







论文动机、现有方法的不足、拟解决的问题、主要贡献和创新点的总结:
1. 动机
伪装目标检测是计算机视觉中的一个重要问题,因为伪装目标在空间域上与背景高度相似,传统的检测方法难以有效区分它们。伪装目标的检测具有广泛的应用场景,例如医学图像分析、物种保护和工业缺陷检测。现有的COD方法主要集中在空间特征的提取和处理,但单一的空间特征在面对复杂背景时,易受到干扰,表现出较差的鲁棒性。为了克服这些挑战,作者提出了一种结合频率域和空间域特征的新方法,称为频率-空间纠缠学习(Frequency-Spatial Entanglement Learning,FSEL),以更好地捕捉伪装目标的特征。
2. 现有方法的不足
现有COD方法主要集中在以下两类:
- 基于空间特征的方法:这些方法主要依赖于局部像素强度和空间位置信息,但由于伪装目标与背景的高相似性,空间特征在复杂背景下容易被干扰,难以有效检测出伪装目标。
- 结合频率特征的方法:一些方法开始结合频率特征(例如通过傅里叶变换获取的频率信息),但大多只关注高频或低频特征,忽略了中间频段的重要信息,导致频域信息的不完全利用。此外,频率域特征在直接从图像提取时,易受到背景噪声的影响,导致不准确的特征表示。
3. 拟解决的问题
该论文旨在解决以下问题:
- 空间特征的局限性:单纯依赖空间域特征容易受到复杂背景的干扰,尤其是当伪装目标和背景在局部像素级别相似时,难以分离它们。
- 频率特征的不足:现有结合频率特征的方法,通常仅利用高频和低频特征,而忽略了中频信息,导致对图像内容的理解不够全面。此外,频率特征容易受噪声影响,难以直接与空间特征融合。
4. 主要贡献
论文的主要贡献体现在以下几个方面:
- 提出了频率-空间纠缠学习(FSEL)框架,通过结合全球的频率特征和局部的空间特征,提升了伪装目标的检测性能。
- 设计了纠缠Transformer块(Entanglement Transformer Block, ETB),实现了频率域和空间域特征之间的相互学习与优化,增强了特征的表示能力。
- 引入了联合域感知模块(Joint Domain Perception Module, JDPM),通过结合多尺度的频率-空间信息,增强了特征的上下文理解能力。
- 提出了双域反向解析器(Dual-domain Reverse Parser, DRP),在频率域和空间域中对多层特征进行优化和融合,提升了预测的准确性。
5. 创新点
- 频率与空间域的深度融合:提出了频率-空间纠缠学习的概念,首次将频率特征和空间特征进行深度融合,不仅考虑了高频和低频特征,还结合了不同频率之间的关系,提供了更全面的特征表示。
- 纠缠Transformer块:通过ETB实现频域与空间域特征的交互学习,使得模型能够从不同域中学习到互补的信息,提升了伪装目标的检测能力。
- 多尺度的频率与空间感知:JDPM通过频率变换和多尺度卷积,提升了模型对伪装目标的全局和局部特征的感知能力。
- 双域反向解析:DRP能够在频率和空间域中对多层特征进行优化和反向解析,增强了模型的分割精度,特别是在复杂背景和难以识别的伪装目标场景中表现出色。
总结来说,论文的核心创新点在于通过将频率特征与空间特征结合,并设计了新的学习机制来更好地理解和检测伪装目标,显著提升了检测的精度和鲁棒性。
1. Introduction
主要介绍了研究背景、当前的挑战、已有方法的不足,以及论文提出的方法和贡献。以下是对该部分的详细解释:
1.1 研究背景
论文首先引入了伪装现象及其重要性。伪装是自然界中一些生物(如变色龙、蝗虫和毛虫)用来自我保护的防御机制,它们通过与环境的相似性隐藏自己。研究伪装目标检测(Camouflaged Object Detection,COD)旨在解决从真实世界图像中识别这些隐藏目标的问题。这项研究在计算机视觉领域具有重要意义,并且在多个领域中有广泛应用:
- 医学图像分析:如用于检测难以发现的病变组织。
- 物种保护:帮助监测伪装物种的存在。
- 工业缺陷检测:识别制造过程中难以察觉的缺陷。
1.2 伪装目标检测的挑战
伪装目标与背景的高度相似性是该领域的主要挑战。由于这些目标与周围环境在空间域(如颜色、纹理、形状等方面)高度相似,传统的图像检测技术难以有效地区分它们。具体而言,伪装目标检测的难点在于:
- 像素级别的相似性:伪装目标的像素信息(颜色、纹理等)往往与背景非常接近,导致在图像的空间域中难以分割出伪装目标。
- 复杂背景的干扰:伪装目标往往隐藏在复杂的背景中,现有的基于空间域的方法难以准确区分目标与背景。
1.3 现有方法的不足
在早期,伪装目标检测依赖于手工设计的特征,但由于伪装目标的外观具有很大的不确定性,这些方法的效果通常不理想。随着深度学习的进展和大规模数据集的出现(如CAMO、COD10K等),许多基于深度学习的COD方法逐渐涌现。这些方法自动提取图像特征,虽然提升了性能,但依然面临一些挑战:
- 基于单一空间特征的方法:尽管这些方法有效地提取了空间特征,但由于这些特征主要依赖于像素级别的信息,容易受到复杂背景的干扰,尤其在像素点之间的局部区域,特征之间的相关性较低。这意味着仅依赖空间特征难以捕捉目标与背景之间的细微差别。
- 频率特征的潜力未被充分挖掘:研究表明,通过傅里叶变换得到的频率特征具有全局性,可以更好地理解图像内容,弥补空间特征的局限性。然而,现有的COD方法大多只使用高频或低频特征,忽略了中频段的信息。此外,频率特征在直接从图像提取时,易受到背景噪声的影响。
1.4 提出的方法
基于以上观察,作者提出了一种新的检测伪装目标的方法,称为频率-空间纠缠学习(Frequency-Spatial Entanglement Learning,FSEL),它结合了频率域和空间域特征来优化初始输入特征,增强特征的区分能力。具体来说:
- 首先,通过**频率自注意力(Frequency Self-attention)**提取全局的频率特征,这些特征可以有效地建模不同频段之间的相关性,提升对频率域信息的表征能力。
- 其次,设计了纠缠Transformer块(Entanglement Transformer Block, ETB),实现频率特征与空间特征之间的交互学习,使得它们可以相互优化、协作。
- 最后,通过**联合域感知模块(Joint Domain Perception Module)和双域反向解析器(Dual-domain Reverse Parser)**进一步对频率域与空间域特征进行优化,生成同时包含两种特征的强大表示。
1.5 论文贡献
论文的主要贡献总结为以下几点:
- 提出了一个新的频率-空间纠缠学习(FSEL)框架,该框架通过结合频率域和空间域的全局与局部特征,增强了伪装目标的检测能力。
- 设计了纠缠Transformer块(ETB),它能够学习频率和空间特征的相互依赖关系,实现特征的有效融合
- 提出了联合域感知模块(JDPM)和双域反向解析器(DRP),这些模块能够在频率和空间域中实现特征的多层次融合与解析。
