






强化学习算法,DDPG算法,在simulink或MATLAB中编写强化学习算法,基于强化学习的自适应pid,基于强化学习的模型预测控制算法,基于RL的MPC,Reinforcement learning工具箱,具体例子的编程。
根据需求进行算法定制:
1.强化学习DDPG与控制算法MPC,鲁棒控制,PID,ADRC的结合。
2.基于强化学习DDPG的机械臂轨迹跟踪控制。
3.基于强化学习的自适应控制等。
4.基于强化学习的倒立摆控制。
ID:78500646485777521
欲买桂花同载酒
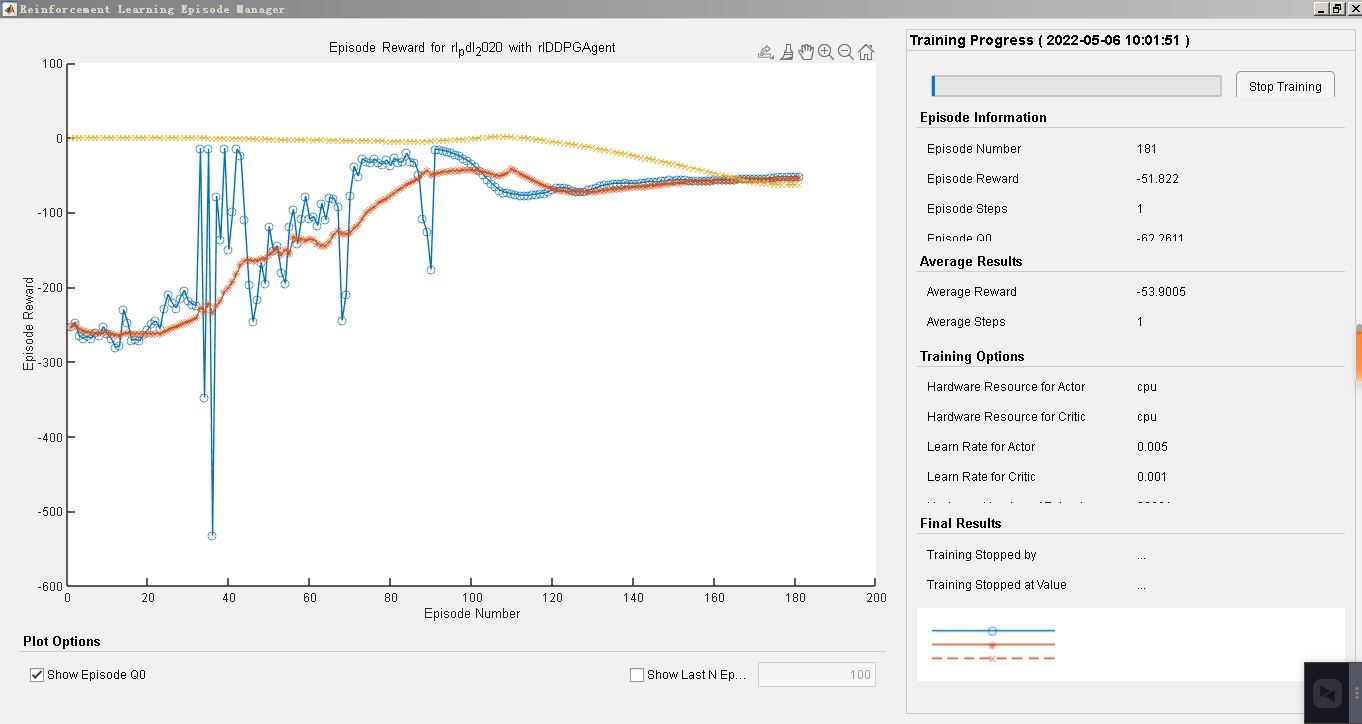

