






作者 | Haodong Li 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/2377911279
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
记录分享一些喜欢&开源的工作的Pipeline,方便后面找codebase
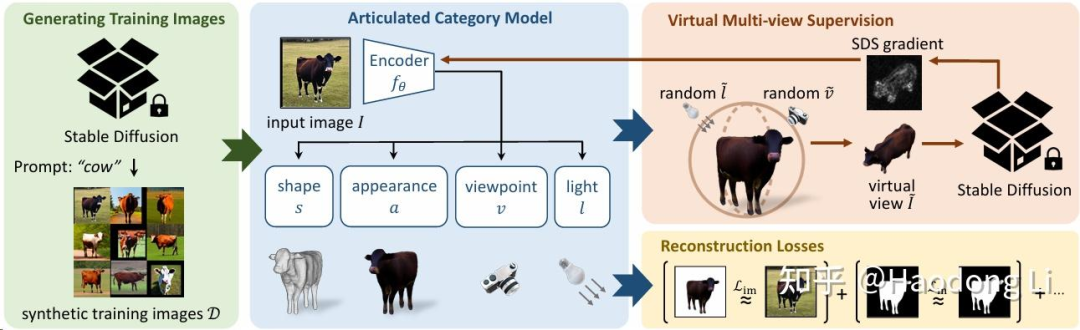
现在主流3D generation model都在利用2D foundation model prior实现lift to 3D,也有一些大公司做出了一些3D Foundation model但都局限于object level,我们离实现pyhsical-alignment/controlable/interactive 4D generation model还有很长的路要走,by the way,这也是我的long-term goal
3D object generate
SyncDreamer
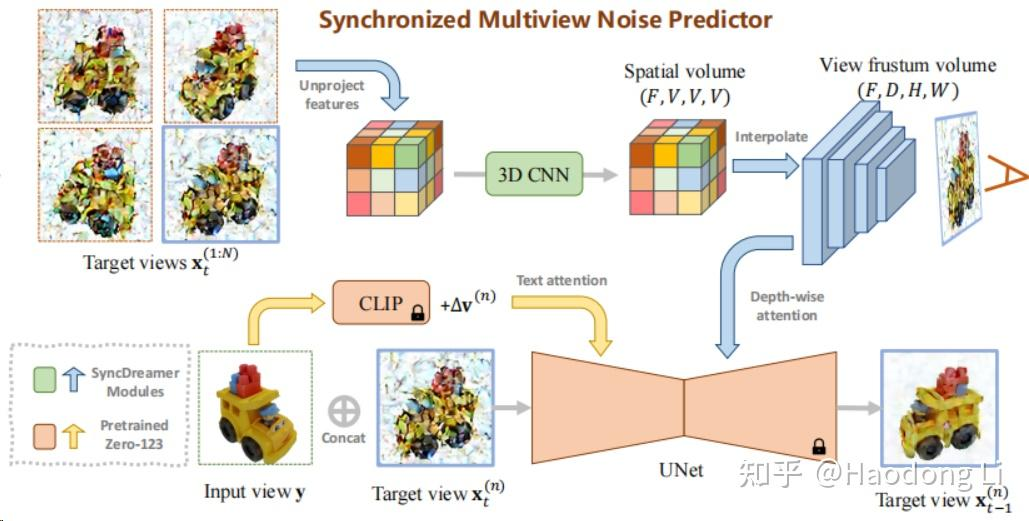
SyncDreamer
在Multiview Diff+NeRF中算做的比较不错的
在Zero-123的backbone中加入cost volume作为condition
Zero123/Zero123++
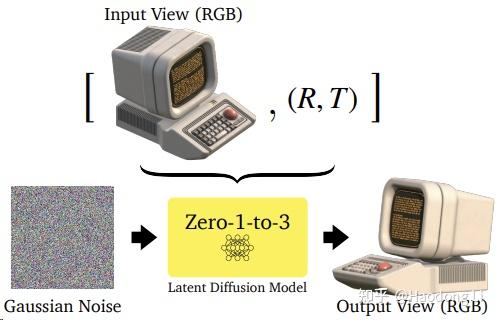
zero123plus
第一个用SD生成Multiview image的工作
Zero123++在engine上加很多design,结果是能生成6个view(知道elevation和azimuth绝对值的)image
Wonder3D
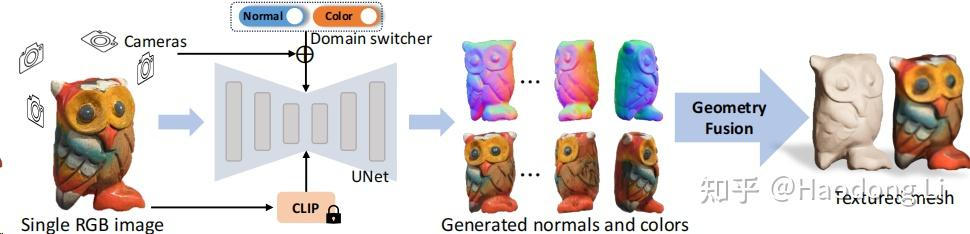
Wonder3D: Single Image to 3D using Cross-Domain Diffusion (xxlong.site)
make-your-3D
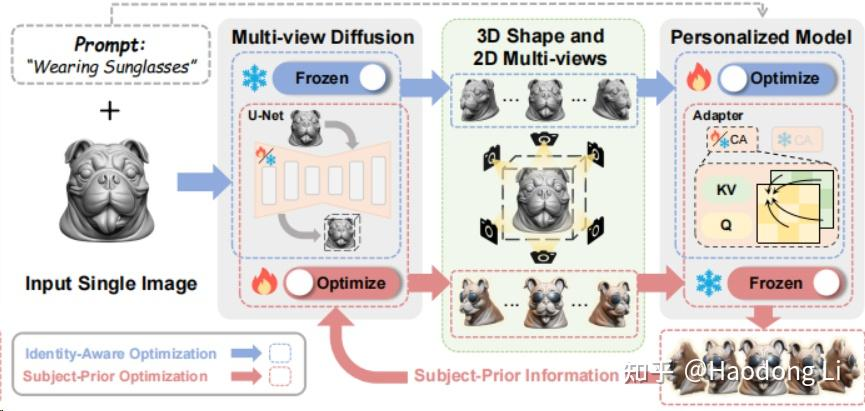
Make-Your-3D: Fast and Consistent Subject-Driven 3D Content Generation (liuff19.github.io)
两个Condition给到两个不同model,可以做相互蒸馏拉到同一个Distribution
LGM
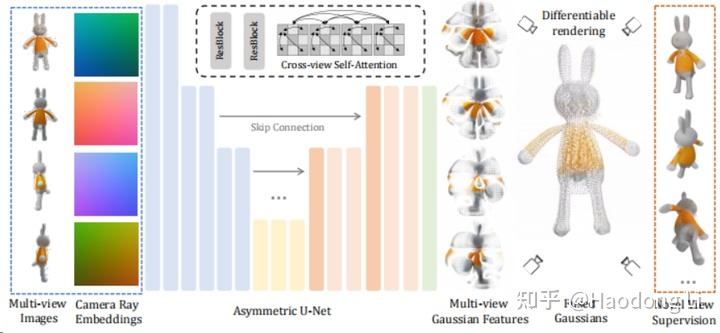
LGM
大力出奇迹,将Multiview和Camera ray给concat在一起然后用一个大的UNet回归出gaussian attribution
InstantMesh
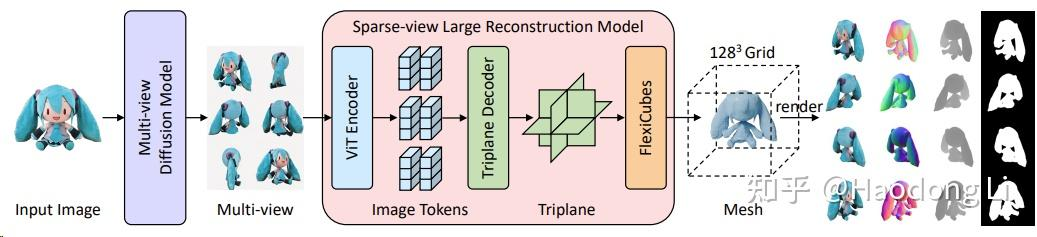
TencentARC/InstantMesh: InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models (github.com)
CraftsMan
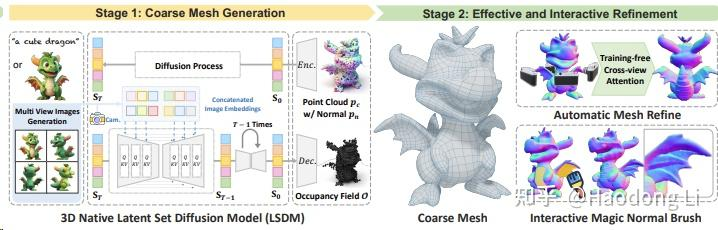
wyysf-98/CraftsMan: CraftsMan: High-fidelity Mesh Generation with 3D Native Diffusion and Interactive Geometry Refiner (github.com)
使用3Dshape2vecset作为Representation,将multiview image通过CA注入UNet
Splatter Image
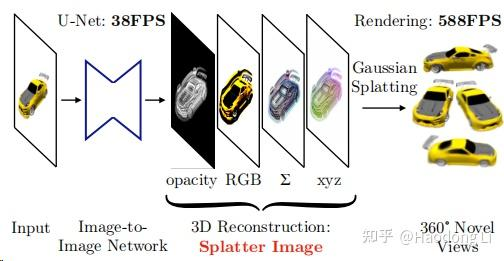
szymanowiczs/splatter-image: Official implementation of `Splatter Image: Ultra-Fast Single-View 3D Reconstruction' CVPR 2024 (github.com)
最早用Gaussian做generalization的工作,用UNet直接forward出Gaussian attribution
VideoMV
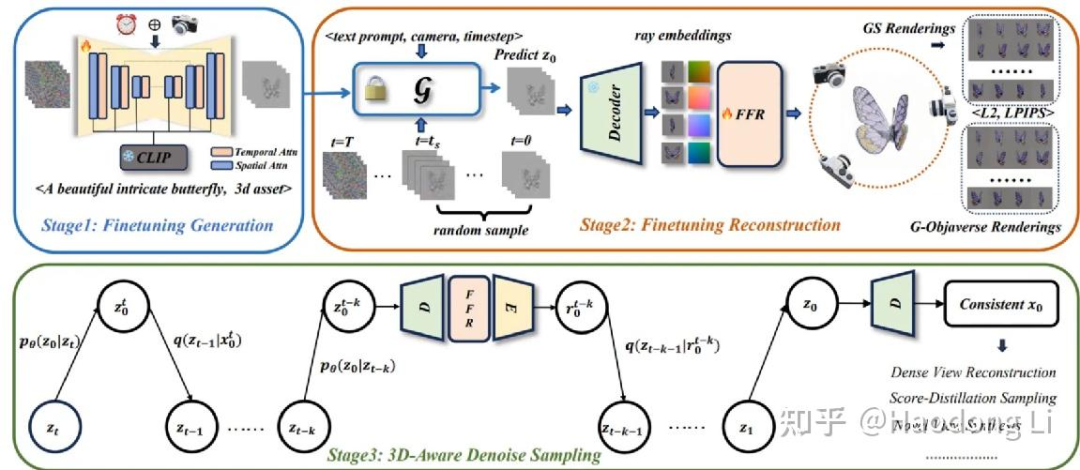
VideoMV (aigc3d.github.io)
ComboVerse
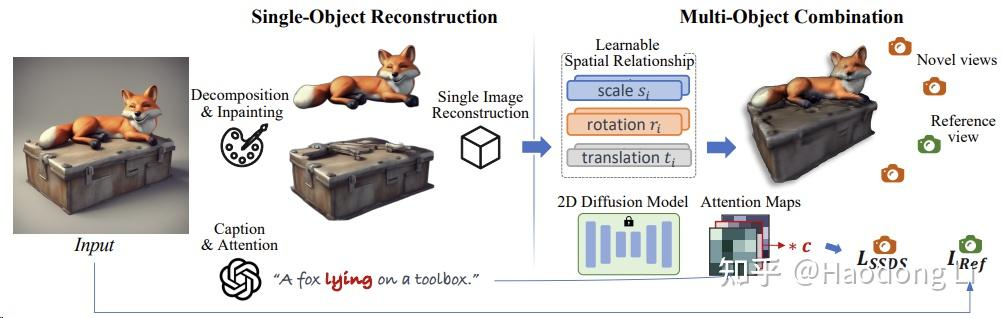
ComboVerse
将Caption中prep提取出来,用Attention map计算SSDS loss,Insight是用Caption中prep对组合体生成很重要
感觉类似这种做法很多呀,做Attention map上做一些design做zero-shot
DreamComposer
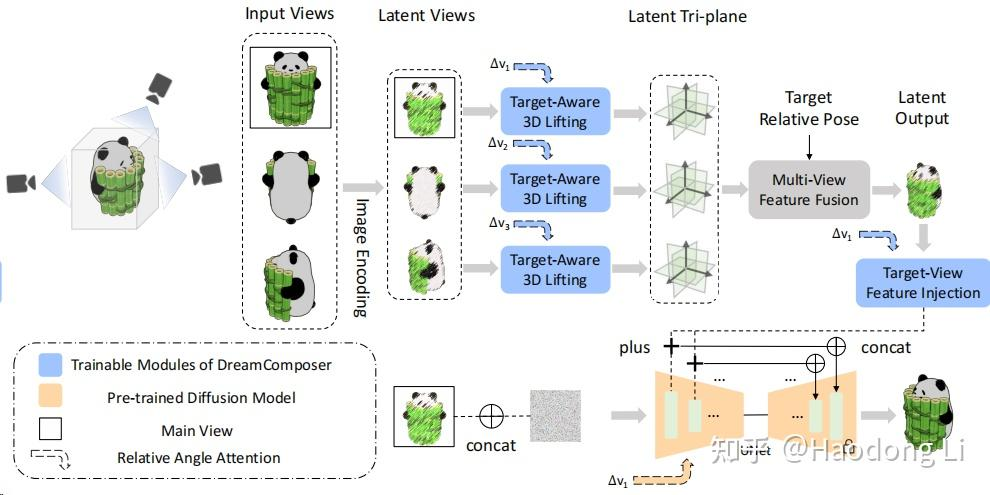
DreamComposer
挺有设计的,不愧是hku-mmlab的工作
MVDream
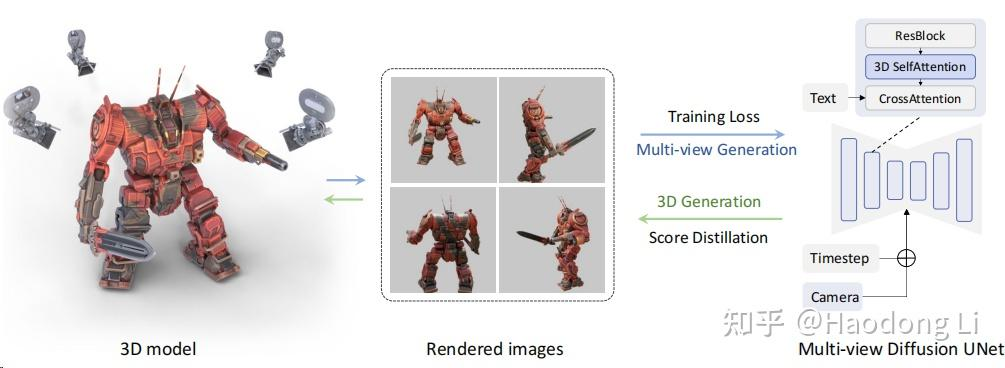
MVDream: Multi-view Diffusion for 3D Object Generation
早期工作,计算开销很高
GenLRM
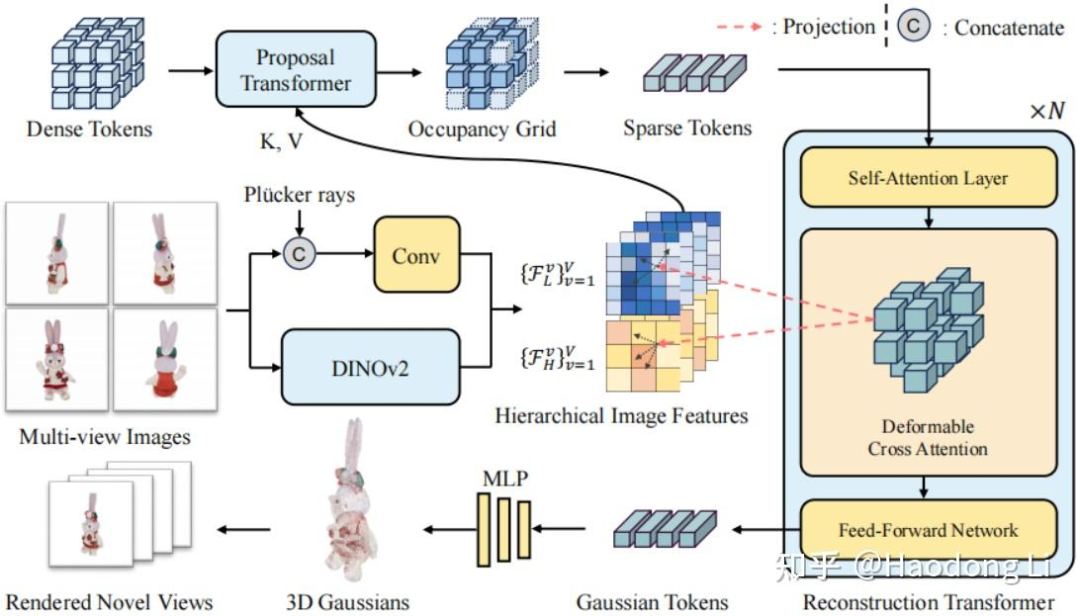
GeoLRM
用Transformer做3d aigc,hierarchical feature将高频信息和低频信息结合起来做Attention
LRM的优势就是可以end-to-end做scale up
Sherpa3D
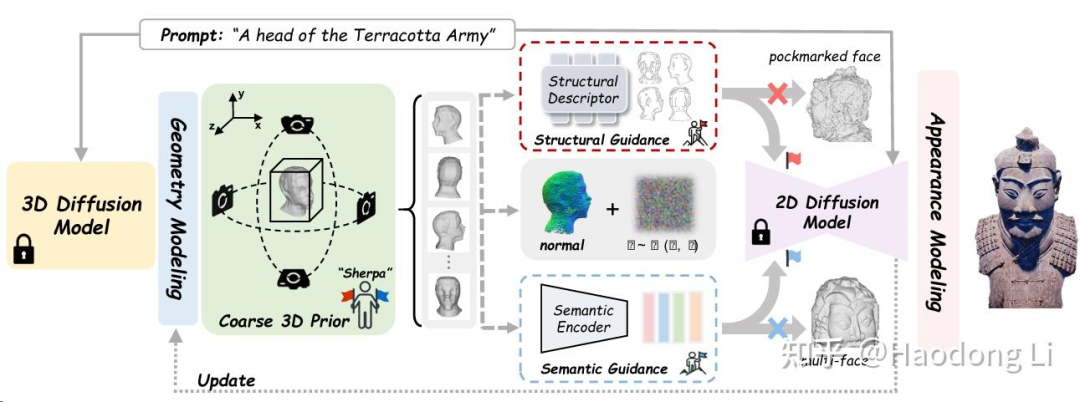
Sherpa3D
GaussianCube
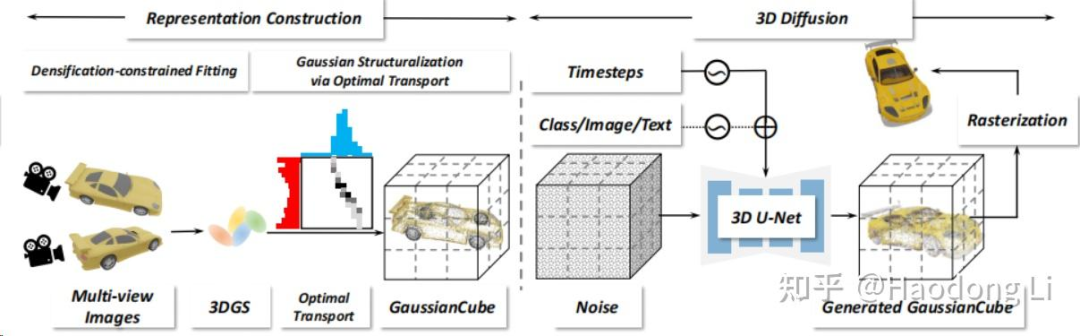
GaussianCube
将每个3dgs移到voxel中
DMTet/Nvdiffrec
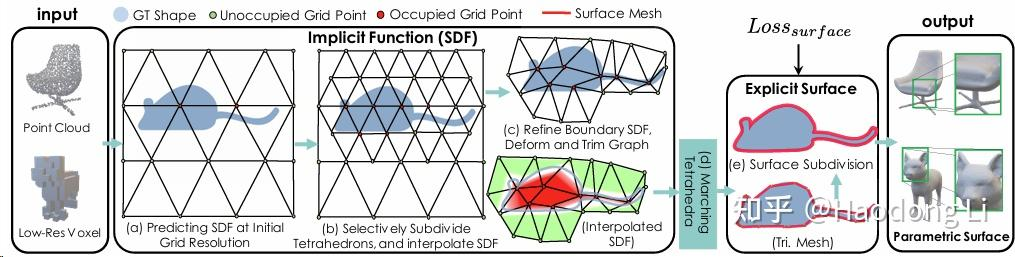
Deep Marching Tetrahedra: a Hybrid Representation for High-Resolution 3D Shape Synthesis
这里记录DMTet主要是因为它常用作3D Generation中mesh的表征(DMTet相对NeRF/3DGS表征适合提取mesh)
DMTet团队后面也用DMTet representation做了大名鼎鼎的Nvdiffrec

NVlabs/nvdiffrec: Official code for the CVPR 2022 (oral) paper "Extracting Triangular 3D Models, Materials, and Lighting From Images".
后面NVIDIA团队也用DMTet表征做text 2 3d的magic3d(不开源)
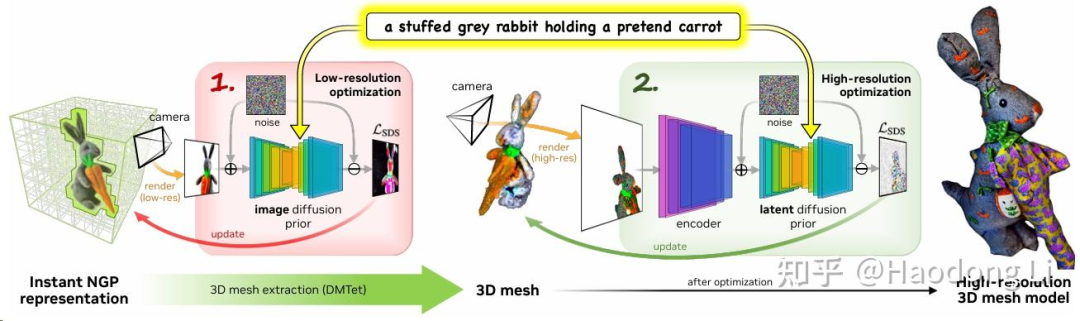
Fantasia3D
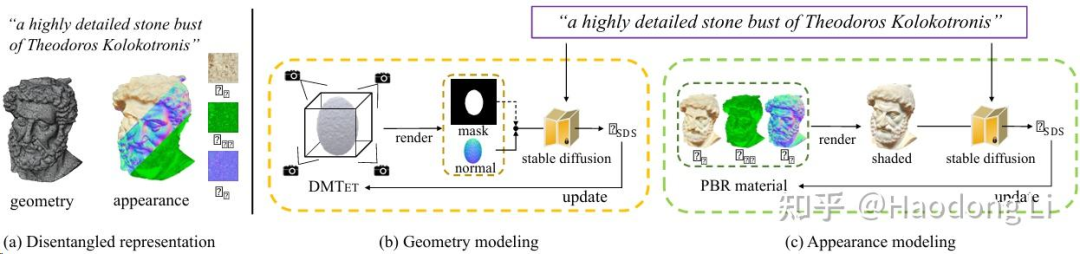
Fantasia3D: Disentangling Geometry and Appearance for High-quality Text-to-3D Content Creation
ProlificDreamer
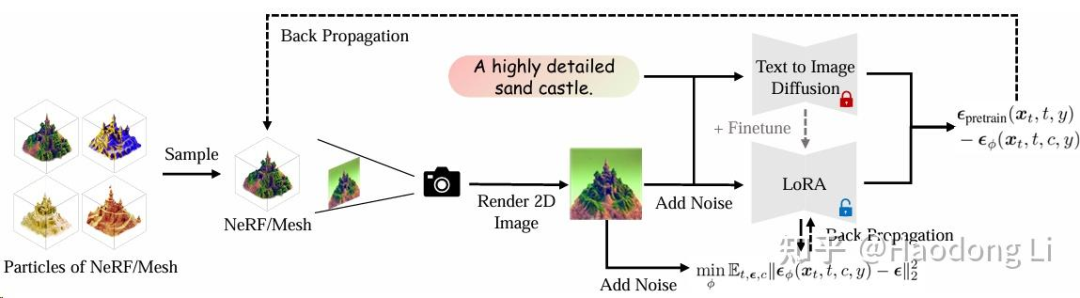
ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation
RichDreamer
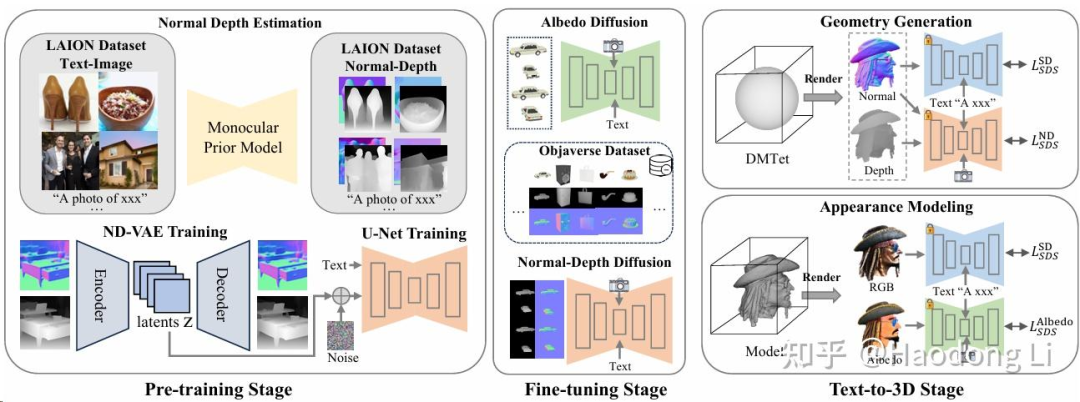
RichDreamer: A Generalizable Normal-Depth Diffusion Model for Detail Richness in Text-to-3D
GSGEN
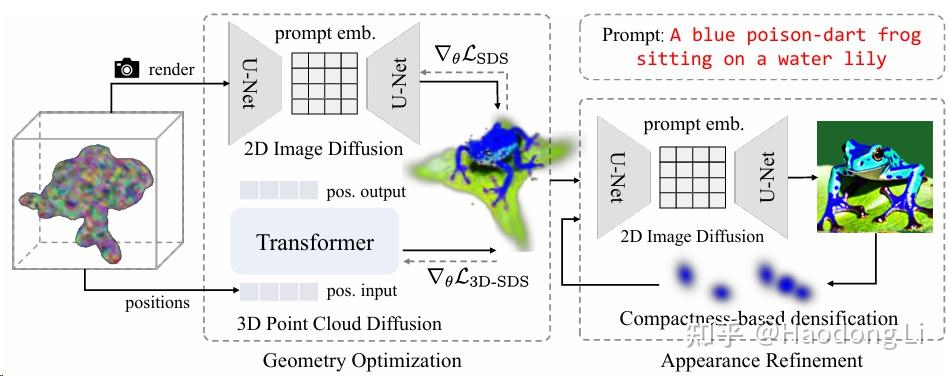
GSGEN: Text-to-3D using Gaussian Splatting
DreamGaussian
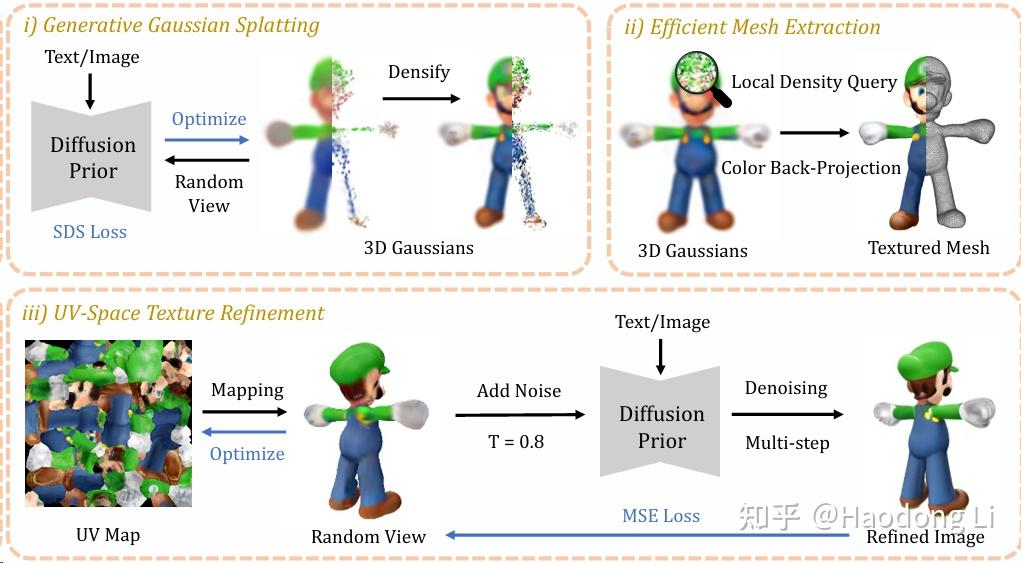
DreamGaussian
这里连续记录了几个SDS-based的方法
优点:能调用SD的high-quality/diversity,缺点:对于每个prompt都要逐一优化,同时如果缺乏3D信息监督通常缺乏多视角一致性
Instant3D
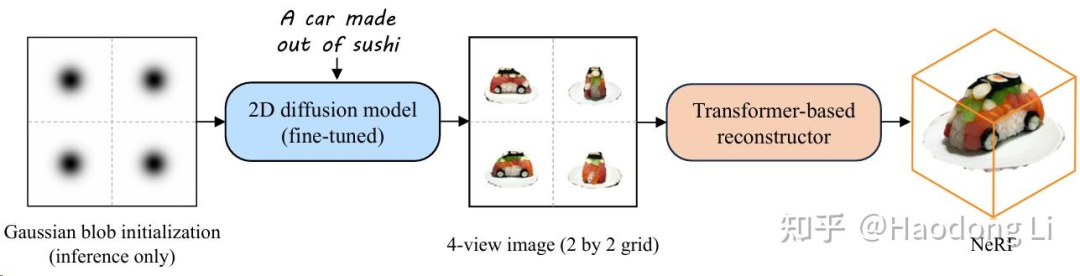
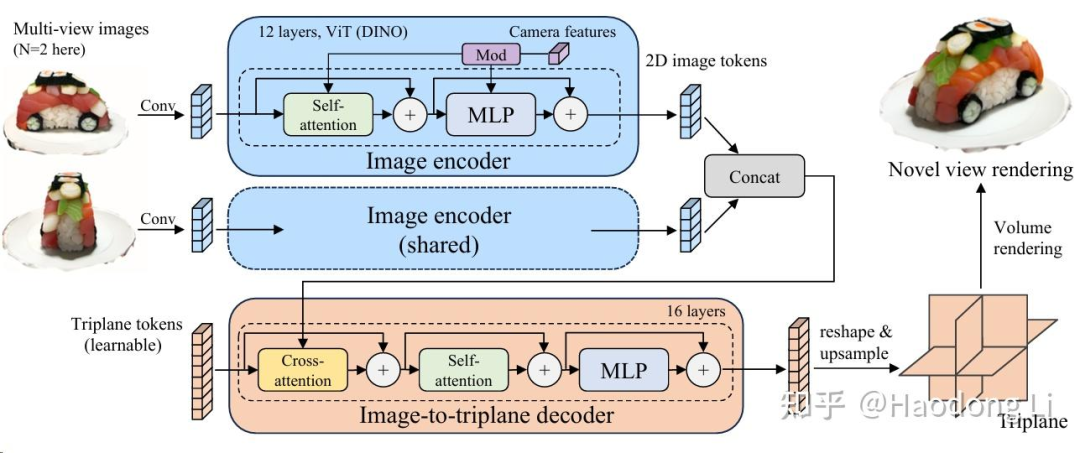
ming1993li/Instant3DCodes
在Pipeline的最底下,训了一个很大的网络将random token学出Triplane token后还原成Triplane NeRF
虽然非常快,但是最底下那个网络的开销非常大
Inpaint3D
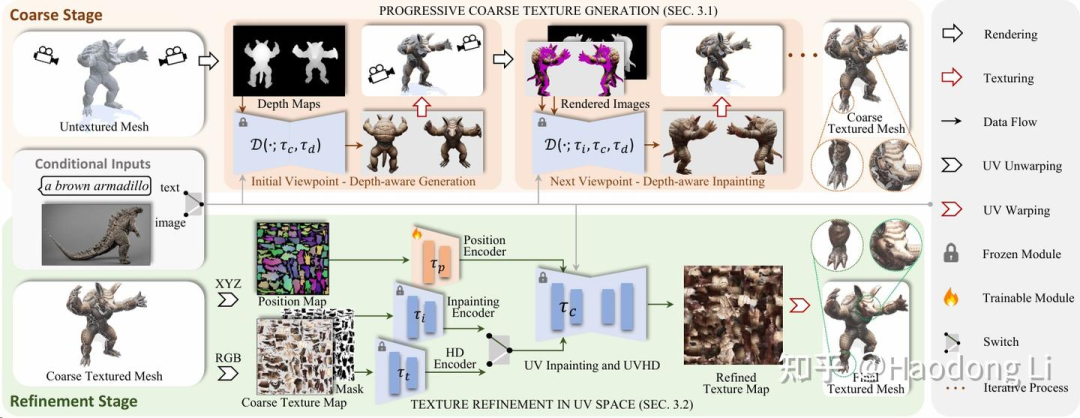
Paint3D
IM-3D
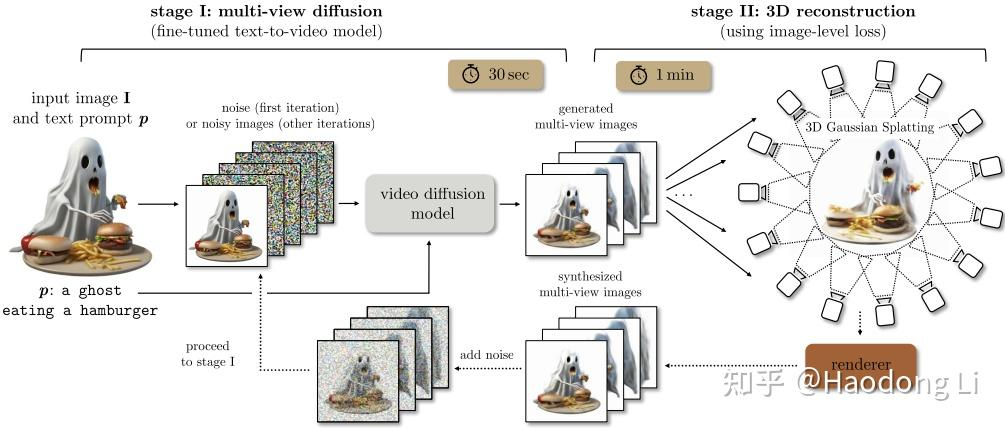
没开源,backbone video diffusion用的是EMU(meta自己的工作)
先用video Diffusion生成Multiview,再用Multiview过3dgs的Pipeline
One-2-3-45++
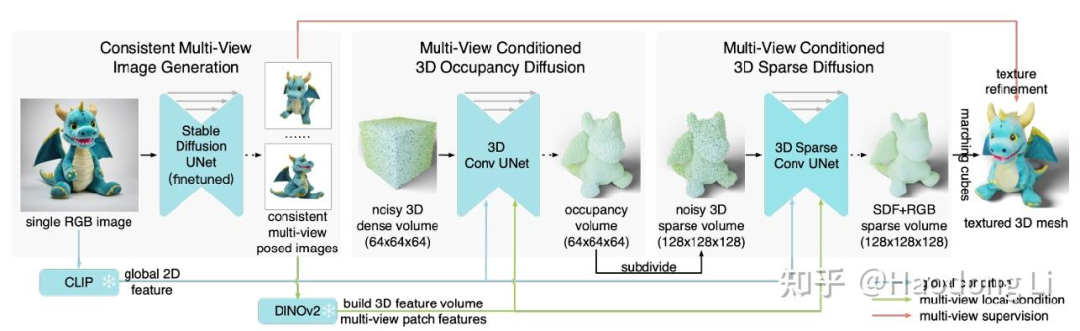
One-2-3-45++
DreamCraft3D
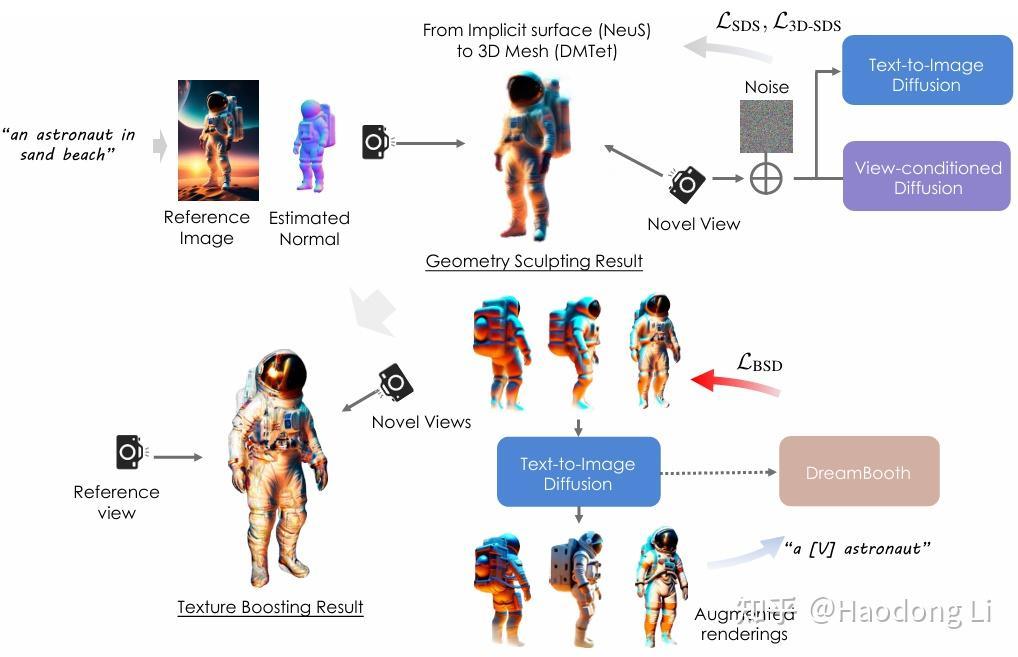
DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior
LAS-DIffusion

