







文章目录
Graph Transformer for Recommendation
核心内容是提出了一种新颖的推荐系统方法,名为Graph TransFormer(GFormer),它通过结合图Transformer 架构和生成式自监督学习(SSL)来改进推荐系统中的表示学习。
-
问题背景:在推荐系统中,标签稀缺是一个常见问题。自监督学习(SSL)已成为解决这一问题的一种流行方法,它通过从未标记的数据中生成辅助监督信号。
-
方法介绍:GFormer模型的核心是利用图变换器架构来编码用户-项目交互的配对关系,并发现有用的自监督信号,这些信号具有其自身的合理性解释。该方法自动化了自监督数据增强过程,并通过任务自适应的合理化来指导图变换器。
-
主要贡献:
- 1)提出了一种新的推荐系统方法,该方法通过图变换器自动提取具
有信息性的用户-项目交互模式。 - 2)开发了一种拓扑感知的图变换器,用于整合用户-项目交互建模,并实现自动化的协作合理性发现。
- 1)提出了一种新的推荐系统方法,该方法通过图变换器自动提取具
摘要
这篇论文提出了一种新颖的推荐系统表示学习方法,该方法通过整合生成式自监督学习(SSL)和图变换器架构来实现。我们强调了使用相关自监督预训练任务进行高质量数据增强对于提升性能的重要性。为此,我们提出了一种新方法,它通过一种理由感知的生成式SSL自动化自监督增强过程,该方法能够提取信息丰富的用户-项目交互模式。我们提出的推荐系统Graph TransFormer(GFormer)提供了参数化的协作理由发现,以进行选择性增强,同时保持全局用户-项目关系。在GFormer中,我们允许理由感知的SSL启发图协同过滤,通过图变换器中的任务自适应不变合理化。实验结果表明,我们的GFormer能够在不同数据集上一致性地提高基线性能。此外,通过几项深入实验,我们进一步从不同方面调查了不变理由感知增强。
论文链接
开源代码
引言
自监督学习(SSL)已成为解决推荐系统中标签稀缺问题的流行解决方案,它通过从未标记的数据中生成辅助监督信号。通过与图神经网络(GNN)架构的协同过滤整合,SSL增强的图增强已被证明在有限的训练标签下对建模用户-项目交互有效。在当代方法中,基于图对比学习的推荐模型是使用最广泛的增强范式之一,其关键洞见是利用辅助学习任务中的监督信号,这些任务通过SSL增强的共同训练来补充主要的推荐目标。
现有的基于图对比的方法旨在通过实现生成的正样本(例如,用户自我区分)之间的表示一致性,以及最小化负样本对(例如,不同用户)之间的相似性来最大化互信息。最近的努力尝试遵循互信息最大化的原则,通过启发式数据增强器对比用户-项目交互图的不同结构视图。例如,SGL提出通过随机移除用户和项目节点及其连接来破坏图结构,以构建拓扑对比视图。然而,盲目破坏图拓扑结构可能导致用户和项目之间关键关系的丢失,例如独特的用户交互模式或长尾项目有限的标签(如图1(a)所示)。因此,明确提供学习有信息表示所需的基本自监督信号是至关重要的,这需要在设计的增强器中具有不变的合理性。
从对齐局部级别和全局级别嵌入以进行增强的角度来看,一些研究通过各种信息聚合技术获得语义相关的子图表示,例如HCCF中的基于超图的消息传递和NCL中的EM算法基于节点聚类。然而,由于它们手工制作的性质,增强的质量可能受到手动构建的超图结构和用户聚类设置的影响。因此,这些增强方案不足以使用有用的自监督信号(例如,真正的负样本对和硬增强实例)来规范训练过程。此外,**这些手动设计的对比方法可能很容易被常见的噪声(例如,误点击行为[18],受欢迎度偏见[39])所误导(如图1(b)所示)。**从有偏见的数据中引入增强的SSL信息可能会放大噪声效应,这会稀释学习真正的用户-项目交互模式。因此,现有解决方案可能在适应不断变化的实际推荐环境中的自监督过程方面存在不足。
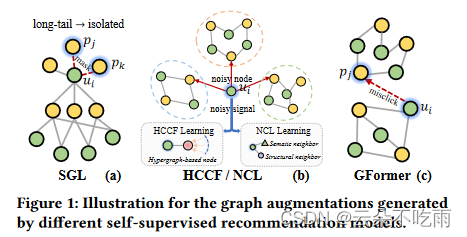
尽管在SSL增强的推荐系统中取得了进展,但一个基本问题仍然被理解不足:**在推荐中,哪些信息是关键的,应该为自监督增强而保留?**受到最近在推进自监督学习方面取得成功的掩码自编码(MAE)技术的启发,这项工作从生成式自监督增强的角度探索了上述问题,具有理由感知的不变表示学习。与对比学习不同,掩码自编码范式直接采用重建目标作为数据增强的原则性前提任务。它自然地避免了上述手动生成的对比视图数据增强的局限性。当前工作。在这项工作中,我们提出了一个新的推荐系统,使用Graph TransFormer自动提取具有不变协作理由的掩码自监督信号。我们从理由发现[26, 40]中获得灵感,以弥合图掩码自编码器与自适应增强之间的差距。我们的GFormer充分利用了变换器在显式编码成对关系方面的强大功能,以发现对下游推荐任务有益的自监督信号,并解释它们自己的理由。具体来说,我们开发了一个拓扑感知的图T
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