总结
引言部分清晰地描述了伪装目标检测中的挑战,现有方法的不足以及作者提出的新方法的动机。通过频率域和空间域的结合,作者旨在克服现有方法在应对复杂背景和目标区分上的局限,提出了一种新颖的学习框架,并展示了该框架在多个基准数据集上的优越性。
Frequency Learning
2.1 频率域在信号分析中的重要性
频率域(Frequency Domain)是信号处理中的一个重要领域,通常通过傅里叶变换(Fourier Transform)将信号从时域或空间域转换到频率域进行分析。在频率域中,信号的能量或振动可以通过不同频率的分量表示,这对于理解图像内容和信号特性非常有帮助。
在图像处理任务中,频率域信息可以捕获图像的全局特征,与仅关注局部像素的空间域特征形成互补关系。 通过将图像信号从空间域转换为频率域,能够更好地分析图像的全局能量分布、纹理 等信息,这些信息在伪装目标检测中尤为重要,因为伪装目标与背景通常在局部像素上高度相似,但在全局频率特征上可能存在差异。
2.2 频率学习在计算机视觉中的应用
近年来,频率域特征逐渐应用到各种计算机视觉任务中。例如:
- 通道注意力(Channel Attention):Qin 等人在通道注意力模型中引入了频率变换,通过将通道注意力任务看作一个压缩问题,利用频率特征提升模型的表现。
- 平衡不同频率成分的视觉特征:Yun 等人处理了视觉特征中不同频率成分的平衡问题,确保模型能够同时关注高频和低频信息。
- 图像分类中的频率捷径:Wang 等人提出了一种频率捷径的观点,说明在图像分类中,利用频率信息可以有效提升模型的性能。
通过这些研究,频率特征被证明对理解图像内容有显著帮助。在很多情况下,结合频率域特征可以弥补空间域特征的不足,尤其是在全局图像理解和复杂背景场景中。
2.3 频率特征在伪装目标检测中的优势
作者进一步指出,频率域特征对于伪装目标检测具有独特的优势。在伪装目标检测任务中,目标往往通过色彩、纹理、形状等方式与背景高度相似,传统的基于空间特征的方法容易受到这种相似性的干扰。然而,通过分析图像的频率信息,可以捕捉到目标与背景之间微妙的全局差异,从而增强伪装目标的可检测性。
具体而言,频率特征有以下几个方面的优势:
- 全局性: 频率域特征具有全局性,能够捕捉图像中大尺度的变化,这对于理解伪装目标的整体结构非常重要。与局部的空间域特征相比,频率特征不依赖于具体的像素值,因此对局部噪声和干扰不敏感。
- 对局部噪声的鲁棒性:在伪装目标检测任务中,背景复杂且具有大量噪声,空间特征往往会受到这些背景噪声的干扰,而频率域特征可以通过高频和低频信息的分析过滤掉背景中的噪声,更好地突出目标与背景之间的差异。
- 丰富的频率信息:频率域中不仅包含高频和低频的信息,还可以捕捉中频特征,而这些中频特征往往被现有的频率学习方法忽略。作者认为,通过全面利用所有频段的频率信息,可以显著提升伪装目标检测的效果。
2.4 现有方法的局限性
尽管一些伪装目标检测方法已经开始使用频率特征,但现有方法存在以下局限:
- 频率特征的局限:现有方法大多只关注高频或低频信息,忽略了中频段的信息。然而,目标的关键特征可能位于中频段,单纯依赖高频或低频信息会导致遗漏部分有用的频率特征。
- 噪声问题:一些方法直接从图像输入提取频率特征,但伪装目标往往包含大量背景噪声,这使得从图像中提取的频率特征不够可靠,频率特征中可能会引入不必要的噪声,从而影响检测效果。
