







原文链接:https://arxiv.org/abs/2404.02517
1. 引言
目前的端到端多任务3D感知使用高分辨率输入图像、长的时间输入和大的图像编码器,这会导致训练代价高昂。一些方法存储过去帧的信息,但存在时间特征的不一致性和数据增广的低效性。因此,最近的方法重新计算过去帧的特征,进一步增加了训练代价。
此外,很多方法直接沿通道维度求和或拼接BEV时间特征,这会因为运动物体的不对齐而降低感知精度。
第三,端到端多任务学习的现有方法使用共享的编码器和多个解码器,这种联合学习会导致次优性能。
本文提出HENet,一种基于多视图图像的多任务3D感知方法,使用混合图像编码器,对不同帧使用不同的分辨率和图像编码器。具体来说,高分辨率输入、大图像主干和复杂的透视变换网络处理短期帧以生成高精度BEV特征;低分辨率输入、小图像主干和简单透视变换网络处理长期帧以高效生成BEV特征。此外,还提出时间整合模块,对齐和融合多帧BEV特征,包含时间反向和前向过程和相邻帧融合模块(AFFM),使用注意力机制解决运动物体的不对齐问题。最后,本文研究了多任务学习中3D目标检测任务和BEV语义分割任务冲突的原因,发现二者偏好的BEV分辨率不同,因此本文选择不同网格大小的BEV特征,使用独立的BEV编码器和任务解码器。
3. 方法
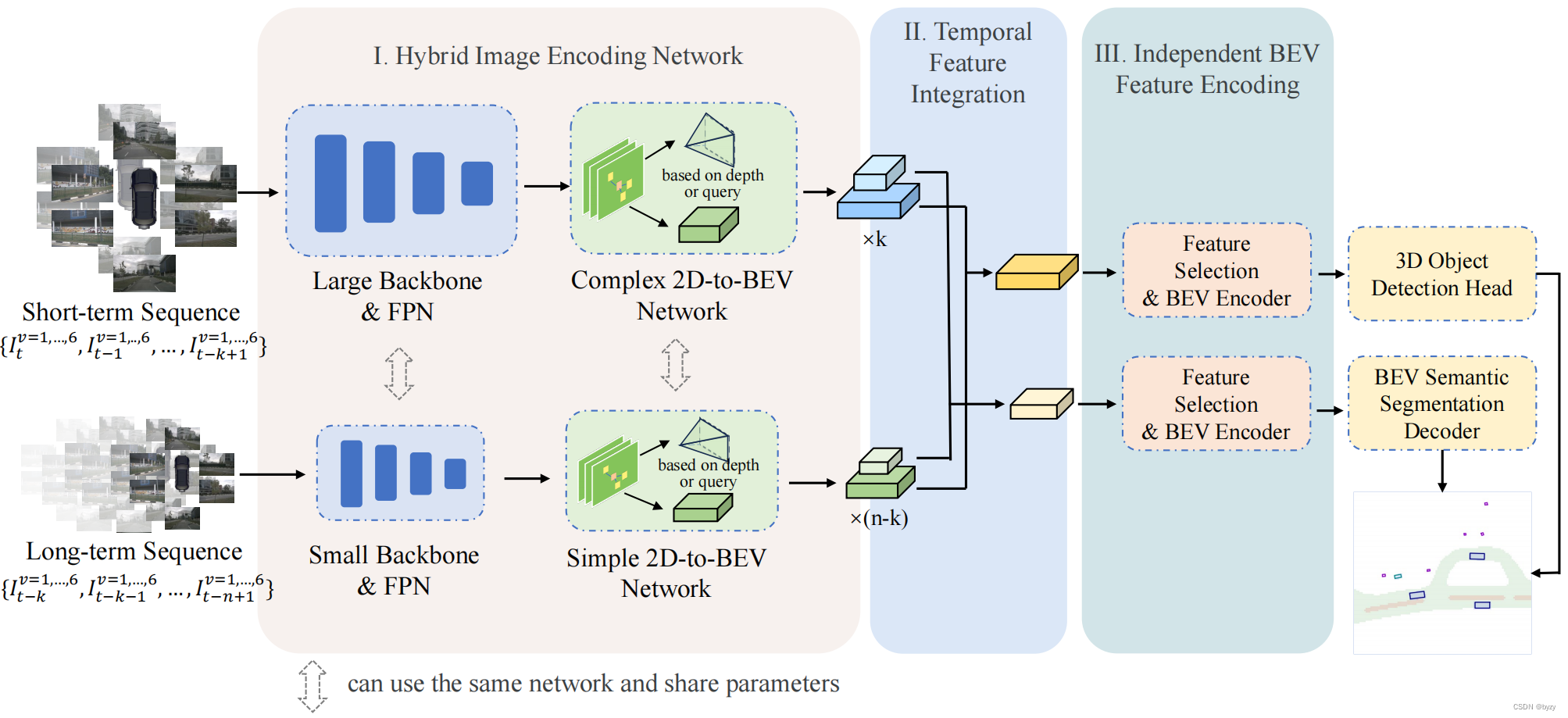
3.1 混合图像编码网络
短期序列使用高分辨率输入、大图像主干和复杂的透视变换网络;长期序列使用低分辨率输入、小图像主干和简单透视变换网络。
3.2 时间特征聚合
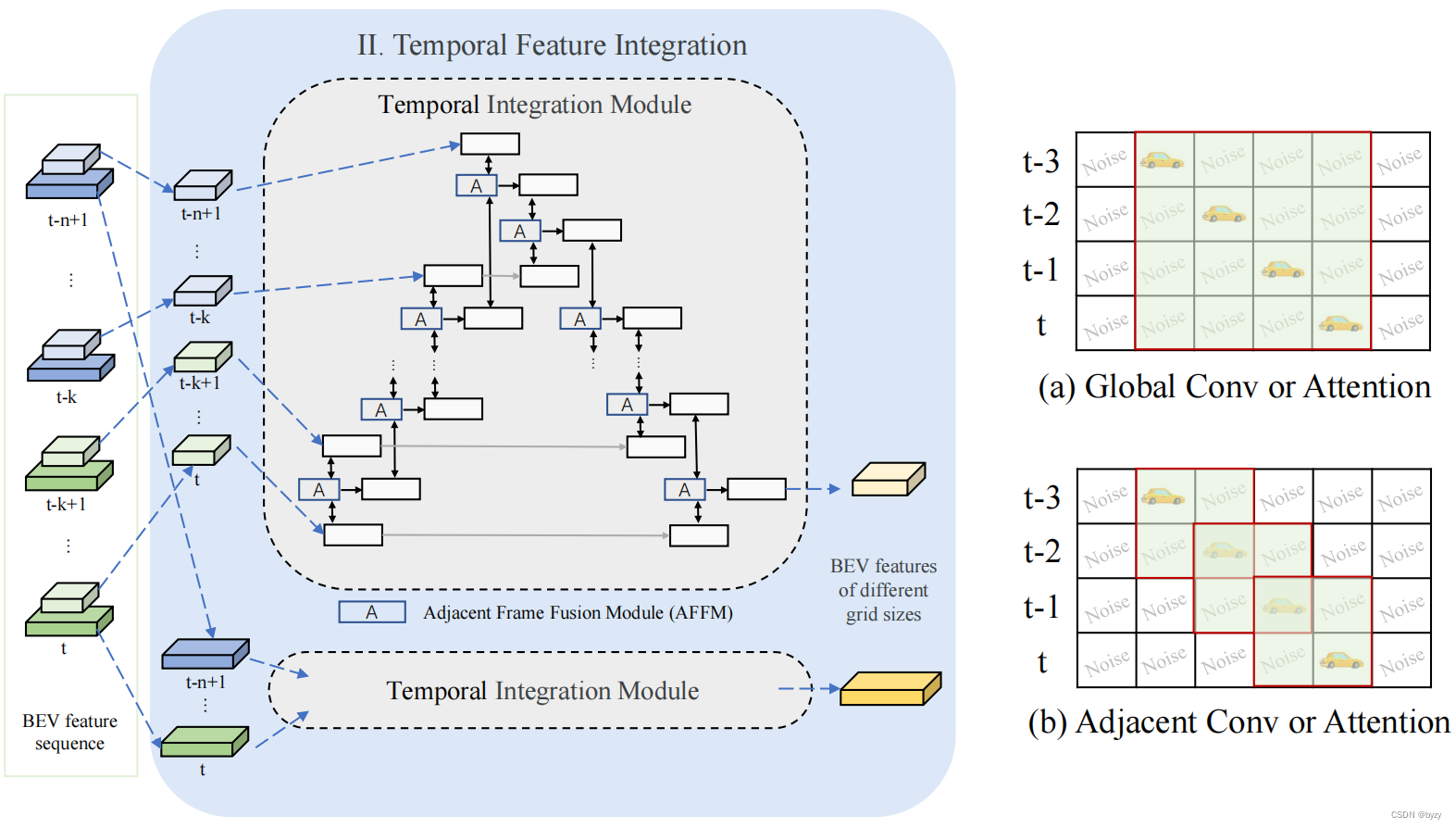
如图所示,时间聚合模块包含反向和前向过程,反向过程将当前帧的特征融合到过去帧;而前向过程将过去帧的特征聚合到当前帧。每个步骤都用到了带交叉注意力的相邻帧融合模块(AFFM)融合相邻帧的特征。具体来说,设两帧BEV特征分别为
f
i
,
f
j
f_i,f_j
fi,fj,则AFFM为
AFFM
(
f
i
,
f
j
)
=
f
j
+
γ
×
Avg
(
Attn
(
<
f
i
,
f
j
>
,
f
i
,