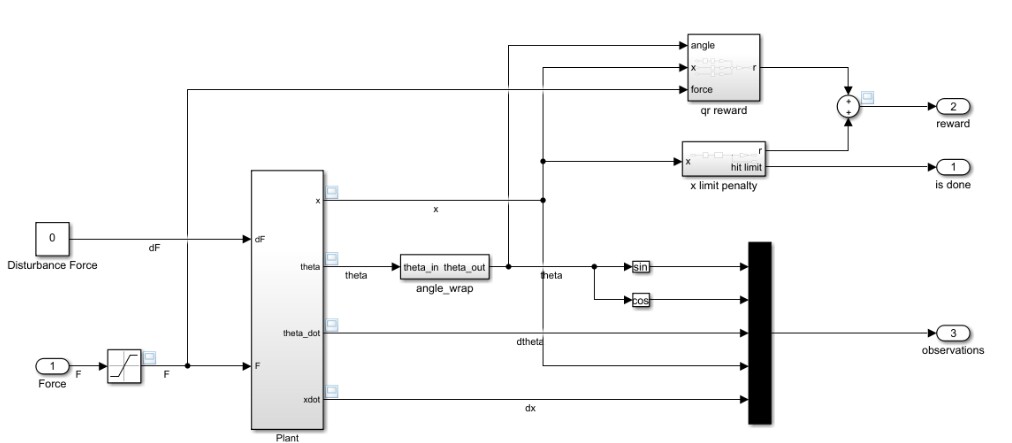

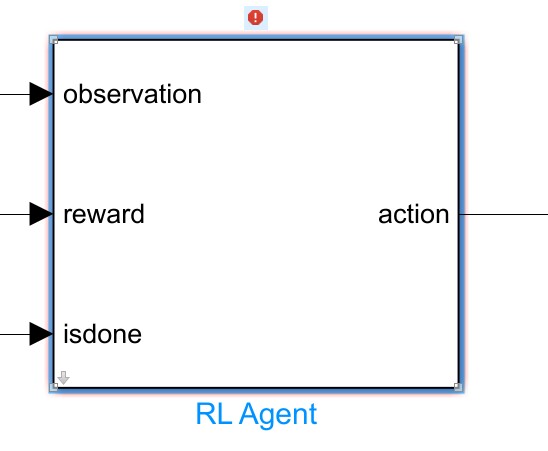
强化学习在近年来逐渐受到了广泛关注,它具有很强的适应性和智能性,能够通过与环境的交互来优化系统的控制策略。在工程领域,强化学习算法的应用也越来越广泛。本文将围绕强化学习算法和相关应用展开讨论,重点介绍DDPG算法及其在控制算法MPC、鲁棒控制、PID和ADRC等方面的结合,并给出一些具体例子的编程实现。
首先,我们来了解一下强化学习算法中的DDPG算法。DDPG全称为Deep Deterministic Policy Gradient,是一种基于策略梯度的深度强化学习算法。与传统的值函数方法不同,DDPG使用了一种连续动作空间的策略网络,能够处理高维、连续、非线性的控制问题。在simulink或MATLAB中编写强化学习算法时,可以借助深度神经网络模型,通过训练神经网络来实现DDPG算法。
接下来,我们将讨论基于强化学习的自适应PID控制算法。PID控制是一种经典的控制算法,可以通过调节比例、积分和微分参数来实现对系统的控制。但是传统的PID控制算法往往需要通过人工调参来适应系统的变化,缺乏自适应性。利用强化学习的思想,我们可以将PID控制算法与DDPG算法相结合,通过训练强化学习网络来自适应地调整PID控制器的参数,实现对系统的智能控制。
此外,基于强化学习的模型预测控制算法也是一个研究热点。模型预测控制(MPC)是一种基于系统模型的控制方法,通过优化控制变量的序列来实现对系统的控制。将强化学习算法与MPC结合,可以通过训练强化学习网络来学习系统的动态模型,并根据学习到的模型进行控制策略的优化,提高控制性能。
除了上述应用之外,强化学习还可以应用于机械臂轨迹跟踪控制、倒立摆控制等领域。在机械臂轨迹跟踪控制中,强化学习算法可以通过与环境的交互来学习到机械臂的运动规律,实现精确的轨迹跟踪。在倒立摆控制中,强化学习算法可以通过与环境的交互来找到最优的控制策略,实现倒立摆的平衡控制。
综上所述,强化学习算法在控制领域的应用十分广泛。通过结合DDPG算法与控制算法MPC、鲁棒控制、PID和ADRC等,可以实现对系统的智能控制和优化。在具体的应用中,我们可以借助强化学习工具箱进行算法的编程实现。通过对系统的建模和环境的交互,可以训练出适应性强、控制性能优越的控制策略,提高系统的稳定性和性能。
需要注意的是,本文仅仅是对强化学习算法在控制领域的一些应用进行了初步介绍,具体的算法原理和编程实现还需要进一步深入研究和探索。希望本文能够为读者提供一些思路和启发,促进强化学习算法在工程实践中的应用和发展。
(以上内容仅供参考,具体编写时可根据实际需要进行适当调整和补充)
以上相关代码,程序地址:http://matup.cn/646485777521.html















 640
640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