2.5 提出的解决方案:频率-空间纠缠学习
为了克服现有方法的局限,论文提出了一种 频率-空间纠缠学习(Frequency-Spatial Entanglement Learning,FSEL)方法。这种方法不仅关注高频和低频特征, 还通过频率自注意力(Frequency Self-attention)机制,学习频率域中不同频段之间的关系,确保所有频段的信息都被充分利用。
通过将频率域特征与空间域特征进行纠缠学习,可以在空间域的基础上进一步优化频率特征,同时增强空间特征的表现,最终生成更具区分力的特征表示。这种方法可以帮助模型在复杂背景下更准确地检测出伪装目标。

第二行:频率域比较
- 每个图对应的空间域图像转换到频率域后的表示结果。这里使用了傅里叶变换,将空间域信息转化为频率信息,展示了图像中频率分量的分布情况。图中颜色的不同代表不同的频率分量强度,通常中央亮点代表低频分量,边缘区域表示高频分量。
- Image:原始输入图像的频率域表示,显示了伪装目标和背景在频率域中的频率特征。
- GT、Ours、FPNet、EVP、FEDER:分别是GT、FSEL方法和其他现有方法的分割结果在频率域中的表现。可以看出,FSEL方法在频率域中生成的特征分布与GT非常接近,频率特征较为清晰且集中,能够更好地区分目标与背景。相比之下,FPNet、EVP和FEDER的方法在频率域中的表现则不如FSEL清晰,可能存在某些频率信息被错误处理或频率特征不够集中,导致检测效果较差。
Method
Overall Architecture
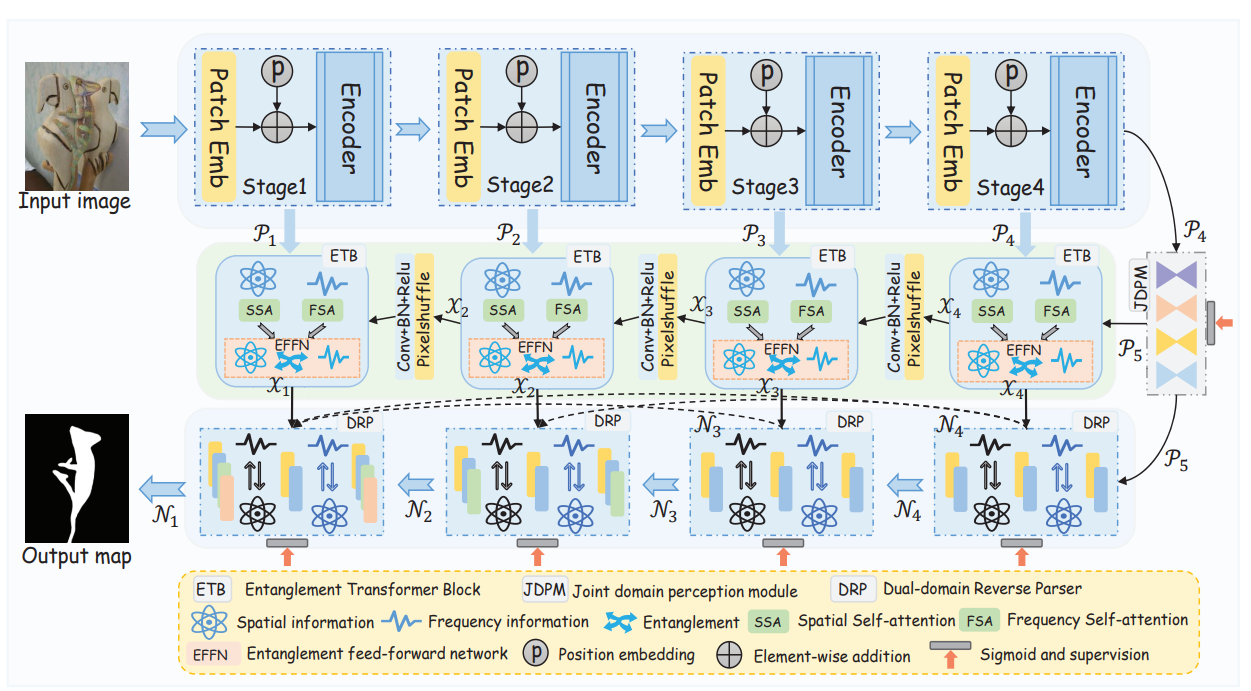
JDPM 模块类似 ASPP ,利用多分支提取并融合多尺度特征,并获得一个粗略预测图,JDPM在频率域中引入了FFT(快速傅里叶变换)和IFFT(逆傅里叶变换),进一步增强了模型对于全局信息的感知。。中间的 4个 ETB 模块,主要作用是利用注意力对频率特征和空间特征进行增强,然后融合二者。DRP 就是解码器,接收的输入是 ETB 增强融合后的特征和粗略预测图,DRP 它还通过引入反向注意力机制,帮助模型进一步细化目标区域的分割,特别是在边缘和细节区域。同时使用了跳跃连接,传递低分辨率但语义丰富的特征到解码阶段。这种设计在伪装目标检测中尤为重要,能够有效结合语义信息和解码阶段的特征,从而增强模型的分割能力。
JDPM 模块
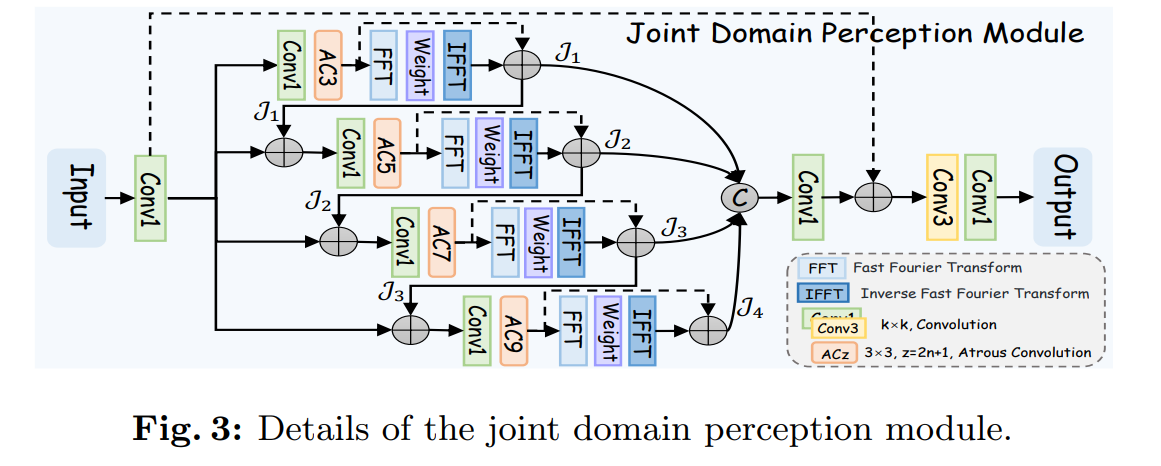
类似 ASPP 模块,也是利用不同膨胀率的空洞卷积提取多尺度特征,并同时使用了大量的残差连接(进行特征融合/增强),这样得到语义信息更强的特征。11卷积主要是调整通道,FFT和IFFT之间的weight是可学习参数,来对频率域特征进行学习。然后将频率域学习到的特征进行element-wise addition实现空间特征与频域特征融合增强,在最终输出之前,通过33卷积提取融合后的特征,并通过1*1卷积调整通道。
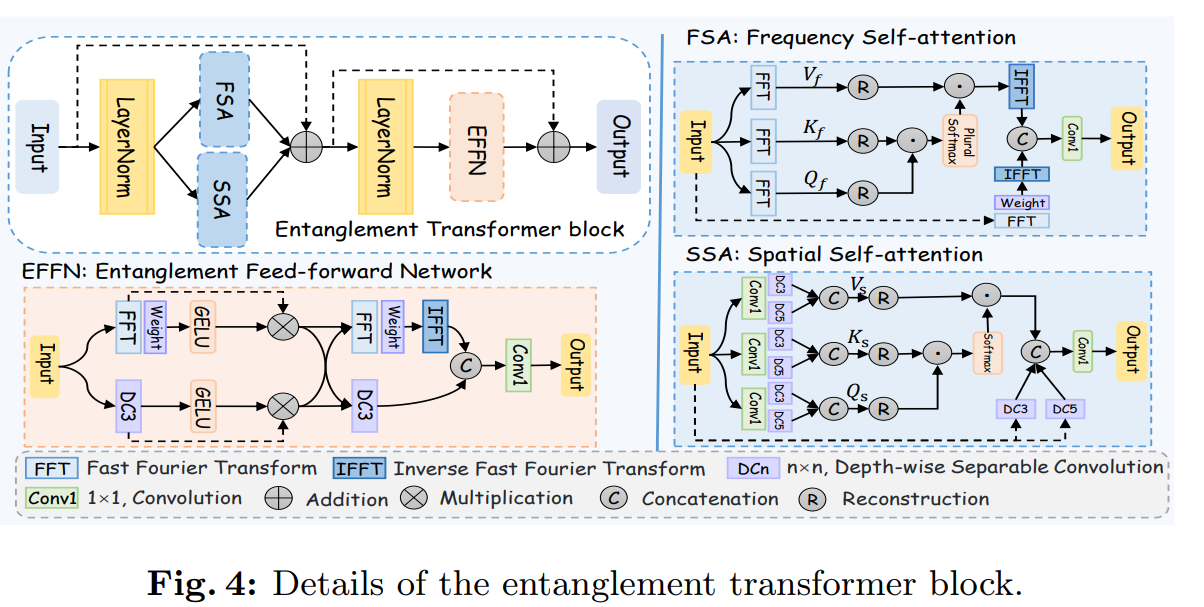
1.图中左上角子图中,为什么经过FSA和SSA之后要继续经过EFFN模块?EFFN模块的作用是?
2.图中FSA模块的子图中,softmax plural是什么含义?
关于你对图4中的**纠缠Transformer块(ETB)**的两个问题,我将逐一进行详细解释:
1. 为什么经过FSA和SSA之后要继续经过EFFN模块?EFFN模块的作用是什么?
