







交叉设计(cross-over design)作为一种将自身对照和组间比较相结合的设计方法,它通过按事先设计好的试验次序(sequence),对每个受试者(subject)在整个试验的不同阶段(period)均接受不同的处理,使得相比平行组设计具有更高的试验效率,在自愈性慢性疾病、药物生物利用度和生物等效性研究方面广泛运用。
新药临床试验中,常采用交叉试验设计比较两种或多种药物的疗效差异。众所周知,优效性试验设计(Superiority Design)是证明一种药物(医疗器械/治疗手段等)的疗效是否优于另一种药物(医疗器械/治疗手段等)的经典研究设计方法。但随着医学的快速发展,在已有非常有效的治疗手段的基础上,进一步证明某种新手段疗效显著优于现有疗法通常是非常难的,特别是当技术上没有大的突破时。同时,对于某些疾病,出于伦理学考虑,并不总能进行安慰剂对照的优效性试验设计,需要选择阳性药物或标准治疗做对照。而非劣效试验设计(Non-Inferiority Design)主要研究目的是显示对试验药的反应,在临床意义上不差于(非劣于)对照药的试验。现在已经有越来越多的新药和医疗器械都是通过非劣效试验设计来完成临床试验并通过药品/器械审批部门的审批上市。
任何研究的样本含量的估计,都应该根据研究目的、研究设计的类型、研究资料的性质、接受的处理因素、研究对象的种类以及其具体的统计学方法等因素而决定。因此,在样本含量估计前,一定要事先表明检验假设的内容及其统计学方法。每一种不同的检验所对应的样本含量的估计均不相同。这里主要介绍研究设计为2x2交叉设计,主要评价指标为定量资料时,两个均数比较时非劣效性试验的样本含量的主要计算公式:
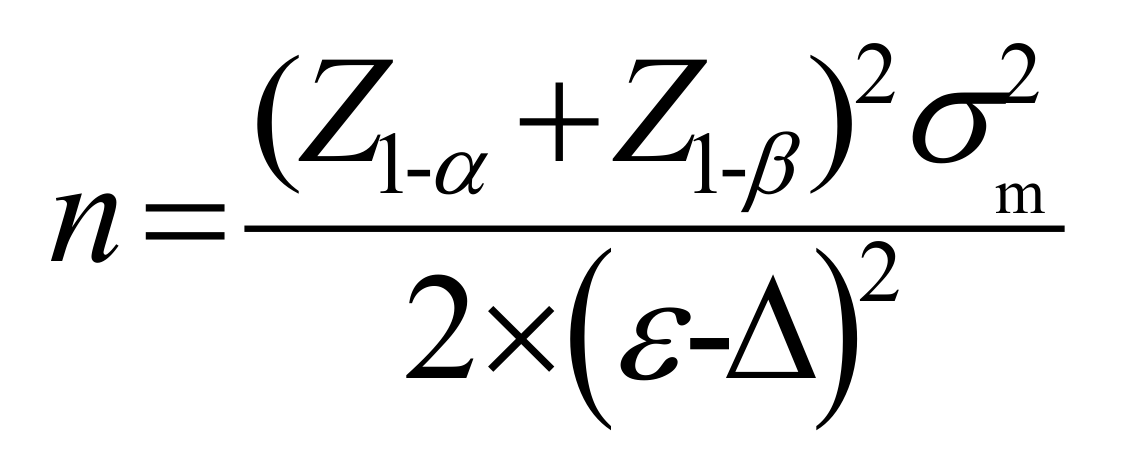
公式中n代表每组所需的样本含量;σm代表个体前后差值的标准差;ε为阳性试验组与对照组的均数之差(ε=μT-μC);Δ表示具有临床意义的非劣效界值(公式中,Δ<0);Z1-α表示标准正态分布的第1-α分位数或单侧α界值和Z1-β表示标准正态分布的第1-β分位数或单侧β界值,Z1-α和Z1-β均可通过查阅Z值表获得。
本节将主要讲解采用PASS15软件实现2x2交叉设计两样本均数比较时临床非劣效性试验的样本所需的样本含量估计方法。
例:一项临床试验研究某新型降压药治疗高血压的作用,与对照药品进行两组平行交叉对照设计。A组先服用新降压药1个月,经过2周洗脱期后开始服用对照药1个月;B组反之。如果新型降压药比对照药品平均多降收缩压5mmHg,则认为有价值推广。估计新型药物和对照药品收缩压降低值差值的标准差为10mmHg。规定α=0.05,检验效能(1-β)=0.9,假设该新药降低收缩压能力低于对照药1mmHg就认为有临床意义,则双侧非劣效检验,每组需要多少样本?
解析:本例是个2x2交叉设计的两样本均数比较非劣效性检验的临床研究,其主要结局指标是收缩压降低值,为连续型变量,且为高优指标,本例主要确定了五个参数:①两组均值的差值ε=μT-μC=5mmHg;②个体前后差值的标准差=10mmHg;③非劣效界值Δ=-1mmHg;④α=0.05;⑤检验效能(1-β)=0.9。