f
i
)
,
Attn
(
<
f
i
,
f
j
>
,
f
j
,
f
j
)
)
\text{AFFM}(f_i,f_j)=f_j+\gamma\times\text{Avg}(\text{Attn}(\left<f_i,f_j\right>,f_i,f_i),\text{Attn}(\left<f_i,f_j\right>,f_j,f_j))
AFFM(fi,fj)=fj+γ×Avg(Attn(⟨fi,fj⟩,fi,fi),Attn(⟨fi,fj⟩,fj,fj))
其中
Avg
(
⋅
)
\text{Avg}(\cdot)
Avg(⋅)为平均操作,
γ
\gamma
γ为可学习缩放参数,
<
⋅
,
⋅
>
\left<\cdot,\cdot\right>
⟨⋅,⋅⟩表示拼接,
Attn
(
⋅
,
⋅
,
⋅
)
\text{Attn}(\cdot,\cdot,\cdot)
Attn(⋅,⋅,⋅)表示注意力模块:
Attn
(
q
,
k
,
v
)
=
softmax
(
q
k
T
d
)
v
\text{Attn}(q,k,v)=\text{softmax}(\frac{qk^T}{\sqrt d})v
Attn(q,k,v)=softmax(dqkT)v
反向过程中, j = i − 1 j=i-1 j=i−1;前向过程中, j = i + 1 j=i+1 j=i+1。
如图(a)(b)所示,相邻注意力会比全局注意力或所有帧的卷积引入更少的噪声。注意这一方法也适用于基于查询的方法。
3.3 独立BEV特征编码
由于不同任务偏好的BEV分辨率不同,本文对不同任务进行独立的BEV编码。本文的编码过程包括自适应特征选择和BEV编码。
自适应特征选择使用通道注意力选择重要特征:
f
adaptive
(
F
)
=
σ
(
W
f
avg
(
F
)
)
⋅
F
f_\text{adaptive}(F)=\sigma(Wf_\text{avg}(F))\cdot F
fadaptive(F)=σ(Wfavg(F))⋅F