LAS-Diffusion
直接使用3D diffusion将2D sketch生成为3D object
先用sketch input作为condition通过cross-attention注入到occupancy-diffusion中,得到一个64^3的粗糙结果
再将64^3object进行upsample得到128^3的粗糙结果,再用SDF-diffusion进行refinement
这个方法后面也被One-2-3-45++延用
DreamReward
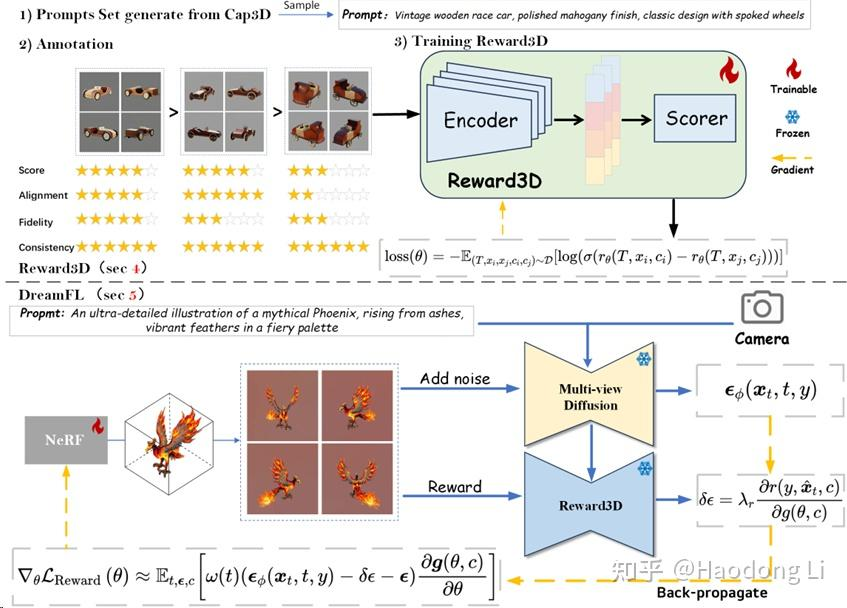
DreamReward
第一次将RLHF引入3d aigc,提出了一套人类打分的数据集来加入新的loss做约束
SweetDreamer
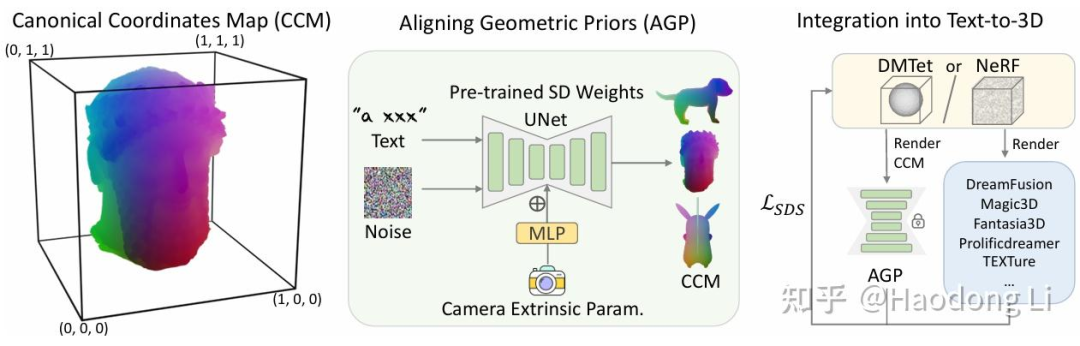
SweetDreamer: Aligning Geometric Priors in 2D Diffusion for Consistent Text-to-3D
3D-Adaptor
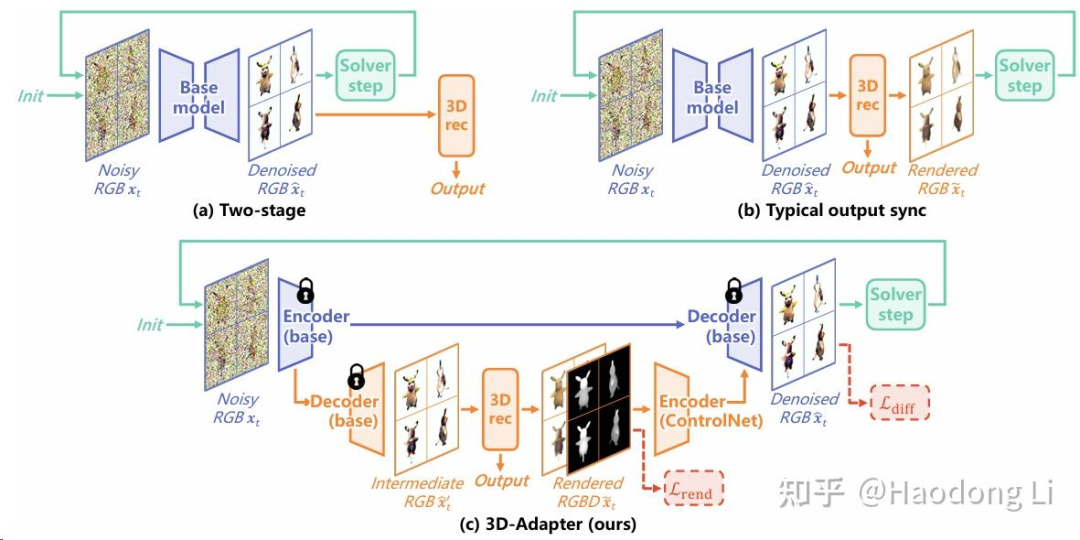
3D-Adapter: Geometry-Consistent Multi-View Diffusion for High-Quality 3D Generation
SplatFormer
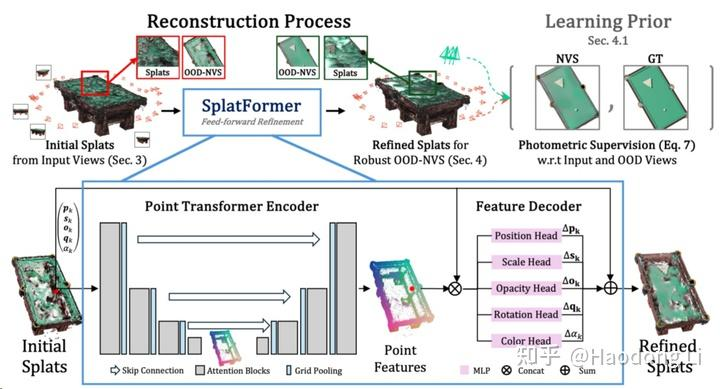
SplatFormer
第一个做OOD,提了数据集(object-level),开坑的工作所以Pipeline很简单
用PTv3学出Point feature再用MLP学bias得到refinement后的3dgs field
SketchDream
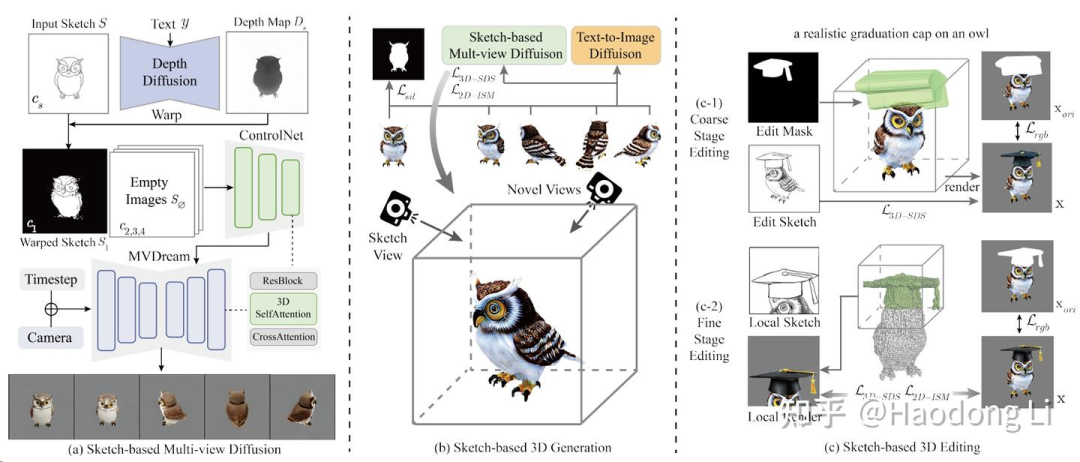
SketchDream
Semantic-SDS
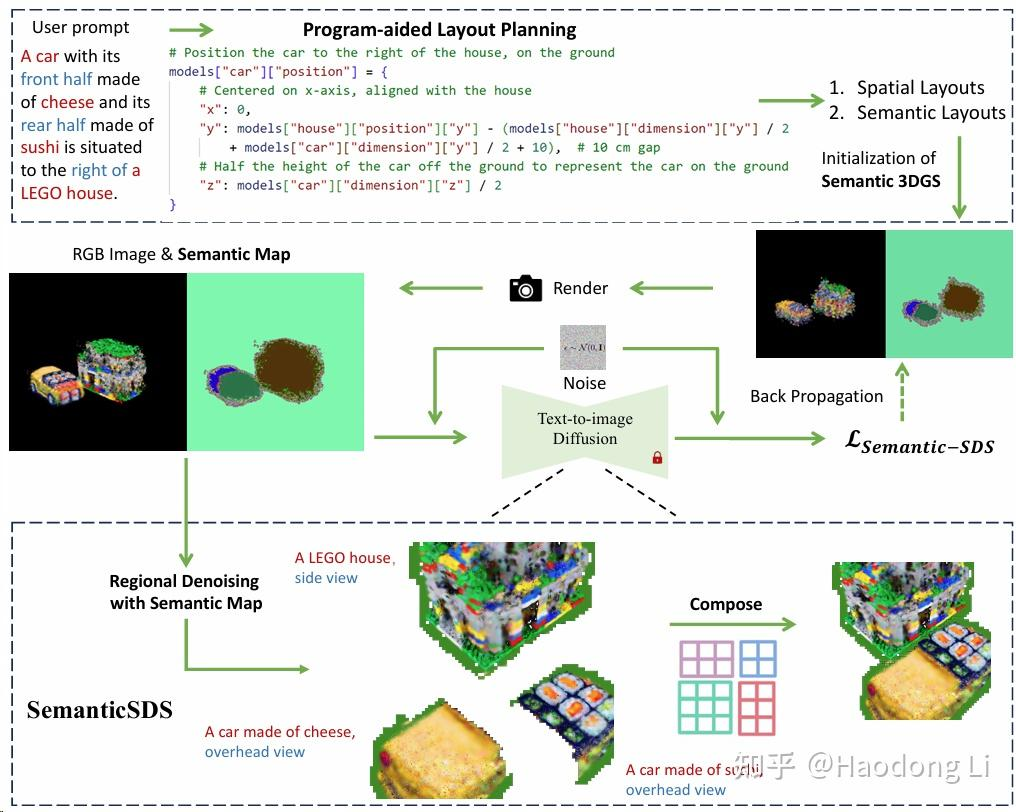
SemanticSDS-3D
用LLM生成带语义的layout,每个区域denoising的时候都可以用局部具体的prompt
Direct3D
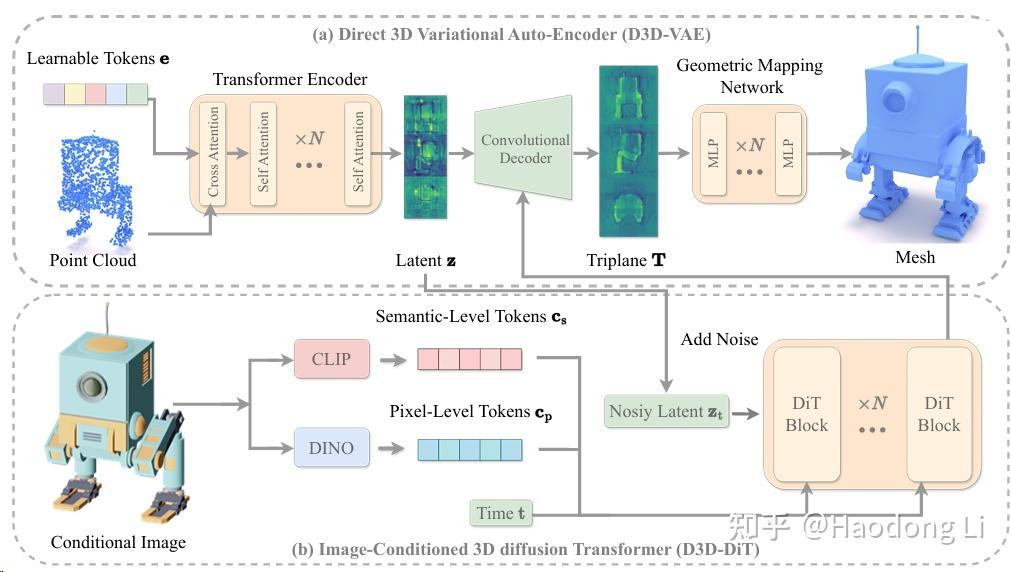
Direct3D
用DiT恢复出Triplane token,用CLIP得到Semantic token已经可以恢复出个大概了,再用DINO得到pixel token恢复出高频信息
Tailor3D
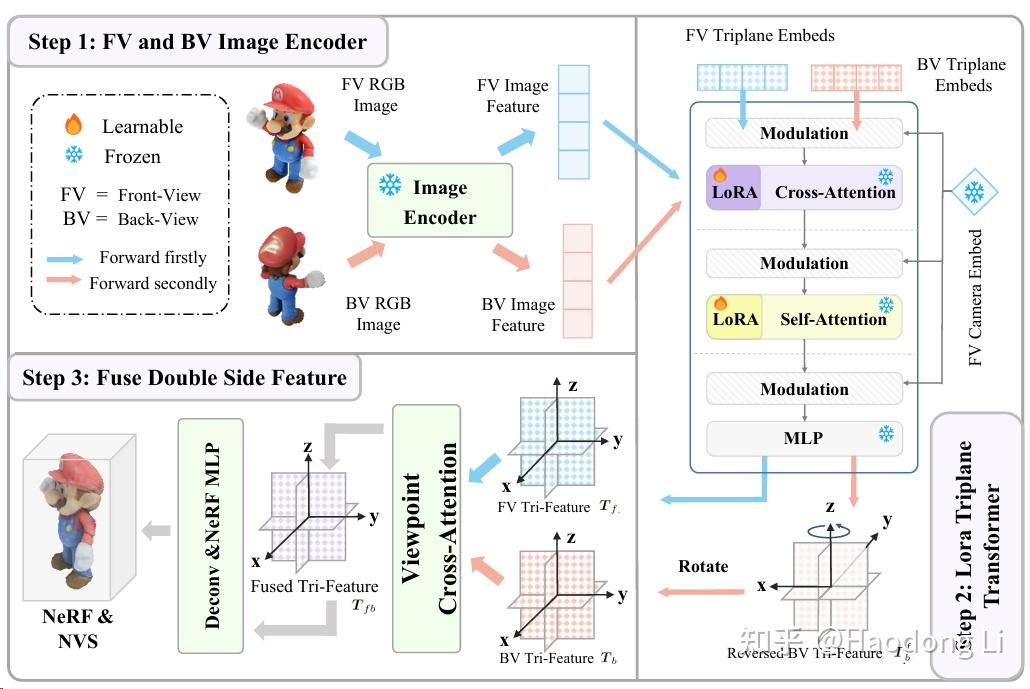
Tailor3D
是基于Multiview LRM(Instant3D)上去Finetune lora实现的,所以训练/推理计算开销不高(LRM-based model计算开销都不高)
先生成正反面的2D image,用加入LoRA的LRM重建正负面的Triplane,再将两个Triplane给merge到一起得到3D的
One-2-3-45++
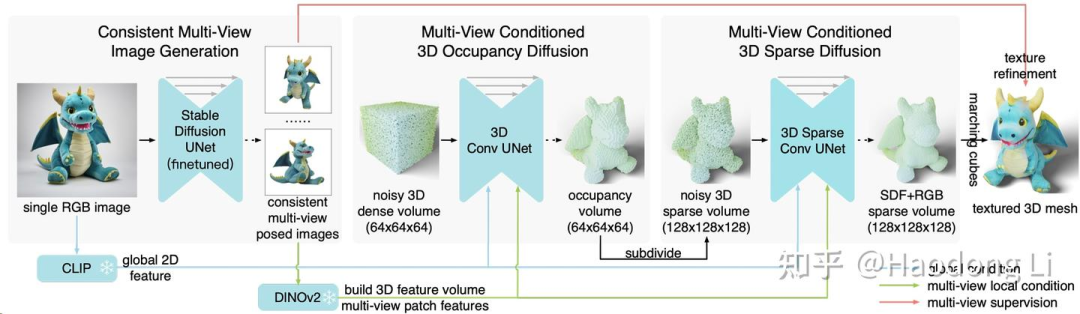
One-2-3-45++
先用Zero123++生成6个view的RGB image(包括elevation和azimuth),再用LAS-Diffusion生成一个volume
SPAR3D
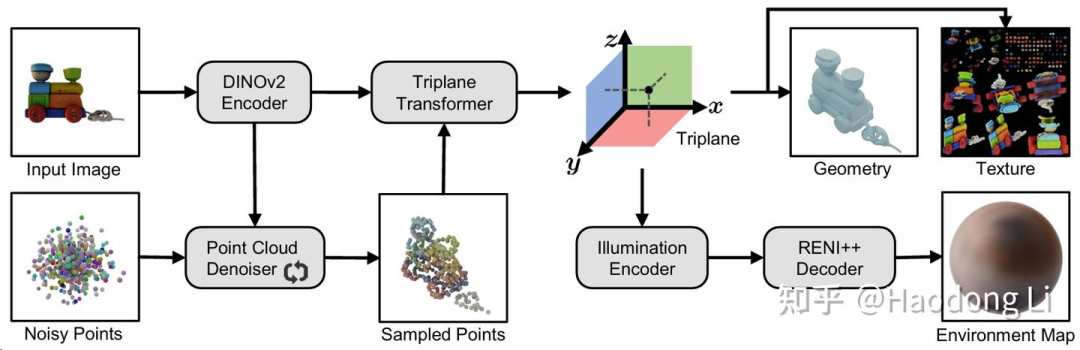
SPAR3D
Diffusion-based:high quality&inconsistency(poor fidelity)/AR-based:poor quality&consistency(high fidelity)
先用Pointcloud DIffusion恢复出global Pointcloud,再用Triplane Transformer恢复出各种attribution
未来做object reconstruction速度上感觉没啥好卷的,大家应该都会疯狂关注inverse rendering,这个才是最本质的reconstruction
Gaussian Surfel
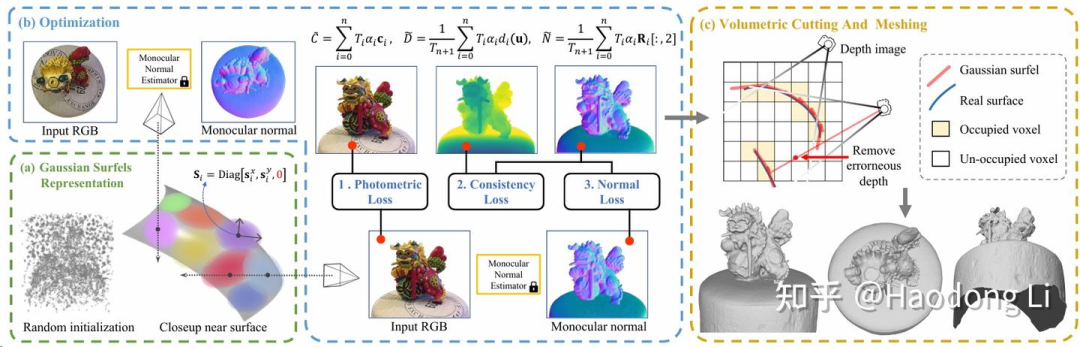
Gaussian Surfels
LaRa
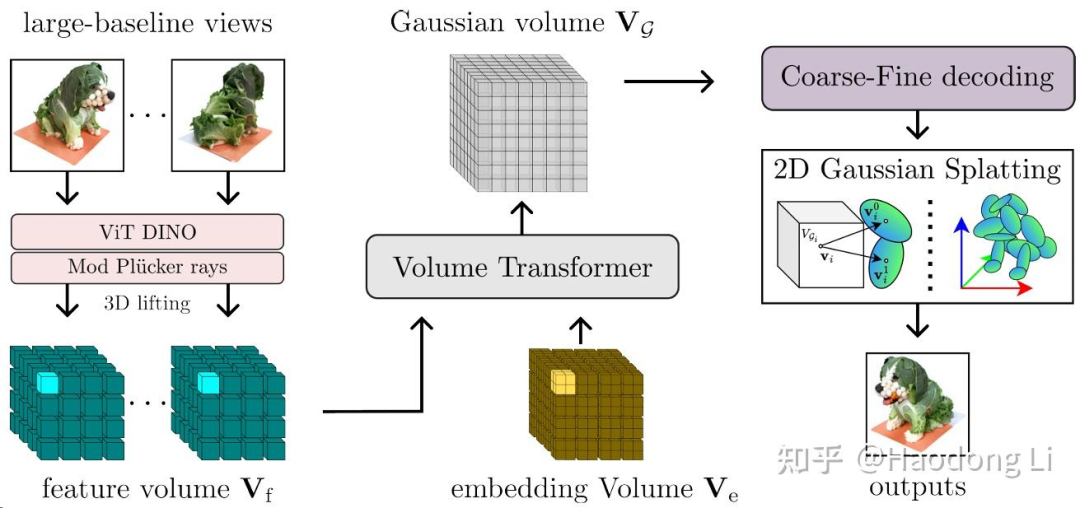
LaRa
3D scene generate
MVDiffusion
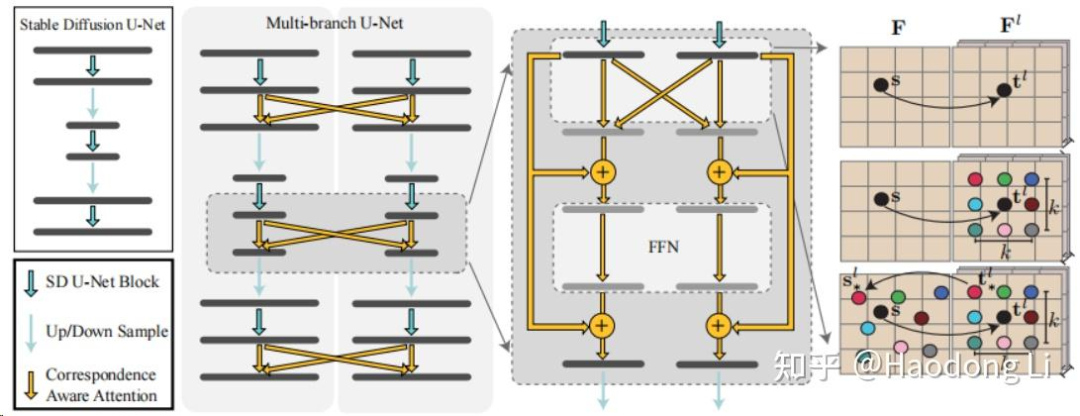

MVDiffusion: Enabling Holistic Multi-view Image Generation with Correspondence-Aware Diffusion
说实话这个工作我并不是很喜欢,觉得并没有从本质解决问题,loop closure也缺乏设计
Flash3D

Flash3D
比较早期的工作,Insight是先用深度估计将3dgs位置放好,但是会用ResNet学个偏置量做调整
后续follow这个思路出了很多工作
pixelSplat
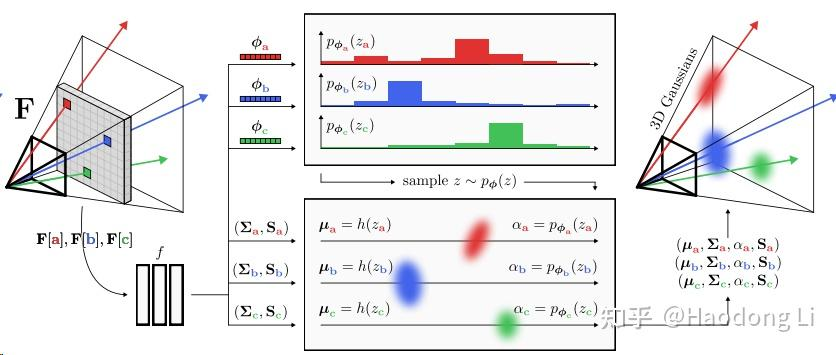
pixelSplat (davidcharatan.com)
先在near-far间预设一些深度区间,回归出Gaussian分布在该区间上概率
再将该概率和Opacity不透明耦合在一起,在表面概率越大,对于Opacity就越大
虽然整个空间上都是有梯度的,但是不如深度预测后直接在表面定义Gaussian
MVSplat
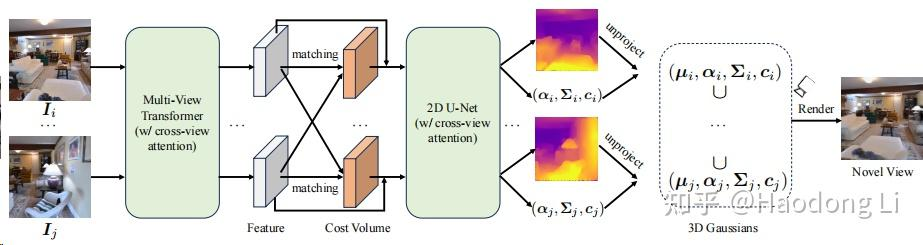
MVSplat (donydchen.github.io)
用一个很强的Multiview depth estimatio估计出深度,再用一个UNet forward出其他Gaussian attribution
DepthSplat
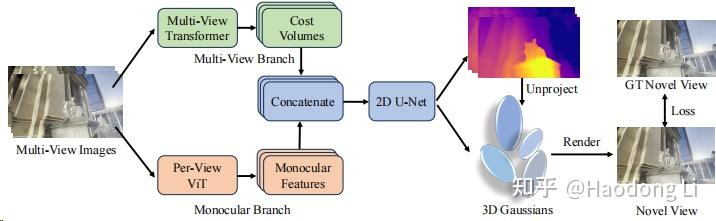
https://haofeixu.github.io/depthsplat/
LatentSplat
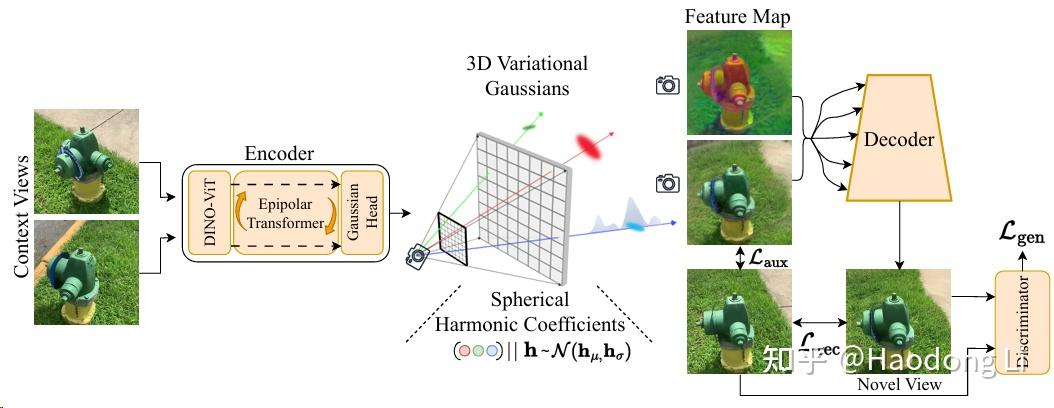
latentSplat
GS-LRM
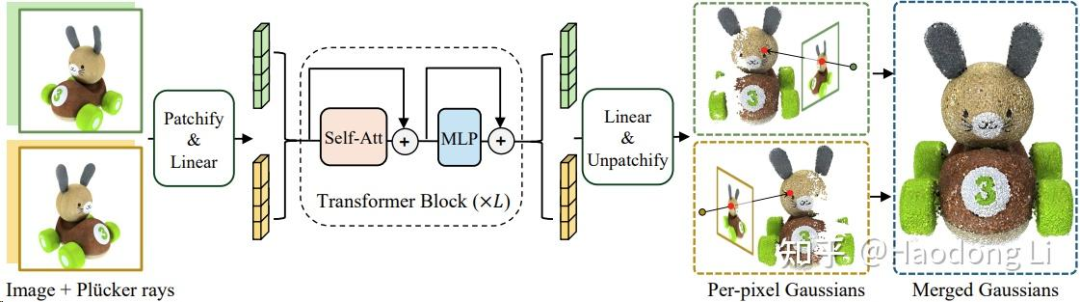
虽然主实验是object level,但是也claim自己能做scene level
Abode的LRM/GS-LRM/MeshLRM都不开源
Director3D
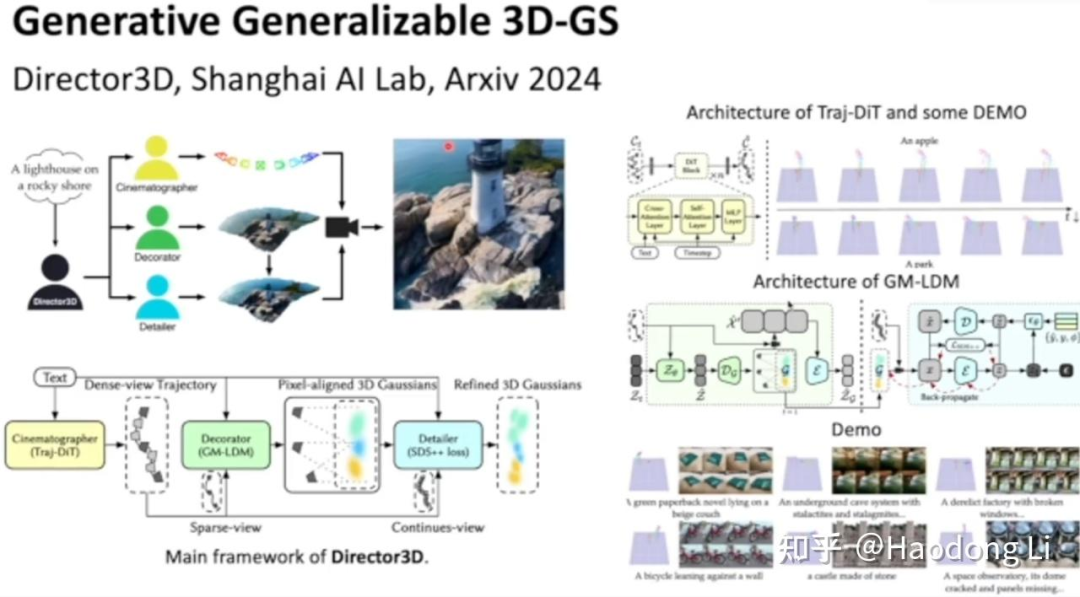
Director3D: Real-world Camera Trajectory and 3D Scene Generation from Text (imlixinyang.github.io)
GGRt
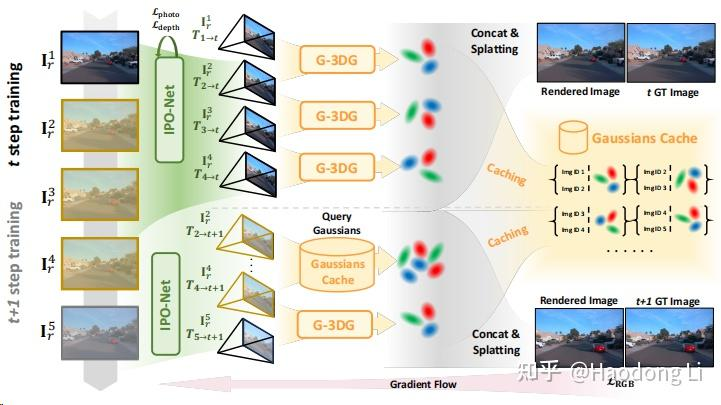
https://3d-aigc.github.io/GGRt
pose-free,昊哥的工作,虽然我没太看懂detail
DUSt3R
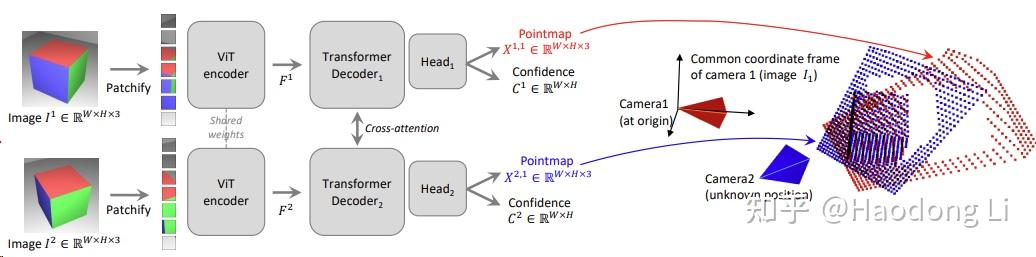
DUSt3R: Geometric 3D Vision Made Easy (naverlabs.com)
简化SfM,直接将两张图的pixel投影到3D space中
Spann3R
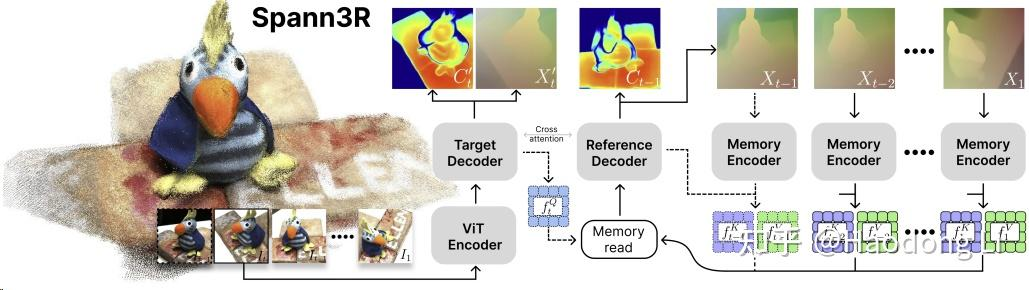
https://hengyiwang.github.io/projects/spanner
DUSt3R改进,一次性将多张图align到3D space中
Splatter3R
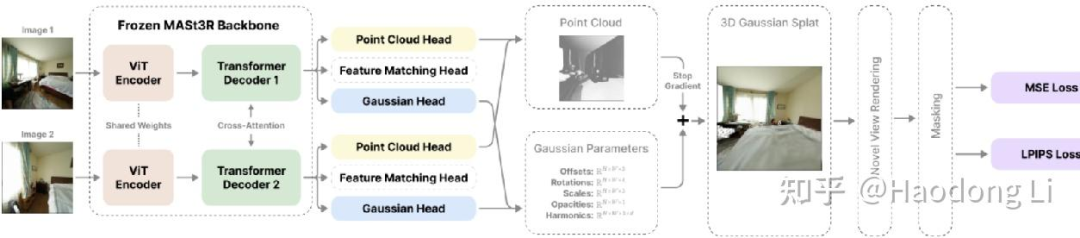
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs (active.vision)
Text2Room

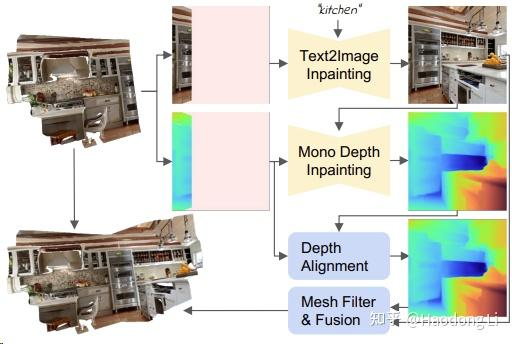
Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models (lukashoel.github.io)
warp&Inpaint,经常被作为baseline去比
GALA3D
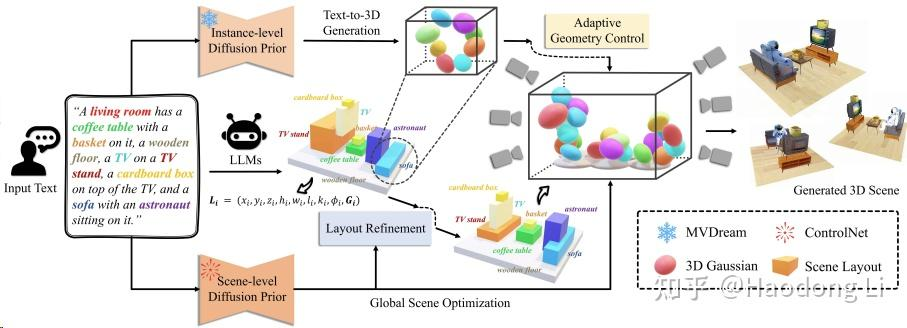
GALA3D: Towards Text-to-3D Complex Scene Generation via Layout-guidedGenerative Gaussian Splatting
用LLM生成layout
WonderJourney
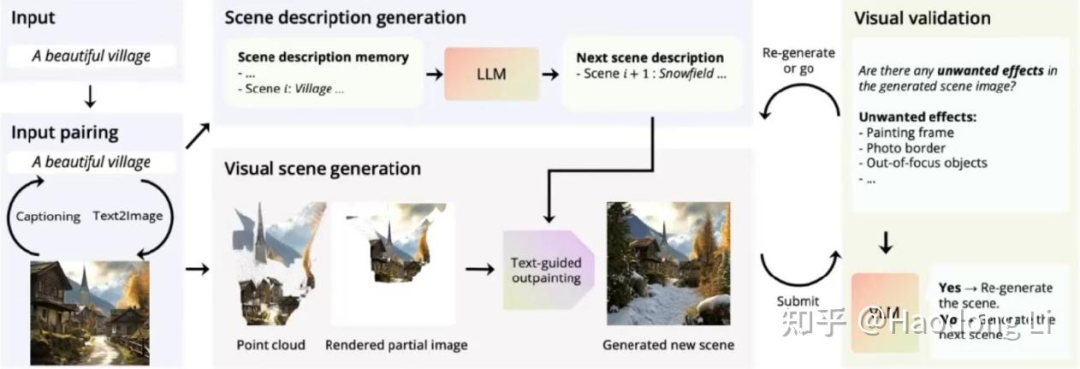
WonderJourney
warp&Inpaint,用新得到RGB图片更新PointCloud,再用VLM去除artifact更make sense
WonderWorld
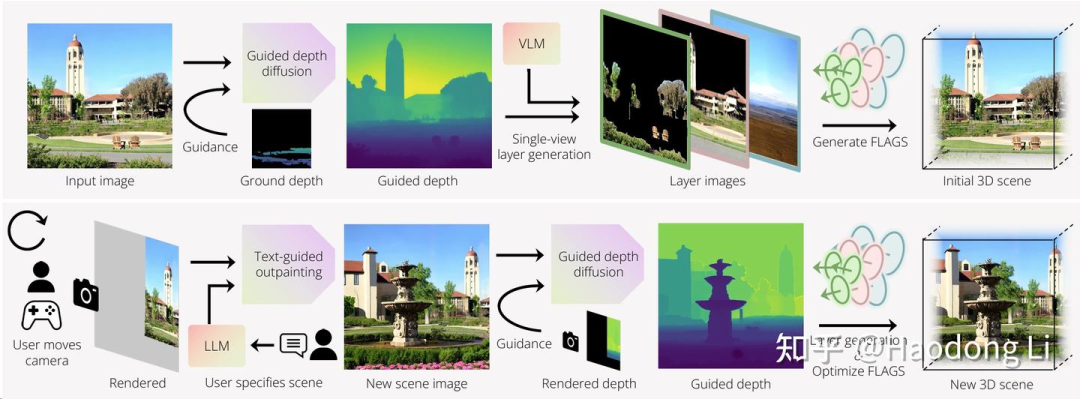
WonderWorld
提出了Gaussian Surfel表征解决过去3D无法做到real-time的问题(只有opacity需要optimation)
同时为每一层layer image都用Gaussian Surfel进行overfit实现对于对于遮挡也可以很快解决
最后是用Guided Depth DIffusion(用DIffusion做深度估计)使Geometry更Consistency
不过这个Gaussian Surfel和2DGS有什么很大区别吗,好像没有
DL3DV
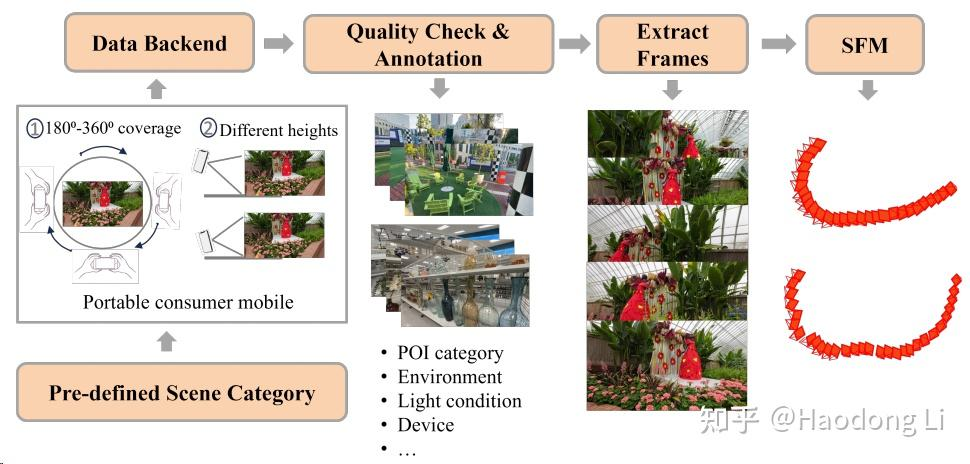
CVPR24提的real-world数据集,可以作为比较有挑战性的数据集
DreamScene360
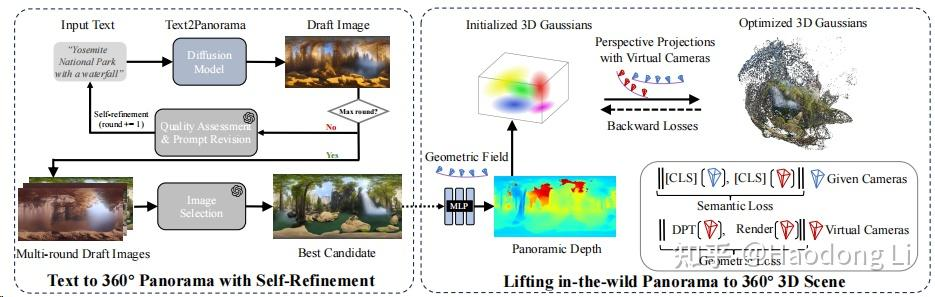
http://dreamscene360.github.io/
用MLLM生成比较好的Panorama,再用Semantic loss+Geometry loss+RGB loss能优化出不错的360 Gaussian场
MVSGaussian
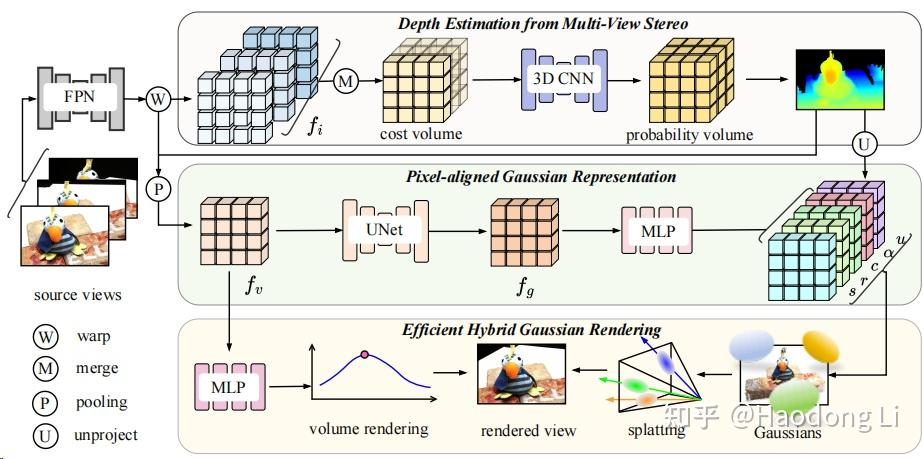
MVSGaussian: Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo
SceneTex
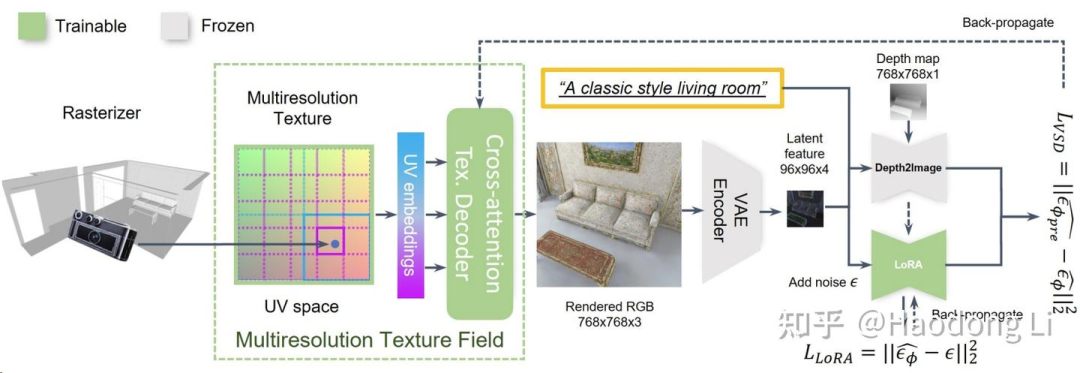
SceneTex: High-Quality Texture Synthesis for Indoor Scenes via Diffusion Priors (daveredrum.github.io)
GenWarp
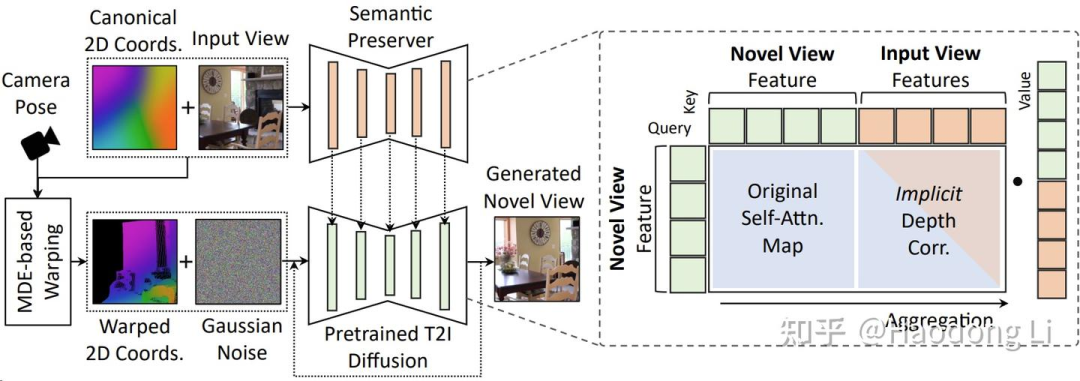
GenWarp (genwarp-nvs.github.io)
VistaDream
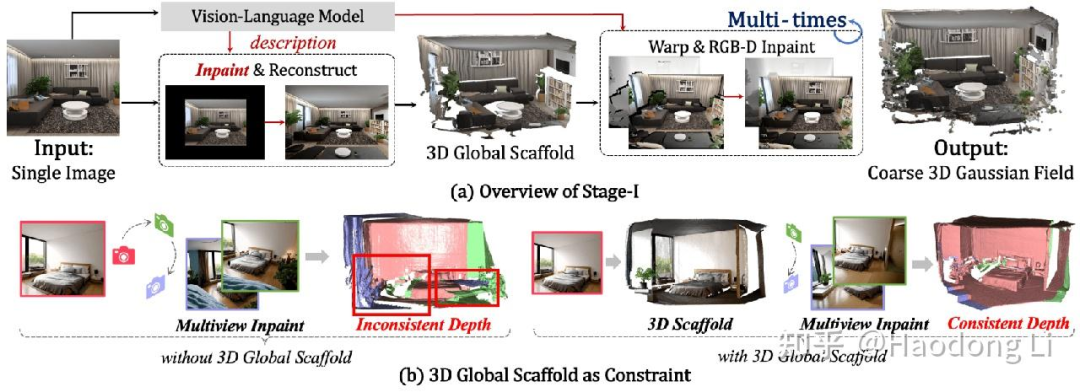

VistaDream
先通过VLM打caption+warp&inpaint的方式得到coarse scene
再用加权的MCS优化(做Consistency&quality的trade-off)
启示:对于trade-off,对两个loss做加权的优化,把效果做work就好了
Inifinigen

Infinigen
Infinigen相当于3D中Imagenet,而且是无限生成的
他不是从website上download Asset进行组合,是直接生成Asset进行组合,同时可以提供high-quality label之类的
Inifinigen Indoor

