







【Lua进阶系列】分割中英文字符串
大家好,我是Lampard猿奋~~
欢迎来到Lua进阶系列的博客,今天和大家分享一下lua如何分割中英文字符串

(1)需求背景
最近接到了一个小需求,就是游戏中一个名称超长了。策划并不想让名字自动换行,也不想挪动其他的UI位置,于是提出了如果超过某长度就将之后的字符隐藏并用省略号代替,比如“AABBCCDD”超长了,想显示成“AABB...”
(2)初次尝试
我一开始的想法是首先定下这个长度的阈值(比如说是140),那么我就判断这个名字UI赋值后是否超过140,不是最好,是的话则按照阈值140除以实际长度,得到应该显示文本的百分比,然后再用名字的总长度乘以这个比值,就算出应该显示多少文本,最后拼接一个“...”就行了

结果显示纯英文或者纯中文的名字没有问题,但是中英结合的名字后面出现了乱码,原因在于string.len拿到的是字符串的字节数,并不是这个字符串有多少个“字”,而英文的字节数是1,中文的字节数是3甚至有一些是4,所以不可以这样子直接去算出显示多少字节,不然这个中文就会显示不全
(3)了解utf8的编码规则
UTF-8 的编码规则很简单:
对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
如下图所示:
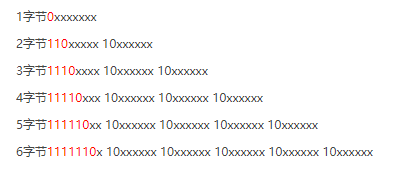
知道这一点之后我们就好办了,其实刚才我是错在了想按照比例算出“字”数,但是实际的操作是按比例算出了字节数,那么我们只需要把这个字符串切割成一个个中英文,就可以知道再根据比率去取舍多少个字了
(4)切割字符串
首先肯定是从第一个字节开始,我们通过string.byte(字符串,1)拿到了第一个字节的数据,然后根据我们上文的utf8的编码规则,如果这个值大于239(1110开头)则这个是个四字节的文本,如果是223到239之间(1110)则是3字节的文本,以此类推到最后字节数小于192(0开头)的,则是1个字节的文本
如果是1就是英文,3或者4就是中文嘛。知道这个文本是多少字节之后,就可以再去读string.byte(字符串,1 + 刚才算出的字节数)是多少字节的,然后一直递归知道字符串被读完为止,就成功把字符串分割啦!!
最后再根据你算出的比例,决定显示多少个数字,再换算出多少字节,通过string.sub就可以读到想要的内容了(项目代码就不方便贴啦)
好啦今天就到这里
点赞,关注!!!

















 2896
2896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