其中 F ∈ R X × Y × C F\in\mathbb R^{X\times Y\times C} F∈RX×Y×C为BEV特征, W W W为线性变换矩阵, f avg f_\text{avg} favg表示全局均值池化, σ \sigma σ表示Sigmoid函数。BEV编码器使用残差块和FPN。不同任务的自适应特征选择和BEV编码器结构相同,但网络权重不同。
3.4 解码器和损失
使用CenterPoint作为检测头;使用SegNet作为BEV语义分割头,损失为focal损失。此外,还有深度损失。
4. 实验
4.1 实施细节
训练时,图像主干读取预训练网络的参数。
4.3 主要结果
HENet的性能能超越或达到SotA相当的性能,且每个epoch的训练时间更少;同样的GPU内存下,可使用更多帧数融合。
4.4 端到端多任务3D感知冲突的分析
实验发现,增加输入图像分辨率和时间融合的帧数,两个任务的性能有一致的提升。而BEV分辨率对两任务有不同的影响,这可能是任务的特点导致的。BEV语义分割任务需要聚合全局特征以进行完整的场景理解,因此当BEV分辨率过高时,局部特征的聚合较为困难。而3D目标检测任务则需要高分辨率特征以提供局部细节。
4.5 单任务结果
实验表明,在单任务训练下,本文方法能超过其余单任务方法的性能或达到相当水平。
多任务训练下的结果仅比单任务训练的结果略低,说明独立BEV特征编码这一设计对解决多任务冲突的有效性。
4.6 消融
混合图像编码器:与使用更高分辨率的图像输入和更多帧的融合相比,本文的混合图像编码器能达到更高的性能,且有更短的推断时间和更低的训练代价。两单一图像编码器基准方案的集成会降低性能,因为小主干会引入更多误检。
可视化表明,部分物体或场景需要长时间序列感知;高分辨率和复杂深度估计方法能促进困难物体和场景的感知。
时间特征聚合:比较不同的时间特征聚合方法,本文的相邻注意力能达到比全局操作(全局注意力或拼接+卷积)更高的性能,且参数量更低。
独立BEV特征编码:为不同任务使用不同的BEV分辨率能达到最好的性能;使用任务独立的自适应特征选择和BEV编码器可进一步提高多任务性能。















 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