将Inifinigen扩展到了Indoor中,不过加入了很多约束条件(因为outdoor随便摆都make sense,但是Indoor 需要有结构)
用贪心算法对组合做约束
3D-GPT
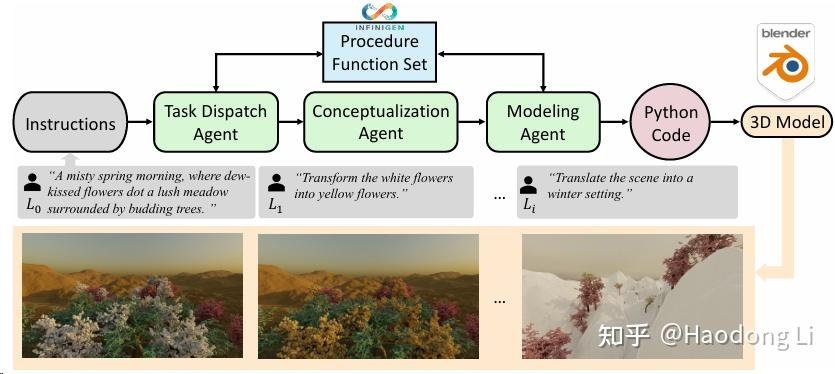
3D-GPT: 3D MODELING WITH LARGE LANGUAGE MODELS
基于Inifinigen上支持text to 3d
非常straight forward,类似和三个agent讨论得到python code,后在blender中建模,同时也claim自己能editting
large spatial model
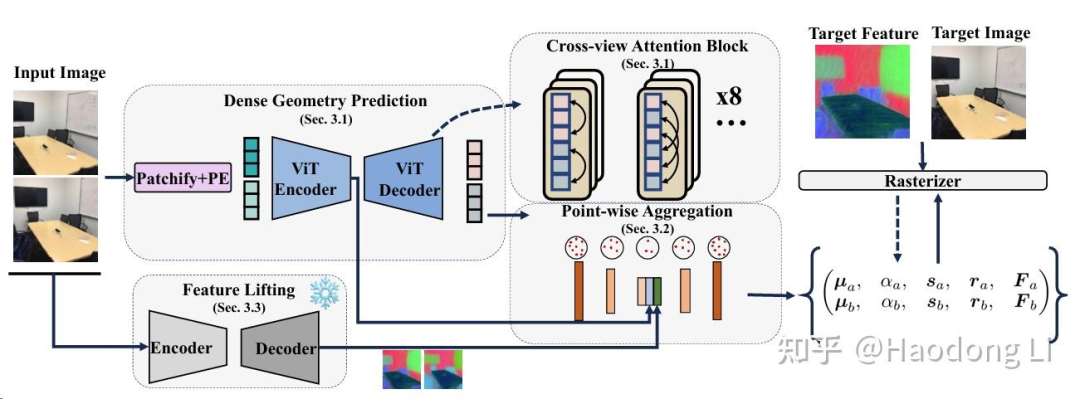
large spatial model
claim能直接forward能reconstruction RGB/depth/semantic,能做depth是因为他是pixel-align Gaussian
StylizedGS
4K4DGen
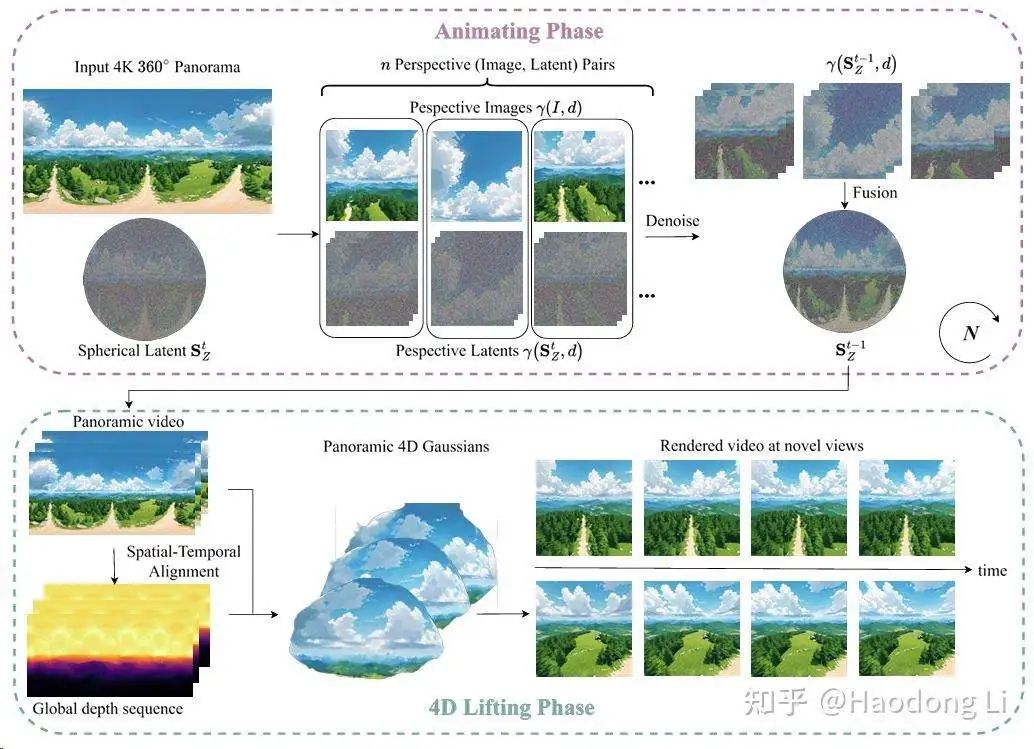
4K4DGen
得到多帧dynamic Panorama,再lift to 4d
ViewExtrapolator
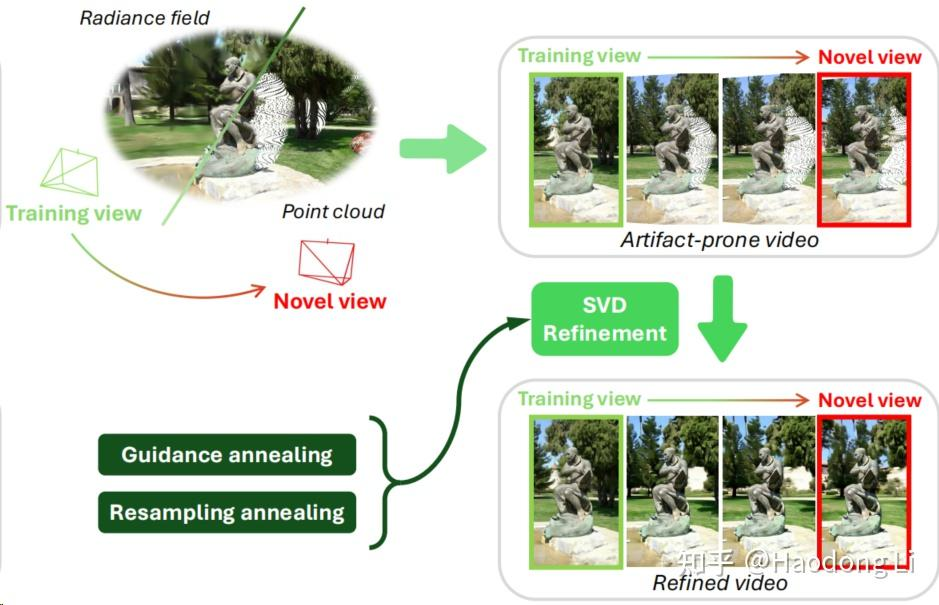
ViewExtrapolator
用SVD做OOD NVS setting,reconstruction-based generation model可以参考denoising的design
NopoSplat
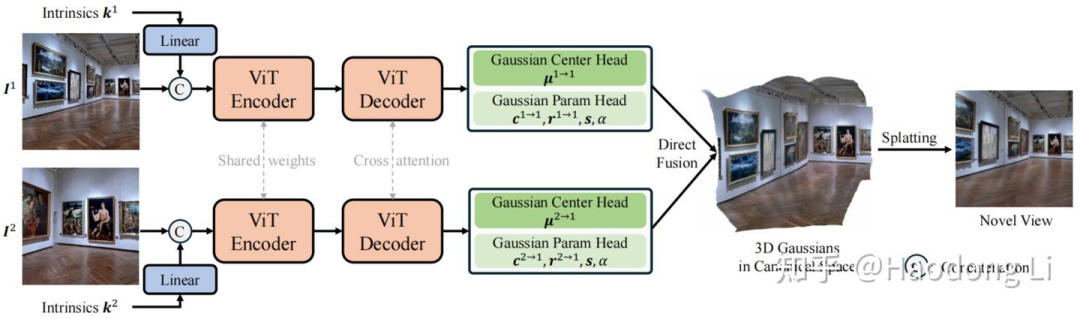
NoPoSplat
一方面是直接预测统一坐标系下的位置,另外一方面是使用了相机内参,DUSt3R以及其他算法由于不使用相机内参,会导致不同相机图像的FoV不同,比如相机长宽比例不同
GenXD
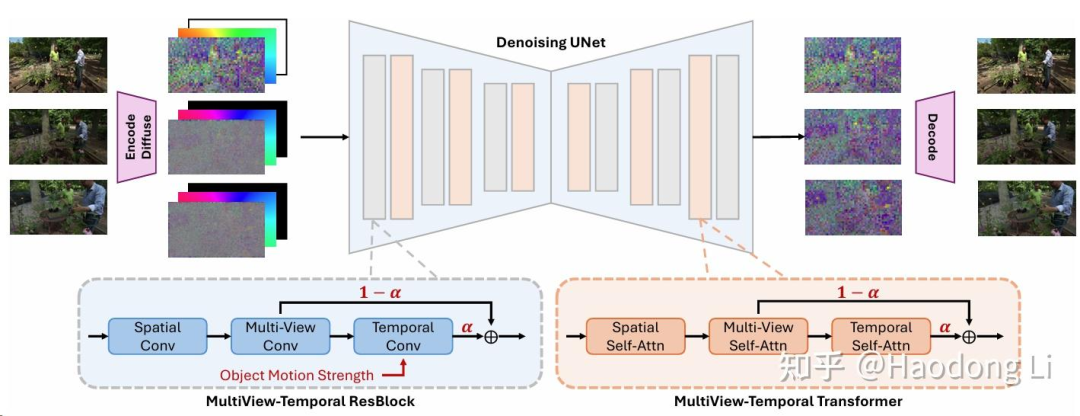
GenXD
很想cat3d,开源了一个很大的4d dataset来训这个模型
MVGenMaster
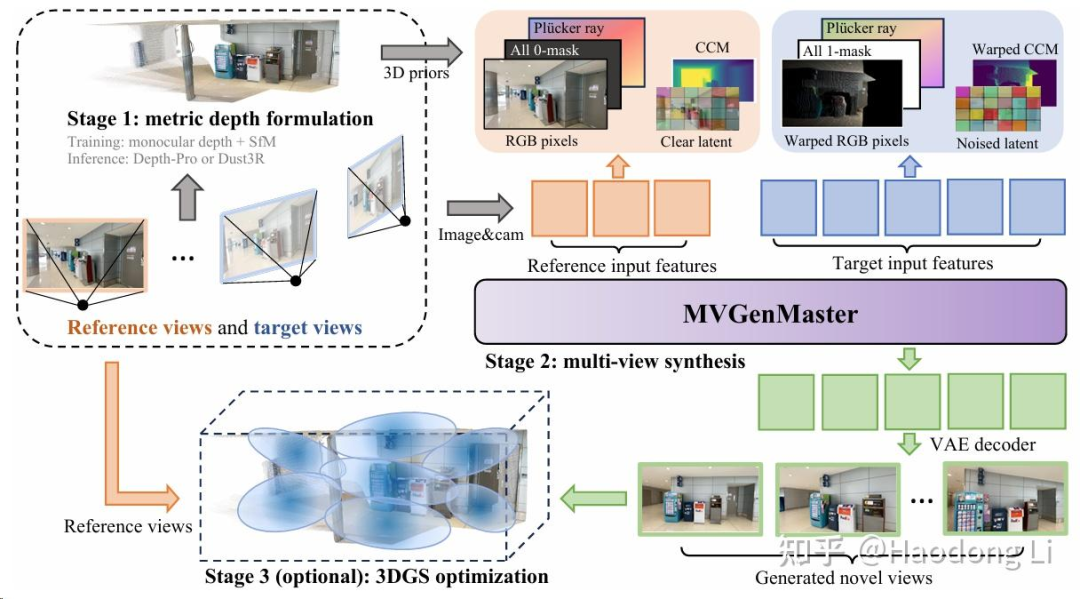
MVGenMaster: Scaling Multi-View Generation from Any Image via 3D Priors Enhanced Diffusion Model
viewcrafter+cat3d,开源了很大的scene dataset
Instruct-NeRF2NeRF
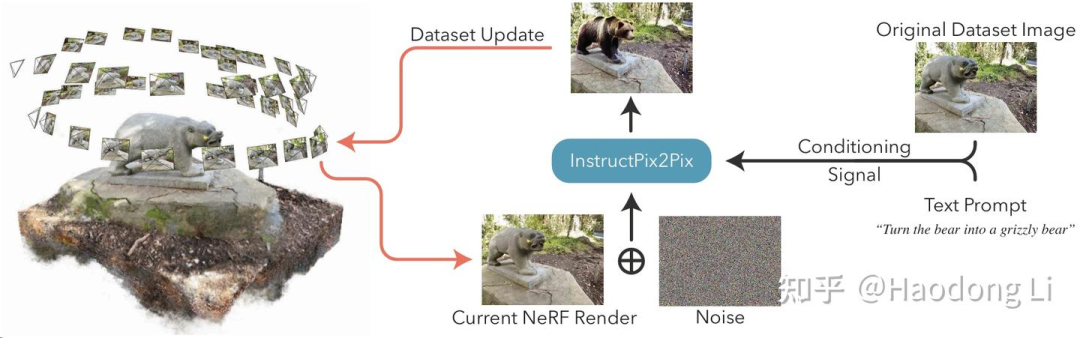
Instruct-NeRF2NeRF
采样出图片,用T&I diffusion进行edit后再更新3D field
ReconFusion
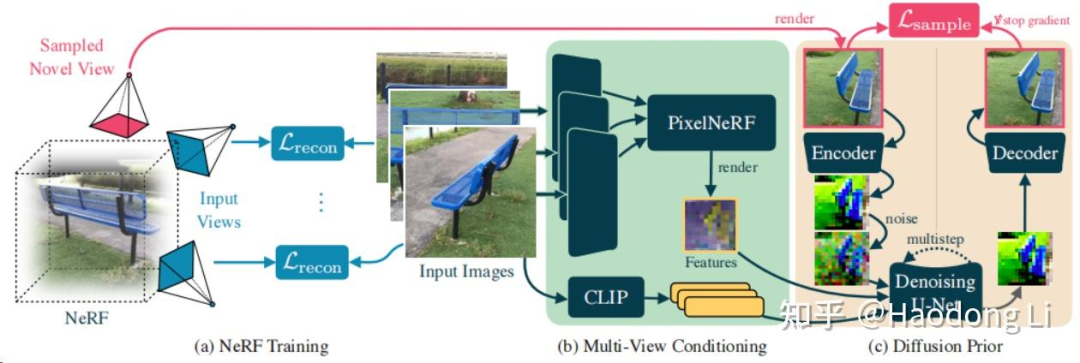
ReconFusion
Reconstructurion-based generation,先用sparse view得到Coarse NeRF field,再用3张input image对sample image进行refinement,将refinement前后梯度传给NeRF做update
和DreamFusion是一个团队的,想法上也是将梯度传给NeRF/3DGS field
Reconstruction-based generate会在quality上差一些,但是Consistency上好很多
See3D
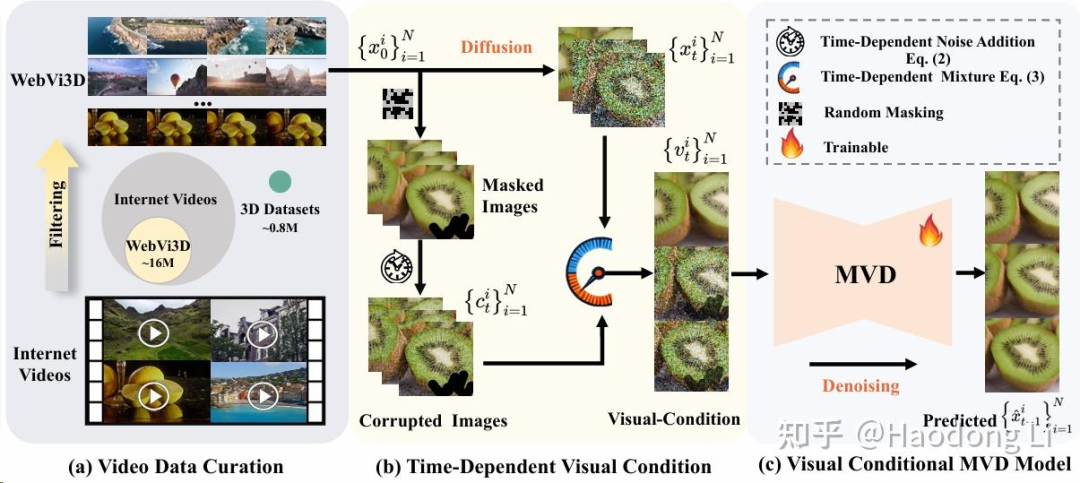
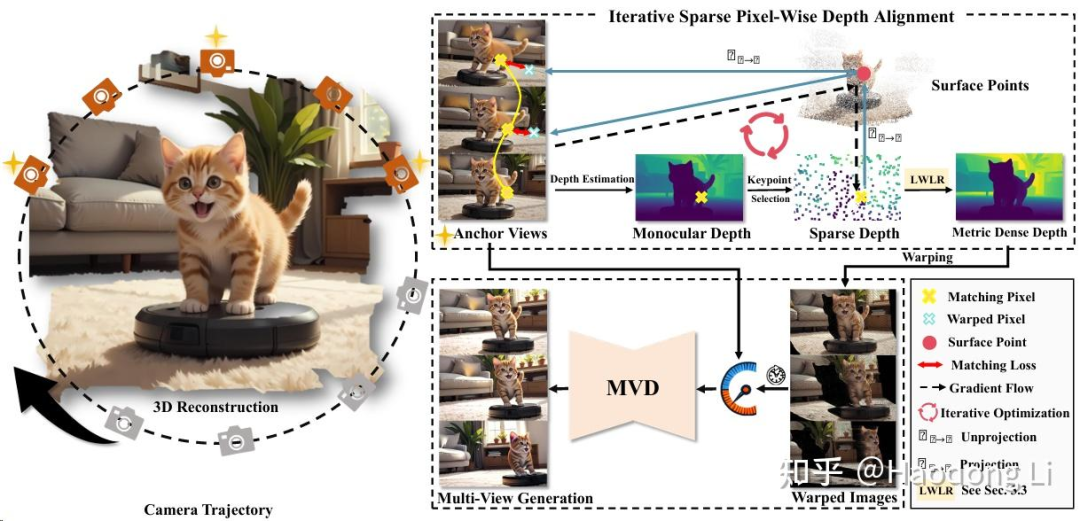
See3D
model architecture上与MVDream应该是没什么区别的,主要是在data Scaling上的尝试
通过洗video data得到WebVid3D的数据集,这个数据集真的非常大,得到类似加强版的MVDream的Multiview DIffusion model
然后可以在warp&inpaint之类的task上去apply起来
Video generate
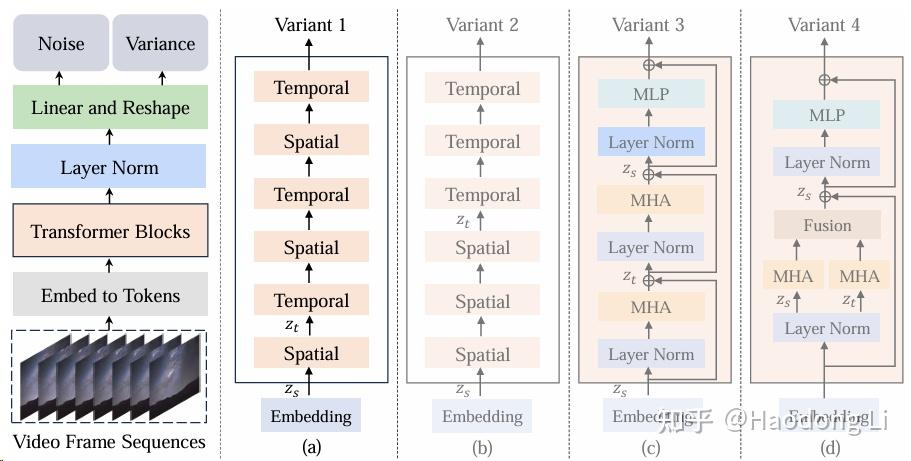
DiT
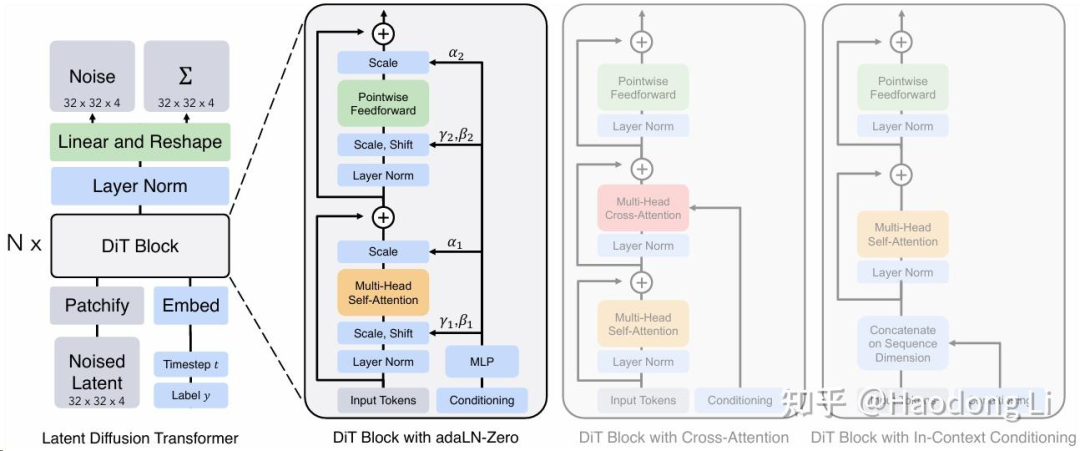
facebookresearch/DiT
UNets其实还是CNN-based的,DiT paper比较实验性质,将CA/In-Context/adaLN/adaLN-Zero四种结构都试了一次发现adaLN-Zero最好
DiT主要还是class-conditionalmodels,不是T2I(在Imagenet上训的),后续工作使用DiT权重往往还是会在data上做一些列清洗
VideoCrafter
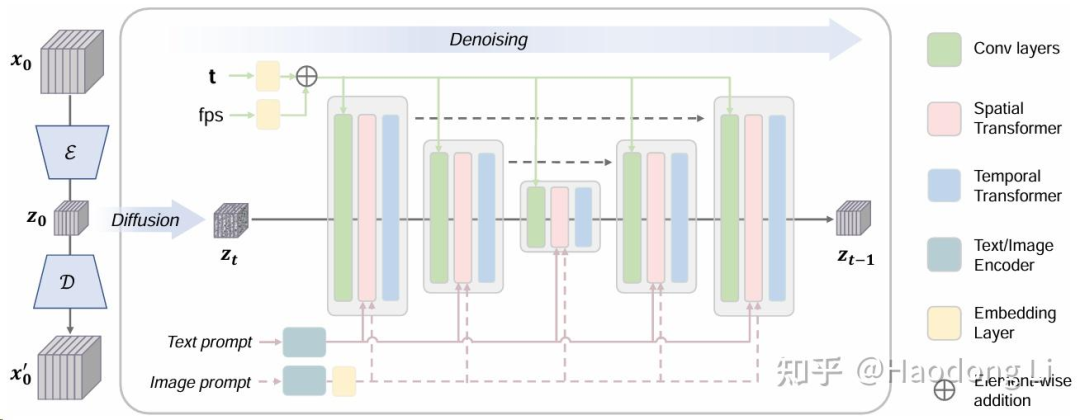
VideoCrafter2
VideoCrafter2在training strategy上做了update
训练策略很重要,apple有个工作就在解释VideoGen的Foundation model应该怎么训
MotionCtrl
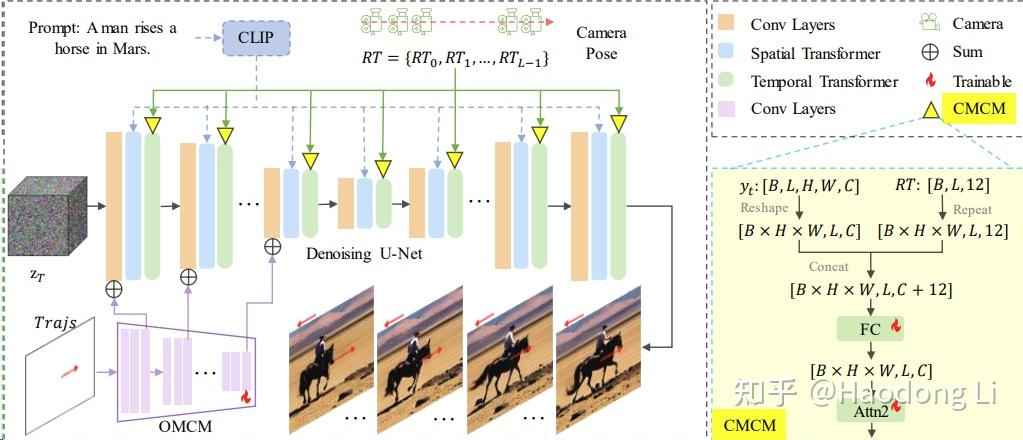
MotionCtrl
将camera motion和object motion解耦开学(dimensionx),分别用了两套数据分别训object和camera的Adapter
Pyramid Flow
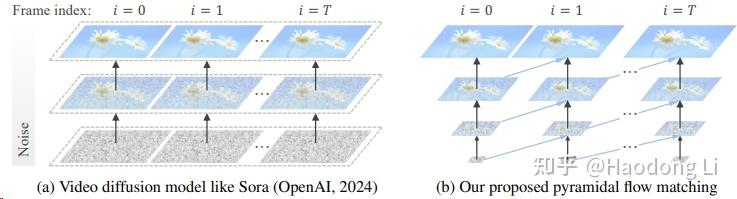
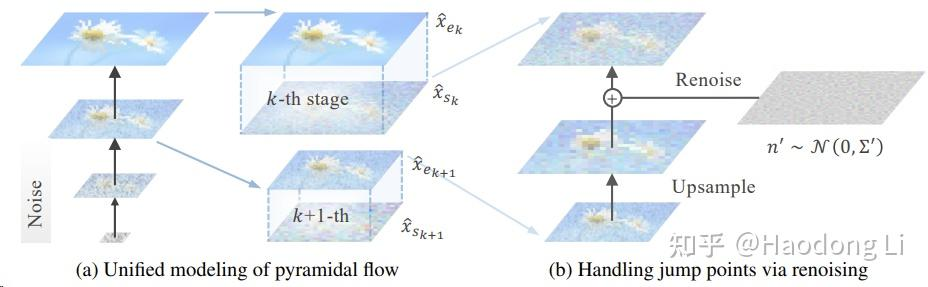
Pyramid Flow (pyramid-flow.github.io)
通过类似VAR的结果不断做scale up(scale比较小的时候,token也比较少)
通过flow matching的Diffusion做高效videogen
ViewDiff
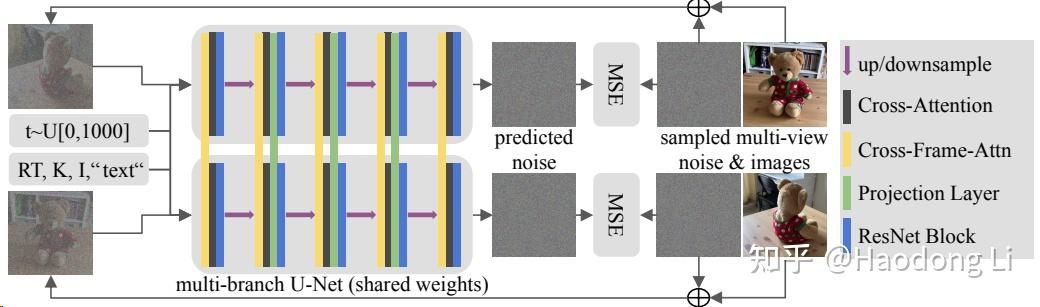
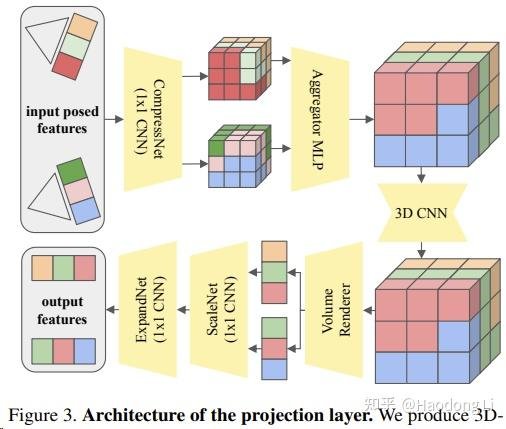
ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models
Facebook开源的喔,罕见
CameraCtrl
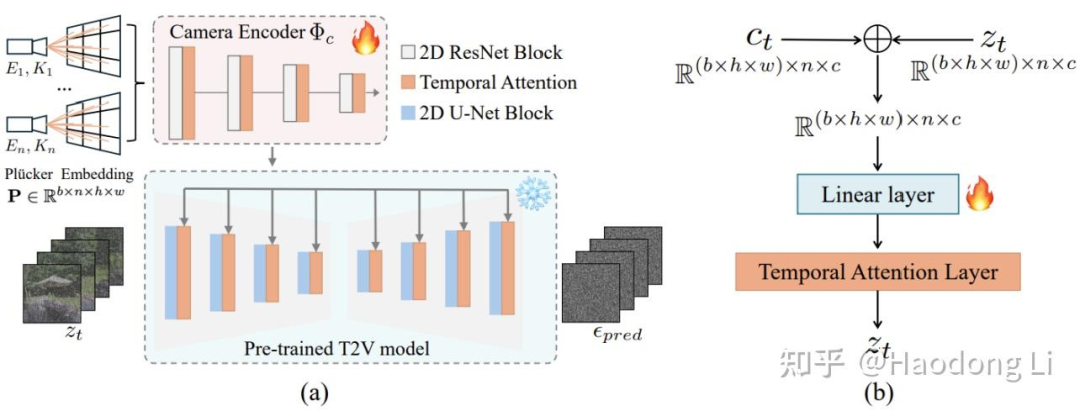
CameraCtrl
为每种Camera trajectory训个lora做Camera control
Collaborative Video Diffusion
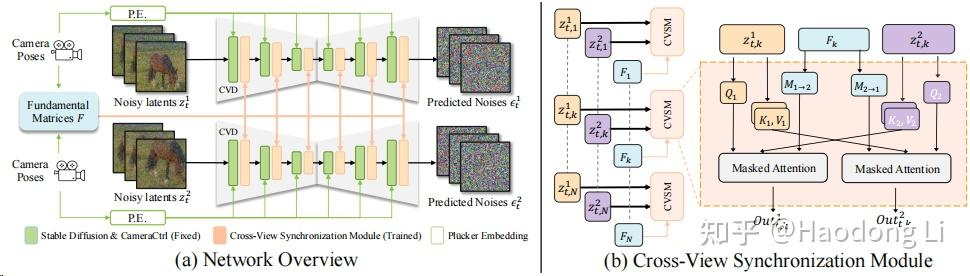
https://collaborativevideodiffusion.github.io/
based上一篇Cameratrol,在训练上做了一些Multiview和time耦合的设计训模型
ViewCrafter
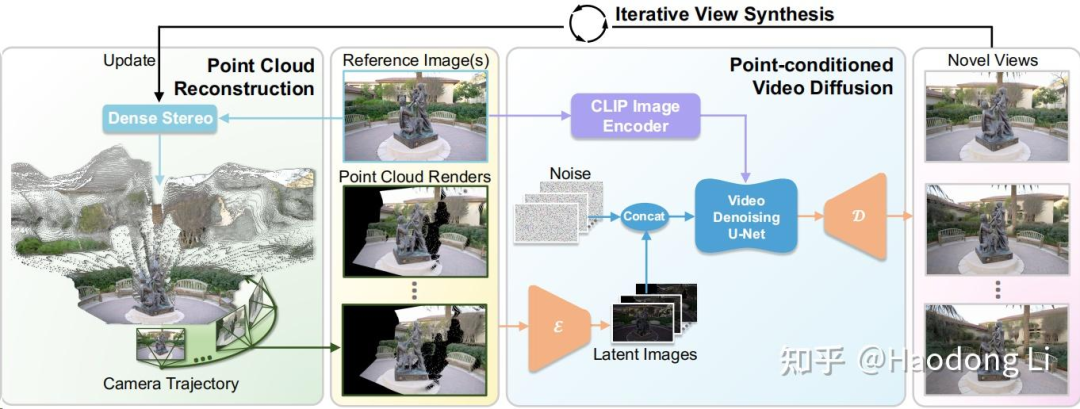

