






边界注意力(Boundary Attention)是一种新型的注意力机制,主要用于从图像中检测和推断边界结构,包括边缘、角点、交叉点等。
我还整理出了相关的论文+开源代码,以下是精选部分论文
更多论文料可以关注 :AI科技探寻,发送:111 领取更多[论文+开源码】
:AI科技探寻,发送:111 领取更多[论文+开源码】
论文1
标题:
Boundary-Aware Axial Attention Network for High-Quality Pavement Crack Detection
用于高质量路面裂缝检测的边界感知轴向注意力网络
方法:
-
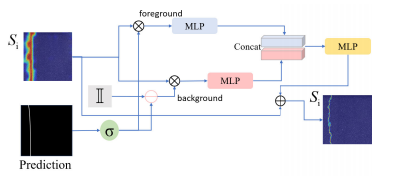
位置引导的轴向注意力模块(PAA):提出了一种将二维注意力分解为两个一维位置引导注意力的机制,分别沿水平和垂直方向计算,以降低计算复杂度并扩展模型的感受野。
-
边界正则化模块(BRM):通过显式整合前景和背景信息,对不同空间区域之间的模糊细节进行正则化,以更准确地识别裂缝的边界。
-
边界细化损失(BRL):提出了一种新的损失函数,专注于边界像素而非区域,以解决高度不平衡的前景-背景分割问题,为优化提供补充信息。
-
层次化编码器-解码器架构:构建了一个包含多个PAA模块的层次化编码器-解码器网络结构,用于高效地学习裂缝的局部细节和全局上下文信息。
创新点:
-
PAA模块:通过将二维注意力分解为一维注意力,显著降低了计算复杂度,同时通过在查询、键和值中嵌入位置信息,提高了模型对裂缝空间结构的感知能力。
-
BRM模块:通过显式学习前景和背景之间的关系,显著提高了裂缝检测的准确性。
-
BRL损失:通过专注于边界像素,解决了传统像素级交叉熵损失在处理不平衡数据时的不足。使用BRL后,模型在边界区域的检测精度显著提高。
-
整体性能提升:BAAN在多个裂缝检测数据集上均表现出色,例如在CrackTree260数据集上,ODS、OIS和AP指标分别达到了0.971、0.974和0.977,相比其他方法有显著提升。
论文2
标题:
ABANet: Attention Boundary-Aware Network for image segmentation
ABANet:用于图像分割的注意力边界感知网络
方法:
-
注意力门控机制(AG):在跳跃连接中引入注意力门控模块,以增强网络对显著特征区域的学习能力,特别是在处理掩膜与非掩膜区域的边界时。
-
混合损失函数:提出了一种包含焦点损失(Focal Loss)、SSIM损失和IoU损失的混合损失函数,用于在像素级、块级和地图级提供监督,以实现更准确的区域分割和边界预测。
-
两阶段网络架构:设计了一个包含分割网络和细化网络的两阶段架构,其中分割网络负责初步分割掩膜区域,细化网络进一步优化掩膜边界。
-
特征级注意力:选择特征级注意力而非空间级注意力,以更好地适应复杂的面部结构和轮廓,同时减少对空间变化的敏感性。
创新点:
-
注意力门控机制(AG):通过在跳跃连接中引入AG,显著提高了分割精度。
-
混合损失函数:通过结合焦点损失、SSIM损失和IoU损失,模型在训练过程中能够更好地处理不平衡的正负样本分布。使用混合损失后,IoU指标从91.262提升到93.814,F1分数从94.18提升到96.817。
-
两阶段架构:通过分割网络和细化网络的结合,模型能够更精确地预测掩膜边界。
-
整体性能提升:ABANet在MFSD数据集上的表现优于其他先进方法,例如在IoU、F1分数、精度和准确度等指标上分别达到了93.814、96.817、97.164和97.623,相比其他方法有显著提升。
