







动机
- 挑战性任务:伪装物体检测(Camouflaged Object Detection, COD)是计算机视觉中的一个挑战性任务,由于伪装物体与其背景的高度相似,现有的方法在检测边界和防止过于自信的错误预测方面表现不佳。
- 现有方法的不足:目前的COD方法在处理细微的物体边界和避免过于自信的错误预测方面存在困难。这导致了在实际应用中的性能限制。
- 引入扩散模型:扩散模型在生成能力和条件感知方面表现出色,其迭代的噪声消除机制适合处理COD任务的复杂性。然而,直接应用扩散模型存在辨别能力有限和掩膜细化不足的问题。
贡献
- 新颖的框架:提出了一个新的框架CamoDiffusion,将COD视为一个条件掩膜生成任务,利用扩散模型来生成预测。
- 网络架构设计:提出了一种自适应Transformer条件网络(Adaptive Transformer Conditional Network, ATCN)来增强模型的表达能力,通过引入指导提示来区分复杂边界的伪装物体。
- 训练策略:设计了基于信噪比(SNR)的方差计划、结构破坏和一致时间集成等训练策略,以提高模型的特征探索和纠正能力。
- 采样策略:提出了一种一致时间集成(Consensus Time Ensemble, CTE)策略,通过结合多个采样步骤的预测,增强了结果的精确性和可靠性。
- 优越性能:在三个COD数据集上的广泛实验表明,该模型在性能上优于现有的最先进方法,特别是在最具挑战性的COD10K数据集上,其MAE值达到了0.019。
创新点
- 条件掩膜生成任务:首次将COD任务视为一个条件掩膜生成问题,利用扩散模型的去噪过程逐步修正预测。
- 自适应Transformer条件网络(ATCN):通过引入零重叠嵌入(Zero Overlapping Embedding, ZOE)和时间令牌拼接(Time Token Concatenation, TTC),动态地提取辨别特征。
- 结构破坏策略(Structure Corruption):在训练过程中,通过随机破坏GT的轮廓并加入高斯噪声,增强模型对细微边界的纠正能力。
- 一致时间集成(CTE):通过结合不同采样步骤的预测,降低了过于自信的错误分割,提高了预测的可靠性。
这些动机、贡献和创新点共同构成了这篇论文的核心内容和创新价值,为伪装物体检测提供了一种新的视角和方法。
如何理解论文中的这句话:
Due to the stochastic sampling process of diffusion, our model is
capable of sampling multiple possible predictions, avoiding the
problem of overconfident point estimation.
这句话的意思是:由于扩散模型的随机采样过程,模型能够生成多种可能的预测结果,从而避免了过于自信的点估计问题。以下是对此的详细解释:
扩散模型的随机采样过程
扩散模型的工作原理是通过逐步去除噪声来生成数据,这个过程是随机的。这意味着,每次运行扩散过程时,模型可能会产生不同的预测结果。这个特性使得模型在给定输入时不会只输出一个确定的结果,而是可以生成多种可能的结果。