https://drexubery.github.io/ViewCrafter/
用Dust3R给Sparese view打个底,用SVD去refine点云
不过轨迹是预先定义好的,训的时候从25帧中抽1帧来refine剩余24帧
ReconX
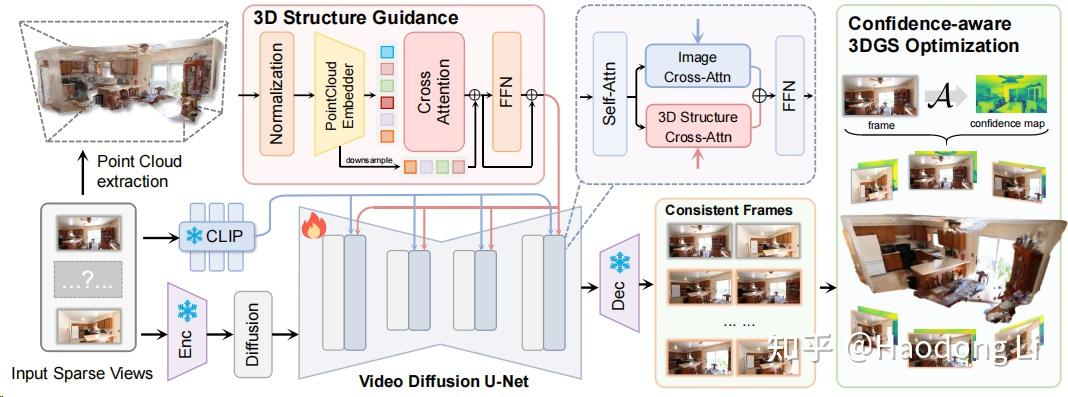
ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model
类似Viewcrafter,加入3D点云解码作为UNet Condition
DynamiCrafter
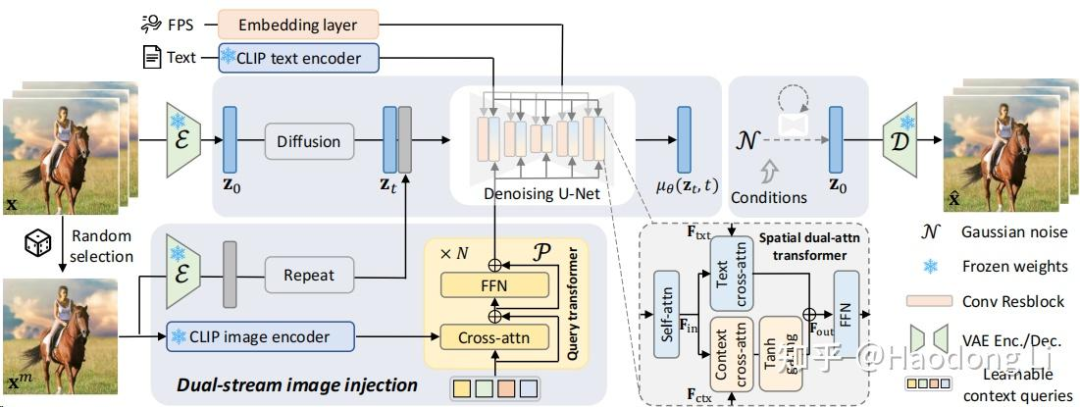
https://doubiiu.github.io/projects/DynamiCrafter
用text/image的双流Attention,为了将image Embedding给align到text Embedding space中用了Q-Former
ToneCrafter
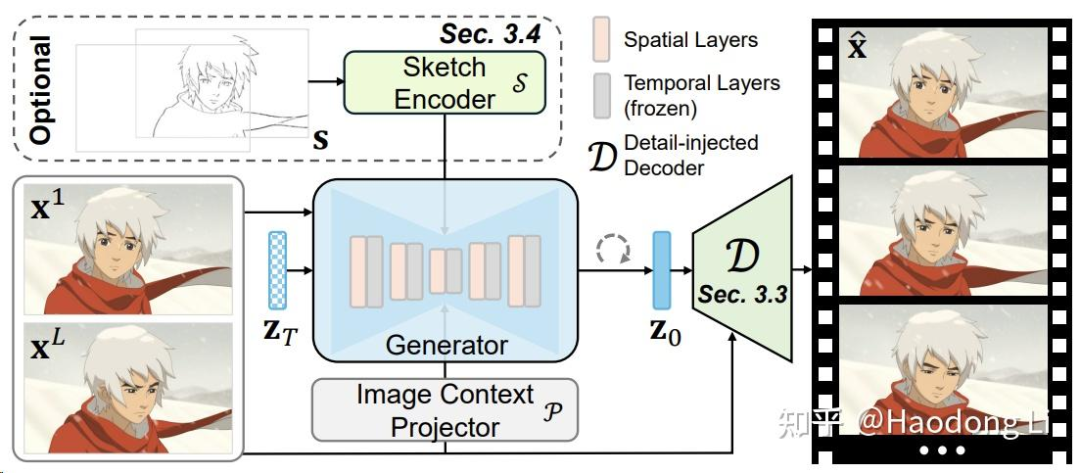
ToonCrafter: Generative Cartoon Interpolation (doubiiu.github.io)
SimDA
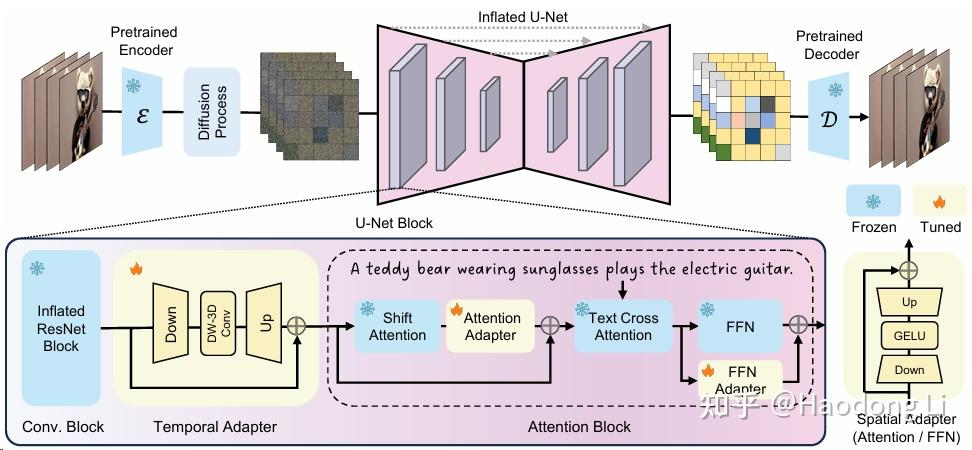
SimDA
FreeNoise/FreeU/FreeInit
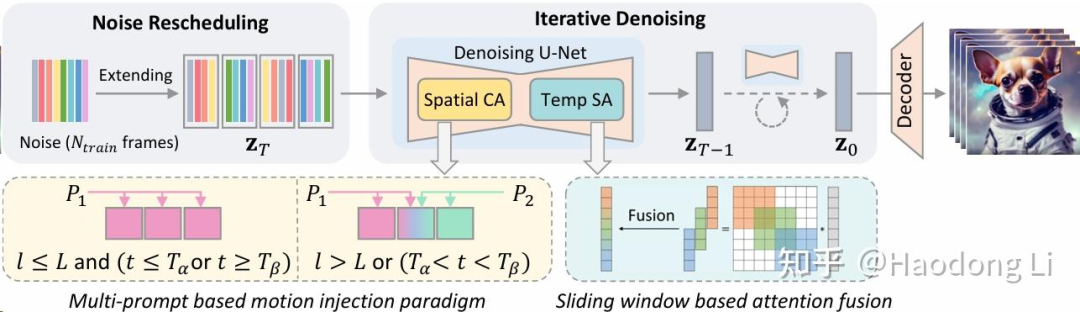
FreeNoise
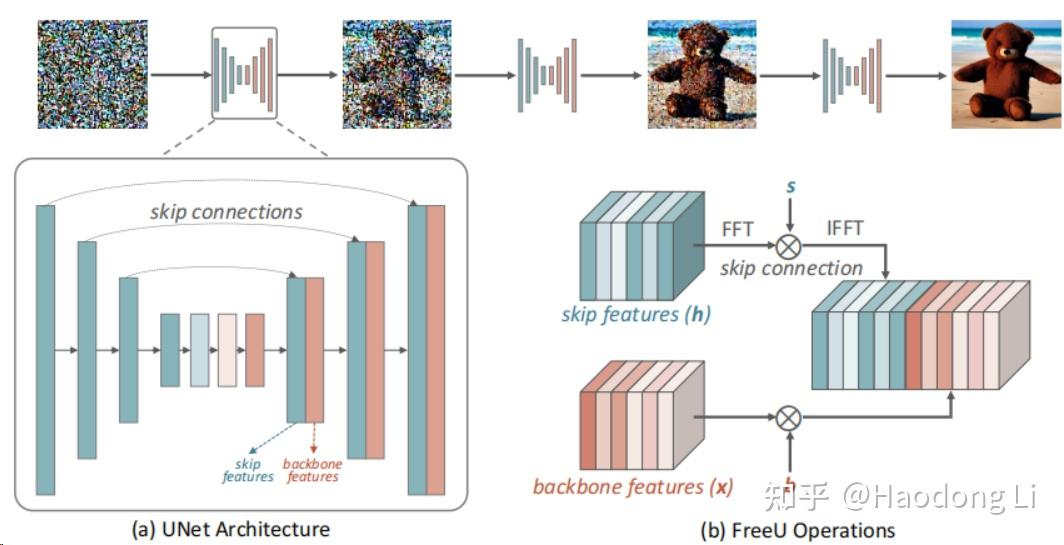
Free Lunch in Diffusion U-Net
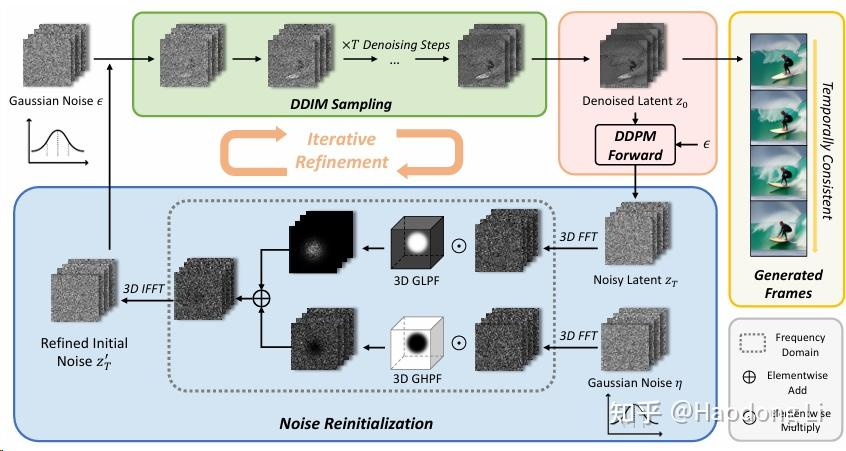
FreeInit: Bridging Initialization Gap in Video Diffusion Models
Video LDM(align your latent)
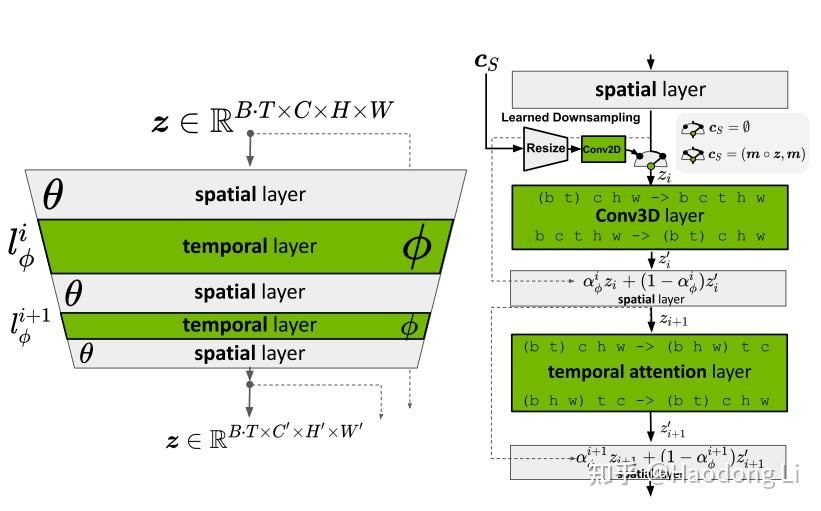
nvidia/closed source
值得关注的是做tensor dimension的处理,ldm只能处理4 dimension的image,加入了两个Temporal layer实现了5 dimension的处理
后面Stability.ai开源的stable video DIffusion完全延用了这个结构(同一个作者)
Tune-A-Video
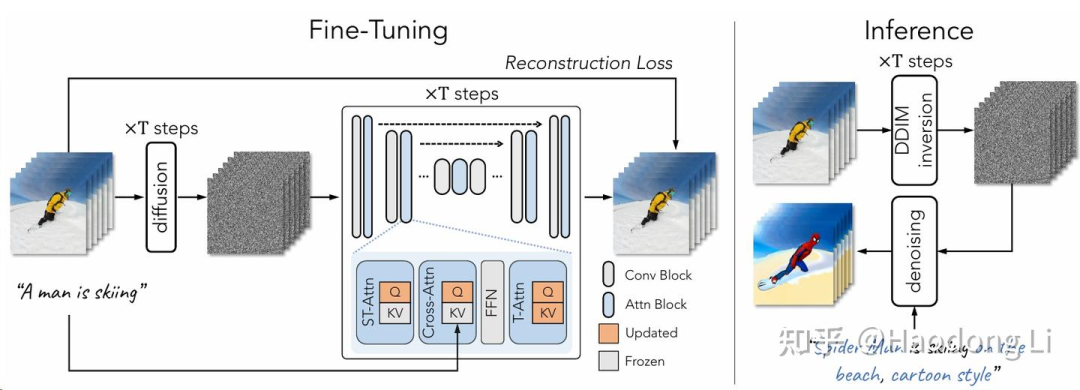
常用于editting task的codebase
Tune-A-Video
逻辑:在editting前进行DDIM inversion,再通过改变prompt进行denoising实现editting
训video DIffusion还是基于LDM做Finetune,具体做法是在UNet中加入adapter(加入ST-Attn)
AnimateDiff
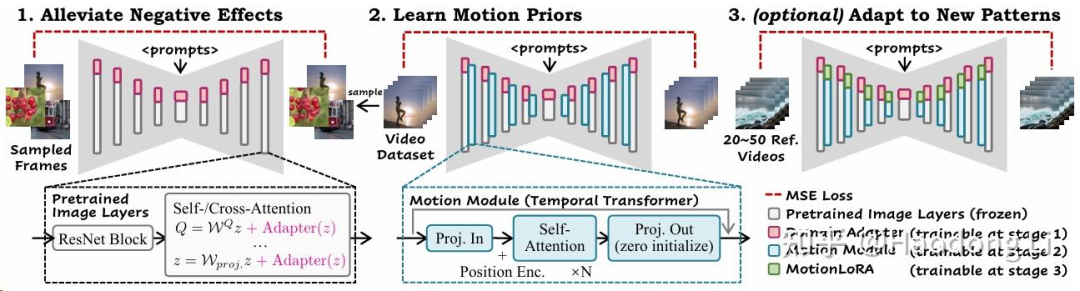
AnimateDiff
提出了video Finetune的范式:
第一阶段:通过LoRA拉进image和video frame的domain gap
第二阶段:用video去训adapter
第三阶段:通过LoRA学motion
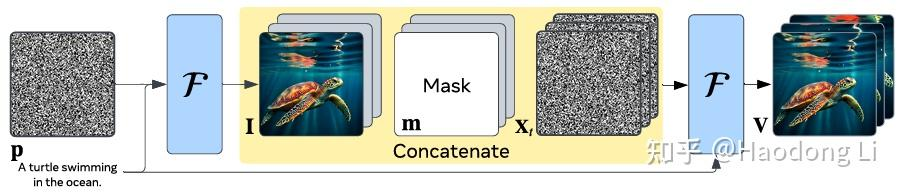
Emu Video
Emu Video | Meta
好像没开源,自回归的方式一帧训出剩下全部帧
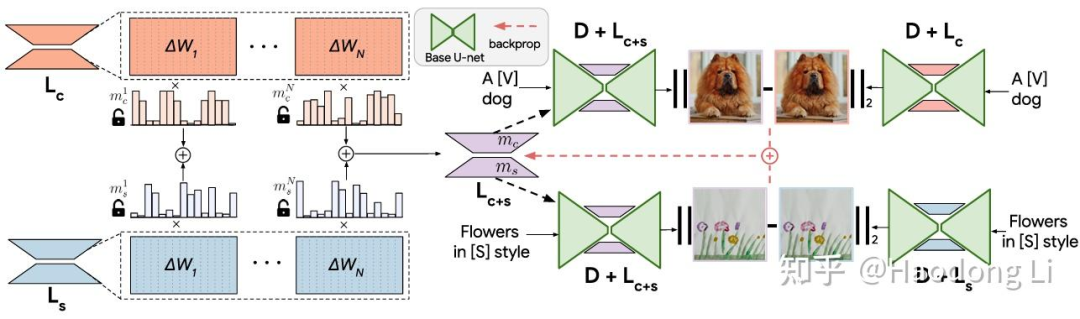
ZipLoRA
ZipLoRA
一个LoRA提供ID,另外一个LoRA提供Style
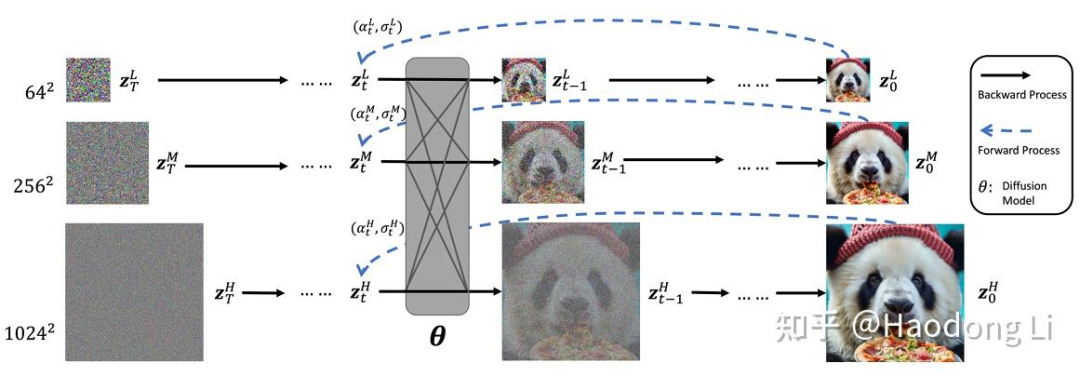
Matryoshka Diffusion model
apple/ml-mdm: Train high-quality text-to-image diffusion models in a data & compute efficient manner
套娃DIffusion,无需VAE
Pyramid Attention Broadcast
NUS-HPC-AI-Lab/VideoSys: VideoSys: An easy and efficient system for video generation
做加速生成的,通过共享Attention计算结果
Latte
Latte: Latent Diffusion Transformer for Video Generation
第一批用DiT的video Generate,同期:Open-Sora/Open-Sora-plan,学术界追赶工业界hhhh
感觉Latte像是一篇技术报告,告诉你什么是最好的,不过latte对于video的token化还是比较有Insight的(时空tokenization)
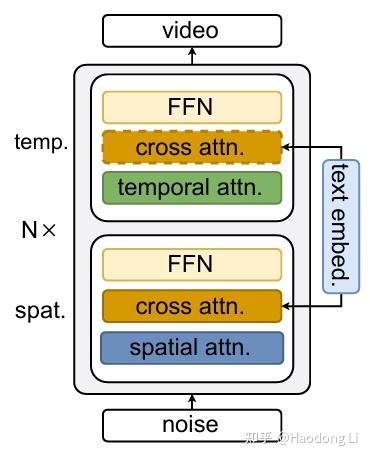
Follow-Your-Pose
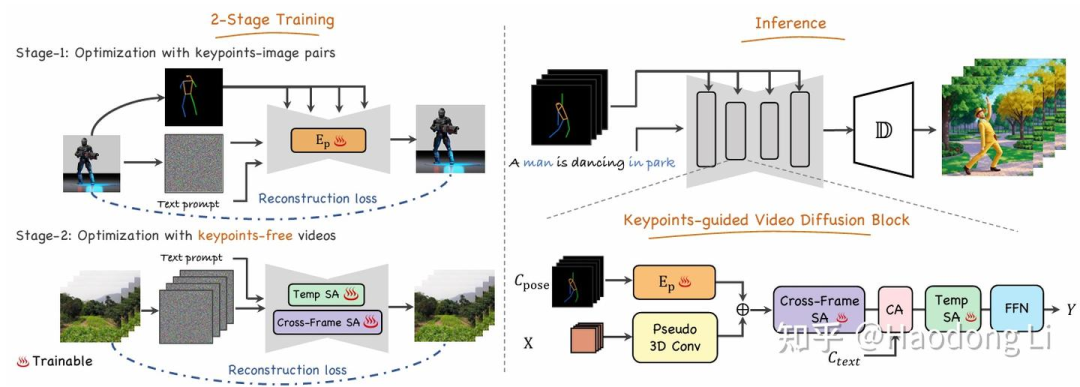
Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos
两阶段训练策略
Follow-Your-Click
Follow-Your-Click
局部视频生成(open-domain regional image animation),和两个text做CA,增强对motion control
Follow-Your-Handle
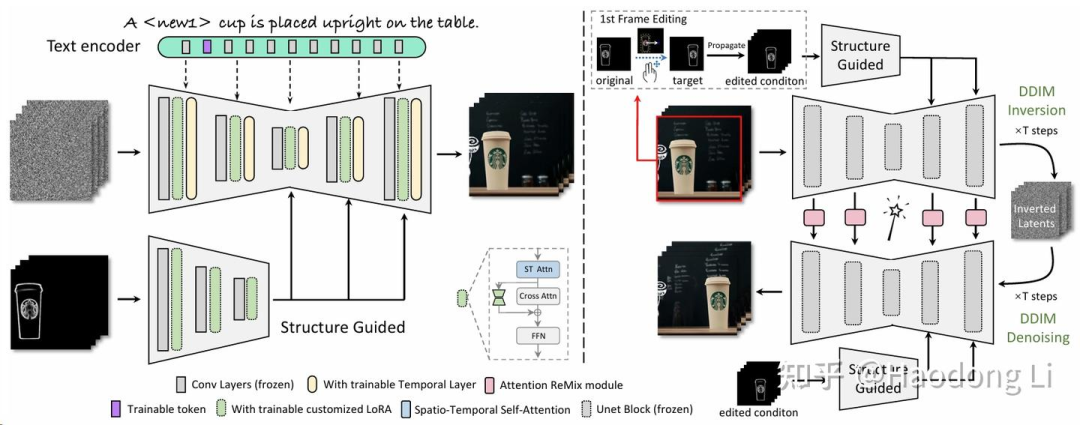
MagicStick
通过Sketch生成video,同时我们可以通过edit sketch进行video editting,包括放大缩小等等
(有点没看懂,可能不是sketch,和attention map有关,不过代码不开源我也没细看了)
Follow-Your-Emoji
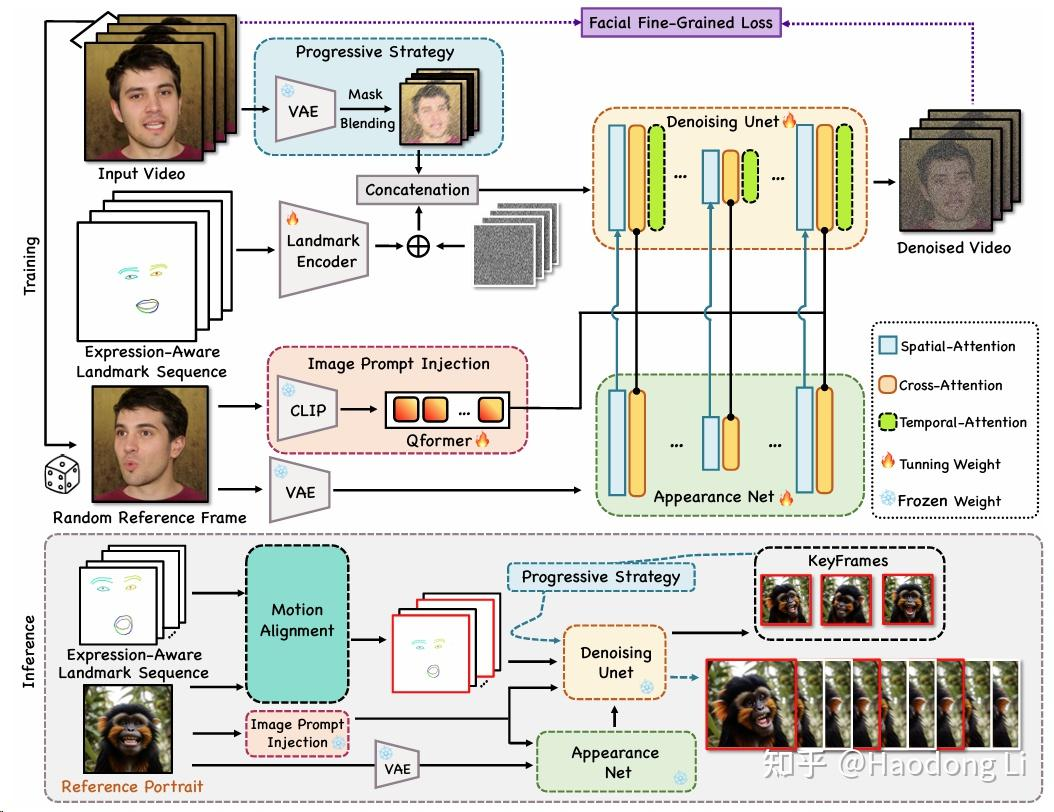
Follow-Your-Emoji
做face-control会比做pose-control难很多,所以他提了个细粒度的face landmark且做了个数据集
Follow-Your-Canvas
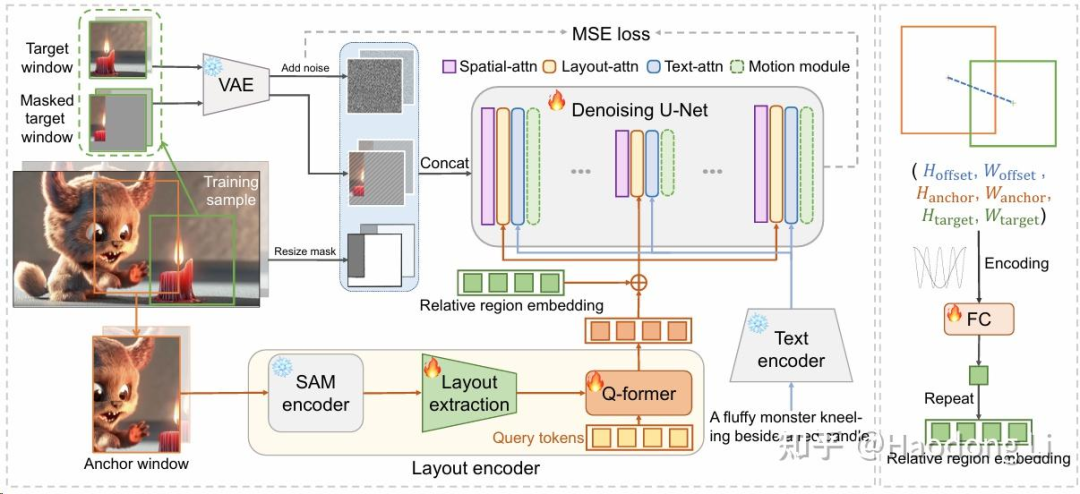
Follow-Your-Canvas: Higher-Resolution Video Outpainting with Extensive Content Generation
过去做outpaint的工作只能做差不多1:1这种级别,Follow-Your-Canvas通过滑动窗口机制可以做到1:4的outpaint
CogVideoX
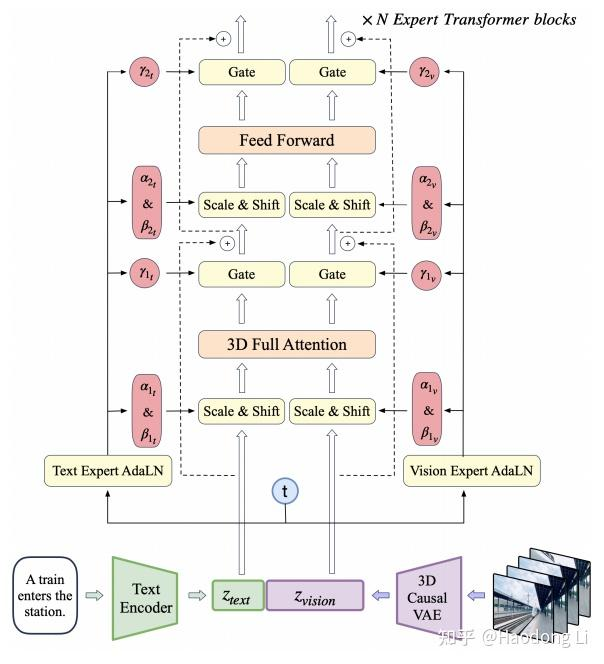
THUDM/CogVideo: text and image to video generation: CogVideoX (2024) and CogVideo (ICLR 2023)
用DiT-backbone,不再只是让text做CA,而是参与SA+FFN,同时也用AdaLN设计让text/video对齐
同时也做了video data caption的data argument和训练上video-image joint training的训练策略
Lavie
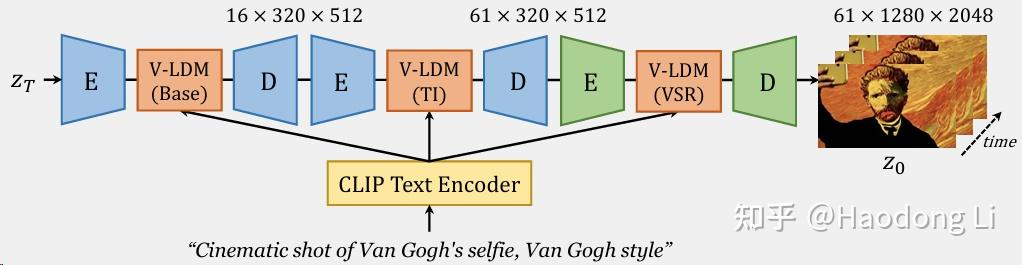
LaVie
先用base model生成一个短时间+低分辨率的视频(16320 512),再用两个超分模块先延时,再提高分辨率
MIMO
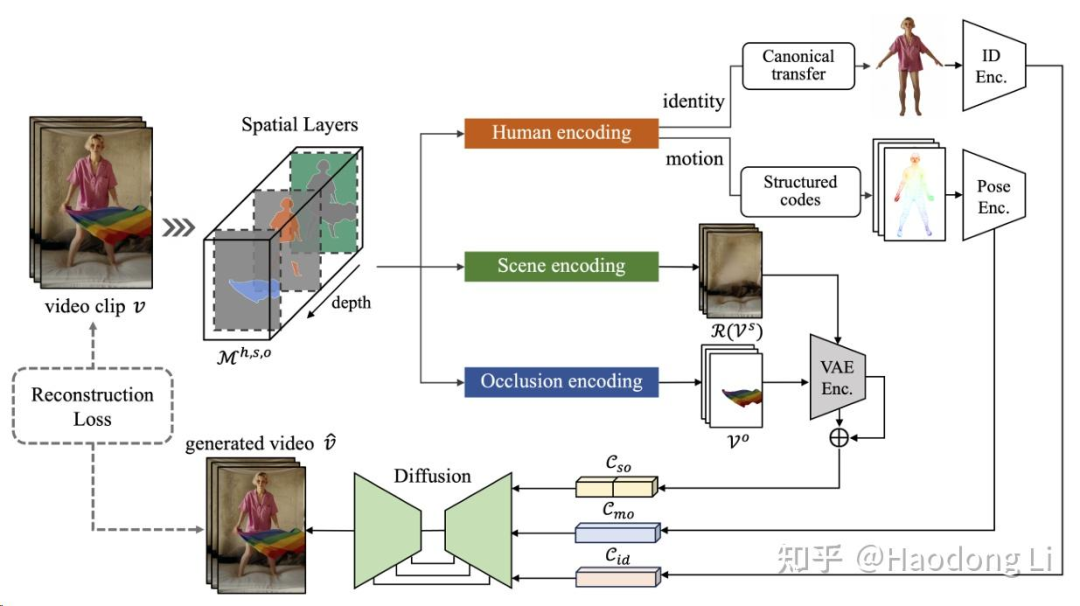
MIMO
将video解耦为三层:前置遮挡层,主体层,背景层,再进一步将主体层解耦为motion和appearance
这样相比直接scale up的方法可以做Controlable,同时也可以更容易做editing
Tora
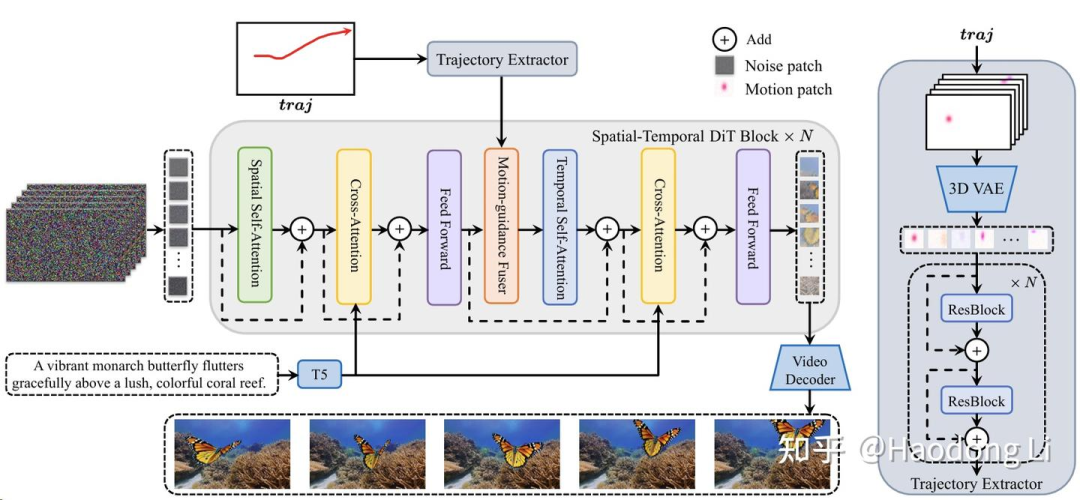
Tora
通过Trajectory extractor(3D VAE)将traj信息注入到DiT架构中,训的时候先用密集光流再用稀疏轨迹
再将motion latent和video latent通过adaptive norm的方式结合在一起训DiT
有一个小的Insight:将两种information结合往往adaptive norm(自适应归一化)效果是比较好的
IV-mixed Sampler
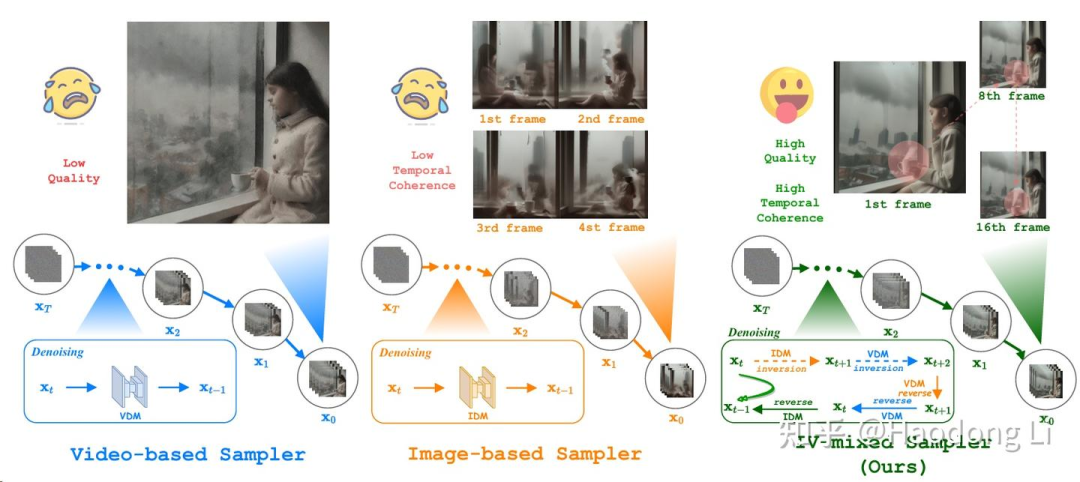
IV-mixed-Sampler
Z-sampling的后续工作,从t2i扩展到了t2v
VideoGen由于training dataset low quality导致inference result low quality
image generate model在motion上做的很差
所以IVIV的denoise&inversion方式本质上是在做quality(image generation)&motion(video generation)d trade-off
SynCamMaster
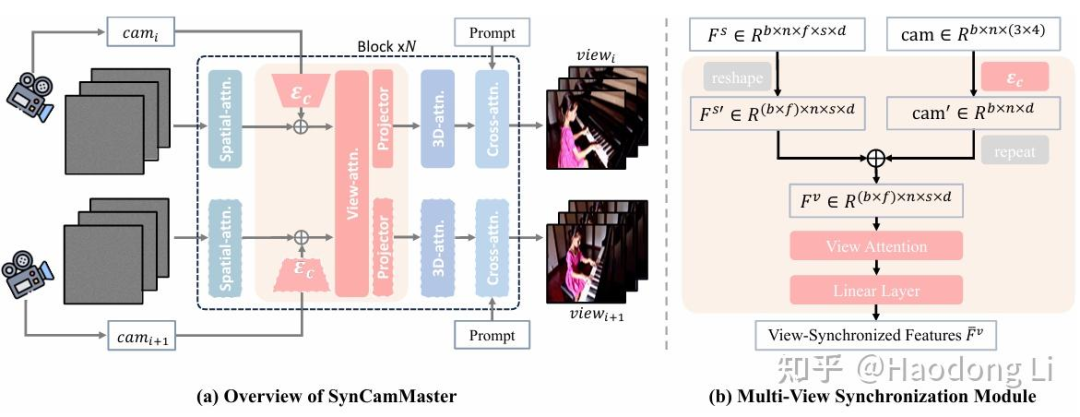
SynCamMaster
在camera control的VideoGen越来越火,常见几个applicant:1. 电影制作 2. 4D reconstruction 3. 为具身提供数据
camera control的做法基本是在Finetune VideoGen backbone,加adapter或lora
这篇paper在Pipelinen还是很直接的,直接encode camera 外参和frame相加加入到DiT-based中
3DTrajMaster
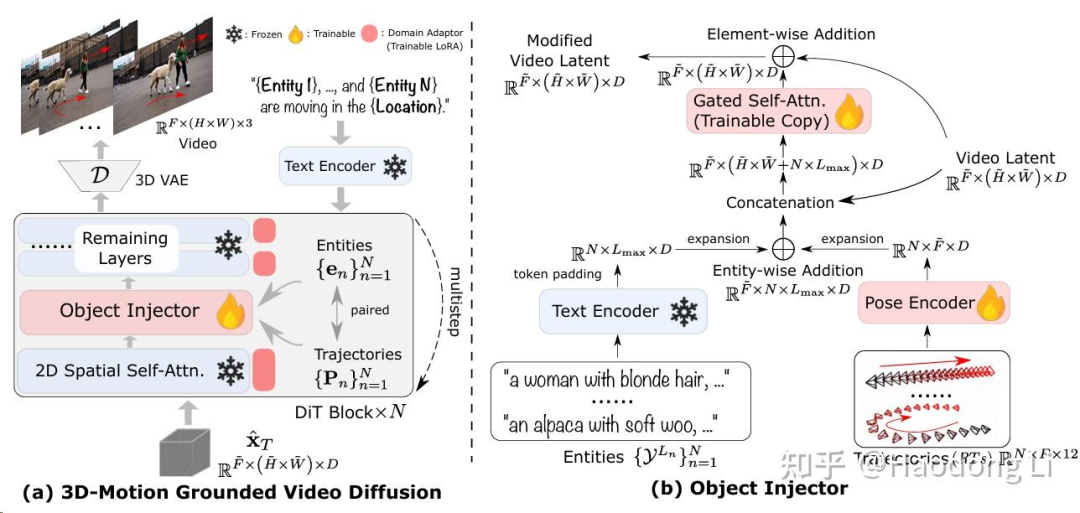
3DTrajMaster
在dataset的design上,用UE+打光获得360 scene date(我当时想用blender采集scene的发现没有)
也是通过data-driven的方式实现6 DoF control,即可以控制video id的朝向
在framework的design上,先对每个layer训LoRA,再将LoRA frozen住训Object Injector layer
有个有意思的地方:训练数据都是Synthesis那怎么生成real world data呢:通过降低LoRA的\alpha控制程度
其次是DDIM:前几个steps会将低频的Trajectory信息生成出来,后几个step就退化为标准的T2V降低计算开销恢复出高频信息
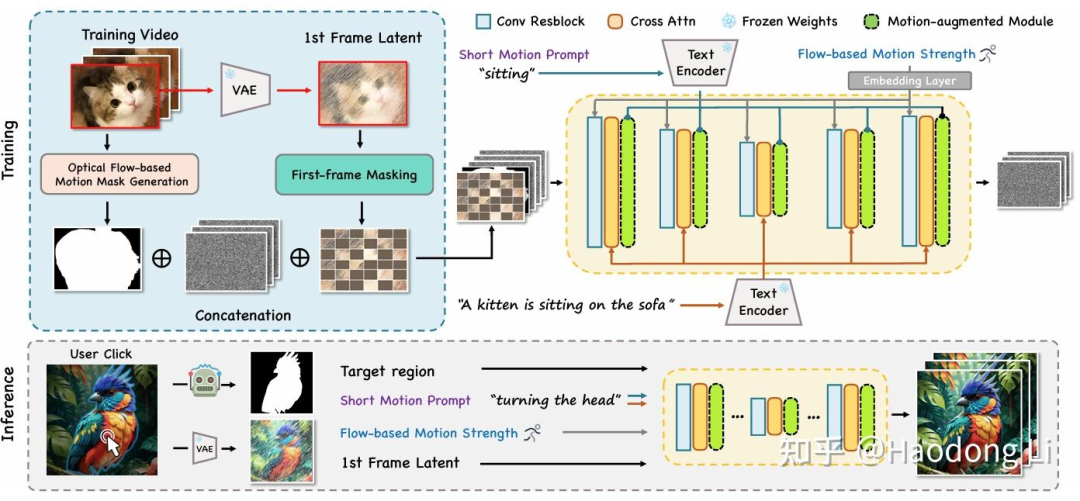
MOFA-Video
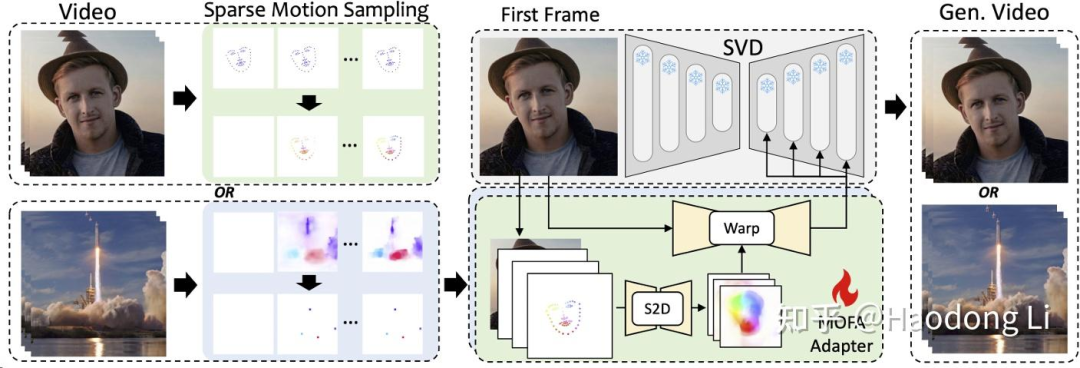
MOFA-Video