经过FSA和SSA后进入EFFN的原因:
- **FSA(频率自注意力)和SSA(空间自注意力)**模块分别在频率域和空间域中提取特征,主要通过注意力机制捕捉到长距离的依赖关系。
- FSA通过傅里叶变换在频率域中计算特征相关性,提取全局频率特征;
- SSA在空间域中捕捉到像素级别的依赖关系,从局部视角优化空间特征。
虽然这两个模块能够分别在全局和局部层面增强特征的表示,但它们独立工作,FSA和SSA只处理各自领域的信息,尚未对频率域和空间域进行真正的融合。
EFFN的作用:
- EFFN(纠缠前馈网络)模块的作用是对FSA和SSA生成的特征进行深度融合,即所谓的“纠缠学习”。这一步使得频率特征和空间特征能够相互补充,进而生成更具表现力的特征表示。具体来说,EFFN执行了以下操作:
- FFT/IFFT操作:再次通过傅里叶变换和逆傅里叶变换,将特征在频率域和空间域之间来回转换。这一过程使得特征能够在两个域之间来回流动,帮助频率特征和空间特征进一步交互。
- 卷积操作(Conv1, DC3等):卷积操作用于对特征进行局部优化,同时保证特征的通道数能够与模型的下一步处理相匹配。
- 非线性激活(GELU):引入非线性激活函数(如GELU)使得模型能够捕捉到更复杂的特征模式。
因此,EFFN模块的核心作用在于通过特征融合将频率域和空间域的特征紧密结合在一起,从而提升模型在伪装目标检测中的全局与局部感知能力。FSA和SSA模块各自处理不同维度的信息,而EFFN负责将这些特征进行有效结合,形成更具区分力的特征表示。
2. FSA模块中的“softmax plural”是什么意思?
softmax plural的含义:
-
在图中FSA模块的子图里,Softmax后面标注了“plural”(复数),这指的是Softmax在多个频率通道上应用,而不是单独对一个通道进行操作。具体来说,Softmax通常用于将某个权重矩阵归一化,使得权重值位于0到1之间,并且和为1。
-
“plural”的意思是Softmax在处理多个通道时,将每个通道的频率分量分别进行Softmax归一化。在频率自注意力模块中,特征会通过快速傅里叶变换(FFT)被转化到频率域,生成多个通道的频率特征。Softmax操作的“plural”表明,模型需要对多个频率通道的权重分别进行处理,以确保在多个频率层面上都能合理分配注意力权重,而不是将所有频率通道作为一个整体进行归一化。
作用:
Softmax plural能够确保频率域中的每一个频率通道都可以独立处理其注意力权重。这意味着模型可以在不同的频率通道上专注于不同的信息,确保各个频段的全局特征能够得到合理的处理和学习。通过这种方式,FSA模块可以在频率域上更好地捕捉到全局模式。
总结:
- 经过FSA和SSA后要进入EFFN模块是为了将频率域和空间域的特征进行深度融合,EFFN模块通过纠缠学习的方式结合全局和局部信息,生成更具表现力的特征。
- Softmax plural表明Softmax在FSA中对多个频率通道分别进行操作,确保频率域中每个通道的特征都能得到合理的注意力分配,从而提升全局特征的捕捉能力。
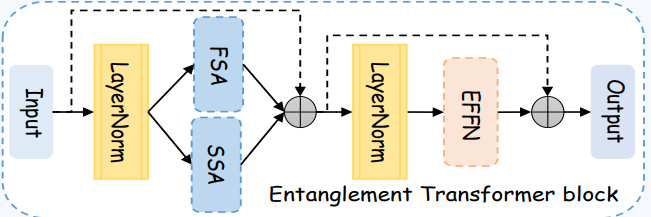
也就是说,图中FSA和SSA的作用是特征增强,紧接着的EFFN是特征融合作用,对吗?那么两个LayerNorm的作用是?
是的,你的理解非常正确!FSA(频率自注意力)和SSA(空间自注意力)的主要作用是对输入特征进行增强,分别在频率域和空间域中提升特征的表达能力。而EFFN(纠缠前馈网络)则是对经过增强的特征进行融合,将频率域和空间域的信息有效结合,生成更为综合的特征表示。
现在针对你的问题,LayerNorm(层归一化)在这个模块中的作用也非常重要,主要有以下几点:
LayerNorm的作用:
1. 归一化特征,稳定训练过程
LayerNorm的主要作用是对输入特征进行归一化,即在每一个特征维度上调整数据的均值和方差到一定范围。其具体过程是,在每个样本的不同通道之间计算均值和方差,并将其归一化。通过这种归一化,特征在输入到后续网络层时,数值分布更加稳定,防止梯度消失或爆炸问题,进而使训练更加稳定、快速。
2. 防止数值差异过大
由于FSA和SSA模块分别在频率域和空间域对特征进行处理,这些操作可能导致特征值在不同域中的分布差异较大。LayerNorm通过对这些特征进行标准化,确保特征值的范围在合适的区间内,不会因为某一部分的特征值过大或过小而影响后续的计算。
3. 消除特征通道之间的偏差
LayerNorm通过对特征进行归一化处理,消除了不同通道之间的数值偏差,使得后续的操作(如特征融合或注意力计算)能够更加准确和高效。这一步非常重要,尤其是在FSA和SSA两个域间融合时,确保特征在统一的尺度上进行计算。
具体解释LayerNorm在图中两个位置的作用:
第一个LayerNorm(在FSA和SSA之前)
- 作用:在输入特征进入FSA和SSA之前,首先经过LayerNorm。这一步确保输入到自注意力模块的特征是归一化后的特征,避免在频率域或空间域中的操作因特征值过大或不均匀分布而导致计算不稳定。这一归一化操作为后续的自注意力机制提供了更稳定的输入。
第二个LayerNorm(在EFFN之前)
- 作用:第二个LayerNorm出现在FSA和SSA输出后、EFFN之前。此时,FSA和SSA生成的特征可能存在较大的数值差异(因为来自不同域),再一次归一化确保这些特征能够在同一个标准下进行特征融合。通过归一化后的特征输入到EFFN中,可以更有效地进行频率域与空间域特征的交互和融合。
总结:
- FSA和SSA负责在频率域和空间域对特征进行增强。
- EFFN负责将增强后的特征进行深度融合。
- LayerNorm的作用是在特征增强和融合过程中,确保特征值分布的稳定性和一致性,从而提高模型的训练稳定性和收敛速度。
这两次LayerNorm的使用非常重要,帮助特征在每个阶段都保持稳定和可控。
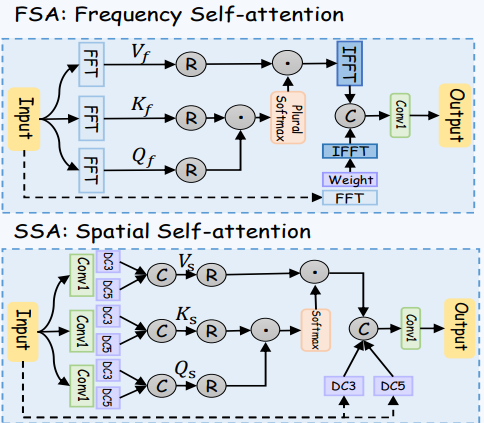
为什么图中都需要 Reconstruction 操作?
