic regression. This should be 1 if the bounding box prior overlaps a ground truth object by more than any other bounding box prior. If the bounding box prior is not the best but does overlap a ground truth object by more than some threshold we ignore the prediction, following. We use the threshold of 0.5. Unlike [17] our system only assigns one bounding box prior for each ground truth object. If a bounding box prior is not assigned to a ground truth object it incurs no loss for coordinate or class predictions, only objectness.
这段话描述的是YOLOv3模型中对于边界框(bounding box)和对象置信度(objectness score)的处理方式。具体来说:
-
对象置信度预测 在YOLOv3中,对于每个ground truth对象,只有与之IoU最高的anchor box的对象置信度分数会被设置为1,表明这个anchor box负责预测该对象。其余的anchor boxes的对象置信度分数会被设置为0,表示它们不负责预测该对象。
-
忽略预测 如果一个边界框的先验不是最好的,但仍然与真实对象重叠超过某个阈值(在这里是0.5),那么这个预测将被忽略。这意味着在训练过程中,这种情况下的预测不会对损失函数产生影响。
-
单一 Anchor box分配 与其他一些系统不同,YOLOv3为每个真实对象只分配一个anchor box负责预测该目标。
-
损失函数 如果一个边界框先验没有被分配给任何真实对象,那么它在坐标或类别预测上不会产生损失,只会在对象置信度上产生损失。这是因为这个边界框没有被用来预测任何具体的对象,所以它的位置和类别是不重要的,只有它的对象置信度是有意义的(应该接近于0,因为它没有检测到任何对象)。
简而言之,这段话描述了YOLOv3中如何处理边界框和对象置信度的预测,以及如何在训练过程中计算损失。
Class Prediction
YOLOv3中的多标签类预测是指模型能够为每个检测到的对象预测多个类别标签,而不是只预测单一的类别。这对于处理那些可能属于多个类别的对象特别有用,例如在某些场景中,一个对象可能既被视为"人"也被视为"运动员"。
在YOLOv3中,这种多标签类预测是通过使用逻辑回归(而不是传统的softmax函数)来实现的。对于每个对象,模型会为每个类别输出一个独立的置信度分数,这个分数表示对象属于该类别的概率。这些置信度分数是独立的,因此一个对象可以同时具有多个高置信度的类别标签。
Predictions Across Scales
在YOLOv3中,多尺度预测指的是使用不同尺寸的特征图(feature maps)来进行目标检测。这些特征图分别对应于网络中不同深度的层,每个层捕获了图像的不同尺度的信息。通过这种方式,模型能够同时检测图像中不同尺寸的对象,从而提高了检测的准确性和鲁棒性。
YOLO的多尺度训练是一种技术,用于提高模型在不同大小的对象上的性能。在训练过程中,输入图像的尺寸会在一定范围内随机变化,这样模型就能够学习在不同尺度上识别对象。
YOLOv3在 3 个不同的尺度上预测边界框。使用与特征金字塔网络相似的概念从这些尺度中提取特征[8]。在基本特征提取器中,作者添加了几个卷积层。最后一层预测了一个3维张量编码边界框、对象和类预测。在使用COCO[10]的实验中,作者在每个尺度上预测3个边界框,因此对于4个边界框偏移量,1个物体预测和80个类别预测,张量是 N × N × [ 3 ∗ ( 4 + 1 + 80 ) ] N × N ×[3∗(4 + 1 + 80)] N×N×[3∗(4+1+80)]。
这段话描述了YOLOv3在三个不同尺度上预测边界框的方法,以及它是如何利用特征金字塔网络(Feature Pyramid Networks,FPN)的概念来提取特征的。具体来说:
-
多尺度预测 YOLOv3在三个不同的尺度上预测边界框。这意味着模型能够检测不同大小的对象。
-
特征提取 模型从基础特征提取器中添加了几个卷积层,最后一个卷积层预测一个三维张量,该张量编码了边界框、对象置信度和类别预测。在COCO数据集上的实验中,每个尺度预测3个边界框,因此张量的维度是 N × N × [ 3 × ( 4 + 1 + 80 ) ] N × N × [3 × (4 + 1 + 80)] N×N×[3×(4+1+80)],其中4代表边界框的偏移量,1代表对象置信度预测,80代表类别预测。
-
特征融合 接着,模型将前两层的特征图上采样2倍,并将其与网络更早层的特征图通过连接(concatenation)合并。这样做可以从上采样的特征中获取更有意义的语义信息,同时从早期的特征图中获取更细粒度的信息。然后,模型添加了一些卷积层来处理这个合并的特征图,并最终预测一个类似的张量
-
重复操作 模型再次重复这个设计,以预测最后一个尺度的边界框。因此,第三个尺度的预测受益于之前的所有计算以及网络早期的细粒度特征。
-
边界框先验 模型仍然使用 k-means 聚类来确定边界框先验。模型选择了9个聚类和3个尺度,然后在尺度之间均匀地划分聚类。在COCO数据集上,9个聚类的尺寸分别是: ( 10 × 13 ) , ( 16 × 30 ) , ( 33 × 23 ) , ( 30 × 61 ) , ( 62 × 45 ) , ( 59 × 119 ) , ( 116 × 90 ) , ( 156 × 198 ) , ( 373 × 326 ) (10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326) (10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)。
总的来说,这段话描述了YOLOv3是如何在不同的尺度上预测边界框,并利用特征融合来提高模型对不同大小对象的检测能力的。
Feature Extractor
使用一种新的网络提取特征 Darknet 53
过去,YOLO在处理小物体时遇到了困难。然而,现在作者看到了这一趋势的逆转。通过新的多尺度预测,作者看到YOLOv3具有相对较高的APS性能。但是,它在中型和大型对象上的性能相对较差。要弄清这件事的真相,还需要更多的调查。














 1763
1763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