做hybrid control(trajectory箭头+人脸 landmark),比如talkingface同时让背景动起来
从dense flow提取sparse flow,再用S2D转为dense flow进行生成
和MotionDreamer类似,但是MOFA更关注视觉质量,MotionDreamer更关注将sparse flow转为Dense Flow
MotionDreamer
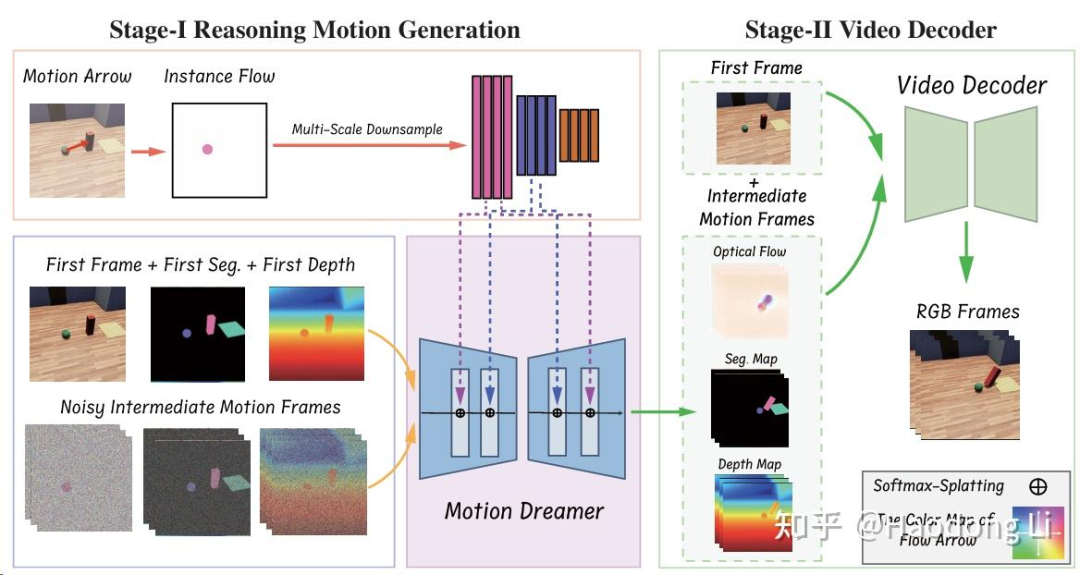
Motion Dreamer
类似GPT4Motion,first frame-->middle frame feature map(depth/flow/segment)-->video
采用two-stage method,先生成causal condition再生成high quality video
主要在predict middle frame feature map中通过掩码建模等loss训的比较好
EvalCrafter
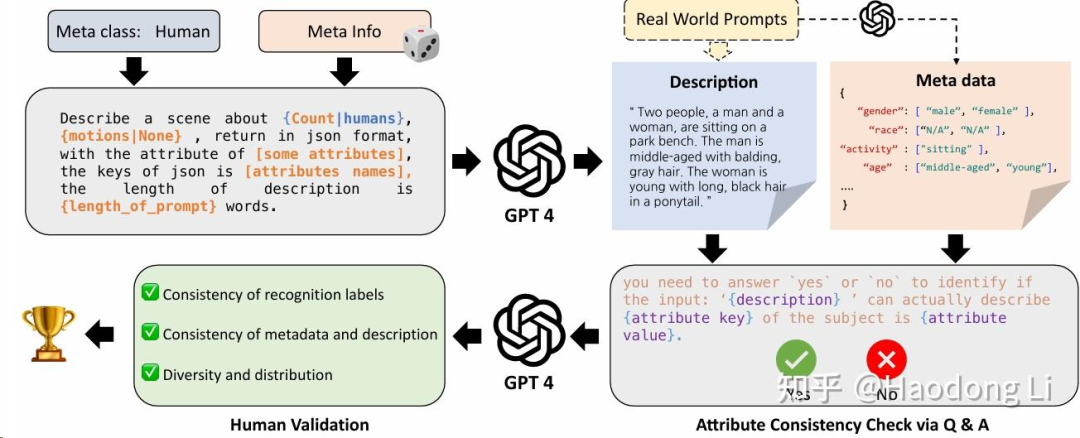
EvalCrafter
和VBench同期,对VideoGen perform 评估的工作
Cosmos
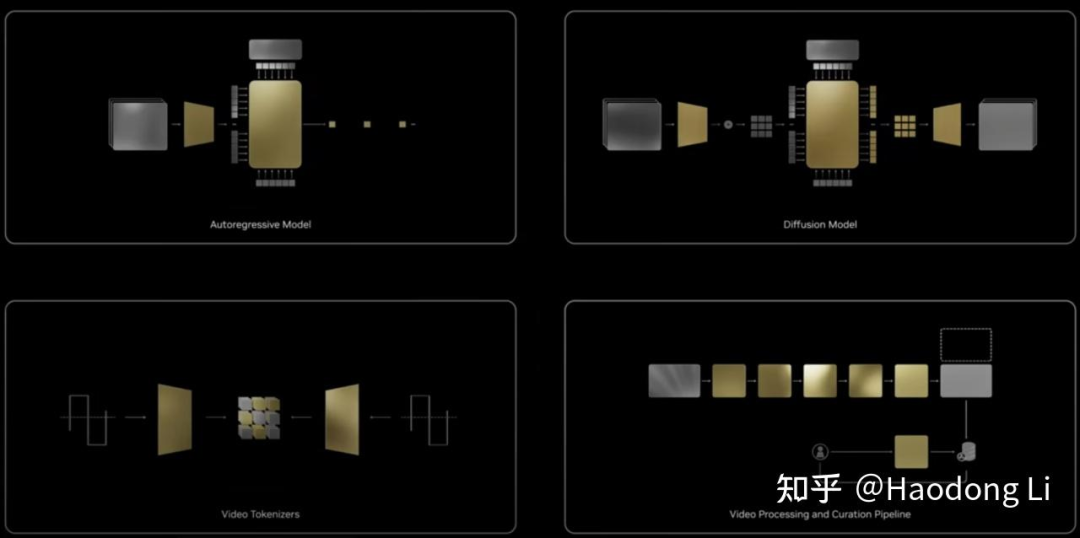
Cosmos
和Omnivarse左脚踩右脚,在1w块h100上训3个月,开源了DIffusion-based和AR-based 7B/14B
专门用Physical Synthesis data训的,但是很多case上也没有做的非常好,师兄和我说跑起来很慢,7B生成5s video要半小时
VidTok
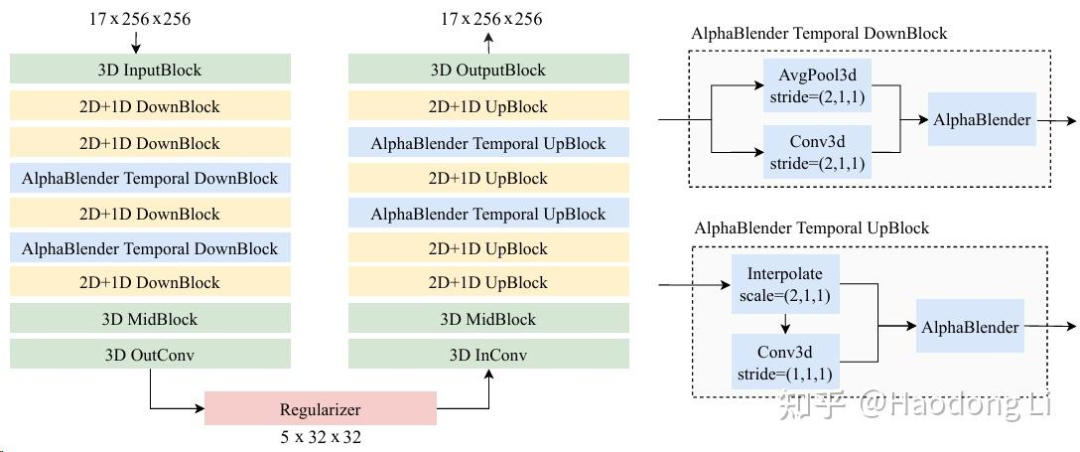
VidTok
用2D+1D卷积的backbone和FSD的量化方式做的video encoder,对于各种setting都可以有比较好的performance
encoder classify: 1)continous and discrete latents 2)causal and non-causal 3)different video compression ratios(temporal&spatial)
4D generate
MAV3D(Make-A-Video3D)
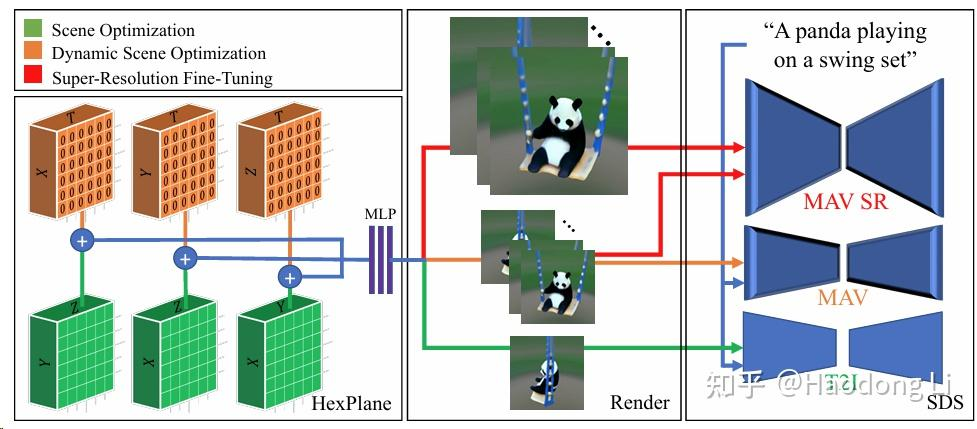
MAV3D 未开源
Sync4D
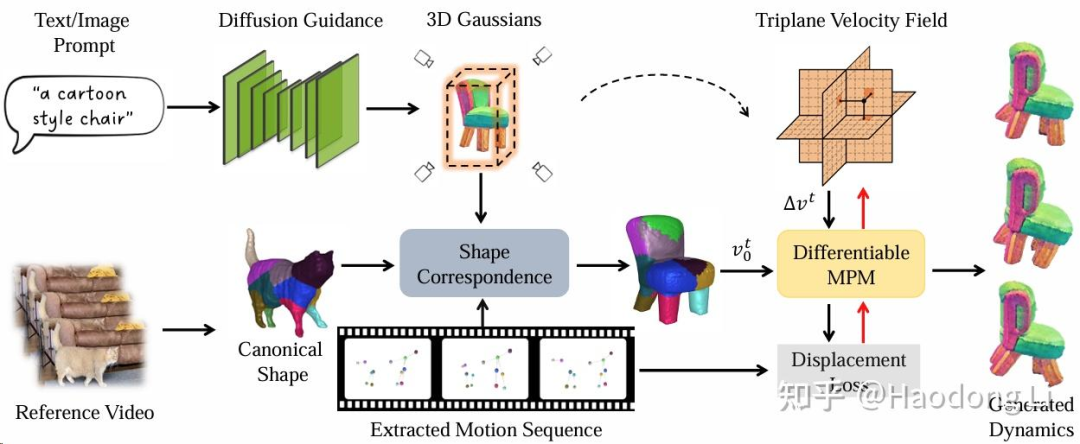
Sync4D
保存A主体id信息,学B主体motion
4DGen
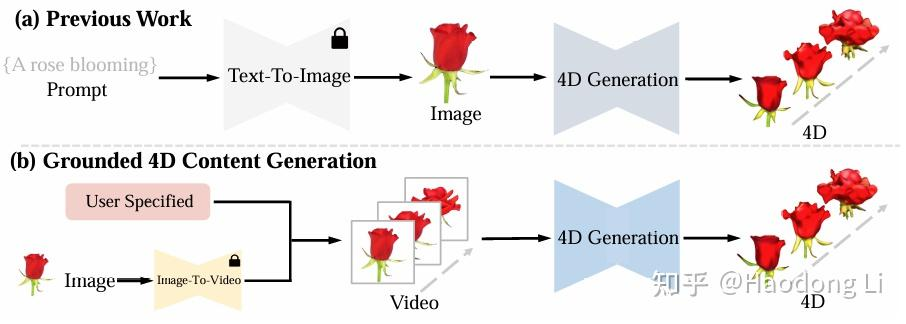
4DGen: Grounded 4D Content Generation with Spatial-temporal Consistency
Video out of Pipeline,先有一个好的video再做4D,可以将appearance和motion给balance比较好
Diffusion4D
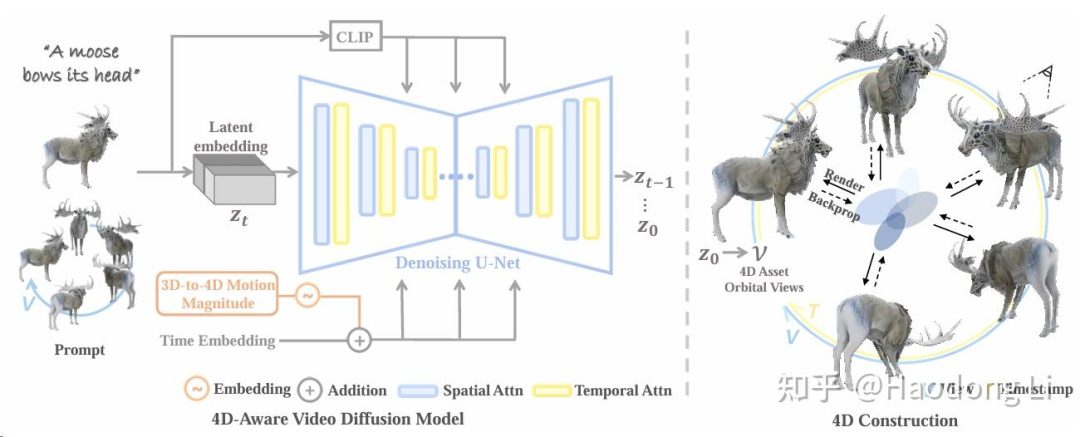
Diffusion4D
Gaussian-Flow
Gaussian-Flow
Deformable 3DGS
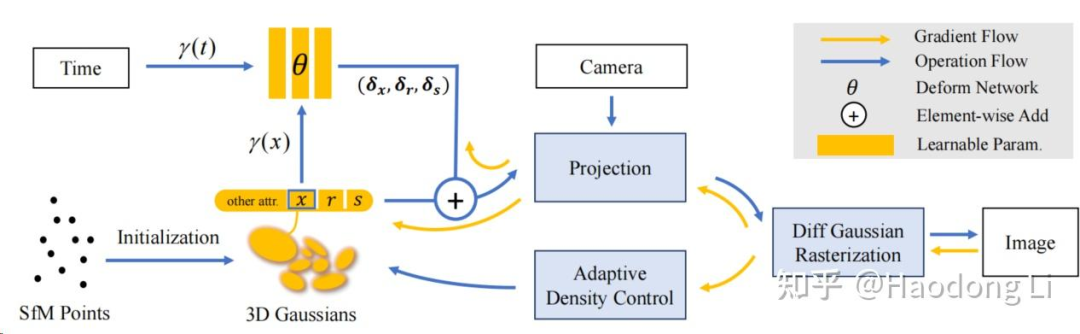
Deformable 3DGS
SC-GS
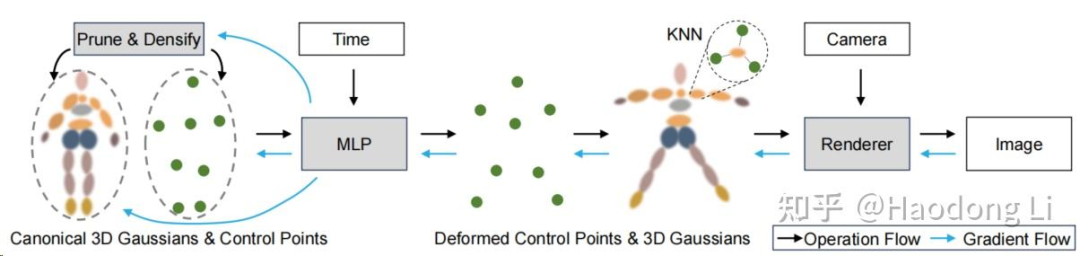
SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes
加入稀疏control points做控制
4DGS
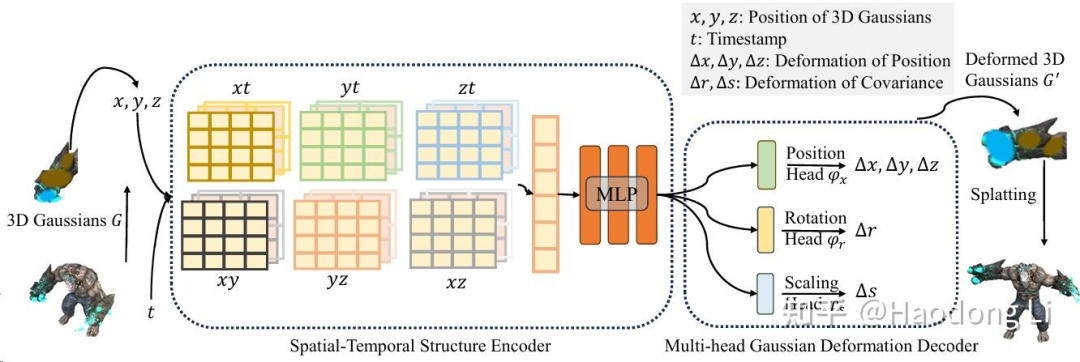
4DGS
分为6平面,后用MLP建模变化
STAG4D
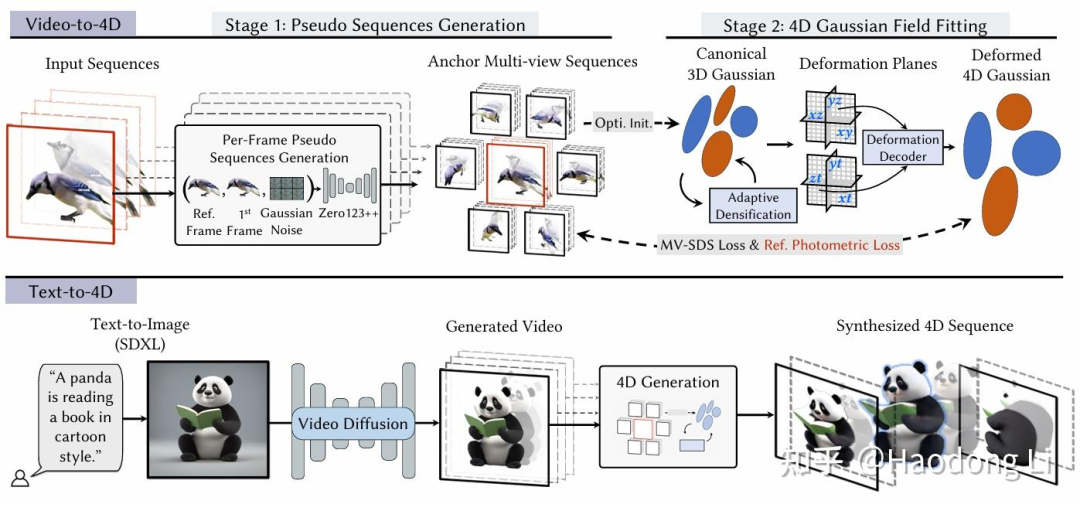
STAG4D
用的是video-->multiview video-->SDS蒸馏到4D Gaussian field 范式
提了一些trick:1. 4DGS更新在densification上 2. 用关键帧提高Consistency上
Trans4D
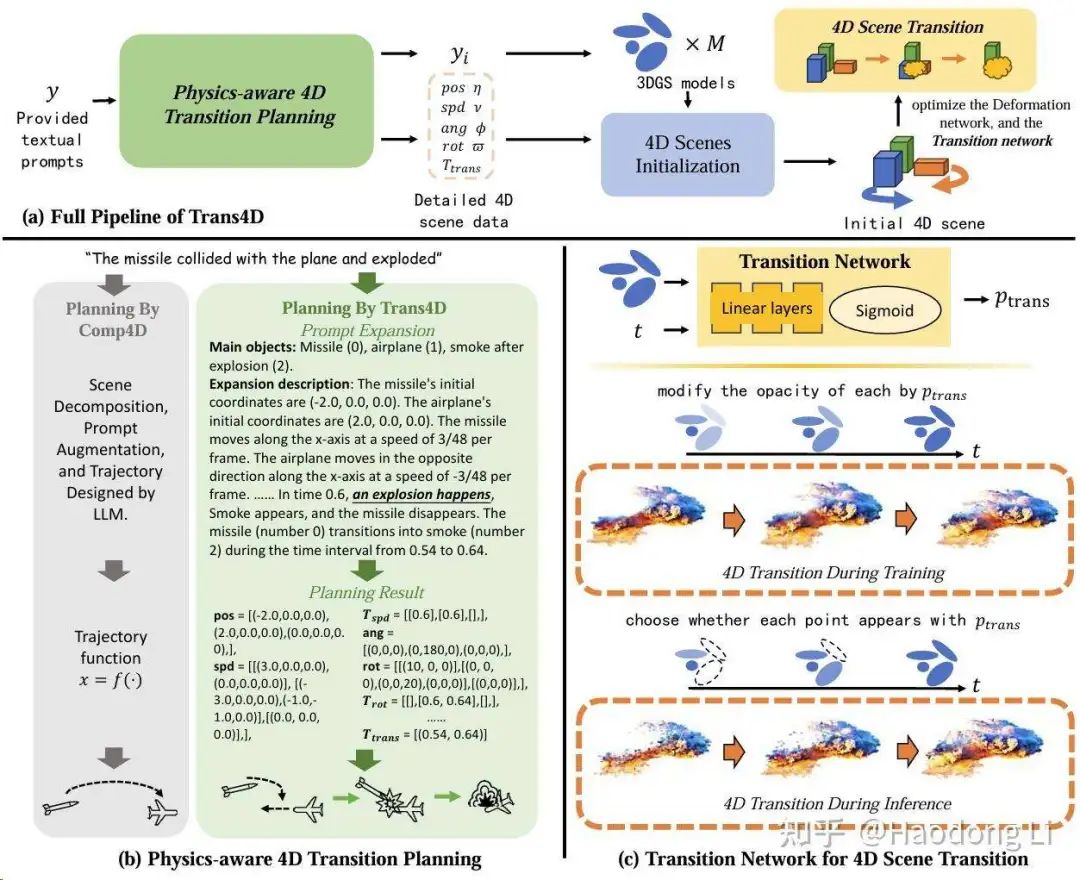
Trans4D
通过MLLM规划到3DGS在每个时间点下变化函数/出现与否等物理控制实现高质量4D
DimensionX
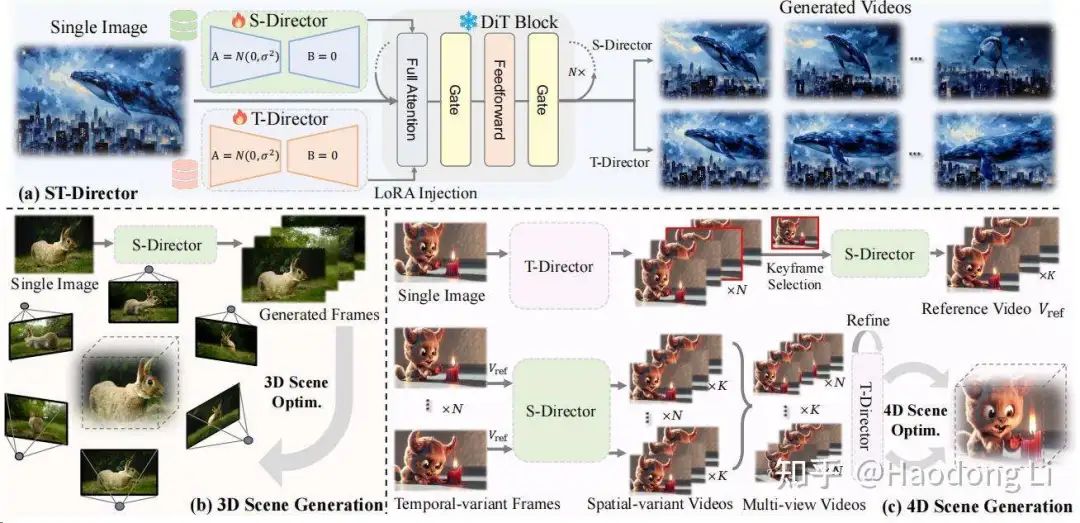
DimensionX
用video generation+Camera control做3D/4D
通过data-driven学出S-Director/T-Director(LoRA),将Temporal和spatial的decouple做的比较好
MotionGS
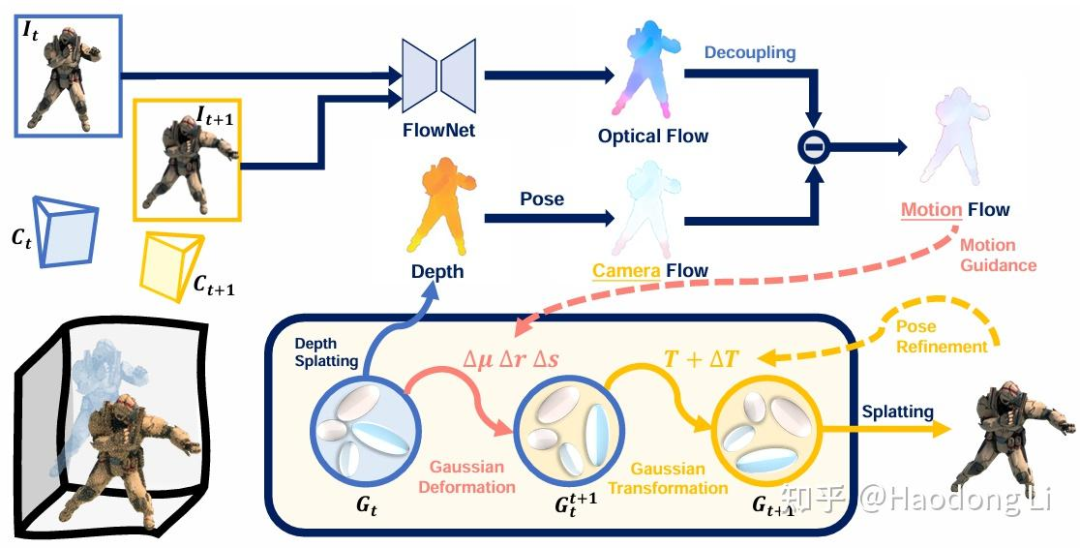
MotionGS
4D reconstruction常见几个数据集都是camera和object同时有motion,这里将optical flow decouple为camera flow&motion flow,用其中motion flow显式监督GS
Image generation
DreamBooth
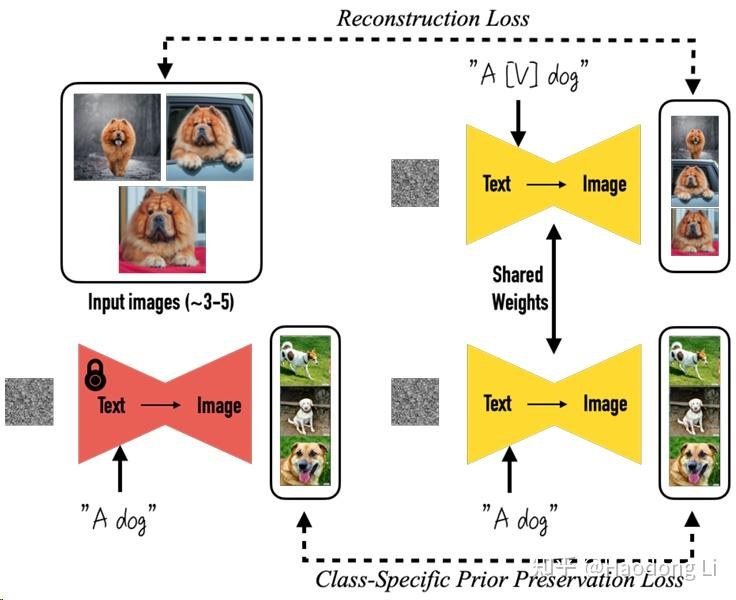
DreamBooth
将image information蒸馏到text prompt中做subject-driven
Textual Inversion
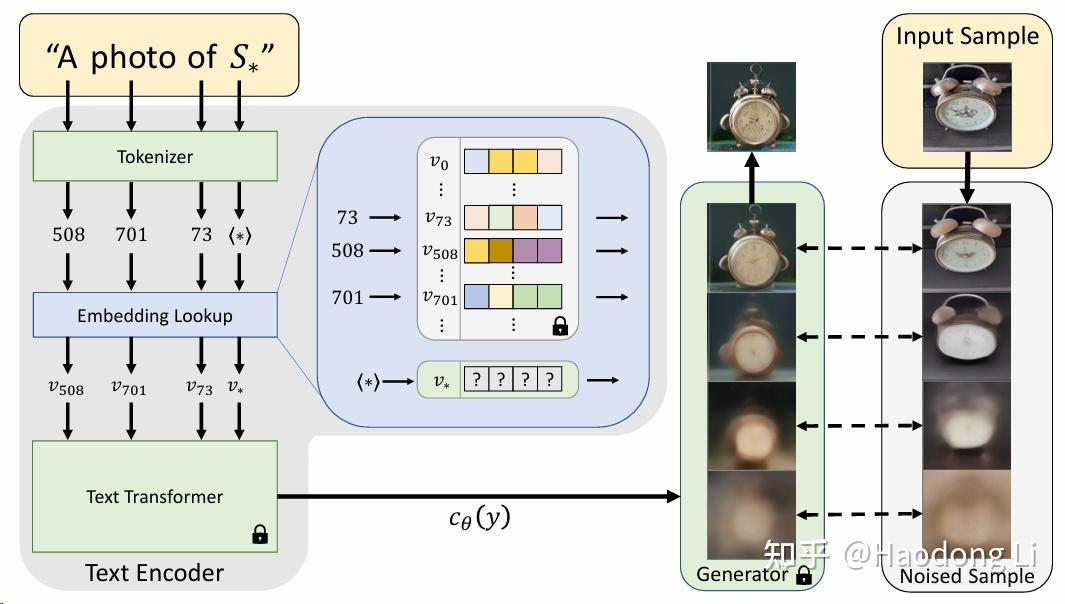
textual-inversion
Cone2
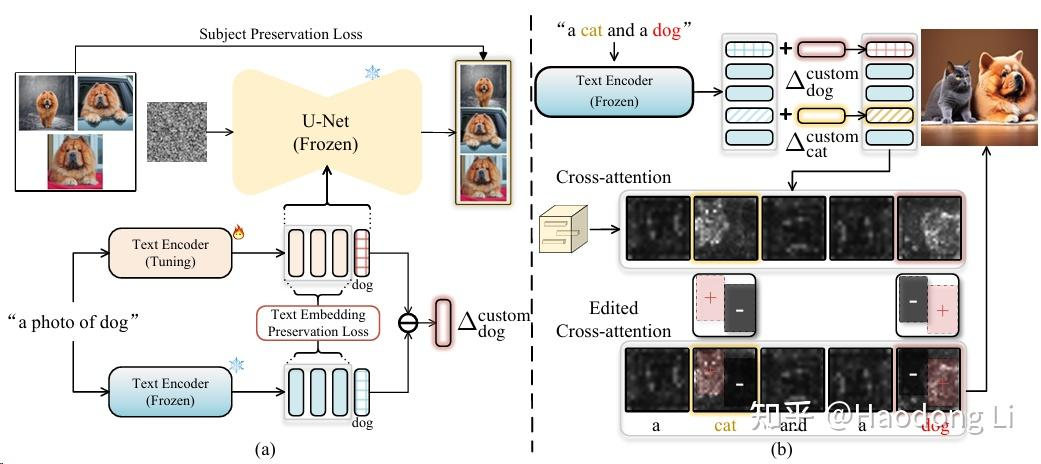
Cones 2: Customizable Image Synthesis with Multiple Subjects
AnyDoor
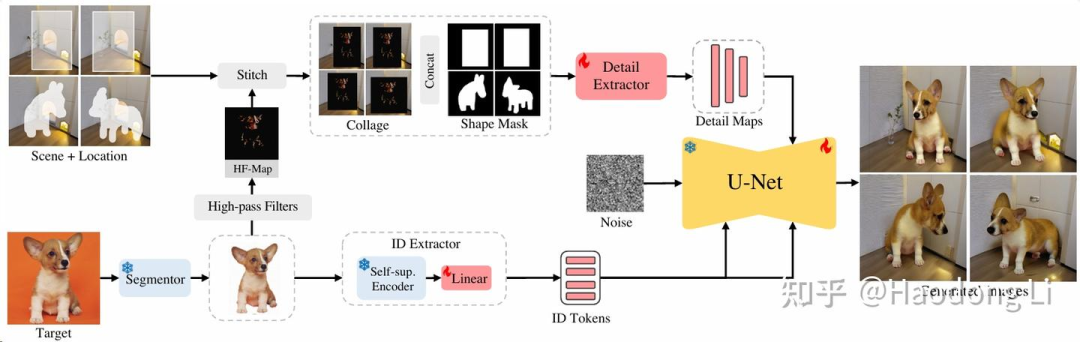
AnyDoor
InstantID
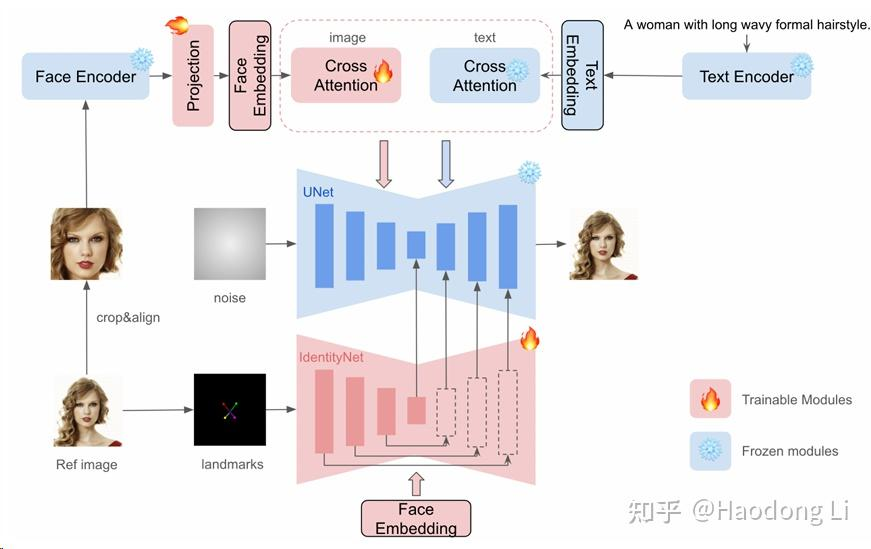
InstantID
和IP-adapter很像,1. 将CLIP-image encoder换为face encoder 2. 加入landmarks分支控制
PersonalVideo
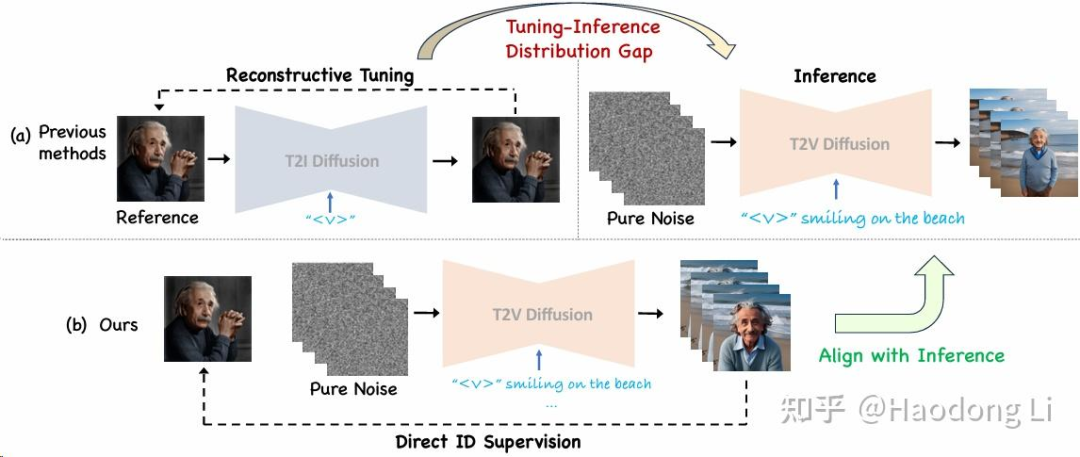
PersonalVideo
MotionDirector
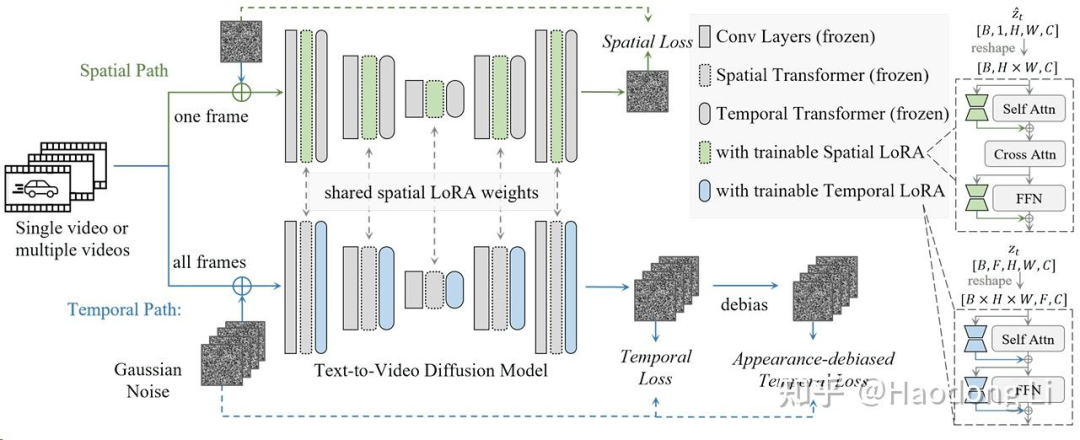
MotionDirector
解耦appearance和motion
Make-Your-3D
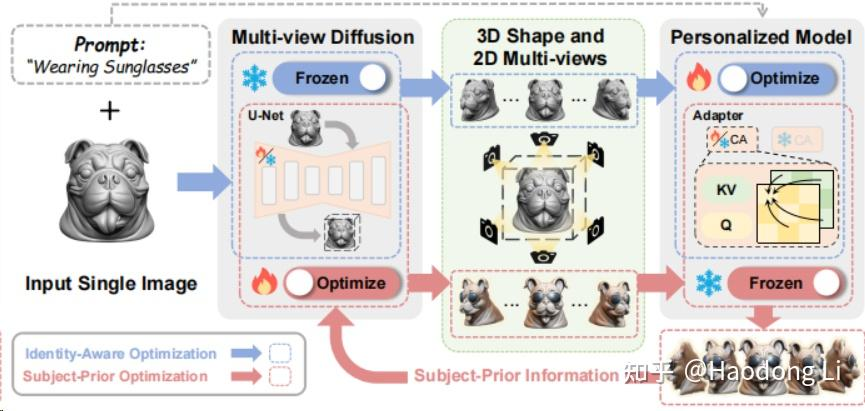
Make-Your-3D: Fast and Consistent Subject-Driven 3D Content Generation (liuff19.github.io)
两个Condition给到两个不同model,可以做相互蒸馏拉到同一个Distribution
VideoBooth
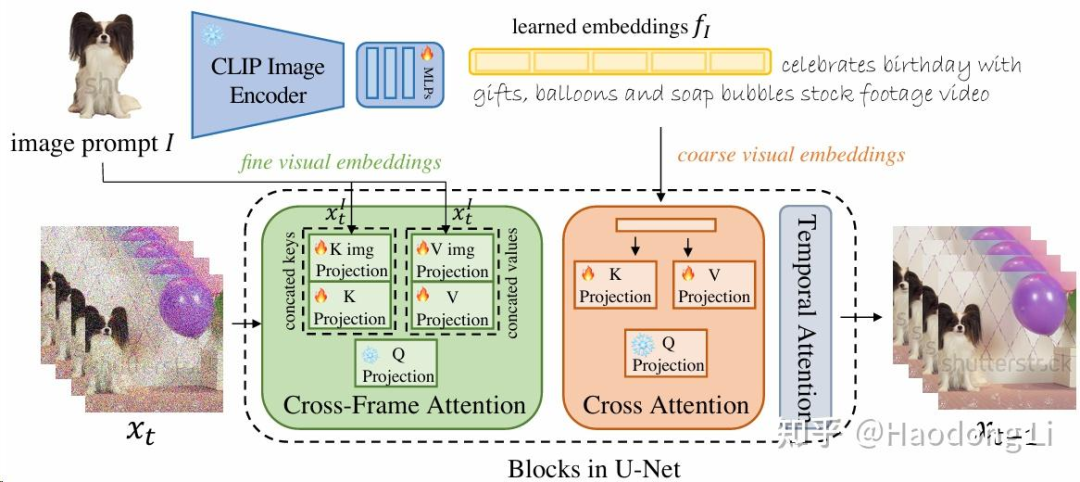
VideoBooth
通过coarse-to-fine的design将image information注入,实现细粒度生成
coarse:通过加MLP层 2. fine:通过更新KV矩阵 10. DreamVideo
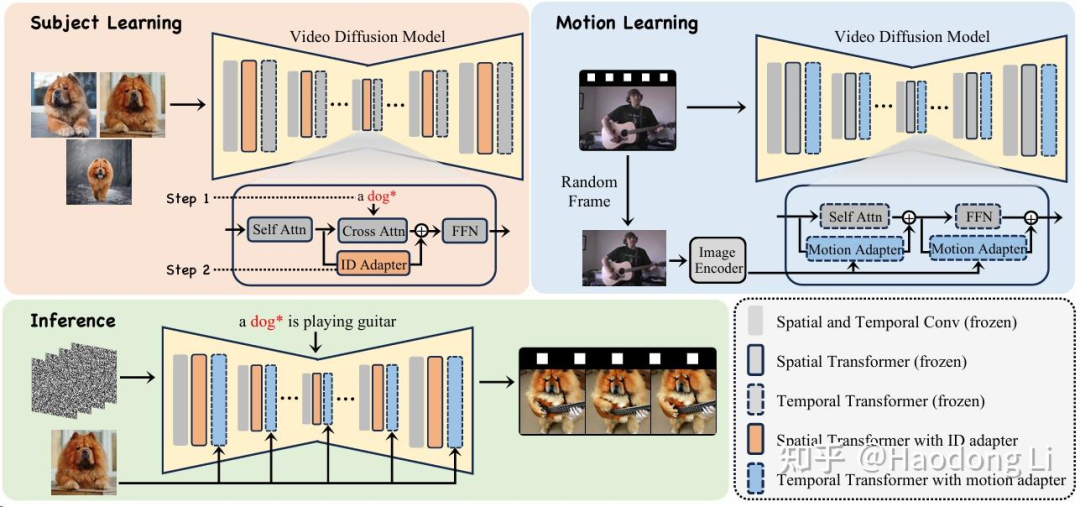
DreamVideo
Collaborative Diffusion
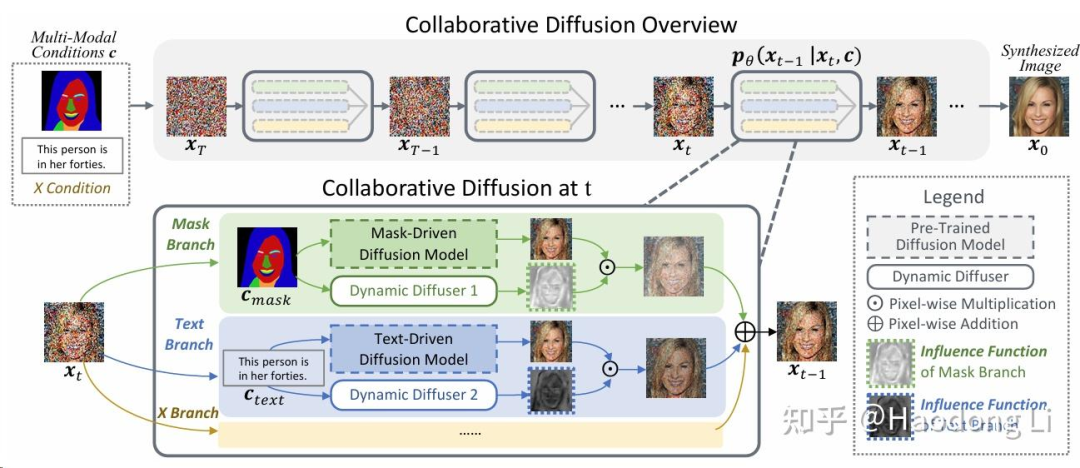
Collaborative Diffusion
只训Dynamic Diffuser控制多模态输入信号生成,类似给了个权重
ReVersion
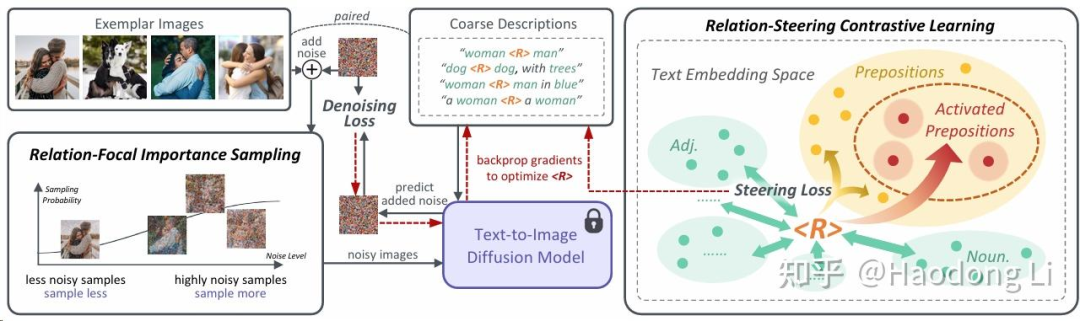
ReVersion: Diffusion-Based Relation Inversion from Images
提出个relation Generation的new task
InstantID
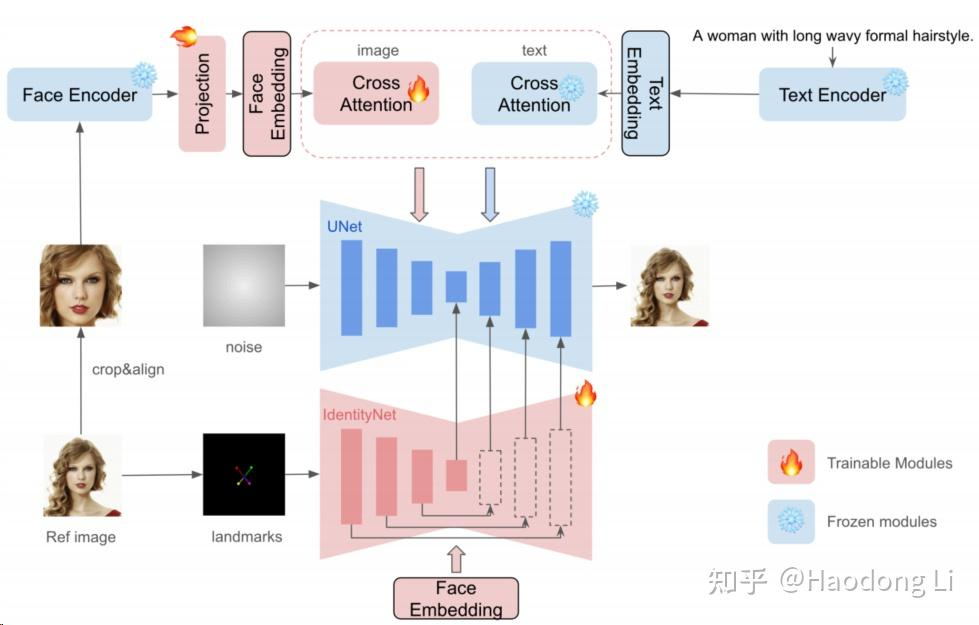
InstantID
和IP-adapter很像,1. 将CLIP-image encoder换为face encoder 2. 加入landmarks分支控制
SD3
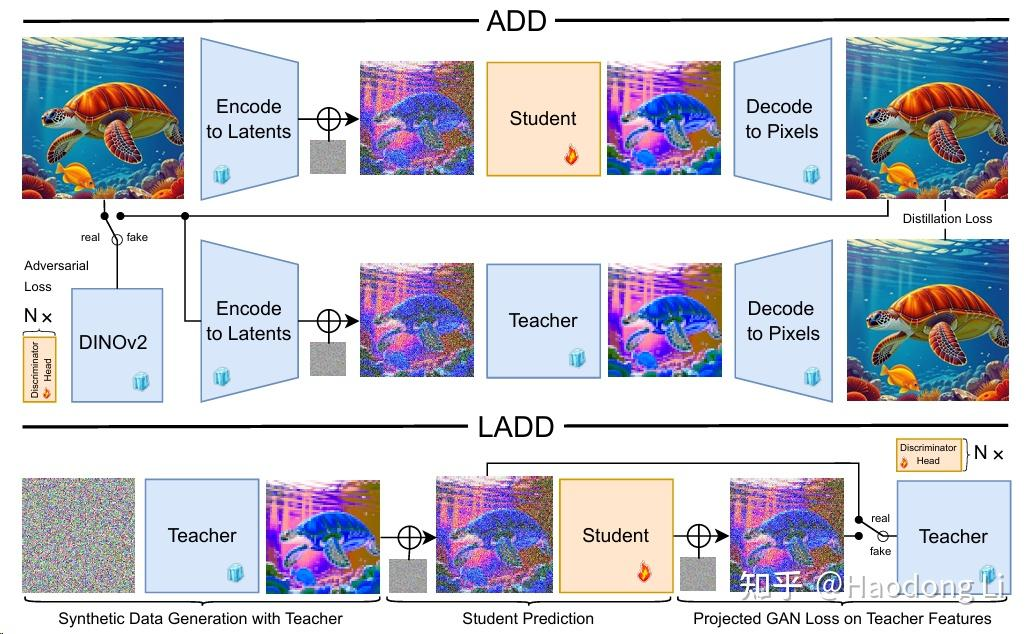
Stability-AI/sd3-ref
不再用UNet,用Transformer做high-resolution
IP-Adapter
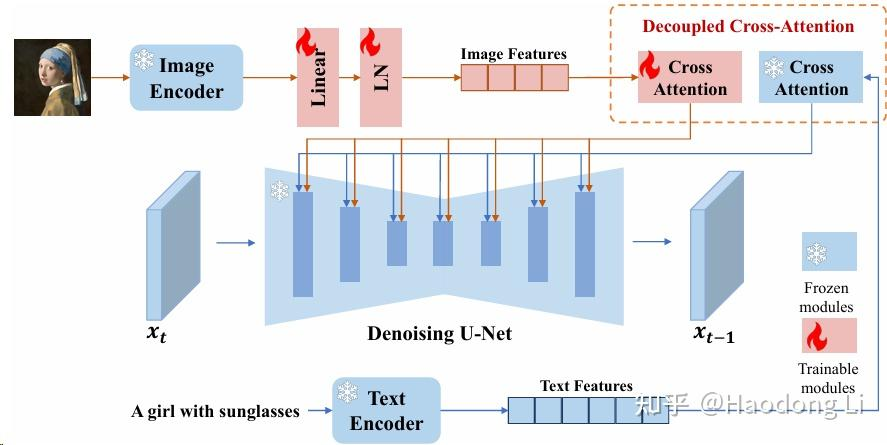
IP-Adapter
design很直接,但是Image Encoder采用CLIP,生成效果难处细粒度信息
VAR(VIsual Autogressive Model)
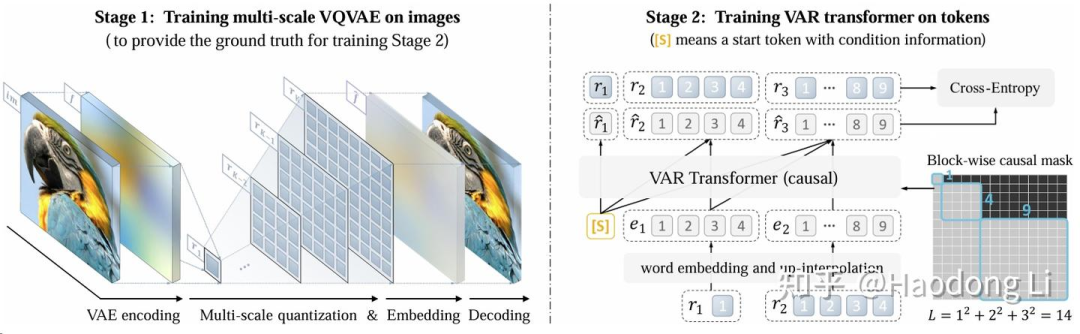
FoundationVision/VAR nb,中nips best paper了
过去的工作AR:对patch做auto regress,但是这个其实非常破坏信息连续性
VAR是对不同resolution做auto regress,符合autogression定义且符合人类直觉
PixArt-alpha
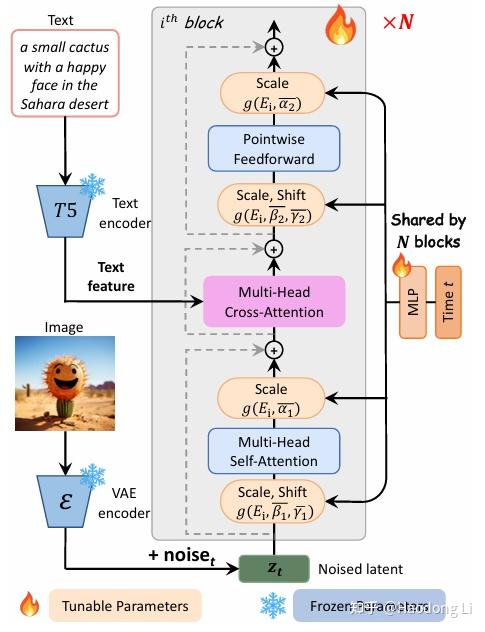
PIXART-α
不是training from sketch,是用Imagenet训好的DiT做init,Finetune CA那一层
在model+data都都在了一些设计,在data上设计包括llm重整Caption等
RealCompo
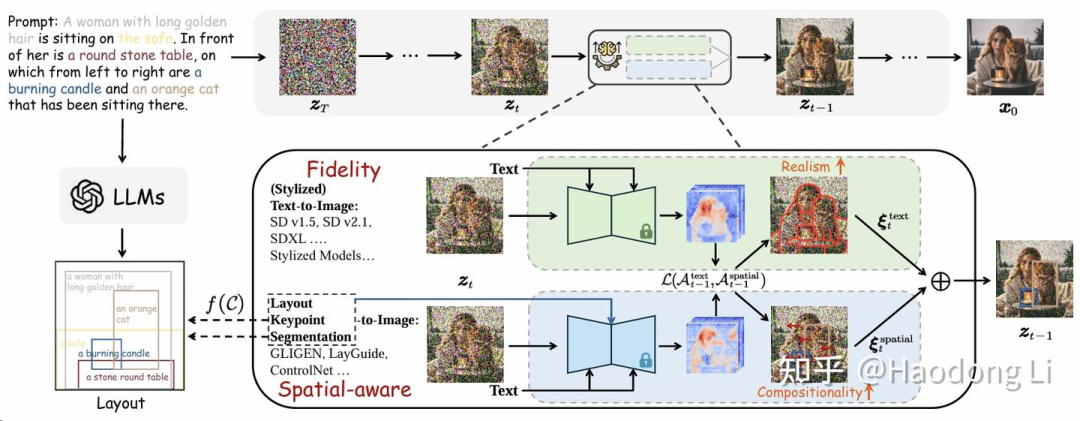
RealCompo
通过layout和text的协同控制,实现control-quality的balance
IterComp
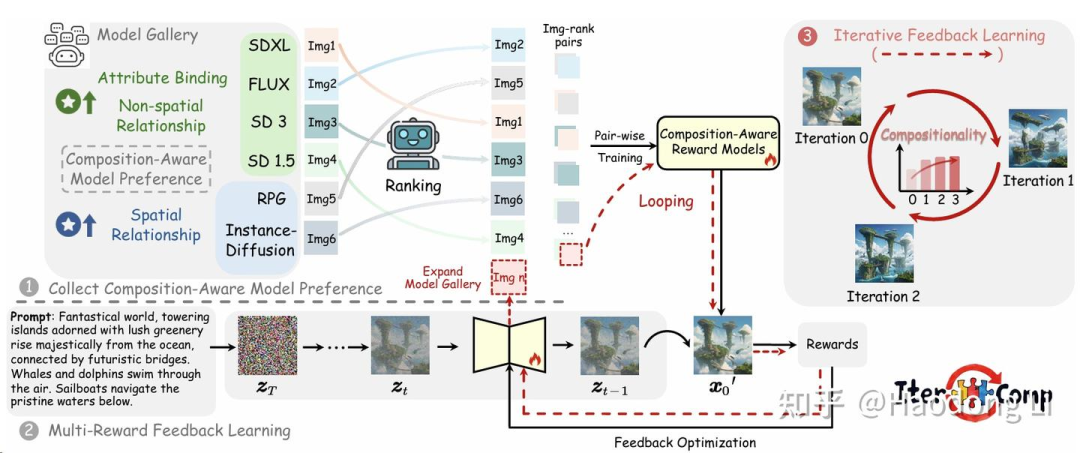
IterComp
构建Diffusion model gallery,通过reward的方式左脚踩右脚提高生成质量(类似MoE)
FlashFace
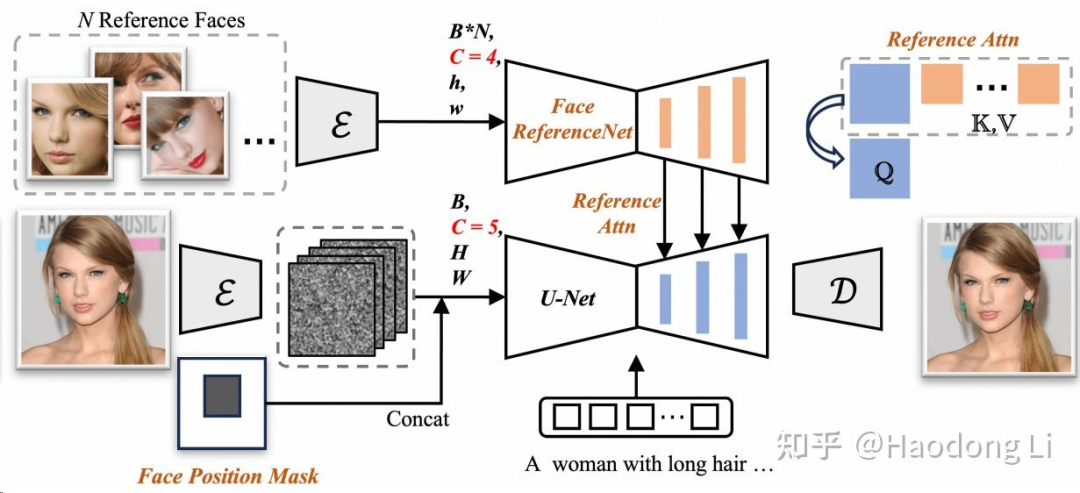
FlashFace
做customization的时候可以从text/image中学出高频信息
过去包括Dynamicrafter之类的工作都是将image feature投影到text space中作为condition,很自然id的高频信息学得不好
FlashFace则将face Embedding和text信息解耦开注入到UNet中
GDT(Group diffusion transformer)
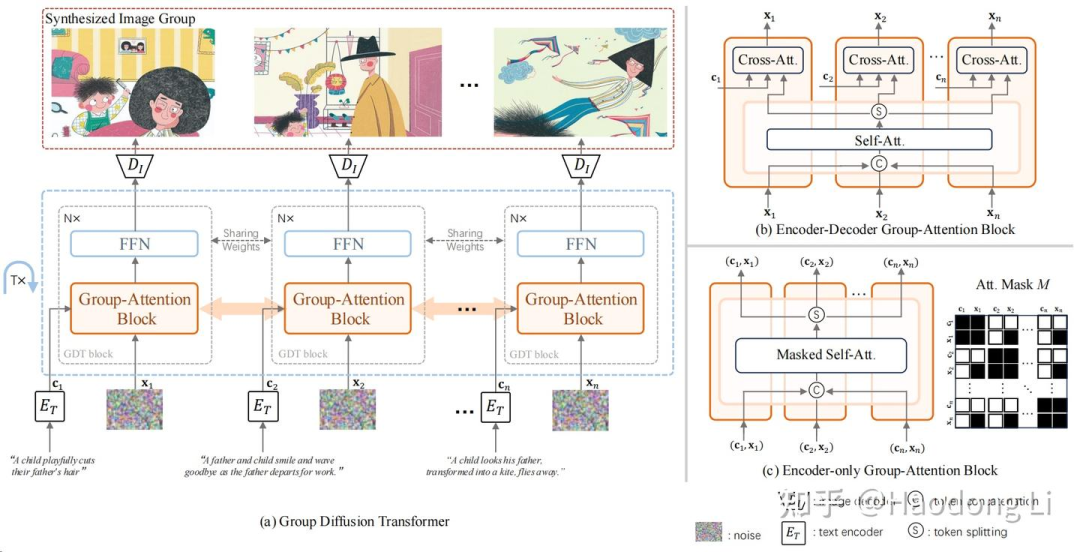
In-Context LoRA