在图中,FSA(频率自注意力)和SSA(空间自注意力)模块中都引入了Reconstruction(重构)操作,这在自注意力机制的架构中是一个常见且关键的步骤。Reconstruction的主要作用是通过将注意力权重应用到**值特征(Value)**上来重构和优化输入特征,从而生成更有表现力的特征表示。
1. Reconstruction的基本工作原理
在注意力机制中,输入特征通常会被分解为三个部分:
- Query(查询,Q):用于与键比较以计算注意力权重。
- Key(键,K):与查询进行相似性计算。
- Value(值,V):被加权的特征,通过注意力权重对值特征进行加权求和后生成最终输出。
Reconstruction操作就是将计算得到的注意力权重应用到值特征上,即通过加权求和操作来生成增强后的特征表示。
2. FSA中的Reconstruction
在FSA(频率自注意力)模块中,特征首先经过快速傅里叶变换(FFT)进入频率域,得到Q_f(查询)、K_f(键)和V_f(值)。接下来,系统会计算Q和K的相似性,生成注意力权重矩阵,表示频率域中不同特征分量之间的相关性。
- Reconstruction在这里的作用是:将计算得到的注意力权重应用到**V_f(值)**上,通过加权求和生成一个新的频率域特征表示。这一过程的目的是优化频率特征,突出那些在频率域中更有意义的全局模式。
- 之后,通过逆快速傅里叶变换(IFFT),将这些优化后的频率特征转换回空间域,从而得到融合了频率信息的特征表示。
3. SSA中的Reconstruction
在SSA(空间自注意力)模块中,输入特征直接在空间域进行处理,生成Q_s(查询)、K_s(键)和V_s(值)。类似于FSA,SSA模块也通过Q和K计算注意力权重矩阵,表示空间域中不同像素之间的依赖关系。
- Reconstruction在SSA中的作用同样是:将计算得到的注意力权重应用到**V_s(值)**上。通过这种方式,模型能够加强那些在空间域中相关性较强的像素,使得模型在空间域的特征表示更具区分性。
- 通过Reconstruction后的特征在空间域内能够捕捉到更清晰的局部细节和长距离依赖关系,从而提升伪装目标的边界识别能力。
4. Reconstruction的总体作用
无论是在FSA还是SSA中,Reconstruction的作用都是至关重要的,因为它是注意力机制的核心操作。其具体作用可以总结为:
- 重构输入特征:通过将注意力权重应用到值特征上,模型可以重新构建输入特征,使得特征经过自注意力机制处理后更加敏感于全局模式(FSA中的频率特征)或局部模式(SSA中的空间特征)。
- 增强有用信息:Reconstruction通过加权求和突出那些与其他特征关系密切的特征,增强与任务相关的有用信息,同时抑制无关或冗余信息。
5. 总结
- 在FSA中,Reconstruction用于通过频率域中的注意力权重来优化值特征,从而增强全局频率信息。
- 在SSA中,Reconstruction用于通过空间域中的注意力权重来优化值特征,从而提升局部细节信息和像素间的长距离依赖。
总体而言,Reconstruction是自注意力机制中关键的操作步骤,确保通过计算得到的注意力权重能够有效地优化输入特征,使模型更具感知能力和特征表示能力。
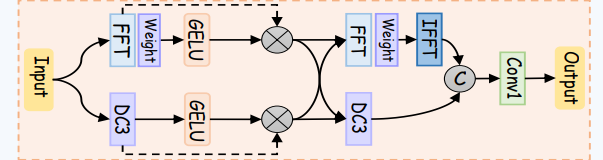
这张图展示了Entanglement Feed-forward Network(EFFN)模块的结构,这是纠缠Transformer块(ETB)中的核心模块之一。该模块的主要作用是将空间域特征和频率域特征进行深度融合。接下来,我将详细解释图中的每个步骤,以及空间域和频率域特征是如何结合在一起的。
1. 输入特征
- 图的左侧是输入特征(Input),输入的特征同时被分为两条路径,一条用于处理频率域特征,另一条用于处理空间域特征。
2. 频率域处理路径
- FFT(快速傅里叶变换):首先,输入特征通过FFT被转换到频率域。通过FFT,特征会被表示为多个频率分量,从而捕捉到输入特征的全局模式。