PASS软件样本含量估算的具体步骤:
01 PASS主菜单进入样本含量估算设置界面:
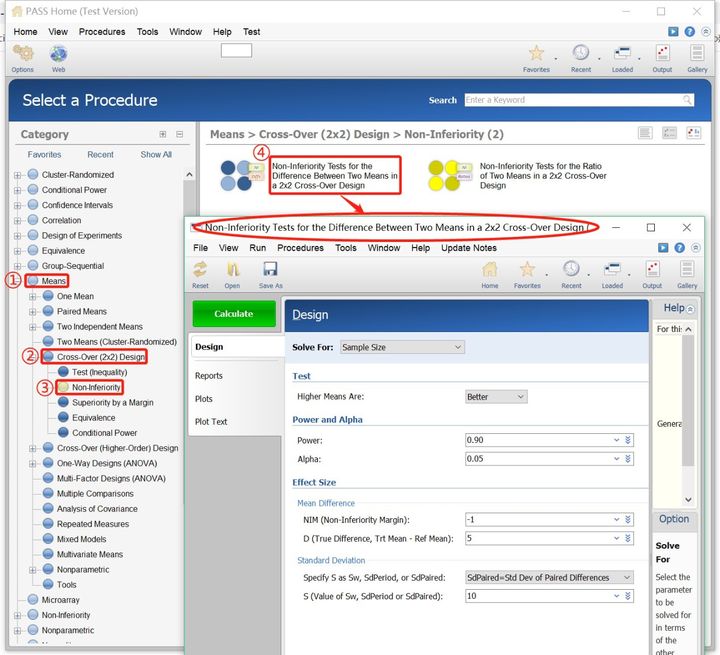
打开PASS15软件,①点击Means菜单并双击或其前面的“+”展开子菜单栏;→②点击Cross-Over(2x2)Design菜单并双击或其前面的“+”展开子菜单栏;→③点击Non-Inferiority;→④点击Non-Inferiority Tests for the Difference Between Two Means in a 2x2 Cross-Over Design→弹出Non-Inferiority Tests for the Difference Between Two Means in a 2x2 Cross-Over Design对话框进入2x2交叉设计两均数比较时非劣效性检验的样本含量估计界面,详见操作示意图(图1)。
02 PASS样本含量估算参数设置:
①Solve For:Sample Size,首先说明我们本次所求的结果为样本含量;→②HigherMeans Are:Better,指定指标类型“高优”指标(选“Worse”则表示为低优指标);→③Power:0.90,表明检验效能为0.90;→④Alpha:0.05,设定其检验水准α=0.05;→⑤NIM(Non-Inferiority Margin):-1,指定非劣效界值;→⑥D(True Difference,Trt Mean- Ref Mean):5,指定试验组与对照组的两均数之差,本例μT-μC=5(常假设为0);表明差值的均值为5mmHg;→⑦Specify S as Sw,SdPeriod,or SdPaired:SdPaired=Std Dev of Paired Differences),指定标准差的类型(三种类型的方差:方差分析的均方差Sw、每个样本阶段间变化的标准差SdPeriod和对子间差值标准差SdPaired,选择不同方差意味着提供的公式也不一样,用户可以根据实际情况合理选用),本例S设为对子间差值标准差;→⑧S(Value of Sw,SdPeriod,or SdPaired):10,个体前后差值的标准差,本例标准差估计值=10;→⑨点击Calculate按钮,完成2x2交叉设计两均数比较时非劣效性试验的样本含量估算,详见操作示意图(图 2)。

03 PASS样本含量估算结果:
由图3可知,PASS软件给出2x2交叉设计两样本均数比较时非劣效性检验的结果只有一个:检验效能、总样本含量估算的结果、非劣效界值、两均值之差、检验水准、第II类误差和个体前后差值的标准差。由于2x2交叉设计,一般为1:1设计,故本次总样本含量(N)=26例=试验组样本含量+对照组样本含量=13+13。本研究最少需要26例研究对象。

想要了解更多统计教程相关知识,请登录常笑医学网(www.cxmed.cn)中医学统计栏目进行查询和学习。















 8295
8295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