ali-vilab/In-Context-LoRA: Official repository of In-Context LoRA for Diffusion Transformers
DiT-based model本来就有in-context learning的能力,只是需要LoRA激发出来
提出了训练范式,将几个图拼在一起,再将几个prompt拼在一起进行训练
Multi-LoRA-Composition
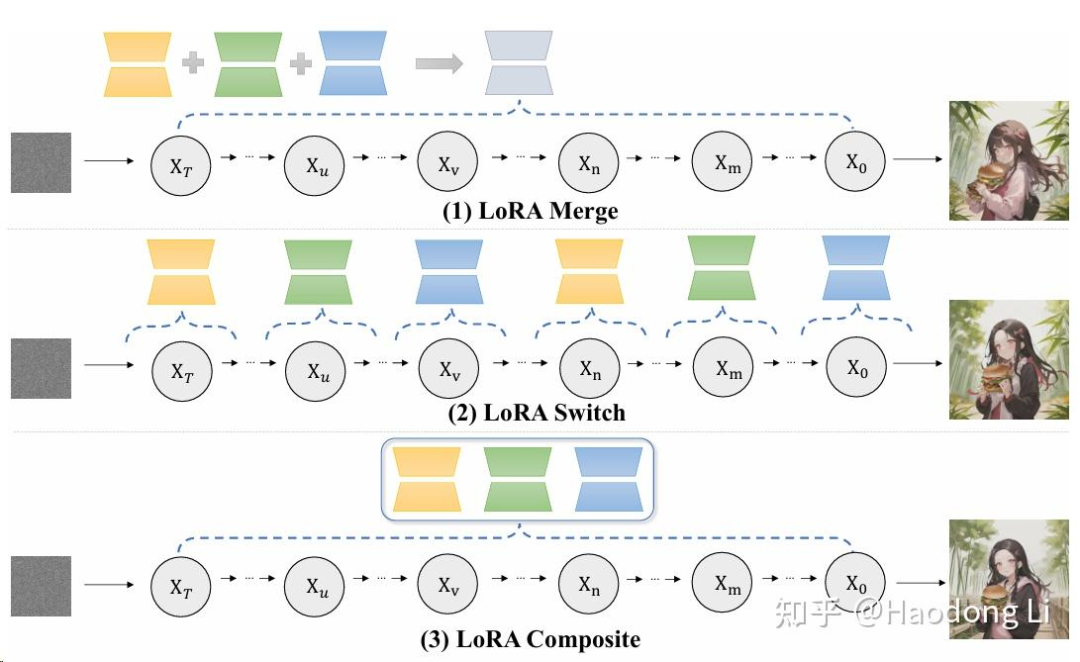
Multi-LoRA Composition for Image Generation
通过LoRA Switch/LoRA Composite对LoRA进行组合,组合方法也不是LoRA Merge那样的权重加和
同时用VLM build了个Benchmark,这个是很值得学习的
ControlNet
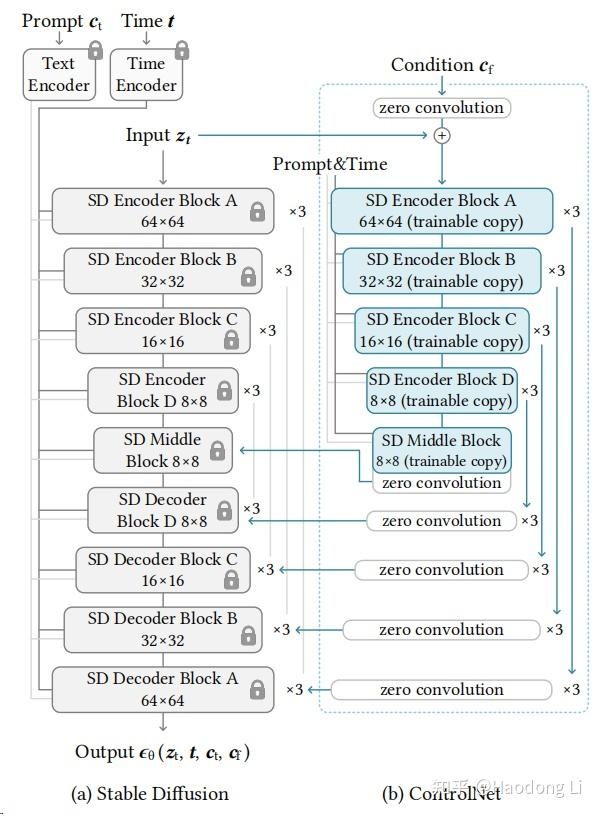
ControlNet
类似hypernetwork的想法,用一个小网络去tune大网络
zero convolution的设计就是保证SD的backbone性能,zero_conv layer是learnable parameter
SDXL
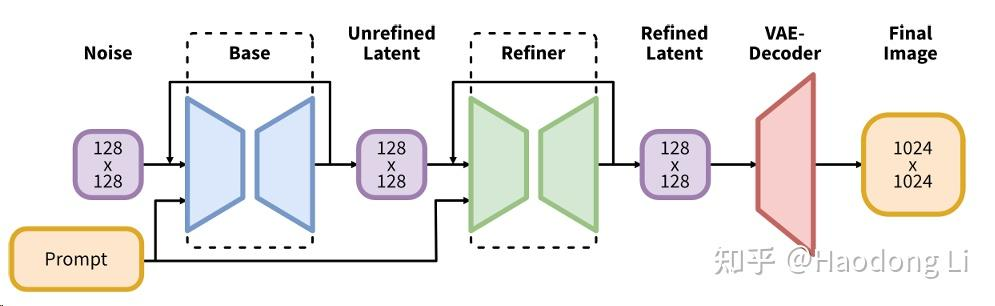
SDXL
用两个text encoder将text Embedding concat在一起,同时使用级联的Diffusion model(base model+refiner)
SDXL-Turbo
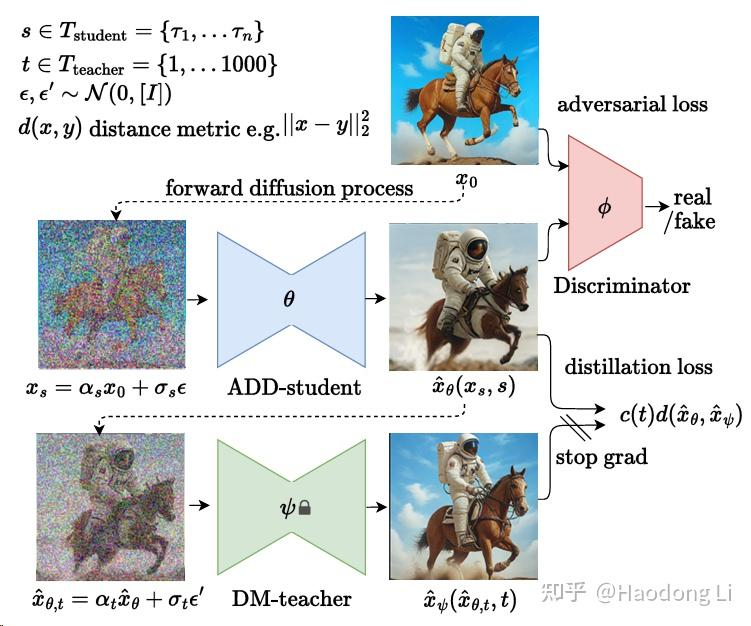
Stability-AI/generative-models:Stability AI 的生成模型
加入模型蒸馏加速采样,通过GAN方式提高质量,小模型高性能
LinFusion
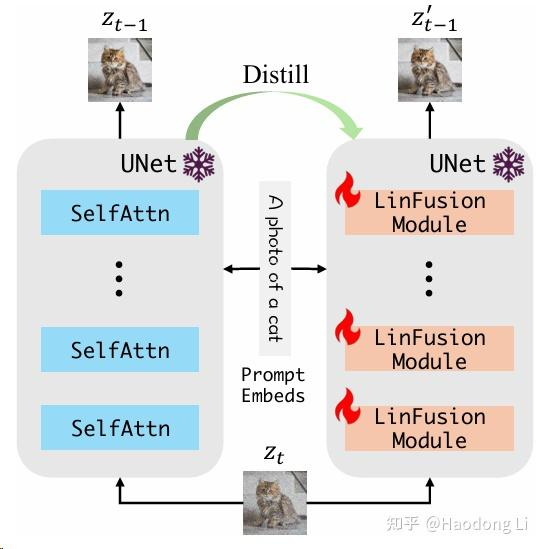
LinFusion
通过降低Attention机制计算复杂度实现高分辨率图片高效生成
U-DiT
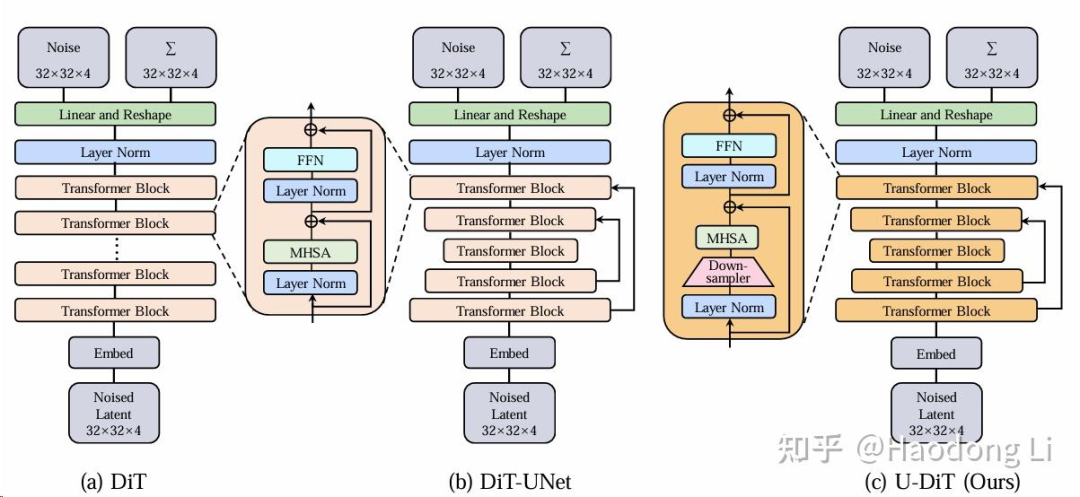
U-DiT
DiT的计算开销太高,所以就提出了用UNet(整体上先两次downsample+两次upsample)+在Attention前对KVQ做downsample降低计算开销,方便scale up
DoRA
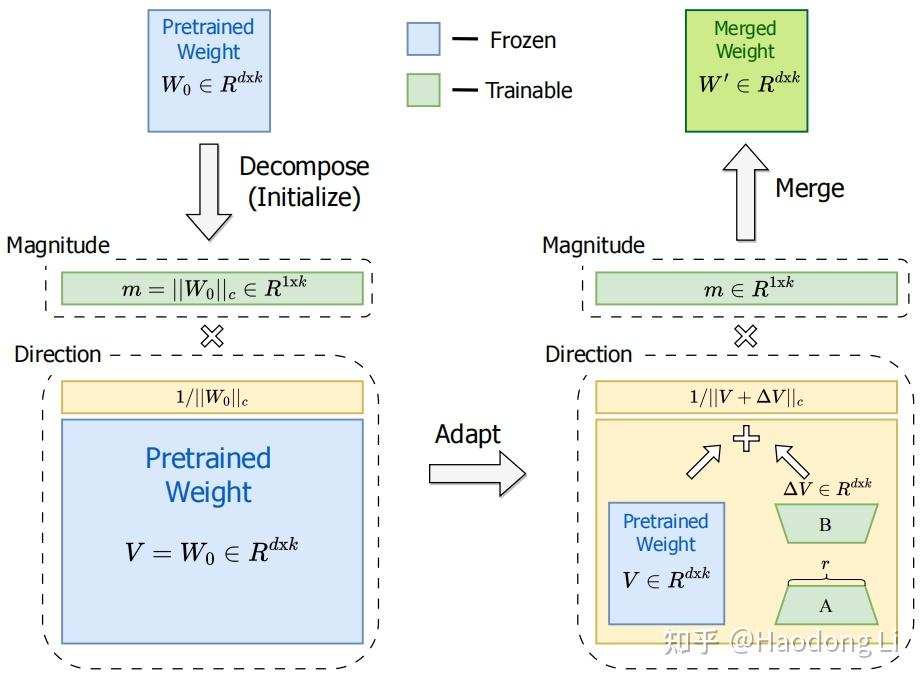
DoRA
将weight解耦为方向和大小(这篇有点没看懂)
UltraPixel
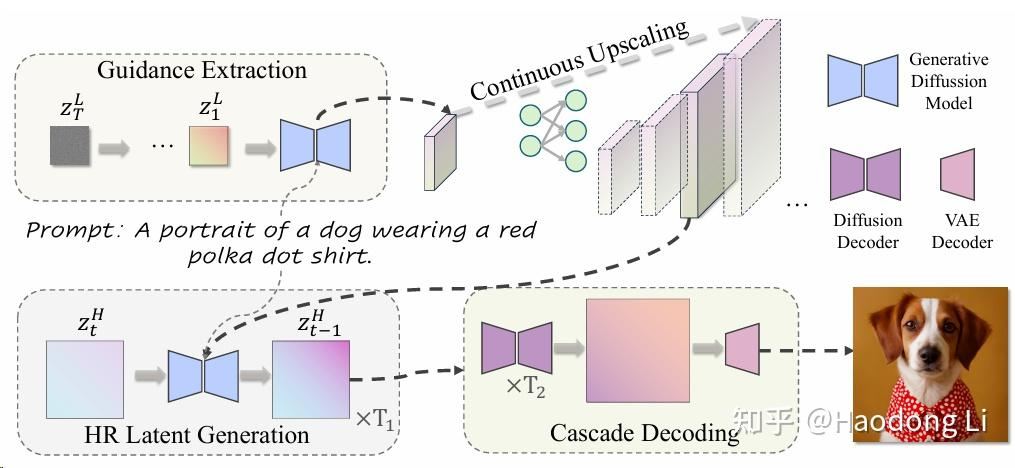
UltraPixel
通过low resolution latent feature提供global guidance,再refine高频信息
不断将latent feature给upscale到指定的shape作为high resolution generate的condition
HiDiffusion
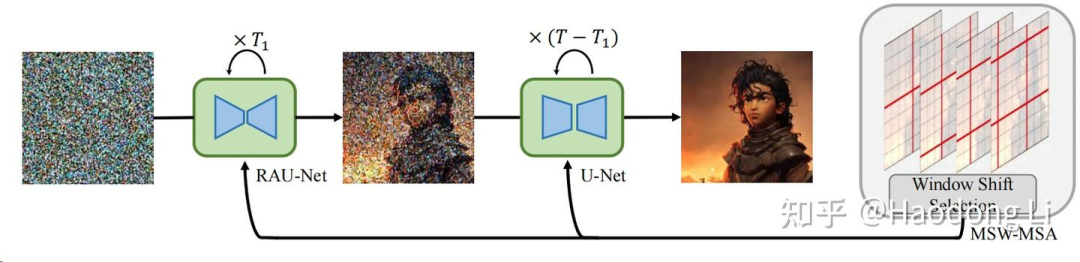
HiDiffusion
先用RAU-Net(在第一次和最后一次upsample/downsample进行4倍下采样)生成轮廓,后用UNet生成高频信息
同时在MSW-MSA(modified shifted window multi-head self-attention)中将global attention替换为local attention降低计算开销
VAE
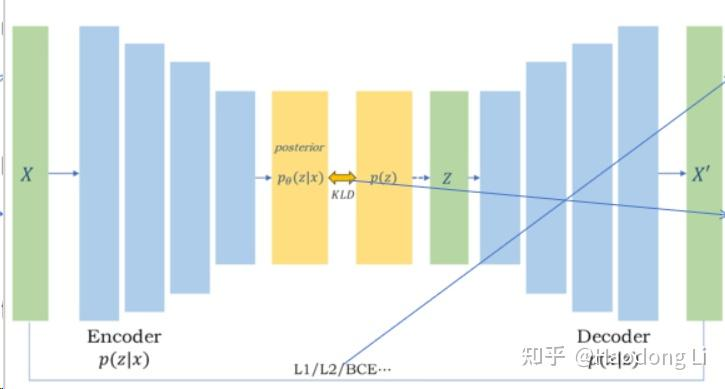
VAE
先对输入值进行压缩,从contiguous distribution中进行sampling,将sampling得到值进行decode
因为sampling的时候有随机性,所以有生成不一样图片的能力
VQVAE
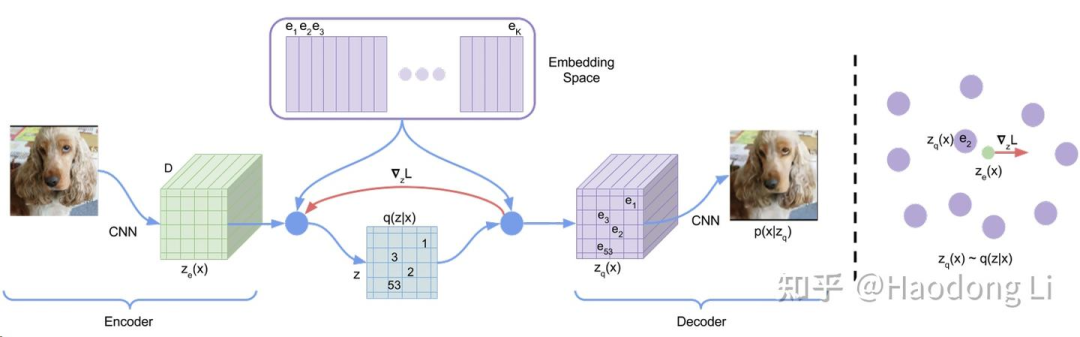
VQVAE
维护一个codebook,在encoder得到feature map中寻找最接近codebook进行sample
相当于通过维护一个更小的codebook实现比VAE更进一步的压缩
BoundaryDiffusion
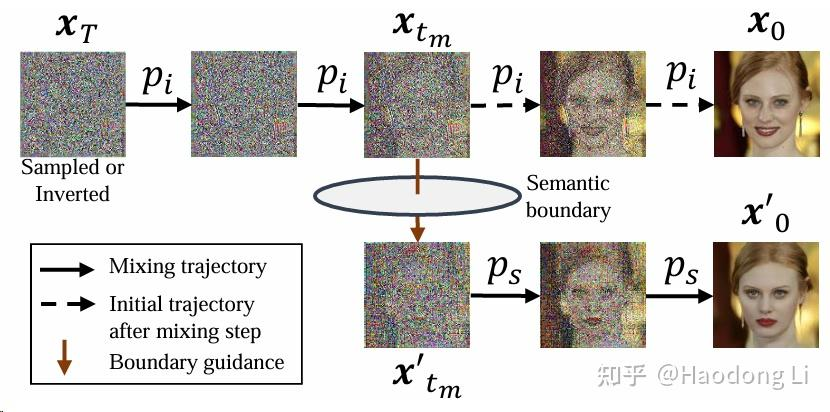
BoundaryDiffusion
tuning-free method都是在noise initialization和denoising trajectory上做design
BoundaryDiffusion定义了inversion和sample间的gap是一个环带,通过在环带法向量上走X个模长的距离实现Editing
COW
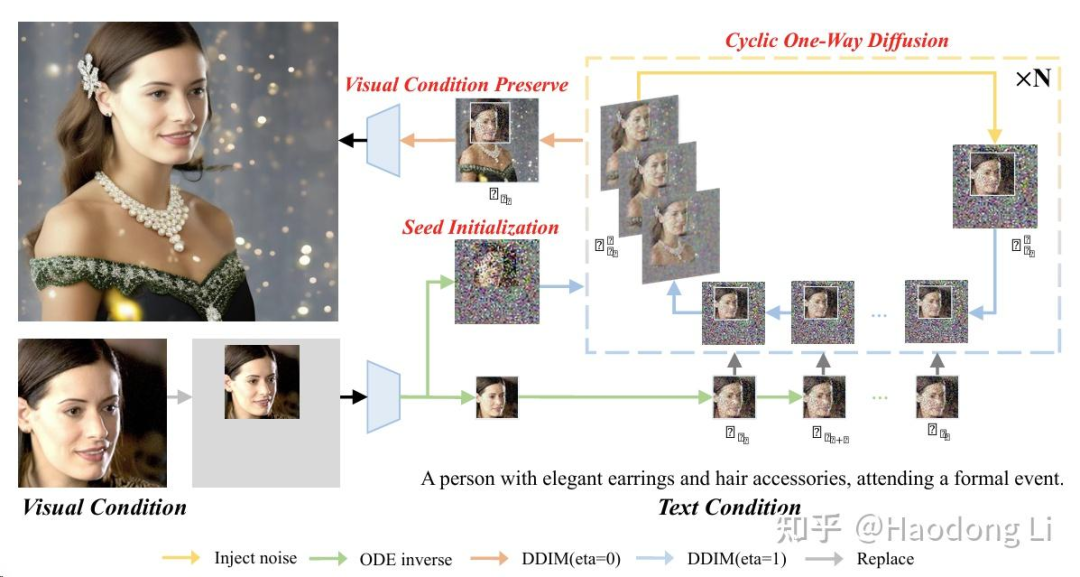
COW
在BoundaryDiffusion只能做Editing的基础上做subject-driven customization
通过mask的方式用已有id信息往外面推,实现subject-driven customization
注意subject-driven中id信息保存,但是背景信息如何控制也是分为text guide和image guide的
这里背景信息就是用text guide实现的,比较粗粒度
NoiseQuery
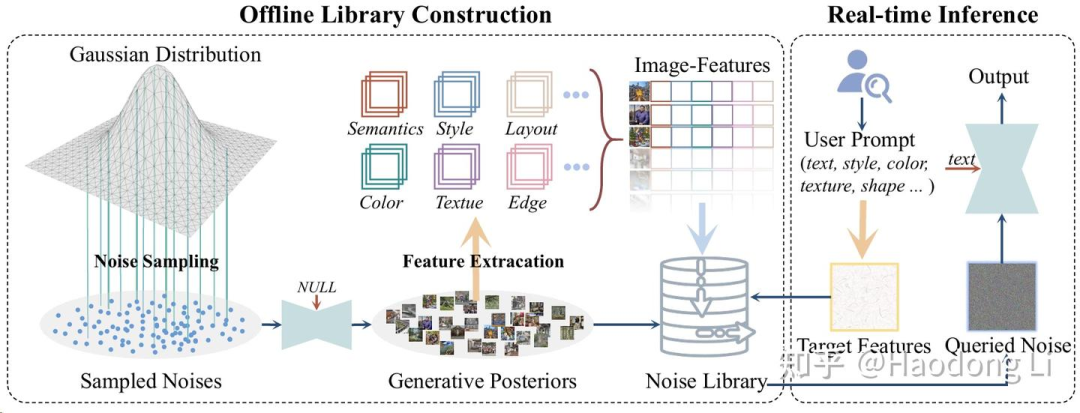
initial noise也需要被视为是prompt的一部分,和condition注入cross attention一样重要
先用guided-free方法生成noise library,再生成的时候选其中最接近要生成case的noise进行生成
这样无需加很多约束就可以做high quality generation
ToME
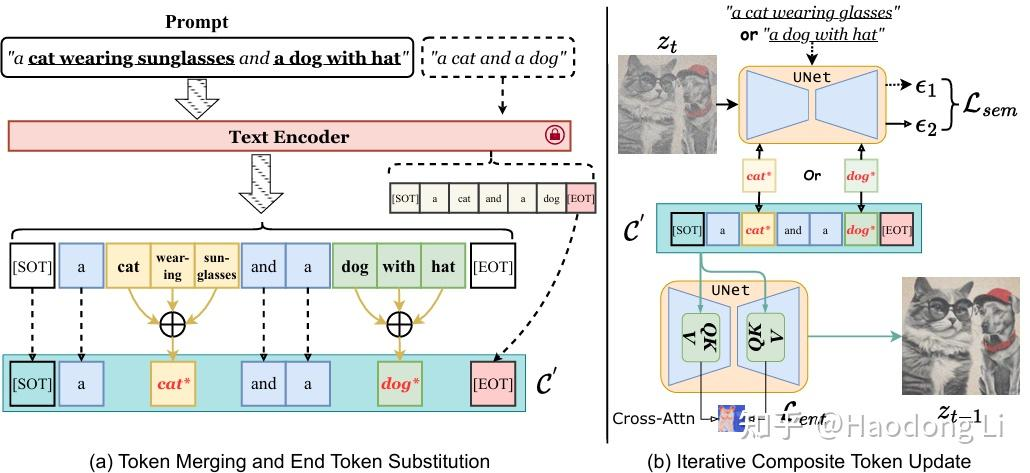
ToMe
我觉得这篇paper挺好的也挺本质的,他想解决generation model中attribution和object的mismatch problem
比如带眼镜的狗和带帽子的猫可以会生成图片:带帽子的狗和带眼镜的猫,这个就是mismatch
分析原因:Attention map的泄露问题,因为clip用双向注意力编码,所以object1会混入别的object2 attribution的Attention导致mismatch(attention泄露问题其实也是老生常谈的问题了)
by the way,过去我都没有很在意text encoder这个组件,这里HighLight一下:编码的结果是77*768的,如果不满77位就用[EOT]进行填充(很自然的,[EOT]也有全局的信息)
Golden Noise
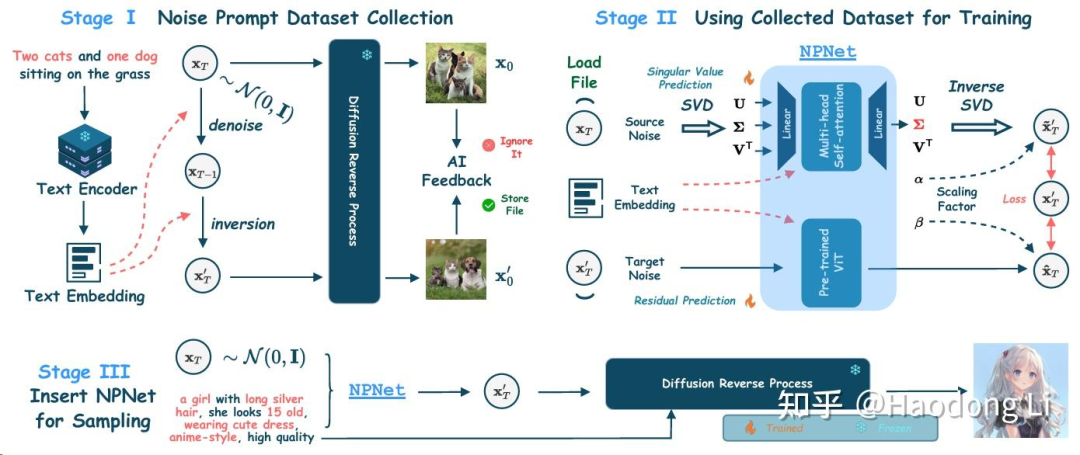
Golden Noise
在noisequery中已经提出了initial noise也是prompt的一部分
Zigzag-Diffusion
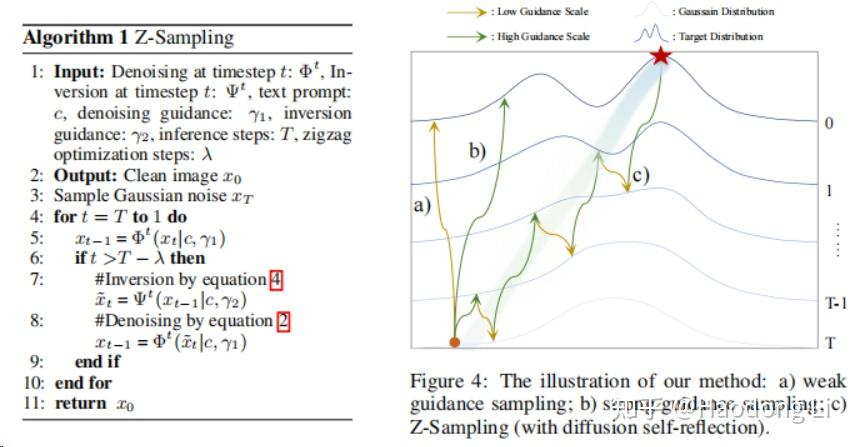
Z sample
非常promoting的工作,用时间换空间,DDIM中每一步都先denoise再reverse
类似LLM中反思的机制,个人认为未来一年generate model中引入inference慢思考的大势所趋
Faster Diffusion
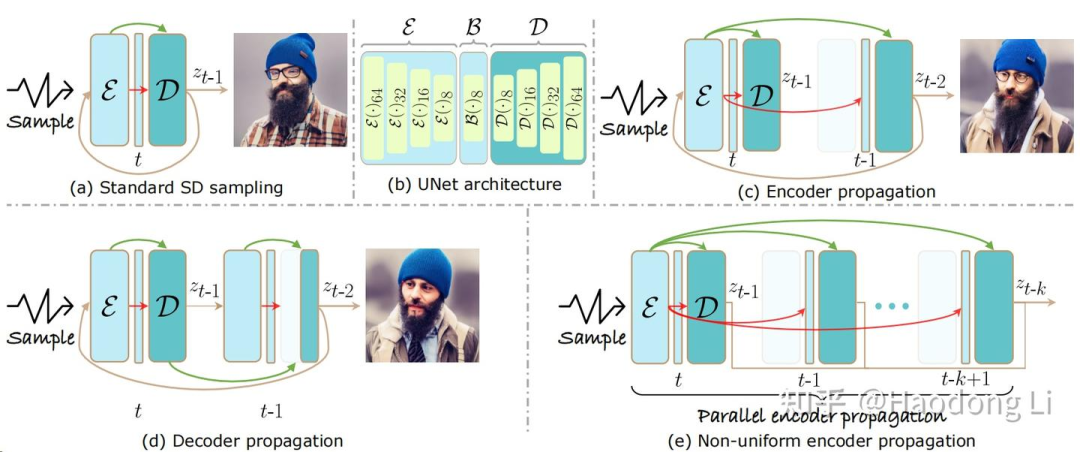
Faster Diffusion
通过PCA降维分析:encoder中step间变化不剧烈,decoder中step间变化剧烈
所以就想在一些time step间共享encoder,节省下encoder计算时间加速generation
这篇paper其实和NUS的DeepCache非常像区别在于DeepCache还共享Decoder(这里claim Decode很重要,我们不能共享Decoder)
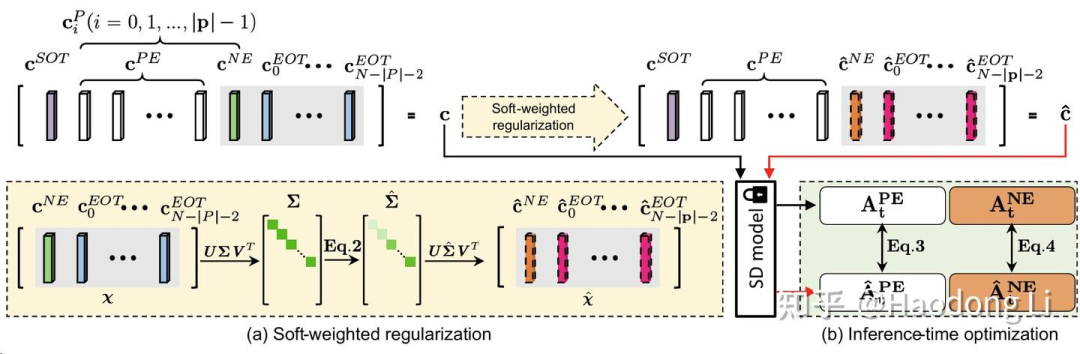
SuppressEOT
SuppressEOT
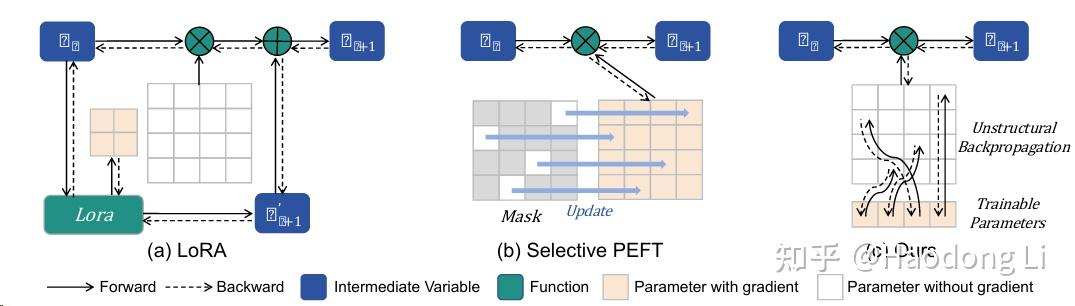
SaRA
SaRA
改进Selective PEFT中GPU占用太高的问题
ConsisID
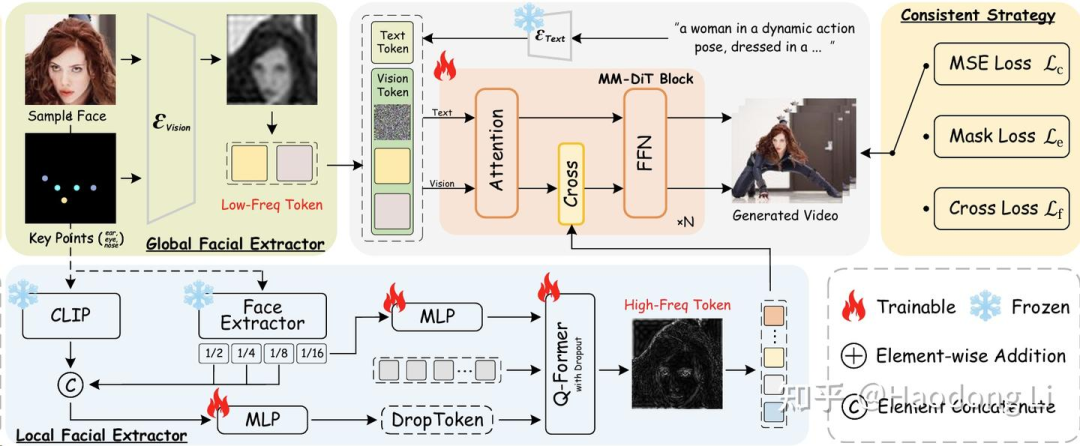
ConsisID
DeqIR
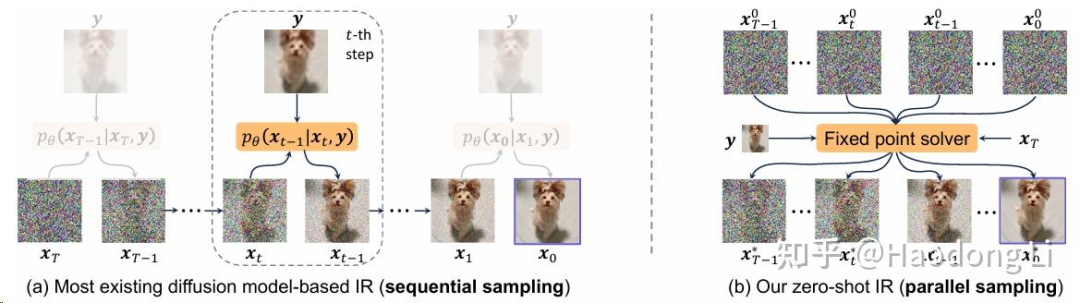
DeqIR
并行Diffusion sampling,提高DIffusion效率
Infinity
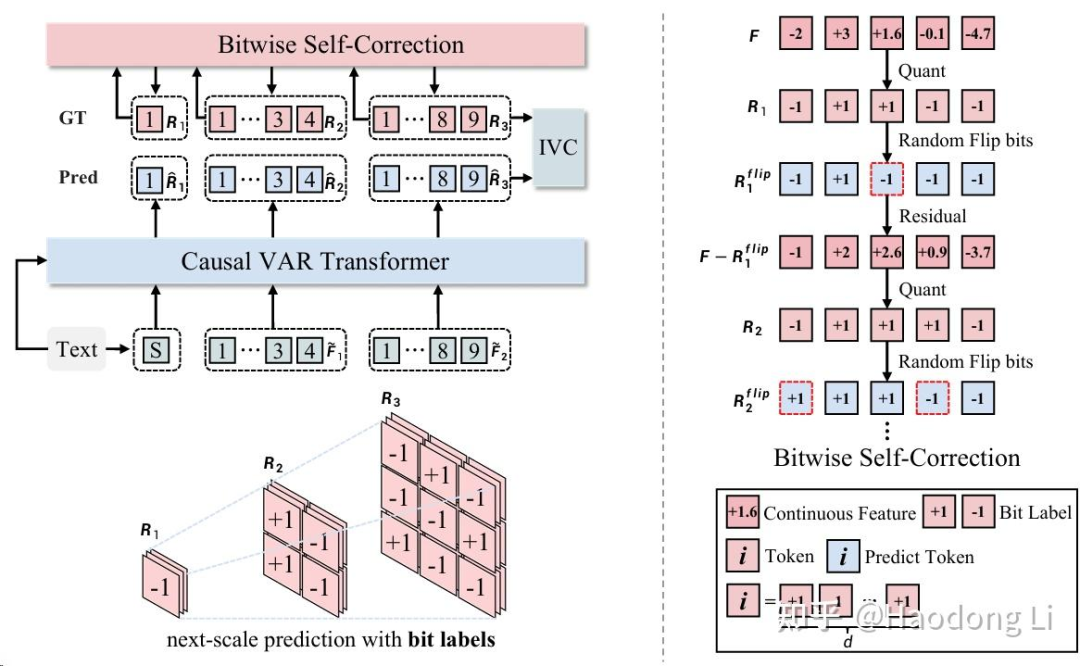
Infinity
MAE
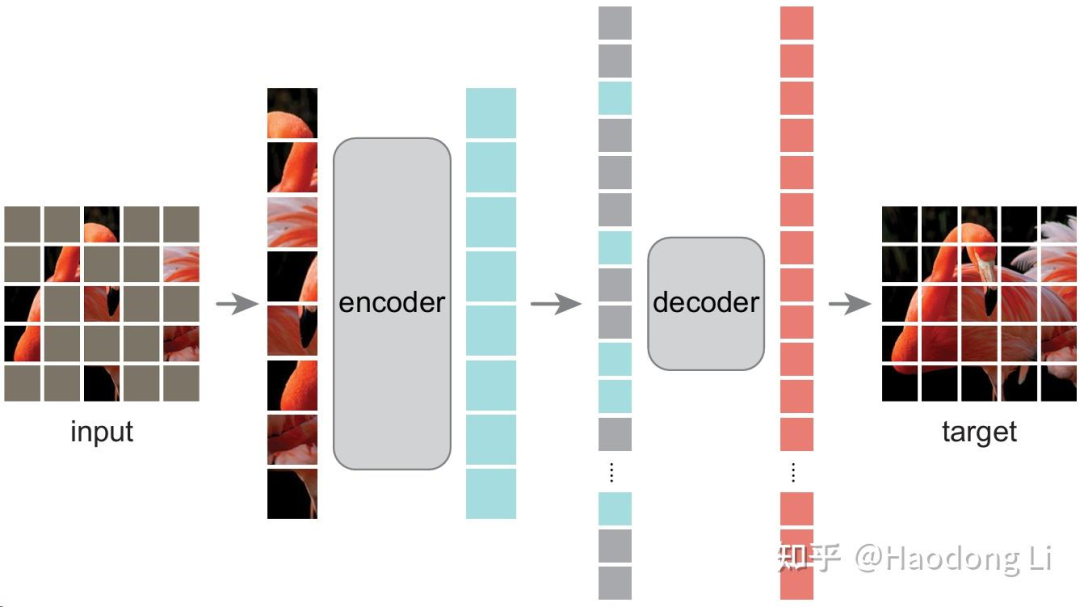
MAE
MAR
Physical-Alignment
这个是我很关注的task所以专门加个分区写它
PhysDreamers
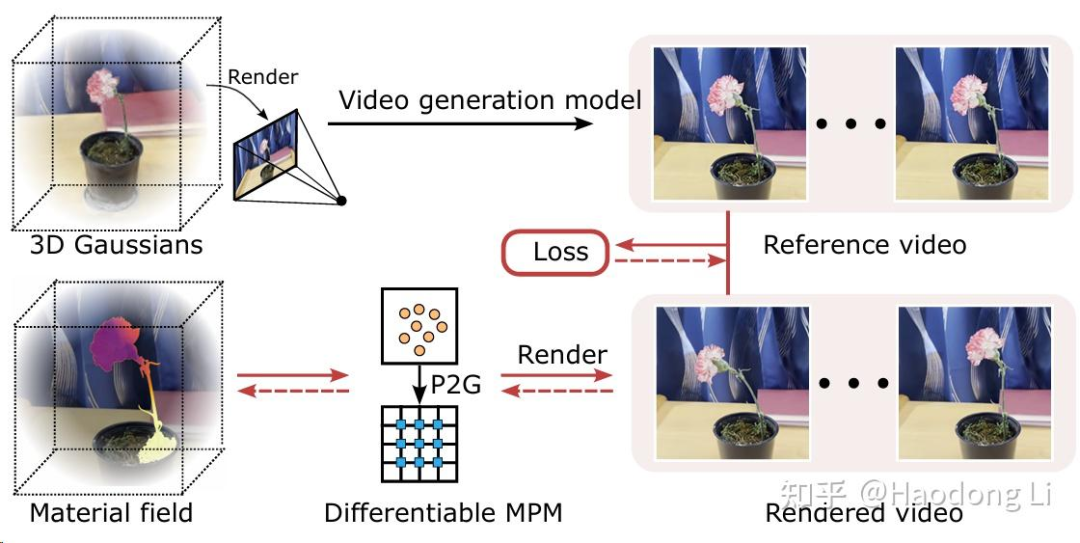
PhysDreamer
过去generate model都是condition-free/text condition的generate model,但是在physical-alignment里面我们关注action condition,其实会难很多
这里的就是用VideoGen生成的Video中pixel变化梯度回传到material field中进行更新
GPT4Motion
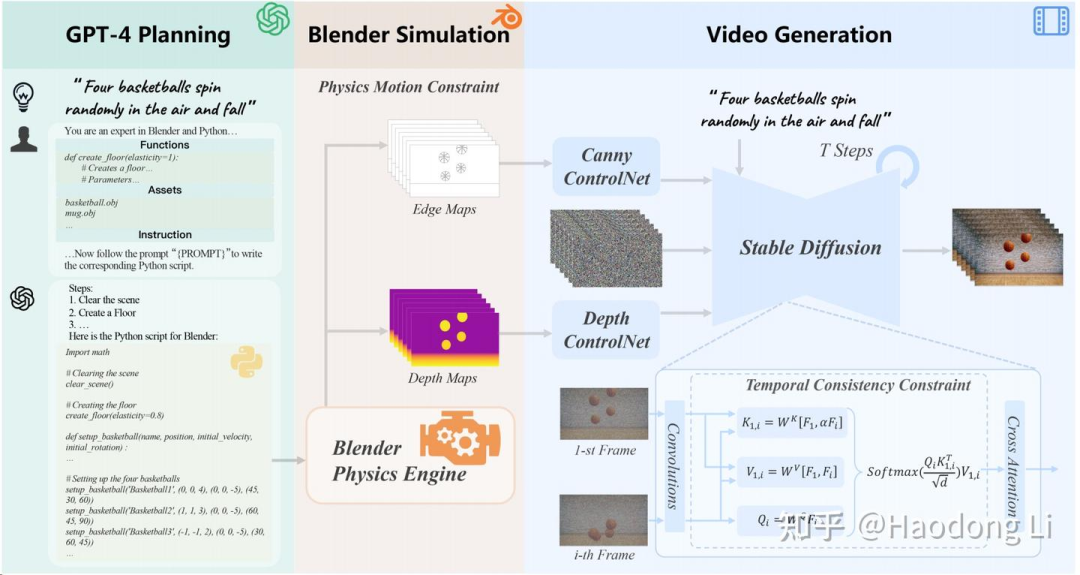
GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning
过去video Diffusion很难做motion很大还能pyhsical-alignment
GPT4Motion将text转为Blender渲染的depth map+edge map,先在图片上和physic先align得很好,再保证video可以align得很好
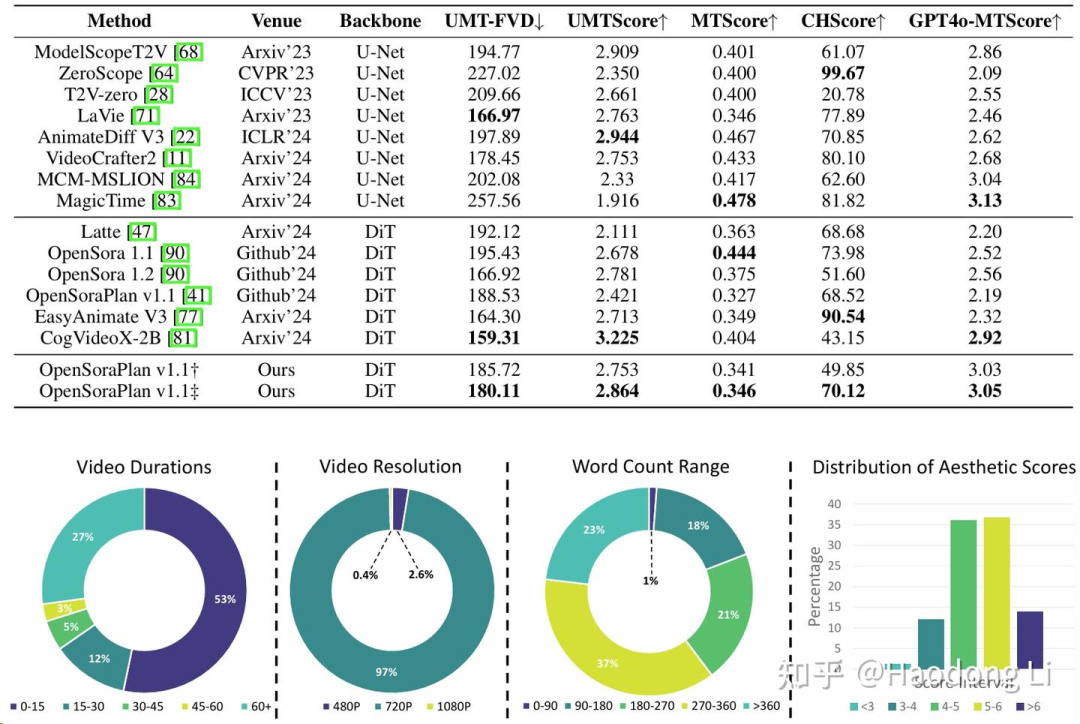
ChronoMagic-Bench
ChronoMagic-Bench
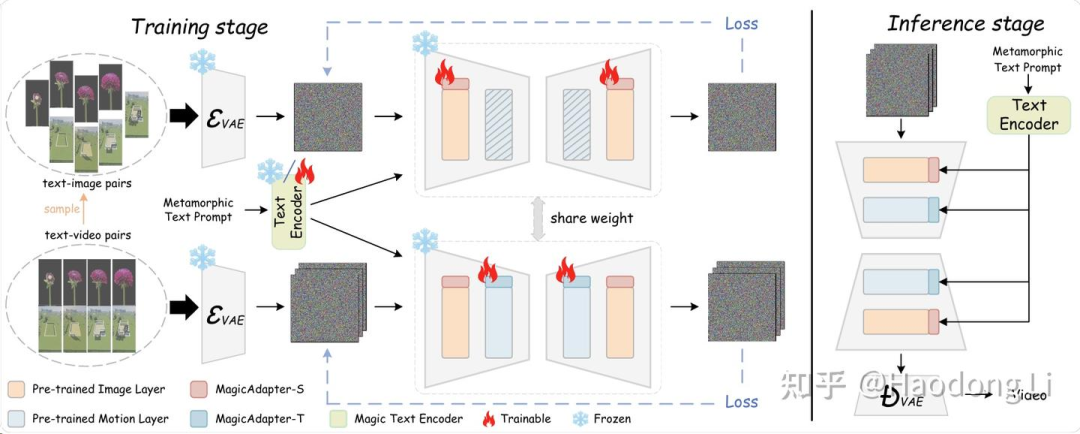
MagicTime
MagicTime
Procedural Generate
Inifinigen