- Weight(加权处理):在频率域中,特征通过一个可学习的加权矩阵进行处理。这个权重矩阵用于调整不同频率分量的贡献,帮助模型选择性地增强某些频率分量的信息。
- GELU激活函数:加权处理后的特征通过GELU激活函数,引入非线性,使得频率特征的表达更加复杂和丰富。
- 乘法操作:之后,经过FFT路径和GELU处理的特征进行一次逐元素的乘法操作,用于进一步增强特征之间的非线性关系。
3. 空间域处理路径
- DC3(深度可分离卷积,Depth-wise Convolution):输入特征的另一路经过3×3的深度可分离卷积(DC3)。深度可分离卷积是对空间域中的特征进行轻量化卷积操作,能够高效地提取局部信息,特别适合处理空间域中的像素级信息和细节。
- GELU激活函数:与频率路径相同,经过DC3卷积后的特征也通过GELU激活函数进行非线性处理。
- 乘法操作:同样,空间域中的特征也进行一次逐元素的乘法操作。
4. 特征融合(Fusion)
- 在频率域和空间域特征分别经过各自路径的处理后,两条路径的特征通过**逐元素加法操作(element-wise addition)**进行融合。这个步骤将经过增强的频率信息和空间信息结合在一起,使得生成的特征既保留了全局的频率特征,也保留了局部的空间特征。
5. 再次处理频率域信息
- FFT/Weight/IFFT:融合后的特征再次通过FFT转换到频率域,进行一次加权处理,进一步优化频率信息。然后,通过**IFFT(逆傅里叶变换)**将这些频率域特征转换回空间域,使得最终的特征融合了两次频率信息和两次空间信息。
6. 最终输出
- 最终,融合后的特征通过1×1卷积(Conv1)处理。1×1卷积的作用是调整通道数,使得输出特征的通道数与后续网络结构匹配。输出的特征已经包含了频率域和空间域的深度融合信息,用于后续的检测和分割任务。
融合的机制与优势
在EFFN模块中,频率域和空间域的特征通过多个步骤进行融合:
- 频率域特征负责捕捉全局模式,能够检测到伪装目标的全局结构或重复模式。
- 空间域特征负责提取局部细节,特别是伪装目标的边缘和纹理信息。
通过多次FFT/IFFT和卷积操作,EFFN模块确保了这两种特征能够紧密结合,生成既具备全局感知能力、又具备细节捕捉能力的强大特征表示。
总结:
- 频率域路径通过FFT、加权和非线性处理捕捉全局特征。
- 空间域路径通过深度可分离卷积和非线性处理捕捉局部特征。
- 两者在逐元素加法操作后进行融合,并通过再次FFT/IFFT转换增强频率信息。
- 最终通过1×1卷积生成融合后的输出特征。
这种设计确保了频率特征和空间特征能够深度融合,为模型提供强大的特征表示能力。
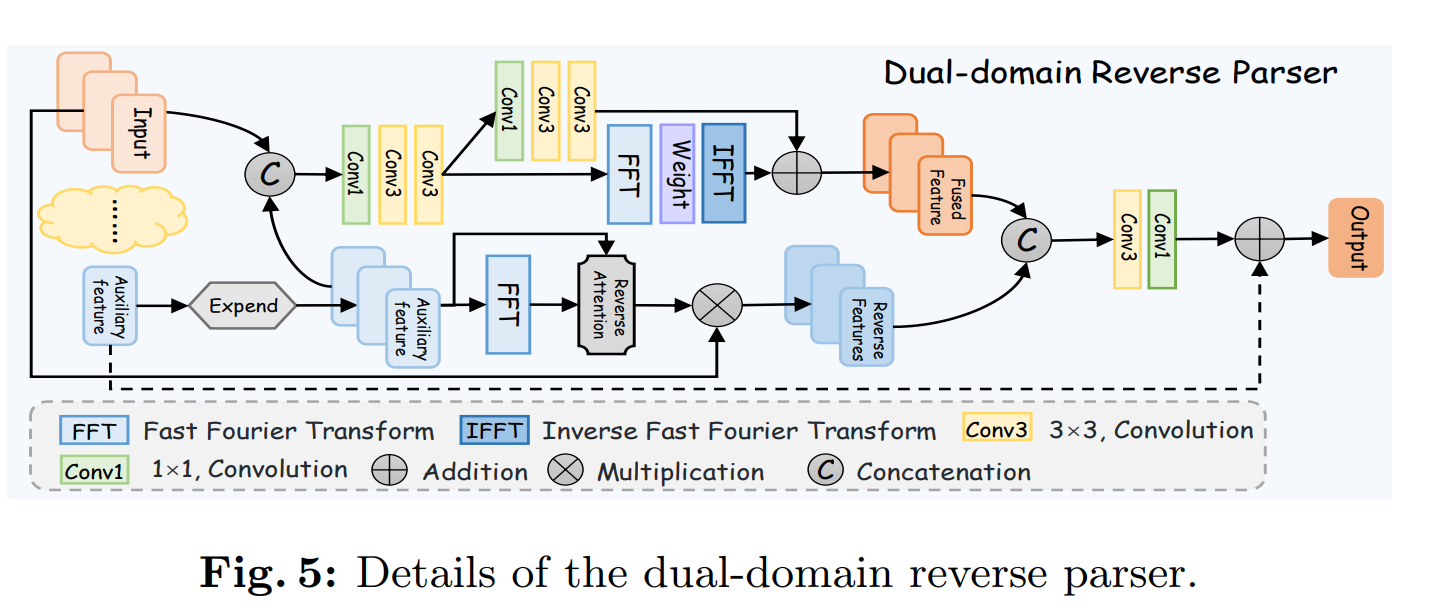
Auxiliary Feature 既和编码器和ETB模块输入的特征进行concatenate融合,又生成注意力权重来对输入的特征进行赋权。这里的 Auxiliary Feature 推测应该是边缘 边界 纹理 等辅助特征,最后还参与残差连接来增强融合特征,实现细化分割。之所以这里还需要分别经过空间域和频率域进一步融合特征,是因为DRP模块接收2个输入,分别是ETB模块输入的特征和上一个DRP模块输出的特征,需要对这二者进行融合。
实现细节
-
硬件和框架:
- 该模型是在PyTorch框架下实现的,并且使用了四块NVIDIA GTX 4090 GPU,每块GPU拥有24GB的显存。这意味着实验环境是非常强大的计算平台,能够处理较大规模的数据和模型。
-
编码器(Encoder):
- 模型使用了预训练的编码器,其中包括PVTv2、ResNet50和Res2Net等架构。预训练模型在图像分类等任务上已经经过了训练,能够从图像中提取出高质量的初始特征,缩短训练时间并提高特征提取的质量。
-
数据增强:
- 实验中使用了数据增强技术,包括随机翻转(random flipping)和随机裁剪(random clipping)。这些数据增强方法通过对输入图像进行随机的操作,生成不同形式的训练样本,以提高模型的泛化能力,防止模型过拟合。