多种预测结果
由于这个随机过程,模型可以对同一输入生成多种不同的掩膜预测。比如,对于一幅包含伪装物体的图像,模型在不同的采样过程中可能会生成几种略有不同的物体边界。这些不同的预测结果可以反映出模型在边界判断上的不确定性。
避免过于自信的点估计问题
传统的伪装物体检测方法通常会输出一个确定的掩膜结果,这种结果可能会对某些边界位置产生过于自信的预测,即模型认为某个位置一定是边界或者一定不是边界。然而,实际上边界位置可能具有较大的不确定性。扩散模型通过生成多种预测结果,可以更好地捕捉到这种不确定性,从而避免过于自信的点估计问题。
具体优势
- 反映不确定性:通过生成多种预测结果,模型可以量化和反映出边界区域的不确定性。
- 提高鲁棒性:在实际应用中,利用多种预测结果的综合,可以提高最终结果的鲁棒性,减少错误预测。
- 更好的性能:相比于单一的确定性预测,多种预测结果可以通过集成策略(如一致时间集成,CTE)来提高最终预测的准确性和可靠性。
总结
通过利用扩散模型的随机采样过程,CamoDiffusion模型能够生成多种可能的预测结果,这有助于捕捉和反映边界区域的预测不确定性,从而避免传统方法中因过于自信的点估计所导致的错误,提高伪装物体检测的准确性和可靠性。
通俗地总结这篇论文提出的方法
这篇论文提出了一种名为CamoDiffusion的方法,用于检测伪装的物体。以下是通俗易懂的总结:
主要问题
伪装物体检测很难,因为这些物体与它们的背景非常相似,现有的方法在区分这些物体的边界和防止错误检测上表现不佳。
方法概述
CamoDiffusion方法利用了一种叫做“扩散模型”的先进技术,来逐步改进和生成伪装物体的检测结果。这种方法通过添加和去除噪声,逐步从初始的粗略预测变成精确的结果。
方法细节
-
扩散模型的引入:扩散模型通过逐步减少图像中的噪声来生成更精确的结果。这种方法避免了现有方法中的过度自信错误预测问题。
-
自适应Transformer条件网络(ATCN):这个网络帮助提取图像中的重要特征,并在每一步去噪过程中,利用这些特征来更好地识别伪装物体。通过加入一个初步预测的掩膜作为指导,网络能够更准确地关注特定区域。
-
训练和采样策略:
- 信噪比(SNR)调整:在训练过程中,通过调整噪声的比例,让模型在更困难的条件下进行学习,从而提升模型的特征提取能力。
- 结构破坏(Structure Corruption):在训练时随机破坏真实标签的轮廓,然后加入噪声,让模型学会在不完整的信息下进行准确预测。
- 一致时间集成(CTE):在最终生成结果时,结合多个步骤的预测,减少错误,提高结果的可靠性。
效果
这种方法在三个标准的数据集上进行了测试,表现出了优于现有方法的效果,特别是在处理复杂和细致的伪装物体时表现突出。
总结
CamoDiffusion通过引入扩散模型和一系列创新的网络设计和训练策略,成功解决了现有伪装物体检测方法中的很多问题,使得检测结果更加准确和可靠。
Fig.1
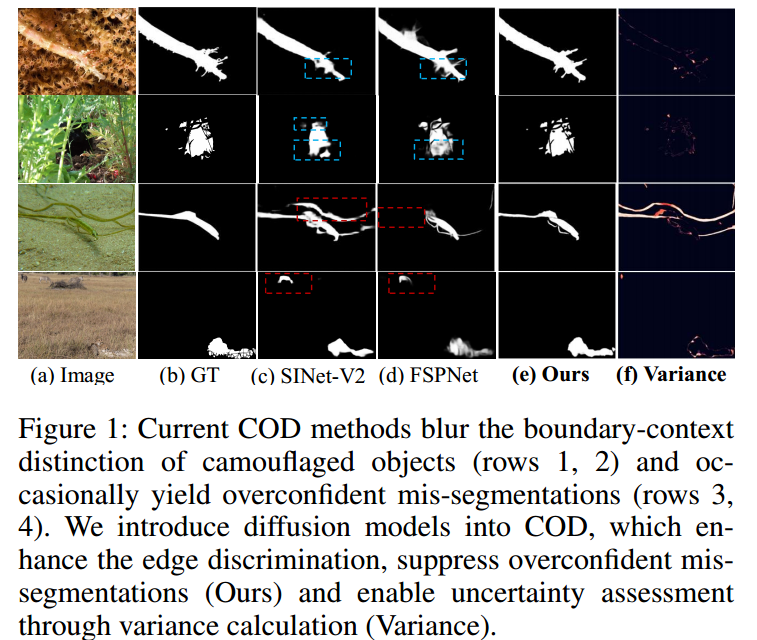
这张配图展示了不同伪装物体检测(COD)方法的比较,包括传统方法和本文提出的方法。以下是对各部分的详细解释:
图像内容解释
每行代表一组对比实验,每列展示不同的方法及其结果:
- (a) Image:原始输入图像。
- (b) GT:真实标签(Ground Truth),即实际的伪装物体的掩膜。
- © SINet-V2:一种现有的COD方法的结果。
- (d) FSPNet:另一种现有的COD方法的结果。
- (e) Ours:本文提出的CamoDiffusion方法的结果。
- (f) Variance:通过方差计算得到的结果,用于评估模型预测的不确定性。
行内容解释
每行代表一个具体的测试样例,从中可以看到不同方法在检测伪装物体时的表现:
- 第一行和第二行:展示了当前COD方法(如SINet-V2和FSPNet)在伪装物体边界和背景区分上的模糊表现。这些方法容易导致物体边界和背景之间的混淆。
- 第三行和第四行:展示了当前COD方法(如SINet-V2和FSPNet)在某些情况下产生过度自信的错误分割结果(红色虚线框内)。
详细解释
-
模糊边界:
- 第一行和第二行展示了伪装物体的边界在SINet-V2和FSPNet方法中的模糊表现。这些方法无法清晰地区分伪装物体的边界和背景,导致边界模糊。
- CamoDiffusion方法(Ours) 在这些情况下表现出更好的边界区分能力,能够更清晰地分割出伪装物体。
-
过度自信的错误分割:
- 第三行和第四行展示了在SINet-V2和FSPNet方法中,模型产生了过度自信的错误分割结果。这些方法错误地将背景区域标记为物体,导致错误的高置信度分割(红色虚线框内)。
- CamoDiffusion方法(Ours) 通过引入扩散模型,有效抑制了这些过度自信的错误分割,生成更准确的分割结果。
-
方差计算(Variance):
- 方差图(f列) 展示了CamoDiffusion方法的方差计算结果。这些图展示了模型在不同区域的预测不确定性。高方差区域表示模型在这些区域存在更高的不确定性,这对于评估模型预测的可靠性非常重要。
总结
这张图通过多个具体样例,直观展示了现有COD方法(SINet-V2和FSPNet)在处理伪装物体检测时存在的主要问题(如边界模糊和过度自信的错误分割),并突出了本文提出的CamoDiffusion方法在这些方面的显著改进。通过引入扩散模型,CamoDiffusion能够更好地处理边界区分问题,并通过方差计算评估预测的不确定性,从而提高了伪装物体检测的准确性和可靠性。
Fig.2
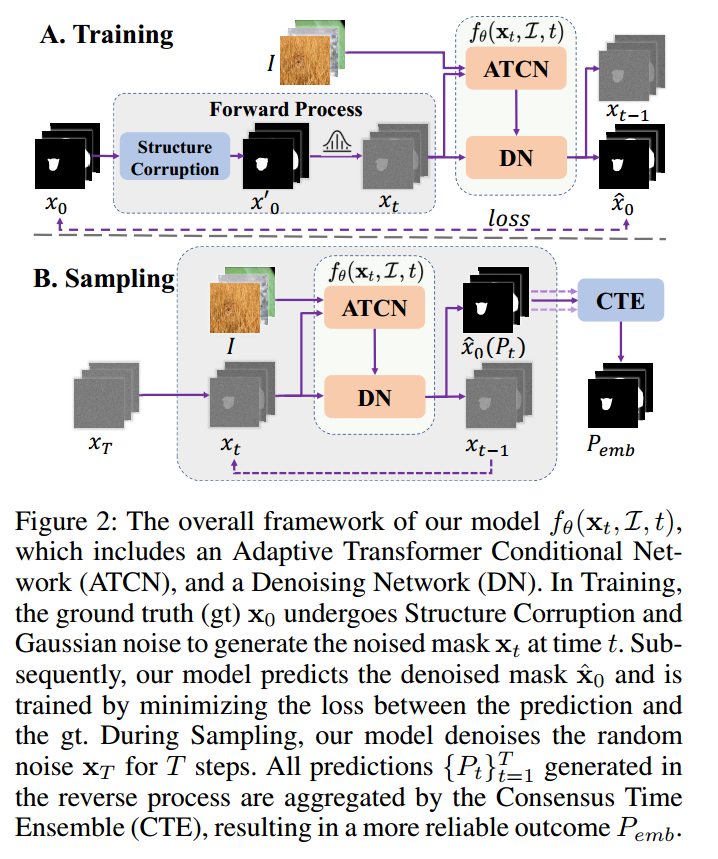
这张配图展示了论文中CamoDiffusion模型的整体框架,包括训练和采样过程。以下是对每个部分的详细解释:
A. 训练 (Training)
-
输入与前向过程(Forward Process):
- 输入真实标签(x0x_0x0):这是实际的伪装物体掩膜。
- 结构破坏(Structure Corruption):将真实标签进行结构破坏,使得标签变得不完整,然后添加高斯噪声生成噪声掩膜(xtx_txt)。
- 噪声掩膜生成(xtx_txt):这是在不同时间步(ttt)生成的噪声掩膜。
-
网络架构:
- 自适应Transformer条件网络(ATCN):提取图像特征并将其作为条件输入给去噪网络(DN)。
- 去噪网络(DN):根据输入图像特征和噪声掩膜,预测去噪后的掩膜(x^0\hat{x}_0x^0),并根据损失函数进行优化。
-
损失函数(Loss):模型通过最小化预测掩膜和真实标签之间的损失来进行训练,从而不断优化模型参数。
B. 采样 (Sampling)
-
输入与采样过程:
- 初始噪声(xTx_TxT):从标准正态分布中随机抽取的噪声图像。
- 逐步去噪(Denoising):模型在每一步中使用ATCN提取的图像特征和去噪网络(DN)逐步减少噪声,生成中间去噪掩膜(xt−1x_{t-1}xt−1)。
-
一致时间集成(CTE):
- 多次预测({ Pt}t=1T\{P_t\}_{t=1}^T{ Pt}t=1T):在去噪过程中,生成多个不同时间步的预测结果。
- 结果集成(CTE):将这些预测结果进行集成,得到最终的更可靠的掩膜(PembP_{emb}Pemb)。
图解说明
- 上半部分 A. 训练 展示了训练过程,包含从真实标签到生成噪声掩膜再到预测去噪掩膜的完整流程。
- 下半部分 B. 采样 展示了模型在推理阶段的工作流程,从随机噪声开始,通过多步去噪过程最终生成可靠的掩膜。
通过这两个过程,CamoDiffusion模型能够有效地在训练和推理过程中处理伪装物体检测的挑战,逐步提高检测精度并减少错误预测。
Fig.3
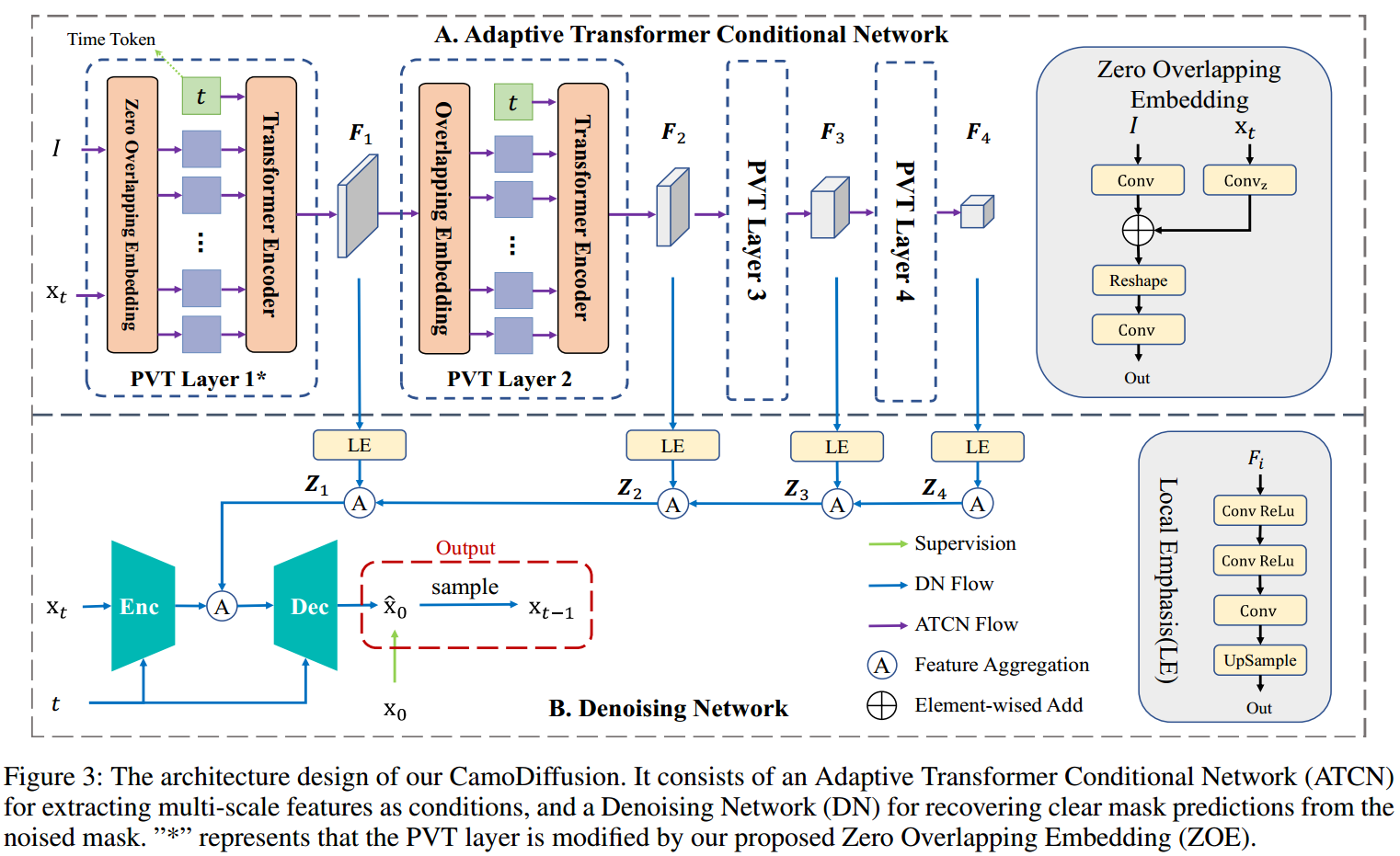
这张配图展示了CamoDiffusion模型的架构设计,包括自适应Transformer条件网络(Adaptive Transformer Conditional Network, ATCN)和去噪网络(Denoising Network, DN)。下面是对各个部分的详细解释:
A. 自适应Transformer条件网络(ATCN)
ATCN的作用是提取多尺度特征作为条件输入,用于去噪网络中恢复清晰的掩膜预测。具体过程如下:
-
输入与处理:
- 输入图像(III)和噪声掩膜(xtx_txt):这些是模型的初始输入。
- 时间令牌(Time Token):表示当前去噪过程中的时间步。
-
PVT层:
- PVT Layer 1:使用零重叠嵌入(Zero Overlapping Embedding, ZOE)模块将输入图像和噪声掩膜嵌入到Transformer编码器中,生成多尺度特征(F1F_1F1)。
- PVT Layer 2-4:这些层逐步处理特征图,每一层通过重叠嵌入模块将特征输入到Transformer编码器中,生成更高层次的特征(F2,F3,F4F_2, F_3, F_4F2,F3,F4)。
-
特征聚合(Feature Aggregation):
- 本地强调模块(Local Emphasis, LE):用于上采样和卷积处理,从每个PVT层中提取的特征图(FiF_iFi)。
- 特征聚合(Z1, Z2, Z3, Z4):特征图通过本地强调模块进行处理和聚合,以便进一步用于去噪网络。
B. 去噪网络(DN)
DN的作用是根据输入图像特征和噪声掩膜,逐步去除噪声,生成清晰的掩膜预测。具体过程如下:
-
编码器(Enc)和解码器(Dec):
- 编码器(Enc):将噪声掩膜(xtx_txt)和时间令牌(ttt)进行编码,生成中间表示。
- 解码器(Dec):将编码后的表示结合聚合特征(Z1Z1Z1)进行解码,生成去噪后的掩膜预测(x^0\hat{x}_0x^0)。
-
输出与采样:
- 采样(Sample):在每个时间步(ttt)生成去噪后的掩膜(xt−1x_{t-1}xt−1),并将其作为下一个时间步的输入,逐步去除噪声。
- 监督(Supervision):最终的去噪掩膜与真实标签(x0x_0x0)进行比较,计算损失,指导模型训练。
零重叠嵌入(Zero Overlapping Embedding, ZOE)
ZOE模块用于将噪声掩膜嵌入到PVT层中,同时保留图像的位置信息。具体步骤如下:
- 卷积层(Conv)和零初始化卷积层(Convz):将图像和噪声掩膜分别进行卷积处理。
- 元素相加(Element-wise Add):将处理后的图像特征和噪声掩膜特征相加。
- 重塑(Reshape):将相加后的特征重塑为适合Transformer编码器的输入。
- 输出(Out):生成嵌入的特征图,输入到PVT层的Transformer编码器中。
本地强调(Local Emphasis, LE)
LE模块用于对特征图进行上采样和卷积处理,以便在特征聚合步骤中使用。具体步骤如下:
- 卷积和ReLU(Conv ReLU):对特征图进行卷积处理,并应用ReLU激活函数。
- 上采样(UpSample):将处理后的特征图上采样到所需尺寸。
总结
这张图展示了CamoDiffusion模型的详细架构,包括特征提取、特征聚合和去噪过程。通过自适应Transformer条件网络和去噪网络的结合,模型能够逐步去除噪声,生成更准确的伪装物体检测结果。
这张图展示了CamoDiffusion模型的详细架构,包括特征提取、特征聚合和去噪过程。通过自适应Transformer条件网络和去噪网络的结合,模型能够逐步去除噪声,生成更准确的伪装物体检测结果。
Method
Background and Notation
背景和符号(Background and Notation)
背景
论文的CamoDiffusion方法基于扩散模型,该模型包括一个正向过程和一个反向过程:
- 正向过程(Forward Process):在正向过程中,真实标签(如掩膜)会逐步被噪声化,即加入噪声,从而生成一系列逐步退化的图像表示。
- 反向过程(Reverse Process):在反向过程中,噪声图像会逐步去噪,恢复为目标分布(如原始图像或掩膜)。
符号定义
给定一个训练样本x0∼q(x0)x_0 \sim q(x_0)x0∼q(x0),噪声版本{ xt}t=1T\{x_t\}_{t=1}^T{ xt}t=1T根据以下马尔可夫过程获得:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I)q(xt∣xt−1)=N(xt;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