Infinigen
Infinigen相当于3D中Imagenet,而且是无限生成的
他不是从website上download Asset进行组合,是直接生成Asset进行组合,同时可以提供high-quality label之类的
Inifinigen Indoor

将Inifinigen扩展到了Indoor中,不过加入了很多约束条件(因为outdoor随便摆都make sense,但是Indoor 需要有结构)
用贪心算法对组合做约束
3D-GPT
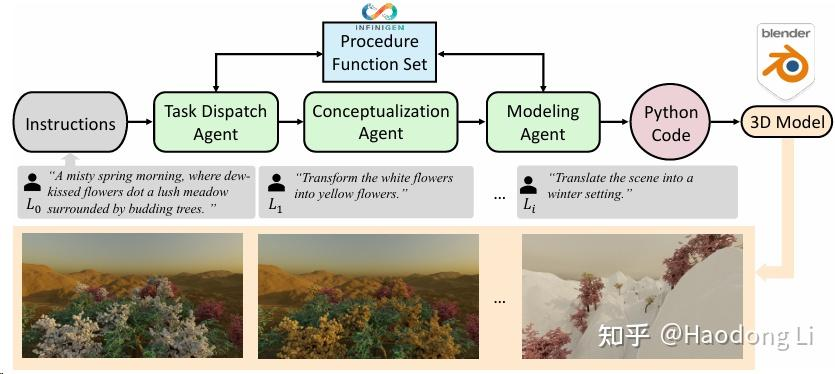
3D-GPT: 3D MODELING WITH LARGE LANGUAGE MODELS
基于Inifinigen上支持text to 3d
非常straight forward,类似和三个agent讨论得到python code,后在blender中建模,同时也claim自己能editting,但是这个工作没有开源
Rigging
Unsup3D
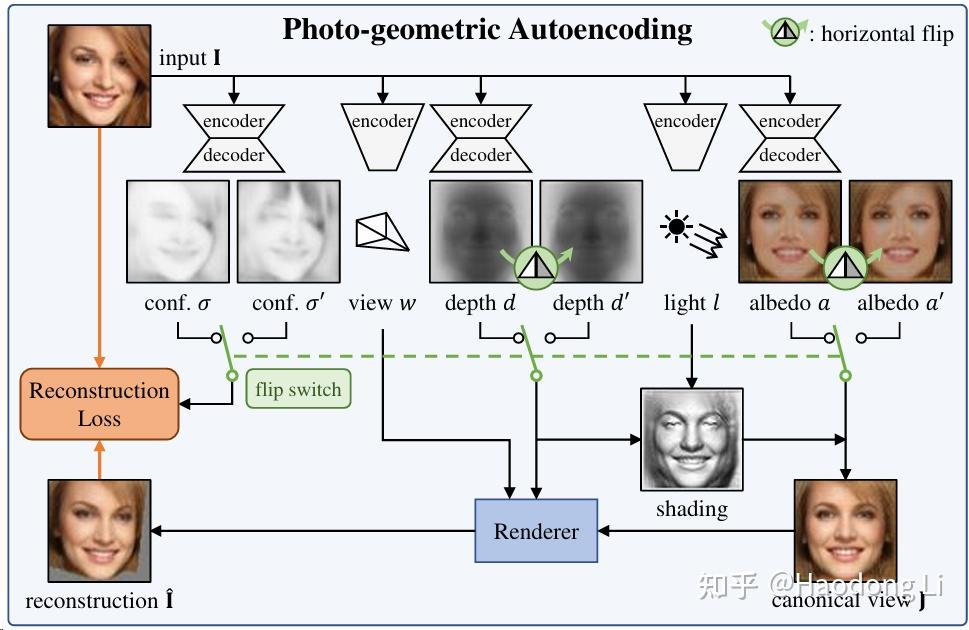
Unsup 3D
Shangzhe wu的derender framework中有三层重要假设:1. 对称 2. 层次(DINO feature) 3. low-rank basis
Derender
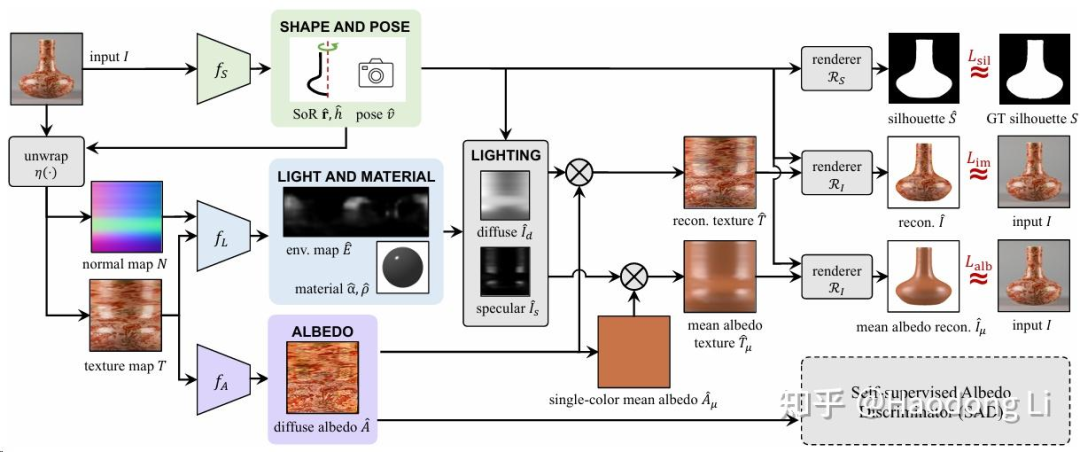
Derender
MagicPony
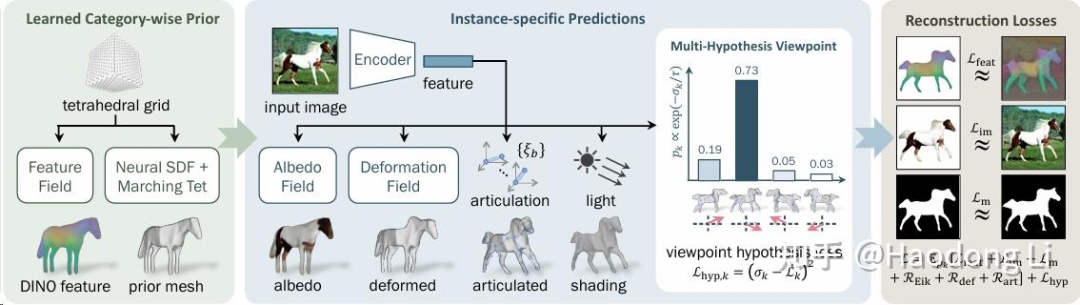
MagicPony
Farm3D
Farm3D
3D-Fauna
3D-Fauna
Ponymation
Ponymation
Understanding
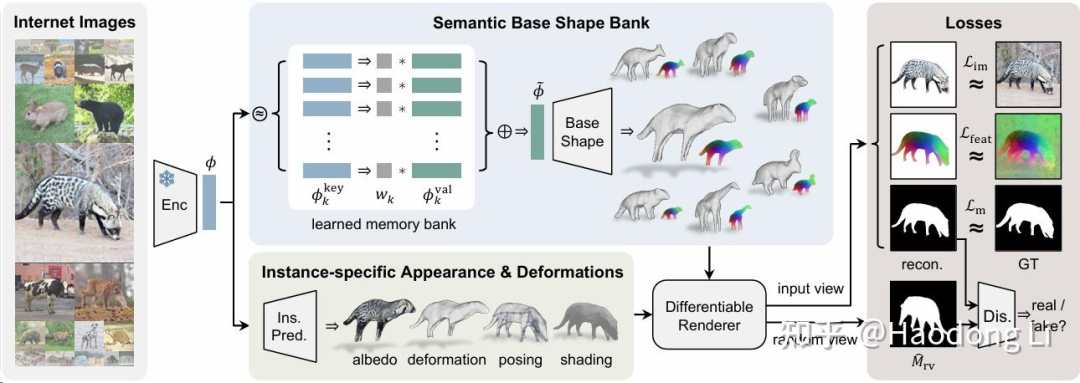
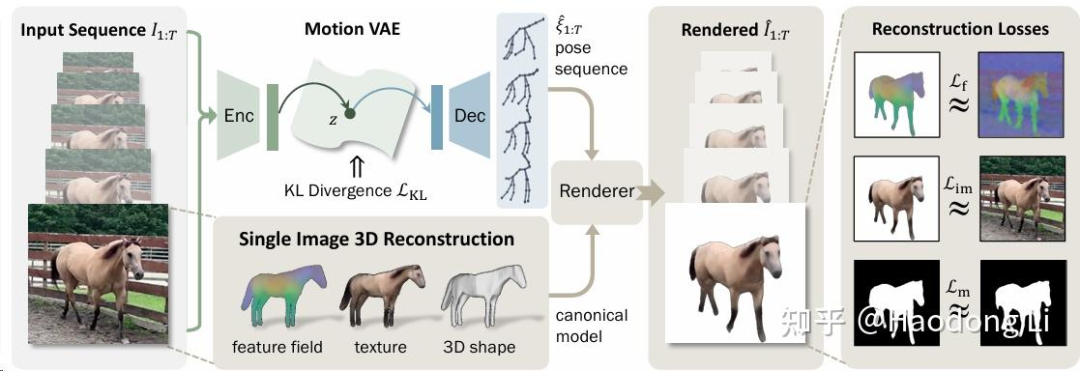
专门开个列表记录PointCloud主要是因为在sparse view的task上,PointCloud确实是个很好用的表征(可能是因为Dust3R)。而且后续做understand很多work都是based on Pointcloud的
所以记录一下PointCloud特别是PointCloud Foundation Model的文章
Point Transformer v1/v2/v3
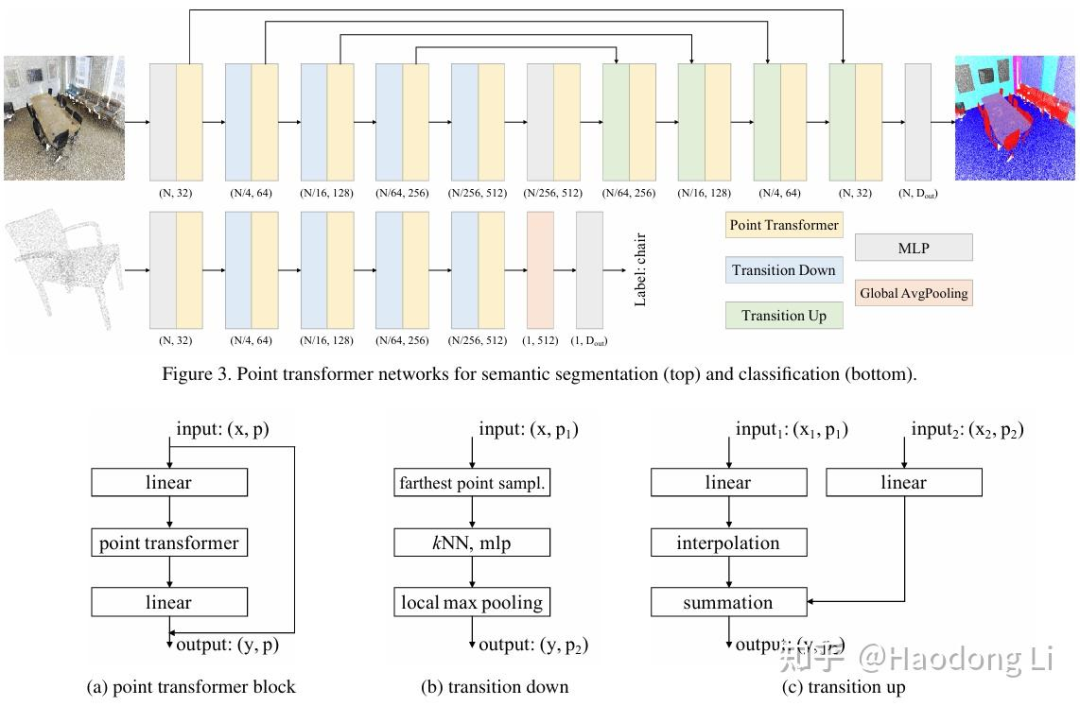
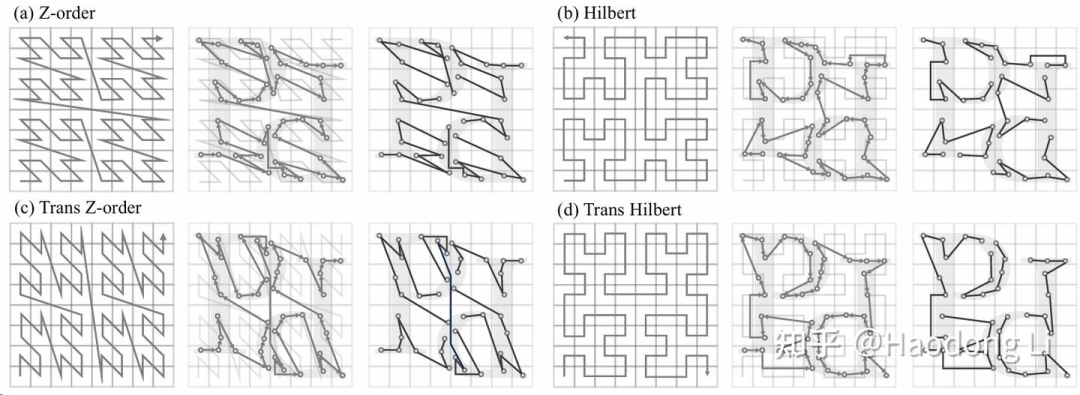
PointTransformerV3
PTV3最强Insight:将Pointcloud这种离散3D Representation转为结构化数据类型
GPT4Scene
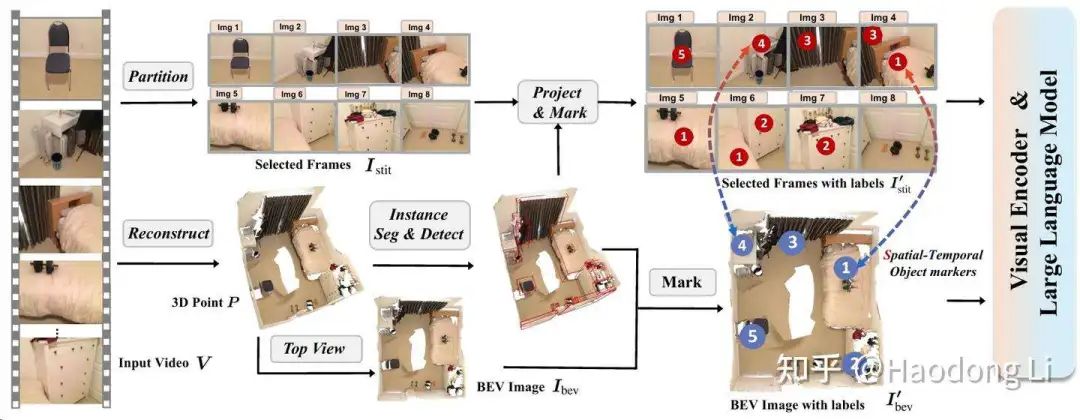
GPT4Scene
不在使用Pointcloud-based MLLM,而是使用Video/image-based MLLM(因为在更大data上Pretraining过)
再加入BEV和序号对应关系作为Prompt
我觉得这个后面会是一个趋势,因为没有这么多Pointcloud data进行Pretraining
Avatar
SMPL/SMPLX
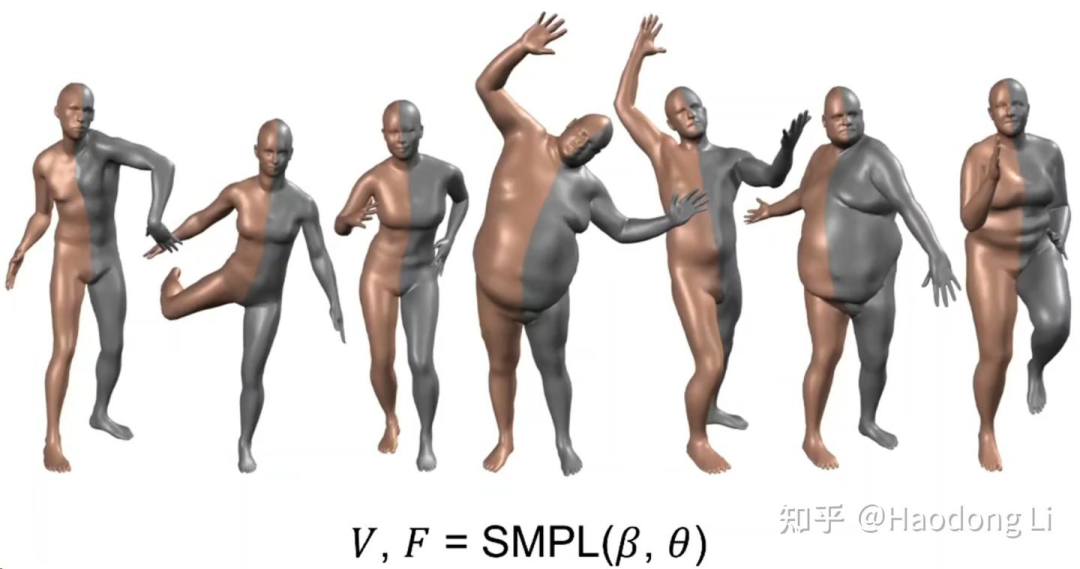
SMPL
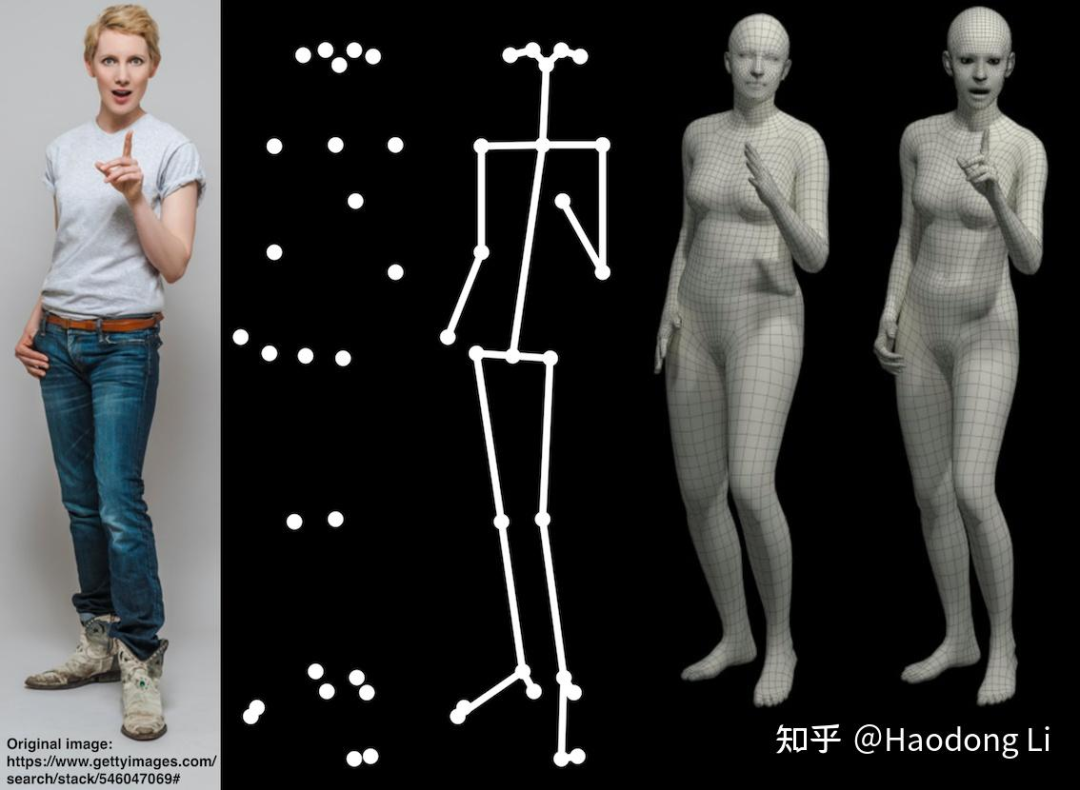
SMPL-X
FloRen
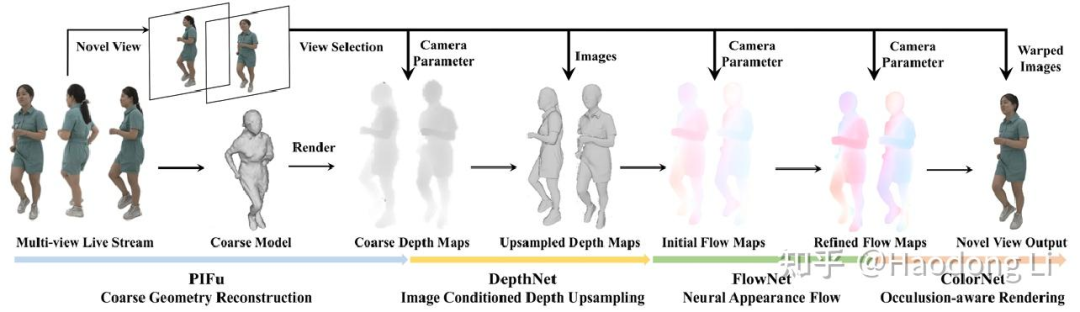
RGBD-based method
没开源代码
GaussianAvatar
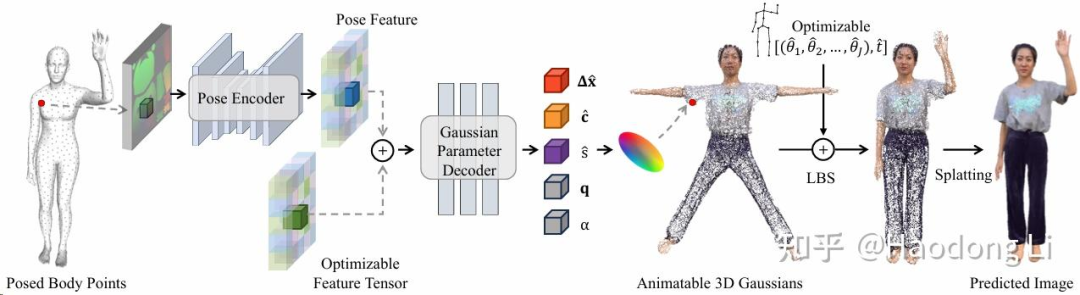
Projectpage of GaussianAvatar
单目task,所以就简单使用裸体人pose模型
Animatable Gaussian
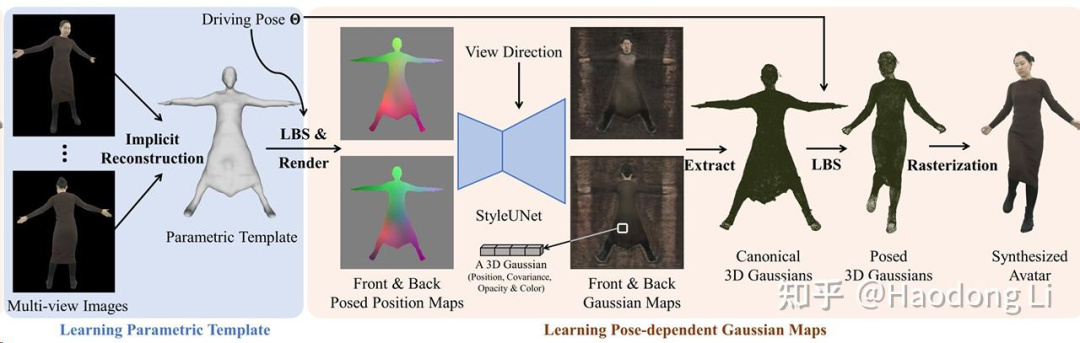
Projectpage of Animatable Gaussians
LayGA

LayGA's Project Page
Animatable And Relightable Gaussian
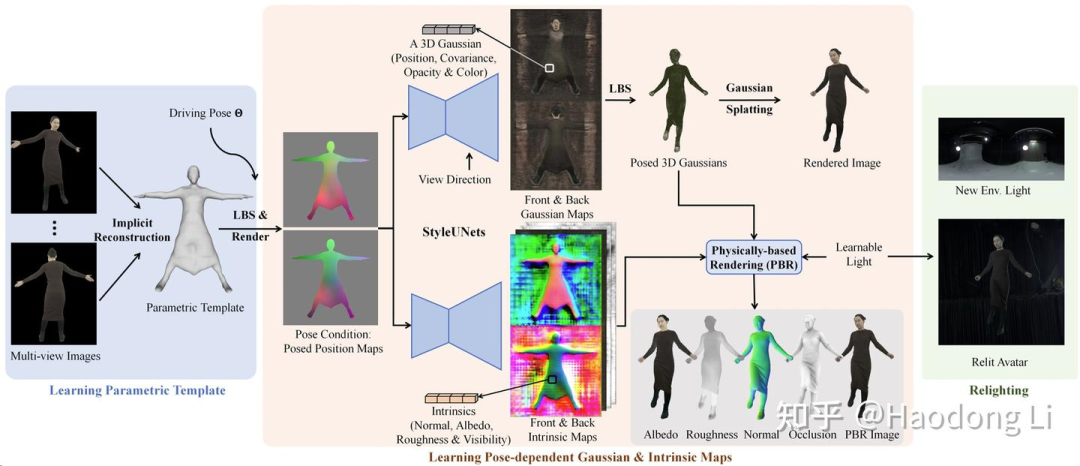
Projectpage of Animatable & Relightable Gaussians
GGHead
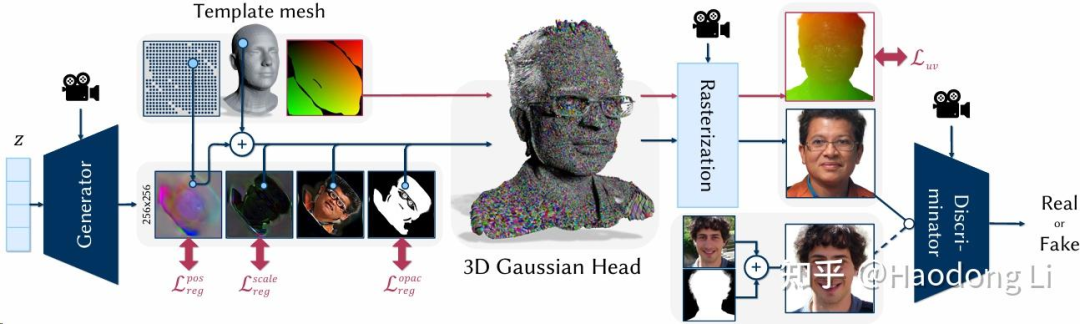
GGHead: Fast and Generalizable 3D Gaussian Heads
GPS-Gaussian
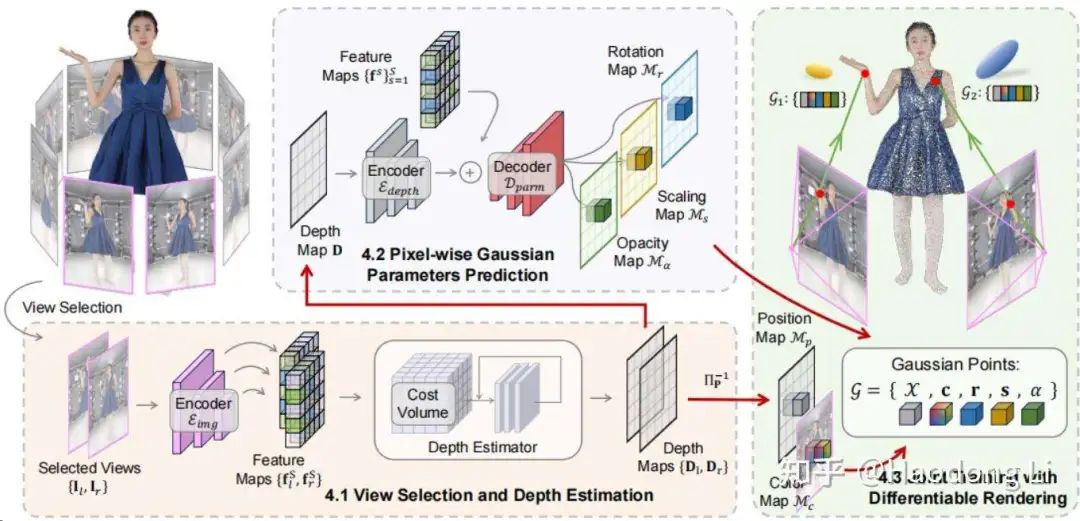
Projectpage of GPS-Gaussian
ID2albedo
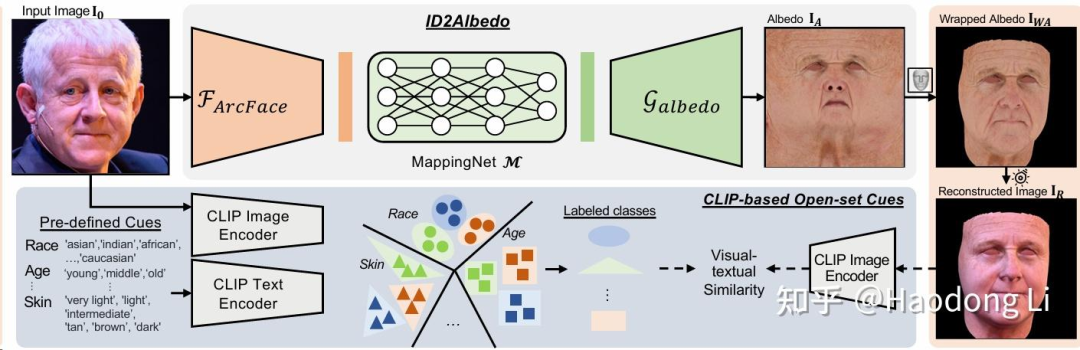
id2albedo
R(反射率)=L(光照)*A(反照率),从R结果中反推A本身就是ill-pose problem
所以ID2albedo引入大模型,通过ID信息提供race/skin/age等prior去解决ill-posed
引入Foundation model prior解决ill-pose是2D lift to 3D等问题常见的,这篇paper怎么引入的design是挺值得学习的
ID2Reflectance
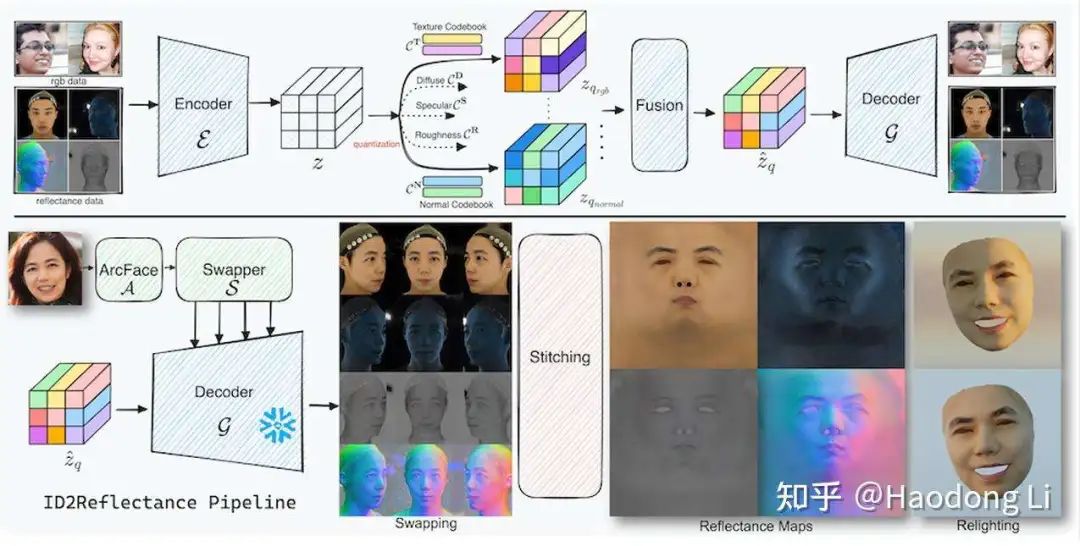
id2reflectance
FaceEdit3D
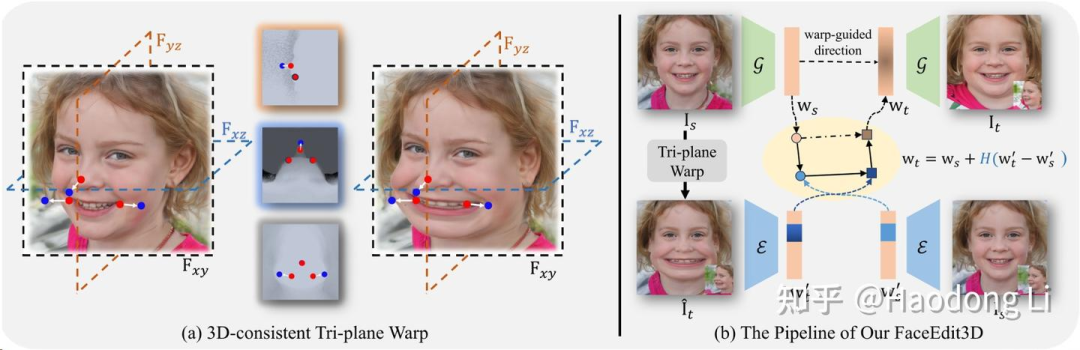
FaceEdit3D:3D-Aware Face Editing via Warping-Guided Latent Direction Learning
GS-VTON
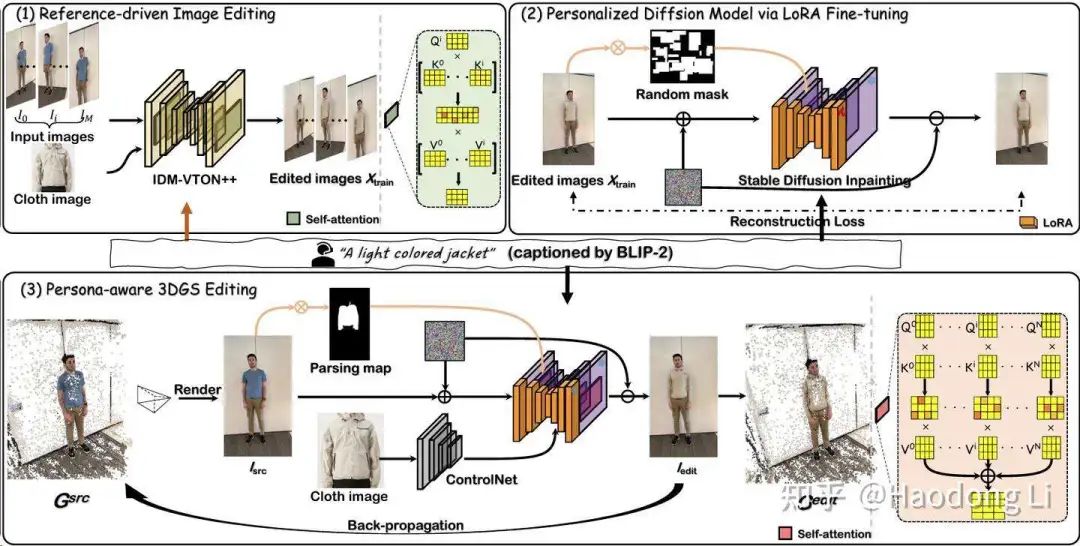
GS-VTON
HandCraft
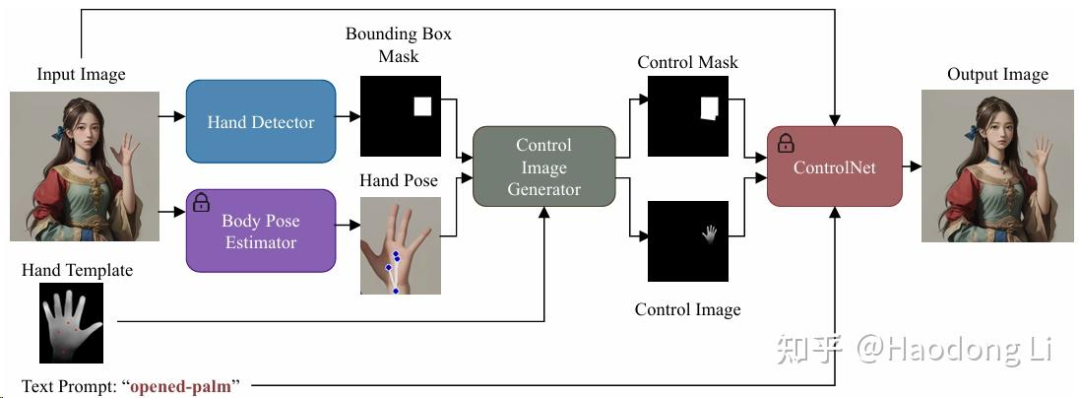
HandCraft
将手部以外的地方mark起来,检测vanilla image手部key point和hand template key point对齐(通过缩放平移旋转)
再用template中control image通过controlnet做hand refinement
3DGS
DreamScene360
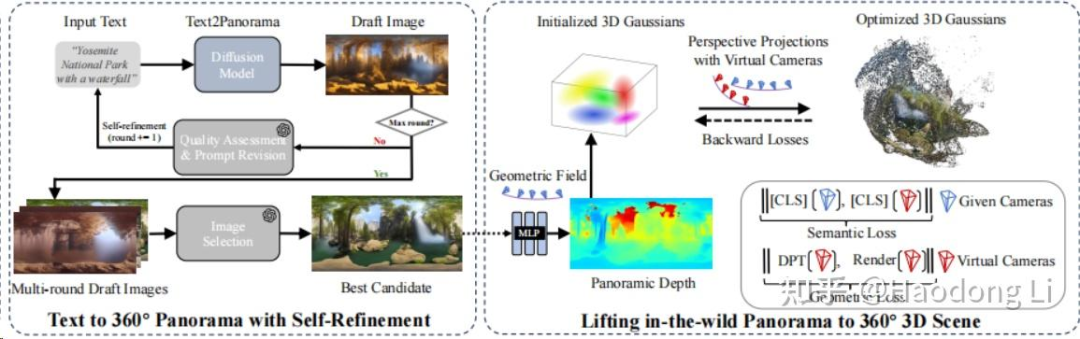
DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
InstantSplat
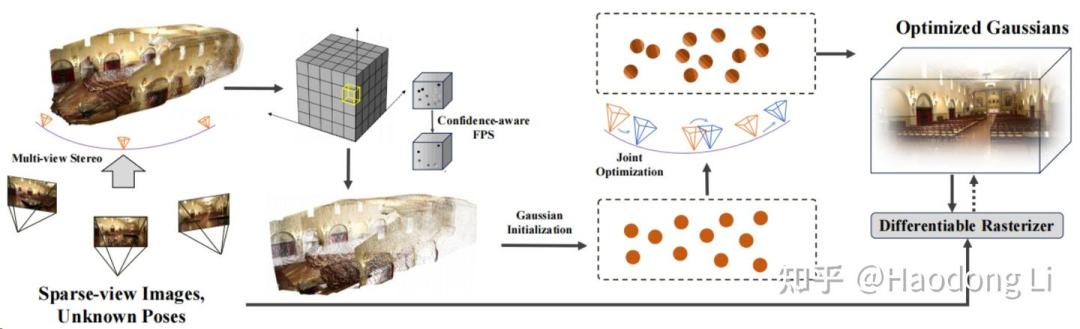
InstantSplat: Sparse-view SfM-free Gaussian Splatting in Seconds
PGSR
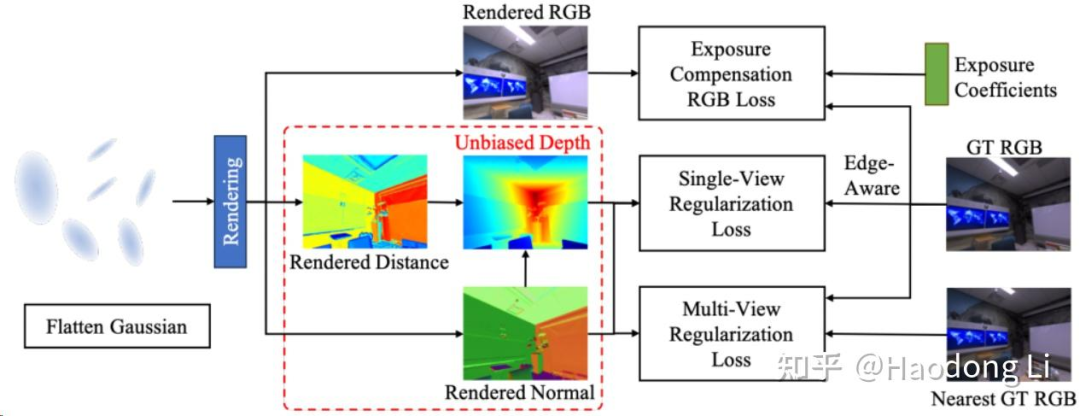
PGSR: Planar-based Gaussian Splatting for Efficient and High-Fidelity Surface Reconstruction
GeoGaussian
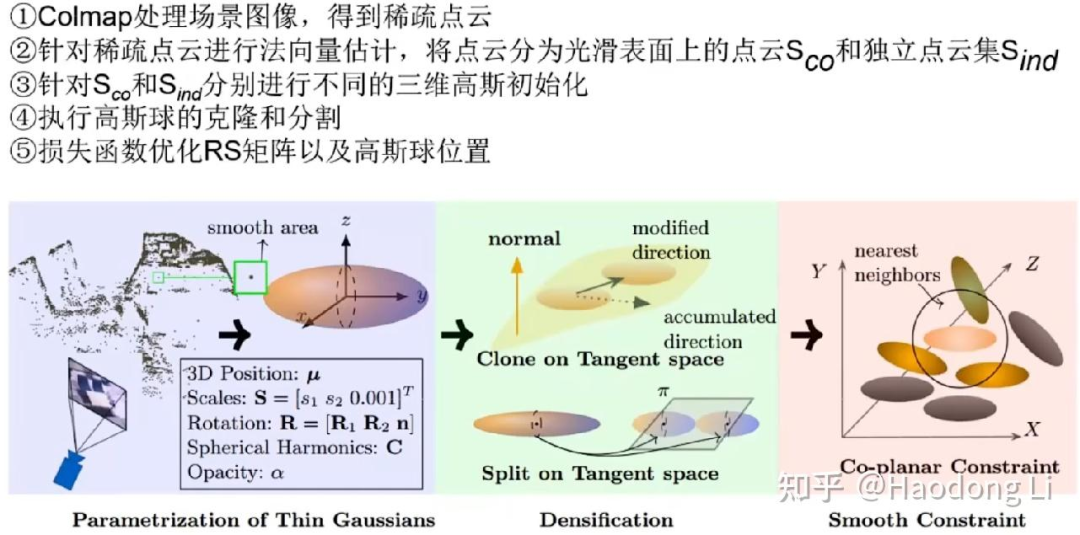
GeoGaussian: Geometry-aware Gaussian Splatting for Scene Rendering
将Gaussian分为复杂纹理的普通Gaussian和光滑纹理的压扁Gaussian,更新的时候也做不同的处理
SparseGS
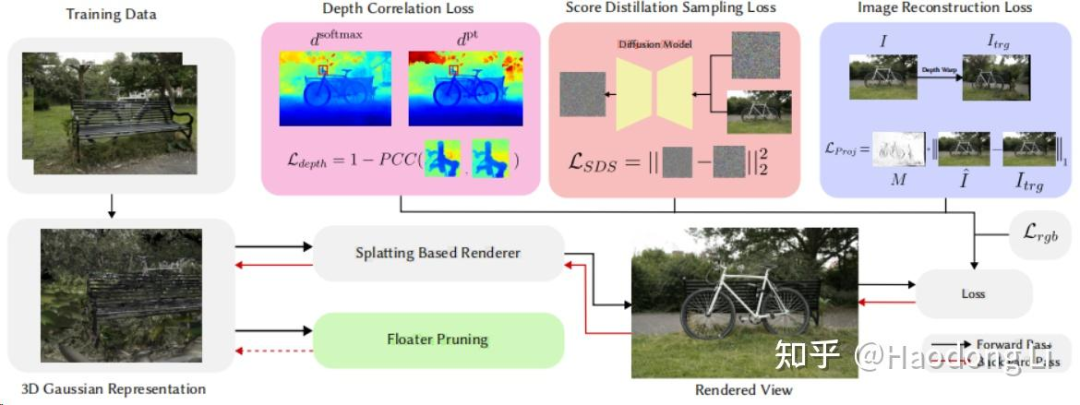
SparseGS
注意看Pipeline中有个不太起眼的trick:Floater Pruning的部分,用双峰检测的方法进行剪枝
3DGS-Enhancer
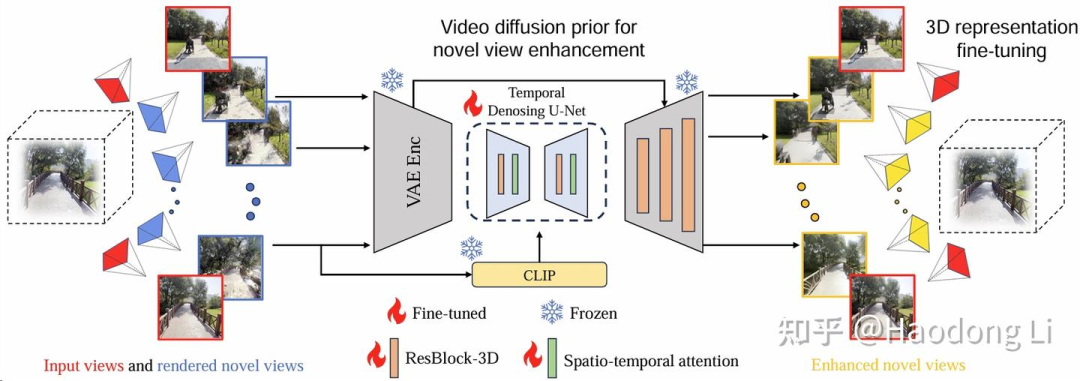
3DGS-Enhancer
用DL3DV中120个scene去Finetune VideoGen,是比较小的数据
小细节:VAE中decoder解码导致高频信息丢失,这里在Decoder部分做了一些design
WildGaussian/Wild-GS/GS-W
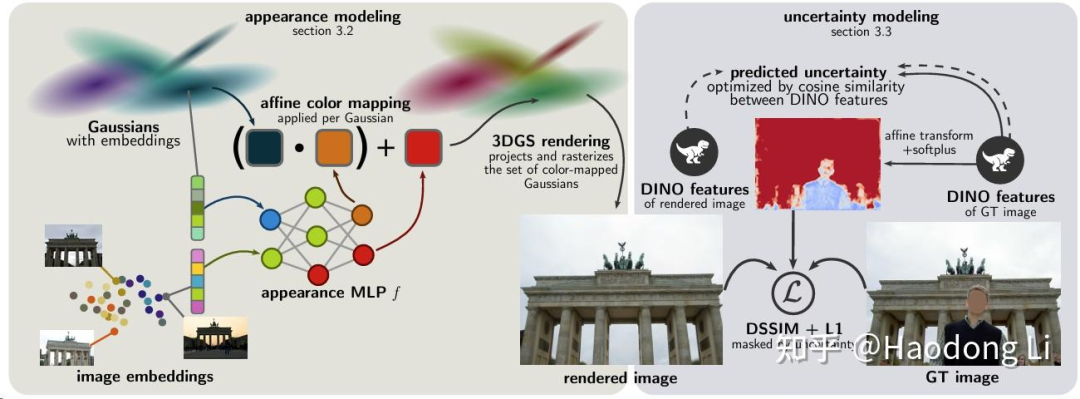
WildGaussians: 3D Gaussian Splatting in the Wild
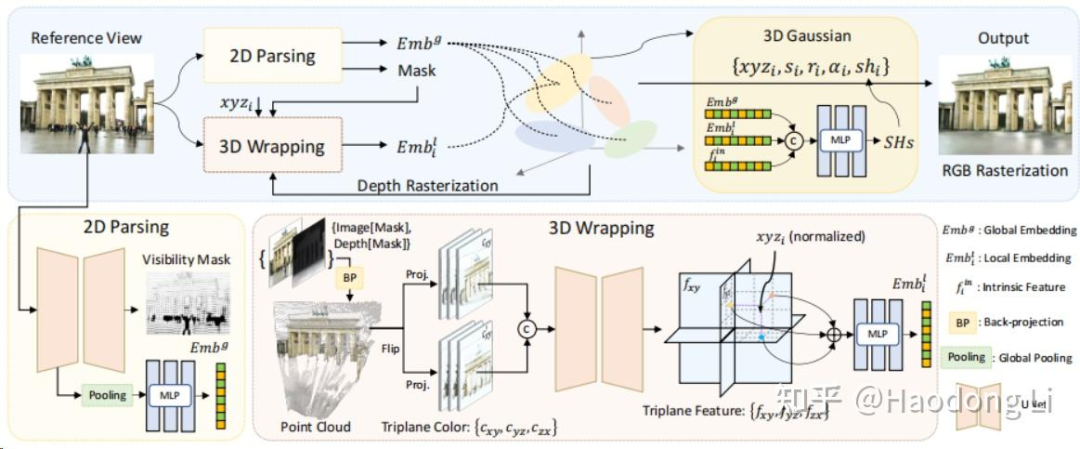
Wild-GS没开源,也没project-page
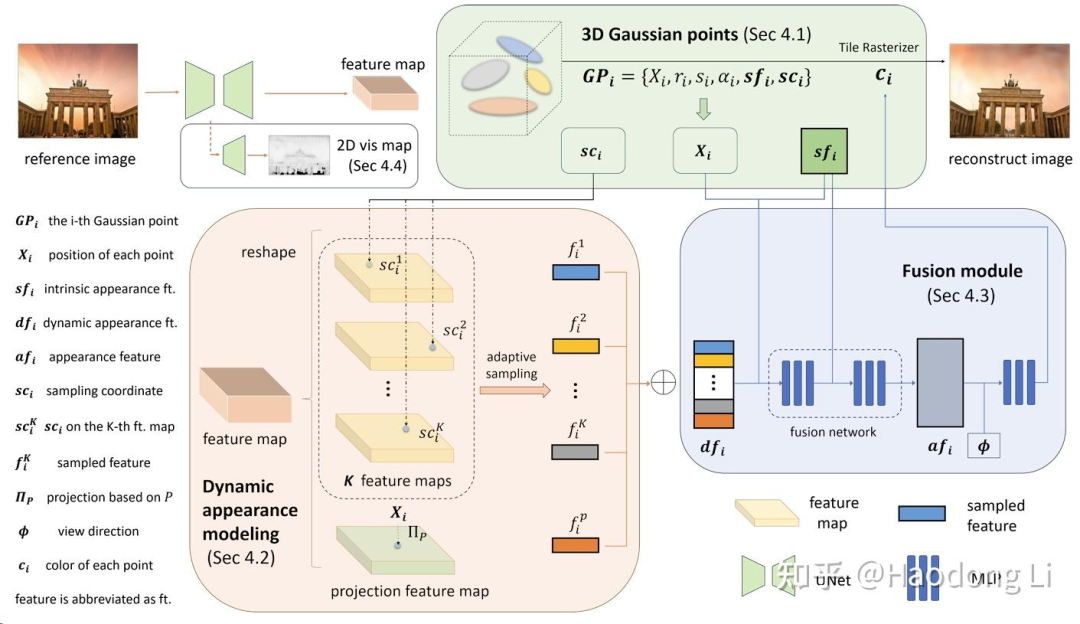
GS-W: Gaussian in the Wild
记录这几篇主要对遮挡的处理(in-the-wild task下经常要人扣除掉之类的),这三篇工作都是用强大的foundation model(DINO/UNet)得到visibility mask实现扣除遮挡物
Binocular3DGS
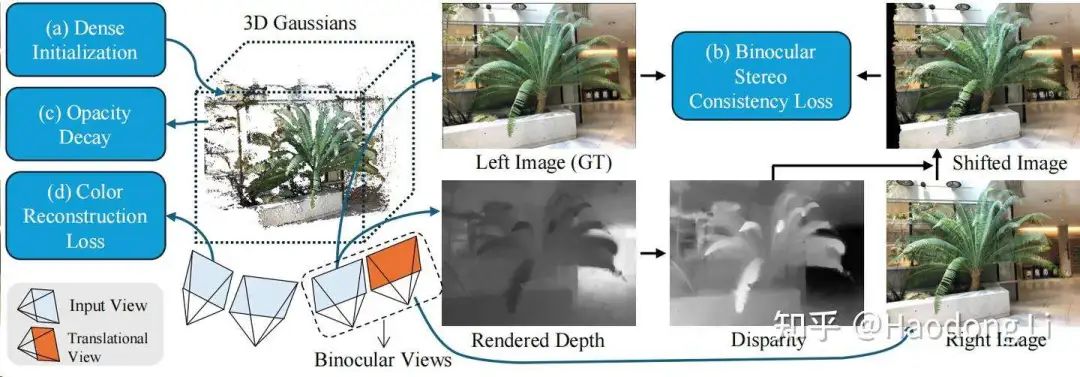
Binocular3DGS
用双目深度估计代替单目深度估计,用立体匹配的方法用视差+内参估出深度,HighLight自己不用foundation model也能做的比用了Foundation model的工作做得好
同时剪枝的地方和SparseGS剪枝效果很相似,基于opacity的剪枝策略
FreGS
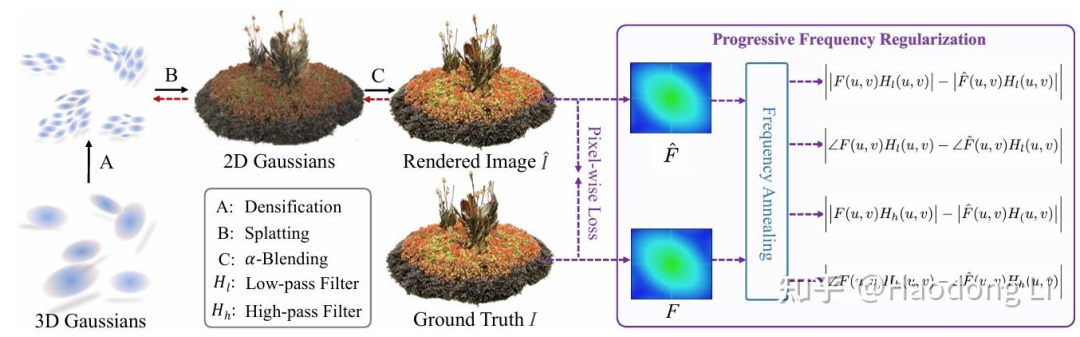
未开源,在频域上加loss
FreGS
LightGaussian
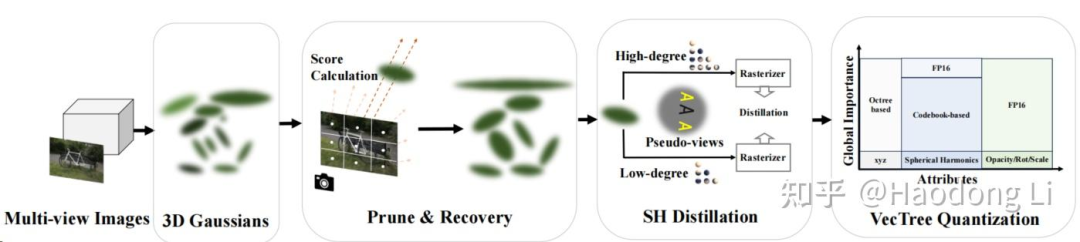
LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS
teacher model是高阶球谐系数,蒸馏给Student model是低阶球谐系数,压缩保存SH的空间
Analytic Splatting
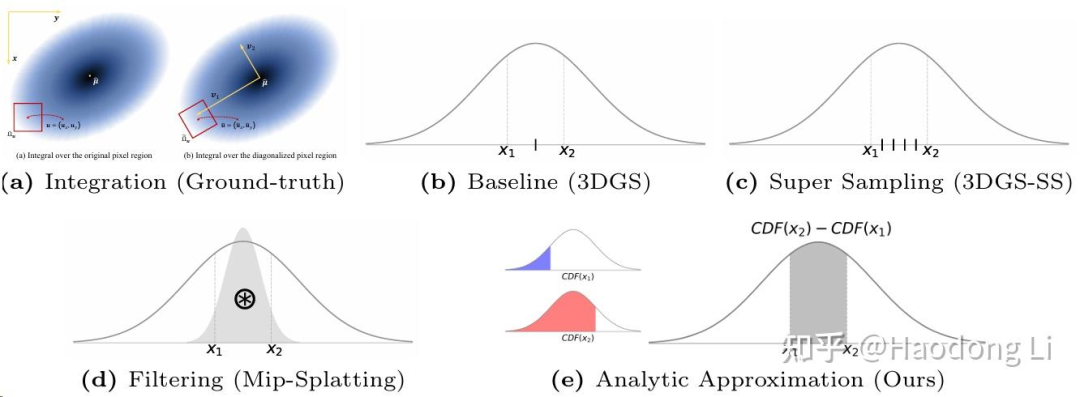
Analytic-Splatting
Spec-Gaussian
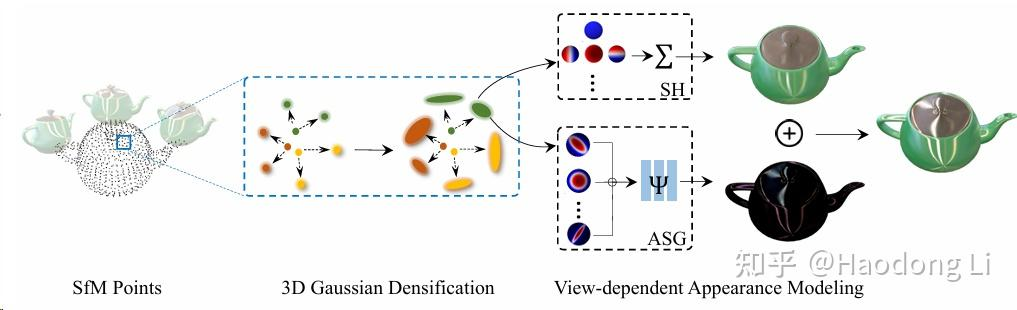
Spec-Gaussian
受限于SH的性质,3DGS本身的性质是难以做高频信息的建模(镜面/反射),将ASG+SH结合起来
其中SH学漫反射分量,ASG学镜面反射分量
同时加入Coarse-to-Fine加快收敛
StyleGaussian