-
优化器和学习率策略:
- 模型使用了Adam优化器,初始学习率为1e-4(0.0001)。Adam优化器是一种常用的优化方法,能够动态调整每个参数的学习率,从而加速收敛。
- 学习率衰减:每经过60个epoch,学习率会衰减10倍。这种学习率调整策略能够确保模型在早期阶段进行较大步幅的学习,而在后期进行更细微的调整,有助于提升模型的收敛性和精度。
-
输入图像和批量大小:
- 所有的输入图像被调整为416×416像素。这说明输入的图像大小是固定的,通过调整尺寸,确保模型可以处理不同分辨率的图像输入。
- 批量大小(Batch size)被设定为40,也就是说每次模型迭代时会处理40张图像。
-
训练周期:
- 模型总共训练了180个epoch。这是相对较长的训练周期,尤其是在如此强大的硬件平台上运行,意味着模型有足够的时间进行充分训练。
总结:
- 实验使用了强大的硬件平台和预训练模型,结合数据增强技术和学习率衰减策略,来提高模型的训练效率和性能。输入图像被标准化为416×416,并且每个批次处理40张图像,整个训练过程持续了180个epoch。这些设置保证了模型可以在复杂的伪装目标检测任务中取得优异的性能。
在阅读这篇论文之后,对你有哪些启发?
作为一名研究方向为**伪装目标检测(COD)**的硕士研究生,阅读这篇论文后,有以下几个关键点启发了我,帮助我在设计自己的COD模型时有了新的思路和改进方向:
1. 频率域与空间域的结合
-
启发:论文通过引入频率域和空间域特征的结合,利用自注意力机制分别在两个域中增强特征表示。这让我意识到,伪装目标检测任务不应仅依赖于空间特征(即传统的卷积操作),频率域的全局信息(例如通过快速傅里叶变换获取的频率特征)也同样重要。
-
改进思路:在设计自己的COD模型时,我可以尝试结合频率域的全局特征与空间域的局部特征,特别是可以通过类似FFT/IFFT的变换,探索全局模式的特征,并与卷积网络生成的空间特征进行融合。
2. 自注意力机制的使用
-
启发:论文中的**频率自注意力(FSA)和空间自注意力(SSA)**机制分别在频率和空间域中增强特征表示,使模型能够更好地理解目标和背景之间的复杂关系。
-
改进思路:自注意力机制在COD任务中的作用是显著的。自注意力机制能够捕捉到远距离像素之间的关系,可以帮助模型更好地分辨伪装目标的细节。我可以设计自己的多层自注意力机制,不仅仅在频率和空间域,还可以尝试在不同的尺度、层次或模态中进行自注意力的应用,以提升模型的表现。
3. 多尺度特征提取
-
启发:论文中的Joint Domain Perception Module (JDPM) 模块类似于ASPP,通过不同膨胀率的卷积提取多尺度特征。这让我认识到,COD任务中的伪装目标在不同尺度上可能具有不同的表现形式,单一尺度的特征提取不足以捕捉目标的多样性。
-
改进思路:设计一个多尺度特征提取模块,不仅可以通过膨胀卷积来实现多尺度感受野,还可以引入不同尺度的特征融合策略,确保模型能够从多层次、多尺度中捕捉目标的形态信息。
4. 双域反向解析器(DRP)
-
启发:DRP模块通过反向注意力机制以及频率域和空间域的结合,帮助模型进一步优化解码器阶段的特征,尤其在边缘信息和细节信息上进行了显著增强。
-
改进思路:在设计解码器时,我可以借鉴DRP的思想,不仅简单地通过跳跃连接进行特征融合,还可以通过反向注意力机制结合多源信息,特别是引入低分辨率的语义特征与高分辨率的细节特征之间的交互,提升模型对细节的敏感度。
总结:
通过阅读这篇论文,我获得了许多关于如何设计高效COD模型的启发。包括频率和空间域的特征融合、自注意力机制的使用、多尺度特征提取、反向解析器的改进等技术手段。这些思想让我对伪装目标检测模型的设计有了更深刻的理解,并为我后续的研究工作提供了宝贵的思路。


















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