论文3
标题:
ActionFormer: Localizing Moments of Actions with Transformers
ActionFormer:使用Transformer定位动作时刻
方法:
-
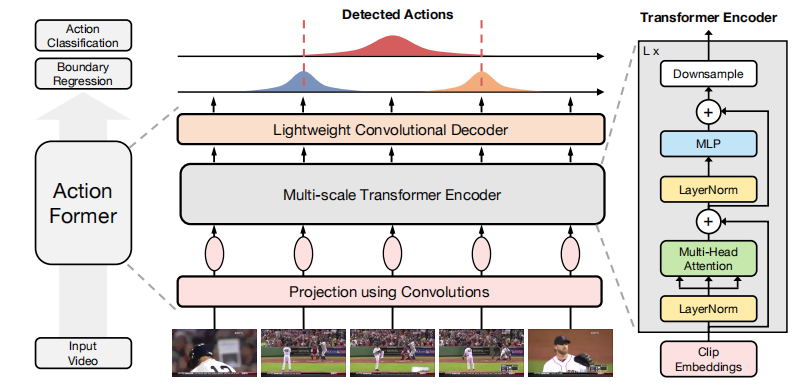
Transformer架构:提出了一种基于Transformer的模型ActionFormer,用于单次检测视频中的动作实例并识别其类别,无需使用动作提议或依赖预定义的锚点窗口。
-
多尺度特征表示:结合局部自注意力机制,从输入视频中提取多尺度特征金字塔,每个位置代表视频中的一个时刻,被视为动作候选。
-
轻量级解码器:使用轻量级卷积解码器对特征金字塔进行分类和回归,预测每个时刻的动作类别和对应的边界距离。
创新点:
-
单阶段无锚点设计:ActionFormer是首个基于Transformer的单阶段无锚点模型,直接在输入视频上进行动作定位和分类,无需复杂的提议生成和解码过程。
-
局部自注意力机制:通过限制自注意力的范围为局部窗口,显著降低了计算复杂度,同时保持了对长距离依赖的建模能力。在ActivityNet 1.3数据集上,使用局部自注意力的模型平均mAP达到了36.6%,优于使用全局自注意力的模型。
-
多尺度特征金字塔:设计了多尺度特征金字塔,能够捕捉不同时间尺度上的动作特征,提高了模型对动作边界的定位精度。在EPIC-Kitchens 100数据集上,该模型平均mAP达到了23.5%,比之前的最佳方法高出超过13.5个百分点。
-
端到端训练:整个模型通过标准的分类和回归损失进行端到端训练,简化了训练过程,提高了模型的泛化能力。
论文4
标题:
Progressive Attention on Multi-Level Dense Difference Maps for Generic Event Boundary Detection
在多级密集差异图上进行渐进式注意力的通用事件边界检测
方法:
-
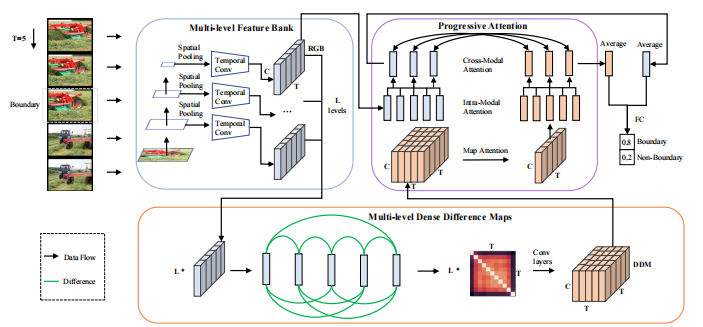
多级特征库:构建一个多级特征库,存储不同空间和时间尺度的特征,为多尺度差异计算做准备。
-
密集差异图(DDM):提出密集差异图来全面表征运动模式,通过计算视频片段中每两帧之间的特征差异,获得更丰富的运动信息。
-
渐进式注意力:在多级DDM上应用渐进式注意力机制,联合聚合外观和运动线索,提高对事件边界的判别能力。
创新点:
-
密集差异图(DDM):与传统的光流或RGB差异相比,DDM能够提供更全面和密集的运动信息,显著提高了模型对事件边界的检测精度。在Kinetics-GEBD数据集上,使用DDM的模型在最严格的阈值(Rel.Dis.=0.05)下,F1分数从62.5%提升到76.4%,提高了13.9个百分点。
-
多级特征融合:通过构建多级特征库,模型能够捕捉到不同层次的运动和外观变化,从而更好地处理事件边界的多样性。在TAPOS数据集上,该模型将F1分数从52.2%提高到60.4%,提升了8.2个百分点。
-
渐进式注意力机制:通过渐进式注意力机制,模型能够更有效地聚合外观和运动线索,生成更具区分性的特征表示,从而提高对复杂事件边界的识别能力。
-
端到端学习:整个模型通过端到端的方式进行训练,简化了训练过程,提高了模型的泛化能力和适应性。
更多论文料可以关注:AI科技探寻,发送:111 领取更多[论文+开源码】

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