StyleGaussian
将Gaussian给encode到feature space上,在feature space中做变化,再用3D CNN给decode回RGB
其实Stylize在2D里面已经做得比较好了,但是在3D中我们会HighLight mutliview consistency,这里用KNN-based 3D CNN进行多视角约束
同时在GS里面Embedding一些信息的做法是很值得学习的
GaussianEditor

GaussianEditor
先在3D model render出的multiview 2D image进行segment,将2D mask投影回3D space中Gaussian上(这个语义mark后面很多工作都在follow)
后续动态更新也会有语义追踪,所以其实它用的就是迭代式编辑
GaussianCtrl
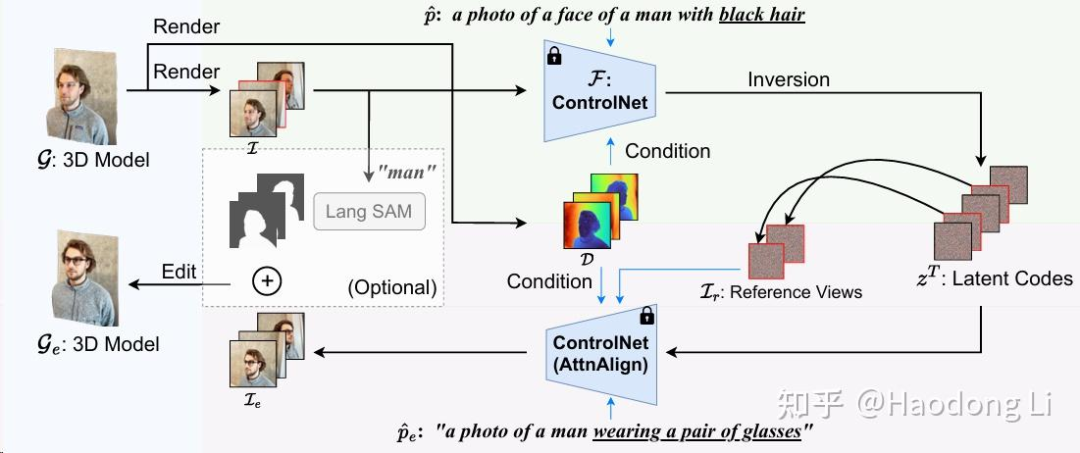
GaussCtrl
DGE
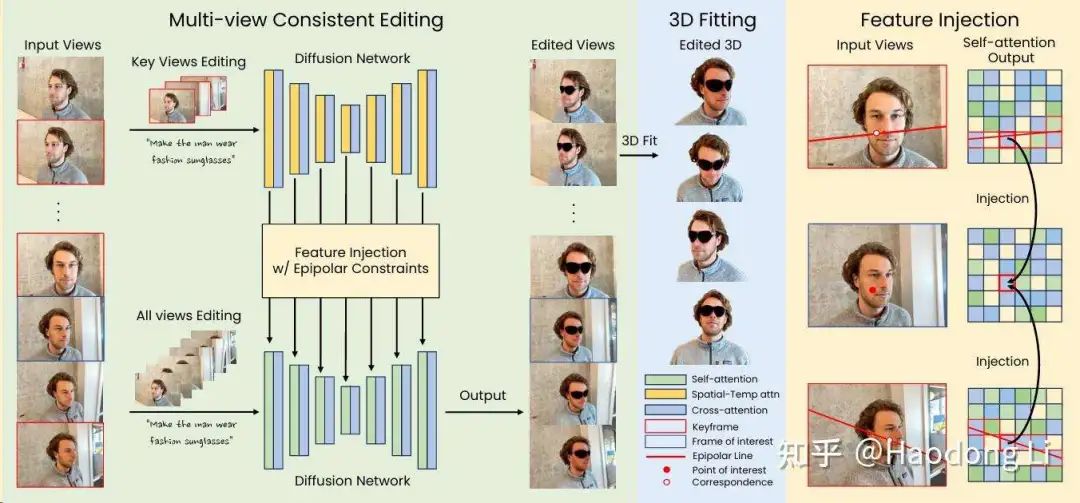
DGE
先对key frame做edit,通过epipolar进行feature injection到all frame上作为condition
再对all frame做edit,注意他参考了GaussianEditor的做法,将mark反投影到Gaussian上
frozen后景,只改变前景
TIP-Editor
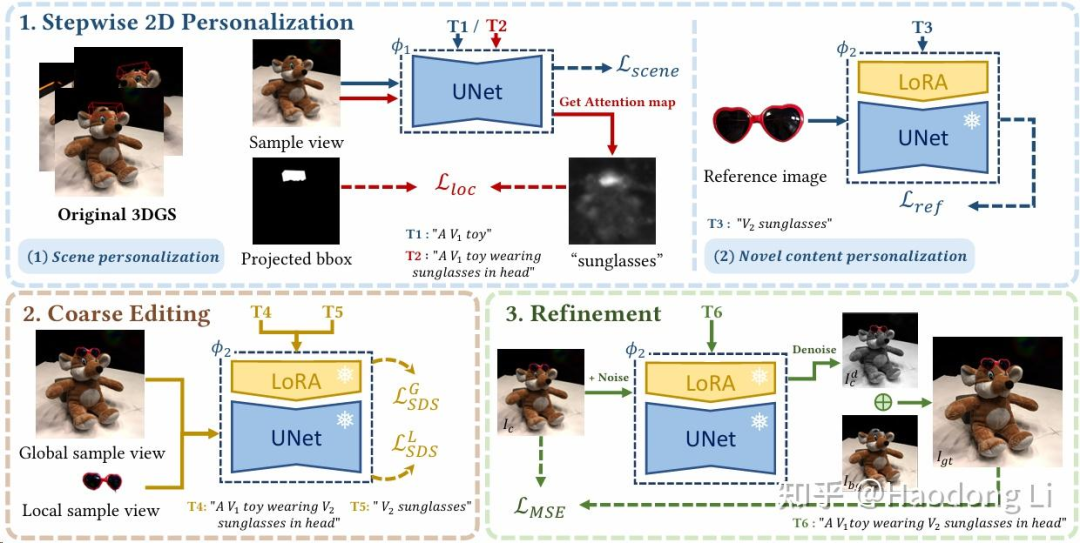
TIP-Editor
Dynamic
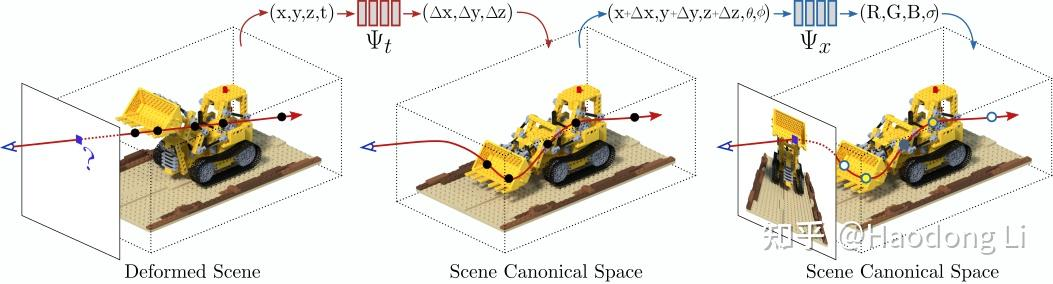
D-NeRF
Albert Pumarola - D-NeRF
很好的思路,只用一个MLP学(RGB,\sigma,motion)的信息太难了
先用一个MLP学出motion,将motion和原来的input给concat耦合在一起,再用一个MLP学(RGB,\sigma)
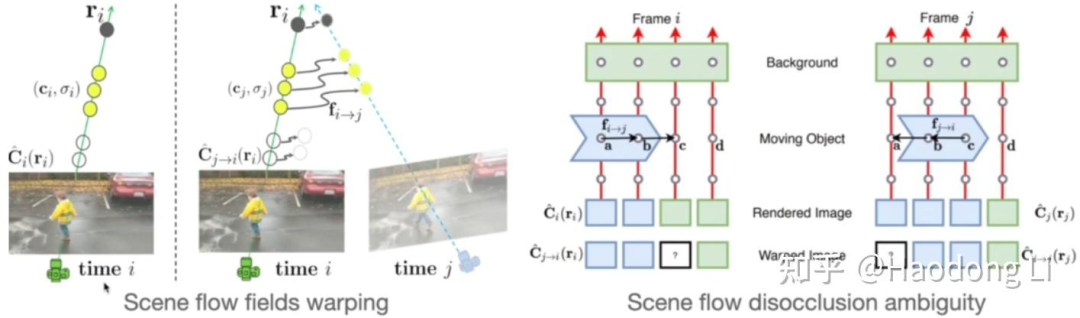
Neural Scene Flow Fields
cs.cornell.edu/~zl548/NSFF/
其实这个思路直接用来Gaussian这种显式表征上就很好做了
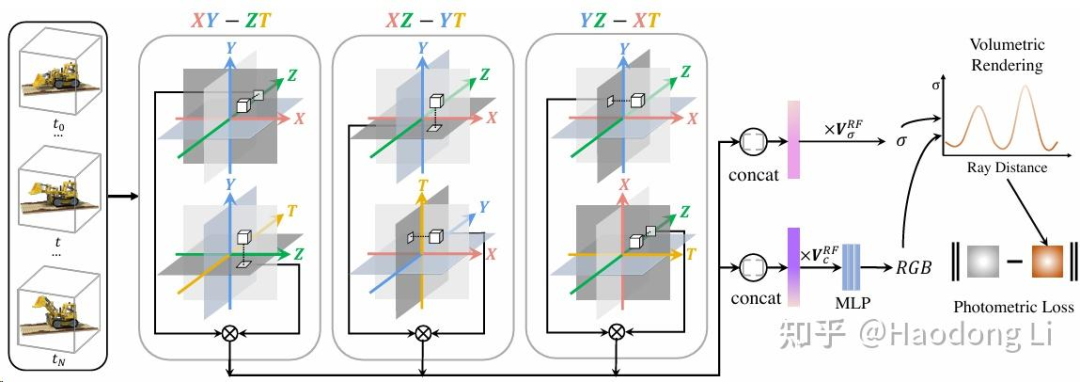
HexPlane
HexPlane
解耦成6planes,3个Static planes,3个Dynamic planes,可以将motion和appearance分开学
K-Planes
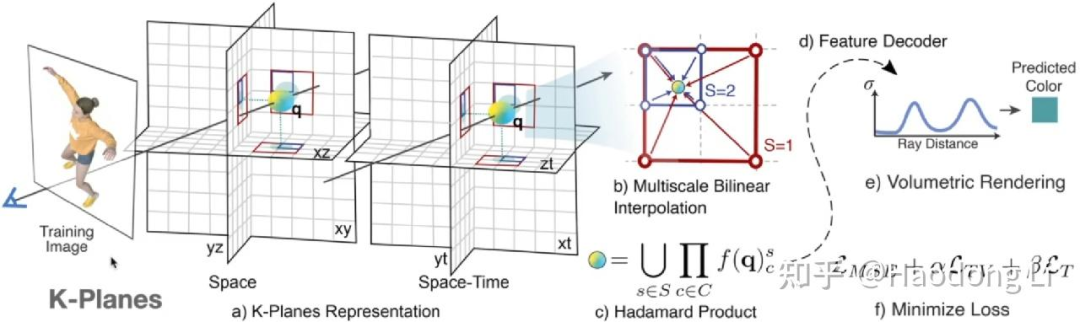
K-Plane
Gaussian-Flow
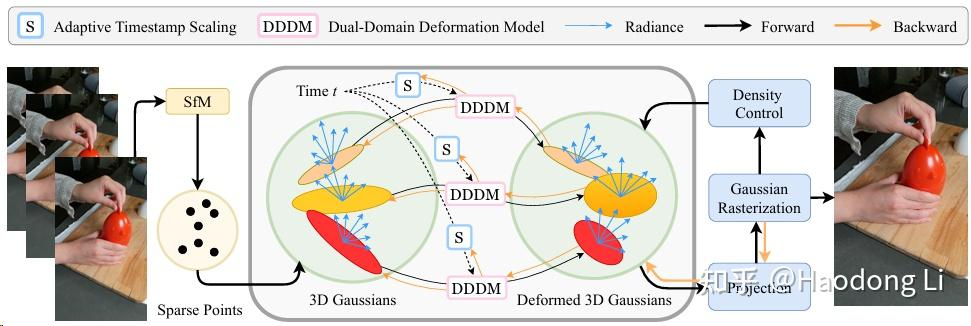
Gaussian-Flow
claim自己能做实时渲染
Mesh
这里topic下HighLight的不是extract mesh/mesh reconstruction,而是mesh generation(我比较看好这个,而且工业界很多创业公司也在做这个)
PolyGen
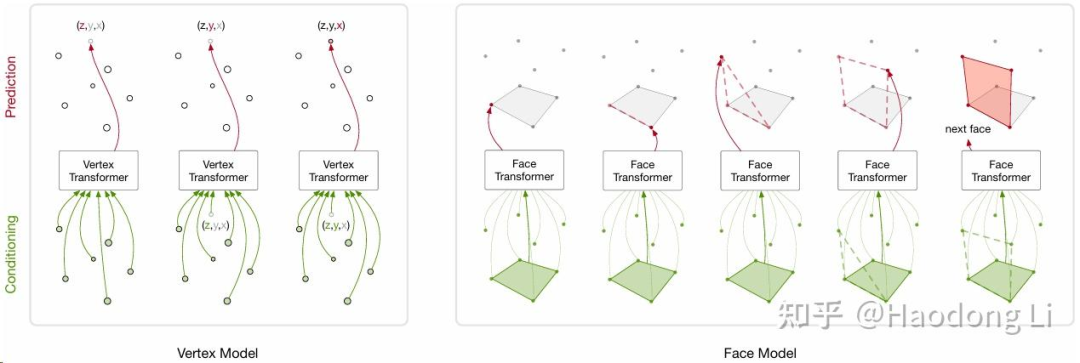
anshulcgm/polygen: Pytorch Implementation of Polygen
MeshGPT
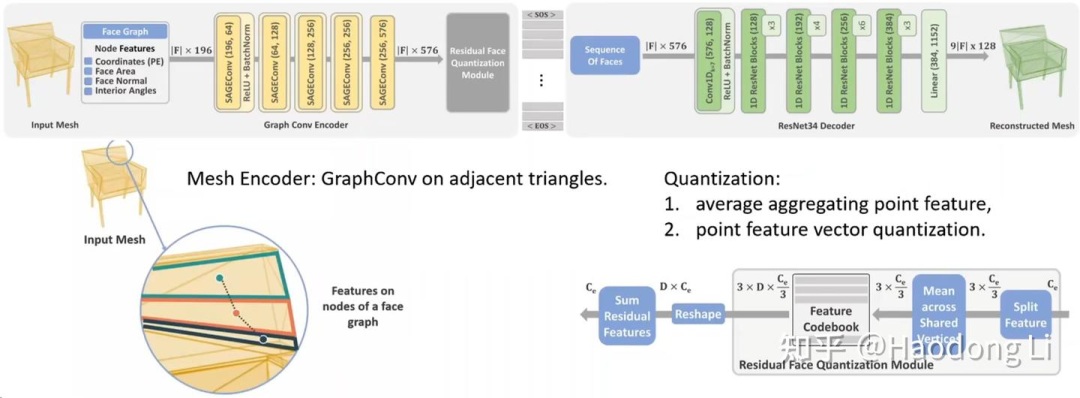
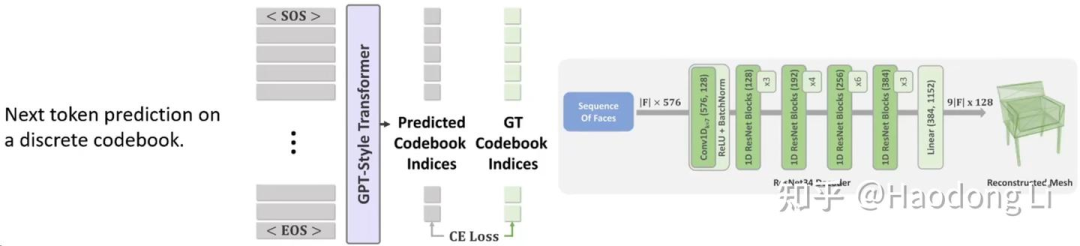
lucidrains/meshgpt-pytorch: Implementation of MeshGPT, SOTA Mesh generation using Attention, in Pytorch(unofficial code)
MeshXL
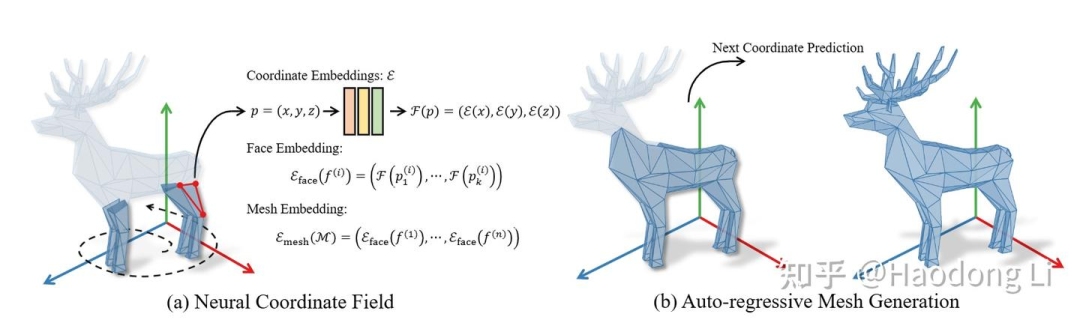
MeshXL
LLaMA-Mesh
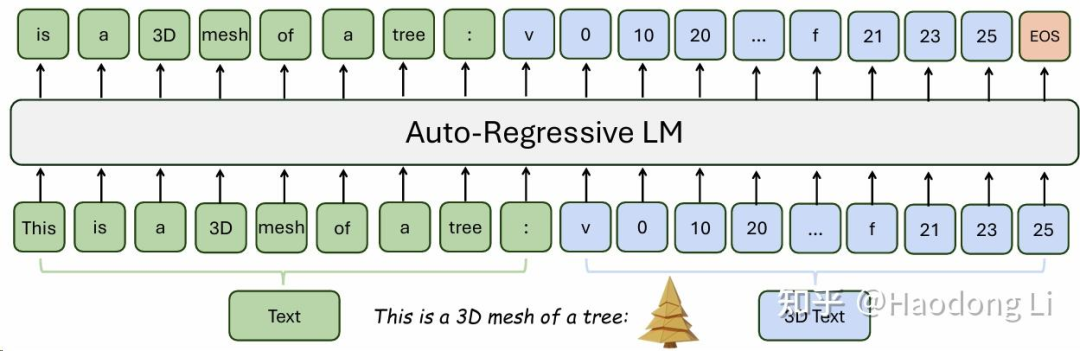
LLaMA-Mesh
Mesh本身就是Symbolic的,可以将mesh编码为纯文本的格式
这篇paper就是用Objaverse的mesh和text align在一起然后Finetune LLama-mesh
其实训的数据量不大,所以在Objaverse的domain以外的自然performance不佳
5. Surf-D
添加图片注释,不超过 140 字(可选)
Surf-D
Depth
0. MiDaS
MiDaS
将不同scene data中depth进行Normalization,实现大数据上训练
Marigold

添加图片注释,不超过 140 字(可选)
marigold
看到另外一个做classification的工作也是类似这样,将Diffusion预测的noise和vanilla noise做loss,回传更新Diffusion
这种生成式的方法整体Geometry不错,detail也不错, sy
Surf-D
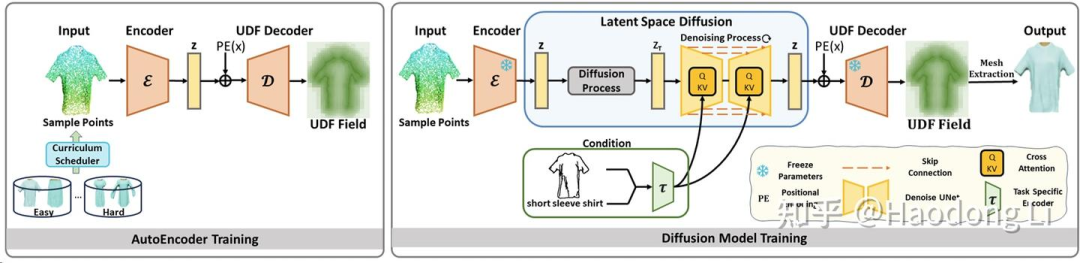
Surf-D
Depth
MiDaS
MiDaS
将不同scene data中depth进行Normalization,实现大数据上训练
Marigold
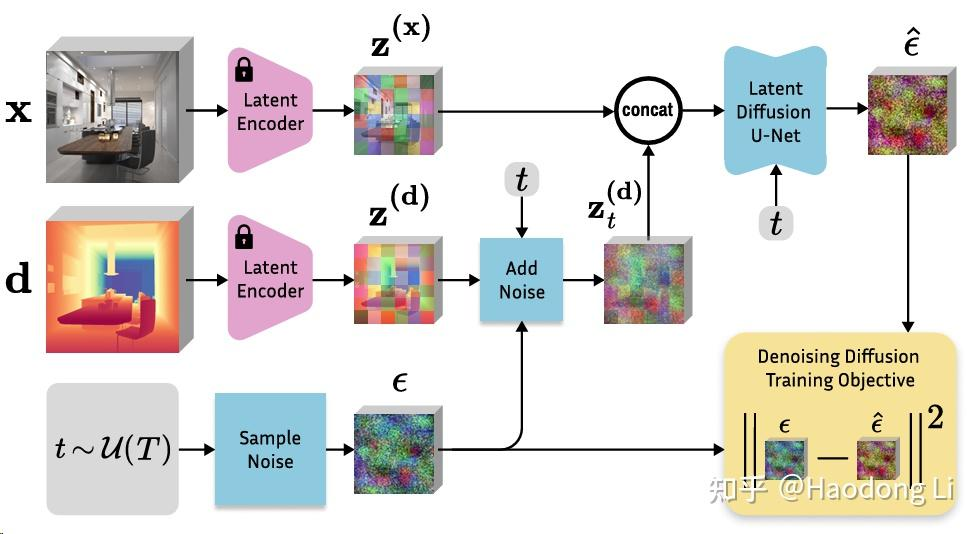
marigold
看到另外一个做classification的工作也是类似这样,将Diffusion预测的noise和vanilla noise做loss,回传更新Diffusion
这种生成式的方法整体Geometry不错,detail也不错,但是和gt存在很大gap
DepthAnythingV2

Depth Anything V2
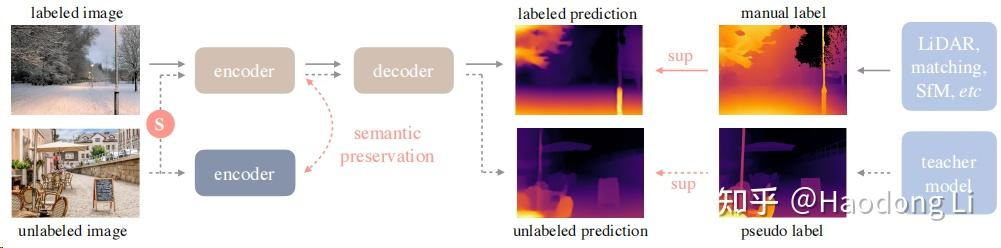
主要在HighLight用semi-supervised方法,先用有label data训teacher model给unlabel data打pseudo label,再用pseudo label训Student model
非常promoting,再很多领域RGB都是没有depth/..等gt condition的,这个时候我们就需要做知识蒸馏之类的将unlabel data用起来
DepthCrafter
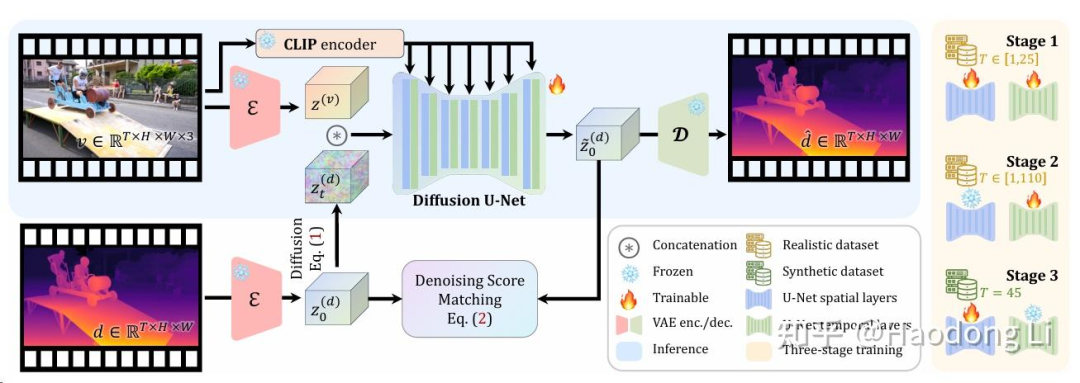
DepthCrafter
D3RoMa
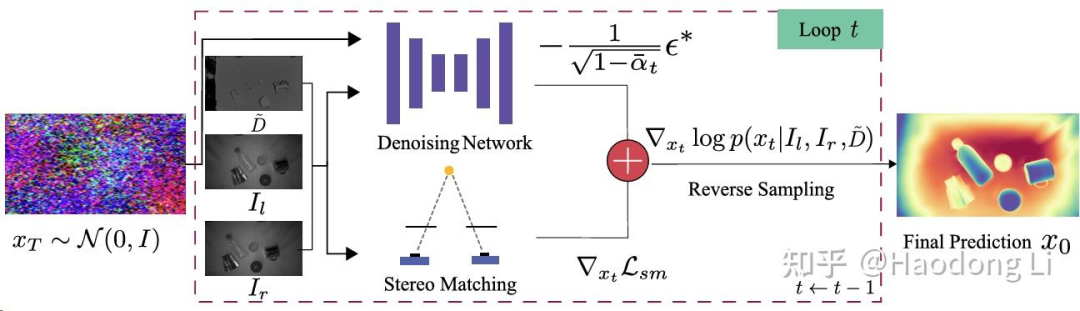
D3RoMa
双目深度估计的sota
Metric3D
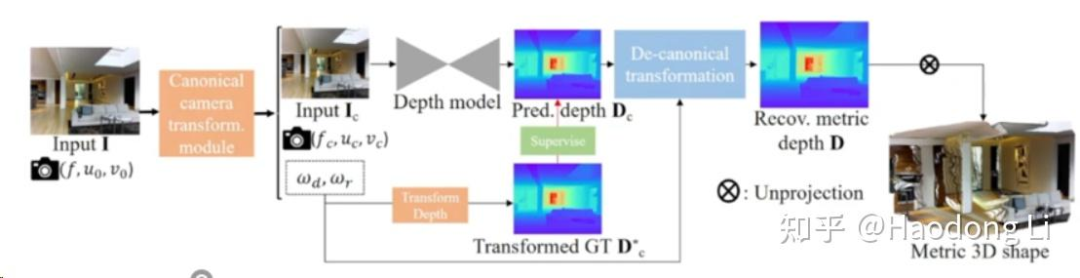
Metric3D
注意区分绝对深度&相对深度:类似MiDaS之类的需要对深度进行Normalization的一定是相对深度估计
Normal
GeoWizard
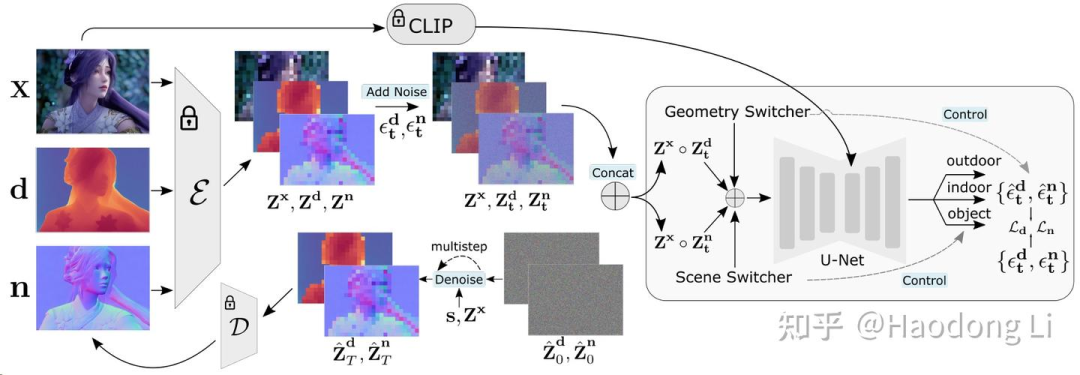
GeoWizard
将Depth和Normal两个模态放在generate model里面一起学
缺点是不鲁棒,受random seed的initialization影响很大
StableNormal
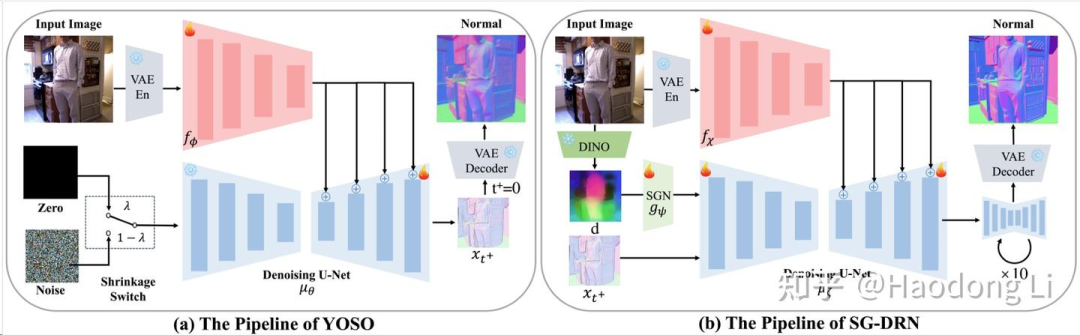
StableNormal
针对GeoWizard初始化不鲁棒的问题提先用YOSO做initialization再用SG-DRN对Normal做refinement
提供data scale up和DINO强大backbone进行enhance performance
by the way,DINO被用来很多generate model中作为condition
Relight/Inverse Render(IR)
GS-IR
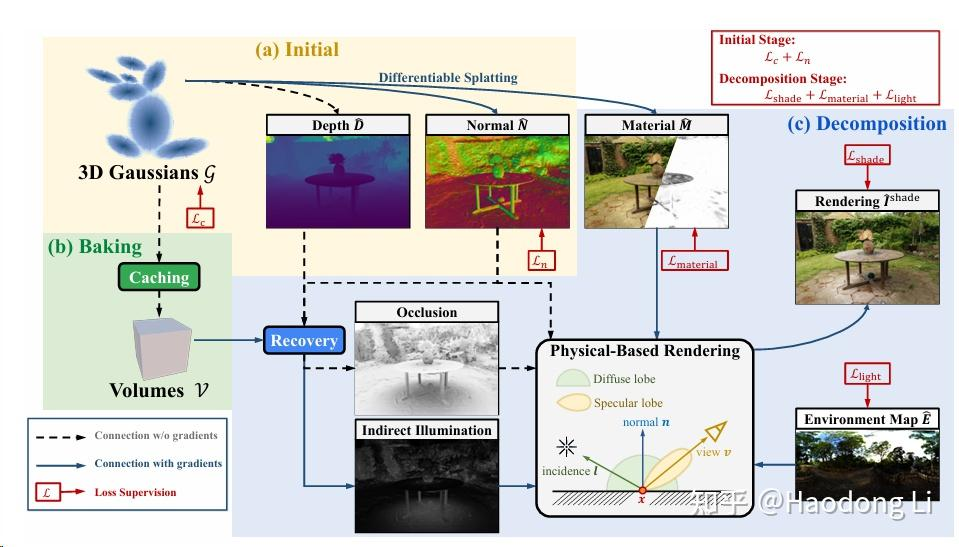
GS-IR
Autonomous Driving
Autonomous Driving的background一定时序的,类似4D,所以整体建模时序就只有两类 1. Fusion-based(建模多帧融合) 2. Streaming-based(建模变化量)
DrivingWorld
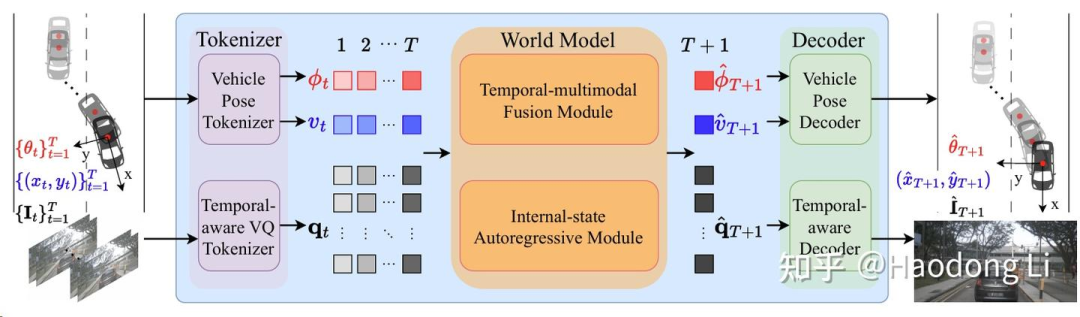
DrivingWorld
对orientation/location/image分别tokenization后,通过fusion module对时序和帧内information进行fusion
用autogression model进行prediction,值得注意的是autogression world只做单帧的prediction降低计算开销
DOME
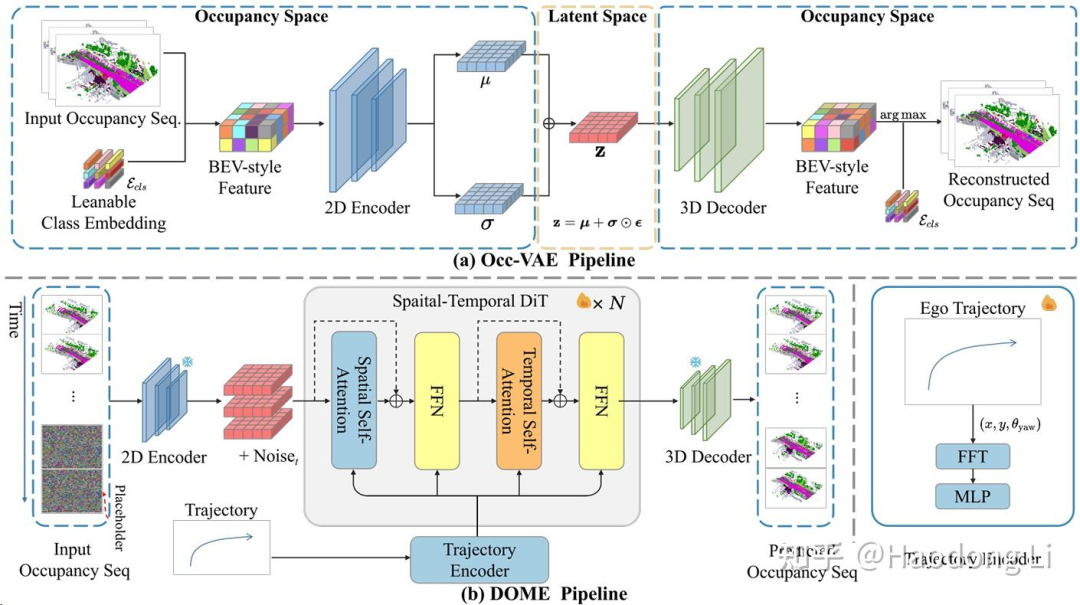
DOME
用DiT-based generation生成next frame Occupancy space,同时用VAE compress Occupancy space performance优于discrete VQ-VAE
同时在data design上,现有data size太小而且不够diverse(往往都是直线),对于scene Trajectory进行resample得到large size&diversity Occupancy data
GaussianWorld
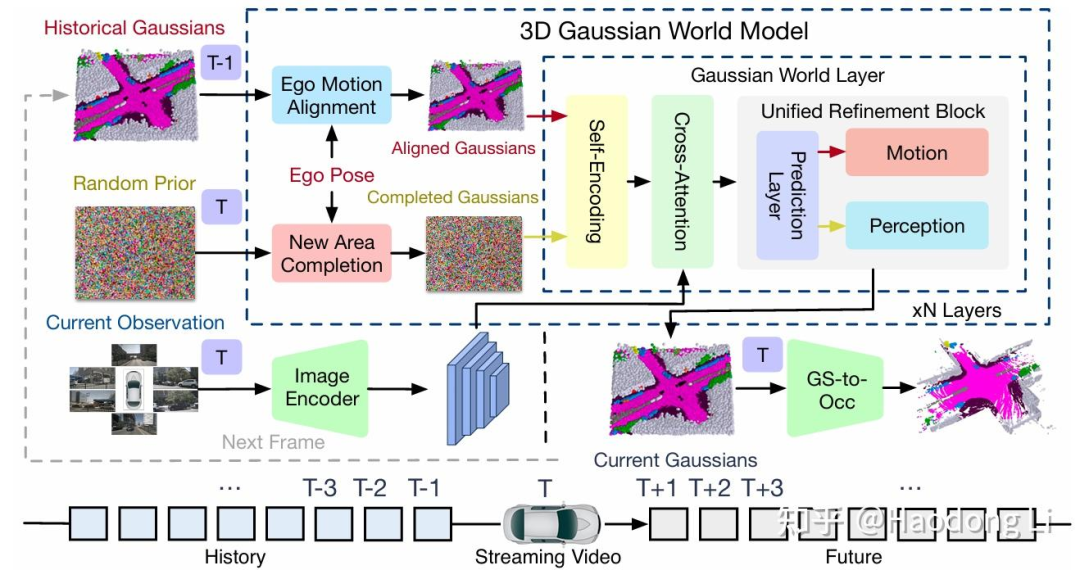
GaussianWorld
使用Streaming范式建模,同时用Gaussian分层表征scene
DynamicCity
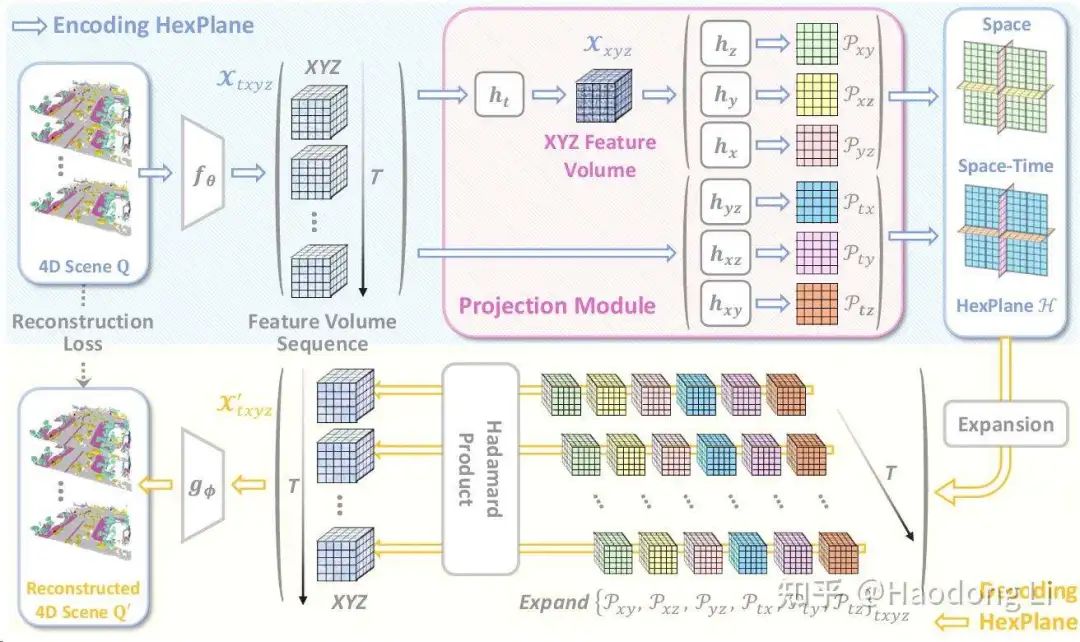
DynamicCity
不是很看得懂这种Occ generation,以前ECCV也看到过一篇
embodied AI
EgoExoLearn
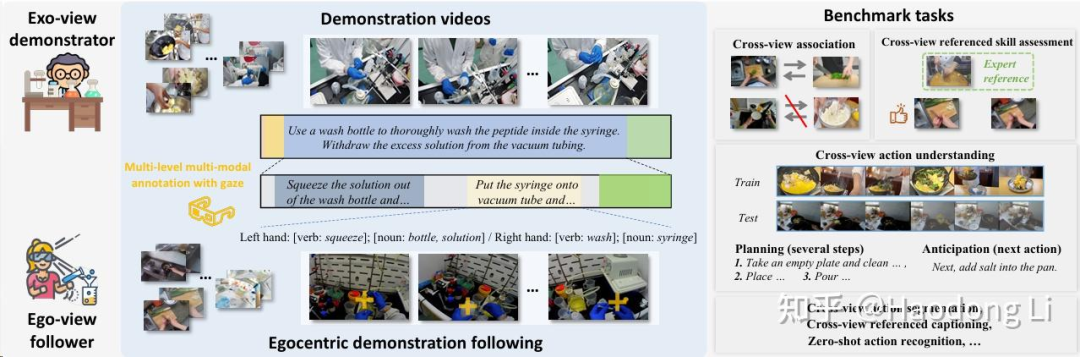
EgoExoLearn
EgoInstructor
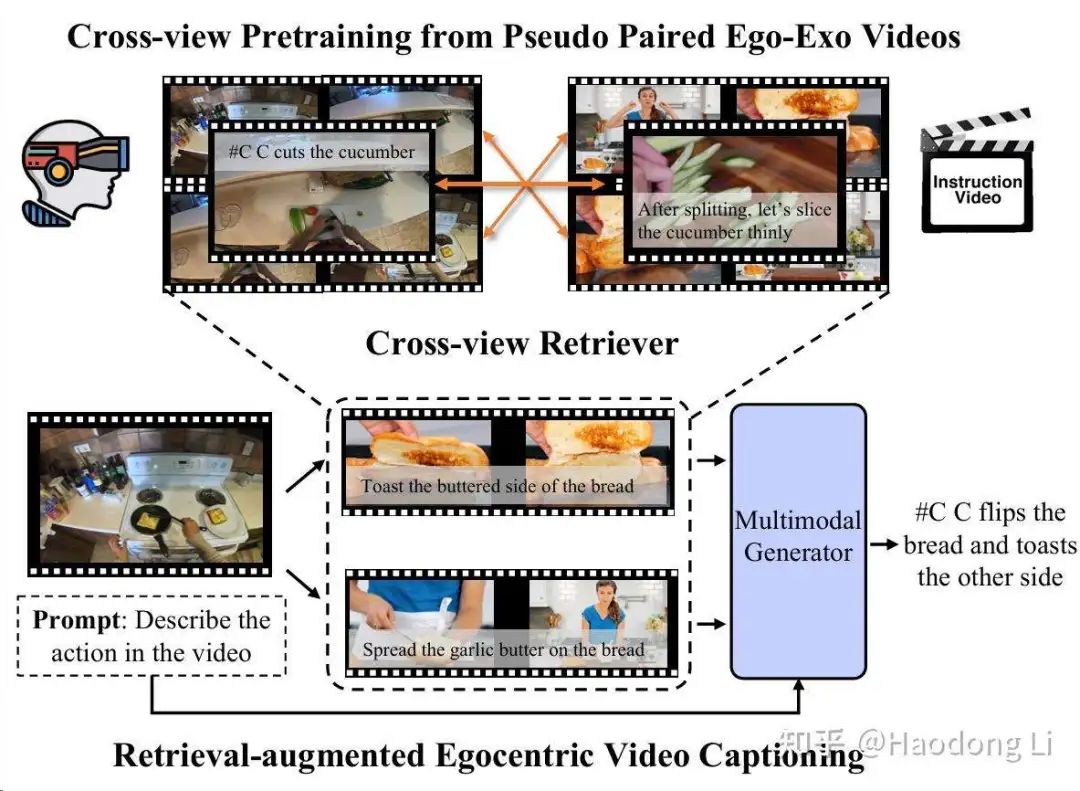
EgoInstructor
Vinci
Vinci
Tool
Videotuna

VideoTuna: Let's Finetune Video Generation Models!
qifeng组的工作,可以支持t2v/i2v model的inference&Finetune
inference:CoVideoX/OpenSora/VideoCrafter/DynamiCrafter/Flux
Finetune:DynamiCrafter/OpenSora/Videocrafter(LoRA)/CogVideoX
gsplat

GSPLAT
基本都用这个库写vanilla Gaussian training和viewer
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 718
718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









